

Die meisten durch Web-Scraping erfassten Daten stammen von dynamischen Websites, wie Amazon und YouTube. Diese Websites bieten auf der Grundlage von Nutzereingaben ein interaktives und reaktionsschnelles Nutzererlebnis. Wenn Sie z. B. auf Ihr YouTube-Konto zugreifen, werden die Videoinhalte, die Ihnen angezeigt werden, auf Ihre Eingaben zugeschnitten. Da die Daten sich infolge der Benutzerinteraktionen ständig ändern, kann das Web Scraping dynamischer Websites komplizierter sein.
Um Daten von dynamischen Websites zu scrapen, müssen Sie fortgeschrittene Techniken verwenden, die die Interaktion eines Benutzers mit der Website simulieren. Auch müssen Sie navigieren und bestimmte Inhalte auswählen, die von JavaScript generiert werden, und mit asynchronen JavaScript- und XML-Anfragen (AJAX) umgehen können.
Mit dieser Anleitung lernen Sie, wie Sie Daten von einer dynamischen Website mithilfe einer Open-Source-Bibliothek für Python namens Selenium scrapen.
Scrapen von Daten aus einer dynamischen Website mit Selenium
Bevor Sie mit dem Scrapen von Daten einer dynamischen Website beginnen, müssen Sie das Python-Paket, das Sie verwenden werden, verstehen: Selenium
Was ist Selenium?
Selenium ist ein Open-Source-Paket für Python und ein Framework für automatisiertes Testen, mit dem Sie verschiedene Operationen oder Aufgaben auf dynamischen Websites ausführen können. Diese Aufgaben umfassen Dinge wie das Öffnen/Schließen von Dialogen, die Suche nach bestimmten Anfragen auf YouTube oder das Ausfüllen von Formularen – all dies mit Ihrem bevorzugten Webbrowser.
Wenn Sie Selenium zusammen mit Python verwenden, können Sie Ihren Webbrowser steuern und automatisch Daten aus dynamischen Websites extrahieren. Mit dem Selenium-Paket für Python müssen Sie gerade einmal ein paar Zeilen Code in Python schreiben.
Nachdem Sie nun wissen, wie Selenium funktioniert, können Sie loslegen.
Ein neues Python-Projekt erstellen
Als Erstes müssen Sie ein neues Python-Projekt erstellen. Legen Sie ein Verzeichnis mit dem Namen data_scraping_project an. Darin werden Sie später alle erfassten Daten und Quellcodedateien speichern. Dieses Verzeichnis hat zwei Unterverzeichnisse:
- strong>
scriptsenthält alle Python-Skripte, die Daten aus der dynamischen Website erfassen und extrahieren. dataist das Unterverzeichnis, in dem alle von einer dynamischen Website extrahierten Daten gespeichert werden.
Python-Pakete installieren
Nachdem Sie das Verzeichnis data_scraping_project angelegt haben, müssen Sie die folgenden Python-Pakete installieren, die Sie beim Scrapen, Erfassen und Speichern von Daten von einer dynamischen Website unterstützen:
- Webdriver Manager
- pandas
Installieren sie das Selenium-Paket für Python, indem sie den folgenden Befehl pip auf Ihrem Gerät ausführen:
pip install selenium
Selenium steuert den von Ihnen gewählten Webbrowser mit dem binären Treiber. Dieses Python-Paket enthält binäre Treiber für die folgenden unterstützten Webbrowser: Chrome, Chromium, Brave, Firefox, IE, Edge und Opera.
Um den webdriver-manager zu installieren, führen Sie den folgenden Befehl pip auf Ihrem Gerät aus:
pip install webdriver-manager
Um pandas zu installieren, führen Sie den folgenden Befehl pip aus:
pip install pandas
Was Sie scrapen werden
In diesem Artikel werden Sie Daten von zwei verschiedenen Sites abrufen: einem YouTube-Kanal namens Programming with Mosh und Hacker News:
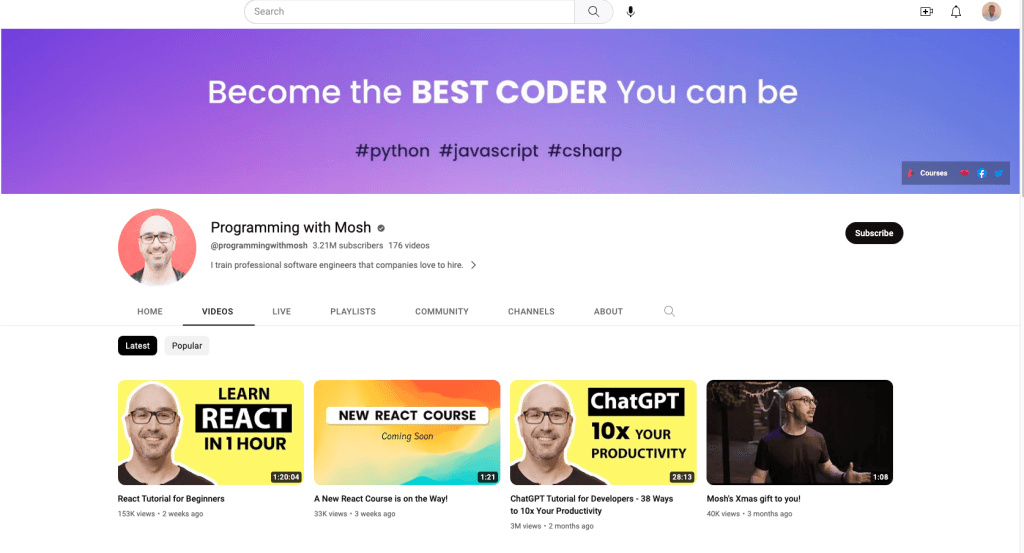
Scrapen Sie die folgenden Informationen vom YouTube-Kanal „Programming with Mosh“:
- Den Titel des Videos.
- Den Link, der auf das Video verweist, oder die URL des Videos.
- Den Link, der auf das Bild verweist, oder die URL des Bildes.
- Die Anzahl der Aufrufe dieses Videos.
- Den Zeitpunkt der Veröffentlichung des Videos.
- Kommentare zu einer bestimmten YouTube-Video-URL.
Auf Hacker News werden Sie die folgenden Daten erfassen:
- Den Titel des Artikels.
- Den Link, der auf den Artikel verweist.

Da Sie nun wissen, was Sie scrapen werden, erstellen Sie ein neues Python-Skript (data_scraping_project/scripts/youtube_videos_list.py).
Python-Pakete importieren
Zunächst müssen Sie die Python-Pakete importieren, die Sie zum Scrapen, Erfassen und Speichern von Daten in einer CSV-Datei verwenden werden:
# import libraries
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd
Webdriver instanziieren
Um Webdriver zu instanziieren, wählen Sie den Browser aus, den Selenium verwenden soll (in diesem Fall Chrome). Installieren Sie dann den binären Treiber.
Chrome verfügt über Entwickler-Tools zur Anzeige des HTML-Codes der Webseite und zur Identifizierung von HTML-Elementen für das Scrapen und Erfassen der Daten. Um den HTML-Code anzuzeigen, klicken Sie in Ihrem Chrome-Webbrowser mit der rechten Maustaste auf eine Website und wählen Sie das Inspect Element.
Um einen binären Treiber für Chrome zu installieren, führen Sie den folgenden Code aus:
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
Der binäre Treiber für Chrome wird auf Ihrem Gerät installiert und instanziiert Webdriver automatisch.
Scrapen von Daten mit Selenium
Um Daten mit Selenium zu scrapen, müssen Sie die YouTube-URL in einer einfachen Python-Variable definieren (ie url). Über diesen Link erfassen Sie alle zuvor erwähnten Daten mit Ausnahme der Kommentare aus einer bestimmten YouTube-URL:
# Define the URL
url = "https://www.youtube.com/@programmingwithmosh/videos"
# load the web page
driver.get(url)
# set maximum time to load the web page in seconds
driver.implicitly_wait(10)
Selenium lädt den YouTube-Link automatisch in den Chrome-Browser. Außerdem wird ein Zeitrahmen festgelegt (z. B. zehn Sekunden), um sicherzustellen, dass die Webseite vollständig geladen ist (einschließlich aller HTML-Elemente). Das unterstützt Sie beim Scrapen von Daten, die mit JavaScript gerendert werden.
Scrapen von Daten mit ID und Tags
Einer der Vorteile von Selenium ist, dass es Daten anhand verschiedener Elemente (einschließlich ID und Tags) von der Website extrahieren kann.
Um die Daten zu scrapen, können Sie beispielsweise entweder das Element ID (d. h post-title) oder Tags (z. B h1 und p) verwenden:
<h1 id ="post-title">Introduction to data scrapping using Python</h1>
<p>You can use selenium python package to collect data from any dynamic website</p>
Wenn Sie hingegen Daten von einem YouTube-Link scrapen möchten, müssen Sie die auf der Webseite angegebene ID verwenden. Öffnen Sie die YouTube URL in Ihrem Webbrowser; klicken Sie dann mit der rechten Maustaste auf Inspect (Untersuchen) und wählen Sie diese Option, um die ID zu identifizieren. Benutzen Sie dann die Maus, um die Seite anzuzeigen und die ID zu identifizieren, die die Liste mit den auf dem Kanal wiedergegebenen Videos enthält:
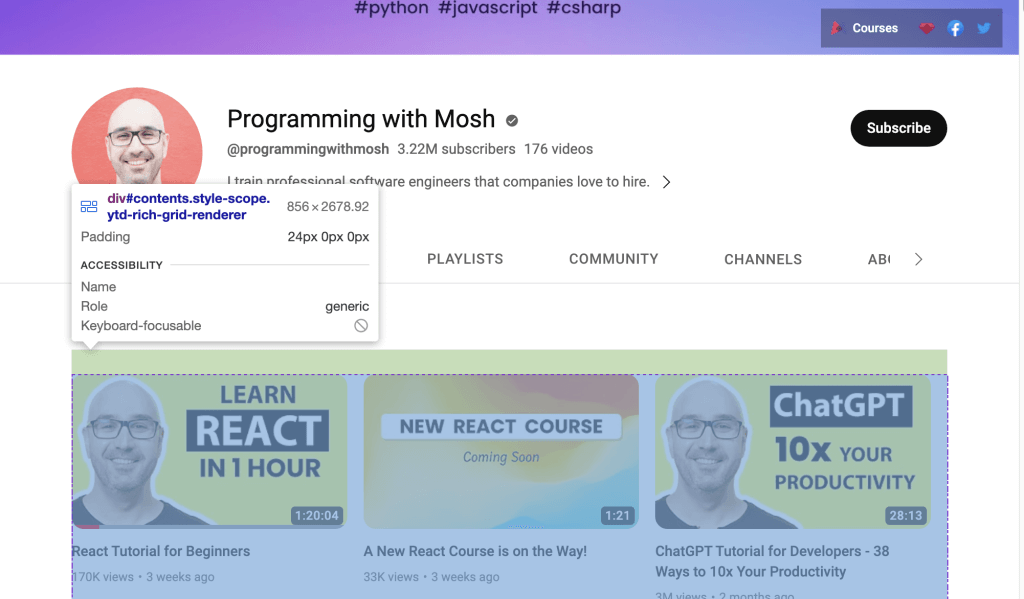
Verwenden Sie Webdriver zum Scrapen der Daten, die sich in der identifizierten ID befinden. Um ein HTML-Element anhand des ID-Attributs zu finden, rufen Sie die Selenium-Methode find_element() auf und übergeben Sie By.ID als erstes Argument und ID als zweites Argument.
Um für die einzelnen Videos den jeweiligen Titel und den Link zum Video zu erfassen, verwenden Sie das ID-Attribut video-title-link. Da Sie mit diesem ID-Attribut mehrere HTML-Elemente erfassen werden, müssen Sie die Methode find_elements() verwenden:
# collect data that are withing the id of contents
contents = driver.find_element(By.ID, "contents")
#1 Get all the by video tite link using id video-title-link
video_elements = contents.find_elements(By.ID, "video-title-link")
#2 collect title and link for each youtube video
titles = []
links = []
for video in video_elements:
#3 Extract the video title
video_title = video.get_attribute("title")
#4 append the video title
titles.append(video_title)
#5 Extract the video link
video_link = video.get_attribute("href")
#6 append the video link
links.append(video_link)
Dieser Code führt die folgenden Aufgaben aus:
- Er erfasst die Daten, die sich in dem ID-Attribut
contentsbefinden. - Er erfasst alle HTML-Elemente, die das ID-Attribut
video-title-linkhaben, aus dem WebElement-Objektcontents. - Er erstellt zwei Listen, in die jeweils die Titel und Links eingefügt werden.
- Er extrahiert den Videotitel mithilfe der Methode
get_attribute()und übergibt dentitle. - Er fügt den Videotitel in die Liste mit den Titeln ein.
- Er extrahiert den Videolink mit der Methode
get_atribute()und übergibthrefals Argument. - Es fügt den Videolink in die List mit den Links ein.
Jetzt befinden sich alle Videotitel und Links in den folgenden beiden Python-Listen: code>titles und links.
Bevor Sie auf den Link zum YouTube-Video klicken, um sich das Video anzusehen, scrapen Sie den Link zu dem Bild, das auf der Webseite verfügbar ist. Um diesen Link, der auf das Bild verweist, zu scrapen, müssen Sie alle HTML-Elemente finden. Rufen Sie zu diesem Zweck die Selenium-Methode find_elements() auf und übergeben Sie By.TAG_NAME als erstes Argument und den Tagnamen als zweites Argument:
#1 Get all the by Tag
img_elements = contents.find_elements(By.TAG_NAME, "img")
#2 collect img link and link for each youtube video
img_links = []
for img in img_elements:
#3 Extract the img link
img_link = img.get_attribute("src")
if img_link:
#4 append the img link
img_links.append(img_link)
Dieser Code erfasst alle HTML-Elemente mit dem Tagnamen img aus dem WebElement-Objekt namens contents. Außerdem erstellt er eine Liste, in die die Links zu den Bildern eingefügt werden, extrahiert diese mit der Methode get_attribute() und übergibt src als Argument. Schließlich fügt er den Link zum Bild in die Datei img_links ein.
Um weitere Daten aus den jeweiligen YouTube-Videos zu scrapen, können Sie auch die ID und den Tagnamen verwenden. Auf der zur YouTube-URL gehörenden Website sollten Sie die Anzahl der Aufrufe und den Zeitpunkt der Veröffentlichung der einzelnen, auf der Website aufgelisteten Videos sehen können. Um diese Daten zu extrahieren, erfassen Sie alle HTML-Elemente, die in der Metadatenzeilen das Attribut ID aufweisen, und dann die Daten der HTML-Elemente mit dem Tagnamen span:
#1 find the element with the specific ID you want to scrape
meta_data_elements = contents.find_elements(By.ID, 'metadata-line')
#2 collect data from span tag
meta_data = []
for element in meta_data_elements:
#3 collect span HTML element
span_tags = element.find_elements(By.TAG_NAME, 'span')
#4 collect span data
span_data = []
for span in span_tags:
#5 extract data for each span HMTL element.
span_data.append(span.text)
#6 append span data to the list
meta_data.append(span_data)
# print out the scraped data.
print(meta_data)
Dieser Codeblock erfasst in dem WebElement-Objekt contents alle HTML-Elemente, die in der Metadatenzeile das Attribut ID haben, und erstellt eine Liste, in die die Daten des Tags span eingefügt werden. Diese Liste enthält die Anzahl der Aufrufe und den Zeitpunkt der Veröffentlichung.
Es werden auch alle HTML-Elemente mit dem Tagnamen span aus dem WebElement-Objekt namens meta_data_elements erfasst, und es wird eine Liste mit diesen span-Daten erstellt. Dann werden die Textdaten aus dem HTML-Element span extrahiert und in die Liste span_data eingefügt. Schließlich werden die Daten aus der Liste span_data in meta_data eingefügt.
Die aus dem HTML-Element span extrahierten Daten sehen folgendermaßen aus:

Als nächstes erstellen Sie zwei Python-Listen und speichern die Anzahl der Aufrufe und den Zeitpunkt der Veröffentlichung getrennt voneinander:
#1 Iterate over the list of lists and collect the first and second item of each sublist
views_list = []
published_list = []
for sublist in meta_data:
#2 append number of views in the views_list
views_list.append(sublist[0])
#3 append time published in the published_list
published_list.append(sublist[1])
Jetzt erstellen Sie zwei Python-Listen, die Daten aus code>meta_data extrahieren. Danach fügen Sie die Anzahl der Aufrufe der jeweiligen Teilliste in view_list ein und den Zeitpunkt der Veröffentlichung der jeweiligen Teilliste in published_list.
Jetzt haben Sie den Titel des Videos, die URL der Website mit dem Video, die URL des Bildes, die Anzahl der Aufrufe und den Zeitpunkt der Veröffentlichung des Videos erfasst. Diese Daten können mit dem Pandas-Python-Paket in einem Pandas DataFrame gespeichert werden. Verwenden Sie den folgenden Code, um die Daten aus den Listen titles, links, img_links, views_list und published_list im Pandas DataFrame zu speichern:
# save in pandas dataFrame
data = pd.DataFrame(
list(zip(titles, links, img_links, views_list, published_list)),
columns=['Title', 'Link', 'Img_Link', 'Views', 'Published']
)
# show the top 10 rows
data.head(10)
# export data into a csv file.
data.to_csv("../data/youtube_data.csv",index=False)
driver.quit()
So sollten die gescrapten Daten im Pandas DataFrame aussehen:

Diese gespeicherten Daten werden von Pandas mit to_csv() in eine CSV-Datei namens youtube_data.csv exportiert.
Jetzt können Sie youtube_videos_list.py ausführen und sicherstellen, dass alles wunschgemäß funktioniert.
Scrapen von Daten mit dem CSS-Selektor
Selenium kann auch Daten extrahieren, die auf bestimmten Mustern in den HTML-Elementen basieren, indem es den CSS selector auf der Website verwendet. Der CSS-Selektor wird angewendet, um bestimmte Elemente anhand ihrer ID, ihres Tagnamens, ihrer Klasse oder anderer Attribute auszuwählen.
In diesem Beispiel enthält die HTML-Website einige div-Elemente, von denen eins den Klassennamen "inline-code" hat:
<html>
<body>
<p>Hello World!</p>
<div>Learn Data Scraping</div>
<div class="inline-code"> data scraping with Python code</div>
<div>Saving</div>
</body>
</html>
Sie können einen CSS-Selektor nutzen, um auf einer Website das HTML-Element zu finden, dessen Tagname div lautet und dessen Klassenname „”inline-code”“ ist. Sie können diesen Ansatz auch anwenden, um Kommentare aus dem Kommentarbereich der YouTube-Videos zu extrahieren.
Verwenden wir nun einen CSS-Selektor, um die Kommentare zu erfassen, die im Zusammenhang mit diesem YouTube-Video gepostet wurden.
Der Kommentarbereich von YouTube steht unter dem folgenden Tag und Klassennamen zur Verfügung:
<ytd-comment-thread-renderer class="style-scope ytd-item-section-renderer">...</tyd-comment-thread-renderer>
Erstellen Sie ein neues Skript (d. h. data_scraping_project/scripts/youtube_video_
comments.py). Importieren Sie alle erforderlichen Pakete wie zuvor, und fügen Sie den folgenden Code hinzu, um den Chrome-Webbrowser automatisch zu starten, die URL des YouTube-Videos zu suchen und dann die Kommentare mithilfe des CSS-Selektors zu scrapen:
#1 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#2 Define the URL
url = "https://www.youtube.com/watch?v=hZB5bHDCmeY"
#3 Load the webpage
driver.get(url)
#4 define the CSS selector
comment_section = 'ytd-comment-thread-renderer.ytd-item-section-renderer’
#5 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, comment_section))
)
except:
driver.quit()
#6. collect HTML elements within the CSS selector
comment_blocks = driver.find_elements(By.CSS_SELECTOR,comment_section)
Um die geposteten Kommentare zu scrapen, instanziiert dieser Code den Chrome-Treiber und definiert den Link, der auf das YouTube-Video verweist. Dann lädt er die Website in den Browser und wartet zehn Sekunden, bis die HTML-Elemente, die dem CSS-Selektor entsprechen, verfügbar sind.
Als nächstes sammelt er alle HTML-Elemente comment mithilfe des CSS-Selektors namensytd-comment-thread-renderer.ytd-item-section-renderer und speichert alle Elemente des Kommentars in dem WebElement-Objekt comment_blocks.
Dann können Sie den Namen eines jedes Autors mit der ID author-text und den Text des Kommentars mit der ID content-text aus den einzelnen Kommentaren in das WebElement-Objekt comment_blocks extrahieren:
#1 specify the id attribute for author and comment
author_id = 'author-text'
comment_id = 'content-text'
#2 Extract the text value for each comment and author in the list
comments = []
authors = []
for comment_element in comment_blocks:
#3 collect author for each comment
author = comment_element.find_element(By.ID, author_id)
#4 append author name
authors.append(author.text)
#5 collect comments
comment = comment_element.find_element(By.ID, comment_id)
#6 append comment text
comments.append(comment.text)
#7 save in pandas dataFrame
comments_df = pd.DataFrame(list(zip(authors, comments)), columns=['Author', 'Comment'])
#8 export data into a CSV file.
comments_df.to_csv("../data/youtube_comments_data.csv",index=False)
driver.quit()
Dieser Code gibt die ID für den Autor und den Kommentar an. Dann werden zwei Python-Listen erstellt, in die jeweils der Name des Autors und der Text des Kommentars eingefügt wird. Danach werden alle HTML-Elemente, die die angegebenen ID-Attribute aus dem WebElement-Objekt haben, erfasst und die Daten werden in die Python-Listen eingefügt.
Schließlich werden die gescrapten Daten in einem Pandas DataFrame gespeichert und in eine CSV-Datei namens youtube_comments_data.csv exportiert.
So sehen die ersten zehn Zeilen mit den Autoren und Kommentaren im Pandas DataFrame aus:

Scrapen von Daten mit dem Klassennamen
Zusätzlich zum Scrapen von Daten mit dem CSS-Selektor können Sie auch Daten, die auf einem bestimmten Klassennamen basieren, extrahieren. Um ein HTML-Element anhand seines Klassennamen-Attributs mit Selenium zu finden, rufen Sie die Methode find_element() auf und übergeben code>By.CLASS_NAME als erstes Argument und den Klassennamen als zweites Argument.
In diesem Abschnitt werden Sie den Klassennamen verwenden, um die Titel der einzelnen Artikel, die auf Hacker News veröffentlicht sind, und die Links, die darauf verweisen, zu erfassen. Auf dieser Website hat das HTML-Element, das die Titel der einzelnen Artikel und die Links dazu enthält, den Klassennamen titleline, wie am Code der Website zu erkennen ist:
<span class="titleline"><a href="https://mullvad.net/en/browser">The Mullvad Browser</a><span class="sitebit comhead"> (<a href="from?site=mullvad.net"><span class="sitestr">mullvad.net</span></a>)</span></span></td></tr><tr><td colspan="2"></td><td class="subtext"><span class="subline">
<span class="score" id="score_35421034">302 points</span> by <a href="user?id=Foxboron" class="hnuser">Foxboron</a> <span class="age" title="2023-04-03T10:11:50"><a href="item?id=35421034">2 hours ago</a></span> <span id="unv_35421034"></span> | <a href="hide?id=35421034&auth=60e6bdf9e482441408eb9ca98f92b13ee2fac24d&goto=news" class="clicky">hide</a> | <a href="item?id=35421034">119 comments</a> </span>
Erstellen Sie ein neues Python-Skript (d. h. data_scraping_project/scripts/hacker_news.py), importieren Sie alle erforderlichen Pakete und fügen Sie den folgenden Python-Code ein, um den Titel des jeweiligen, auf der Website Hacker News veröffentlichten Artikels sowie den Link, der darauf verweist, zu scrapen:
#1 define url
hacker_news_url = 'https://news.ycombinator.com/'
#2 instantiate chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 load the web page
driver.get(hacker_news_url)
#4 wait until element matching the given criteria to be found
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'titleline'))
)
except:
driver.quit()
#5 Extract the text value for each title and link in the list
titles= []
links = []
#6 Find all the articles on the web page
story_elements = driver.find_elements(By.CLASS_NAME, 'titleline')
#7 Extract title and link for each article
for story_element in story_elements:
#8 append title to the titles list
titles.append(story_element.text)
#9 extract the URL of the article
link = story_element.find_element(By.TAG_NAME, "a")
#10 appen link to the links list
links.append(link.get_attribute("href"))
driver.quit()
Dieser Code definiert die URL der Webseite, startet automatisch den Chrome-Webbrowser und sucht dann die URL von Hacker News. Er wartet zehn Sekunden, bis die HTML-Elemente, die dem CLASS NAME (Klassennamen) entsprechen, verfügbar sind.
Danach werden zwei Python-Listen erstellt, in die die Titel der einzelnen Artikel und die Links, die darauf verweisen, eingefügt werden. Mit dem Code werden auch die HTML-Elemente, die den Klassennamen titleline haben, aus dem WebElement-Treiberobjekt erfasst und die Titel und die Links zu den Artikeln, die im WebElement-Objekt story_elements angezeigt werden, extrahiert.
Schließlich fügt der Code die Titel der Artikel in die Titelliste ein und erfasst das HTML-Element mit dem Tagnamen a aus dem Objekt story_element. Er extrahiert den Link mit der Methode get_attribute() und fügt ihn in die Liste mit den Links ein.
Als nächstes verwenden Sie die Methode to_csv() von Pandas, um die gescrapten Daten zu exportieren. Sie exportieren sowohl die Titel als auch die Links in die CSV-Datei code>hacker_news_data.csv und speichern die Daten in folgendem Verzeichnis:
# save in pandas dataFrame
hacker_news = pd.DataFrame(list(zip(titles, links)),columns=['Title', 'Link'])
# export data into a csv file.
hacker_news.to_csv("../data/hacker_news_data.csv",index=False)
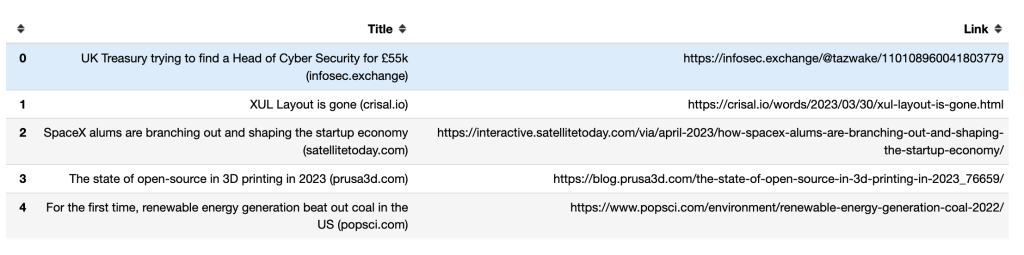
So sehen die in den ersten fünf Zeilen enthaltenen Titel und Links im Pandas DataFrame aus:
Umgang mit unendlichem Scrollen (infinite scrolls)
Wenn Sie zum unteren Ende der Seite scrollen, werden von einigen dynamischen Websites zusätzliche Inhalte geladen. Wenn Sie nicht bis nach unten navigieren, kann Selenium nur die Daten erfassen, die auf Ihrem Bildschirm sichtbar sind.
Um mehr Daten abzurufen, müssen Sie Selenium anweisen, zum Ende der Seite zu scrollen und zu warten, bis die neuen Inhalte geladen sind, und dann automatisch die gewünschten Daten zu scrapen. Das folgende Python-Skript blättert zum Beispiel durch die ersten vierzig Ergebnisse, die im Zusammenhang mit Python-Büchern angezeigt werden, und extrahiert die Links, die darauf verweisen:
#1 import packages
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#2 Instantiate a Chrome webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 Navigate to the webpage
driver.get("https://example.com/results?search_query=python+books")
#4 instantiate a list to keep links
books_list = []
#5 Get the height of the current webpage
last_height = driver.execute_script("return document.body.scrollHeight")
#6 set target count
books_count = 40
#7 Keep scrolling down on the web page
while books_count > len(books_list):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
#8 Wait for the page to load
time.sleep(5)
#9 Calculate the new height of the page
new_height = driver.execute_script("return document.body.scrollHeight")
#10 Check if you have reached the bottom of the page
if new_height == last_height:
break
last_height = new_height
#11 Extract the data
links = driver.find_elements(By.TAG_NAME, "a")
for link in links:
#12 append extracted data
books_list.append(link.get_attribute("href"))
#13 Close the webdriver
driver.quit()
Dieser Code importiert die Python-Pakete, die verwendet werden sollen. Er instanziiert und öffnet auch Chrome. Dann navigiert er zu der Website und erstellt eine Python-Liste, in die die Links zu den einzelnen Suchergebnissen eingefügt werden.
Er ermittelt die Höhe der aktuellen Seite, indem er das Skript return document.body.scrollHeight ausführt, und legt die Anzahl der Links fest, die Sie erfassen möchten. Dann scrollt er so lange nach unten, bis der Wert der Variable book_count größer ist als die Länge der book_list und wartet fünf Sekunden, bis die Seite geladen ist.
Er berechnet die neue Höhe der Website, indem er das Skript return document.body.scrollHeight ausführt und überprüft, ob der untere Rand der Seite erreicht wurde. Wenn dies der Fall ist, wird die Schleife beendet; andernfalls wird last_height aktualisiert und weiter nach unten gescrollt. Schließlich erfasst der Code das HTML-Element mit dem Tagnamen a aus dem WebElement-Objekt, extrahiert den Link und fügt ihn in die Liste mit den Links ein. Nach der Erfassung der Links wird der Webdriver geschlossen.
Bitte beachten Sie Folgendes: Wenn die Webpage über Infinite Scrolls (unendliches Scrollen) verfügt, müssen Sie die Gesamtzahl der Elemente festlegen, die Sie scrapen möchten, damit Ihr Skript an einem bestimmten Punkt stoppt. Wenn Sie das nicht tun, wird Ihr Code weiter ausgeführt.
Web Scraping mit Bright Data
Es ist zwar möglich, Daten mit Open-Source-Scrapern wie Selenium zu scrapen, doch mangelt es diesen oft an Support-Dienstleistungen. Darüber hinaus kann das Verfahren kompliziert und zeitaufwändig sein. Wenn Sie an einer leistungsstarken und zuverlässigen Lösung für das Web Scraping interessiert sind, sollten Sie Bright Data in Betracht ziehen.
Bright Data ist eine Webdaten-Plattform, die es Ihnen ermöglicht, öffentlich zugängliche Webdaten zu scrapen. Sie stellt Ihnen verschiedene Tools und Dienste zur Verfügung, darunter Lösungen für das Web Scraping, Proxys und vorab gesammelte Datensätze. Sie können sogar die gehostete Web Scraper IDE verwenden, um Ihre eigenen Scraper in einer JavaScript-Programmierumgebung zu erstellen.
Die Web Scraper IDE verfügt außerdem über vorgefertigte Scraping-Funktionen und Code-Vorlagen für verschiedene beliebte dynamische Websites, darunter Vorlagen Indeed Scraper und Walmart Scraper. Das bedeutet, dass es einfach ist, die Entwicklungszeit zu beschleunigen und dass eine schnelle Skalierbarkeit garantiert ist.
Bright Data bietet eine Reihe von Optionen zur Formatierung Ihrer Daten, darunter JSON, NDJSON, CSV und Microsoft Excel. Es ist auch in verschiedene Plattformen integriert, sodass Sie Ihre gescrapten Daten problemlos bereitstellen können.
Fazit
Das Scrapen von Daten aus dynamischen Websites ist aufwändig und muss geplant werden. Mit Selenium können Sie automatisch mit jeder dynamischen Website interagieren und Daten von solchen Websites scrapen.
Es ist zwar möglich, Daten mit Selenium zu scrapen, aber das ist zeitaufwändig und kompliziert. Deshalb empfehlen wir Web Scraper IDE zum Scrapen dynamischer Websites. Mit den vorgefertigten Scraping-Funktionen und Code-Vorlagen können Sie sofort mit der Datenextraktion beginnen.




