

In diesem Leitfaden erfahren Sie mehr:
- Warum Sie den Unterschied zwischen statischen und dynamischen Inhalten kennen sollten
- Was statische Inhalte sind, wie man sie erkennt, welche Tools man zum Scrapen verwendet und welche Herausforderungen damit verbunden sind
- Was sind dynamische Inhalte, wie erkennt man sie, welche Tools eignen sich am besten für das Scraping, und welche Hindernisse können auftreten?
- Eine Vergleichstabelle für statische und dynamische Inhalte im Zusammenhang mit Web Scraping
Lasst uns eintauchen!
Eine Einführung in statische und dynamische Inhalte beim Web Scraping
Beim Web Scraping gibt es einen erheblichen Unterschied in der Vorgehensweise, je nachdem, ob der zu extrahierende Inhalt statisch oder dynamisch ist. Diese Unterscheidung wirkt sich stark darauf aus, wie Sie die Datenanalyse, -verarbeitung und -extraktion handhaben.
Als Faustregel gilt, dass für SEO optimierte Abschnitte oder Seiten eher statisch sind. Hochgradig interaktive Abschnitte oder solche, die Live-Updates erfordern, sind hingegen in der Regel dynamisch. In den meisten Fällen ist die Realität jedoch komplexer.
Moderne Webseiten sind oft hybride Seiten, d. h. sie enthalten sowohl statische als auch dynamische Inhalte. Daher ist die Bezeichnung einer ganzen Seite als “statisch” oder “dynamisch” in der Regel ungenau. Präziser ist es, zu sagen, dass bestimmte Inhalte auf der Seite entweder statisch oder dynamisch sind.
Noch komplizierter wird es, wenn eine Seite einer Website statisch ist, während eine andere Seite derselben Website dynamisch sein kann. Genauso wie eine einzelne Webseite beide Arten von Inhalten enthalten kann, kann eine Website eine Sammlung von statischen und dynamischen Seiten sein.
Machen Sie sich also auf den folgenden Vergleich zwischen statischen und dynamischen Inhalten gefasst!
Statischer Inhalt
Im Folgenden erfahren Sie alles, was Sie über statische Inhalte in Webseiten wissen müssen, und wie Sie diese auslesen können.
Was ist statischer Inhalt?
Statische Inhalte sind alle Elemente auf einer Webseite, die direkt in das vom Server zurückgegebene HTML-Dokument eingebettet sind. Mit anderen Worten, sie erfordern kein Rendering auf der Client-Seite und keinen zusätzlichen Datenabruf durch den Browser. Somit ist alles bereits in der ursprünglichen HTML-Antwort enthalten.
Dazu gehören in der Regel Elemente der Benutzeroberfläche, Text, Bilder und andere Inhalte, die sich nicht ändern, solange der serverseitige Quellcode nicht aktualisiert wird. Selbst wenn der Server dynamisch Daten aus Datenbanken oder APIs abruft, bevor er das HTML-Dokument erzeugt und an den Client sendet, wird der Inhalt aus Sicht des Clients als statisch betrachtet. Der Grund dafür ist, dass im Browser keine weitere Verarbeitung erforderlich ist.
Wie man erkennt, ob eine Webseite statischen Inhalt verwendet
Wie bereits in der Einleitung erwähnt, sind moderne Websites selten zu 100 % statisch. Schließlich enthalten die meisten Webseiten ein gewisses Maß an clientseitiger Interaktivität. Die eigentliche Frage ist also nicht, ob eine Seite vollständig statisch oder dynamisch ist, sondern vielmehr, welche Teile der Seite statische Inhalte verwenden.
Um festzustellen, ob ein Inhalt statisch ist, müssen Sie das vom Server zurückgegebene HTML-Rohdokument untersuchen. Beachten Sie, dass dies nicht dasselbe ist wie das, was Sie in Ihrem Browser sehen. Der Browser zeigt das gerenderte DOM an, das nach dem Laden der Seite durch JavaScript geändert werden kann.
Es gibt zwei einfache Möglichkeiten zu prüfen, ob eine Seite statische Inhalte verwendet und welche Elemente statisch sind:
- Quelle der Seite anzeigen
- Einen HTTP-Client verwenden
Um die erste Methode anzuwenden, klicken Sie mit der rechten Maustaste auf einen leeren Bereich der Seite und wählen Sie die Option “Seitenquelle anzeigen”:

Das Ergebnis ist das vom Server zurückgegebene Original-HTML:

In diesem Fall können Sie zum Beispiel feststellen, dass die Anführungszeichen-Elemente bereits in diesem HTML-Code vorhanden sind. Daher können Sie sicher davon ausgehen, dass sie statisch sind.
Bei der zweiten Methode wird eine einfache GET-Anfrage an die URL der Seite mit einem HTTP-Client durchgeführt:

Auch hier wird das vom Server zurückgegebene Roh-HTML angezeigt. Da HTTP-Clients kein JavaScript ausführen können, müssen Sie sich keine Gedanken über DOM-Änderungen machen. Dennoch – und darauf werden wir noch zu sprechen kommen – könnte Ihre Anfrage vom Server aufgrund von Anti-Bot-Schutzmaßnahmen blockiert werden. Daher ist die Methode “Seitenquelltext anzeigen” die empfohlene Vorgehensweise.
Tools für das Scraping statischer Inhalte
Das Scraping statischer Inhalte ist einfach, da sie direkt in den HTML-Quelltext der Seite eingebettet sind. Im Folgenden finden Sie einen grundlegenden Überblick über den Prozess:
- Rufen Sie das HTML-Dokument ab, indem Sie mit einem einfachen HTTP-Client eine GET-Anfrage an die URL der Seite stellen.
- Parsen Sie die Antwort mit einem HTML-Parser.
- Extrahieren Sie die gewünschten Elemente mithilfe von CSS-Selektoren, XPath oder ähnlichen Strategien, die vom HTML-Parser bereitgestellt werden.
Wenn Sie nach Tools für das Scraping von Inhalten suchen, lesen Sie unsere ausführlichen Anleitungen:
Ein vollständiges Beispiel für die Seite “Quotes to Scrape” – deren HTML in einem früheren Abschnitt gezeigt wurde – finden Sie in unserem Tutorial über Web Scraping mit Python.
Einige beliebte Scraping-Stacks zum Abrufen statischer Inhalte sind:
- Python: Requests + Beautiful Soup, HTTPX + Beautiful Soup, AIOHTTP + Beautiful Soup
- JavaScript: Axios + Cheerio, Node Fetch + Cheerio, Fetch API + Cheerio
- PHP: cURL + DomCrawler, Guzzle + DomCrawler, cURL + einfacher HTML-DOM-Parser
- C#: HttpClient + HtmlAgilityPack, HttpClient + AngleSharp
“BeautifulSoup ist schneller und verbraucht weniger Speicher als Selenium. Es führt kein JavaScript aus und macht nichts anderes als HTML zu parsen und mit dem DOM zu arbeiten.” – Diskussion auf Reddit
Herausforderungen beim Scraping statischer Inhalte
Die größte Herausforderung beim Scraping statischer Inhalte besteht darin, die richtige HTTP-Anfrage zu stellen, um das HTML-Dokument abzurufen. Viele Server sind so konfiguriert, dass sie Inhalte nur echten Browsern zur Verfügung stellen. Daher können sie Ihre Anfrage blockieren, wenn bestimmte Header fehlen oder TLS-Fingerprinting-Prüfungen fehlschlagen.
Um diese Probleme zu vermeiden, sollten Sie manuell die richtigen HTTP-Header für Web Scraping setzen. Alternativ können Sie einen fortschrittlichen HTTP-Client verwenden, der das Verhalten des Browsers simulieren kann, wie z. B. cURL Impersonate.
Für eine professionelle Lösung, die nicht auf umständliche Tricks oder Workarounds in Ihrem Code angewiesen ist, sollten Sie den Web Unlocker verwenden. Dabei handelt es sich um einen Endpunkt, der den HTML-Code einer beliebigen Webseite zurückgibt, unabhängig von den vom Server implementierten Schutzmechanismen.
Wenn Sie außerdem zu viele Anfragen von derselben IP-Adresse senden, kann dies zu einer Ratenbegrenzung oder sogar zu einer IP-Sperre führen. Um dies zu verhindern, sollten Sie rotierende Proxys integrieren, um Ihre Anfragen auf mehrere IPs zu verteilen. In unserem Leitfaden erfahren Sie, wie Sie IP-Sperren mit Proxys vermeiden können.
Dynamischer Inhalt
Fahren wir mit diesem Leitfaden zu statischen und dynamischen Inhalten fort, indem wir untersuchen, wie dynamische Inhalte von Webseiten geladen oder gerendert werden und wie man sie abgreift.
Was sind dynamische Inhalte?
Auf Webseiten bezieht sich dynamischer Inhalt auf alle Inhalte, die auf der Client-Seite geladen oder gerendert werden – entweder beim ersten Laden der Seite oder nach der Benutzerinteraktion. Dazu gehören Daten, die über Technologien wie AJAX und WebSockets abgerufen werden, sowie in JavaScript eingebettete Inhalte, die zur Laufzeit im Browser gerendert werden.
Insbesondere ist der dynamische Inhalt nicht Teil des ursprünglichen HTML-Dokuments, das vom Server zurückgegeben wird. Das liegt daran, dass er der Seite nach der Ausführung von JavaScript hinzugefügt wird. Das bedeutet, dass er erst sichtbar wird, wenn die Seite in einem Browser gerendert wird – dem einzigen Tool, das JavaScript ausführen kann.
Wie man erkennt, ob eine Webseite dynamischen Inhalt verwendet
Der einfachste Weg, um festzustellen, ob eine Seite dynamisch ist oder nicht, ist der umgekehrte Ansatz, der zur Erkennung statischer Inhalte verwendet wird. Wenn das vom Server zurückgegebene HTML-Dokument nicht den Inhalt enthält, den Sie auf der Seite sehen, dann gibt es irgendeinen Mechanismus, um diesen Inhalt dynamisch auf dem Client abzurufen oder darzustellen.
Der umgekehrte Weg funktioniert nicht unbedingt. Wenn der vom Server zurückgegebene HTML-Code einen Inhalt enthält, bedeutet das nicht, dass die Seite völlig statisch ist. Dieser Inhalt kann veraltet sein, und der Client könnte ihn entweder einmal oder in regelmäßigen Abständen nach dem Laden der Seite dynamisch aktualisieren. Dies ist z. B. häufig bei Seiten der Fall, die Live-Updates anzeigen.
Im Allgemeinen können Sie feststellen, ob eine Seite dynamische Inhalte enthält, indem Sie die Seite neu laden oder die Benutzeraktion wiederholen, die den Inhalt erscheinen lässt, während Sie den Abschnitt “Netzwerk” in den DevTools Ihres Browsers untersuchen:
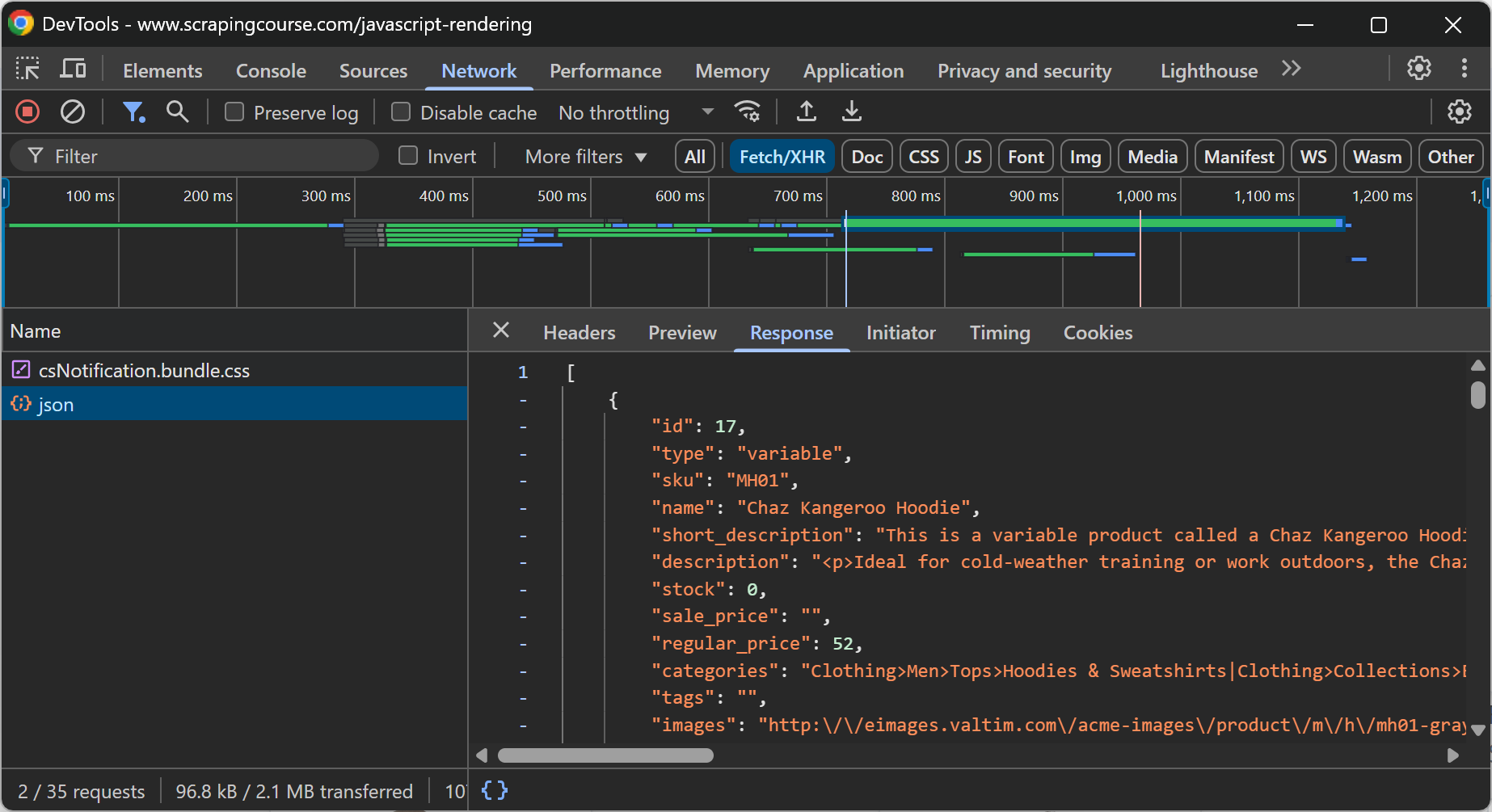
Auf der obigen Webseite ist beispielsweise ersichtlich, dass die E-Commerce-Daten dynamisch im Client durch einen API-Aufruf über AJAX abgerufen werden.
Eine weitere mögliche Quelle für dynamische Inhalte sind Webanwendungen, die als SPAs(Single-Page Applications) erstellt wurden. Diese werden von Frontend-Technologien wie React angetrieben, die sich stark auf das Rendering von JavaScript stützen. Wenn sich also das DOM, das Sie in DevTools sehen, stark von dem HTML unterscheidet, das vom Server zurückgegeben wird, dann ist die Seite dynamisch.
Tools für das Scraping dynamischer Inhalte
Dynamische Inhalte erfordern die Ausführung von JavaScript, um gerendert oder abgerufen werden zu können. Da nur Browser JavaScript ausführen können, sind Ihre Möglichkeiten zum Scraping dynamischer Inhalte im Allgemeinen auf Browser-Automatisierungstools wie Playwright, Selenium und Puppeteer beschränkt.
Diese Tools stellen APIs zur Verfügung, mit denen Sie einen echten Browser programmatisch steuern können. Für das Web-Scraping dynamischer Inhalte sind daher diese drei Schritte erforderlich:
- Weisen Sie den Browser an, zur Zielseite zu navigieren.
- Warten Sie, bis bestimmte dynamische Inhalte auf der Seite erscheinen.
- Wählen Sie den Inhalt aus und extrahieren Sie ihn mithilfe der von ihnen bereitgestellten APIs für die Knotenauswahl und Datenextraktion.
Weitere Anleitungen finden Sie in unserem Artikel über das Scrapen dynamischer Websites in Python.
Herausforderungen beim Scraping dynamischer Inhalte
Das Scraping dynamischer Inhalte ist von Natur aus viel schwieriger als das Scraping statischer Inhalte. Erstens, weil Sie in Ihrem Code möglicherweise Benutzerinteraktionen simulieren müssen, um alle für den Zugriff auf den Inhalt erforderlichen Aktionen nachzubilden. Das kann ein Problem sein, wenn es sich um Websites mit einer komplexen Navigation handelt.
Zweitens, weil auf dynamischen Webseiten oft fortschrittliche Anti-Scraping- und Anti-Bot-Maßnahmen wie CAPTCHAs, JavaScript-Challenges, Browser-Fingerprinting usw. eingesetzt werden.
Bedenken Sie auch, dass Browser-Automatisierungstools den Browser instrumentieren müssen, um ihn zu kontrollieren. Diese Änderungen an den Browsereinstellungen können ausreichen, damit fortgeschrittene Anti-Bot-Systeme Sie als Bot erkennen. Dies gilt insbesondere, wenn Sie den Browser im Headless-Modus steuern, um Ressourcen zu sparen.
Ein Open-Source-Workaround für diese Probleme ist die Verwendung von Browser-Automatisierungsbibliotheken mit integrierten Anti-Bot-Umgehungsfunktionen, wie SeleniumBase, Undetected ChromeDriver, Playwright Stealth oder Puppeteer Stealth.
Dennoch sind diese Lösungen nur die Spitze des Eisbergs und unterliegen allen Problemen, die beim Scraping von statischen Inhalten auftreten, wie IP-Sperren, IP-Reputationsprobleme und mehr. Deshalb ist der effektivste Ansatz die Verwendung einer Lösung wie dem Scraping Browser von Bright Data, der:
- Integrierbar mit Puppeteer, Playwright, Selenium und jedem anderen Browser-Automatisierungstool
- Läuft in der Cloud und ist unendlich skalierbar
- Arbeitet mit einem Proxy-Netzwerk von über 150 Millionen IPs
- Arbeitet im Headful-Modus, um eine Headless-Erkennung zu vermeiden
- Mit eingebauten CAPTCHA-Lösungsfunktionen
- Verfügt über erstklassige Anti-Bot-Umgehungsfunktionen
Statische vs. dynamische Inhalte für Web Scraping: Vergleichstabelle
Dies ist eine zusammenfassende Tabelle, in der statische und dynamische Inhalte für Web Scraping verglichen werden:
| Aspekt | Statischer Inhalt | Dynamischer Inhalt |
|---|---|---|
| Definition | Direkt in die erste HTML-Antwort des Servers eingebetteter Inhalt | Inhalte, die über JavaScript geladen oder gerendert werden, nachdem die Seite geladen wurde |
| Sichtbarkeit in HTML | Sichtbar in dem vom Server zurückgegebenen HTML-Rohdokument | Im ursprünglichen HTML-Dokument nicht sichtbar |
| Standort des Renderings | Server-seitiges Rendering | Client-seitiges Rendering |
| Erkennungsmethoden | – Option “Seitenquelltext anzeigen – HTML in einem HTTP-Client inspizieren |
– Unterschiede zwischen Quell-HTML und gerendertem DOM prüfen – Untersuchen Sie die Registerkarte “Netzwerk” von DevTools |
| Häufige Anwendungsfälle | – SEO-orientierter Inhalt – Einfache Info-Listen |
– Live-Aktualisierungen – Benutzerspezifische Dashboards – SPA-Inhalt |
| Schwierigkeiten beim Kratzen | Einfach | Von mittel bis hart |
| Scraping-Ansatz | HTTP-Client + HTML-Parser | Werkzeuge zur Browser-Automatisierung |
| Leistung | Schnell, da kein JS-Rendering erforderlich ist | Langsam, da die Seiten im Browser gerendert werden und auf das Laden von Elementen gewartet werden muss |
| Wichtigste Herausforderungen beim Scrapen | – TLS-Fingerprinting – Ratenbegrenzung – IP-Sperren |
– CAPTCHAs – Komplexe Navigation/Interaktionsabläufe – JS-Herausforderungen |
| Empfohlene Werkzeuge zur Vermeidung von Blockaden | Proxies, Web Unlocker | Scraping-Browser |
| Beispiel Stapel | Anfragen + Schöne Suppe | Dramaturg, Selenium, oder Puppenspieler |
Eine Liste von Scraping-Tools in bestimmten Programmiersprachen, die beide Szenarien abdecken, finden Sie in den folgenden Leitfäden:
- Beste JavaScript-Bibliotheken für Web Scraping
- Beste Python-Bibliotheken für Web-Scraping
- Die 7 besten PHP-Bibliotheken für Web-Scraping
- Top 7 C# Web Scraping Bibliotheken
Schlussfolgerung
In diesem Artikel haben Sie die Unterschiede zwischen statischen und dynamischen Inhalten auf Webseiten verstanden, wobei der Schwerpunkt auf Web Scraping lag. Sie haben gelernt, was diese beiden Arten von Inhalten sind, wie sie sich unterscheiden und wie man beide beim Parsen von Webdaten behandelt.
Unabhängig davon, ob Sie es mit statischen oder dynamischen Inhalten zu tun haben, können die Dinge aufgrund von Anti-Scraping- und Anti-Bot-Maßnahmen kompliziert werden. Hier kommt Bright Data ins Spiel und bietet eine umfassende Reihe von Tools, die alle Ihre Scraping-Anforderungen abdecken:
- Proxy-Dienste: Mehrere Arten von Proxys zur Umgehung von Geobeschränkungen, mit mehr als 150 Mio. IPs[1].
- Scraping-Browser: Ein Playright-, Selenium-, Puppeter-kompatibler Browser mit eingebauten Freischaltfunktionen.
- Web Scraper APIs: Vorkonfigurierte APIs zum Extrahieren strukturierter Daten aus über 100 wichtigen Domains.
- Web Unlocker: Eine All-in-One-API, die die Freischaltung von Websites mit Anti-Bot-Schutz ermöglicht.
- SERP-API: Eine spezielle API, die Suchmaschinenergebnisse freischaltet und vollständige SERP-Daten von allen großen Suchmaschinen extrahiert[2].
Erstellen Sie ein Bright Data-Konto und testen Sie unsere Scraping-Produkte mit einer kostenlosen Testversion!





