

In diesem Lernprogramm werden Sie sehen:
- Was Qwen3 ist und was es von anderen LLM-Studiengängen unterscheidet
- Warum es für Web-Scraping-Aufgaben gut geeignet ist
- Wie man Qwen3 lokal für Web Scraping mit Hugging Face verwendet
- Seine wichtigsten Einschränkungen und wie man sie umgehen kann
- Einige Alternativen zu Qwen3 für KI-gestütztes Scraping
Lasst uns eintauchen!
Was ist Qwen3?
Qwen3 ist die neueste Generation von LLMs, die vom Qwen-Team von Alibaba Cloud entwickelt wurde. Das Modell ist quelloffen und kann auf GitHub frei erforscht werden – verfügbarunter der Apache 2.0-Lizenz. Das ist ideal für Forschung und Entwicklung.
Zu den wichtigsten Merkmalen von Qwen3 gehören:
- Hybrides Denken: Er kann zwischen einem “Denkmodus” für komplexes logisches Denken (wie Mathematik oder Codierung) und einem “Nicht-Denkmodus” für schnellere, allgemeine Antworten umschalten. Auf diese Weise können Sie die Tiefe des Denkens für optimale Leistung und Kosteneffizienz steuern.
- Vielfältige Modelle: Qwen3 bietet eine umfassende Palette von Modellen, darunter dichte Modelle (mit 0,6B bis 32B Parametern) und Mixture-of-Experts (MoE)-Modelle (wie die 30B- und 235B-Varianten).
- Verbesserte Fähigkeiten: Es weist erhebliche Fortschritte bei der Argumentation, der Befolgung von Anweisungen, den Fähigkeiten von Agenten und der Unterstützung mehrerer Sprachen (über 100 Sprachen und Dialekte) auf.
- Trainingsdaten: Qwen3 wurde auf einem riesigen Datensatz von etwa 36 Billionen Token trainiert, fast doppelt so viel wie sein Vorgänger Qwen2.5.
Warum Qwen3 für Web Scraping verwenden?
Qwen3 erleichtert das Web Scraping durch die automatische Interpretation und Strukturierung unstrukturierter Inhalte in HTML-Seiten. Damit entfällt die Notwendigkeit, Daten manuell zu analysieren. Anstatt komplexe Logik zu schreiben, um Daten zu extrahieren, versteht das Modell die Struktur der Seite für Sie.
Der Einsatz von Qwen3 für das Parsen von Webdaten ist besonders nützlich, wenn es um gängige Web-Scraping-Herausforderungen geht:
- Häufig wechselnde Seitenlayouts: Ein beliebtes Szenario ist Amazon, wo jede Produktseite unterschiedliche Daten anzeigen kann.
- Unstrukturierte Daten: Qwen3 kann wertvolle Informationen aus unstrukturiertem Freiformtext extrahieren, ohne dass hart kodierte Selektoren oder Regex-Logik erforderlich sind.
- Schwierig zu parsende Inhalte: Bei Seiten mit inkonsistenter oder komplexer Struktur macht ein LLM wie Qwen3 eine eigene Parsing-Logik überflüssig.
Wenn Sie tiefer eintauchen möchten, lesen Sie unseren Leitfaden zum Einsatz von KI für Web Scraping.
Ein weiterer großer Vorteil ist, dass Qwen3 Open-Source ist. Das bedeutet, dass Sie es lokal auf Ihrem eigenen Rechner kostenlos ausführen können, ohne auf APIs von Drittanbietern angewiesen zu sein oder für Premium-LLMs wie die von OpenAI zu bezahlen. So haben Sie die volle Kontrolle über Ihre Scraping-Architektur.
Wie man Web Scraping mit Qwen3 in Python durchführt
In diesem Abschnitt wird die Zielseite die Produktseite “Affirm Water Bottle” aus der Sandbox “Ecommerce Test Site to Learn Web Scraping” sein:
Diese Seite ist ein gutes Beispiel, denn E-Commerce-Produktseiten sind in der Regel uneinheitlich strukturiert und zeigen unterschiedliche Datentypen an. Diese Variabilität macht das E-Commerce-Web-Scraping zu einer besonderen Herausforderung – und zu einem Bereich, in dem KI einen großen Unterschied machen kann.
Hier werden wir einen Qwen3-gesteuerten Scraper verwenden, um auf intelligente Weise Produktinformationen zu extrahieren, ohne manuelle Parsing-Regeln zu schreiben.
Hinweis: Dieses Tutorial zeigt Ihnen, wie Sie Hugging Face verwenden können , um Qwen3-Modelle lokal und kostenlos auszuführen. Es gibt noch andere praktikable Optionen. Dazu gehören die Verbindung zu einem LLM-Anbieter, der Qwen3-Modelle hostet, oder die Nutzung von Lösungen wie Ollama.
Führen Sie die folgenden Schritte aus, um mit Qwen3 Webdaten zu scrapen!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, stellen Sie sicher, dass Sie Python 3.10+ auf Ihrem Rechner installiert haben. Andernfalls laden Sie es herunter und folgen Sie den Installationsanweisungen.
Führen Sie anschließend den folgenden Befehl aus, um einen Ordner für Ihr Scraping-Projekt zu erstellen:
mkdir qwen3-scraperDas Verzeichnis qwen3-scraper dient als Projektordner für Web Scraping mit Qwen3.
Navigieren Sie in Ihrem Terminal zu diesem Ordner und initialisieren Sie darin eine virtuelle Python-Umgebung:
cd qwen3-scraper
python -m venv venvLaden Sie den Projektordner in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind beide ausgezeichnete Optionen.
Erstellen Sie eine Datei scraper.py im Projektordner, die nun Folgendes enthalten sollte:

Im Moment ist scraper.py nur ein leeres Python-Skript, aber es wird bald die Logik für LLM Web Scraping enthalten.
Aktivieren Sie dann die virtuelle Umgebung. Unter Linux oder macOS führen Sie aus:
source venv/bin/activateÄquivalent unter Windows: Verwenden Sie:
venv/Scripts/activateHinweis: Die folgenden Schritte werden Sie durch die Installation aller erforderlichen Bibliotheken führen. Wenn Sie es vorziehen, alles auf einmal zu installieren, können Sie jetzt den unten stehenden Befehl verwenden:
pip install transformers torch accelerate requests beautifulsoup4 markdownifyFantastisch! Ihre Python-Umgebung ist vollständig für das Web-Scraping mit Qwen3 eingerichtet.
Schritt #2: Qwen3 in Hugging Face konfigurieren
Wie zu Beginn dieses Abschnitts erwähnt, werden wir Hugging Face verwenden, um ein Qwen3-Modell lokal auszuführen. Dies ist jetzt möglich, da Hugging Face kürzlich Unterstützung für Qwen3-Modelle hinzugefügt hat.
Stellen Sie zunächst sicher, dass Sie sich in einer aktivierten virtuellen Umgebung befinden. Installieren Sie dann die erforderlichen Hugging Face-Abhängigkeiten, indem Sie diese ausführen:
pip install transformers torch accelerateAls Nächstes importieren Sie in der Datei scraper.py die erforderlichen Klassen aus der Transformatorenbibliothek von Hugging Face:
from transformers import AutoModelForCausalLM, AutoTokenizerVerwenden Sie nun diese Klassen, um einen Tokenizer und das Qwen3-Modell zu laden:
model_name = "Qwen/Qwen3-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)In diesem Fall verwenden wir das Modell Qwen/Qwen3-0.6B, aber Sie können aus mehr als 40 anderen verfügbaren Qwen3-Modellen bei Hugging Face wählen.
Großartig! Jetzt haben Sie alles vorbereitet, um Qwen3 in Ihrem Python-Skript zu verwenden.
Schritt #3: Holen Sie sich den HTML-Code der Zielseite
Nun ist es an der Zeit, den HTML-Inhalt der Zielseite abzurufen. Das können Sie mit einem leistungsfähigen Python-HTTP-Client wie Requests erreichen.
Installieren Sie in Ihrer aktivierten virtuellen Umgebung die Requests-Bibliothek:
pip install requestsImportieren Sie dann in Ihrer scraper.py-Datei die Bibliothek:
import requestsVerwenden Sie die Methode get(), um eine HTTP-GET-Anfrage an die URL der Seite zu senden:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)Der Server antwortet mit dem Roh-HTML der Seite. Um den vollständigen HTML-Inhalt zu sehen, können Sie response.content ausdrucken:
print(response.content)Das Ergebnis sollte diese HTML-Zeichenfolge sein:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Affirm Water Bottle – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Sie haben nun das komplette HTML der Zielseite in Python zur Verfügung. Lassen Sie uns damit fortfahren, sie zu analysieren und die benötigten Daten mit Qwen3 zu extrahieren!
Schritt Nr. 4: Konvertieren Sie die HTML-Seite in Markdown (optional, aber empfohlen)
Hinweis: Dieser Schritt ist nicht unbedingt erforderlich. Er kann Ihnen jedoch lokal viel Zeit sparen (und Geld, wenn Sie kostenpflichtige Qwen3-Anbieter nutzen). Er ist also auf jeden Fall eine Überlegung wert.
Nehmen Sie sich einen Moment Zeit, um zu sehen, wie andere KI-gestützte Web-Scraping-Tools wie Crawl4AI und ScrapeGraphAI mit Roh-HTML umgehen. Sie werden feststellen, dass beide Tools Optionen zur Konvertierung von HTML in Markdown anbieten, bevor sie den Inhalt an den konfigurierten LLM weitergeben.
Warum tun sie das? Dafür gibt es zwei Hauptgründe:
- Kosteneffizienz: Die Markdown-Konvertierung reduziert die Anzahl der an die KI gesendeten Token und hilft Ihnen, Geld zu sparen.
- Schnellere Verarbeitung: Weniger Eingabedaten bedeuten geringere Rechenkosten und schnellere Antworten.
Weitere Informationen finden Sie in unserem Leitfaden darüber, warum die neuen KI-Agenten Markdown gegenüber HTML bevorzugen.
Da Qwen3 in diesem Fall lokal ausgeführt wird, spielt die Kosteneffizienz keine Rolle, da Sie nicht mit einem LLM-Anbieter verbunden sind. Was hier wirklich zählt, ist eine schnellere Verarbeitung. Und warum? Weil das gewählte Qwen3-Modell (das übrigens eines der kleineren verfügbaren Modelle ist) bei der Verarbeitung der gesamten HTML-Seite eine i7-CPU leicht für mehrere Minuten zu 100 % auslasten kann.
Das ist zu viel, denn Sie wollen ja nicht, dass Ihr Laptop oder PC überhitzt oder einfriert. Daher ist die Verringerung der Eingabegröße durch Konvertierung in Markdown absolut sinnvoll.
Es ist an der Zeit, die HTML-zu-Markdown-Konvertierungslogik zu replizieren und die Verwendung von Token zu reduzieren!
Öffnen Sie zunächst die Ziel-Webseite im Inkognito-Modus, um eine neue Sitzung zu gewährleisten. Klicken Sie dann mit der rechten Maustaste auf eine beliebige Stelle der Seite und wählen Sie “Inspect”, um die DevTools zu öffnen. Untersuchen Sie nun die Seitenstruktur. Sie werden sehen, dass alle relevanten Daten in dem HTML-Element enthalten sind, das durch den CSS-Selektor #main gekennzeichnet ist:
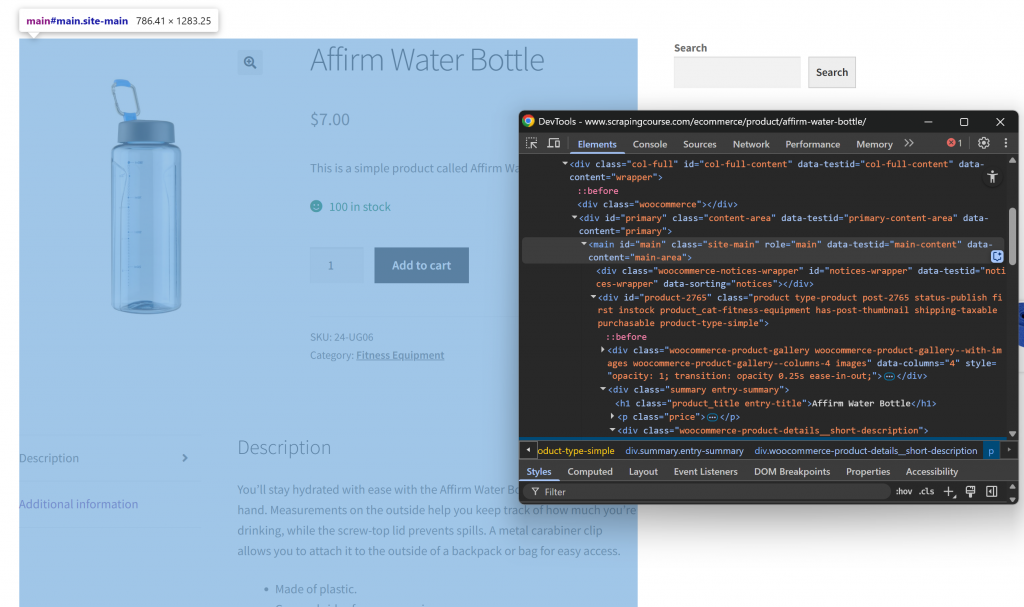
Indem Sie sich bei der Umwandlung von HTML in Markdown auf den Inhalt innerhalb von #main konzentrieren, extrahieren Sie nur den Teil der Seite mit den relevanten Daten. Dadurch werden Kopf- und Fußzeilen sowie andere Abschnitte, die Sie nicht interessieren, nicht mit einbezogen. Auf diese Weise wird die endgültige Markdown-Ausgabe viel kürzer sein.
Um nur den HTML-Code im #main-Element auszuwählen, benötigen Sie eine Python-HTML-Parsing-Bibliothek wie Beautiful Soup. Installieren Sie sie in Ihrer aktivierten virtuellen Umgebung mit diesem Befehl:
pip install beautifulsoup4Wenn Sie mit der API nicht vertraut sind, folgen Sie unserem Leitfaden zu Beautiful Soup Web Scraping.
Dann importieren Sie es in scraper.py:
from bs4 import BeautifulSoupVerwenden Sie Beautiful Soup, um:
- Parsen Sie das mit Requests abgerufene Roh-HTML
- Wählen Sie das Element
#main - Extrahieren des HTML-Inhalts
Implementieren Sie die drei oben genannten Mikroschritte mit diesem Snippet:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element
main_html = str(main_element)Wenn Sie main_html ausdrucken, sehen Sie etwas wie dieses:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
<div id="product-2765" class="product type-product post-2765 status-publish first instock product_cat-fitness-equipment has-post-thumbnail shipping-taxable purchasable product-type-simple">
<!-- omitted for brevity... -->
</div>
</main>Diese Zeichenfolge ist viel kleiner als die vollständige HTML-Seite, enthält aber immer noch etwa 13 402 Zeichen.
Um die Größe noch weiter zu reduzieren, ohne wichtige Daten zu verlieren, konvertieren Sie das extrahierte HTML in Markdown. Installieren Sie zunächst die markdownify-Bibliothek:
pip install markdownifyImportieren Sie markdownify in scraper.py:
from markdownify import markdownifyDann konvertieren Sie damit den HTML-Code von #main in Markdown:
main_markdown = markdownify(main_html)Der Datenkonvertierungsprozess sollte eine Ausgabe wie die folgende ergeben:
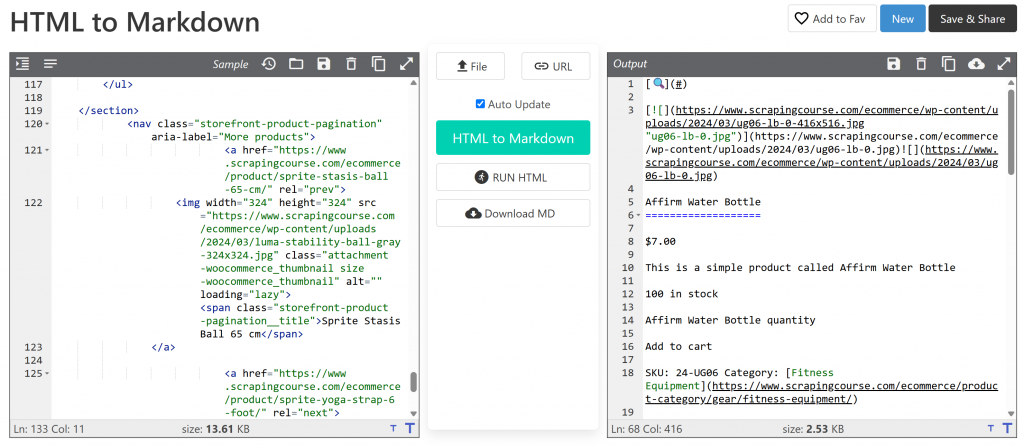
Die Markdown-Version ist etwa 2,53 KB groß, verglichen mit 13,61 KB für die ursprüngliche HTML-Version von #main. Das ist eine Größenreduzierung von 81 %! Darüber hinaus ist es wichtig, dass die Markdown-Version alle wichtigen Daten enthält, die Sie zum Scrapen benötigen.
Mit diesem einfachen Trick können Sie einen sperrigen HTML-Schnipsel in einen kompakten Markdown-String umwandeln. Dies wird das lokale Parsen von LLM-Daten über Qwen3 erheblich beschleunigen!
Schritt Nr. 5: Qwen3 für die Datenanalyse verwenden
Um Qwen3 dazu zu bringen, Daten korrekt auszulesen, müssen Sie eine effektive Eingabeaufforderung schreiben. Analysieren Sie zunächst die Struktur der Zielseite:
Der obere Teil der Seite ist für alle Produkte gleich. Die Tabelle “Zusätzliche Informationen” hingegen ändert sich je nach Produkt. Da Sie vielleicht möchten, dass Ihre Eingabeaufforderung auf allen Produktseiten der Plattform funktioniert, könnten Sie Ihre Aufgabe in allgemeinen Worten wie folgt beschreiben:
Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
<MARKDOWN_PRODUCT_CONTENT>Diese Eingabeaufforderung weist Qwen3 an, strukturierte Daten aus dem Inhalt von main_markdown zu extrahieren. Um zuverlässige Ergebnisse zu erhalten, sollten Sie Ihre Eingabeaufforderung so klar und spezifisch wie möglich formulieren. So kann das Modell genau verstehen, was Sie erwarten.
Verwenden Sie nun Hugging Face, um die Eingabeaufforderung auszuführen, wie in der offiziellen Dokumentation beschrieben:
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")Der obige Code verwendet apply_chat_template(), um die Eingabenachricht zu formatieren und erzeugt eine Antwort aus dem konfigurierten Qwen3-Modell.
Hinweis: Ein wichtiges Detail ist die Einstellung enable_thinking=False in apply_chat_template(). Standardmäßig ist diese Option auf True gesetzt, was den internen “Denk”-Modus des Modells aktiviert. Diese Aufgabe ist nützlich für komplexe Problemlösungen, aber unnötig und potenziell kontraproduktiv für einfache Aufgaben wie Web Scraping. Die Deaktivierung stellt sicher, dass sich das Modell ausschließlich auf die Extraktion konzentriert, ohne Erklärungen oder Annahmen hinzuzufügen.
Fantastisch! Sie haben Qwen3 soeben angewiesen, Web Scraping auf der Zielseite durchzuführen.
Jetzt müssen Sie nur noch die Ausgabe optimieren und sie in JSON exportieren.
Schritt #6: Konvertieren der Qwen3-Ausgabe
Die vom Modell Qwen3-0.6B erzeugte Ausgabe kann von Lauf zu Lauf leicht variieren. Dies ist ein typisches Verhalten für LLMs, insbesondere für kleinere Modelle wie das hier verwendete.
So enthält die Variable product_raw_string manchmal die gewünschten Daten als einfachen JSON-String. In anderen Fällen wird der JSON-String in einen Markdown-Code-Block eingeschlossen, etwa so:
```jsonn{n "sku": "24-UG06",n "name": "Affirm Water Bottle",n "images": ["https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"],n "price": "$7.00",n "description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much you’re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",n "category": "Fitness Equipment",n "additional_information": {n "Activity": "Yoga, Recreation, Sports, Gym",n "Gender": "Men, Women, Boys, Girls, Unisex",n "Material": "Plastic"n }n}n```Um beide Fälle zu behandeln, können Sie einen regulären Ausdruck verwenden, um den JSON-Inhalt zu extrahieren, wenn er innerhalb eines Markdown-Blocks erscheint. Andernfalls behandeln Sie die Zeichenfolge als rohes JSON. Anschließend können Sie die resultierenden JSON-Daten in das Python-Wörterbuch json.loads() parsen:
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Jetzt geht’s los! An dieser Stelle haben Sie die gescrapten Daten in ein brauchbares Python-Objekt umgewandelt. Der letzte Schritt besteht darin, die ausgewerteten Daten in ein benutzerfreundlicheres Format zu exportieren.
Schritt #7: Exportieren Sie die gescrapten Daten
Nun, da Sie die Produktdaten in einem Python-Wörterbuch haben, können Sie sie wie folgt in einer JSON-Datei speichern:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Dadurch wird eine Datei namens product.json erstellt, die Ihre strukturierten Produktdaten enthält.
Gut gemacht! Ihr Qwen3 Web Scraper ist nun vollständig.
Schritt #8: Alles zusammenfügen
Hier ist der endgültige Code für das Qwen3-Skript scraper.py:
from transformers import AutoModelForCausalLM, AutoTokenizer
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
import re
# The Qwen3 model to use for web scraping
model_name = "Qwen/Qwen3-0.6B"
# Load the tokenizer and the Qwen3 model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Führen Sie das Skript mit aus:
python scraper.pyWenn Sie das Skript zum ersten Mal ausführen, wird Hugging Face automatisch das ausgewählte Qwen3-Modell herunterladen. Dieses Modell ist etwa 1,5 GB groß, daher kann der Download je nach Internetgeschwindigkeit einige Zeit dauern. Im Terminal sehen Sie die folgende Ausgabe:
model.safetensors: 100%|██████████████████████████████████████████████████████████| 1.50G/1.50G [00:49<00:00, 30.2MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████| 239/239 [00:00<?, ?B/s]Die Fertigstellung des Skripts kann ein wenig dauern, da PyTorch Ihre CPU beim Laden und Ausführen des Modells belastet.
Sobald das Skript fertig ist, erstellt es eine Datei namens product.json in Ihrem Projektordner. Öffnen Sie diese Datei, und Sie sollten strukturierte Produktdaten wie diese sehen:
{
"sku": "24-UG06",
"name": "Affirm Water Bottle",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"
],
"price": "$7.00",
"description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much youu2019re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",
"category": "Fitness Equipment",
"additional_information": {
"Activity": "Yoga, Recreation, Sports, Gym",
"Gender": "Men, Women, Boys, Girls, Unisex",
"Material": "Plastic"
}
}Hinweis: Die genaue Ausgabe kann aufgrund der Natur von LLMs, die den gescrapten Inhalt auf unterschiedliche Weise strukturieren können, leicht variieren.
Et voilà! Ihr Skript hat gerade rohen HTML-Inhalt in sauberes, strukturiertes JSON umgewandelt. Alles dank Qwen3 Web Scraping.
Überwindung der Hauptbeschränkung dieses Ansatzes für Web Scraping
Sicher, in unserem Beispiel hat alles reibungslos funktioniert. Das liegt aber nur daran, dass wir eine eigens für diesen Zweck erstellte Demo-Website verwendet haben.
In der realen Welt sind sich die meisten Websites des Wertes ihrer öffentlich zugänglichen Daten durchaus bewusst. Daher implementieren sie oft Anti-Scraping-Techniken, die automatisierte HTTP-Anfragen mit Tools wie requests schnell blockieren können.
Außerdem funktioniert dieser Ansatz nicht bei JavaScript-lastigen Seiten. Das liegt daran, dass die Kombination aus Anfragen und BeautifulSoup gut für statische Seiten funktioniert, aber nicht für dynamische Inhalte. Wenn Sie mit dem Unterschied nicht vertraut sind, werfen Sie einen Blick auf unseren Artikel über statische vs. dynamische Inhalte.
Weitere potenzielle Blocker sind IP-Sperren, Ratenbegrenzer, TLS-Fingerprinting, CAPTCHAs und mehr. Kurz gesagt, Web Scraping ist nicht einfach – vor allem jetzt, da die meisten Websites so ausgestattet sind, dass sie KI-Crawler und Bots erkennen und blockieren können.
Die Lösung besteht darin, eine Web Unlocker API zu verwenden, die für modernes Web Scraping mit Anfragen entwickelt wurde. Ein solcher Dienst übernimmt alle schwierigen Aufgaben für Sie, einschließlich der Rotation von IPs, dem Lösen von CAPTCHAs, dem Rendern von JavaScript und der Umgehung des Bot-Schutzes.
Alles, was Sie tun müssen, ist, die URL der Zielseite an den Web Unlocker API-Endpunkt zu übergeben. Die API gibt vollständig freigeschaltetes HTML zurück, selbst wenn die Seite auf JavaScript basiert oder durch fortschrittliche Anti-Bot-Systeme geschützt ist.
Um es in Ihr Skript zu integrieren, ersetzen Sie einfach die Zeile requests.get() aus Schritt 3 durch den folgenden Code:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the payload with the target URL
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/", # Replace this with your target URL on a different scraping scenario
"format": "raw"
}
# Send the request
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
# Get the unlocked HTML
html_content = response.textWeitere Einzelheiten finden Sie in der offiziellen Dokumentation von Web Unlocker.
Mit einem Web Unlocker können Sie Qwen3 vertrauensvoll nutzen, um strukturierte Daten aus jeder Website zu extrahieren – keine Blöcke, Rendering-Probleme oder fehlende Inhalte mehr.
Alternativen zu Qwen3 für Web Scraping
Qwen3 ist nicht der einzige LLM, den Sie für das automatisierte Parsen von Webdaten verwenden können. Entdecken Sie einige alternative Ansätze in den folgenden Anleitungen:
- Web Scraping mit Gemini: Vollständiges Tutorial
- Web Scraping mit Perplexity: Schritt-für-Schritt-Anleitung
- LLM Web Scraping mit ScrapeGraphAI
- Wie man einen AI Scraper mit Crawl4AI und DeepSeek erstellt
- Web Scraping mit LLaMA 3: Jede Website in strukturiertes JSON verwandeln
Schlussfolgerung
In diesem Tutorial haben Sie gelernt, wie Sie Qwen3 mit Hugging Face lokal ausführen, um einen KI-gesteuerten Web Scraper zu erstellen. Eine der größten Hürden beim Web-Scraping ist das Blockieren von Daten, aber das wurde mit der Web Unlocker API von Bright Data gelöst.
Wie bereits erwähnt, ermöglicht die Kombination von Qwen3 mit der Web Unlocker API die Extraktion von Daten aus praktisch jeder Website. Und das alles, ohne dass eine eigene Parsing-Logik erforderlich ist. Dieses Setup zeigt nur einen der vielen leistungsstarken Anwendungsfälle, die durch die Infrastruktur von Bright Data ermöglicht werden und Sie beim Aufbau skalierbarer, KI-gesteuerter Webdaten-Pipelines unterstützen.
Warum also hier aufhören? Erkunden Sie die Web Scraper APIs – spezielleEndpunkte zum Extrahieren von frischen, strukturierten und vollständig konformen Webdaten aus über 120 beliebten Websites.
Melden Sie sich noch heute für ein kostenloses Bright Data-Konto an, und beginnen Sie mit KI-fähigen Scraping-Lösungen zu arbeiten!




