

In diesem Lernprogramm lernen Sie:
- Was Crawl4AI ist und was es für Web Scraping bietet
- Die idealen Szenarien für die Verwendung von Crawl4AI mit einem LLM wie DeepSeek
- Wie man einen DeepSeek-betriebenen Crawl4AI Scraper in einem geführten Abschnitt baut.
Lasst uns eintauchen!
Was ist Craw4AI?
Crawl4AI ist ein quelloffener, KI-fähiger Webcrawler und Scraper, der für die nahtlose Integration mit großen Sprachmodellen (LLMs), KI-Agenten und Datenpipelines entwickelt wurde. Er liefert Hochgeschwindigkeitsdatenextraktion in Echtzeit und ist gleichzeitig flexibel und einfach zu implementieren.
Die Funktionen, die es für AI Web Scraping bietet, sind:
- Gebaut für LLMs: Erzeugt strukturiertes Markdown, das für die abruferweiterte Generierung (RAG) und die Feinabstimmung optimiert ist.
- Flexible Browser-Steuerung: Unterstützt Sitzungsmanagement, Proxies und benutzerdefinierte Hooks.
- Heuristische Intelligenz: Verwendet intelligente Algorithmen zur Optimierung des Datenparsings.
- Vollständig quelloffen: Keine API-Schlüssel erforderlich; Bereitstellung über Docker und Cloud-Plattformen.
Weitere Informationen finden Sie in der offiziellen Dokumentation.
Wann Crawl4AI und DeepSeek für Web Scraping verwendet werden sollten
DeepSeek bietet leistungsstarke, kostenlose Open-Source-LLM-Modelle, die aufgrund ihrer Effizienz und Effektivität in der KI-Gemeinschaft Wellen geschlagen haben. Außerdem lassen sich diese Modelle nahtlos in Crawl4AI integrieren.
Durch die Nutzung von DeepSeek in Crawl4AI können Sie strukturierte Daten selbst aus den komplexesten und inkonsistentesten Webseiten extrahieren. Und das alles ohne vordefinierte Parsing-Logik.
Nachfolgend sind Schlüsselszenarien aufgeführt, in denen die Kombination DeepSeek + Crawl4AI besonders nützlich ist:
- Häufige Änderungen der Website-Struktur: Herkömmliche Scraper brechen ab, wenn Websites ihre HTML-Struktur aktualisieren, aber AI passt sich dynamisch an.
- Inkonsistente Seitenlayouts: Plattformen wie Amazon haben unterschiedliche Designs von Produktseiten. Ein LLM kann Daten unabhängig von Layout-Unterschieden intelligent extrahieren.
- Parsing unstrukturierter Inhalte: Das Extrahieren von Erkenntnissen aus Freitext-Rezensionen, Blogbeiträgen oder Forumsdiskussionen wird mit LLM-gestützter Verarbeitung zum Kinderspiel.
Web Scraping mit Craw4AI und DeepSeek: Schritt-für-Schritt-Anleitung
In diesem geführten Tutorial lernen Sie, wie Sie mit Crawl4AI einen KI-gesteuerten Web Scraper erstellen können. Als LLM-Engine werden wir DeepSeek verwenden.
Sie werden insbesondere sehen, wie Sie einen AI Scraper erstellen, um Daten von der G2-Seite für Bright Data zu extrahieren:
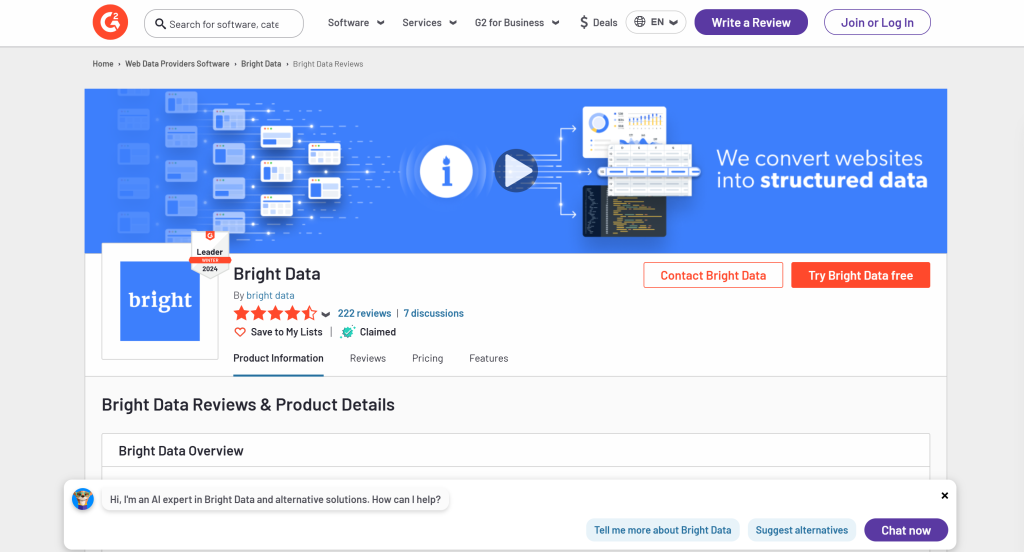
Folgen Sie den nachstehenden Schritten und erfahren Sie, wie Sie Web Scraping mit Crawl4AI und DeepSeek durchführen können!
Voraussetzungen
Um diesem Tutorial folgen zu können, müssen Sie die folgenden Voraussetzungen erfüllen:
- Python 3+ auf Ihrem Rechner installiert
- Ein GroqCloud-Konto
- Ein Bright Data-Konto
Machen Sie sich keine Sorgen, wenn Sie noch kein GroqCloud- oder Bright Data-Konto haben. Sie werden in den nächsten Schritten durch die Einrichtung geführt.
Schritt 1: Projekt einrichten
Führen Sie den folgenden Befehl aus, um einen Ordner für Ihr Crawl4AI DeepSeek Scraping-Projekt zu erstellen:
mkdir crawl4ai-deepseek-scraperNavigieren Sie in den Projektordner und erstellen Sie eine virtuelle Umgebung:
cd crawl4ai-deepseek-scraper
python -m venv venvLaden Sie nun den Ordner crawl4ai-deepseek-scraper in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind zwei gute Optionen.
Erstellen Sie innerhalb des Projektordners:
scraper.py: Die Datei, die die KI-gestützte Scraping-Logik enthalten wird.models/: Ein Verzeichnis zum Speichern von Pydantic-basierten Crawl4AI LLM-Datenmodellen..env: Eine Datei zum sicheren Speichern von Umgebungsvariablen.
Nachdem Sie diese Dateien und Ordner erstellt haben, sollte Ihre Projektstruktur wie folgt aussehen:

Als nächstes aktivieren Sie die virtuelle Umgebung im Terminal Ihrer IDE.
Unter Linux oder macOS starten Sie diesen Befehl:
./env/bin/activateUnter Windows führen Sie entsprechend aus:
env/Scripts/activateGroßartig! Sie haben jetzt eine Python-Umgebung für Crawl4AI Web Scraping mit DeepSeek.
Schritt #2: Craw4AI installieren
Wenn Ihre virtuelle Umgebung aktiviert ist, installieren Sie Crawl4AI über das Pip-Paket crawl4ai:
pip install crawl4aiBeachten Sie, dass die Bibliothek mehrere Abhängigkeiten hat, so dass die Installation eine Weile dauern kann.
Nach der Installation führen Sie den folgenden Befehl in Ihrem Terminal aus:
crawl4ai-setupDer Prozess:
- Installiert oder aktualisiert die erforderlichen Playwright-Browser (Chromium, Firefox, usw.).
- Führt Prüfungen auf Betriebssystemebene durch (z. B. Sicherstellung, dass die erforderlichen Systembibliotheken unter Linux installiert sind).
- Bestätigt, dass Ihre Umgebung ordnungsgemäß für das Web-Crawling eingerichtet ist.
Nach der Ausführung des Befehls sollten Sie eine ähnliche Ausgabe wie die folgende sehen:
[INIT].... → Running post-installation setup...
[INIT].... → Installing Playwright browsers...
[COMPLETE] ● Playwright installation completed successfully.
[INIT].... → Starting database initialization...
[COMPLETE] ● Database backup created at: C:Usersantoz.crawl4aicrawl4ai.db.backup_20260219_092341
[INIT].... → Starting database migration...
[COMPLETE] ● Migration completed. 0 records processed.
[COMPLETE] ● Database initialization completed successfully.
[COMPLETE] ● Post-installation setup completed!Erstaunlich! Crawl4AI ist jetzt installiert und einsatzbereit.
Schritt #4: scraper.py initialisieren
Da Crawl4AI asynchronen Code benötigt, beginnen Sie mit der Erstellung eines einfachen Asyncio-Skripts:
import asyncio
async def main():
# Scraping logic...
if __name__ == "__main__":
asyncio.run(main())Denken Sie daran, dass das Projekt Integrationen mit Drittanbieterdiensten wie DeepSeek beinhaltet. Um dies zu implementieren, müssen Sie sich auf API-Schlüssel und andere Geheimnisse verlassen. Wir werden sie in einer .env-Datei speichern.
Installieren Sie python-dotenv, um Umgebungsvariablen zu laden:
pip install python-dotenvBevor Sie main() definieren, laden Sie die Umgebungsvariablen aus der .env-Datei mit load_dotenv():
load_dotenv()Importieren Sie load_dotenv aus der python-dotenv-Bibliothek:
from dotenv import load_dotenvPerfekt! scraper.py ist bereit, eine KI-gestützte Scraping-Logik zu hosten.
Schritt #5: Erstellen Sie Ihren ersten AI Scraper
Fügen Sie innerhalb der main() -Funktion in scraper.py die folgende Logik unter Verwendung eines einfachen Crawl4AI-Crawlers hinzu:
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")Die wichtigsten Punkte des obigen Ausschnitts sind:
BrowserConfig: Steuert, wie der Browser gestartet wird und sich verhält, einschließlich Einstellungen wie Headless-Modus und benutzerdefinierte User-Agents für Web Scraping.CrawlerRunConfig: Legt das Crawling-Verhalten fest, z. B. Caching-Strategie, Regeln für die Datenauswahl, Timeouts und mehr.headless=True: Konfiguriert den Browser so, dass er im Headless-Modus ohnegrafische Benutzeroberfläche läuft, um Ressourcen zu sparen.CacheMode.BYPASS: Diese Konfiguration garantiert, dass der Crawler frische Inhalte direkt von der Website holt, anstatt sich auf zwischengespeicherte Daten zu verlassen.crawler.arun(): Mit dieser Methode wird der asynchrone Crawler gestartet, um Daten aus der angegebenen URL zu extrahieren.result.markdown: Der extrahierte Inhalt wird in das Markdown-Format konvertiert, damit er leichter geparst und analysiert werden kann.
Vergessen Sie nicht, die folgenden Importe hinzuzufügen:
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheModeMomentan sollte scraper.py enthalten:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
# Load secrets from .env file
load_dotenv()
async def main():
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:n{result.markdown[:1000]}")
if __name__ == "__main__":
asyncio.run(main())Wenn Sie das Skript ausführen, sollten Sie eine Ausgabe wie unten sehen:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 0.83s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 1ms
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 0.83s
Parsed Markdown data:Dies ist verdächtig, da der geparste Markdown-Inhalt leer ist. Um dies weiter zu untersuchen, drucken Sie den Antwortstatus aus:
print(f"Response status code: {result.status_code}")Dieses Mal wird die Ausgabe Folgendes enthalten:
Response status code: 403Das mit Markdown geparste Ergebnis ist leer, weil die Crawl4AI-Anfrage von den Bot-Erkennungssystemen von G2 blockiert wurde. Dies wird durch den vom Server zurückgegebenen Statuscode 403 Forbidden deutlich.
Das sollte nicht überraschen, denn G2 hat strenge Anti-Bot-Maßnahmen eingeführt. Insbesondere werden häufig CAPTCHAs angezeigt – auch wenn der Zugriff über einen normalen Browser erfolgt:

Da in diesem Fall kein gültiger Inhalt empfangen wurde, konnte Crawl4AI ihn nicht in Markdown umwandeln. Im nächsten Schritt werden wir untersuchen, wie diese Einschränkung umgangen werden kann. Weitere Informationen finden Sie in unserem Leitfaden zur Umgehung von CAPTCHAs in Python.
Schritt #6: Web Unlocker API konfigurieren
Crawl4AI ist ein leistungsstarkes Tool mit eingebauten Mechanismen zur Umgehung von Bots. Allerdings kann es hochgradig geschützte Websites wie G2, die strenge und erstklassige Anti-Bot- und Anti-Scraping-Maßnahmen anwenden, nicht umgehen.
Die beste Lösung für solche Websites ist die Verwendung eines speziellen Tools, das jede beliebige Website unabhängig von ihrer Schutzstufe entsperren kann. Das ideale Scraping-Produkt für diese Aufgabe ist der Web Unlocker von Bright Data, eine Scraping-API, die:
- Simuliert echtes Benutzerverhalten, um die Anti-Bot-Erkennung zu umgehen
- Automatische Proxy-Verwaltung und CAPTCHA-Auflösung
- Nahtlos skalierbar, ohne dass eine Infrastrukturverwaltung erforderlich ist
Folgen Sie den nächsten Anweisungen, um die Web Unlocker API in Ihren Crawl4AI DeepSeek Scraper zu integrieren.
Alternativ können Sie auch einen Blick in die offizielle Dokumentation werfen.
Melden Sie sich zunächst bei Ihrem Bright Data-Konto an oder erstellen Sie eines, falls Sie dies noch nicht getan haben. Laden Sie Ihr Konto auf oder nutzen Sie die kostenlose Testversion, die für alle Produkte verfügbar ist.
Navigieren Sie dann im Dashboard zu “Proxies & Scraping” und wählen Sie in der Tabelle die Option “Unblocker”:
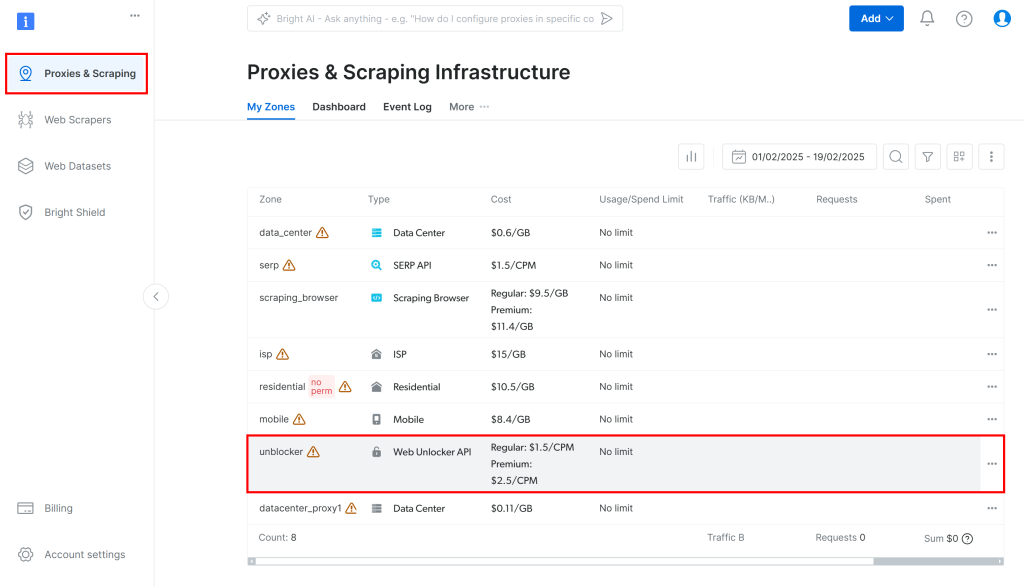
Dadurch gelangen Sie auf die unten gezeigte Einrichtungsseite für die Web Unlocker API:
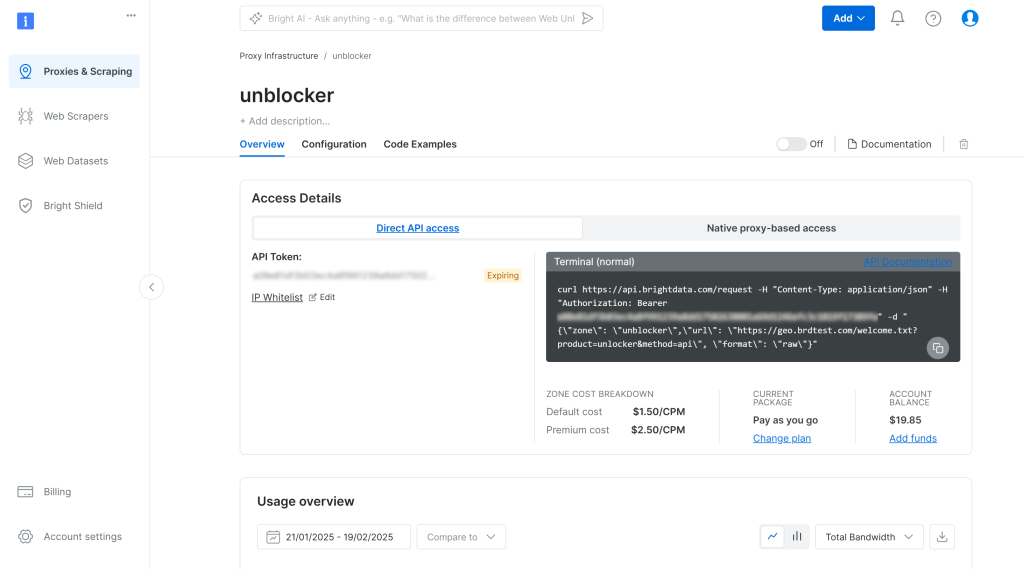
Aktivieren Sie hier die Web Unlocker API, indem Sie auf den Kippschalter klicken:

G2 ist durch fortschrittliche Anti-Bot-Verfahren, einschließlich CAPTCHAs, geschützt. Vergewissern Sie sich daher, dass die folgenden beiden Schalter auf der Seite “Konfiguration” aktiviert sind:
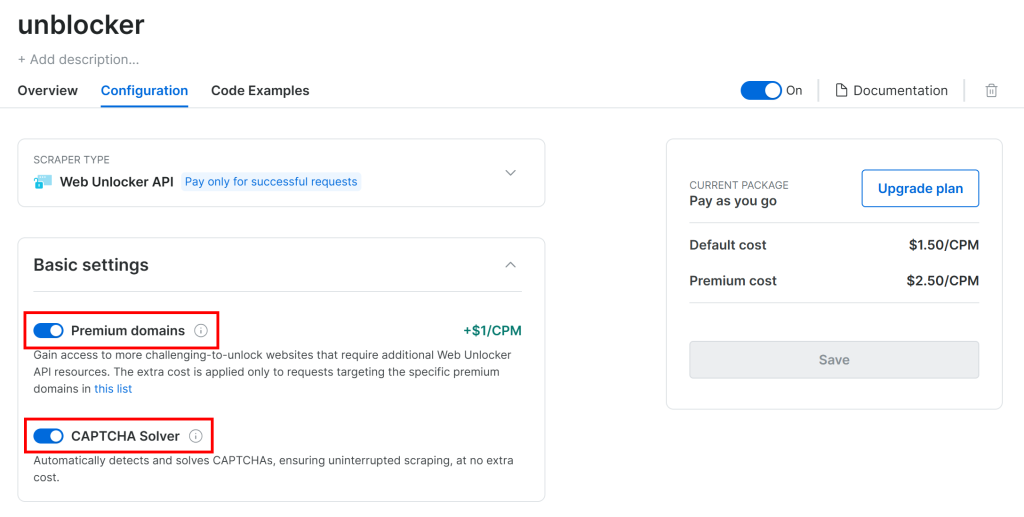
Crawl4AI navigiert in einem kontrollierten Browser durch die Seiten. Unter der Haube stützt es sich auf die goto() -Funktion von Playwright, die eine HTTP-GET-Anfrage an die Zielwebseite sendet. Im Gegensatz dazu arbeitet die Web Unlocker API mit POST-Anfragen.
Das ist kein Problem, denn Sie können Web Unlocker API mit Crawl4AI verwenden, indem Sie es als Proxy konfigurieren. Dies ermöglicht es dem Crawl4AI-Browser, Anfragen über das Produkt von Bright Data zu senden und unblockierte HTML-Seiten zurückzubekommen.
Um auf Ihre Web Unlocker API Proxy-Zugangsdaten zuzugreifen, gehen Sie auf den Reiter “Native proxy-based access” auf der Seite “Overview”:
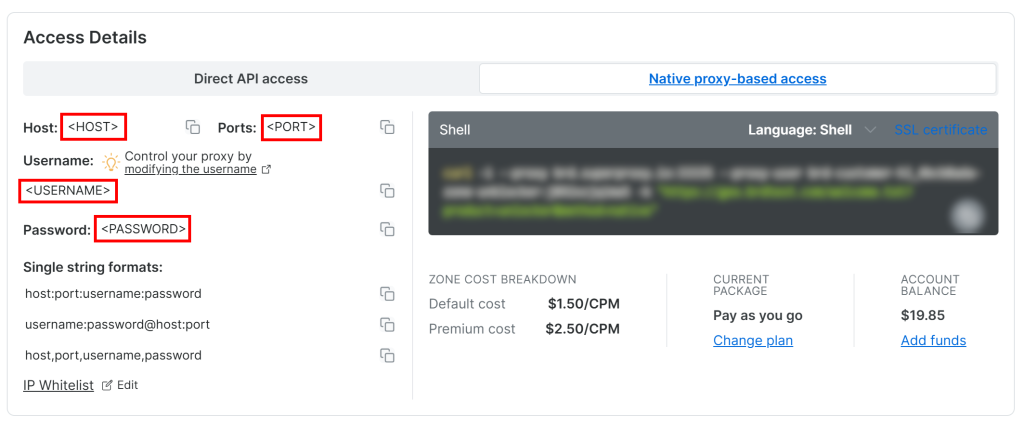
Kopieren Sie die folgenden Anmeldeinformationen von der Seite:
<HOST><PORT><BENUTZERNAME><PASSWORT>
Verwenden Sie diese dann, um Ihre .env-Datei mit diesen Umgebungsvariablen zu füllen:
PROXY_SERVER=https://<HOST>:<PORT>
PROXY_USERNAME=<USERNAME>
PROXY_PASSWORD=<PASSWORD>Fantastisch! Web Unlocker ist jetzt bereit für die Integration mit Crawl4AI.
Schritt #7: Web Unlocker API einbinden
BrowserConfig unterstützt die Proxy-Integration durch das proxy_config-Objekt. Um Web Unlocker API mit Crawl4AI zu integrieren, füllen Sie dieses Objekt mit den Umgebungsvariablen aus Ihrer .env-Datei und übergeben es an den BrowserConfig-Konstruktor:
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)Denken Sie daran, os aus der Python-Standardbibliothek zu importieren:
import osBeachten Sie, dass die Web Unlocker API durch die IP-Rotation über den Proxy und die eventuelle CAPTCHA-Auflösung einen gewissen Zeitaufwand verursacht. Um dies zu berücksichtigen, sollten Sie:
- Erhöhen Sie die Zeitüberschreitung beim Laden der Seite auf 3 Minuten
- Weisen Sie den Crawler an, darauf zu warten, dass das DOM vollständig geladen ist, bevor er es analysiert
Erreichen Sie dies mit der folgenden CrawlerRunConfig-Konfiguration:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded", # wait until the DOM of the page has been loaded
page_timeout=180000, # wait up to 3 mins for page load
)Beachten Sie, dass auch die Web Unlocker API nicht fehlerfrei ist, wenn es um komplexe Websites wie G2 geht. In seltenen Fällen kann es vorkommen, dass die Scraping-API die entsperrte Seite nicht abrufen kann, was dazu führt, dass das Skript mit dem folgenden Fehler abbricht:
Error: Failed on navigating ACS-GOTO:
Page.goto: net::ERR_HTTP_RESPONSE_CODE_FAILURE at https://www.g2.com/products/bright-data/reviewsSeien Sie versichert, dass Ihnen nur erfolgreiche Anfragen in Rechnung gestellt werden. Sie brauchen sich also keine Sorgen zu machen, dass Sie das Skript neu starten müssen, bis es funktioniert. Erwägen Sie bei einem Produktionsskript die Implementierung einer automatischen Wiederholungslogik.
Wenn die Anfrage erfolgreich ist, erhalten Sie eine Ausgabe wie diese:
Response status code: 200
Parsed Markdown data:
* [Home](https://www.g2.com/products/bright-data/</>)
* [Write a Review](https://www.g2.com/products/bright-data/</wizard/new-review>)
* Browse
* [Top Categories](https://www.g2.com/products/bright-data/<#>)
Top Categories
* [AI Chatbots Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/ai-chatbots>)
* [CRM Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/crm>)
* [Project Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/project-management>)
* [Expense Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/expense-management>)
* [Video Conferencing Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/video-conferencing>)
* [Online Backup Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/online-backup>)
* [E-Commerce Platforms](https://www.g2.com/products/brigGroßartig! Diesmal antwortete G2 mit einem Statuscode 200 OK. Das bedeutet, dass die Anfrage nicht blockiert wurde und Crawl4AI das HTML erfolgreich in Markdown umwandeln konnte, wie vorgesehen.
Schritt #8: Groq-Einrichtung
GroqCloud ist einer der wenigen Anbieter, der DeepSeek-KI-Modelle über OpenAI-kompatible APIs unterstützt – sogar mit einem kostenlosen Plan. Daher wird es die Plattform sein, die für die LLM-Integration in Crawl4AI verwendet wird.
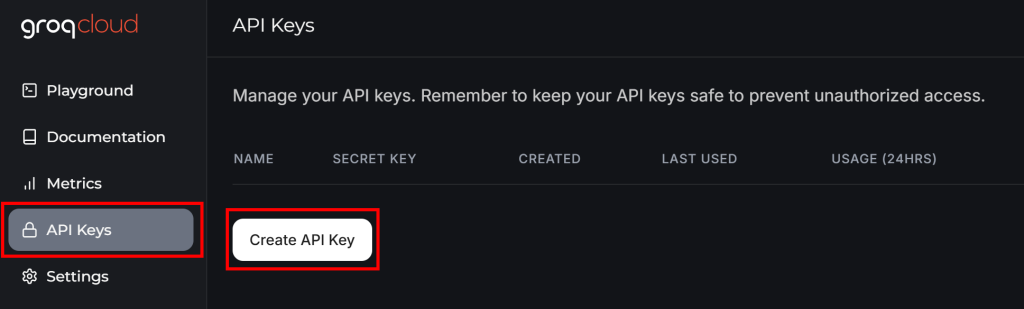
Wenn Sie noch kein Groq-Konto haben, erstellen Sie eines. Ansonsten melden Sie sich einfach an. Navigieren Sie in Ihrem Benutzer-Dashboard im linken Menü zu “API-Schlüssel” und klicken Sie auf die Schaltfläche “API-Schlüssel erstellen”:
Es erscheint ein Popup-Fenster:
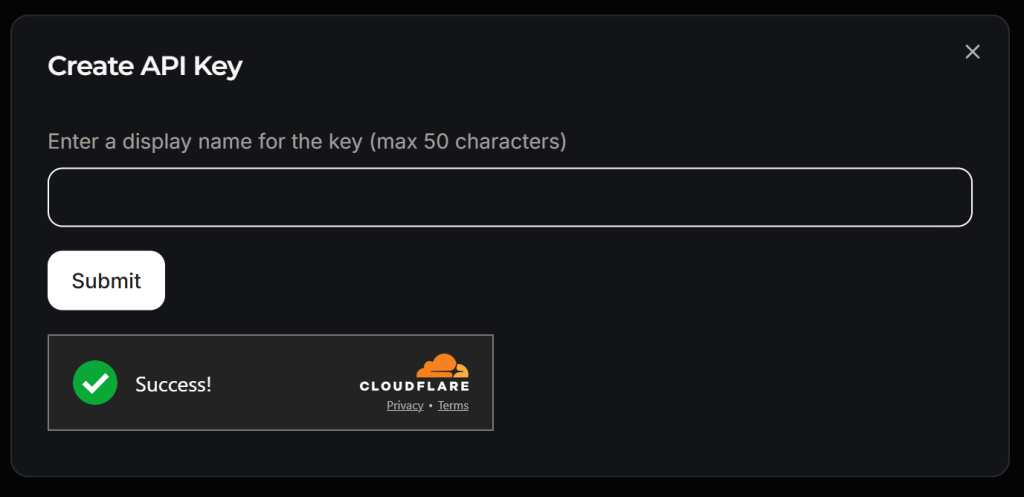
Geben Sie Ihrem API-Schlüssel einen Namen (z. B. “Crawl4AI Scraping”) und warten Sie auf die Anti-Bot-Verifizierung durch Cloudflare. Klicken Sie dann auf “Senden”, um Ihren API-Schlüssel zu generieren:
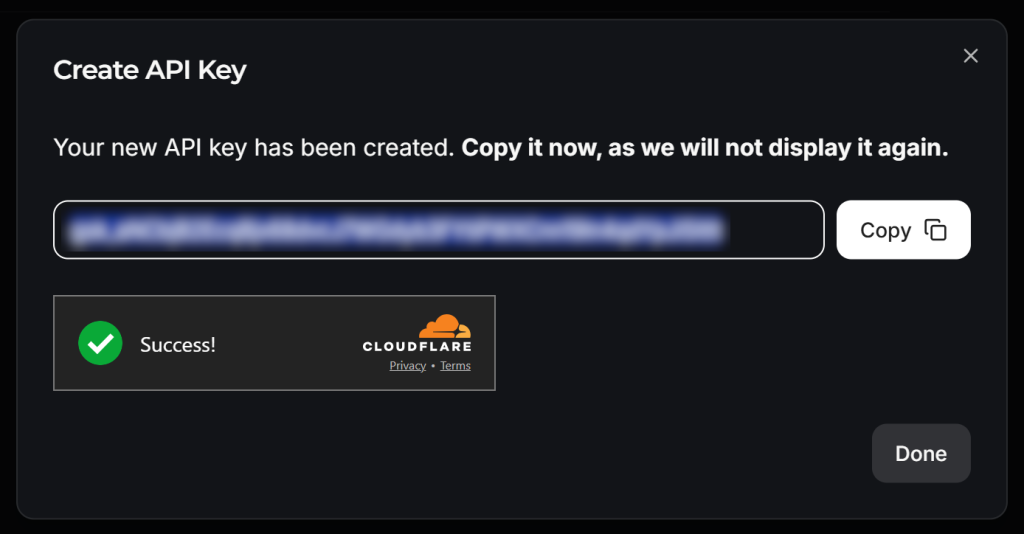
Kopieren Sie den API-Schlüssel und fügen Sie ihn wie folgt zu Ihrer .env-Datei hinzu:
LLM_API_TOKEN=<YOUR_GROK_API_KEY>Ersetzen Sie durch den tatsächlichen, von Groq bereitgestellten API-Schlüssel.
Wunderbar! Sie sind bereit, DeepSeek für LLM-Scraping mit Crawl4AI zu verwenden.
Schritt Nr. 9: Definieren Sie ein Schema für Ihre gescrapten Daten
Crawl4AI führt das LLM-Scraping nach einem schema-basierten Ansatz durch. In diesem Zusammenhang ist ein Schema eine JSON-Datenstruktur, die definiert:
- Ein Basis-Selektor, der das “Container”-Element auf der Seite identifiziert (z. B. eine Produktreihe, eine Blogpost-Karte).
- Felder, die die CSS/XPath-Selektoren zur Erfassung der einzelnen Daten (z. B. Text, Attribut, HTML-Block) angeben.
- Geschachtelte oder Listen-Typen für wiederholte oder hierarchische Strukturen.
Um das Schema zu definieren, müssen Sie zunächst die Daten identifizieren, die Sie aus der Zielseite extrahieren möchten. Öffnen Sie dazu die Zielseite im Inkognito-Modus in Ihrem Browser:
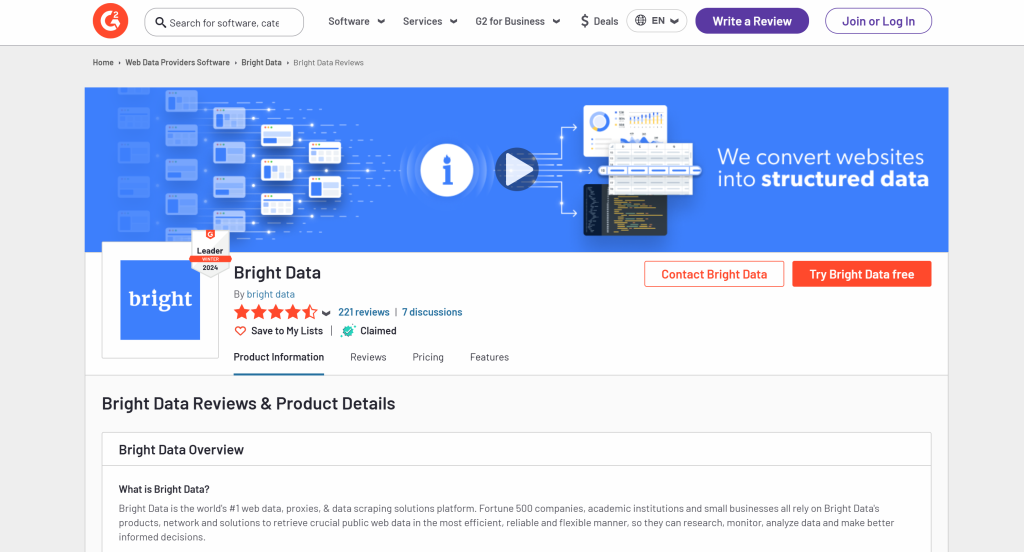
In diesem Fall nehmen Sie an, dass Sie an den folgenden Feldern interessiert sind:
name: Der Name des Produkts/der Firma.bild_url: Die URL des Produkt-/Firmenbildes.Beschreibung: Eine kurze Beschreibung des Produkts/des Unternehmens.rezension_score: Die durchschnittliche Bewertungsnote des Produkts/Unternehmens.anzahl_der_rezensionen: Die Gesamtzahl der Bewertungen.beansprucht: Ein boolescher Wert, der angibt, ob das Unternehmensprofil vom Eigentümer beansprucht wird.
Erstellen Sie nun im Ordner models eine Datei g2_product.py und füllen Sie sie wie folgt mit einer Pydantic-basierten Schemaklasse namens G2Product:
# ./models/g2_product.py
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolJa! Der von DeepSeek durchgeführte LLM-Scraping-Prozess wird Objekte zurückgeben, die dem oben genannten Schema entsprechen.
Schritt #10: Vorbereiten der Integration von DeepSeek
Bevor Sie die Integration von DeepSeek mit Crawl4AI abschließen, überprüfen Sie die Seite “Einstellungen > Limits” in Ihrem GroqCloud-Konto:
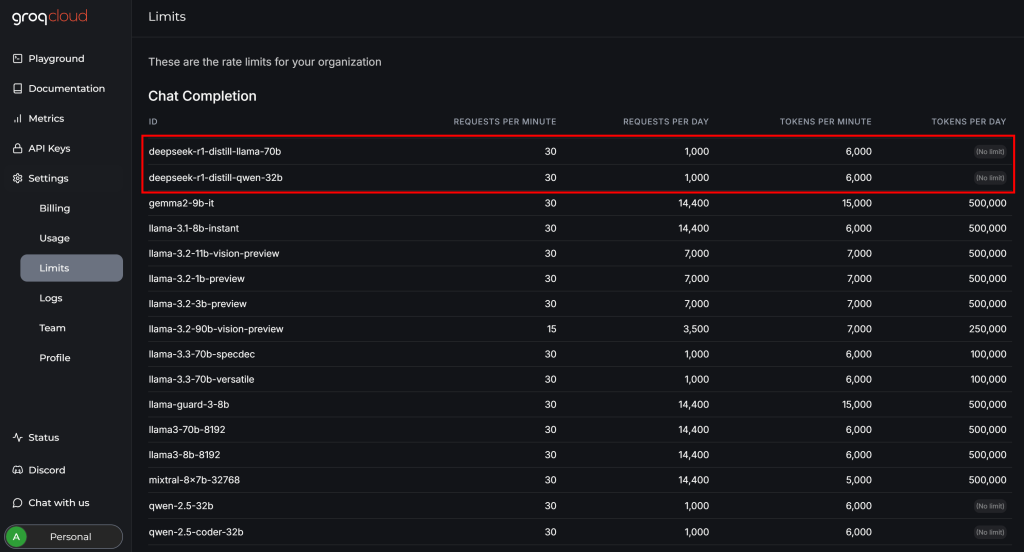
Dort können Sie sehen, dass die beiden verfügbaren DeepSeek-Modelle die folgenden Einschränkungen für den kostenlosen Plan haben:
- Bis zu 30 Anfragen pro Minute
- Bis zu 1.000 Anfragen pro Tag
- Nicht mehr als 6.000 Token pro Minute
Während die ersten beiden Einschränkungen für dieses Beispiel kein Problem darstellen, ist die letzte eine Herausforderung. Eine typische Webseite kann Millionen von Zeichen enthalten, was zu Hunderttausenden von Token führt.
Mit anderen Worten: Sie können nicht die gesamte G2-Seite direkt in DeepSeek-Modelle über Groq einspeisen, da die Token-Limits nicht ausreichen. Um dieses Problem zu lösen, erlaubt Crawl4AI, nur bestimmte Abschnitte der Seite auszuwählen. Diese Abschnitte – und nicht die gesamte Seite – werden in Markdown konvertiert und an den LLM weitergeleitet. Die Auswahl der Abschnitte erfolgt mit Hilfe von CSS-Selektoren.
Um die auszuwählenden Abschnitte zu bestimmen, öffnen Sie die Zielseite in Ihrem Browser. Klicken Sie mit der rechten Maustaste auf die Elemente, die die gewünschten Daten enthalten, und wählen Sie die Option “Untersuchen”:
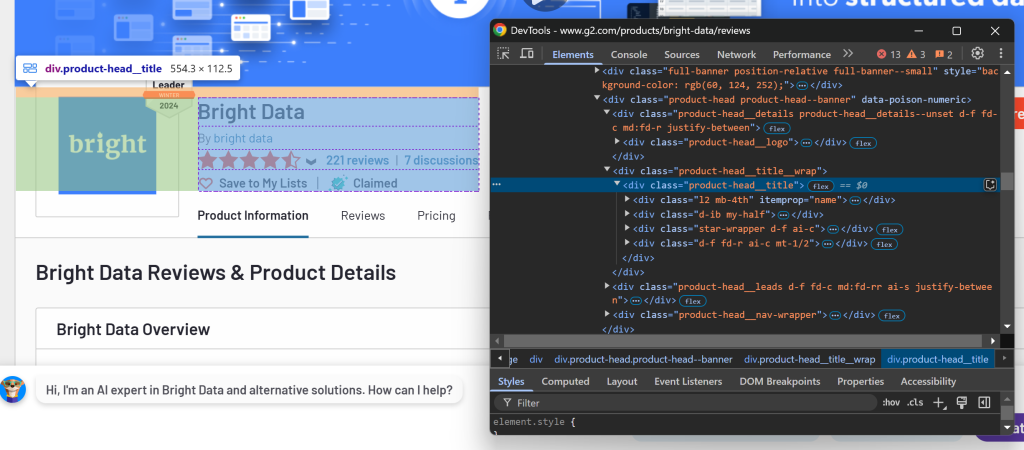
Hier können Sie sehen, dass das Element .product-head__title den Produkt-/Firmennamen, die Bewertungszahl, die Anzahl der Bewertungen und den beanspruchten Status enthält.
Überprüfen Sie nun den Bereich Logo:
Sie können diese Informationen mit dem CSS-Selektor .product-head__logo abrufen.
Prüfen Sie schließlich den Abschnitt Beschreibung:
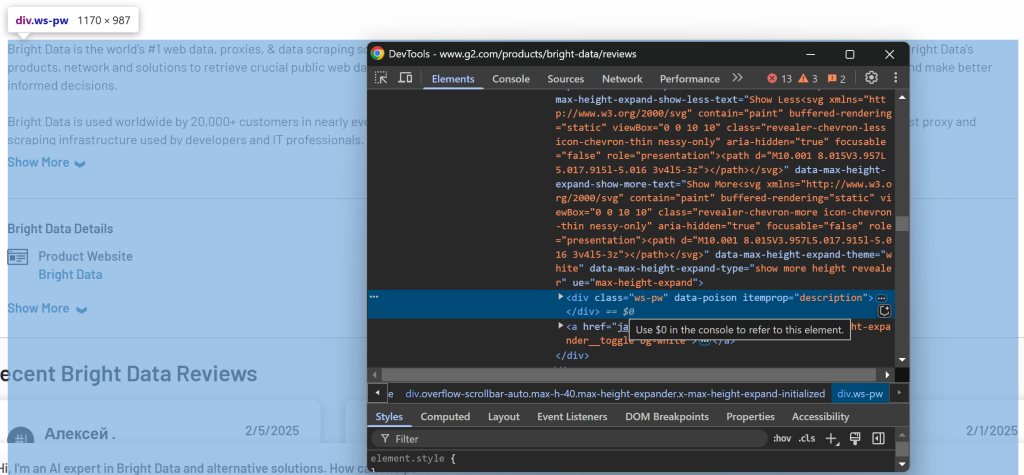
Die Beschreibung ist über den Selektor [itemprop="description"] verfügbar.
Konfigurieren Sie diese CSS-Selektoren in CrawlerRunConfig wie folgt:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000,
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]", # the CSS selectors of the elements to extract data from
)Wenn Sie scraper.py erneut ausführen, erhalten Sie jetzt etwas wie:
Response status code: 200
Parsed Markdown data:
[](https:/www.g2.com/products/bright-data/reviews)
[Editedit](https:/my.g2.com/bright-data/product_information)
[Bright Data](https:/www.g2.com/products/bright-data/reviews)
By [bright data](https:/www.g2.com/sellers/bright-data)
Show rating breakdown
4.7 out of 5 stars
[5 star78%](https:/www.g2.com/products/bright-data/reviews?filters%5Bnps_score%5D%5B%5D=5#reviews)
[4 star19%](https:/www.g2.cDie Ausgabe umfasst nur die relevanten Abschnitte und nicht die gesamte HTML-Seite. Dieser Ansatz reduziert die Verwendung von Token erheblich und ermöglicht es Ihnen, innerhalb der Free-Tier-Grenzen von Groq zu bleiben, während Sie effektiv die gewünschten Daten extrahieren!
Schritt #11: Definieren Sie die DeepSeek-basierte LLM-Extraktionsstrategie
Craw4AI unterstützt LLM-basierte Datenextraktion durch das LLMExtractionStrategy Objekt. Sie können eine für die DeepSeek-Integration wie folgt definieren:
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)Um das LLM-Modell anzugeben, fügen Sie die folgende Umgebungsvariable zu .env hinzu:
LLM_MODEL=groq/deepseek-r1-distill-llama-70bDamit wird Craw4AI angewiesen, das Modell deepseek-r1-distill-llama-70b von GroqCloud für die LLM-basierte Datenextraktion zu verwenden.
In scraper.py importieren Sie LLMExtractionStrategy und G2Product:
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2ProductAnschließend übergeben Sie das Objekt extraction_strategy an crawler_config:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)Wenn Sie das Skript ausführen, wird Craw4AI:
- Verbinden Sie sich mit der Ziel-Webseite über den Web Unlocker API Proxy.
- Ruft den HTML-Inhalt der Seite ab und filtert Elemente anhand der angegebenen CSS-Selektoren.
- Konvertiert die ausgewählten HTML-Elemente in das Markdown-Format.
- Senden Sie die formatierte Markdown-Datei zur Datenextraktion an DeepSeek.
- Weisen Sie DeepSeek an, die Eingabe entsprechend der angegebenen Aufforderung
(Instruktion) zu verarbeiten und die extrahierten Daten zurückzugeben.
Nachdem Sie crawler.arun() ausgeführt haben, können Sie die Verwendung von Token mit überprüfen:
print(extraction_strategy.show_usage())Anschließend können Sie die extrahierten Daten mit abrufen und ausdrucken:
result_raw_data = result.extracted_content
print(result_raw_data)Wenn Sie das Skript ausführen und die Ergebnisse ausdrucken, sollten Sie eine Ausgabe wie diese sehen:
=== Token Usage Summary ===
Type Count
------------------------------
Completion 525
Prompt 2,002
Total 2,527
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 525 2,002 2,527
None
[
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c07c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}
]Der erste Teil der Ausgabe (Token-Nutzung) stammt von show_usage() und bestätigt, dass wir weit unter dem Limit von 6.000 Token liegen. Die folgenden resultierenden Daten sind eine JSON-Zeichenfolge, die dem G2Product-Schema entspricht.
Einfach unglaublich!
Schritt Nr. 12: Umgang mit den Ergebnisdaten
Wie Sie aus der Ausgabe im vorherigen Schritt ersehen können, gibt DeepSeek normalerweise ein Array statt eines einzelnen Objekts zurück. Um dies zu handhaben, parsen Sie die zurückgegebenen Daten als JSON und extrahieren das erste Element aus dem Array:
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]Denken Sie daran, json aus der Python-Standardbibliothek zu importieren:
import jsonZu diesem Zeitpunkt sollte result_data eine Instanz von G2Product sein. Der letzte Schritt besteht darin, diese Daten in eine JSON-Datei zu exportieren.
Schritt #13: Exportieren Sie die gescrapten Daten in JSON
Verwenden Sie json, um result_data in eine g2.json-Datei zu exportieren:
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)Auftrag erfüllt!
Schritt Nr. 14: Alles zusammenfügen
Ihre endgültige scraper.py-Datei sollte enthalten:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
import os
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2Product
import json
# Load secrets from .env file
load_dotenv()
async def main():
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)
# LLM extraction strategy for data extraction using DeepSeek
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in "x/5" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop="description"]",
extraction_strategy=extraction_strategy
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# Log the AI model usage info
print(extraction_strategy.show_usage())
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]
# Export the scraped data to JSON
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)
if __name__ == "__main__":
asyncio.run(main())Dann wird models/g2_product.py speichern:
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: boolUnd .env wird haben:
PROXY_SERVER=https://<WEB_UNLOCKER_API_HOST>:<WEB_UNLOCKER_API_PORT>
PROXY_USERNAME=<WEB_UNLOCKER_API_USERNAME>
PROXY_PASSWORD=<WEB_UNLOCKER_API_PASSWORD>
LLM_API_TOKEN=<GROQ_API_KEY>
LLM_MODEL=groq/deepseek-r1-distill-llama-70bStarten Sie Ihren DeepSeek Crawl4AI Scraper mit:
python scraper.pyDie Ausgabe im Terminal wird etwa so aussehen:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 56.13s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 397ms
[LOG] Call LLM for https://www.g2.com/products/bright-data/reviews - block index: 0
[LOG] Extracted 1 blocks from URL: https://www.g2.com/products/bright-data/reviews block index: 0
[EXTRACT]. ■ Completed for https://www.g2.com/products/bright-data/reviews... | Time: 12.273853100006818s
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 68.81s
=== Token Usage Summary ===
Type Count
------------------------------
Completion 524
Prompt 2,002
Total 2,526
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 524 2,002 2,526
NoneAußerdem wird eine g2.json-Datei in Ihrem Projektordner erscheinen. Öffnen Sie sie, und Sie werden sehen:
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c7c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}Herzlichen Glückwunsch! Sie haben mit einer Bot-geschützten G2-Seite begonnen und Crawl4AI, DeepSeek und Web Unlocker API verwendet, um strukturierte Daten daraus zu extrahieren – ohne eine einzige Zeile Parsing-Logik zu schreiben.
Schlussfolgerung
In diesem Tutorial haben Sie erfahren, was Crawl4AI ist und wie man es in Kombination mit DeepSeek verwendet, um einen KI-gestützten Scraper zu erstellen. Eine der größten Herausforderungen beim Scrapen ist das Risiko, blockiert zu werden, aber das wurde mit der Web Unlocker API von Bright Data überwunden.
Wie in diesem Tutorial gezeigt wird, können Sie mit der Kombination aus Crawl4AI, DeepSeek und der Web Unlocker API Daten von jeder beliebigen Website extrahieren – selbst von solchen, die stärker geschützt sind, wie G2 -, ohne dass eine spezielle Parsing-Logik erforderlich ist. Dies ist nur eines von vielen Szenarien, die von den Produkten und Services von Bright Data unterstützt werden, mit denen Sie effektives KI-gesteuertes Web Scraping implementieren können.
Entdecken Sie unsere anderen Web Scraping Tools, die mit Crawl4AI integriert werden können:
- Proxy-Dienste: 4 verschiedene Arten von Proxys zur Umgehung von Standortbeschränkungen, einschließlich mehr als 400M+ monthly privater IPs
- Web Scraper APIs: Spezielle Endpunkte zum Extrahieren von frischen, strukturierten Webdaten aus über 100 beliebten Domains.
- SERP-API: API zur Verwaltung aller laufenden Freischaltungen für SERP und Extraktion einer Seite
- Scraping-Browser: Puppeteer-, Selenium- und Playwright-kompatibler Browser mit integrierten Freischaltaktivitäten
Melden Sie sich jetzt bei Bright Data an und testen Sie unsere Proxy-Dienste und Scraping-Produkte kostenlos!




