

In diesem Tutorial lernen wir, wie man Amazon mit Bright Data und einem produktionsreifen Scraping-Projekt scrapt.
Wir behandeln folgende Themen:
- Verwendung des Amazon Scraper API
- Einrichten eines Projekts und Konfigurieren von Amazon-Scrape-Zielen
- Abrufen und Rendern von Amazon-Seiten
- Extrahieren von Produktdaten aus Such- und Produktseiten
- Scraping von Amazon mit Bright Data’s Web MCP mit Claude Desktop
Warum Amazon scrapen?
Amazon ist der weltweit größte Produktmarktplatz und eine der reichhaltigsten Quellen für Echtzeit-Handelsdaten im Internet. Von Preisentwicklungen bis hin zur Kundenstimmung spiegelt die Plattform das Marktverhalten in einem Umfang wider, den nur wenige andere Websites bieten können.
Durch das Scraping von Amazon können Teams über manuelle Recherchen und statische Datensätze hinausgehen und automatisierte, datengestützte Entscheidungen in großem Maßstab treffen.
Häufige Anwendungsfälle für das Scraping von Amazon
Zu den häufigsten Gründen, warum Unternehmen und Entwickler Amazon scrapen, gehören:
- Preisüberwachung und Wettbewerbsanalyse: Verfolgen Sie Produktpreise, Rabatte und Lagerverfügbarkeit über Kategorien und Verkäufer hinweg nahezu in Echtzeit.
- Markt- und Produktforschung: Analysieren Sie Produktlisten, Kategorien und Bestseller-Rankings, um Nachfragetrends und neue Chancen zu identifizieren.
- Bewertungs- und Stimmungsanalyse: Sammeln Sie Kundenbewertungen und -rezensionen, um die Stimmung der Käufer, die Produktleistung und Funktionslücken zu verstehen.
- KI-gestützte Anwendungen: Speisen Sie Live-Daten von Amazon in LLMs und KI-Agenten ein, um Aufgaben wie Einkaufsassistenten, dynamische Preismodelle und automatisierte Marktanalysen zu erledigen.
Nachdem die Anwendungsfälle klar sind, können wir nun praktisch werden und die Möglichkeiten zum Scraping von Amazon mit Bright Data durchgehen.
Scraping von Amazon mit der Bright Data Amazon Scraper API
Neben der Erstellung benutzerdefinierter Scraper oder der Verwendung von MCP mit Claude bietet Bright Data auch eine verwaltete Amazon Scraper API an. Für die Authentifizierung benötigen Sie Ihren API-Schlüssel.
Auswahl eines Amazon-Scrapers
Öffnen Sie zunächst die Bright Data Scraper Library.
Wählen Sie aus der Liste der verfügbaren Scraper den Amazon Scraper aus, der Ihrem Anwendungsfall entspricht, z. B.:
- Produktdetails nach ASIN
- Suchergebnisse
- Bewertungen
Jeder Scraper ist für einen bestimmten Typ von Amazon-Daten ausgelegt.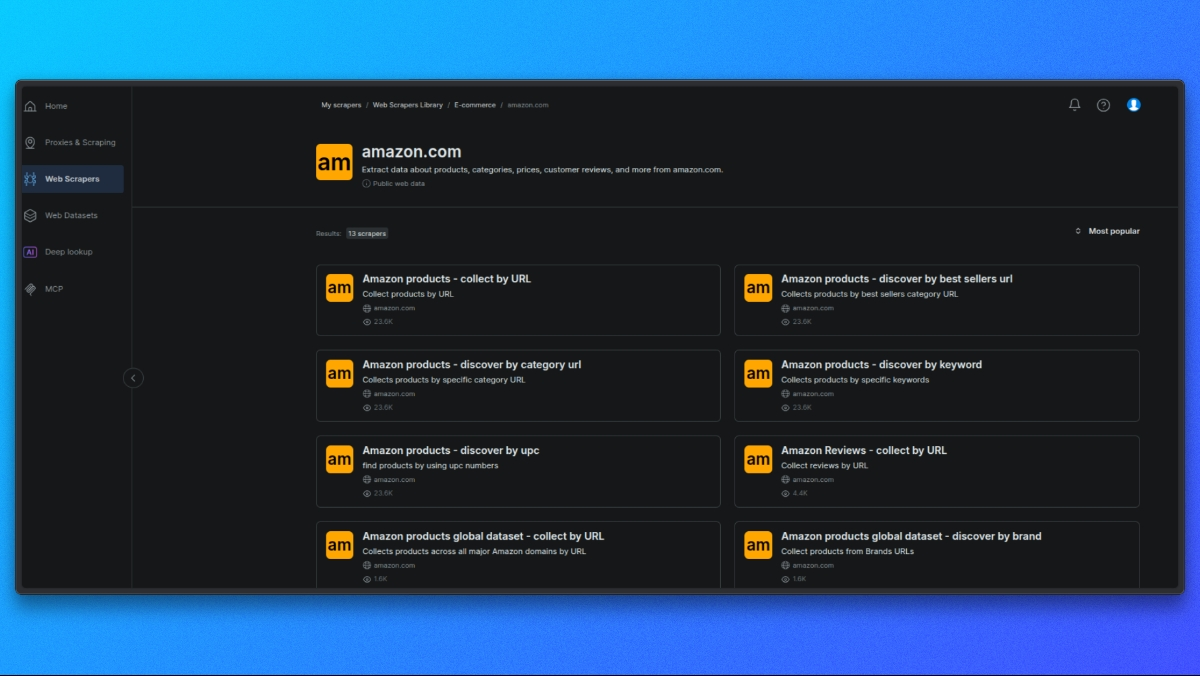
Wählen Sie den Scraper-Endpunkt
Jeder Scraper bietet je nach den gewünschten Daten (z. B. Produktdetails, Suchergebnisse, Bewertungen) unterschiedliche Endpunkte.
Klicken Sie auf den Endpunkt, der Ihrem Anwendungsfall entspricht.
Erstellen Sie Ihre Anfrage
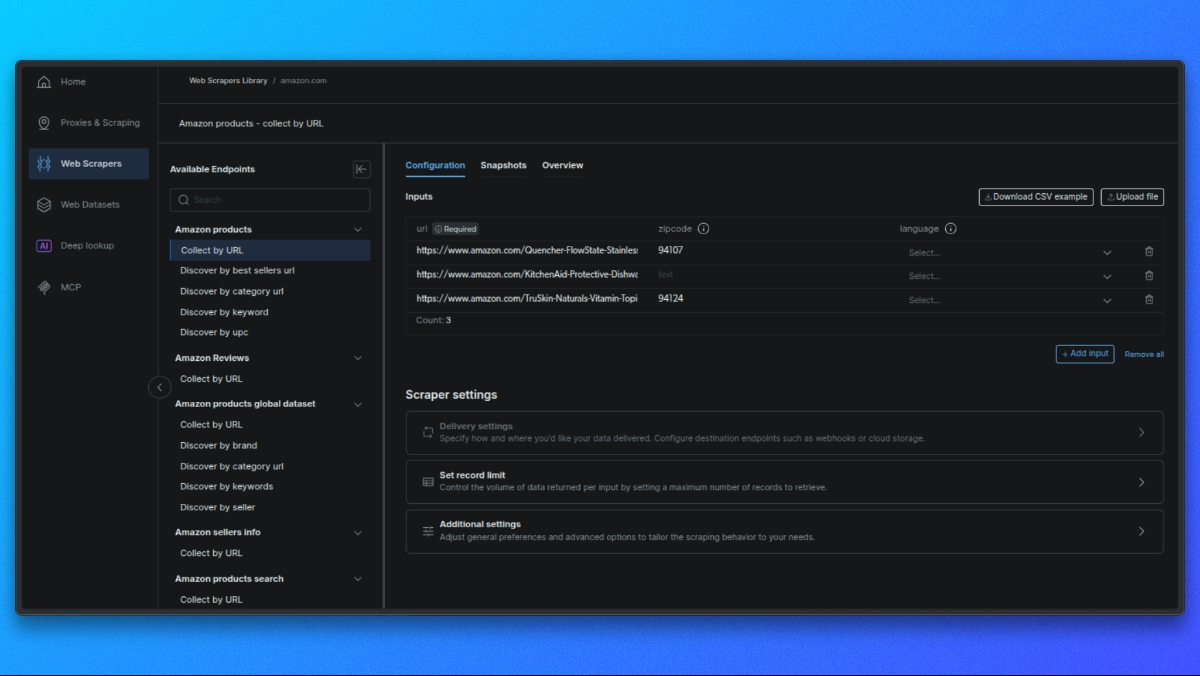
Im mittleren Bereich sehen Sie ein Formular zur Konfiguration Ihrer Anfrage:
- Einzelne Eingabe: Fügen Sie eine Produkt-URL, ASIN oder ein Stichwort ein.
- Bulk-CSV: Laden Sie eine CSV-Datei mit mehreren Eingaben für die Stapelverarbeitung hoch.
Optionale Einstellungen: - Ausgabeschema: Wählen Sie nur die Felder aus, die Sie benötigen.
- Externer Speicher: Richten Sie S3, GCS oder Azure für die direkte Lieferung ein.
- Webhook-URL: Richten Sie einen Webhook ein, um Ergebnisse automatisch zu erhalten.
API-Anfrage stellen
Hier ist ein einfaches Beispiel für die Verwendung von curl für eine Produktseite:
curl -i --silent --compressed "https://api.brightdata.com/dca/trigger?customer=hl_ee3f47e5&zone=YOUR_ZONE_NAME"
-H "Content-Type: application/json"
-H "Authorization: Bearer YOUR_API_KEY"
-d '{
"input": {
"url": "https://www.amazon.com/dp/B08L5TNJHG"
}
}'Ersetzen Sie YOUR_ZONE_NAME und YOUR_API_KEY durch Ihre tatsächliche Zone und Ihren API-Schlüssel.
### Ergebnisse abrufen
- Bei Echtzeit-Aufträgen (bis zu 20 URLs) erhalten Sie die Ergebnisse direkt.
- Bei Batch-Aufträgen erhalten Sie eine Auftrags-ID, mit der Sie die Ergebnisse abfragen oder über Webhook/externen Speicher abrufen können.
Sehen wir uns nun an, wie Sie mit den Residential-Proxys von Bright Data einen benutzerdefinierten Scraper erstellen können.
Projekt einrichten
Sie können diesem Tutorial mit dem im Repository verfügbaren Projektcode folgen.
Bevor Sie beginnen, stellen Sie sicher, dass die folgenden Voraussetzungen auf Ihrem System installiert sind.
Voraussetzungen
Für dieses Projekt ist Folgendes erforderlich:
- Python 3.10+
- pip für die Abhängigkeitsverwaltung
- Node.js 18+ (von Vercel erforderlich)
- Vercel CLI
Darüber hinaus benötigen Sie:
- Ein Bright Data -Konto
- Zugriff auf Bright Datas Web MCP
- Claude Desktop
Installieren von Abhängigkeiten
Installieren Sie die erforderlichen Python-Abhängigkeiten mithilfe der bereitgestellten Datei „requirements.txt“:
pip install -r requirements.txtDadurch werden alle Bibliotheken installiert, die für das Abrufen von Seiten, die Browser-Automatisierung, das Parsen von HTML und die Datenextraktion verwendet werden.
Bright Data CA-Zertifikat
Dieses Projekt verwendet ein Bright Data CA-Zertifikat für die TLS-Überprüfung beim Weiterleiten von Anfragen über den Proxy.
Stellen Sie sicher, dass die Zertifikatsdatei unter dem folgenden Pfad vorhanden ist:
certs/brightdata-ca.crtDiese Datei wird bei Anfragen an den HTTP-Client übergeben. Wenn sie fehlt oder falsch referenziert ist, schlagen Amazon-Anfragen aufgrund von TLS-Verifizierungsfehlern fehl.
Vercel-Einrichtung
Dieses Projekt ist für die Ausführung als Vercel Serverless Function ausgelegt.
Die Datei api/search.py dient als API-Einstiegspunkt und wird von Vercel als Antwort auf eingehende HTTP-Anfragen ausgeführt.
Stellen Sie sicher, dass die Vercel-CLI installiert und authentifiziert ist:
vercel login
Umgebungsvariablen
Das Projekt verwendet eine umgebungsbasierte Konfiguration für die Laufzeiteinstellungen.
Erstellen Sie eine .env-Datei im Stammverzeichnis des Projekts und definieren Sie die erforderlichen Variablen wie im Repository angegeben. Diese Werte steuern, wie der Scraper Amazon-Seiten abruft, rendert und verarbeitet.
Nachdem die Abhängigkeiten installiert und die Umgebungsvariablen konfiguriert wurden, ist das Projekt einsatzbereit.
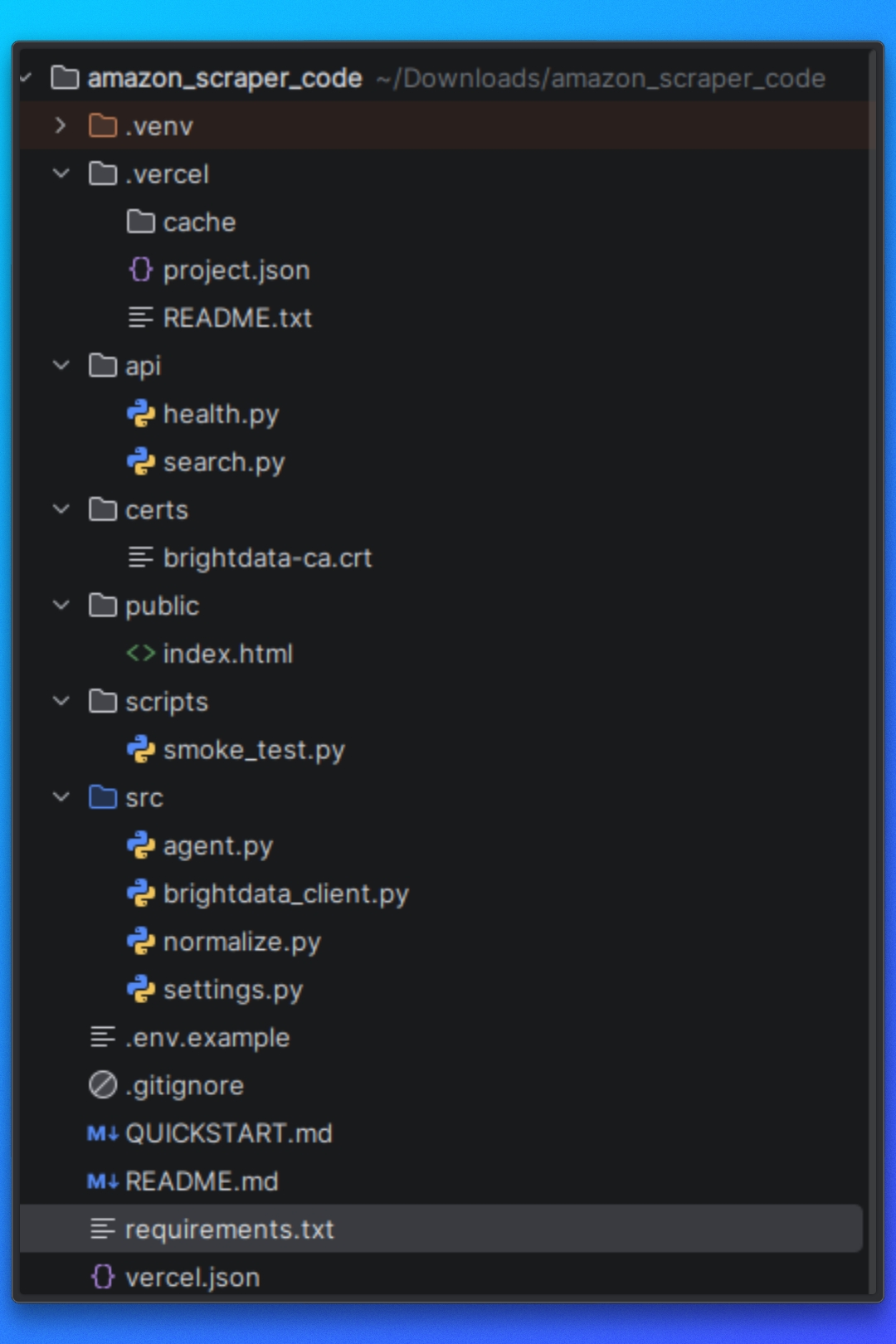
Die Projektstruktur verstehen
Bevor wir den Scraper ausführen, müssen wir verstehen, wie das Projekt organisiert ist und wie die Scraping-Pipeline von Anfang bis Ende abläuft.
Das Projekt ist nach einer klaren Aufgabenteilung strukturiert.
Konfiguration
Dieser Teil des Projekts definiert Amazon-Ziele, Laufzeitoptionen und das Verhalten des Scrapers. Diese Einstellungen steuern, was gescrapt wird und wie der Scraper funktioniert.
Seitenabruf und -rendering
Dieser Teil des Projekts ist für das Laden von Amazon-Seiten und die Rückgabe von nutzbarem HTML verantwortlich. Er übernimmt die Navigation, das Laden von Seiten und die Ausführung von JavaScript, sodass die nachgelagerte Logik mit vollständig gerenderten Inhalten arbeiten kann.
Extraktionslogik
Sobald HTML verfügbar ist, analysiert die Extraktionsschicht die Seite und extrahiert strukturierte Daten. Dies umfasst Logik sowohl für Amazon-Suchergebnisseiten als auch für einzelne Produktseiten.
Ausführungsablauf
Der Ausführungsablauf koordiniert das Abrufen, Rendern, Extrahieren und Ausgeben. Er stellt sicher, dass jeder Schritt in der richtigen Reihenfolge ausgeführt wird.
Ausgabeverarbeitung
Die gescrapten Daten werden in einem strukturierten Format auf die Festplatte geschrieben, sodass sie leicht überprüft oder in anderen Workflows verwendet werden können.
Diese Struktur hält den Scraper modular und erleichtert die Wiederverwendung einzelner Komponenten, insbesondere bei der Integration externer Abrufmethoden wie Bright Data’s Web MCP später im Tutorial.
Mit dieser Übersicht können wir nun zur Konfiguration der Amazon-Ziele und zur Definition der Daten übergehen, die der Scraper sammeln soll.
Konfigurieren von Amazon-Zielen
In diesem Abschnitt konfigurieren wir zwei Dinge:
- Das Amazon-Suchwort, das wir scrapen möchten
- Die Bright Data-Anmeldedaten, die wir benötigen, um Amazon-Seiten erfolgreich abzurufen
1. Übergeben des Amazon-Suchbegriffs
Wir senden unser Amazon-Schlüsselwort mithilfe eines Abfrageparameters namens q.
Dies wird in api/search.py verarbeitet. Die API liest q aus der Anfrage-URL und stoppt sofort, wenn es fehlt:
# api/search.py
query = query_params.get("q", [None])[0]
if not query:
self._send_json_response(400, {"error": "Missing required parameter: q"})
returnWas das bedeutet:
Wir müssen den Endpunkt mit ?q=... aufrufen
Wenn wir q vergessen, erhalten wir eine 400 -Antwort und der Scraper wird nicht ausgeführt
Festlegen, wie viele Produkte wir wollen
Wir können auch mit dem optionalen Parameter „limit” steuern, wie viele Produkte wir zurückgeben.
Noch immer in api/search.py analysieren wir limit, konvertieren es in eine Ganzzahl und begrenzen es auf einen sicheren Bereich:
# api/search.py
limit_str = query_params.get("limit", [None])[0]
limit = DEFAULT_SEARCH_LIMIT
if limit_str:
try:
limit = int(limit_str)
limit = min(limit, MAX_SEARCH_LIMIT)
limit = max(1, limit)
except ValueError:
limit = DEFAULT_SEARCH_LIMITAlso:
Wenn wir limit nicht übergeben, verwenden wir den Standardwert.
Wenn wir einen ungültigen Wert übergeben, greifen wir auf den Standardwert zurück.
Wenn wir einen Wert übermitteln, der höher als der zulässige Wert ist, wird er begrenzt.
Die Standard- und Maximalwerte sind in src/settings.py definiert:
# src/settings.py
DEFAULT_SEARCH_LIMIT = 10
MAX_SEARCH_LIMIT = 50Wenn wir das Standardverhalten ändern möchten, tun wir dies hier.
2. Zuordnung unserer Abfrage zum Suchendpunkt von Amazon
Sobald wir q haben, rufen wir die Amazon-Suchergebnisse über Bright Data mit fetch_products(query, limit) ab:
# api/search.py
raw_response = fetch_products(query, limit)Der zu durchsuchende Amazon-Endpunkt ist in src/brightdata_client.py definiert:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"Und wenn wir die Ergebnisse abrufen, übergeben wir unser Schlüsselwort mit dem Parameter k an Amazon:
# src/brightdata_client.py
r = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,
)Das bedeutet:
- Unser API-Parameter ist
q - Der Suchparameter von Amazon ist
k - Wenn wir q=wireless headphones angeben, wird die Anfrage wie folgt an Amazon gesendet:
https://www.amazon.com/s?k=wireless+headphones
3. Konfigurieren der Bright Data-Anmeldedaten
Um Anfragen über Bright Data zu senden, benötigen wir Proxy-Anmeldedaten, die als Umgebungsvariablen verfügbar sind.
In src/settings.py laden wir die Bright Data-Einstellungen wie folgt:
# src/settings.py
BRIGHTDATA_USERNAME = os.getenv('BRIGHTDATA_USERNAME', '')
BRIGHTDATA_PASSWORD = os.getenv('BRIGHTDATA_PASSWORD', '')
BRIGHTDATA_PROXY_HOST = os.getenv('BRIGHTDATA_PROXY_HOST', 'brd.superproxy.io')
BRIGHTDATA_PROXY_PORT = os.getenv('BRIGHTDATA_PROXY_PORT', 'your_port)Fügen Sie in Ihrer .env -Datei die folgenden Anmeldedaten hinzu:
BRIGHTDATA_USERNAME=your_brightdata_username
BRIGHTDATA_PASSWORD=your_brightdata_password
BRIGHTDATA_PROXY_HOST=brd.superproxy.io
BRIGHTDATA_PROXY_PORT=your_portWenn wir den Scraper ausführen, werden diese Werte verwendet, um die Bright Data-Proxy-URL in src/brightdata_client.py zu erstellen:
# src/brightdata_client.py
proxy_url = (
f"http://{BRIGHTDATA_USERNAME}:{BRIGHTDATA_PASSWORD}"
f"@{BRIGHTDATA_PROXY_HOST}:{BRIGHTDATA_PROXY_PORT}")
proxies = {"http": proxy_url, "https": proxy_url}Wenn wir BRIGHTDATA_USERNAME oder BRIGHTDATA_PASSWORD nicht festlegen, schlägt der Scraper frühzeitig mit einer eindeutigen Fehlermeldung fehl:
# src/brightdata_client.py
if not BRIGHTDATA_USERNAME or not BRIGHTDATA_PASSWORD:
raise ValueError(
"Bright Data-Proxy-Anmeldedaten nicht konfiguriert. "
"Setzen Sie BRIGHTDATA_USERNAME und BRIGHTDATA_PASSWORD."
)Nachdem wir unser Schlüsselwort und die Bright Data-Anmeldedaten konfiguriert haben, können wir nun Amazon-Seiten abrufen.
Abrufen von Amazon-Seiten
Zu diesem Zeitpunkt haben wir bereits die Eingabe validiert und Bright Data konfiguriert. Wir konzentrieren uns nun darauf, wo die Amazon-Anfrage ausgeführt wird und welche minimalen Annahmen sie trifft.
Alle Amazon-Anfragen werden von src/brightdata_client.py gesendet.
Amazon-Suchendpunkt
Wir definieren den Amazon-Suchendpunkt einmal und verwenden ihn für alle Suchanfragen wieder:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"Anfrage-Header
Wir senden generische, browserähnliche Header, um sicherzustellen, dass Amazon das standardmäßige Desktop-HTML-Layout zurückgibt. Diese Header sind nicht an das Betriebssystem des Benutzers gebunden.
# src/brightdata_client.py
headers = {
"User-Agent": (
"Mozilla/5.0 "
"AppleWebKit/537.36 (KHTML, like Gecko) "
„Chrome/120.0 Safari/537.36”
),
„Accept-Language”: „en-US,en;q=0.9”,
„Accept”: „text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8”,
}Senden der Anfrage
Nachdem der Endpunkt, die Header und die Proxy-Konfiguration bereits eingerichtet sind, führen wir die Amazon-Anfrage aus:
# src/brightdata_client.py
response = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,)
response.raise_for_status()
html = response.text or ""Am Ende dieses Aufrufs enthält html den Rohinhalt der Amazon-Suchseite.
Nachdem die Abrufphase abgeschlossen ist, können wir nun mit dem Parsing des HTML-Codes fortfahren und Produktlinks und Metadaten aus der Amazon-Suchergebnisseite extrahieren.
Extrahieren der Suchergebnisse
Nachdem die Amazon-Suchseite abgerufen wurde, besteht der nächste Schritt darin, Produktlisten aus dem zurückgegebenen HTML zu extrahieren. Dieser gesamte Schritt findet in src/brightdata_client.py statt.
Nachdem die Anfrage abgeschlossen ist, übergeben wir den Roh-HTML-Code an den internen Parser:
products = _parse_amazon_search_html(html, limit=limit)
return {"products": products}Die gesamte Logik zur Extraktion der Suchergebnisse befindet sich in _parse_amazon_search_html.
Parsing des HTML-Codes
Zunächst parsen wir den Roh-HTML-Code mit BeautifulSoup in einen DOM-Baum. So können wir die Seitenstruktur zuverlässig abfragen.
soup = BeautifulSoup(html, "lxml")Außerdem normalisieren wir das angeforderte Limit, um sicherzustellen, dass wir immer mindestens einen Artikel extrahieren:
max_items = max(1, int(limit)) if isinstance(limit, int) else 10Suchergebnis-Container lokalisieren
Amazon-Suchseiten enthalten viele Elemente, die keine Produktlisten sind. Um die tatsächlichen Ergebnisse zu isolieren, suchen wir zunächst den primären Suchergebniscontainer von Amazon:
containers = soup.select('div[data-component-type="s-search-result"]')Als Fallback suchen wir auch nach Elementen, die ein gültiges data-asin-Attribut enthalten:
fallback = soup.select('div[data-asin]:not([data-asin=""])')Wenn der primäre Selektor keine Ergebnisse liefert, der Fallback jedoch schon, wechseln wir zum Fallback:
if not containers and fallback:
containers = fallbackDadurch sind wir widerstandsfähig gegenüber geringfügigen Layout-Abweichungen und beschränken die Extraktion weiterhin auf echte Produkteinträge.
Durchlaufen der Ergebnisse
Wir durchlaufen die ausgewählten Container und stoppen, sobald wir das gewünschte Limit erreicht haben:
products = []
for c in containers:
if len(products) >= max_items:
breakFür jeden Container extrahieren wir die Kernfelder. Wenn eine Produktkarte weder einen Titel noch eine URL enthält, überspringen wir sie.
title = _extract_title(c)
url = _extract_url(c)
if not title or not url:
continueExtrahieren von Produktfeldern
Jede Produktkarte wird mit kleinen Hilfsfunktionen analysiert, die alle in derselben Datei definiert sind.
image = _extract_image(c)
rating = _extract_rating(c)
reviews = _extract_reviews_count(c)
price = _extract_price(c)Anschließend erstellen wir ein strukturiertes Produktobjekt:
products.append(
{
"title": title,
"price": price,
"rating": rating,
"reviews": reviews,
"url": url,
"image": image,
}
)Hilfsfunktionen zur Feldextraktion
Jeder Helfer konzentriert sich auf ein Feld und behandelt fehlende oder unvollständige Markups sicher.
Titelextraktion
def _extract_title(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
if a:
t = a.get_text(" ", strip=True)
if t:
return t
img = container.select_one("img.s-image")
alt = img.get("alt") if img else ""
return alt.strip() if isinstance(alt, str) else ""Produkt-URL
def _extract_url(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
href = a.get("href") if a else ""
if isinstance(href, str) and href:
return "https://www.amazon.com" + href if href.startswith("/") else href
return ""Bild
def _extract_image(container) -> Optional[str]:
img = container.select_one("img.s-image")
src = img.get("src") if img else None
return src if isinstance(src, str) and src else NoneBewertung
def _extract_rating(container) -> Optional[float]:
el = container.select_one("span.a-icon-alt")
text = el.get_text(" ", strip=True) if el else ""
if not text:
el = container.select_one('span:contains("out of 5 stars")')
text = el.get_text(" ", strip=True) if el else ""
if not text:
return None
m = re.search(r"(d+(?:.d+)?)", text)
return float(m.group(1)) if m else NoneAnzahl der Bewertungen
def _extract_reviews_count(container) -> Optional[int]:
el = container.select_one("span.s-underline-text")
text = el.get_text(" ", strip=True) if el else ""
m = re.search(r"(d[d,]*)", text)
return int(m.group(1).replace(",", "")) if m else NonePreis
def _extract_price(container) -> str:
whole = container.select_one("span.a-price-whole")
frac = container.select_one("span.a-price-fraction")
whole_text = whole.get_text(strip=True).replace(",", "") if whole else ""
frac_text = frac.get_text(strip=True) if frac else ""
if not whole_text:
return ""
return f"${whole_text}.{frac_text}" if frac_text else f"${whole_text}"Am Ende dieses Schritts haben wir eine Liste strukturierter Produkteinträge, die direkt aus den Amazon-Suchergebnissen extrahiert wurden.
Jeder Eintrag enthält:
- Titel
- Preis
- Bewertung
- Bewertungen
- Produkt-URL
- Bild-URL
Nachdem die Extraktion der Suchergebnisse abgeschlossen ist, fahren wir mit der Normalisierung und Rückgabe der Antwort fort, die in src/normalize.py verarbeitet wird.
Normalisierung der Antwort
Zu diesem Zeitpunkt gibt unsere Suche Produkt-Objekte zurück, aber die Felder sind noch nicht standardisiert. Beispielsweise ist der Preis immer noch eine Zeichenfolge (wie „129,99 $“), die Anzahl der Bewertungen kann Kommas enthalten und je nach Karte können einige Felder fehlen.
Um die API-Antwort konsistent zu gestalten, normalisieren wir alles in src/normalize.py.
In api/search.py erfolgt die Normalisierung unmittelbar nach dem Abrufen der Rohdaten:
# api/search.py
normalized = normalize_response(raw_response, query)Dieser einzelne Aufruf wandelt die Rohdaten von Bright Data in eine saubere Antwortform um, die immer wie folgt aussieht:
items: eine Liste normalisierter Produkt-Objektecount: Anzahl der zurückgegebenen Elemente
Normalisierung einer Dict-Antwort
normalize_response unterstützt mehrere Eingabetypen. In unserem API-Ablauf übergeben wir ein dict wie {"products": [...]} von fetch_products(...).
Hier ist der dict-Zweig:
# src/normalize.py
if isinstance(raw_response, dict):
products = raw_response.get("products", []) or raw_response.get("items", [])
normalized_items = [normalize_product(p) for p in products if isinstance(p, dict)]
return {"items": normalized_items[:limit], "count": len(normalized_items[:limit])}Was dies bewirkt:
- Liest Produkte aus „products” (oder „items”, falls vorhanden)
- Normalisiert jedes Produkt mit normalize_product
- Gibt eine konsistente Nutzlast
{"items": [...], "count": N}zurück
Normalisierung eines einzelnen Produkts
Jedes Produkt wird mit normalize_product(...) normalisiert.
Der Preis wird mit parse_price(...) in einen numerischen Wert und einen Währungscode zerlegt :
# src/normalize.py
price_str = raw_product.get("price", "")
price, currency = parse_price(price_str)Die Bewertung wird nach Möglichkeit in einen Float-Wert umgewandelt:
# src/normalize.py
rating = raw_product.get("rating")
if rating is not None:
try:
rating = float(rating)
except (ValueError, TypeError):
rating = None
else:
rating = NoneDie Anzahl der Bewertungen wird in eine Ganzzahl normalisiert, wobei sowohl die Schlüssel „reviews” als auch „reviews_count” unterstützt werden:
# src/normalize.py
reviews_count = raw_product.get("reviews") or raw_product.get("reviews_count")
if reviews_count is not None:
try:
reviews_count = int(str(reviews_count).replace(",", ""))
except (ValueError, TypeError):
reviews_count = None
else:
reviews_count = NoneSchließlich geben wir ein standardisiertes Produktobjekt zurück:
# src/normalize.py
return {
"title": raw_product.get("title", ""),
"price": price,
"currency": currency,
"rating": rating,
"reviews_count": reviews_count,
"url": raw_product.get("url", ""),
"image": raw_product.get("image"),
"source": "brightdata",
}Nach Abschluss der Normalisierung verfügen wir nun über eine konsistente Liste von Artikeln, die sicher von der API zurückgegeben werden kann und für Kunden leicht zu verwenden ist.
Ausführen des Scrapers auf Vercel
Dieser Scraper läuft als serverlose Funktion von Vercel. Lokal führen wir ihn mit dem Vercel-Entwicklungsserver aus, damit sich die api/ Routen genauso verhalten wie in der Produktion.
Lokal mit Vercel ausführen
Starten Sie den Dev-Server aus dem Stammverzeichnis des Repositorys:
vercel dev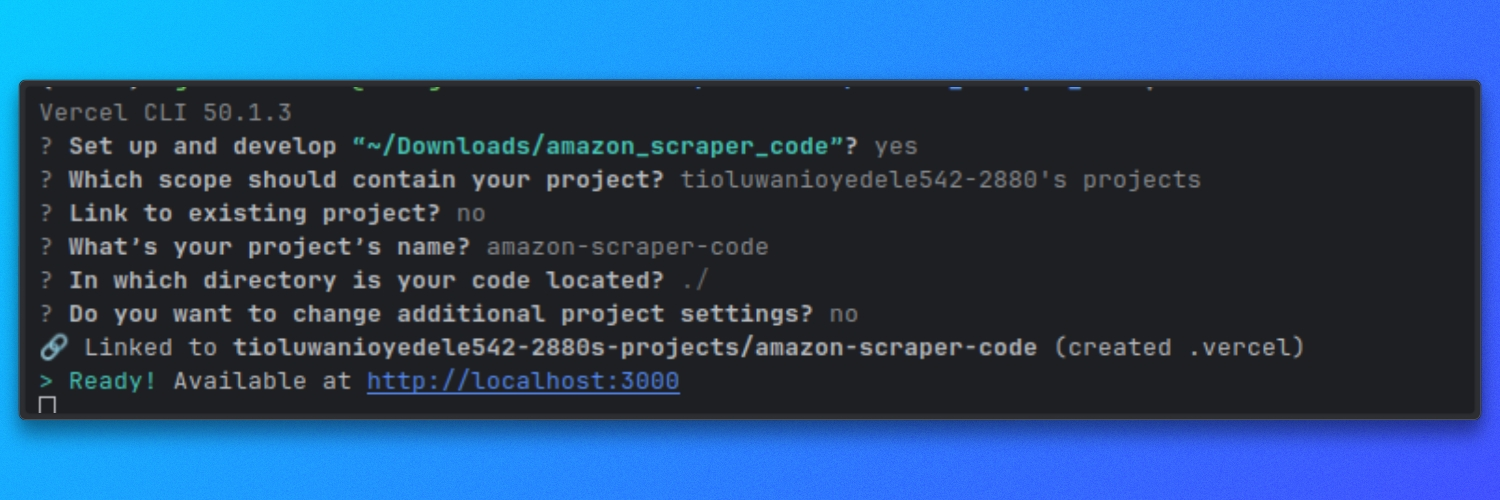
Standardmäßig wird der Server unter folgender Adresse gestartet:
http://localhost
Jetzt haben wir unser vollständiges Scraper-Projekt eingerichtet. Sie können es ausführen und versuchen, verschiedene Amazon-Produkte zu scrapen.
Darüber hinaus können Sie auch mit dem Bright Data MCP mit einem KI-Agenten scrapen. Sehen wir uns kurz an, wie das funktioniert.
Verbinden von Claude Desktop mit Bright Datas Web MCP
Claude Desktop muss so konfiguriert werden, dass der Web MCP-Server von Bright Data gestartet wird.
Öffnen Sie die Konfigurationsdatei von Claude Desktop.
Navigieren Sie zu „Einstellungen“, klicken Sie auf das Entwickler-Symbol und wählen Sie „Konfiguration bearbeiten“. Dadurch wird die von Claude Desktop verwendete Konfigurationsdatei geöffnet.

Fügen Sie die folgende Konfiguration hinzu und ersetzen Sie YOUR_TOKEN_HERE durch Ihren Bright Data API-Token:
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_TOKEN_HERE"
}
}
}
}Speichern Sie die Datei und starten Sie Claude Desktop neu.
Sobald Claude neu gestartet ist, steht Bright Datas Web MCP als Tool zur Verfügung.
Extrahieren von Amazon-Produktlisten mit Claude
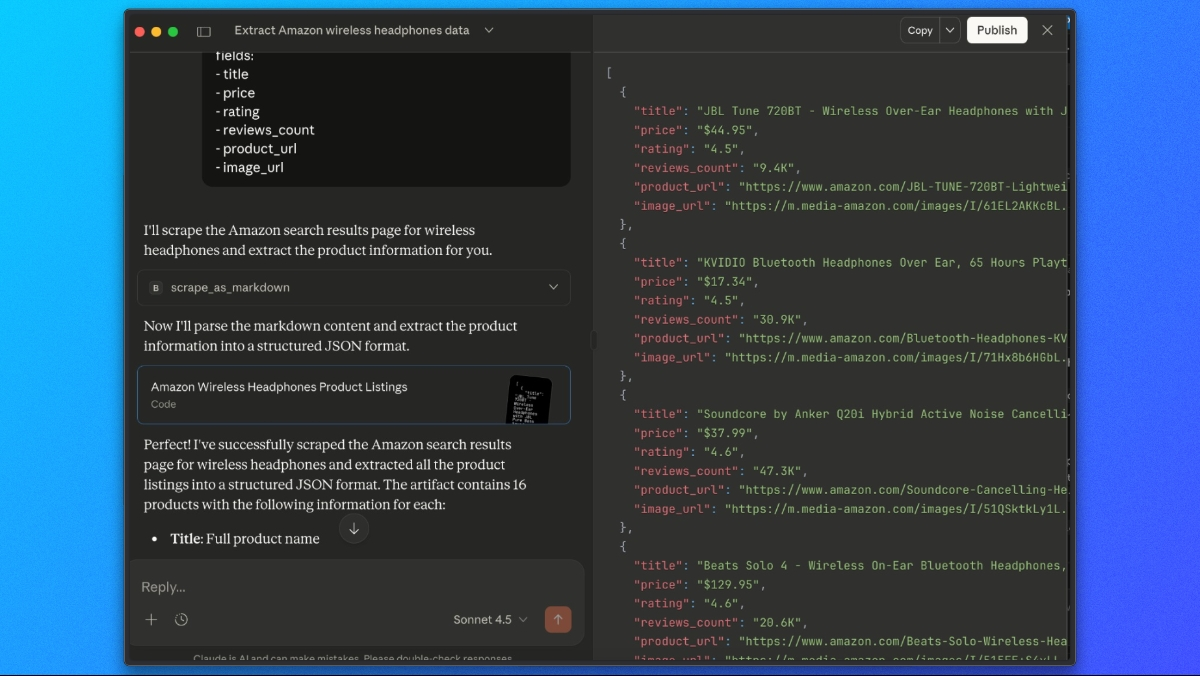
Wenn Bright Data’s Web MCP verbunden ist, können wir Claude bitten, Amazon-Suchergebnisse in einem einzigen Schritt abzurufen und zu extrahieren.
Verwenden Sie dazu eine Eingabeaufforderung wie diese:
Bitte verwenden Sie das Tool scrape_as_markdown, um zu folgender Seite zu gelangen:
https://www.amazon.com/s?k=wireless+headphones
Sehen Sie sich dann die Markdown-Ausgabe an und extrahieren Sie alle Produktlisten in eine JSON-Liste mit den folgenden Feldern:
- title
- price
- rating
- reviews_count
- product_url
- image_urlClaude ruft die Seite über Bright Datas Web MCP ab, analysiert den gerenderten Inhalt und gibt eine strukturierte JSON-Antwort mit den extrahierten Amazon-Produktdaten zurück.
Abschließende Gedanken
In diesem Tutorial haben wir drei Möglichkeiten zum Scrapen von Amazon mit Bright Data untersucht:
- Amazon Scraper API– Der schnellste Weg, um loszulegen. Verwenden Sie vorgefertigte Endpunkte für Produktdetails, Suchergebnisse und Bewertungen, ohne Scraping-Code schreiben zu müssen.
- Benutzerdefinierter Scraper mit Bright Data-Proxy– Erstellen Sie einen produktionsreifen Scraper als Vercel Serverless Function mit vollständiger Kontrolle über das Abrufen, Extrahieren und Normalisieren.
- Claude Desktop mit Web MCP– Scrapen Sie Amazon interaktiv mit KI-gestützter Extraktion, ohne Code schreiben zu müssen.
Überspringen Sie das Scraping komplett
Wenn Sie umfangreiche, produktionsreife Amazon-Daten benötigen, ohne eine Infrastruktur aufzubauen, sollten Sie die Amazon-Datensätze von Bright Data in Betracht ziehen. Sie erhalten Zugriff auf:
- Vorkonfigurierte Produktlisten, Preise und Bewertungen
- Historische Daten für Trendanalysen
- Gebrauchsfertige Datensätze, die regelmäßig aktualisiert werden
- Abdeckung mehrerer Amazon-Marktplätze
Ganz gleich, ob Sie Echtzeit-Scraping oder fertige Datensätze benötigen, Bright Data bietet Ihnen die Infrastruktur, um zuverlässig und in großem Umfang auf Amazon-Daten zuzugreifen.




