

Proxys sind IP-Adressen, die aus einem Proxy-Servers stammen und sich in Ihrem Namen mit dem Internet verbinden. Wenn Sie sich über einen Proxy mit dem Internet verbinden, werden Ihre Anfragen nicht direkt an die von Ihnen besuchte Website übermittelt, sondern über den Proxy-Server weitergeleitet. Die Verwendung eines Proxy-Servers ist eine gute Möglichkeit, Ihre Privatsphäre im Internet zu schützen und Ihre Sicherheit zu verbessern:
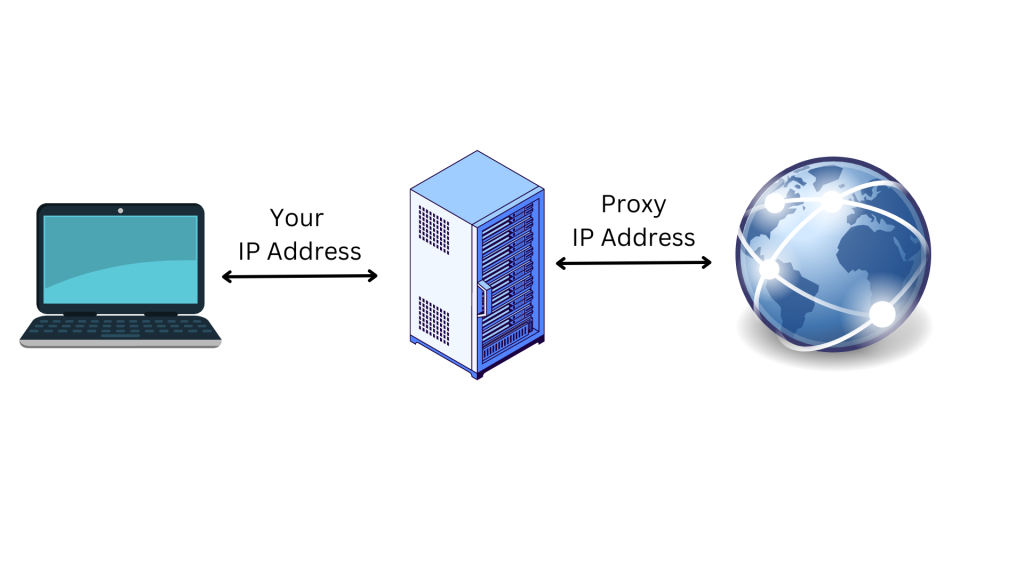
Der Proxy-Server fungiert als vermittelnder Computer, d. h. Ihre ursprüngliche IP-Adresse und Ihr Standort bleiben der Website verborgen. Dies schützt Sie vor Online-Tracking, vor gezielter Werbung und davor, von der Website, auf die Sie zugreifen möchten, blockiert zu werden. Da Proxys Ihre Daten verschlüsseln, während sie zwischen Ihrem Gerät und dem Proxy-Server übertragen werden, bieten Proxys auch eine zusätzliche Sicherheitsebene.
In diesem Artikel erfahren Sie mehr über Proxys und wie Sie sie zusammen mit Python Requests verwenden können. Sie werden auch erfahren, warum dies bei der Arbeit an einem Web-Scraping-Projekt hilfreich sein kann.
Warum Sie beim Web Scraping Proxys benötigen
Web Scraping ist ein automatisiertes Verfahren zum Extrahieren von Daten aus Websites für verschiedene Zwecke, z. B. für die Datenaggregation, Marktforschung und Datenanalyse. Viele dieser Websites haben jedoch Beschränkungen, die den Zugriff auf die gewünschten Informationen erschweren.
Zum Glück können Sie mithilfe von Proxys IP- und standortbezogene Beschränkungen umgehen. In einigen Fällen bieten Websites beispielsweise je nach Standort – einem Land oder Staat – unterschiedliche Informationen an. Wenn Sie sich nicht an einem bestimmten Ort befinden, können Sie ohne einen Proxy, der die IP-Adresse umgehen und Ihren Standort ändern kann, nicht auf die gesuchten Informationen zugreifen.
Darüber hinaus blockieren die meisten Websites die IP-Adressen von Geräten, die an Web-Scraping-Aktivitäten beteiligt sind. In einer solchen Situation können Sie einen Proxy einrichten, um Ihren Standort und ihre IP-Adresse zu verbergen, sodass es für die Website schwieriger wird, Sie zu identifizieren und zu blockieren.
Sie können auch mehrere Proxys gleichzeitig verwenden, um die Web-Scraping-Aktivitäten auf verschiedene IP-Adressen zu verteilen und das Web Scraping zu beschleunigen, da der Scraper so mehrere Anfragen gleichzeitig senden kann.
Da Sie nun wissen, wie Proxys Sie bei Web-Scraping-Projekten unterstützen können, erfahren Sie als Nächstes, wie Sie einen Proxy mit dem Paket Python Requests in Ihrem Projekt implementieren können.
So verwenden Sie einen Proxy bei einer Anfrage in Python
Um einen Proxy für eine Anfrage in Python zu verwenden, müssen Sie ein neues Python-Projekt auf Ihrem Computer einrichten, um die Python-Skripte für das Web Scraping zu schreiben und auszuführen. Erstellen Sie ein Verzeichnis (z. B. web_scrape_project), in dem Sie Ihre Quellcode-Dateien speichern werden.
Alle Codes, die Sie für die Arbeit mit dieser Anleitung benötigen, finden Sie in diesem GitHub Repositorium.
Pakete installieren
Nachdem Sie Ihr Verzeichnis erstellt haben, müssen Sie die folgenden Python-Pakete installieren, um Anfragen an die Website zu senden und die Links zu erfassen:
- Beautiful Soup
Bestandteile einer Proxy-IP-Adresse
Bevor Sie einen Proxy verwenden, sollten Sie seine Bestandteile verstehen. Im Folgenden beschreiben wir die drei Hauptkomponenten eines Proxyservers:
- Das Protokoll (engl. protocol) zeigt die Art der Inhalte an, auf die Sie im Internet zugreifen können. Die gängigsten Protokolle sind HTTP und HTTPS.
- Die Adresse (engl. address) zeigt an, wo sich der Proxyserver befindet. Die Adresse kann eine IP sein(z. B.
192.167.0.1) oder ein DNS-Hostname(z. B.proxyprovider.com). - Port wird verwendet, um den Datenverkehr an den richtigen Serverprozess zu leiten, wenn mehrere Dienste auf einem einzigen Rechner laufen (z. B. Portnummer
2000).
Mit allen drei Komponenten würde eine Proxy-IP-Adresse wie folgt aussehen: 192.167.0.1:2000 oder proxyprovider.com:2000.
Wie Sie Proxys direkt in Requests einrichten
Es gibt mehrere Möglichkeiten, Proxys für Anfragen in Python einzurichten. In diesem Artikel werden Sie drei verschiedene Szenarien kennenlernen. Im ersten Beispiel lernen Sie, wie Sie Proxys direkt im Modul „Requests“ einrichten.
Zu Beginn müssen Sie die Pakete Requests und Beautiful Soup in Ihre Python-Datei für das Web Scraping importieren. Legen Sie dann ein Verzeichnis namens Proxys an, das Informationen des Proxy-Servers enthält, um Ihre IP-Adresse beim Scrapen der Website zu verbergen. An dieser Stelle müssen Sie sowohl die HTTP- als auch die HTTPS-Verbindungen zur Proxy-URL festlegen.
Sie müssen auch die Python-Variable definieren, um die URL der Website festzulegen, von der Sie die Daten scrapen möchten. Im Rahmen dieser Anleitung lautet die URL https://brightdata.com/
Als Nächstes senden Sie mit der Methode request.get() eine GET-Anfrage an die Website. Die Methode benötigt zwei Argumente: die URL der Website und die Proxys. Dann wird die Antwort der Website in der Variable response gespeichert.
Um die Links zu erfassen und den HTML-Inhalt der Website zu parsen, verwenden Sie das Paket Beautiful Soup, indem Sie response.content und html.parser als Argumente an die Methode BeautifulSoup() übergeben.
Verwenden Sie dann die Methode find_all() mit a als Argument, um alle auf der Website vorhandenen Links zu finden. Schließlich extrahieren Sie das Attribut href der einzelnen Links mit der Methode get().
Nachfolgend finden Sie den vollständigen Quellcode, um Proxys direkt in Requests zu setzen:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define proxies to use.
proxies = {
'http': 'http://proxyprovider.com:2000',
'https': 'http://proxyprovider.com:2000',
}
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
Wenn Sie diesen Codeblock ausführen, sendet er unter Verwendung der Proxy-IP-Adresse eine Anfrage an die festgelegte Website und gibt dann die Antwort zurück, die alle Links zu dieser Website enthält:
Einstellen von Proxies über Umgebungsvariablen
Manchmal müssen Sie denselben Proxy für alle Ihre Anfragen, die Sie an verschiedene Websites senden, verwenden. In diesem Fall ist es sinnvoll, Umgebungsvariablen für Ihren Proxy festzulegen.
Um die Umgebungsvariablen für den Proxy verfügbar zu machen, wenn Sie Skripte in der Shell ausführen, führen Sie den folgenden Befehl in Ihrem Computer aus:
export HTTP_PROXY='http://proxyprovider.com:2000'
export HTTPS_PROXY='https://proxyprovider.com:2000'
Hier legt die Variabel HTTP_PROXY den Proxy-Server für HTTP-Anfragen fest, und die Variabel HTTPS_PROXY legt den Proxyserver für HTTPS-Anfragen fest.
Jetzt besteht Ihr Python-Code aus ein paar Zeilen Code und verwendet die Umgebungsvariablen, wenn Sie eine Anfrage an die Website stellen:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
Wie Sie Proxys mit einer benutzerdefinierten Methode und einer Reihe von Proxys rotieren lassen
Die Rotation der Proxys ist von entscheidender Bedeutung, da Websites oft den Zugang für Bots und Scraper blockieren oder einschränken, wenn sie eine große Anzahl von Anfragen von derselben IP-Adresse erhalten. Wenn dies geschieht, können Websites böswillige Scraping-Aktivitäten vermuten und folglich Maßnahmen ergreifen, um den Zugang zu blockieren oder einzuschränken.
Wenn Sie durch verschiedene Proxy-IP-Adressen rotieren, können Sie vermeiden, entdeckt zu werden, da Sie als unterschiedliche organische Benutzer auftreten und so die meisten Anti-Scraping-Maßnahmen der Website umgehen.
Um Proxys rotieren zu lassen, müssen Sie einige Python-Bibliotheken importieren: Requests, Beautiful Soup, und Random.
Erstellen Sie dann eine Proxy-Liste, die während des Rotationsprozesses verwendet werden sollen. Diese Liste muss die URLs der Proxyserver in folgendem Format enthalten: http://proxyserver.com:port:
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
Dann erstellen Sie die benutzerdefiniert Methode namens get_proxy(). Diese Methode wählt nach dem Zufallsprinzip einen Proxy aus der Proxy-Liste aus, indem sie mithilfe der Methode random.choice() einen Proxy aus der Proxy-Liste auswählt und diesen im Wörterbuchformat (sowohl HTTP- als auch HTTPS-Schlüssel) zurückgibt. Verwenden Sie diese Methode immer dann, wenn Sie eine neue Anfrage senden:
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
Sobald Sie die Methode get_proxy() erstellt haben, erstellen Sie eine Schleife, die eine bestimmte Anzahl von GET-Anfragen unter Verwendung der rotierenden Proxys sendet. Bei jeder Anfrage verwendet die Methode get() einen zufällig ausgewählten Proxy, der mit der Methode get_proxy() festgelegt wird.
Dann erfassen Sie die Links aus dem HTML-Inhalt der Website mithilfe des Pakets Beautiful Soup, wie im ersten Beispiel erläutert.
Schließlich fängt der Python-Code alle Ausnahmen ab, die während des Anfrageprozesses auftreten, und gibt die Fehlermeldung auf der Konsole aus.
Hier finden Sie den vollständigen Quellcode für dieses Beispiel:
# import packages
import requests
from bs4 import BeautifulSoup
import random
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
# Send requests using rotated proxies
for i in range(10):
# Set the URL to scrape
url = 'https://brightdata.com/'
try:
# Send a GET request with a randomly chosen proxy
response = requests.get(url, proxies=get_proxy())
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
except requests.exceptions.RequestException as e:
# Handle any exceptions that may occur during the request
print(e)
Verwendung des Proxyservices von Bright Data in Python
Wenn Sie auf der Suche nach einem zuverlässigen, schnellen und stabilen Proxy für Ihr Web Scraping sind, dann sind Sie bei Bright Data genau richtig, einer Webdatenplattform, die verschiedene Arten von Proxys für eine breite Palette von Anwendungsfällen bietet.
Bright Data verfügt über ein großes Netzwerk mit mehr als 400M+ monthly Residential IPs und mehr als 770 000 Datacenter-Proxys, das das Unternehmen dabei unterstützt, zuverlässige und schnelle Proxy-Lösungen anzubieten. Bright Data`s Proxy-Angebote sollen Ihnen helfen, die Herausforderungen des Web Scraping, der Anzeigenüberprüfung und anderer Online-Aktivitäten, die eine anonyme und effiziente Webdatenerfassung erfordern, zu meistern.
Die Einbindung der Proxys von Bright Data in Ihre Python-Anfragen ist ganz einfach. Verwenden Sie zum Beispiel die Datacenter Proxys, um eine Anfrage an die in dem vorhergehenden Beispiel verwendete URL zu senden.
Wenn Sie noch kein Konto haben, melden Sie sich für eine kostenlose Testversion von Bright Data an und fügen Sie dann Ihre Daten hinzu, um Ihr Konto auf der Plattform zu registrieren.
Führen Sie anschließend die folgenden Schritte aus, um Ihren ersten Proxy zu erstellen:
Klicken Sie auf der Startseite auf Proxy, um die verschiedenen von Bright Data angebotenen Proxy-Arten zu sehen:
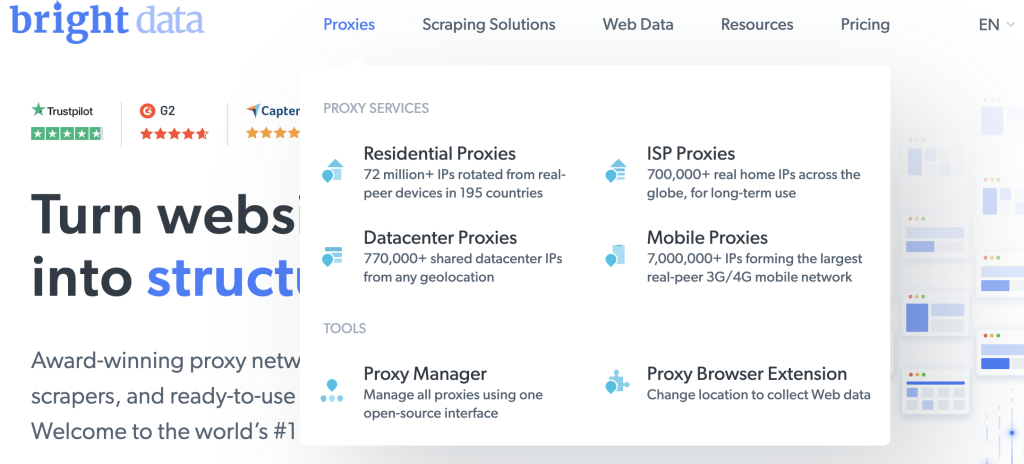
Wählen Sie Datacenter Proxys, um einen neuen Proxy zu erstellen, fügen Sie auf der folgenden Seite Ihre Angaben hinzu und speichern Sie diese:

Sobald Ihr Proxy erstellt ist, können Sie die wichtigen Parameter (d. h. Host, Port, Benutzername und Passwort) einsehen, um darauf zuzugreifen und sie zu benutzen:
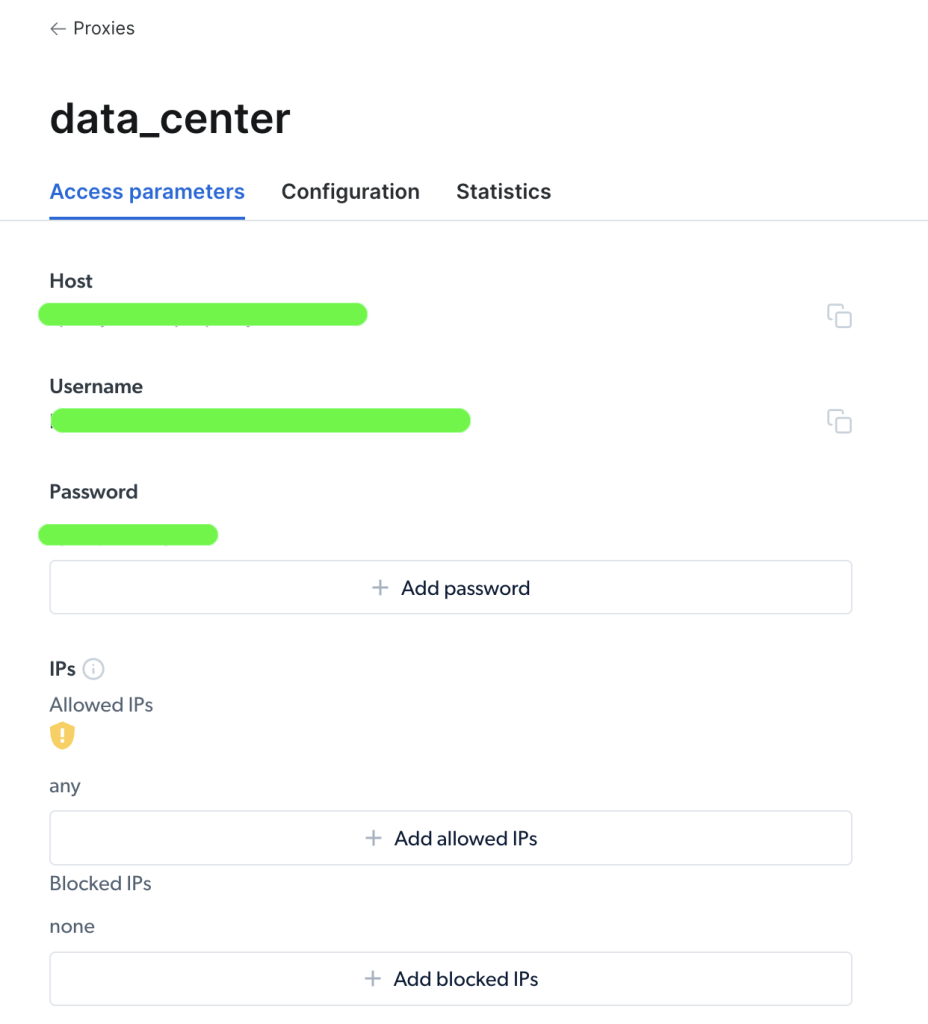
Sobald Sie auf Ihren Proxy zugegriffen haben, können Sie die Informationender Parameter verwenden, um Ihre Proxy-URL zu konfigurieren und eine Anfrage mit dem Paket Python Requests zu senden. Das Format der Proxy-URL ist username-(session-id)-password@host:port.
Hinweis: Die
Session-ID(Sitzungskennung) ist eine Zufallszahl, die mithilfe des Python-Pakets namensRandomerstellt wurde.
Das folgende Codebeispiel zeigt, wie der Proxy von Bright Data für eine Anfrage in Python festgelegt werden kann:
import requests
from bs4 import BeautifulSoup
import random
# Define parameters provided by Brightdata
host = 'zproxy.lum-superproxy.io'
port = 22225
username = 'username'
password = 'password'
session_id = random.random()
# format your proxy
proxy_url = ('http://{}-session-{}:{}@{}:{}'.format(username, session_id,
password, host, port))
# define your proxies in dictionary
proxies = {'http': proxy_url, 'https': proxy_url}
# Send a GET request to the website
url = "https://brightdata.com/"
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website
links = soup.find_all("a")
# Print all the links
for link in links:
print(link.get("href"))
Importieren Sie die Pakete und definieren Sie die Variablen Proxy-Host, Port, Benutzername, Passwort und session_id. Dann erstellen Sie mit den Schlüsseln http und https sowie den Proxy-Zugangsdaten das Wörterbuch Proxys. Schließlich übergeben Sie die Parameter der Proxys an die Funktion requests.get(), um die HTTP-Anfrage zu senden und die Links der URL zu erfassen.
Das war’s schon! Sie haben soeben eine erfolgreiche Anfrage über den Proxyservice von Bright Data gesendet.
Fazit
In diesem Artikel haben Sie erfahren, warum Sie Proxys brauchen und wie Sie sie verwenden können, um mit dem Paket Python Requests eine Anfrage an eine Website zu senden.
Auf der Webplattform von Bright Data können Sie zuverlässige Proxys für Ihr Projekt erhalten, die für alle Länder und Städte der Welt gelten. Um Ihren spezifischen Bedürfnissen gerecht zu werden, bietet Bright Data mehrere Möglichkeiten, um die benötigten Daten mit verschiedenen Arten von Proxys und Tools für das Web-Scraping zu erfassen.
Ganz gleich, ob Sie Daten zu Zwecken der Marktforschung erfassen, Online-Rezensionen überwachen oder die Preisgestaltung von Mitbewerbern verfolgen möchten, Bright Data verfügt über die Ressourcen, die Sie benötigen, um Ihre Arbeit schnell und effizient zu erledigen.






