
In diesem Schritt-für-Schritt-Leitfaden erfahren Sie, wie Sie mit Python Web Scraping auf YouTube durchführen können.
Dieses Tutorial behandelt:
- YouTube-API vs. YouTube-Scraping
- Welche Daten Sie von YouTube scrapen können
- YouTube mit Selenium scrapen
YouTube-API vs. YouTube-Scraping
Die YouTube-Daten-API ist der offizielle Weg, um Daten von der Plattform zu erhalten, einschließlich Informationen über Videos, Wiedergabelisten und Inhaltsersteller. Es gibt jedoch mindestens drei gute Gründe, warum das Scrapen von YouTube besser ist, als sich ausschließlich auf die API zu verlassen:
- Flexibilität und Anpassung: Mit einem YouTube-Spider können Sie den Code so anpassen, dass nur die Daten ausgewählt werden, die Sie benötigen. Dieser Grad der Anpassung hilft Ihnen, genau die Informationen zu sammeln, die Sie für Ihren speziellen Anwendungsfall benötigen. Im Gegensatz dazu haben Sie mit der API nur Zugriff auf vordefinierte Daten.
- Zugriff auf inoffizielle Daten: Die API bietet Zugriff auf bestimmte Datensätze, die von YouTube ausgewählt wurden. Dies bedeutet, dass einige Daten, auf die Sie sich derzeit verlassen, in Zukunft möglicherweise nicht mehr verfügbar sind. Mit Web Scraping können Sie stattdessen alle zusätzlichen Informationen erhalten, die auf der YouTube-Website verfügbar sind, auch wenn sie nicht über die API zugänglich sind.
- Keine Beschränkung: YouTube-APIs unterliegen einer Ratenbegrenzung. Diese Einschränkung bestimmt die Häufigkeit und das Volumen der Anfragen, die Sie in einem bestimmten Zeitrahmen stellen können. Indem Sie direkt mit der Plattform interagieren, können Sie jede Beschränkung umgehen.
Welche Daten Sie von YouTube scrapen können
Wichtigste Datenfelder zum Scrapen von YouTube
- Video-Metadaten:
- Titel
- Beschreibung
- Ansichten
- Likes
- Dauer
- Veröffentlichungsdatum
- Kanal
- Benutzerprofile:
- Benutzername
- Benutzerbeschreibung
- Abonnenten
- Anzahl der Videos
- Playlisten
- Sonstiges:
- Kommentare
- Ähnliche Videos
Wie wir bereits gesehen haben, ist der beste Weg, diese Daten zu erhalten, ein eigener Scraper. Aber welche Programmiersprache soll man wählen?
Python ist dank seiner einfachen Syntax und seines reichhaltigen Ökosystems an Bibliotheken eine der beliebtesten Sprachen für Web Scraping. Seine Vielseitigkeit, Lesbarkeit und die umfangreiche Unterstützung durch die Community machen es zu einer ausgezeichneten Wahl. Lesen Sie unseren ausführlichen Leitfaden, um mit dem Web Scraping mit Python zu beginnen.
YouTube mit Selenium scrapen
In diesem Tutorial erfahren Sie, wie Sie ein YouTube-Web-Scraping-Phyton-Skript erstellen.
Schritt 1: Einrichtung
Vor dem Programmieren müssen Sie die folgenden Voraussetzungen erfüllen:
- Python 3+: Laden Sie das Installationsprogramm herunter, klicken Sie doppelt darauf und folgen Sie den Anweisungen.
- Eine Python-IDE: PyCharm Community Edition oder Visual Studio Code mit der Erweiterung Python sind zwei großartige kostenlose Optionen.
Sie können ein Python-Projekt mit einer virtuellen Umgebung initialisieren, indem Sie die folgenden Befehle verwenden:
mkdir youtube-scraper
cd youtube-scraper
python -m venv env
Das oben erstellte Verzeichnis youtube-scraper stellt den Projektordner für Ihr Python-Skript dar.
Öffnen Sie es in der IDE, erstellen Sie eine scraper.py -Datei und initialisieren Sie sie wie folgt:
print('Hello, World!')
Im Moment ist diese Datei ein Beispielskript, das nur „Hallo, Welt!“ ausgibt, aber sie wird bald die Scraping-Logik enthalten.
Stellen Sie sicher, dass das Skript funktioniert, indem Sie die Ausführen-Taste Ihrer IDE drücken oder mit:
python scraper.py
Im Terminal sollten Sie Folgendes sehen:
Hello, World!
Perfekt, jetzt haben Sie ein Python-Projekt für Ihren YouTube-Scraper.
Schritt 2: Wählen und installieren Sie die Scraping-Bibliotheken.
Wenn Sie einige Zeit auf YouTube verbringen, werden Sie feststellen, dass es sich um eine sehr interaktive Plattform handelt. Auf der Grundlage von Klick- und Scrollvorgängen werden die Daten auf der Website dynamisch geladen und gerendert. Das bedeutet, dass YouTube stark auf JavaScript angewiesen ist.
Das Scraping von YouTube erfordert ein Tool, das Webseiten in einem Browser darstellen kann, genau wie Selenium! Dieses Tool ermöglicht das Scrapen von dynamischen Websites in Python, sodass Sie automatisierte Aufgaben auf Websites in einem Browser durchführen können.
Fügen Sie Selenium und die Webdriver Manager -Pakete zu den Abhängigkeiten Ihres Projekts mit hinzu:
pip install selenium webdriver-manager
Die Installation kann eine Weile dauern, haben Sie also etwas Geduld.
webdriver-manager ist nicht unbedingt erforderlich, erleichtert aber die Verwaltung von Webtreibern in Selenium. Damit müssen Sie Webtreiber nicht mehr manuell herunterladen, installieren und konfigurieren.
Erste Schritte mit Selenium in scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# scraping logic...
# close the browser and free up the resources
driver.quit()
Dieses Skript erstellt eine Instanz von Chrome WebDriver, dem Objekt, über das ein Chrome-Fenster programmatisch gesteuert wird.
Standardmäßig startet Selenium den Browser mit der Benutzeroberfläche. Dies ist zwar für das Debuggen nützlich, da Sie live erleben können, was das automatisierte Skript auf der Seite tut, aber es benötigt eine Menge Ressourcen. Aus diesem Grund sollten Sie Chrome so konfigurieren, dass es im Headless-Modus läuft. Dank der Option --headless=new wird die gesteuerte Browser-Instanz im Hintergrund ohne Benutzeroberfläche gestartet.
Perfekt! Zeit, die Scraping-Logik zu definieren!
Schritt 3: Verbinden Sie sich mit YouTube.
Um Web Scraping auf YouTube durchzuführen, müssen Sie zunächst ein Video auswählen, aus dem Sie Daten extrahieren möchten. In diesem Leitfaden erfahren Sie, wie Sie das neueste Video aus dem YouTube-Kanal von Bright Data scrapen können. Denken Sie daran, dass jedes andere Video ausreicht.
Hier ist die YouTube-Seite, die als Ziel ausgewählt wurde:
https://www.youtube.com/watch?v=kuDuJWvho7Q
Es ist ein Video zum Thema Web Scraping mit dem Titel „Einführung in Bright Data | Scraping Browser“.
Speichern Sie die URL-Zeichenfolge in einer Python-Variablen:
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
Sie können Selenium jetzt anweisen, eine Verbindung zur Zielseite mit Folgendem herzustellen:
driver.get(url)
Die Funktion get() weist den gesteuerten Browser an, die Seite zu besuchen, die durch die als Parameter übergebene URL identifiziert wird.
So sieht dein YouTube-Scraper bisher aus:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up the resources
driver.quit()
Wenn Sie das Skript ausführen, öffnet es das unten stehende Browser-Fenster für den Bruchteil einer Sekunde, bevor es aufgrund der Anweisung quit() geschlossen wird:
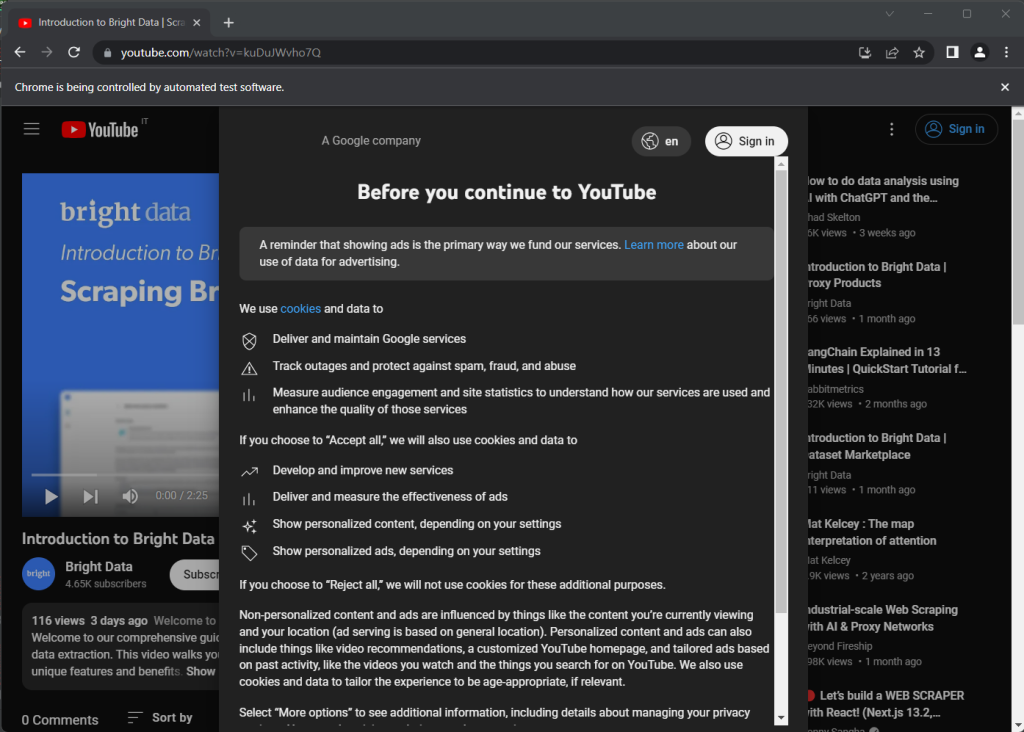
Beachten Sie die Nachricht „Chrome wird von automatisierter Testsoftware gesteuert“, die sicherstellt, dass Selenium in Chrome ordnungsgemäß funktioniert.
Schritt 4: Überprüfen Sie die Zielseite.
Werfen Sie einen Blick auf den vorherigen Screenshot. Wenn Sie YouTube zum ersten Mal öffnen, erscheint ein Zustimmungsdialog. Um auf die Daten auf der Seite zuzugreifen, müssen Sie sie zuerst schließen, indem Sie auf die Schaltfläche „Alle akzeptieren“ klicken. Lernen wir nun, wie das geht!
Um eine neue Browser-Sitzung zu erstellen, öffnen Sie YouTube im Inkognito-Modus. Klicken Sie mit der rechten Maustaste auf das Zustimmungsmodal und wählen Sie „Inspect (Prüfen)“. Dadurch wird der Chrome DevTools-Bereich geöffnet:
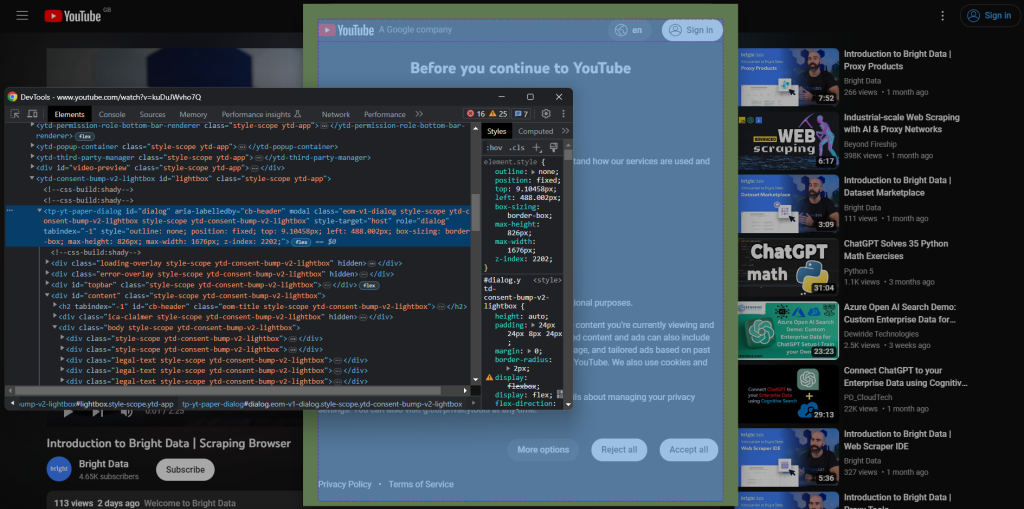
Beachten Sie, dass der Dialog ein id-Attribut hat. Dies ist eine nützliche Information, um eine effektive Selektorstrategie in Selenium zu definieren.
Prüfen Sie in ähnlicher Weise die Schaltfläche „Alle akzeptieren“:
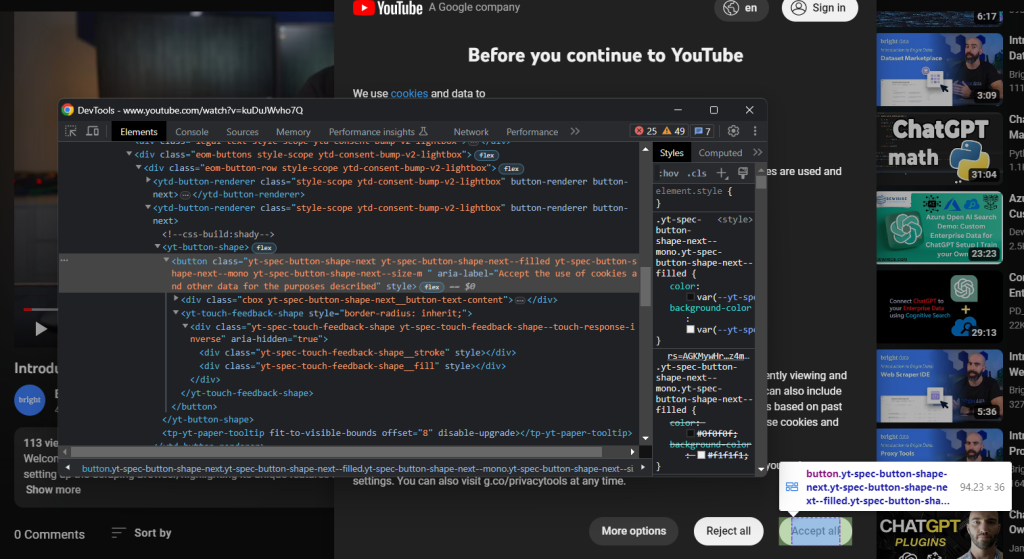
Es ist die zweite Schaltfläche, die vom CSS-Selektor unten identifiziert wird:
.eom-buttons button.yt-spec-button-shape-next
Fügen Sie alles zusammen und verwenden Sie diese Codezeilen, um mit der YouTube-Cookie-Richtlinie in Selenium umzugehen:
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
Das Zustimmungsmodal wird dynamisch geladen und es kann einige Zeit dauern, bis es angezeigt wird. Aus diesem Grund müssen Sie WebDriverWait verwenden, um auf das Eintreten der erwarteten Bedingung zu warten. Wenn im angegebenen Timeout nichts passiert, wird eine TimeoutExceptionausgelöst. YouTube ist ziemlich langsam, daher wird empfohlen, Timeouts von mehr als 10 Sekunden zu verwenden.
Da YouTube seine Richtlinien ständig ändert, kann es sein, dass der Dialog in bestimmten Ländern oder Situationen nicht angezeigt wird. Behandeln Sie die Ausnahme daher mit einem try-catch , um zu verhindern, dass das Skript fehlschlägt, falls das Modal nicht vorhanden ist.
Damit das Skript funktioniert, müssen Sie die folgenden Importe hinzufügen:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
Nach dem Drücken der Schaltfläche „Alle akzeptieren“ benötigt YouTube eine Weile, um die Seite dynamisch erneut zu rendern:
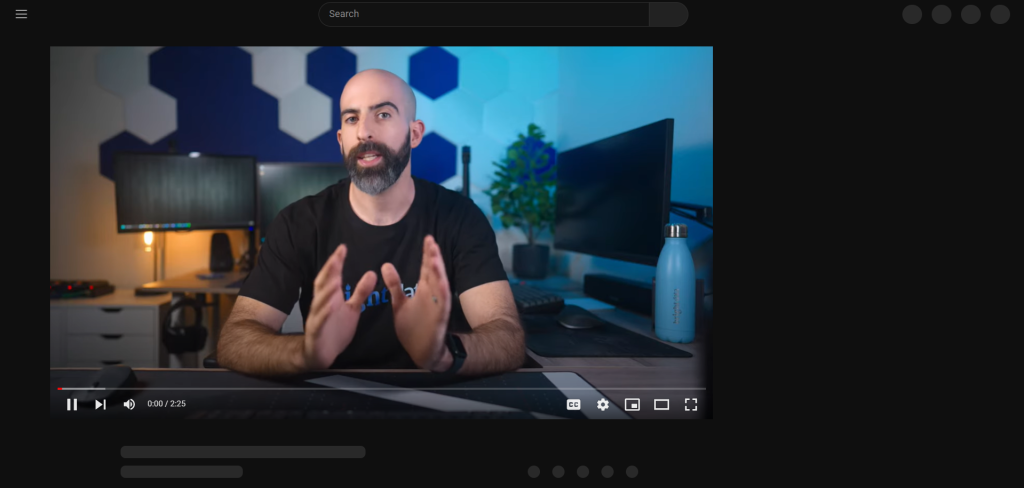
Während dieser Zeit können Sie nicht mit der Seite in Selenium interagieren. Wenn Sie versuchen, ein HTML-Element auszuwählen, erhalten Sie den Fehler „Veraltete Elementreferenz“. Das passiert, weil sich das DOM in diesem Prozess stark ändert.
Wie Sie sehen können, enthält das Titelelement eine graue Linie. Wenn Sie dieses Element untersuchen, werden Sie Folgendes sehen:
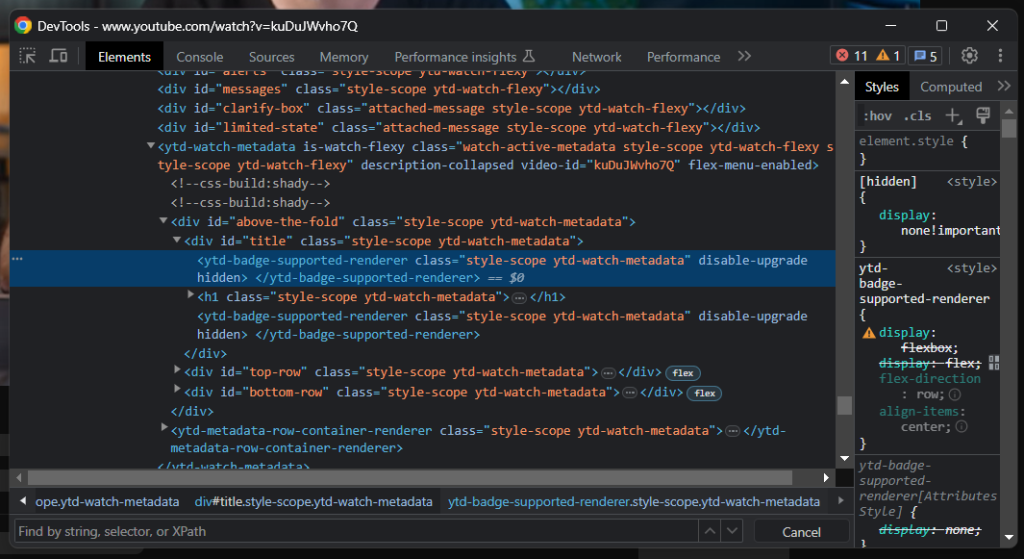
Ein guter Indikator dafür, wann die Seite geladen wurde, ist zu warten, bis das Titelelement sichtbar ist:
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
Sie sind bereit, YouTube in Python zu scrapen. Analysieren Sie die Zielseite in den DevTools weiter und machen Sie sich mit ihrem DOM vertraut.
Schritt 5: Extrahieren Sie YouTube-Daten.
Zunächst benötigen Sie eine Datenstruktur, in der die gescrapten Informationen gespeichert werden sollen. Initialisieren Sie ein Python-Dictionary mit:
video = {}
Wie Sie im vorigen Schritt bemerkt haben sollten, befinden sich einige der interessantesten Informationen in dem Bereich unter dem Videoplayer:

Mit dem h1.ytd-watch-metadata–CSS-Selektor können Sie den Videotitel abrufen:
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
Direkt unter dem Titel befindet sich das HTML-Element, das die Kanalinformationen enthält:
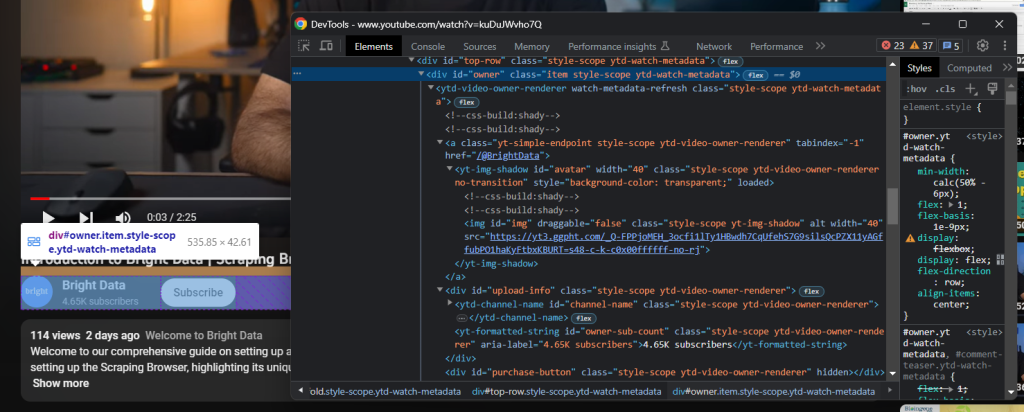
Dies wird durch das Attribut „owner“ id identifiziert, und Sie können alle Daten mit Folgendem daraus abrufen:
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
Noch weiter unten ist die Videobeschreibung. Diese Komponente hat ein kompliziertes Verhalten, da sie unterschiedliche Daten anzeigt, je nachdem, ob sie geschlossen oder geöffnet ist.

Klicken Sie darauf, um Zugriff auf die vollständigen Daten zu erhalten:
driver.find_element(By.ID, 'description-inline-expander').click()
Sie sollten Zugriff auf das erweiterte Beschreibungsinfoelement haben:
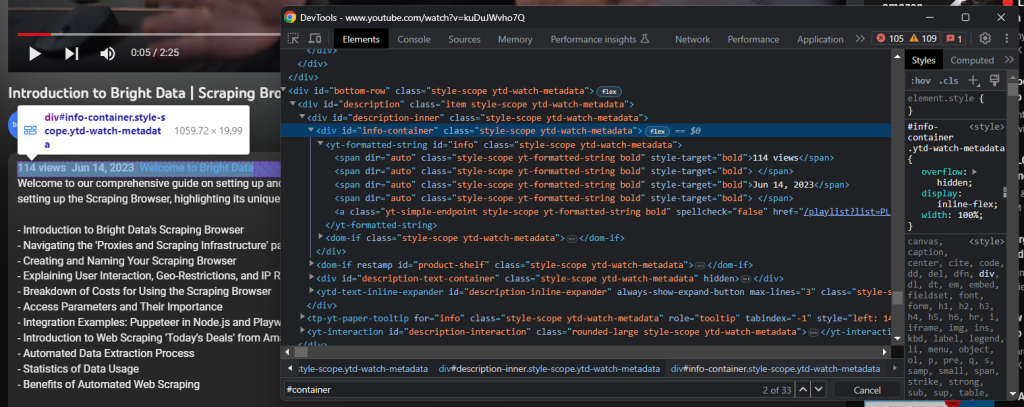
Rufen Sie die Videoaufrufe und das Veröffentlichungsdatum mit Folgendem ab:
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
Die mit dem Video verknüpfte Textbeschreibung ist in dem folgenden untergeordneten Element enthalten:
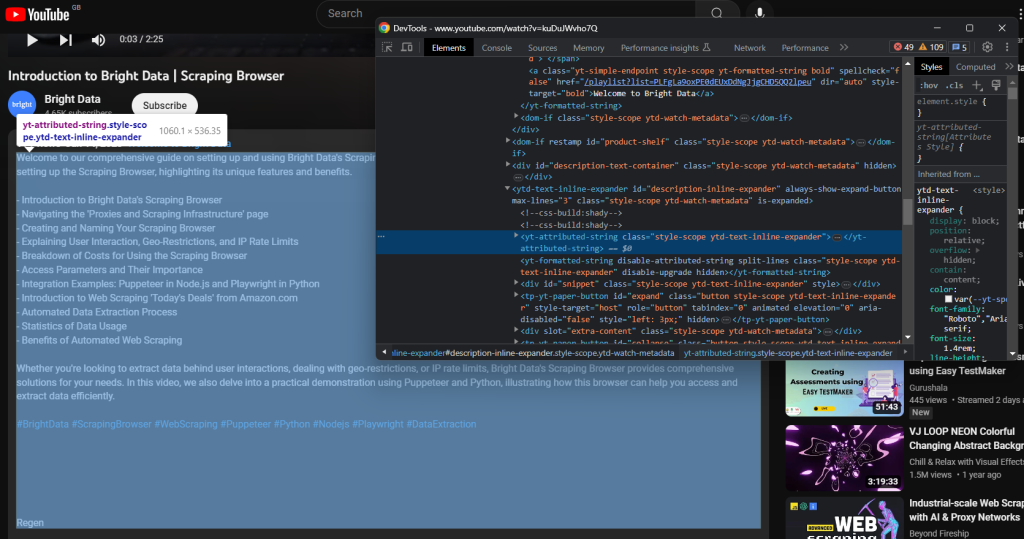
Scrapen Sie es mit:
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
Prüfen Sie als Nächstes den Like-Button:
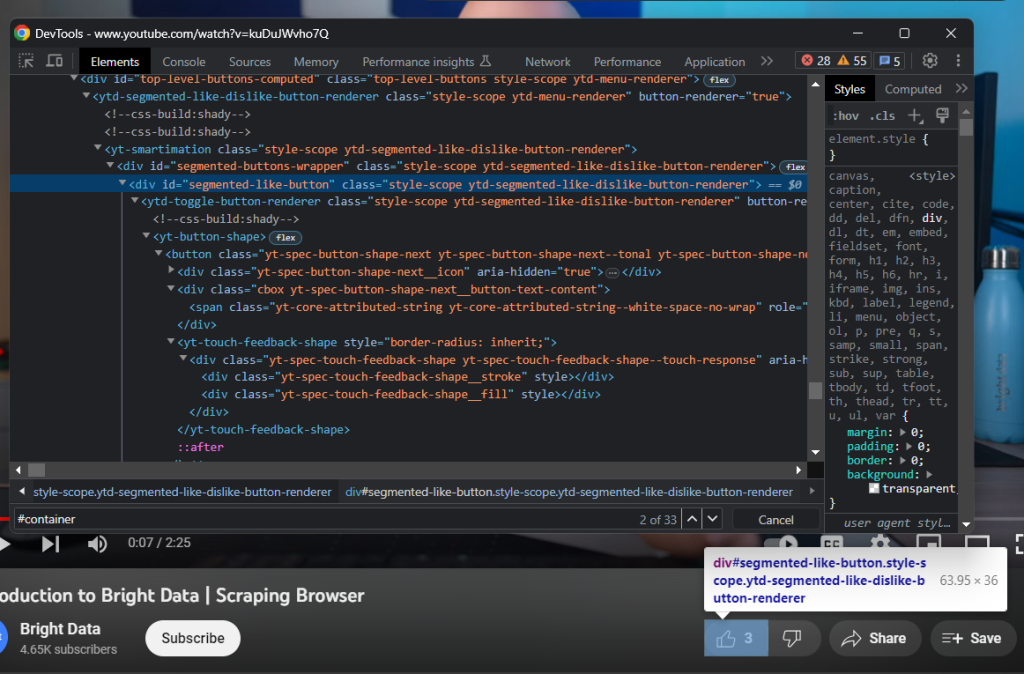
Sammeln Sie die Anzahl der Likes mit:
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
Vergessen Sie schließlich nicht, die gescrapten Daten in das Video-Dictionary einzufügen:
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
Wunderbar! Sie haben gerade Web Scraping in Python durchgeführt!
Schritt 6: Exportieren Sie die gescrapten Daten nach JSON.
Die Daten von Interesse sind jetzt in einem Python-Dictionary gespeichert, was nicht das beste Format für die gemeinsame Nutzung mit anderen Teams ist. Sie können die gesammelten Informationen in JSON konvertieren und in eine Datei mit nur zwei Codezeilen exportieren:
with open('video.json', 'w') as file:
json.dump(video, file)
Dieses Snippet initialisiert eine video.json -Datei mit open(). Dann verwendet es json.dump(), um die JSON-Repräsentation des video-Dictionary in die Ausgabedatei zu schreiben. Werfen Sie einen Blick auf unseren Artikel, um mehr darüber zu erfahren, wie man JSON in Python parst.
Sie benötigen keine zusätzliche Abhängigkeit, um das Ziel zu erreichen. Sie benötigen lediglich das Python Standard Library json-Paket, das Sie mit Folgendem importieren können:
import json
Fantastisch! Sie haben mit Rohdaten begonnen, die auf einer dynamischen HTML-Seite enthalten sind, und verfügen jetzt über halbstrukturierte JSON-Daten. Es ist Zeit, den gesamten YouTube-Scraper zu sehen.
Schritt 7: Fügen Sie alles zusammen.
Hier ist das komplette scraper.py-Skript:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import json
# enable the headless mode
options = Options()
# options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
# initialize the dictionary that will contain
# the data scraped from the YouTube page
video = {}
# scraping logic
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
# click the description section to expand it
driver.find_element(By.ID, 'description-inline-expander').click()
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
# close the browser and free up the resources
driver.quit()
# export the scraped data to a JSON file
with open('video.json', 'w') as file:
json.dump(video, file, indent=4)
Sie können einen Web Scraper erstellen, um Daten aus YouTube-Videos mit nur etwa 100 Zeilen Code zu erhalten!
Starten Sie das Skript, und die folgende video.json -Datei wird im Stammordner Ihres Projekts angezeigt:
{
"url": "https://www.youtube.com/watch?v=kuDuJWvho7Q",
"title": "Introduction to Bright Data | Scraping Browser",
"channel": {
"url": "https://www.youtube.com/@BrightData",
"name": "Bright Data",
"image": "https://yt3.ggpht.com/_Q-FPPjoMEH_3ocfi1lTy1HBwdh7CqUfehS7G9silsQcPZX11yAGffubPO1haKyFtbxKBURT=s48-c-k-c0x00ffffff-no-rj",
"subs": "4.65K"
},
"views": "116",
"publication_date": "Jun 14, 2023",
"description": "Welcome to our comprehensive guide on setting up and using Bright Data's Scraping Browser for efficient web data extraction. This video walks you through the process of setting up the Scraping Browser, highlighting its unique features and benefits.nn- Introduction to Bright Data's Scraping Browsern- Navigating the 'Proxies and Scraping Infrastructure' pagen- Creating and Naming Your Scraping Browsern- Explaining User Interaction, Geo-Restrictions, and IP Rate Limitsn- Breakdown of Costs for Using the Scraping Browsern- Access Parameters and Their Importancen- Integration Examples: Puppeteer in Node.js and Playwright in Pythonn- Introduction to Web Scraping 'Today's Deals' from Amazon.comn- Automated Data Extraction Processn- Statistics of Data Usagen- Benefits of Automated Web ScrapingnnWhether you're looking to extract data behind user interactions, dealing with geo-restrictions, or IP rate limits, Bright Data's Scraping Browser provides comprehensive solutions for your needs. In this video, we also delve into a practical demonstration using Puppeteer and Python, illustrating how this browser can help you access and extract data efficiently.nn#BrightData #ScrapingBrowser #WebScraping #Puppeteer #Python #Nodejs #Playwright #DataExtraction",
"likes": "3"
}
Herzlichen Glückwunsch! Sie haben gerade gelernt, wie man YouTube in Python scrapt!
Fazit
Durch diesen Leitfaden haben Sie erfahren, warum das Scrapen von YouTube besser ist als die Nutzung der Daten-APIs. Insbesondere haben Sie ein Schritt-für-Schritt-Tutorial gesehen, wie man einen Python-Scraper erstellt, der YouTube-Videodaten abrufen kann. Wie hier bewiesen, ist es nicht komplex und benötigt nur wenige Codezeilen.
Gleichzeitig ist YouTube eine dynamische Plattform, die sich ständig weiterentwickelt, sodass der hier entwickelte Scraper möglicherweise nicht ewig funktioniert. Es ist zeitaufwändig und mühsam, ihn zu pflegen, damit er mit Änderungen auf der Zielseite Schritt halten kann. Aus diesem Grund haben wir YouTube-Scraperentwickelt, eine zuverlässige und benutzerfreundliche Lösung, mit der Sie alle gewünschten Daten problemlos abrufen können!
Übersehen Sie auch nicht die Google-Anti-Bot-Systeme. Selenium ist ein großartiges Tool, kann aber gegen solch fortschrittliche Technologien nichts ausrichten. Wenn Google beschließt, YouTube vor Bots zu schützen, werden die meisten automatisierten Skripte abgeschnitten. In diesem Fall benötigen Sie ein Tool, das JavaScript rendern kann und automatisch Fingerprinting, CAPTCHAs und Anti-Scraping für Sie übernimmt. Nun, es existiert und heißt Scraping Browser!
Sie möchten sich überhaupt nicht mit YouTube Web Scraping beschäftigen, sind aber an Elementdaten interessiert? Fordern Sie einen YouTube-Datensatz an.




