

Web-Scraping ist der automatisierte Prozess der Datenextraktion von Websites mithilfe von Skripten oder Software-Tools zum Abrufen von Informationen, typischerweise zur Analyse oder Aggregation.
Beautiful Soup ist eine beliebte Python-Bibliothek zum effizienten Parsing von HTML- und XML-Dokumenten.
In diesem umfassenden Leitfaden erfahren Sie, wie Sie Beautiful Soup für Web-Scraping einsetzen. Mit zahlreichen Code-Beispielen und praktischen Tipps bietet dieser Artikel wertvolle Einblicke während des gesamten Lernprozesses.
Web-Scraping mit Beautiful Soup
Typischerweise werden HTML und XML zur Strukturierung von Web-Inhalten verwendet, und ein Document Object Model (DOM)-Baum repräsentiert das Dokument als Baumstruktur von Objekten. Sie können automatisierte Skripte oder Bibliotheken verwenden, um durch Navigation im DOM bedeutungsvolle Informationen aus Web-Inhalten zu extrahieren.
Die Beautiful Soup Python-Bibliothek kann HTML- und XML-Dokumente parsen und den DOM-Baum navigieren. Die Bibliothek wählt automatisch den besten HTML-Parser auf Ihrem Gerät aus, oder Sie können einen benutzerdefinierten HTML-Parser angeben. Anschließend konvertiert die Bibliothek das HTML-Dokument in einen navigierbaren Baum aus Python-Objekten.
Beautiful Soup ermöglicht auch das Parsing von XML-Inhalten mithilfe eines schnellen und effizienten lxml-Parsers. Ähnlich wie bei HTML-Dokumenten erzeugt die Bibliothek aus dem XML-Dokument einen Baum aus Python-Objekten, der mithilfe von Beautiful Soup Selektoren durchlaufen werden kann.
Der Beautiful Soup HTML- oder XML-Parser kann verwendet werden, um Web-Inhalte zu parsen und Python-Objekte zu erzeugen, die einem DOM-Baum ähneln. Das erzeugte Python-Objekt kann verwendet werden, um Daten aus verschiedenen Teilen des Dokuments effizient zu extrahieren, indem die relevanten Elemente ausgewählt werden. Es gibt mehrere Ansätze zur Elementauswahl, darunter find(), das eine Selektorbedingung entgegennimmt und das erste passende HTML-Element zurückgibt, und find_all(), das eine Selektorbedingung entgegennimmt und eine Liste aller passenden HTML-Elemente zurückgibt. Zum Beispiel können Sie alle Inhalte innerhalb der Absatz-Tags (<p>) mithilfe des find_all('p') Selektors finden.
Beautiful Soup für Web-Scraping verwenden
Bevor Sie mit dem Scraping von Daten von Webseiten beginnen, müssen Sie festlegen, welche Daten Sie scrapen möchten und wie Sie dabei vorgehen werden.
Sie können die Entwicklertools Ihres Webbrowsers verwenden, um Elemente auf der Webseite zu untersuchen. Der folgende Screenshot zeigt beispielsweise die DOM-Elemente für den Zitate-Block auf der Quotes to Scrape Webseite:
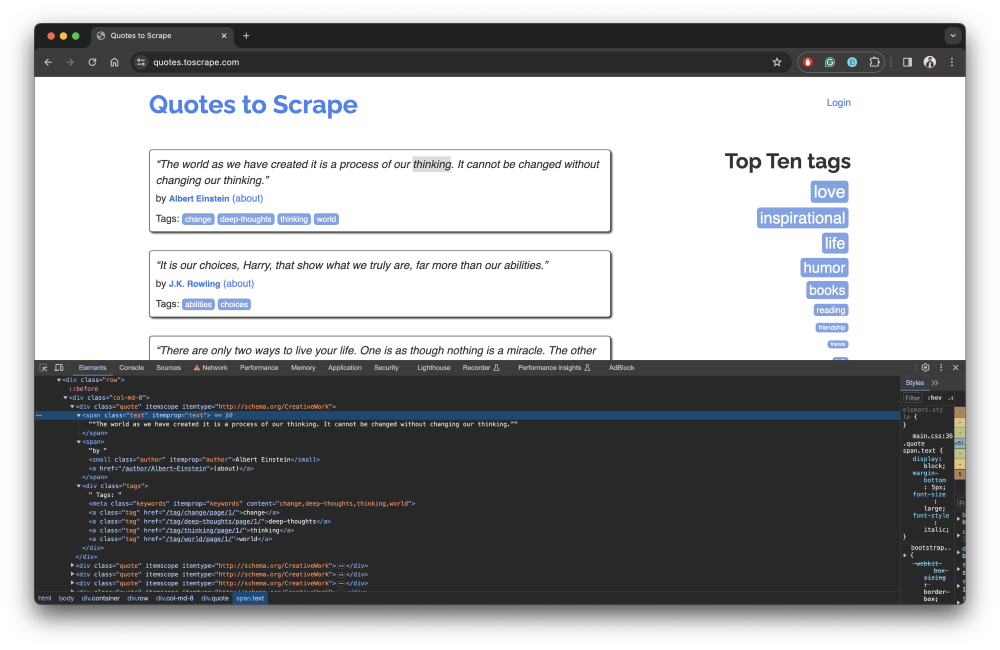
Beachten Sie, dass der Zitattext innerhalb eines span Tags und der Autorenname innerhalb des small Tags steht. Zusätzlich zu Tags können Sie eine Kombination aus HTML-Attributen und CSS-Selektoren verwenden, um bestimmte Elemente auszuwählen. In diesem Leitfaden werden Sie Zitate und Autorennamen von der Quotes to Scrape Seite scrapen.
Ein neues Projekt erstellen
Erstellen Sie zunächst ein neues Projektverzeichnis namens beautifulsoup-scraping-example für die Scraping-Skripte und navigieren Sie mit den folgenden Befehlen dorthin:
mkdir beautifulsoup-scraping-example
cd beautifulsoup-scraping-example
Beim Web-Scraping müssen Sie zunächst den Webseiteninhalt von einer URL über eine HTTP-GET-Anfrage abrufen. Installieren Sie die requests-Bibliothek mit dem folgenden Befehl:
pip install requests
Sie werden diese Bibliothek später für GET-Anfragen verwenden.
Für die eigentliche Web-Scraping-Aufgabe installieren Sie die beautifulsoup4 Python-Bibliothek mit dem folgenden Befehl:
pip install beautifulsoup4
Sie könnten die Liste der Abhängigkeiten auch in einer Datei speichern, um am Skript zusammenzuarbeiten oder es in einem Versionskontrollsystem zu hinterlegen. Erstellen Sie eine requirements.txt Datei im Projektstammverzeichnis mit folgendem Inhalt:
requests
beautifulsoup4
Installieren Sie dann die in der Datei definierten Abhängigkeiten mit diesem Befehl:
pip install -r requirements.txt
Ihr Web-Scraping-Skript definieren
Als Nächstes müssen Sie ein Python-Skript definieren, das den Webseiteninhalt abruft und ihn mithilfe von BeautifulSoup parst, um ein soup-Objekt zu erzeugen. Sie können verschiedene Selektoren mit dem soup-Objekt verwenden, um Elemente auf der Webseite zu finden und die gewünschten Informationen daraus zu extrahieren.
Erstellen Sie zunächst eine Python-Skriptdatei namens main.py im Stammverzeichnis Ihres Projekts und fügen Sie import-Anweisungen für requests und beautifulsoup4 hinzu:
import requests
from bs4 import BeautifulSoup
Definieren Sie anschließend eine Methode, die eine Web-URL entgegennimmt und den Seiteninhalt zurückgibt:
def get_page_contents(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get(url, headers=headers)
if page.status_code == 200:
return page.text
return None
Beachten Sie, dass die get_page_contents-Methode die requests-Bibliothek verwendet, um eine GET-Methode aufzurufen und die text-Antwort zurückzugeben. Beachten Sie außerdem, dass die Methode den User-Agent-Header zusammen mit der GET-Anfrage übergibt, um eine Fehlerantwort vom Webserver zu vermeiden. Die Übergabe des User-Agent-Headers ist optional, aber einige Webserver könnten die Anfrage ablehnen, wenn sie einen unbekannten User Agent erhalten.
Um Zitate und Autoren aus dem Seiteninhalt zu scrapen, definieren Sie eine Methode, die BeautifulSoup verwendet, um die rohen HTML-Daten zu parsen und die gewünschten Daten zurückzugeben:
def get_quotes_and_authors(page_contents):
soup = BeautifulSoup(page_contents, 'html.parser')
quotes = soup.find_all('span', class_='text')
authors = soup.find_all('small', class_='author')
return quotes, authors
Hier nimmt die Methode den page_contents entgegen, der von der get_page_contents-Methode abgerufen wurde. Sie erstellt eine Instanz von BeautifulSoup unter Verwendung des Seiteninhalts und gibt den zu verwendenden Parser-Typ an. Wenn Sie das zweite Argument weglassen, verwendet Beautiful Soup automatisch den besten auf dem Gerät installierten Parser basierend auf dem Seiteninhalt.
Anschließend verwendet es die soup-Instanz, um alle Elemente für Zitate und Autoren zu finden, und nutzt die find_all-Methode, um die Elemente anhand der Tags auszuwählen. Schließlich wird ein CSS-Selektor zur Verfeinerung der Suchkriterien angegeben.
Fügen Sie nun alles zusammen und ergänzen Sie das folgende Code-Snippet am Ende der main.py-Datei:
if __name__ == '__main__':
url = 'http://quotes.toscrape.com'
page_contents = get_page_contents(url)
if page_contents:
quotes, authors = get_quotes_and_authors(page_contents)
for i in range(len(quotes)):
print(quotes[i].text)
print(authors[i].text)
print()
else:
print('Failed to get page contents.')
Dieser Code verwendet get_page_contents zum Abrufen des Seiteninhalts und nutzt diesen, um alle quotes und authors mithilfe der get_quotes_and_authors-Methode zu erhalten. Abschließend iteriert er über die Liste der Zitate und gibt die Ergebnisse aus.
Testen Sie das Skript durch Ausführen des folgenden Befehls:
python main.py
Ihre Ausgabe sollte wie folgt aussehen:
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."
Albert Einstein
--- OUTPUT OMITTED ---
"A day without sunshine is like, you know, night."
Steve Martin
Wie Sie sehen, haben Sie nun erfolgreich ein Scraping-Skript erstellt. Wenn Sie mehr erfahren möchten, lesen Sie unseren Leitfaden zum Web-Scraping mit Python, der einige fortgeschrittenere Scraping-Techniken enthält.
Der gesamte hier verwendete Code ist in diesem GitHub-Repository verfügbar.
Häufige Herausforderungen bewältigen
Je nach Komplexität der zu scrapenden Webseite können beim Scraping folgende Herausforderungen auftreten:
Dynamische Inhalte
Einige Websites laden Inhalte dynamisch über JavaScript, anstatt sie statisch zu rendern (wie die Quotes to Scrape-Webseite, die Sie hier verwendet haben). Die Scraping Sandbox-Startseite listet beispielsweise eine JavaScript-Version derselben Webseite auf, die dynamisch gerendert wird. Prüfen Sie nun, ob das erstellte Skript mit diesem dynamischen Inhalt funktioniert.
Ersetzen Sie die url im main.py-Skript durch folgende:
# update URL in the main.py script
url = 'https://quotes.toscrape.com/js/'
Führen Sie dann das Skript aus. Sie werden feststellen, dass die Ausgabe leer ist.
Wenn Sie dynamische Inhalte rendern und scrapen möchten, müssen Sie einen Headless-Browser wie Selenium verwenden. Ein Headless-Browser läuft ohne grafische Benutzeroberfläche (GUI) und ermöglicht die automatisierte Manipulation einer Webseite in einer Umgebung, die gängigen Webbrowsern ähnelt. Selenium ermöglicht das Scraping von Webseiten, die auf JavaScript angewiesen sind, indem ein echter Browser zum Rendern der Webseiten genutzt wird.
Paginierung
Neben dynamischen Inhalten können Webseiten auch Paginierung auf verschiedene Arten implementieren. Bevor Sie Daten scrapen, müssen Sie verstehen, wie die Paginierung auf der zu scrapenden Website umgesetzt wurde.
Gängige Techniken für die Paginierung umfassen folgende:
Markierungen oder URL-Muster
Die Webseite könnte Markierungen für Vorherige und Nächste Seiten mit URLs enthalten. Außerdem könnte die Website einem bestimmten Muster für paginierte Inhalte folgen. Die Quotes to Scrape-Seite hat beispielsweise eine Nächste-Seiten-Markierung am unteren Rand.
Sie können die Beautiful Soup-Bibliothek verwenden, um die Markierung der nächsten Seite zu finden und deren relativen Link zu erhalten, um die URL für die nächste Seite zu konstruieren und deren Daten zu scrapen.
Endloses Scrollen
Endloses Scrollen bezeichnet das Laden weiterer Inhalte beim Herunterscrollen einer Webseite. Die ToScrape-Website bietet beispielsweise eine Scroll-Version der Quotes to Scrape-Seite, die beim Scrollen weitere Zitate lädt. Für solche Webseiten müssen Sie einen Headless-Browser mit Scroll-Funktionalität verwenden. Sie können Seleniums Scroll-Rad-Aktion nutzen, um die Webseite zu scrollen und weitere Inhalte zu laden.
Fehlerbehandlung
Beim Web-Scraping können gewünschte Elemente manchmal fehlen oder fehlerhafte Daten enthalten. Die Behandlung dieser Szenarien ist entscheidend für konsistente Ergebnisse.
Das Einbetten des Scraper-Codes in einen try-catch-Block verhindert, dass das Skript bei unerwarteten Fehlern abstürzt. Auf der Quotes to Scrape-Website könnte beispielsweise der Autorenname bei einigen Zitaten fehlen. Sie können die get_quotes_and_authors-Methode so anpassen, dass ein try-catch-Block den Fehler abfängt und protokolliert:
def get_quotes_and_authors(page_contents):
soup = BeautifulSoup(page_contents, 'html.parser')
try:
quotes = soup.find_all('span', class_='text')
authors = soup.find_all('small', class_='author')
except Exception as e:
print(e)
return None, None
return quotes, authors
Bonusabschnitt – Tipps und Tricks
In diesem Abschnitt werden einige interessante Tricks vorgestellt, die Ihnen helfen, den Scraping-Prozess mit Beautiful Soup zu optimieren.
Alle verwendeten Tags in einem Dokument finden
Um HTML-Tags zu finden, können Sie Bibliotheken wie Beautiful Soup in Python verwenden. Ein Ansatz besteht darin, eine HTML-Datei mit Beautiful Soup einzulesen und anschließend durch Iteration über ihre Nachkommen eine Liste aller vorhandenen Tags zu extrahieren. Mithilfe des von Beautiful Soup bereitgestellten soup.descendants-Generators können Sie auf den Namen jedes Tags zugreifen und ihn ausgeben, der Teil der HTML-Struktur ist. Dieser Prozess umfasst das Öffnen der HTML-Datei, das Parsing mit Beautiful Soup und die anschließende Iteration durch die Nachkommen, um die Namen der im Dokument vorkommenden HTML-Tags zu identifizieren und anzuzeigen.
Den vollständigen Inhalt aus HTML-Tags extrahieren
Hier ist eine schrittweise Anleitung zur Durchführung dieser Operation:
- Beginnen Sie mit dem Import der erforderlichen Bibliothek BeautifulSoup, die zum Parsing von HTML- und XML-Dokumenten verwendet wird.
- Öffnen Sie die HTML-Datei mit dem zu extrahierenden Inhalt. Nutzen Sie dafür Pythons Dateiverarbeitungsfunktionen. Lesen Sie den Dateiinhalt und speichern Sie ihn in einer Variable.
- Erstellen Sie ein BeautifulSoup-Objekt, indem Sie den Inhalt der HTML-Datei zusammen mit dem angegebenen Parser (in diesem Fall “html.parser”) übergeben.
- Sobald das BeautifulSoup-Objekt erstellt ist, können Sie über die Tag-Namen als Attribute auf bestimmte HTML-Tags im Dokument zugreifen. Wenn Sie beispielsweise den Inhalt innerhalb eines h2-Tags extrahieren möchten, können Sie mit
soup.h2darauf zugreifen. - Ebenso können Sie den Inhalt innerhalb von Absätzen (
<p>) und Listenelementen (<li>) extrahieren, indem Sie mitsoup.pbzw.soup.lidarauf zugreifen. - Durch die Ausführung dieser Anweisungen können Sie den vollständigen Inhalt der angegebenen HTML-Tags in der Reihenfolge ausgeben, in der sie im Dokument erscheinen.
Durch Befolgen dieser Schritte und die Nutzung der BeautifulSoup-Bibliothek können Sie den vollständigen Inhalt aus HTML-Tags in Ihrem HTML-Dokument effektiv extrahieren.
Ethische Überlegungen
Bevor Sie Daten scrapen, müssen Sie die Nutzungsbedingungen der Website überprüfen und einhalten, indem Sie Ihre Skripte entsprechend den definierten Einschränkungen gestalten. Sie sollten die in der robots.txt der Zielwebsite definierten Regeln beim Scraping befolgen.
Stellen Sie außerdem sicher, dass Sie keine personenbezogenen Daten ohne Einwilligung erheben, da dies gegen Datenschutzbestimmungen verstoßen kann.
Sie sollten auch aggressives Scraping vermeiden, das Server überlasten und die Leistung der Website beeinträchtigen kann. Der Webserver könnte Schutzmaßnahmen implementieren, wie die Durchsetzung von Rate-Limits, die Anzeige von CAPTCHAs oder die Sperrung Ihrer IP-Adresse. Wenn möglich, geben Sie die Quellenangabe zur ursprünglichen Website an, um die Bemühungen und Inhalte der Website anzuerkennen.
Web-Scraping optimieren
Um die Zuverlässigkeit und Effizienz Ihrer Web-Scraping-Skripte zu verbessern, sollten Sie die Implementierung einiger der folgenden Techniken in Betracht ziehen:
Parallelisierung verwenden
Erwägen Sie die Nutzung von Parallelisierung in Ihren Skripten durch mehrere Threads für die Verarbeitung verschachtelter Daten. Auf der Quotes to Scrape-Webseite können Sie beispielsweise das Skript so anpassen, dass alle Zitat-div-Blöcke gefunden und parallel verarbeitet werden. Diese Technik kann die Ausführungsgeschwindigkeit eines Skripts erheblich verbessern, wenn der DOM-Baum komplex ist.
Wiederholungslogik hinzufügen
Das Hinzufügen einer Wiederholungslogik für Netzwerkaufrufe im Skript kann dessen Zuverlässigkeit verbessern. In diesem Anwendungsfall könnten Sie beispielsweise eine Wiederholungslogik für get_page_contents hinzufügen, um sicherzustellen, dass das Skript nicht fehlschlägt, wenn der Seiteninhalt beim ersten Versuch nicht abgerufen werden kann.
User Agents rotieren
Wenn ein Webserver eine große Anzahl von Anfragen vom selben User Agent erhält, könnte er Ihre Anfragen blockieren. Um dieses Problem zu umgehen, können Sie die User Agents rotieren, indem Sie mit jeder Anfrage einen neuen User-agent generieren. Beachten Sie, dass die get_page_contents-Methode einen statischen User-agent-Header an den requests.get-API-Aufruf übergibt. Sie können eine Methode namens get_random_user_agent definieren, die einen dynamischen User Agent generiert.
Rate-Limiting implementieren
Der Webserver könnte Ihre Anfragen blockieren oder ablehnen, wenn Sie zu viele Anfragen in kurzer Zeit senden. Um dieses Problem zu lösen, können Sie manuelle Verzögerungen zwischen den Anfragen implementieren.
Einen Proxy-Server verwenden
Sie können einen Proxy-Server als Vermittler zwischen Ihrem Scraping-Skript und den Zielseiten verwenden. Ein Proxy-Server hilft dabei, die IP-Adresse beim Abrufen von Webseiteninhalt zu rotieren und IP-Sperren zu vermeiden. Erfahren Sie mehr über Python IP-Rotation.
Bright Data bietet mehrere Proxy-Netzwerke, leistungsstarke Web-Scraper und gebrauchsfertige Datensätze zum Download an. Bright Data stellt auch verschiedene Proxy-Dienste bereit, darunter Residential-Proxys, Datacenter-Proxys, ISP-Proxys und Mobile-Proxys, um Ihren Web-Scraping-Anforderungen gerecht zu werden. Wenn Sie Ihr Web-Scraping auf die nächste Stufe heben möchten, sollten Sie dies mit Bright Data tun.
Fazit
Beautiful Soup ist ein wertvolles Tool für Web-Scraping und lässt sich nahtlos mit verschiedenen XML- und HTML-Parsern integrieren. Sobald Sie die zu scrapenden Daten identifiziert und die Struktur der Webseite verstanden haben, können Sie die Beautiful Soup Python-Bibliothek verwenden, um schnell ein Skript zu schreiben. Je nach Komplexität der Webseite müssen Sie jedoch möglicherweise Herausforderungen im Zusammenhang mit dynamischen Inhalten, Paginierung und Fehlern bewältigen.
Wenn Sie Ihren Entwicklungsaufwand reduzieren und Ihr Scraping skalieren möchten, sollten Sie das Serverless Functions-Produkt in Betracht ziehen, das auf der entsperrenden Proxy-Infrastruktur aufbaut. Es enthält vorgefertigte JavaScript-Funktionen und Code-Vorlagen von beliebten Websites. Suchen Sie eine einfache, vollautomatische Lösung mit produktionsreifen APIs? Probieren Sie die neue Web Scraping API aus.
Darüber hinaus bieten die Bright Data Proxy-Dienste eine fortschrittliche Proxy-Infrastruktur mit effizienter Leistung und der Möglichkeit, geografische Einschränkungen mit Proxys aus 195 Ländern zu umgehen. Der Dienst ist konform mit der Datenschutz-Grundverordnung (DSGVO) und dem California Consumer Privacy Act (CCPA) und funktioniert mit allen gängigen Programmiersprachen.






