

Der Aufbau einer zuverlässigen Lösung zur Extraktion von Webdaten beginnt mit der richtigen Infrastruktur. In diesem Leitfaden erstellen Sie eine einseitige Anwendung, die eine beliebige URL einer öffentlichen Webseite und eine Eingabeaufforderung in natürlicher Sprache akzeptiert. Anschließend wird der Extraktionsprozess vollständig automatisiert, indem sauberes, strukturiertes JSON analysiert und zurückgegeben wird.
Der Stack kombiniert die Anti-Bot-Scraping-Infrastruktur von Bright Data, das sichere Backend von Supabase und die schnellen Entwicklungstools von Lovable in einem nahtlosen Workflow.
Was Sie bauen werden
Hier sehen Sie die komplette Datenpipeline, die Sie aufbauen werden – von der Benutzereingabe bis zur strukturierten JSON-Ausgabe und Speicherung:
User Input
↓
Authentication
↓
Database Logging
↓
Edge Function
↓
Bright Data Web Unlocker (Bypasses anti-bot protection)
↓
Raw HTML
↓
Turndown (HTML → Markdown)
↓
Clean structured text
↓
Google Gemini AI (Natural language processing)
↓
Structured JSON
↓
Database Storage
↓
Frontend Display
↓
User ExportHier ist ein kurzer Blick auf die fertige App:
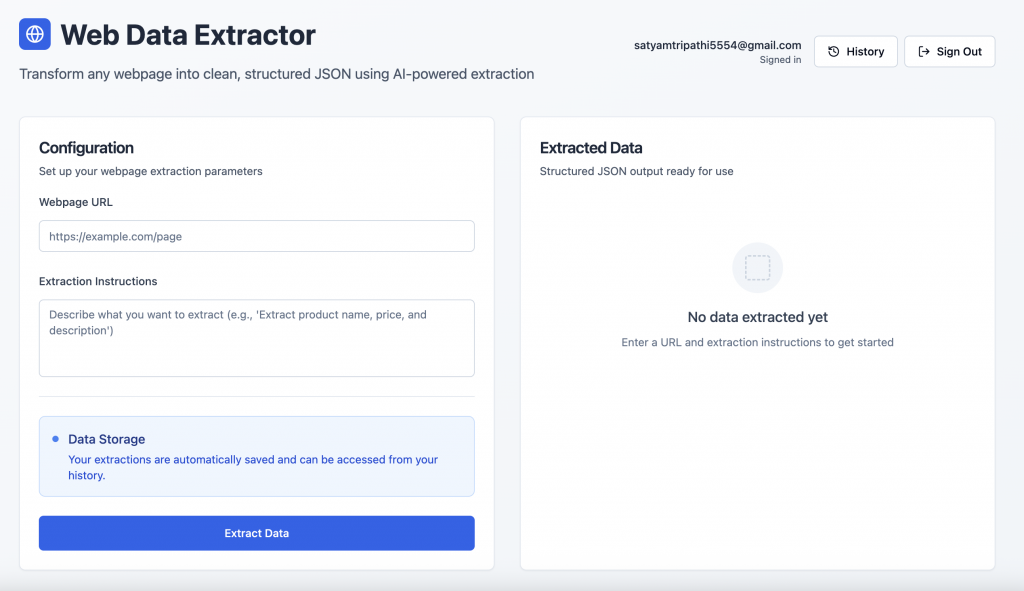
Benutzer-Authentifizierung: Benutzer können sich über den von Supabase unterstützten Authentifizierungsbildschirm sicher anmelden oder einloggen.

Schnittstelle zur Datenextraktion: Nach der Anmeldung können die Benutzer eine URL einer Webseite eingeben und eine natürlichsprachliche Eingabeaufforderung erhalten, um strukturierte Daten abzurufen.
Überblick über den Technologiestapel
Im Folgenden finden Sie eine Aufschlüsselung unseres Stacks und den strategischen Vorteil, den jede Komponente bietet.
- Helle Daten: Web Scraping stößt oft auf Blockaden, CAPTCHAs und erweiterte Bot-Erkennung. Bright Data wurde speziell zur Bewältigung dieser Herausforderungen entwickelt. Es bietet:
- Automatische Proxy-Rotation
- CAPTCHA-Auflösung und Bot-Schutz
- Globale Infrastruktur für konsistenten Zugang
- JavaScript-Rendering für dynamische Inhalte
- Automatisierte Handhabung von Ratenbegrenzungen
Für diesen Leitfaden verwenden wir den Web Unlocker von Bright Data – ein speziell entwickeltes Tool, das selbst von den am stärksten geschützten Seiten zuverlässig den vollständigen HTML-Code abruft.
- Supabase:Supabase bietet eine sichere Backend-Grundlage für moderne Anwendungen, mit folgenden Merkmalen:
- Integrierte Authentifizierung und Sitzungsverarbeitung
- Eine PostgreSQL-Datenbank mit Echtzeit-Unterstützung
- Edge-Funktionen für serverlose Logik
- Sichere Schlüsselspeicherung und Zugangskontrolle
- Liebenswert: Lovable rationalisiert die Entwicklung mit KI-gestützten Tools und nativer Supabase-Integration. Es bietet:
- KI-gesteuerte Code-Generierung
- Nahtloses Front-End/Back-End-Gerüst
- React + Tailwind UI sofort einsatzbereit
- Schnelles Prototyping für produktionsreife Anwendungen
- Google Gemini AI:Gemini wandelt rohes HTML in strukturiertes JSON um und verwendet dabei natürlichsprachliche Eingabeaufforderungen. Es unterstützt:
- Genaues Verstehen und Parsen von Inhalten
- Unterstützung großer Eingaben für ganzseitigen Kontext
- Skalierbare, kosteneffiziente Datenextraktion
Voraussetzungen und Einrichtung
Bevor Sie mit der Entwicklung beginnen, vergewissern Sie sich, dass Sie Zugang zu Folgendem haben:
- Bright Data-Konto
- Anmeldung unter brightdata.com
- Erstellen einer Web Unlocker Zone
- Rufen Sie Ihren API-Schlüssel in den Kontoeinstellungen ab
- Google AI Studio-Konto
- Besuchen Sie Google AI Studio
- Einen neuen API-Schlüssel erstellen
- Supabase-Projekt
- Anmeldung bei supabase.com
- Erstellen Sie eine neue Organisation und legen Sie dann ein neues Projekt an.
- Gehen Sie in Ihrem Projekt-Dashboard zu Edge Functions → Secrets → Add New Secret. Fügen Sie Geheimnisse wie
BRIGHT_DATA_API_KEYundGEMINI_API_KEYmit ihren jeweiligen Werten hinzu
- Liebenswertes Konto
- Registrieren Sie sich unter lovable.dev
- Gehen Sie zu Ihrem Profil → Einstellungen → Integrationen
- Klicken Sie unter Supabase auf Connect Supabase
- Autorisieren Sie den API-Zugang und verknüpfen Sie ihn mit der gerade erstellten Supabase-Organisation
Schrittweiser Aufbau der Anwendung mit Lovable Prompts
Im Folgenden finden Sie einen strukturierten, auf Eingabeaufforderungen basierenden Ablauf für die Entwicklung Ihrer Webdatenextraktionsanwendung, vom Frontend bis zum Backend, zur Datenbank und zum intelligenten Parsing.
Schritt 1 – Frontend-Einrichtung
Beginnen Sie mit der Gestaltung einer sauberen und intuitiven Benutzeroberfläche.
Build a modern web data extraction app using React and Tailwind CSS. The UI should include:
- A gradient background with card-style layout
- An input field for the webpage URL
- A textarea for the extraction prompt (e.g., "Extract product title, price, and ratings")
- A display area to render structured JSON output
- Responsive styling with hover effects and proper spacingSchritt #2 – Supabase verbinden & Authentifizierung hinzufügen
So verknüpfen Sie Ihr Supabase-Projekt:
- Klicken Sie auf das Supabase-Symbol in der oberen rechten Ecke von Lovable
- Wählen Sie Connect Supabase
- Wählen Sie die Organisation und das Projekt, das Sie zuvor erstellt haben
Lovable wird Ihr Supabase-Projekt automatisch integrieren. Verwenden Sie nach der Verknüpfung die unten stehende Eingabeaufforderung, um die Authentifizierung zu aktivieren:
Set up complete Supabase authentication:
- Sign up and login forms using email/password
- Session management and auto-persistence
- Route protection for unauthenticated users
- Sign out functionality
- Create user profile on signup
- Handle all auth-related errorsLovable generiert das erforderliche SQL-Schema und die Trigger – überprüfen und genehmigen Sie diese, um Ihren Authentifizierungsprozess abzuschließen.
Schritt Nr. 3 – Definition des Supabase-Datenbankschemas
Richten Sie die erforderlichen Tabellen zur Protokollierung und Speicherung der Extraktionsaktivitäten ein:
Create Supabase tables for storing extractions and results:
- extractions: stores URL, prompt, user_id, status, processing_time, error_message
- extraction_results: stores parsed JSON output
Apply RLS policies to ensure each user can only access their own dataSchritt Nr. 4 – Erstellen der Supabase Edge-Funktion
Diese Funktion ist für die Kernlogik des Scrapings, der Konvertierung und der Extraktion zuständig:
Create an Edge Function called 'extract-web-data' that:
- Fetches the target page using Bright Data's Web Unlocker
- Converts raw HTML to Markdown using Turndown
- Sends the Markdown and prompt to Google Gemini AI (gemini-2.0-flash-001)
- Returns clean structured JSON
- Handles CORS, errors, and response formatting
- Requires GEMINI_API_KEY and BRIGHT_DATA_API_KEY as Edge Function secrets
Below is a reference implementation that handles HTML fetching using Bright Data, markdown conversion with Turndown, and AI-driven extraction with Gemini:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// Constants
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('Failed to initialize WebContentExtractor:', error);
throw error;
}
}
/**
* Fetches webpage content using Bright Data Web Unlocker service
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// Append Web Unlocker parameters to the target URL
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`Web Unlocker request failed with status: ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('Failed to fetch webpage content:', error);
return null;
}
}
/**
* Converts HTML to clean Markdown format for better AI processing
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('Failed to convert HTML to Markdown:', error);
return null;
}
}
/**
* Uses Gemini AI to extract specific information from markdown content
* Uses low temperature for more consistent, factual responses
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('Failed to extract information with AI:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `You are a data extraction assistant. Below is some content in markdown format extracted from a webpage.
Please analyze this content and extract the information requested by the user.
USER REQUEST: ${userQuery}
MARKDOWN CONTENT:
${markdownContent}
Please provide a clear, structured response based on the user's request. If the requested information is not available in the content, please indicate that clearly.`;
}
/**
* Main extraction workflow: fetches webpage → converts to markdown → extracts with AI
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('Could not retrieve HTML content from URL');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('Could not convert HTML to Markdown');
return null;
}
const extractedInformation: string | null = await this.extractInformationWithAI(markdownContent, extractionQuery);
return extractedInformation;
} catch (error) {
console.error('Error in extractDataFromUrl:', error);
return null;
}
}
}
/**
* Example usage of the WebContentExtractor
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('Failed to extract data from the specified URL');
}
} catch (error) {
console.error(`Application error: ${error}`);
}
}
// Execute the application
runExtraction().catch(console.error);Die Konvertierung von HTML-Rohdaten in Markdown, bevor sie an Gemini AI gesendet werden, hat mehrere entscheidende Vorteile. Unnötiges HTML-Rauschen wird entfernt, die KI-Leistung wird durch sauberere, besser strukturierte Eingaben verbessert, und die Verwendung von Token wird reduziert, was zu einer schnelleren und kosteneffizienteren Verarbeitung führt.
Wichtige Überlegung: Lovable ist hervorragend in der Lage, Anwendungen aus natürlicher Sprache zu erstellen, weiß aber nicht immer, wie externe Tools wie Bright Data oder Gemini korrekt integriert werden können. Um eine korrekte Implementierung zu gewährleisten, sollten Sie einen funktionierenden Beispielcode in Ihre Eingabeaufforderungen aufnehmen. Die Methode fetchContentViaBrightData in der obigen Eingabeaufforderung demonstriert beispielsweise einen einfachen Anwendungsfall für den Web Unlocker von Bright Data.
Bright Data bietet mehrere APIs an, darunter Web Unlocker, SERP-API und Scraper-APIs, jeweils mit eigenem Endpunkt, Authentifizierungsmethode und Parametern. Wenn Sie ein Produkt oder eine Zone im Bright Data-Dashboard einrichten, werden auf der Registerkarte Übersicht sprachspezifische Codeschnipsel (Node.js, Python, cURL) angezeigt, die auf Ihre Konfiguration zugeschnitten sind. Verwenden Sie diese Schnipsel unverändert oder passen Sie sie an die Logik Ihrer Edge-Funktion an.
Schritt Nr. 5 – Verbindung des Frontends mit der Edge-Funktion
Sobald Ihre Edge-Funktion fertig ist, integrieren Sie sie in Ihre React-Anwendung:
Connect the frontend to the Edge Function:
- On form submission, call the Edge Function
- Log the request in the database
- Update status (processing/completed/failed) after the response
- Show processing time, status icons, and toast notifications
- Display the extracted JSON with loading statesSchritt #6 – Extraktionsverlauf hinzufügen
Bieten Sie den Nutzern die Möglichkeit, frühere Anfragen zu überprüfen:
Create a history view that:
- Lists all extractions for the logged-in user
- Displays URL, prompt, status, duration, and date
- Includes View and Delete options
- Expands rows to show extracted results
- Uses icons for statuses (completed,failed,processing)
- Handles long text/URLs gracefully with a responsive layoutSchritt Nr. 7 – Feinschliff der Benutzeroberfläche und letzte Verbesserungen
Verfeinern Sie das Erlebnis mit hilfreichen UI-Elementen:
Polish the interface:
- Add toggle between "New Extraction" and "History"
- Create a JsonDisplay component with syntax highlighting and copy button
- Fix responsiveness issues for long prompts and URLs
- Add loading spinners, empty states, and fallback messages
- Include feature cards or tips at the bottom of the pageSchlussfolgerung
Diese Integration vereint das Beste aus der modernen Web-Automatisierung: sichere Benutzerströme mit Supabase, zuverlässiges Scraping mit Bright Data und flexibles, KI-gestütztes Parsing mit Gemini – und das alles mit dem intuitiven, Chat-basierten Builder von Lovable für einen Null-Code-Workflow mit hoher Produktivität.
Sind Sie bereit, Ihr eigenes System zu erstellen? Starten Sie auf brightdata.com und entdecken Sie die Datenerfassungslösungen von Bright Data für einen skalierbaren Zugriff auf jeden Standort, ohne dass Sie sich um die Infrastruktur kümmern müssen.





