

In diesem Leitfaden erfahren Sie mehr:
- Warum Perplexity eine gute Wahl für AI-gestütztes Web Scraping ist
- Schritt-für-Schritt-Anleitung zum Scrapen einer Website in Python
- Die wichtigste Einschränkung dieses Web-Scraping-Ansatzes und wie sie umgangen werden kann
Fangen wir an!
Warum Perplexity für Web Scraping verwenden?
Perplexity ist eine KI-gestützte Suchmaschine, die große Sprachmodelle verwendet, um detaillierte Antworten auf Benutzeranfragen zu generieren. Sie ruft Informationen in Echtzeit ab, fasst sie zusammen und kann mit zitierten Quellen antworten.
Der Einsatz von Perplexity für Web Scraping reduziert den Prozess der Datenextraktion aus unstrukturierten HTML-Inhalten auf eine einfache Eingabeaufforderung. Dadurch entfällt die Notwendigkeit der manuellen Datenanalyse, was die Extraktion relevanter Informationen erheblich erleichtert.
Darüber hinaus ist Perplexity für fortgeschrittene Web-Crawling-Szenarien ausgelegt, dank seiner Fähigkeiten zur Erkennung und Erforschung von Webseiten.
Weitere Informationen finden Sie in unserem Leitfaden zur Verwendung von KI für Web Scraping.
Anwendungsfälle
Einige Beispiele für Perplexity-gestützte Scraping-Anwendungsfälle sind:
- Seiten, deren Struktur sich häufig ändert: Es kann sich an dynamische Seiten anpassen, bei denen sich Layouts und Datenelemente häufig ändern, wie z. B. bei E-Commerce-Seiten wie Amazon.
- Crawling großer Websites: Es kann beim Auffinden und Navigieren von Seiten helfen oder KI-gesteuerte Suchen durchführen, die den Scraping-Prozess steuern.
- Extrahieren von Daten aus komplexen Seiten: Für Websites mit schwer zu parsenden Strukturen kann Perplexity die Datenextraktion automatisieren, ohne dass eine umfangreiche benutzerdefinierte Parsing-Logik erforderlich ist.
Szenarien
Einige Beispiele, bei denen sich das Scrapen mit Perplexity als nützlich erweist, sind:
- Retrieval-Augmented Generation (RAG): Verbesserung der KI-Einsichten durch Integration von Echtzeit-Datenabfragen. Ein praktisches Beispiel für ein ähnliches KI-Modell finden Sie in unserem Leitfaden zur Erstellung eines RAG-Chatbots mit SERP-Daten.
- Aggregation von Inhalten: Sammeln von Nachrichten, Blogbeiträgen oder Artikeln aus mehreren Quellen, um Zusammenfassungen oder Analysen zu erstellen.
- Scraping von sozialen Medien: Extrahieren strukturierter Daten von Plattformen mit dynamischen oder häufig aktualisierten Inhalten.
Wie man Web Scraping mit Perplexity in Python durchführt
Für diesen Abschnitt werden wir eine bestimmte Produktseite aus der Sandbox “Ecommerce Test Site to Learn Web Scraping” verwenden:

Diese Seite ist ein großartiges Beispiel, denn E-Commerce-Produktseiten sind oft unterschiedlich strukturiert und zeigen verschiedene Arten von Daten an. Das macht das E-Commerce-Web-Scraping so schwierig – und hier kann KI helfen.
Der von Perplexity betriebene Scraper nutzt KI, um diese Produktdetails aus der Seite zu extrahieren, ohne dass eine manuelle Parsing-Logik erforderlich ist:
- SKU
- Name
- Bilder
- Preis
- Beschreibung
- Größen
- Farben
- Kategorie
Hinweis: Das folgende Beispiel wird der Einfachheit halber und wegen der Popularität der beteiligten SDKs in Python ausgeführt. Sie können jedoch das gleiche Ergebnis mit JavaScript oder einer anderen Programmiersprache erzielen.
Führen Sie die folgenden Schritte aus, um zu lernen, wie man mit Perplexity Webdaten scrapen kann!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, stellen Sie sicher, dass Python 3 auf Ihrem Rechner installiert ist. Ist dies nicht der Fall, laden Sie es herunter und folgen Sie den Installationsanweisungen.
Führen Sie dann den folgenden Befehl aus, um einen Ordner für Ihr Scraping-Projekt zu initialisieren:
mkdir perplexity-scraperDas Verzeichnis perplexity-scraper dient als Projektordner für Ihr Projekt zum Web Scraping mit Perplexity.
Navigieren Sie in Ihrem Terminal zu diesem Ordner und erstellen Sie darin eine virtuelle Python-Umgebung:
cd perplexity-scraper
python -m venv venvÖffnen Sie den Projektordner in Ihrer bevorzugten Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind beide ausgezeichnete Optionen.
Erstellen Sie eine scraper.py-Datei im Projektordner, die nun wie folgt aussehen sollte:

Zu diesem Zeitpunkt ist scraper.py nur ein leeres Python-Skript, aber es wird bald die Logik für LLM Web Scraping enthalten.
Als nächstes aktivieren Sie die virtuelle Umgebung im Terminal Ihrer IDE. Unter Linux oder macOS führen Sie aus:
source venv/bin/activateÄquivalent unter Windows: Verwenden Sie:
venv/Scripts/activateGroßartig! Ihre Python-Umgebung ist nun für Web Scraping mit Perplexity eingerichtet.
Schritt #2: Abrufen des Perplexity API-Schlüssels
Wie die meisten KI-Anbieter stellt auch Perplexity seine Modelle über APIs zur Verfügung. Um programmatisch auf sie zuzugreifen, müssen Sie zunächst einen Perplexity-API-Schlüssel einlösen. Sie können sich auf die offizielle “Ersteinrichtung” beziehen oder die unten aufgeführten Schritte befolgen.
Wenn Sie noch kein Perplexity-Konto haben, erstellen Sie eines und melden Sie sich an. Navigieren Sie dann zur Seite “API” und klicken Sie auf “Einrichten”, um eine Zahlungsmethode hinzuzufügen, falls Sie dies noch nicht getan haben:

Hinweis: Dieser Schritt wird Ihnen nicht in Rechnung gestellt. Perplexity speichert Ihre Zahlungsdaten nur für die zukünftige API-Nutzung. Sie können eine Kredit-/Debitkarte, Google Pay oder eine andere unterstützte Zahlungsmethode verwenden.
Sobald Ihre Zahlungsmethode eingerichtet ist, sehen Sie den folgenden Abschnitt:

Kaufen Sie einige Credits, indem Sie auf “+ Credits kaufen” klicken, und warten Sie, bis sie Ihrem Konto hinzugefügt werden. Sobald die Credits verfügbar sind, wird die Schaltfläche “+ Generieren” unter dem Abschnitt API-Schlüssel aktiv. Drücken Sie darauf, um Ihren Perplexity-API-Schlüssel zu generieren:

Es wird ein API-Schlüssel angezeigt:

Kopieren Sie den Schlüssel und bewahren Sie ihn an einem sicheren Ort auf. Der Einfachheit halber werden wir ihn als Konstante in scraper.py definieren:
PERPLEXITY_API_KEY="<YOUR_PERPLEXITY_API_KEY>"Wichtig: Vermeiden Sie in produktiven Perplexity Scraping-Skripten die Speicherung von API-Schlüsseln im Klartext. Speichern Sie solche Geheimnisse stattdessen in Umgebungsvariablen oder einer .env-Datei, die mit Bibliotheken wie python-dotenv verwaltet wird.
Wunderbar! Sie sind bereit, das OpenAI SDK zu verwenden, um API-Anfragen an Perplexitys Modelle in Python zu stellen.
Schritt #3: Konfigurieren Sie Perplexity in Python
Der letzte Satz im vorigen Schritt enthält keinen Tippfehler – auch wenn er das OpenAI SDK erwähnt. Das liegt daran, dass die Perplexity-API vollständig OpenAI-kompatibel ist. Der empfohlene Weg, sich mit Python mit der Perplexity-API zu verbinden, führt über das OpenAI SDK.
Als ersten Schritt installieren Sie das OpenAI Python SDK. Führen Sie es in einer aktivierten virtuellen Umgebung aus:
pip install openaiAnschließend importieren Sie es in Ihr scraper.py-Skript:
from openai import OpenAIUm eine Verbindung zu Perplexity anstelle von OpenAI herzustellen, konfigurieren Sie den Client wie folgt:
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")Großartig! Die Einrichtung von Perplexity Python ist nun abgeschlossen, und Sie können API-Anfragen an die Modelle stellen.
Schritt #4: Holen Sie sich den HTML-Code der Zielseite
Nun müssen Sie den HTML-Code der Zielseite abrufen. Das können Sie mit einem leistungsfähigen Python-HTTP-Client wie Requests erreichen.
In einer aktivierten virtuellen Umgebung installieren Sie Requests mit:
pip install requestsAls nächstes importieren Sie die Bibliothek in scraper.py:
import requestsVerwenden Sie die Methode get(), um eine GET-Anfrage an die URL der Seite zu senden:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)Der Zielserver antwortet mit dem rohen HTML-Code der Seite.
Wenn Sie response.content drucken, sehen Sie das vollständige HTML-Dokument:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Ajax Full-Zip Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Sie haben nun den genauen HTML-Code der Zielseite in Python. Analysieren wir sie und extrahieren wir die benötigten Daten daraus!
Schritt Nr. 5: Konvertieren Sie die HTML-Seite in Markdown (optional)
Achtung! Dieser Schritt ist technisch nicht erforderlich, aber er kann Ihnen viel Zeit und Geld sparen. Er ist also auf jeden Fall eine Überlegung wert.
Nehmen Sie sich einen Moment Zeit, um herauszufinden, wie andere KI-gestützte Web-Scraping-Technologien wie Crawl4AI und ScrapeGraphAI mit Roh-HTML umgehen. Sie werden feststellen, dass sie beide Optionen zur Konvertierung von HTML in Markdown anbieten, bevor sie den Inhalt an den konfigurierten LLM weitergeben.
Warum tun sie das? Dafür gibt es zwei Hauptgründe:
- Kosteneffizienz: Durch die Konvertierung in Markdown wird die Anzahl der an die KI gesendeten Token reduziert, wodurch Sie Geld sparen können.
- Schnellere Verarbeitung: Weniger Eingabedaten bedeuten geringere Rechenkosten und schnellere Antworten.
Weitere Informationen finden Sie in unserem Leitfaden darüber, warum die neuen KI-Agenten Markdown gegenüber HTML bevorzugen.
Es ist an der Zeit, die HTML-zu-Markdown-Konvertierungslogik zu replizieren, um die Verwendung von Token zu reduzieren!
Öffnen Sie zunächst die Ziel-Webseite im Inkognito-Modus (um sicherzustellen, dass Sie mit einer neuen Sitzung arbeiten). Klicken Sie dann mit der rechten Maustaste auf eine beliebige Stelle der Seite und wählen Sie “Prüfen”, um die Entwicklertools zu öffnen.
Untersuchen Sie die Struktur der Seite. Sie werden sehen, dass alle relevanten Daten in dem HTML-Element enthalten sind, das durch den CSS-Selektor #main gekennzeichnet ist:

Technisch gesehen könnten Sie das gesamte HTML-Rohmaterial zum Parsen der Daten an Perplexity senden. Das würde jedoch eine Menge unnötiger Informationen enthalten – wie Kopf- und Fußzeilen. Wenn Sie stattdessen den Inhalt von #main als Eingangsrohdaten verwenden, ist gewährleistet, dass Sie nur mit den wichtigsten Daten arbeiten. Dadurch wird das Rauschen reduziert und KI-Halluzinationen begrenzt.
Um nur das #main-Element zu extrahieren, benötigen Sie eine Python-HTML-Parsing-Bibliothek wie Beautiful Soup. Installieren Sie sie in Ihrer aktivierten virtuellen Python-Umgebung mit diesem Befehl:
pip install beautifulsoup4Wenn Sie mit der API nicht vertraut sind, lesen Sie unseren Leitfaden über Beautiful Soup Web Scraping.
Nun importieren Sie es in scraper.py:
from bs4 import BeautifulSoupVerwenden Sie Beautiful Soup zum:
- Parsen Sie das mit Requests abgerufene Roh-HTML
- Wählen Sie das Element
#main - Abrufen des HTML-Inhalts
Erreichen Sie das mit diesem Ausschnitt:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Wenn Sie main_html ausdrucken, sehen Sie etwas wie dieses:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-309"
class="product type-product post-309 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
</main>Verwenden Sie das Tokenizer-Tool von OpenAI, um zu prüfen, wie vielen Token der ausgewählte HTML-Code entspricht:

Schätzen Sie anschließend die Kosten für das Senden dieser Token an die API von Perplexity mit dem LLM API Pricing Calculator:

Wie Sie sehen können, führt dieser Ansatz zu mehr als 20.000 Token. Das bedeutet zwischen 0,21 und etwa 0,63 $ pro Anfrage. Bei einem großen Projekt mit Tausenden von Seiten ist das eine Menge!
Um den Tokenverbrauch zu reduzieren, konvertieren Sie das extrahierte HTML in Markdown mit einer Bibliothek wie markdownify. Installieren Sie sie in Ihrem Perplexity-gestützten Scraping-Projekt mit:
pip install markdownifyImportieren Sie markdownify in scraper.py:
from markdownify import markdownifyDann konvertieren Sie damit den HTML-Code von #main in Markdown:
main_markdown = markdownify(main_html)Der Datenkonvertierungsprozess führt zu einer Ausgabe wie unten dargestellt:

Anhand des Elements “size” am Ende der beiden Textbereiche können Sie erkennen, dass die Markdown-Version der Eingabedaten viel kleiner ist als das ursprüngliche #main HTML. Außerdem werden Sie bei der Betrachtung feststellen, dass sie immer noch alle wichtigen Daten zum Scrapen enthält!
Verwenden Sie erneut den Tokenizer von OpenAI, um zu prüfen, wie viele Token die neue Markdown-Eingabe verbraucht:

Mit diesem einfachen Trick konnten Sie 20.658 Token auf 950 Token reduzieren – eine Verringerung um mehr als 95 %. Dies bedeutet auch eine enorme Reduzierung der Perplexity-API-Kosten pro Anfrage:
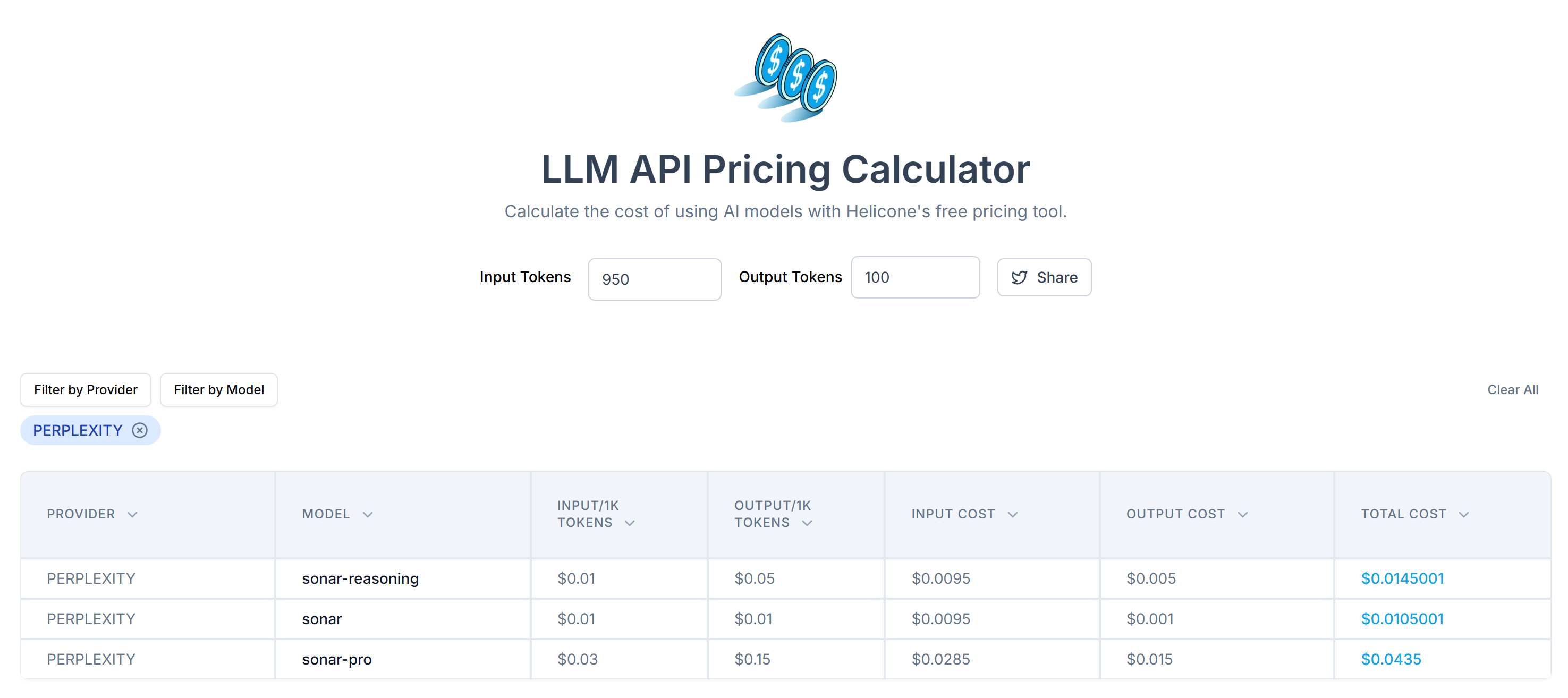
Die Kosten sinken von etwa 0,21 bis 0,63 $ pro Anfrage auf nur 0,014 bis 0,04 $ pro Anfrage!
Schritt Nr. 6: Perplexität für das Parsen von Daten verwenden
Befolgen Sie diese Schritte, um Daten mit Perplexity zu scrapen:
- Schreiben Sie eine gut strukturierte Eingabeaufforderung, um JSON-Daten im gewünschten Format aus der Markdown-Eingabe zu extrahieren
- Senden Sie eine Anfrage an das LLM-Modell von Perplexity mit dem OpenAI Python SDK
- Parsen Sie das zurückgegebene JSON
Implementieren Sie die ersten beiden Schritte mit dem folgenden Code:
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.contentDie Variable prompt weist Perplexity an, strukturierte Daten aus dem Inhalt von main_markdown zu extrahieren. Um die Ergebnisse zu verbessern, empfiehlt es sich, eine klare Aufforderung für das System zu definieren, damit es weiß, wie es sich verhalten und was es tun soll.
Hinweis: Perplexity verwendet immer noch die alte OpenAI Legacy-Syntax für API-Aufrufe. Wenn Sie versuchen, die neuere responses.create() -Syntax zu verwenden, werden Sie den folgenden Fehler erhalten:
httpx.HTTPStatusError: Client error '404 Not Found' for url 'https://api.perplexity.ai/responses'Jetzt sollte product_raw_string JSON-Daten im folgenden Format enthalten:
"```json
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "$69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.nnMint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": ["XS", "S", "M", "L", "XL"],
"colors": ["Blue", "Green", "Red"],
"category": "Hoodies & Sweatshirts"
}
```"Wie Sie sehen können, gibt Perplexity die Daten im Markdown-Format zurück.
Um Schritt 3 des Algorithmus am Anfang dieses Abschnitts zu implementieren, müssen Sie den rohen JSON-Inhalt mithilfe eines Regex extrahieren. Anschließend können Sie die resultierenden JSON-Daten in das Python-Wörterbuch json.loads() parsen:
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Vergessen Sie nicht, json und re aus der Python-Standardbibliothek zu importieren:
import json
import reHinweis: Wenn Sie Perplexity Tier-3 Nutzer sind, können Sie den Schritt des Regex-Parsing überspringen, indem Sie die API so konfigurieren, dass die Daten direkt in einem strukturierten JSON-Format zurückgegeben werden. Weitere Informationen finden Sie in der Perplexity-Anleitung “Structured Outputs”.
Nachdem Sie das Wörterbuch product_data geparst haben, können Sie auf die Felder für die weitere Datenverarbeitung zugreifen. Zum Beispiel:
price = product_data["price"]
price_eur = price * USD_EUR
# ...Fantastisch! Sie haben Perplexity erfolgreich für Web Scraping eingesetzt. Jetzt müssen Sie nur noch die gescrapten Daten nach Bedarf exportieren.
Schritt #7: Exportieren Sie die gescrapten Daten
Derzeit haben Sie die gescrapten Daten in einem Python-Wörterbuch gespeichert. Um sie als JSON-Datei zu speichern, verwenden Sie den folgenden Code:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Dadurch wird eine Datei product.json erzeugt, die die gescrapten Daten im JSON-Format enthält.
Gut gemacht! Ihr mit Perplexity betriebener Web Scraper ist jetzt fertig.
Schritt #8: Alles zusammenfügen
Hier ist der vollständige Code Ihres Scraping-Skripts, das Perplexity zum Parsen der Daten verwendet:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import re
import json
# Your Perplexity API key
PERPLEXITY_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" # replace with your API key
# Conffigure the OpenAI SDK to connect to Perplexity
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)
# Convert the #main HTML to Markdown
main_markdown = markdownify(main_html)
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.content
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Führen Sie das Scraping-Skript mit aus:
python scraper.pyAm Ende der Ausführung wird eine Datei product.json in Ihrem Projektordner erstellt. Wenn Sie sie öffnen, finden Sie strukturierte Daten wie diese:
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.n• Mint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Blue",
"Green",
"Red"
],
"category": "Hoodies & Sweatshirts"
}Et voilà! Das Skript hat unstrukturierte Daten aus einer HTML-Seite in eine ordentlich organisierte JSON-Datei umgewandelt, alles dank Perplexity-gestütztem Web Scraping.
Nächste Schritte
Um Ihren mit Perplexity betriebenen Scraper auf die nächste Stufe zu bringen, sollten Sie diese Verbesserungen in Betracht ziehen:
- Machen Sie es wiederverwendbar: Ändern Sie das Skript so, dass es die Eingabeaufforderung und die Ziel-URL als Befehlszeilenargumente akzeptiert. Dadurch wird der Scraper flexibler und kann für verschiedene Anwendungsfälle und Projekte angepasst werden.
- Sichere API-Anmeldedaten: Speichern Sie Ihren Perplexity-API-Schlüssel in einer .env-Datei und verwenden Sie python-dotenv, um sie sicher zu laden. Dieser Ansatz vermeidet die Hardcodierung sensibler Anmeldedaten im Skript und verbessert die Sicherheit, indem die Geheimnisse privat und von der Codebasis getrennt bleiben.
- Implementieren Sie Web-Crawling: Nutzen Sie die KI-gesteuerten Such- und Crawling-Funktionen von Perplexity für intelligentes, optimiertes Crawling. Konfigurieren Sie den Scraper, um durch verlinkte Seiten zu navigieren und strukturierte Daten aus verschiedenen Quellen zu extrahieren.
Die größte Einschränkung dieser Web-Scraping-Methode durchbrechen
Was ist die größte Einschränkung dieses KI-gestützten Ansatzes für Web Scraping? Die HTTP-Anfrage, die von Anfragen gestellt wird!
Das obige Beispiel hat zwar perfekt funktioniert, aber das liegt daran, dass die Zielsite im Grunde eine Spielwiese für Web-Scraping ist. In Wirklichkeit sind sich Unternehmen und Website-Besitzer über den Wert ihrer Daten im Klaren, selbst wenn diese öffentlich zugänglich sind. Um sie zu schützen, setzen sie Anti-Scraping-Maßnahmen ein, die Ihre automatisierten HTTP-Anfragen leicht blockieren können.
In solchen Fällen schlägt das Skript mit 403 Forbidden-Fehlern fehl, wie:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>
Außerdem funktioniert dieser Ansatz nicht bei dynamischen Webseiten, die auf JavaScript für das Rendering oder den asynchronen Datenabruf angewiesen sind. Daher benötigen Websites nicht einmal fortschrittliche Anti-Bot-Schutzmaßnahmen, um Ihren LLM-gestützten Scraper zu blockieren.
Was ist also die Lösung für all diese Probleme? Eine Web Unlocking API!
Die Web Unlocker API von Bright Data ist ein Scraping-Endpunkt, den Sie von jedem HTTP-Client aus aufrufen können. Er gibt den vollständig freigeschalteten HTML-Code jeder URL zurück, die Sie an ihn übergeben – und umgeht so Anti-Scraping-Blocks für Sie. Unabhängig davon, wie viele Schutzmechanismen eine Zielseite hat, können Sie mit einer einfachen Anfrage an den Web Unlocker den HTML-Code der Seite abrufen.
Folgen Sie zunächst der offiziellen Web Unlocker-Dokumentation, um Ihren API-Schlüssel abzurufen. Ersetzen Sie dann Ihren bestehenden Anforderungscode aus “Schritt #4” durch diese Zeilen:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
Und einfach so – keine Sperren mehr, keine Einschränkungen mehr! Sie können jetzt das Web mit Perplexity scrapen, ohne sich Sorgen zu machen, dass Sie gestoppt werden.
Schlussfolgerung
In diesem Tutorial haben Sie gelernt, wie Sie Perplexity in Kombination mit Requests und anderen Tools verwenden können, um einen KI-gestützten Scraper zu erstellen. Eine der größten Herausforderungen beim Web-Scraping ist das Risiko, blockiert zu werden. Dies wurde mithilfe der Web Unlocker API von Bright Data gelöst.
Wie bereits erwähnt, können Sie durch die Integration von Perplexity mit der Web Unlocker API Daten von jeder beliebigen Website extrahieren, ohne dass Sie eine eigene Parsing-Logik benötigen. Dies ist nur einer der vielen Anwendungsfälle, die von den Produkten und Services von Bright Data unterstützt werden und die es Ihnen ermöglichen, effizientes KI-gesteuertes Web Scraping zu implementieren.
Entdecken Sie unsere anderen Web Scraping Tools:
- Proxy-Dienste: Vier Arten von Proxys zur Umgehung von Standortbeschränkungen, einschließlich Zugang zu mehr als 400M+ monthly privaten IPs.
- Web Scraper APIs: Spezielle Endpunkte zum Extrahieren von frischen, strukturierten Webdaten aus über 100 beliebten Domains.
- SERP-API: API zur Verwaltung der laufenden Freischaltung für SERPs und zur Extraktion einzelner Seiten.
- Scraping-Browser: Ein Cloud-Browser, der mit Puppeteer, Selenium und Playwright kompatibel ist und über integrierte Freischaltfunktionen verfügt.
Melden Sie sich jetzt bei Bright Data an und testen Sie unsere Proxy-Dienste und Scraping-Produkte kostenlos!




