

In diesem Tutorial erfahren Sie:
- Die Definition von E-Commerce-Scraping und warum es nützlich ist
- Die Arten von E-Commerce-Scraper-Tools
- Die Daten, die Sie von E-Commerce-Plattformen scrapen können
- Wie Sie mit Python ein E-Commerce-Scraping-Skript erstellen
- Die Herausforderungen beim Scraping von E-Commerce-Websites
Lassen Sie uns eintauchen!
Was ist E-Commerce-Web-Scraping?
E-Commerce-Web-Scraping ist der Prozess der Extraktion von Daten aus Online-Handelsplattformen wie Amazon, Walmart, eBay und ähnlichen Websites. Dies kann zwar durch manuelles Kopieren der Daten erfolgen, wird jedoch in der Regel mit automatisierten Tools oder Skripten durchgeführt.
Die aus E-Commerce-Websites extrahierten Daten können Unternehmen, Forschern und Entwicklern helfen:
- Produktpreisschwankungen zu analysieren
- Bewertungsergebnisse zu verfolgen
- Markttrends zu identifizieren
- Konkurrenten zu untersuchen
Diese Erkenntnisse ermöglichen fundierte Entscheidungen und strategische Planungen.
Beachten Sie, dass ein Tool zum Scraping von E-Commerce-Daten gemeinhin als E-Commerce-Scraper bezeichnet wird.
Arten von E-Commerce-Scrapern
Nachfolgend finden Sie eine Liste der beliebtesten Arten von E-Commerce-Scraper-Tools:
- Benutzerdefinierte Skripte: Maßgeschneiderte Skripte zum Extrahieren bestimmter E-Commerce-Daten unter Verwendung von Web-Scraping-Programmiersprachen wie Python oder JavaScript.
- No-Code-Scraper: Benutzerfreundliche Tools, die eine Datenextraktion ohne Programmierung ermöglichen und sich ideal für nicht-technische Anwender eignen. Entdecken Sie die besten No-Code-Scraper.
- Web-Scraping-APIs: Schnittstellen, die strukturierte E-Commerce-Daten programmgesteuert bereitstellen und häufig die Echtzeit- oder groß angelegte Extraktion unterstützen.
- Scraping-Erweiterungen: Browserbasierte Add-ons, die die Datenerfassung direkt von E-Commerce-Webseiten vereinfachen, während Sie diese durchsuchen.
In diesem Artikel konzentrieren wir uns speziell auf die Erstellung eines benutzerdefinierten E-Commerce-Web-Scraping-Bots.
Daten, die von E-Commerce-Websites gescrapt werden können
E-Commerce-Scraper helfen Ihnen in der Regel dabei, die folgenden Daten abzurufen:
- Produktdetails: Namen, Beschreibungen, Spezifikationen und Bilder.
- Preisinformationen: Aktuelle Preise, Rabatte und historische Preisentwicklungen.
- Kundenbewertungen: Bewertungen, Bewertungsinhalte und Kundenfeedback.
- Kategorien und Tags: Klassifizierung und Kategorisierung von Produkten.
- Verkäuferinformationen: Namen, Bewertungen und Kontaktdaten der Verkäufer.
- Versanddetails: Kosten, Lieferzeiten und Versandbedingungen.
- Lagerverfügbarkeit: Lagerbestände und Benachrichtigungen bei Nichtverfügbarkeit.
- Marketingdaten: Produktlisten, Preisstrategien, Werbeaktionen und saisonale Rabatte.
Lernen Sie jetzt, wie Sie einen Python-E-Commerce-Scraper erstellen!
So erstellen Sie einen E-Commerce-Scraper
Um einen E-Commerce-Scraper manuell zu erstellen, müssen Sie sich zunächst mit der Zielwebsite vertraut machen. Untersuchen Sie die Zielseite mit den DevTools, um:
- ihre Struktur zu verstehen
- zu bestimmen, welche Daten Sie extrahieren können
- zu entscheiden, welche Scraping-Bibliotheken Sie verwenden möchten
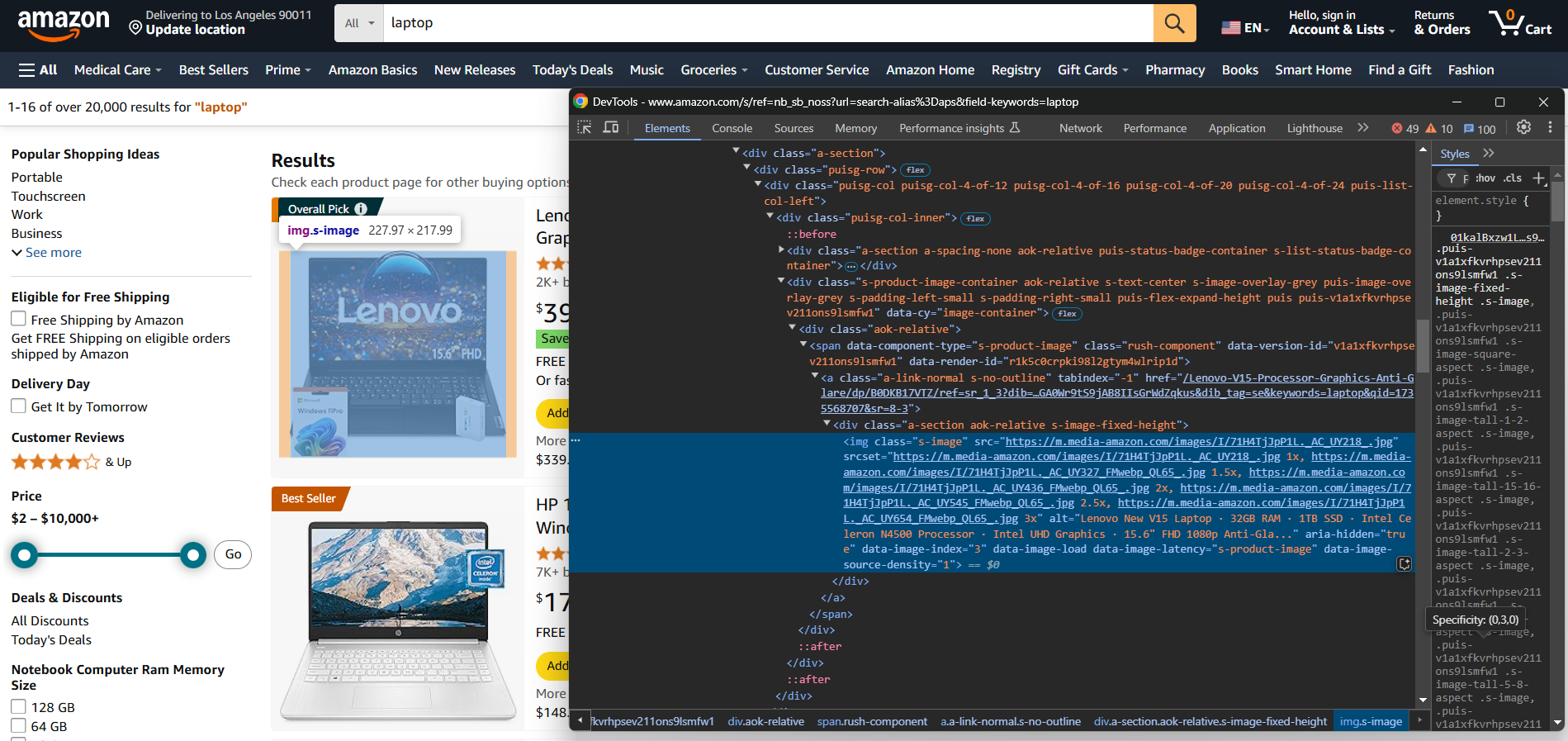
Für einfachere E-Commerce-Websites sind die folgenden zwei Python-Bibliotheken ausreichend:
- Requests: Zum Senden von HTTP-Anfragen. Damit können Sie den rohen HTML-Inhalt einer Webseite abrufen.
- Beautiful Soup: Zum Parsing von HTML- und XML-Dokumenten. Vereinfacht die Navigation und Datenextraktion aus der HTML-Struktur einer Seite. Weitere Informationen finden Sie in unserem Leitfaden zum Beautiful Soup-Scraping.
Sie können beide mit folgendem Befehl installieren:
pip install requests beautifulsoup4
Für E-Commerce-Plattformen, die Daten dynamisch laden oder stark auf JavaScript-Rendering angewiesen sind, benötigen Sie Browser-Automatisierungstools wie Selenium. Weitere Informationen finden Sie in unserem Tutorial zum Selenium-Scraping.
Sie können Selenium mit folgendem Befehl installieren:
pip install selenium
Anschließend läuft der Web-Scraping-Prozess wie folgt ab:
- Verbinden Sie sich mit der Zielwebsite: Verwenden Sie Requests oder Selenium, um den HTML-Code der Seite abzurufen und durchzuführen.
- Wählen Sie die gewünschten Elemente aus: Suchen Sie bestimmte Elemente (z. B. Produktbild, Preis, Beschreibung) in der HTML-Struktur und wählen Sie sie mit CSS-Selektoren oder XPath-Ausdrücken aus.
- Extrahieren Sie Daten: Entnehmen Sie die gewünschten Informationen aus diesen HTML-Elementen.
- Daten bereinigen: Verarbeiten Sie die extrahierten Daten, um unnötige Inhalte zu entfernen oder sie bei Bedarf neu zu formatieren.
- Exportieren Sie die Daten: Speichern Sie die bereinigten Daten in einem bevorzugten Format, z. B. JSON oder CSV.
Zu den Vorteilen dieses Ansatzes gehören die vollständige Kontrolle über den Datenextraktionsprozess und die Möglichkeit, ihn an spezifische Anforderungen anzupassen. Allerdings sind für die Gestaltung und Wartung technische Fachkenntnisse erforderlich. Außerdem benötigt jede E-Commerce-Website ein eigenes Skript.
In den nächsten Kapiteln finden Sie Beispiele für Python-E-Commerce-Scraping-Skripte zum Extrahieren von Daten aus Amazon, Walmart und eBay!
Amazon-Scraping
- Zielseite: Suchseite „Laptop” auf Amazon
- URL der Zielseite: https://www.amazon.com/s?k=laptop&ref=nb_sb_noss
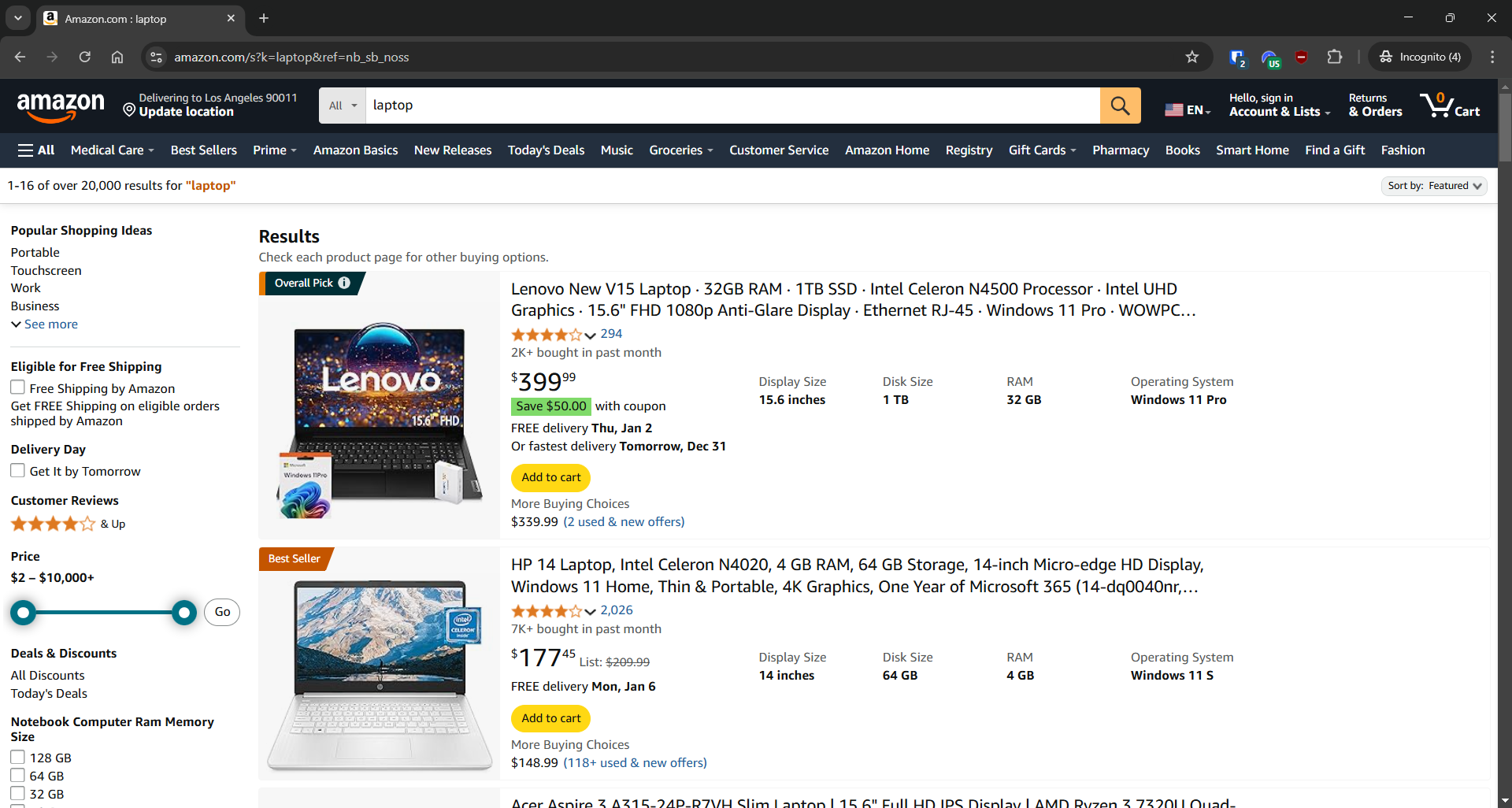
Amazon verfügt über Anti-Scraping-Maßnahmen, die dazu dienen, Anfragen zu blockieren, die nicht von einem Browser stammen. Um diese Einschränkungen zu umgehen, müssen Sie ein Browser-Automatisierungstool wie Selenium verwenden:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Initialisieren Sie den WebDriver
driver = webdriver.Chrome(service=Service())
# Öffnen Sie die Amazon-Startseite im Browser
driver.get("https://amazon.com/")
# Füllen Sie das Suchformular aus
search_input_element = driver.find_element(By.ID, "twotabsearchtextbox")
search_input_element.send_keys("laptop")
# Suchen Sie die Suchschaltfläche und klicken Sie darauf
search_button_element = driver.find_element(By.ID, "nav-search-submit-button")
search_button_element.click()
# Sie befinden sich nun auf der Zielseite
# Wo sollen die gescrapten Daten gespeichert werden?
products = []
# Wählen Sie alle Produktelemente auf der Seite aus
product_elements = driver.find_elements(By.CSS_SELECTOR, "[role="listitem"][data-asin]")
# Iterieren Sie über sie
for product_element in product_elements:
# Scraping-Logik
url_element = product_element.find_element(By.CSS_SELECTOR, ".a-link-normal")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h2")
name = name_element.text
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-image-load]")
image = image_element.get_attribute("src")
# Neues Objekt mit den gescrapten Daten füllen
product = {
"url": url,
"name": name,
"image": image
}
# Füge es zur Liste der gescrapten Produkte hinzu
products.append(product)
# Exportiere Daten in eine JSON-Datei
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
Führen Sie den oben genannten Amazon-E-Commerce-Scraper aus. Wenn Amazon kein CAPTCHA anzeigt, wird das folgende Ergebnis generiert:
[
{
"url": "https://www.amazon.com/A315-24P-R7VH-Display-Quad-Core-Processor-Graphics/dp/B0BS4BP8FB/ref=sr_1_3?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-3",
„name”: „Acer Aspire 3 A315-24P-R7VH Slim Laptop | 15,6" Full HD IPS-Display | AMD Ryzen 3 7320U Quad-Core-Prozessor | AMD Radeon Grafik | 8 GB LPDDR5 | 128 GB NVMe SSD | Wi-Fi 6 | Windows 11 Home im S-Modus”,
„image“: „https://m.media-amazon.com/images/I/61gKkYQn6lL._AC_UY218_.jpg“
},
// der Kürze halber ausgelassen...
{
"url": "https://www.amazon.com/Lenovo-Newest-Flagship-Chromebook-HubxcelAccesory/dp/B0CBJ46QZX/ref=sr_1_8?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-8",
„name”: „Lenovos neuestes Flaggschiff-Chromebook, 14-Zoll-FHD-Touchscreen, schlanker, leichter Laptop, 8-Kern-MediaTek-Kompanio-520-Prozessor, 4 GB RAM, 64 GB eMMC, WiFi 6, Chrome OS + Hubxcel-Zubehör, Abyss Blue”,
„image”: „https://m.media-amazon.com/images/I/61KlKRdsQ7L._AC_UY218_.jpg”
}
]
Beachten Sie, dass Amazon möglicherweise weiterhin ein CAPTCHA anzeigt und Ihre Anfrage blockiert, selbst wenn Sie diese über Selenium stellen. In diesem Fall sollten Sie SeleniumBase als Alternative in Betracht ziehen. Andernfalls lesen Sie den Artikel weiter, da wir Ihnen eine definitive Lösung vorstellen werden.
Eine umfassende Anleitung finden Sie in unserem detaillierten Tutorial zum Web-Scraping bei Amazon.
Walmart-Scraping
- Zielseite: Suchseite „Tastatur” auf Walmart
- URL der Zielseite: https://www.walmart.com/search?q=keyboard
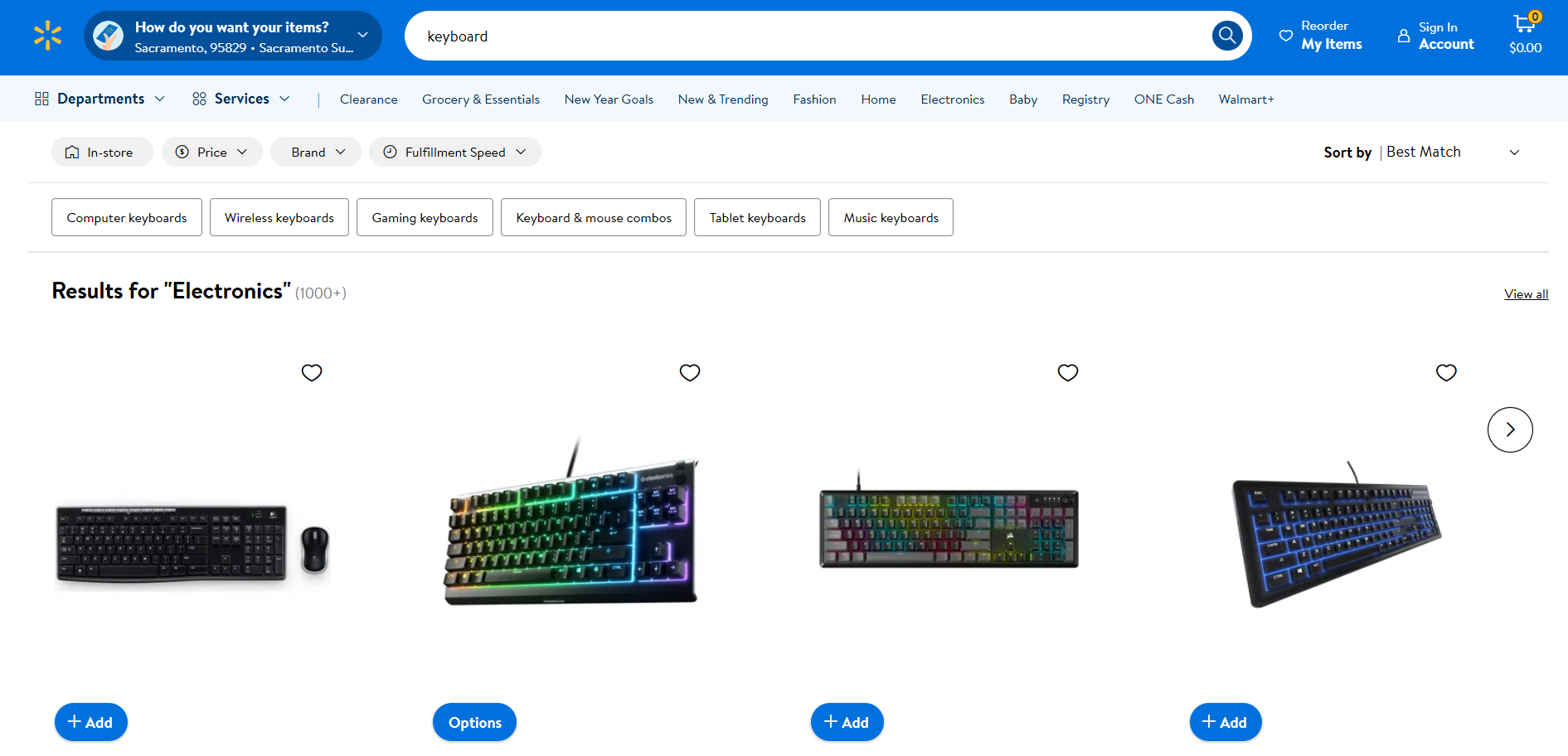
Genau wie Amazon verwendet Walmart Anti-Bot-Lösungen, um Anfragen von automatisierten HTTP-Clients zu blockieren. Sie können also mit Selenium wie folgt scrapen:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Initialisieren Sie den WebDriver
driver = webdriver.Chrome(service=Service())
# Navigieren Sie zur Zielseite
driver.get("https://www.walmart.com/search?q=keyboard")
# Speicherort für die gescrapten Daten
products = []
# Alle Produktelemente auf der Seite auswählen
product_elements = driver.find_elements(By.CSS_SELECTOR, ".carousel-4[data-testid="carousel-container"] li")
# Durchlaufen Sie diese
for product_element in product_elements:
# Scraping-Logik
url_element = product_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h3")
name = name_element.get_attribute("innerText")
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-testid="productTileImage"]")
image = image_element.get_attribute("src")
# Neues Objekt mit den gescrapten Daten füllen
product = {
"url": url,
"name": name,
"image": image
}
# Zur Liste der gescrapten Produkte hinzufügen
products.append(product)
# Daten in eine JSON-Datei exportieren
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
Führen Sie den Walmart-E-Commerce-Scraper aus, und Sie erhalten:
[
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=1&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FLogitech-920-004536-Mk270-Tastatur-Maus-USB-Wireless-Combo-Schwarz%2F28540111%3FclassType%3DREGULAR%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=sAX_0l4wzWXzBji34bVpmheXU7_ETXGbDXcA9LhcshG_YbqBx24VWzt7yesHivpt1lpckuNhxQqbLidA-d8L4agqx_YPQVlj2EfM_TnEyfsSWiTEkvBaqgkaMzy6bgIZ4eC8t9-qqz7qtb7uXMz3cH92UCf5EEgQlfKwnxJ-SAF1EW1ouCjC10Ur3hELs3143xQPjxNUSUoN8FIF12fxJmTlSlTe4makoj1s2NoubYTqnlJLs3pohowJCRFT76Vl&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=REGULAR",
"name": "Logitech Wireless Combo MK270",
„image”: „https://i5.walmartimages.com/seo/Logitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black_99591453-341e-4c5b-937e-b2ab9b321519.3860011d84a23ccd0732e46474590b15.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=2&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FSteelSeries-Apex-3-TKL-RGB-Gaming-Tastatur-ohne-Ziffernblock-wasser- und staubgeschützt-PC-und-USB-A%2F996783321%3FclassType%3DVARIANT%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=Dp3ons-xIcmPw9Ze7UUZuW3PD9Dto_vYCLjglme5vSy5Ze1p4NXg3uzApRy4mgfB-dGDchsq6FDoaZeMy6Dmeagqx_YPQVlj2EfM_TnEyfv_0r9GA9WwEd1cWbcx63Diahe72Zw6lw8suSf-OFKKH6UaiJl_8Qtpar-x0VhgrMsbqG7gDKh5DkQZql3HeMLncWSwburhSEjvpT1dXlDoWKxUrZwxZhOMry-uCqhuSb7Y6B-xZGrNPjYyel0nw11Z&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=VARIANT",
"name": "SteelSeries Apex 3 TKL RGB Gaming-Tastatur – ohne Ziffernblock – wasser- und staubgeschützt – PC und USB-A",
„image”: „https://i5.walmartimages.com/seo/SteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A_876430c2-eed8-404a-aa55-1c66193daf8e.8c617e57ba48bc49d003f917f85cb535.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
// der Kürze halber ausgelassen...
{
"url": "https://www.walmart.com/ip/DEP-06-Portable-Digital-Piano-with-X-Stand/7598762909?classType=REGULAR",
"name": "Donner Portable Digital Piano 88-Tasten-Synth-Action-Keyboard mit X-Ständer, Pedal, Auto-Begleitung für Anfänger, 128 Klänge, 83 Rhythmen, Unterstützung für USB/MIDI/Melodics, drahtlose Verbindung",
„image“: „https://i5.walmartimages.com/seo/DEP-06-Portable-Digital-Piano-with-X-Stand_1175fc1e-c191-4c71-9e9a-7e4a13274487.6673e0430c23d122744cfb63ccc8c155.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
}
]
Weitere Informationen finden Sie in unserem Artikel zum Thema Walmart-Web-Scraping.
eBay-Scraping
- Zielseite: Suchseite „Maus” auf eBay
- URL der Zielseite: https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0
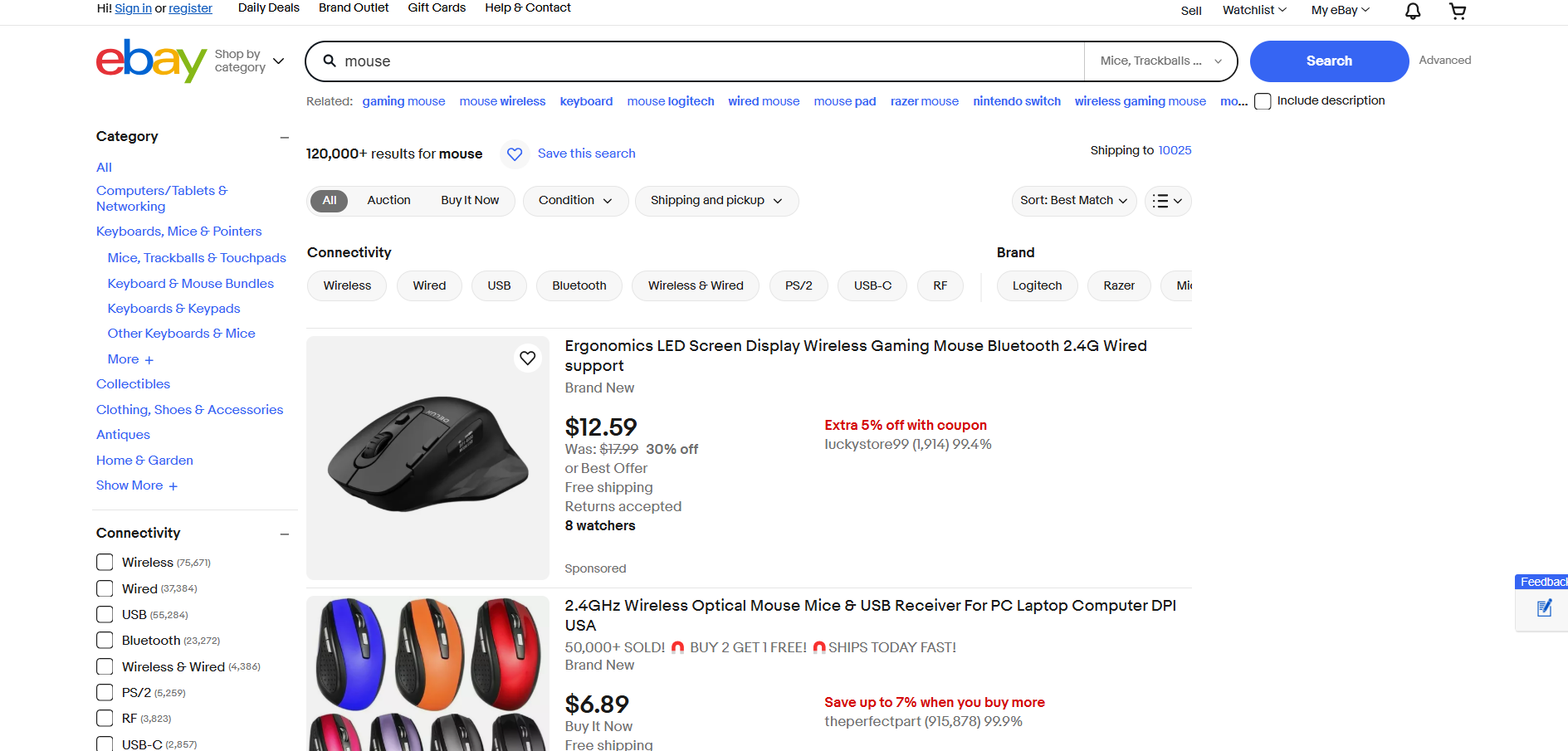
eBay verwendet kein JavaScript zum Rendern von Produkten oder zum dynamischen Laden von Daten. Daher kann es mit Requests und Beautiful Soup wie folgt gescrapt werden:
import requests
from bs4 import BeautifulSoup
import json
# Zielseite
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0"
# Senden einer GET-Anfrage an die eBay-Suchseite
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# Analysieren Sie den Seiteninhalt mit BeautifulSoup.
soup = BeautifulSoup(response.text, "html.parser")
# Wo sollen die gescrapten Daten gespeichert werden?
products = []
# Wählen Sie alle Produktelemente auf der Seite aus.
product_elements = soup.select("li.s-item")
# Durchlaufen Sie diese
for product_element in product_elements:
# Scraping-Logik
url_element = product_element.select("a[data-interactions]")[0]
url = url_element["href"]
name_element = product_element.select("[role="heading"]")[0]
name = name_element.text
image_element = product_element.select("img")[0]
image = image_element["src"]
# Neues Objekt mit den gescrapten Daten füllen
product = {
"url": url,
"name": name,
"image": image
}
# Zur Liste der gescrapten Produkte hinzufügen
products.append(product)
# Daten in eine JSON-Datei exportieren
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)Starten Sie das eBay-E-Commerce-Web-Scraping-Skript, und es wird Folgendes ausgegeben:
[
{
"url": "https://www.ebay.com/itm/193168148815?_skw=mouse&itmmeta=01JGC679WKT327K11R9YCGMQAN&hash=item2cf9b8094f:g:8F4AAOSw3B1drMr-&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlr8NKoodwElhyHbl4CwcBMRqdGJme95%2F3tIll4uI7QYBk4%2BUBpwVvwiXdAl2%2BcILZ9axc%2BdHSZStWWMxWVyq4JdZ6r52PrRP2aS1jUoFoJ11vL4KyH2S8R5ha71xBtDFcGA2%2BtzhTzcR7J25kxuxbyd%2Frd4YnKbTPKwhn2Q0TP8qL30BJKcj4FnJYP0zhgO4WOGgOCHQhM21%2BanVk%2Fl0eg1H8mqCU91mkgKAt8KghFmw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
„name”: „2,4-GHz-Funkmaus & USB-Empfänger für PC, Laptop, Computer, DPI, USA”,
„image”: „https://i.ebayimg.com/images/g/8F4AAOSw3B1drMr-/s-l500.webp”
},
{
„url”: „https://www.ebay.com/itm/356159975164?_skw=mouse&itmmeta=01JGC679WKE9V782ZXT15SEPHP&hash=item52ecc9eefc:g:0ikAAOSwHStnD33Q&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlZ7pO0lYrvftkZhnT7ja625fcsjcktK0eaub2HNzEgsmo3b2VehoA4tffYdt0xiTXwHb%2BzYU4NBZ5onBh68cyKWhhMJowbRvnCwuwy2IQIRlkeijpbRtJNJPuaaiDZdV0eabGGkps8433kCR6fcX1xEodUxujoeYUjp0VP81OWcl%2BbBGd70%2Fq45HC3SXg4k%2FlK0%2FqR80yJYexSEfzUq7%2BN3Sa6Y01uCo5XPWFLHzRoSw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
„name”: „Ergonomische LED-Bildschirm-Anzeige Drahtlose Gaming-Maus Bluetooth 2,4G Kabelgebundene Unterstützung”,
„image”: „https://i.ebayimg.com/images/g/0ikAAOSwHStnD33Q/s-l500.webp”
},
// der Kürze halber ausgelassen...
{
"url": "https://www.ebay.com/itm/116250548048?_skw=mouse&itmmeta=01JGC679WN076MJ17QJ9P4FA5J&hash=item1b11129750:g:gr8AAOSwsSFmkXG3&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKkArX38iC0VVXTpfv4BzqCegsh22yxmsDAwZAmd4RxM9JlEMfuVRoYGVZFVCeurJYwAjWd2YK3%2BNs6m5rQHZXISyWtev1lEvfVVKP4Rd5QeC2KzLgqXOvp1lWiK5b31kfujkmKjF%2BEaR1kplulwrgUvzMO%2F78F%2BFukgIAoL8dE4nRD9jo%2BieiAgIpLBUcs8AmCy5vk65gt1JGonUOncRksGYciF%2FJg6arB9%2FVOYYq7N8A%3D%3D%7Ctkp%3ABlBMULyenYaDZQ",
„name”: „Razer x Sanrio Kuromi DeathAdder Gaming Mouse and Mouse Pad Combo”,
„image”: „https://i.ebayimg.com/images/g/gr8AAOSwsSFmkXG3/s-l500.webp”
}
]
Erstaunlich! Sie haben gerade einige Beispiele für Python-Skripte zum Scraping von E-Commerce-Daten gesehen!
Herausforderungen beim Web-Scraping im E-Commerce und wie man sie bewältigt
In den obigen Beispielen haben wir uns darauf konzentriert, grundlegende Details wie Produktname, URL und Bild-URL aus einigen E-Commerce-Websites zu extrahieren. Diese Einfachheit lässt das Scraping von E-Commerce-Websites zwar unkompliziert erscheinen, doch in Wirklichkeit ist es aus mehreren Gründen weitaus komplexer:
- Dynamische Seitenstrukturen: E-Commerce-Plattformen aktualisieren häufig ihre Seitengestaltung, was eine ständige Pflege der Skripte erforderlich macht.
- Vielfältige Produktseiten: Verschiedene Produkte können unterschiedliche Datensätze anzeigen und völlig unterschiedliche Layouts verwenden.
- Dynamische Preisgestaltung: Das Scraping genauer Preisdaten kann aufgrund von zeitlich begrenzten Angeboten, Rabatten oder regionsspezifischen Angeboten eine Herausforderung darstellen.
Darüber hinaus setzen große E-Commerce-Websites wie Amazon fortschrittliche Anti-Scraping-Maßnahmen ein, wie z. B. CAPTCHAs:
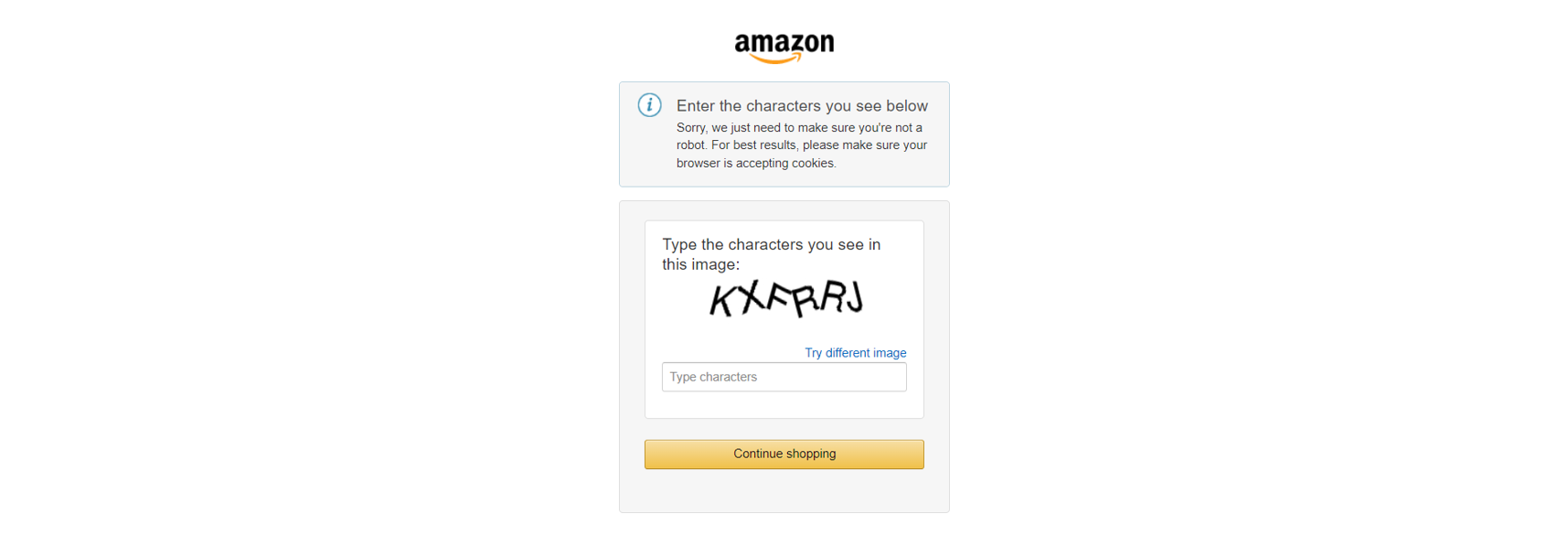
Oder, ähnlich, JavaScript-Herausforderungen:

Um diese Hindernisse zu überwinden, können Sie:
- Erlernen Sie fortgeschrittene Scraping-Techniken: Lesen Sie unseren Leitfaden zum Umgehen von CAPTCHA mit Python und sehen Sie sich ausführliche Scraping-Tutorials mit praktischen Tipps an.
- Verwenden Sie fortschrittliche Automatisierungstools: Nutzen Sie robuste Tools wie Playwright Stealth, um Websites mit Anti-Bot-Mechanismen zu scrapen.
Die effizienteste Lösung ist jedoch die Verwendung einer speziellen E-Commerce-Scraper-API.
Die E-Commerce-Scraper-API von Bright Data ist eine zuverlässige Lösung für die Extraktion von Daten aus E-Commerce-Plattformen wie Amazon, Target, Walmart, Lazada, Shein, Shopee und anderen. Zu den wichtigsten Vorteilen gehören:
- Abrufen strukturierter Details wie Produkttitel, Verkäufername, Marke, Beschreibung, Bewertungen, ursprünglicher Preis, Währung, Verfügbarkeit, Kategorien und mehr.
- Keine Sorgen mehr über die Verwaltung von Servern und Proxys oder die Umgehung von Website-Sperren.
- Vermeiden Sie Unterbrechungen durch CAPTCHAs oder JavaScript-Herausforderungen.
Optimieren Sie noch heute Ihren E-Commerce-Scraping-Prozess!
Fazit
In diesem Artikel haben Sie erfahren, was ein E-Commerce-Scraper ist und welche Art von Daten er aus E-Commerce-Webseiten extrahieren kann. Unabhängig davon, wie ausgefeilt Ihr E-Commerce-Web-Scraping-Skript ist, können die meisten Websites automatisierte Aktivitäten erkennen und Sie blockieren.
Die Lösung ist eine leistungsstarke E-Commerce-Scraper-API, die speziell dafür entwickelt wurde, E-Commerce-Daten zuverlässig von verschiedenen Plattformen abzurufen. Diese APIs bieten strukturierte und umfassende Daten, darunter:
- Amazon Scraper API: Scrapen Sie Amazon und sammeln Sie Daten wie Titel, Verkäufernamen, Marke, Beschreibung, Bewertungen, ursprünglichen Preis, Währung, Verfügbarkeit, Kategorien, ASIN, Anzahl der Verkäufer und vieles mehr.
- eBay Scraper API: Sammeln Sie Daten wie ASIN, Verkäufername, Händler-ID, URL, Bild-URL, Marke, Produktübersicht, Beschreibung, Größen, Farben, Endpreis und mehr.
- Walmart Scraper API: Sammeln Sie Daten wie URL, SKU, Preis, Bild-URL, verwandte Seiten, Verfügbarkeit für Lieferung und Abholung, Marke, Kategorie, Produkt-ID und Beschreibung und vieles mehr.
- Target Scraper API: Sammeln Sie Daten wie URL, Produkt-ID, Titel, Beschreibung, Bewertung, Anzahl der Bewertungen, Preis, Rabatt, Währung, Bilder, Verkäufername, Angebote, Versandbedingungen und vieles mehr.
- Lazada Scraper API: Scrape Daten wie URL, Titel, Bewertung, Rezensionen, Anfangs- und Endpreis, Währung, Bild, Verkäufername, Produktbeschreibung, SKU, Farben, Werbeaktionen, Marke und mehr.
- Shein Scraper API: Rufen Sie Daten wie Produktname, Beschreibung, Preis, Währung, Farbe, Lagerbestand, Größe, Anzahl der Bewertungen, Hauptbild, Ländercode, Domain und mehr ab.
- Shopee Scraper API: Scrapen Sie Daten wie URL, ID, Titel, Bewertung, Rezensionen, Preis, Währung, Lagerbestand, Favoriten, Bild, Shop-URL, Bewertungen, Beitrittsdatum, Follower, Verkaufszahlen, Marke und mehr.
Wenn Sie Daten von bestimmten Produkten scrapen möchten, sollten Sie unsere Web-Scraping-API in Betracht ziehen. Wenn Sie keinen Scraper erstellen möchten, sehen Sie sich unsere gebrauchsfertigen E-Commerce-Datensätze an.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unsere Scraper-APIs auszuprobieren oder unsere Datensätze zu erkunden.




