

Web-Scraping ist eine Technik, mit der Sie Daten aus Webseiten extrahieren können. Sie ist besonders nützlich, wenn die Zielwebsite keine API anbietet, die API nicht verwendet werden kann oder nicht genau die gewünschten Daten zurückgibt.
Regex, kurz für „reguläre Ausdrücke“, ist ein leistungsstarkes Grammatikmuster zum Extrahieren von Daten aus Texten und wird häufig für das Web-Scraping verwendet. Regex definiert ein Muster, das in Texten abgeglichen werden kann, und wird häufig zum Auffinden und Extrahieren von Informationen aus Texten verwendet. Daher wird es häufig beim Web-Scraping eingesetzt.
In diesem Artikel erfahren Sie, wie Sie Regex inPython für das Web-Scraping verwenden können. Am Ende des Artikels wissen Sie, wie Sie statische und dynamische Websites scrapen können, und Sie haben ein Verständnis für einige der Einschränkungen, mit denen Sie möglicherweise konfrontiert werden.
Was ist Regex
Ein regulärer Ausdruck wird mithilfe von Tokens definiert, die einem bestimmten Muster entsprechen. Eine detaillierte Beschreibung aller Tokens würde den Rahmen dieses Artikels sprengen, aber in der folgenden Tabelle sind einige häufig verwendete Tokens aufgeführt, denen Sie wahrscheinlich begegnen werden:
| Token | Übereinstimmungen |
|---|---|
| Jedes Nicht-Sonderzeichen | Das angegebene Zeichen |
^ |
Beginn einer Zeichenfolge |
$ |
Ende einer Zeichenfolge |
. |
Jedes Zeichen außer n |
* |
Null oder mehr Vorkommen des vorherigen Elements |
? |
Null oder ein Vorkommen des vorherigen Elements |
+ |
Ein oder mehrere Vorkommen der vorherigen Zeichen |
{Ziffer} |
Genaue Anzahl des vorherigen Elements |
d |
Beliebige Ziffer |
s |
Beliebiges Leerzeichen |
w |
Beliebige Wortzeichen |
D |
Umkehrung von d |
S |
Umkehrung von s |
W |
Umkehrung von w |
Um mehr über Regex zu erfahren und praktische Erfahrungen zu sammeln, besuchen Sieregexr.com. Darüber hinaus enthältdieser Artikeleinige wichtige Tipps zur Optimierung Ihrer Regex-Leistung.
Verwendung von Regex in Python für das Web-Scraping
In diesem Tutorial erstellen Sie einen einfachen Web-Scraper in Python, der Regex verwendet, um Daten aus Webseiten zu extrahieren.
Erstellen Sie zunächst ein Verzeichnis für Ihr Projekt:
mkdir web_scraping_with_regex
cd web_scraping_with_regex
Erstellen Sie dann eine virtuelle Python-Umgebung:
python -m venv venv
Und aktivieren Sie diese:
source ./venv/bin/activate
Um den Web-Scraper zu schreiben, müssen Sie zwei Bibliotheken installieren:
requestszum Abrufen von Webseitenbeautifulsoup4zum Parsing des HTML-Inhalts und zum Auffinden von Elementen
Führen Sie den folgenden Befehl aus, um die Bibliotheken zu installieren:
pip install beautifulsoup4 requests
Hinweis: Bevor Sie eine Website scrapen, lesen Sie unbedingt deren Nutzungsbedingungen, um sicherzustellen, dass Sie die Website scrapen dürfen. Sie sollten keine Website scrapen, wenn dies verboten ist.
Scraping einer E-Commerce-Website
In diesem Abschnitt erstellen Sie einen Scraper, um eine einfacheDummy-E-Commerce-Website zu scrapen. Sie scrapen die erste Seite und extrahieren die Titel und Preise der Bücher.
Erstellen Sie dazu eine Datei mit dem Namen scraper.py und importieren Sie die erforderlichen Module:
import requests
from bs4 import BeautifulSoup
import re
Hinweis: Das Modul
„re”ist ein in Python integriertes Modul, das mit regulären Ausdrücken arbeitet.
Als Nächstes müssen Sie eine GET-Anfrage an die Zielwebseite senden, um den HTML-Inhalt der Seite abzurufen:
page = requests.get('https://books.toscrape.com/')
Übergeben Sie diese Daten an Beautiful Soup, das das Parsing der HTML-Struktur der Webseite durchführt:
soup = BeautifulSoup(page.content, 'html.parser')
Um herauszufinden, wie die Elemente in HTML strukturiert sind, verwenden Sie das Tool„Element untersuchen”. Öffnen Sie dieWebseiteim Browser und drücken SieStrg + Umschalt + I, um denInspektor zu öffnen. Wie Sie im Screenshot sehen können, sind die Produkte inli-Elementenmit der Klassecol-xs-6 col-sm-4 col-md-3 col-lg-3 gespeichert. Der Buchtitel kann ausa-Elementendurch Auslesen ihresTitelattributsermittelt werden, und die Preise sind inp-Elementenmit der Klasseprice_color gespeichert:
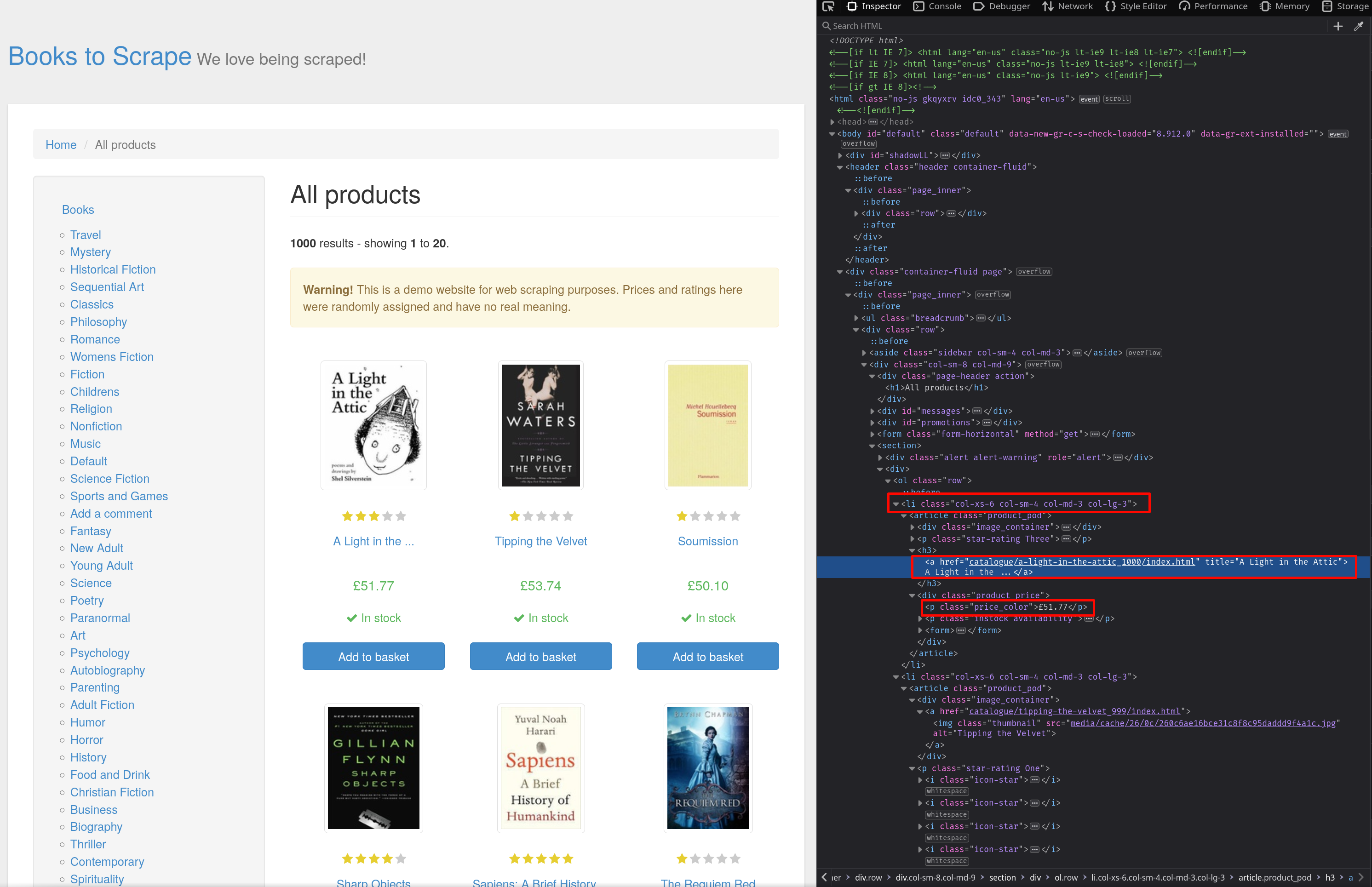
Verwenden Sie die Methode find_all von Beautiful Soup, um alle li-Elemente mit der Klasse col-xs-6 col-sm-4 col-md-3 col-lg-3 zu finden:
books = soup.find_all("li", class_="col-xs-6 col-sm-4 col-md-3 col-lg-3")
content = str(books)
Die Variable content enthält nun den HTML-Text der li-Elemente, und Sie können mit Hilfe von Regex die Titel und Preise extrahieren.
Der erste Schritt besteht darin, einen regulären Ausdruck zu erstellen, der mit den Titeln und Preisen des Textes übereinstimmt. Dazu müssen Sie erneut die Funktion „Element untersuchen” verwenden.
Beachten Sie, dass die Titel der Bücher im Attribut „title“ der a-Elemente gespeichert sind und die a-Elemente wie folgt aussehen:
<a href="..." title="...">
Um den Inhalt der doppelten Anführungszeichen nach dem Titel abzugleichen, verwenden Sie den klassischen regulären Ausdruck .*?. Das . entspricht einem einzelnen Zeichen, das * entspricht null oder mehr Vorkommen des vorangehenden Elements (in diesem Fall alles, was mit . übereinstimmt) und das ? entspricht null oder einem Vorkommen des vorangehenden Elements (in diesem Fall alles, was mit .* übereinstimmt). Zusammen werden sie verwendet, um den Inhalt der doppelten Anführungszeichen in diesem vollständigen Ausdruck abzugleichen:
<a href=".*?" title="(.*?)"
Die Klammern um.*?werden verwendet, um eineErfassungsgruppe zu erstellen. Erfassungsgruppen speichern die Informationen über die Musterübereinstimmung und werden in komplizierten Ausdrücken verwendet, um bereits übereinstimmende Muster zu identifizieren und darauf zurückzugreifen. In diesem Fall wird die Erfassungsgruppe jedoch verwendet, um den übereinstimmenden Text zu extrahieren. Ohne die Erfassungsgruppe würde der Text zwar immer noch übereinstimmen, aber Sie könnten nicht auf den übereinstimmenden Text zugreifen.
Um den Preis zu extrahieren, verwenden Sie denselben regulären Ausdruck (.*?). Die Preise sind in p-Elementen mit der Klasse price_color gespeichert, sodass der vollständige reguläre Ausdruck <p class="price_color">(.*?)</p> lautet.
Definieren Sie die beiden Muster:
re_book_title = r'<a href=".*?" title="(.*?)"'
re_prices = r'<p class="price_color">(.*?)</p>'
Hinweis:Falls Sie sich fragen, warum das
?nach.*benötigt wird, erklärtdiese Antwort auf Stack Overflowdie Rolle von?gut.
Jetzt können Sie re.findall() verwenden, um alle Regex-Übereinstimmungen aus der HTML-Zeichenkette zu finden:
titles = re.findall(re_book_title, content)
prices = re.findall(re_prices, content)
Schließlich durchlaufen Sie die Übereinstimmungen und geben die Ergebnisse aus:
for i in zip(titles, prices):
print(f"{i[0]}: {i[1]}")
Sie können diesen Code mit python scraper.py ausführen. Die Ausgabe sieht wie folgt aus:
A Light in the Attic: 51,77 £
Tipping the Velvet: 53,74 £
Soumission: 50,10 £
Sharp Objects: 47,82 £
Sapiens: A Brief History of Humankind: 54,23 £
The Requiem Red: 22,65 £
The Dirty Little Secrets of Getting Your Dream Job: 33,34 £
The Coming Woman: Ein Roman über das Leben der berüchtigten Feministin Victoria Woodhull: 17,93 £
The Boys in the Boat: Neun Amerikaner und ihr epischer Kampf um Gold bei den Olympischen Spielen 1936 in Berlin: 22,60 £
The Black Maria: 52,15 £
Starving Hearts (Triangular Trade Trilogy, #1): 13,99 £
Shakespeares Sonette: 20,66 £
Befreie mich: 17,46 £
Scott Pilgrims kostbares kleines Leben (Scott Pilgrim #1): 52,29 £
Zerreiße es und fang von vorne an: 35,02 £
Unsere Band könnte dein Leben sein: Szenen aus der amerikanischen Indie-Underground-Szene, 1981–1991: 57,25 £
Olio: 23,88 £
Mesaerion: Die besten Science-Fiction-Geschichten 1800–1849: 37,59 £
Libertarismus für Anfänger: 51,33 £
Es ist nur der Himalaya: 45,17 £
Eine Wikipedia-Seite scrapen
Nun erstellen wir einen Scraper, der eineWikipedia-Seitescrapen und Informationen über alle Links extrahieren kann.
Erstellen Sie eine neue Datei mit dem Namen wiki_scraper.py. Beginnen Sie wie zuvor mit dem Importieren der Bibliotheken, dem Erstellen einer GET-Anfrage und dem Parsing des Inhalts:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
Um alle Links zu finden, verwenden Sie die Methode find_all():
links = soup.find_all("a")
content = str(links)
Die Linktexte werden im Attribut „title ” gespeichert, die Link-URLs im Attribut „href ”. Sie können denselben regulären Ausdruck (.*?) verwenden, um die Informationen zu extrahieren. Der vollständige Ausdruck sieht wie folgt aus:
<a href="(.*?)" title="(.*?)">.*?</a>
Beachten Sie, dass das dritte .*? nicht in einer Erfassungsgruppe enthalten ist, da Sie nicht am Inhalt der a- Tags interessiert sind.
Verwenden Sie wie zuvor findall(), um alle Übereinstimmungen zu finden und das Ergebnis auszugeben:
re_links = r'<a href="(.*?)" title="(.*?)">.*?</a>'
links = re.findall(re_links, content)
for i in links:
print(f"{i[0]} => {i[1]}")
Wenn Sie dies mit python wiki_scraper.py ausführen, erhalten Sie die folgende Ausgabe:
AUSGABE DER KÜRZE HINWEG GEKÜRZT
/wiki/Category:Web-Scraping => Category:Web-Scraping
/wiki/Category:CS1_maint:_multiple_names:_authors_list => Category:CS1 maint: multiple names: authors list
/wiki/Category:CS1_Danish-language_sources_(da) => Category:CS1 Danish-language sources (da)
/wiki/Category:CS1_French-language_sources_(fr) => Category:CS1 French-language sources (fr)
/wiki/Kategorie:Artikel_mit_kurzer_Beschreibung => Kategorie:Artikel mit kurzer Beschreibung
/wiki/Kategorie:Kurzbeschreibung_stimmt_mit_Wikidata_überein => Kategorie:Kurzbeschreibung stimmt mit Wikidata überein
/wiki/Kategorie:Artikel,_die_zusätzliche_Quellenangaben_ab_April_2023_benötigen => Kategorie:Artikel, die zusätzliche Quellenangaben ab April 2023 benötigen
/wiki/Kategorie:Alle_Artikel,_die_zusätzliche_Quellenangaben_benötigen => Kategorie:Alle Artikel, die zusätzliche Quellenangaben benötigen
/wiki/Kategorie:Artikel_mit_begrenztem_geografischem_Umfang_ab_Oktober_2015 => Kategorie:Artikel mit begrenztem geografischem Umfang ab Oktober 2015
/wiki/Kategorie:USA-zentriert => Kategorie:USA-zentriert
/wiki/Kategorie:Alle_Artikel_mit_nicht_quellengestützten_Aussagen => Kategorie:Alle Artikel mit nicht quellenangegebenen Aussagen
/wiki/Kategorie:Artikel_mit_nicht_quellengestützten_Aussagen_aus_April_2023 => Kategorie:Artikel mit nicht quellenangegebenen Aussagen aus April 2023
Scraping einer dynamischen Website
Bisher waren alle von Ihnen gescrapten Webseiten statisch. Das Web-Scraping dynamischer Webseiten ist etwas schwieriger, da hierfür ein Browser-Automatisierungstool wieSelenium erforderlich ist. Im Folgenden finden Sie ein Beispiel für das Web-Scraping derOpenWeatherMap-Homepagefür London und die Verwendung von Regex und Selenium zum Scraping der aktuellen Temperatur:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
driver = webdriver.Firefox()
driver.get("https://openweathermap.org/city/2643743")
elem = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, ".current-temp")))
content = elem.get_attribute('innerHTML')
re_temp = r'<span .*?>(.*?)</span>'
temp = re.findall(re_temp, content)
print(repr(temp))
driver.close()
Dieser Code verwendet Selenium, um eine Instanz von Firefox zu starten, und wählt mit dem CSS-Selektor das Element mit der aktuellen Temperatur aus. Anschließend wird mit dem regulären Ausdruck <span .*?>(.*?)</span> die Temperatur extrahiert.
Wenn Sie weitere Informationen suchen, die Ihnen den Einstieg in das Web-Scraping dynamischer Webseiten mit Selenium erleichtern, sehen Sie sichdieses Tutorial an.
Einschränkungen von Regex für das Web-Scraping
Reguläre Ausdrücke sind leistungsstarke Werkzeuge für die Mustererkennung und das Extrahieren von Informationen aus Texten. Entwickler lernen oft Regex und versuchen, es für das Web-Scraping zu verwenden. Allerdings ist Regex allein nicht für das Web-Scraping geeignet. Regex funktioniert mit Text und hat kein Konzept oder Verständnis für HTML-Strukturen. Das bedeutet, dass die Ergebnisse stark von der Art und Weise abhängen, wie der HTML-Code geschrieben ist. Im Wikipedia-Beispiel haben Sie vielleicht bemerkt, dass einige Links nicht korrekt extrahiert wurden:

Wenn Sie den Python-Code bearbeiten und print(content) hinzufügen, um die von Beautiful Soup zurückgegebene HTML-Zeichenfolge auszugeben, sehen Sie, dass der Fehler wie folgt aussieht:
<a href="#cite_ref-9">^</a>
Hier fehlt das Attribut „title“, aber in der Regex haben Sie die Struktur <a href="(.*?)" title="(.*?)">.*?</a> angenommen. Da Regex keine Ahnung von HTML-Elementen hat, hat das Muster .*? statt einen Fehler auszugeben oder die Übereinstimmung zu beenden, blind weiter Zeichen abgeglichen, bis es „title="(.*?)">.*?</a>“ finden konnte, um das Muster zu vervollständigen. Dies führte dazu, dass die nächsten paar a-Tags verschlungen wurden, und zeigt, dass die Verwendung von Regex zu unbeabsichtigten Effekten führen kann, wenn der HTML-Code auf unerwartete Weise geschrieben ist.
Außerdem ist HTML keine reguläre Sprache, was bedeutet, dass Regex allein nicht zum Parsing beliebiger HTML-Daten verwendet werden kann. DieseAntwort auf Stack Overflowist unter Entwicklern ein Kultklassiker, weil sie sich über Entwickler lustig macht, die versuchen, HTML mit Regex zu parsen. Es gibt jedoch einige Situationen, in denen Sie Regex zum Parsing und Scrapen von HTML-Daten verwenden können.
Wenn Sie beispielsweise über einen bekannten, begrenzten Satz von HTML-Code verfügen und genau wissen, wie der Code strukturiert ist, können Sie reguläre Ausdrücke verwenden. Wenn Sie beispielsweise wissen, dass alle a-Tags im HTML die Attribute href und title haben und einem festen Muster entsprechen, können Sie reguläre Ausdrücke verwenden, um Informationen zu extrahieren. Eine bessere und robustere Lösung ist jedoch die Verwendung eines HTML-Parsers wie Beautiful Soup, um Elemente zu finden und Textdaten aus ihnen zu extrahieren.
Nachdem Sie die Textdaten extrahiert haben, können Sie sie mit Regex weiterverarbeiten. Hier ist beispielsweise eine modifizierte Version des Wikipedia-Scrapers, der Beautiful Soup verwendet, um die Attribute href und title zu extrahieren, und dann Regex verwendet, um alle Tags herauszufiltern, die nicht-alphanumerische Zeichen enthalten:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
links = soup.find_all("a")
for link in links:
href = link.get('href')
title = link.get('title')
if title == None:
title = link.string
if title == None:
continue
pattern = r"[a-zA-Z0-9]"
if re.match(pattern, title):
print(f"{href} => {title}")
Fazit
Regex ist ein leistungsstarkes Werkzeug zum Auffinden von Mustern in Textdaten. Dank seiner Robustheit wird es häufig beim Web-Scraping zum Extrahieren von Informationen verwendet.
In diesem Artikel haben Sie gelernt, was Regex ist und wie Sie es mit Beautiful Soup verwenden können, um E-Commerce-Websites, Wikipedia und dynamische Webseiten zu scrapen. Sie haben auch einige der Einschränkungen von Regex kennengelernt und erfahren, wie Sie es am besten in Verbindung mit einem anderen Tool einsetzen können.
Selbst wenn Sie Regex voll ausnutzen, ist Web-Scraping mit vielen Herausforderungen verbunden. Wiederholtes Web-Scraping kann dazu führen, dass die IP-Adresse Ihres Scrapers blockiert wird. Außerdem können Sie mit CAPTCHAs konfrontiert werden, die die korrekte Funktion Ihres Scrapers verhindern. Bright Databietet leistungsstarke Proxys, mit denen Sie IP-Sperren umgehen können. Das weltweite Proxy-Netzwerk umfasstDatencenter-Proxys,Residential-Proxys,ISP-Proxys undMobile-Proxys. Mit demWeb Unlocker können Sie die Bot-Erkennung umgehen und CAPTCHAs ohne Probleme lösen. Gratis testen!






