

TL; DR: In diesem Tutorial erfahren Sie, wie Sie in C++ Daten aus einer Website extrahieren können und warum C++ eine der effizientesten Sprachen für Scraping ist.
Dieser Leitfaden behandelt Folgendes:
- Ist C++ eine gute Sprache für Web Scraping?
- Beste C++-Web-Scraping-Bibliotheken
- Wie man einen Web Scraper in C++ erstellt
Ist C ++ eine gute Sprache für Web Scraping?
C++ ist eine statisch typisierte Programmiersprache, die häufig für die Entwicklung von Hochleistungsanwendungen verwendet wird. Der Grund dafür ist, dass sie für ihre Geschwindigkeit, Effizienz und Speicherverwaltungsfähigkeiten bekannt ist. C++ ist eine vielseitige Sprache, die sich in einer Vielzahl von Anwendungen, einschließlich Web Scraping, als nützlich erweist.
C++ ist eine kompilierte Sprache und von Natur aus schneller als interpretierte Sprachen wie Python. Das macht ihn zu einer ausgezeichneten Wahl für den Bau schneller Scraper. C++ ist jedoch nicht für die Webentwicklung konzipiert und es stehen nicht viele Bibliotheken für Web Scraping zur Verfügung. Es gibt zwar einige Pakete von Drittanbietern, aber die Optionen sind nicht so umfangreich wie in Python, Ruby oder Java.
Zusammenfassend lässt sich sagen, dass Web Scraping in C++ möglich und effizient ist, aber im Vergleich zu anderen Sprachen mehr Low-Level-Programmierung erfordert. Lassen Sie uns herausfinden, welche Tools diesen Prozess vereinfachen können!
Beste C++-Web-Scraping-Bibliotheken
Hier sind einige beliebte Web-Scraping-Bibliotheken für C++:
- CPR: Eine moderne C++-HTTP-Client-Bibliothek, inspiriert vom Python Requests-Projekt. Es ist ein Wrapper von libcurl, der eine leicht verständliche Oberfläche, eingebaute Authentifizierungsfunktionen und Unterstützung für asynchrone Aufrufe bietet.
- libxml2: Eine leistungsstarke Bibliothek mit vollem Funktionsumfang zum Parsen von XML- und HTML-Dokumenten, die ursprünglich für Gnome entwickelt wurde. Es unterstützt die DOM-Manipulation über XPath-Selektoren.
- Lexbor: Eine schnelle und leichte HTML-Parsing-Bibliothek, die vollständig in C geschrieben wurde und CSS-Selektoren unterstützt. Es ist nur für Linux verfügbar.
Jahrelang war Gumbo der am häufigsten verwendete HTML-Parser für C++. Dieser wird seit 2016 nicht mehr gepflegt und sogar die offizielle README rät inzwischen von seiner Verwendung ab.
Voraussetzungen
Bevor Sie mit dem Programmieren beginnen, müssen Sie:
- Einen C++-Compiler haben
- Den
vcpkgC++-Paketmanager einrichten - CMake installieren
Folgen Sie dem nachstehenden Leitfaden für Ihr Betriebssystem und erfahren Sie, wie Sie diese Voraussetzungen erfüllen.
C++ auf macOS einrichten
Unter macOS ist der beliebteste C-, C++- und Objective-C-Compiler Clang. Denken Sie daran, dass auf vielen Macs Clang vorinstalliert ist. Um dies zu überprüfen, öffnen Sie ein Terminal und starten Sie den folgenden Befehl:
clang --version
Wenn Sie den Fehler command not found: clang erhalten, bedeutet das, dass Clang nicht installiert oder richtig konfiguriert ist. In diesem Fall können Sie es über die Xcode-Befehlszeilentools installieren:
xcode-select --install
Das kann eine Weile in Anspruch nehmen. Seien Sie also geduldig.
Um vcpkg einzurichten, benötigen Sie zuerst die macOS-Entwicklertools. Fügen Sie diese Ihrem Mac hinzu mit:
xcode-select --install
Dann müssen Sie vcpkg global installieren. Erstellen Sie einen /dev-Ordner, geben Sie ihn in das Terminal ein und führen Sie ihn aus:
git clone https://github.com/microsoft/vcpkg
Das Verzeichnis wird jetzt den Quellcode enthalten. Erstellen Sie den Paketmanager mit:
./vcpkg/bootstrap-vcpkg.sh
Um diesen Befehl auszuführen, benötigen Sie möglicherweise erweiterte Rechte.
Fügen Sie schließlich /dev/vcpkg zu Ihrem $PATH hinzu und folgen Sie diesem Leitfaden.
Um CMake zu installieren, laden Sie das Installationsprogramm von der offiziellen Website herunter, starten Sie es und folgen Sie dem Installationsassistenten.
C++ unter Windows einrichten
Laden Sie das Installationsprogramm MinGW-x64 von MSYS2 herunter, starten Sie es und folgen Sie den Anweisungen. Dieses Paket enthält aktuelle native Builds von GCC, MinGW-W64 und anderen hilfreichen C++-Tools und -Bibliotheken.
Führen Sie im MSYS2-Terminal, das am Ende des Installationsprozesses geöffnet wird, den folgenden Befehl aus, um die Mingw-w64-Toolchain zu installieren:
pacman -S --needed base-devel mingw-w64-x86_64-toolchain
Warten Sie, bis der Vorgang beendet ist, und fügen Sie dann MinGW zur PATH-Umgebung hinzu, wie hier erklärt.
Als Nächstes müssen Sie vcpkg global installieren. Erstellen Sie einen C:/dev-Ordner, öffnen Sie ihn in PowerShell und führen Sie ihn aus:
git clone https://github.com/microsoft/vcpkg
Erstellen Sie den Quellcode des Paketmanagers, der sich im Unterordner vcpkg befindet, mit:
./vcpkg/bootstrap-vcpkg.bat
Fügen Sie nun wie zuvor C:/dev/vcpkg zu Ihrem PATH hinzu.
Jetzt müssen Sie nur noch CMake installieren. Laden Sie das Installationsprogramm herunter, klicken Sie doppelt darauf und achten Sie darauf, während der Installation die unten stehende Option zu überprüfen.

C++ auf Linux einrichten
Installieren Sie auf Debian-basierten Distributionen GCC (GNU Compiler Collection), CMake und andere nützliche Pakete für die Entwicklung mit:
sudo apt install build-essential cmake
Das kann einige Zeit in Anspruch nehmen. Seien Sie also geduldig.
Als Nächstes müssen Sie vcpkgglobal installieren. Erstellen Sie ein /dev-Verzeichnis, öffnen Sie es im Terminal und geben Sie ein:
git clone https://github.com/microsoft/vcpkg
Das vcpkg-Unterverzeichnis wird jetzt den Quellcode des Paketmanagers enthalten. Erstellen Sie das Tool mit:
./vcpkg/bootstrap-vcpkg.sh
Beachten Sie, dass für diesen Befehl möglicherweise Administratorrechte erforderlich sind.
Fügen Sie dann /dev/vcpkg zu Ihren $PATH-Umgebungsvariablen hinzu, indem Sie diesem Leitfaden folgen.
Perfekt! Sie haben jetzt alles, was Sie brauchen, um mit C++ Web Scraping zu beginnen!
So erstellen Sie einen Web Scraper in C++
In diesem Kapitel erfahren Sie, wie man einen C++-Web-Spider programmiert. Die Zielseite wird die Startseite von Bright Data sein und das Skript kümmert sich um:
- Verbindungsherstellung zur Webseite
- Auswahl der gewünschten HTML-Elemente aus dem DOM
- Abrufen von Daten von diesen
- Exportieren der gescrapten Daten nach CSV
Im Moment sehen Besucher Folgendes, wenn sie die Zielseite erkunden:

Denken Sie daran, dass sich die Startseite von BrightData häufig ändert. Sie könnte sich also geändert haben, während Sie diesen Artikel lesen.
Einige interessante Daten, die Sie aus der Seite extrahieren können, sind die Brancheninformationen, die in diesen Karten enthalten sind:
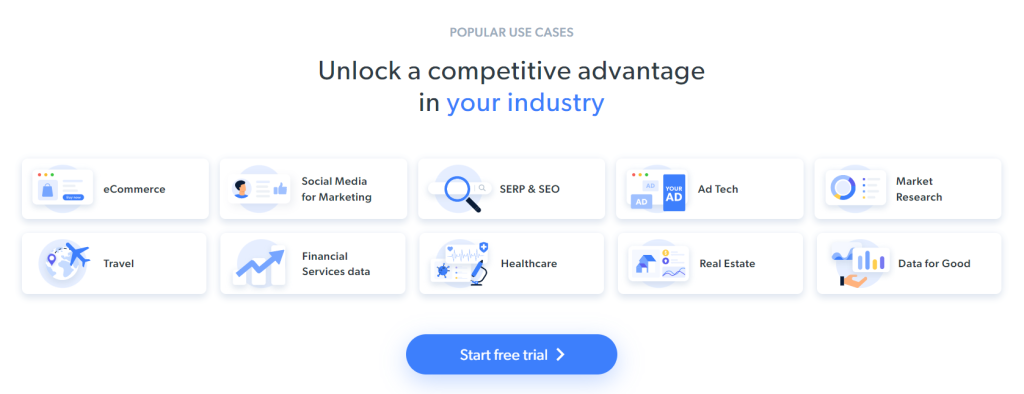
Das Scraping-Ziel für dieses Schritt-für-Schritt-Tutorial wurde definiert. Mal sehen, wie man Web Scraping mit C ++ macht!
Schritt 1: Initialisieren Sie ein C++-Scraping-Projekt.
Zuerst benötigen Sie einen Ordner, in dem Sie Ihr C++-Projekt platzieren können. Öffnen Sie das Terminal und erstellen Sie das Projektverzeichnis mit:
mkdir c++-web-scraper
Dies wird Ihr Scraping-Skript enthalten.
Wenn Sie Software in C++ erstellen, sollten Sie sich für eine Visual Studio IDE entscheiden. Im Detail werden Sie sehen, wie Sie Visual Studio Code (VS Code) für die C++-Entwicklung mit vcpkg als Paketmanager einrichten. Beachten Sie, dass ähnliche Verfahren auf andere C++-IDEs angewendet werden können.
VS Code bietet keine integrierte Unterstützung für C++, daher müssen Sie zuerst das C/C++-Plugin hinzufügen. Starten Sie Visual Studio Code, klicken Sie auf das Symbol „Erweiterungen“ in der linken Leiste und geben Sie „C++“ in das Suchfeld oben ein.
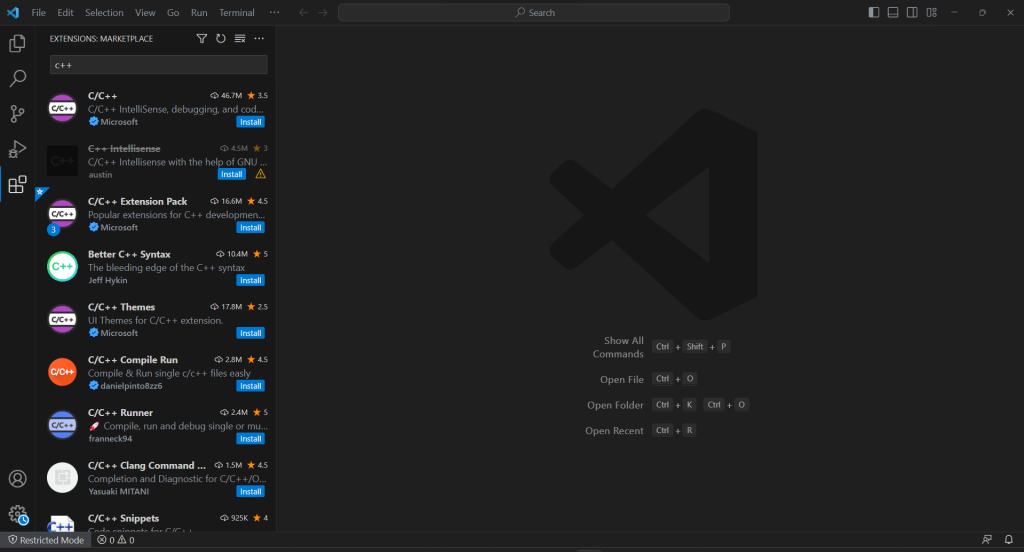
Klicken Sie auf die Schaltfläche „Installieren“ im ersten Element, um C++-Entwicklungsfunktionen zu VS Code hinzuzufügen. Warten Sie, bis die Erweiterung eingerichtet ist, und öffnen Sie dann den Ordner c++-web-scraper mit "``File``" > "``Open Folder...``".
Klicken Sie mit der rechten Maustaste auf den Abschnitt „EXPLORER“, wählen Sie „New File… (Neue Datei …)“ und initialisieren Sie eine scraper.cpp-Datei wie folgt:
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}
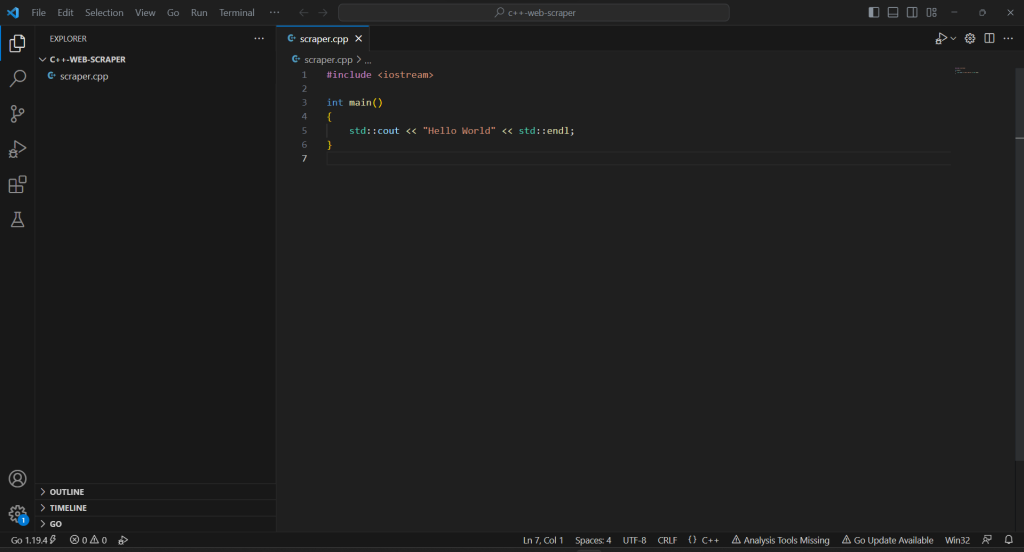
Sie haben jetzt ein C++-Projekt!
Schritt 2: Installieren Sie die Scraping-Bibliotheken.
Die umständliche C++-Syntax und ihre begrenzten Webfunktionen können ein Hindernis beim Erstellen eines Web-Scrapers darstellen. Um alles einfacher zu gestalten, sollten Sie einige C++-Bibliotheken für Web Scraping verwenden. Wie bereits erwähnt, ist die Auswahl ziemlich begrenzt. Daher sollten Sie sich für die beliebtesten entscheiden: cpr und libxml2.
Sie können sie unter Windows über vcpkg installieren mit:
vcpkg install cpr libxml2 --triplet=x64-windows
Ersetzen Sie unter macOS die Triplettoption durch x64-osx . Verwenden Sie unter Linux x64-linux.
Im Visual Studio Code-Terminal müssen Sie außerdem den folgenden Befehl im Stammverzeichnis Ihres Projekts ausführen:
vcpkg integrate install
Dies ermöglicht die Verknüpfung von vcpkg-Paketen mit dem Projekt.
Starten Sie VS Code neu und Sie können jetzt jede installierte Bibliothek mit #include importieren. Fügen Sie also die folgenden drei Zeilen zu Ihrer scraper.cpp-Datei hinzu:
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
Stellen Sie sicher, dass die IDE keine Fehler meldet.
Schritt 3: Finalisieren Sie die Initialisierung des C++-Projekts.
Um das C++-Scraping-Skript zu erstellen und den Projektinitialisierungsprozess abzuschließen, müssen Sie die Erweiterung CMake Tools zu VS Code hinzufügen:
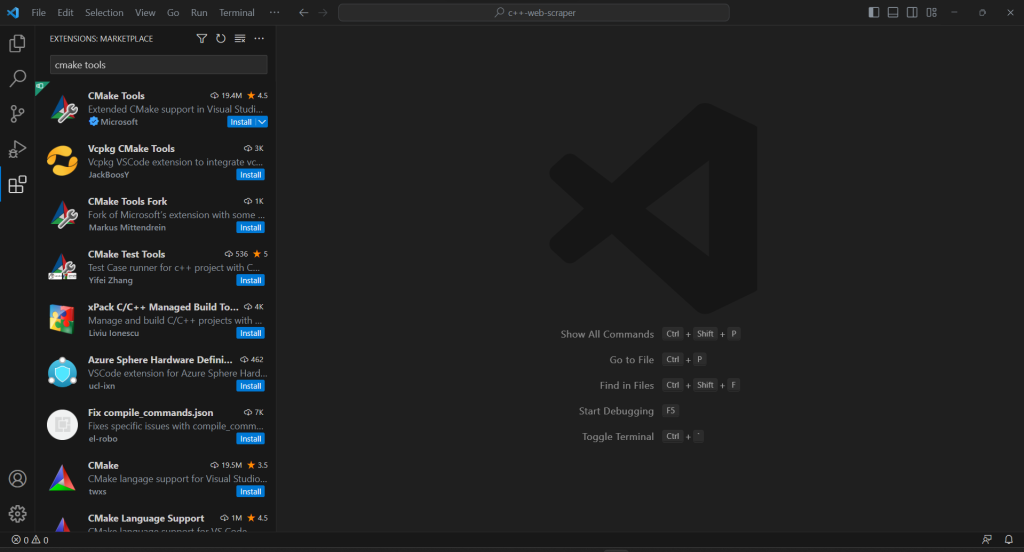
Wenn Ihr Projekt über keinen .vscode-Ordner verfügt, erstellen Sie ihn. Dort sucht VS Code nach Konfigurationen, die sich auf das aktuelle Projekt beziehen.
Konfigurieren Sie CMake Tools so, dass vcpkg als Toolchain verwendet wird, indem Sie eine settings.json-Datei im .vscode-Ordner wie folgt erstellen:
{
"cmake.configureSettings": {
"CMAKE_TOOLCHAIN_FILE": "c:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake"
}
}
Korrigieren Sie unter macOS und Linux das Feld CMAKE_TOOLCHAIN_FILE entsprechend dem Pfad, in dem Sie vcpkg installiert haben. Wenn Sie der obigen Installationsanleitung gefolgt sind, sollte es /dev/vcpkg/scripts/buildsystems/vcpkg.cmake lauten.
Geben Sie in der Hauptsuchleiste von VS Code „>cmake“ ein und wählen Sie die Option „CMake: Configure“:

Dadurch können Sie die Zielkompilierungsplattform auswählen. Wählen Sie unter Windows „Visual Studio Build Tools 2019 Release – x86_amd64“:

Fügen Sie die CMakeLists.txt-Datei im Stammordner Ihres Projekts hinzu, um CMake einzurichten:
cmake_minimum_required(VERSION 3.0.0)
project(main VERSION 0.1.0)
INCLUDE_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/include
)
LINK_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/lib
)
add_executable(main scraper.cpp)
target_compile_features(main PRIVATE cxx_std_20)
find_package(cpr CONFIG REQUIRED)
target_link_libraries(main PRIVATE cpr::cpr)
find_package(LibXml2 REQUIRED)
target_link_libraries(main PRIVATE LibXml2::LibXml2)
Beachten Sie, dass es sich um die beiden zuvor installierten Pakete handelt. Stellen Sie sicher, dass Sie INCLUDE_DIRECTORIES und LINK_DIRECTORIES entsprechend Ihrem vcpkg-Installationsordner aktualisieren.
Damit Visual Studio Code das C++-Programm ausführen kann, benötigen Sie eine Startkonfigurationsdatei. Initialisieren Sie im .vscode-Ordner launch.json wie folgt:
{
"configurations": [
{
"name": "C++ Launch (Windows)",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceFolder}/build/Debug/main.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": []
}
]
}
Beim Starten des Befehls zum Ausführen oder Debuggen führt VS Code die Datei nun im von CMake erstellten Pfad des Programms aus. Beachten Sie, dass es unter macOS und Linux keine .exe-Datei sein wird.
Die Konfiguration ist fertig!
Jedes Mal, wenn Sie Ihre App debuggen oder erstellen möchten, geben Sie „>cmake: Build“ in das obere Eingabefeld ein und wählen Sie die Option „CMake: Build“.

Warten Sie, bis der Build-Prozess beendet ist, und führen Sie das kompilierte Programm aus dem Abschnitt „Run & Debug (Ausführen und Debuggen)“ aus oder drücken Sie F5. Sie werden das Ergebnis Ihrer Anwendung in der VSC-Debug-Konsole sehen.
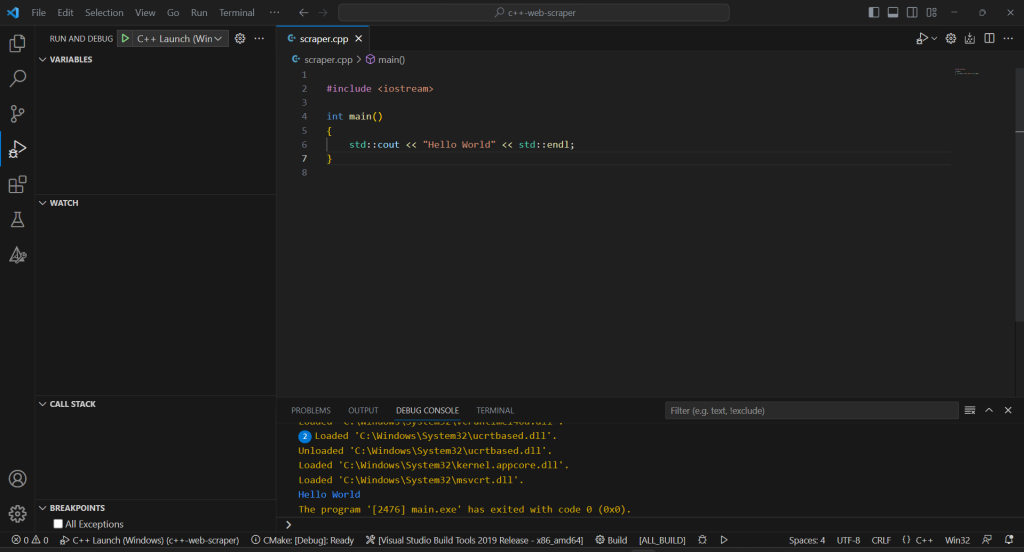
Großartig! Es ist Zeit, mit dem Scrapen einiger Daten in C ++ zu beginnen!
Schritt 4: Laden Sie die Zielseite mit CPR herunter.
Wenn Sie Daten von einer Seite extrahieren möchten, müssen Sie zuerst ihr HTML-Dokument über eine HTTP-GET-Anfrage abrufen.
Verwenden Sie CPR, um die Zielseite herunterzuladen mit:
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"});
Im Hintergrund führt die Methode Get() eine GET-Anfrage an die als Parameter übergebene URL aus. response.text enthält die Zeichenkettendarstellung des vom Server zurückgegebenen HTML-Codes.
Beachten Sie, dass die Ausführung automatisierter HTTP-Anfragen Anti-Bot-Technologien auslösen kann. Diese können Ihre Anfragen abfangen und verhindern, dass Ihr Skript auf die Zielseite zugreift. Insbesondere blockieren die grundlegendsten Anti-Scraping-Lösungen eingehende Anfragen ohne einen gültigen User-Agent HTTP-Header. Weitere Informationen finden Sie in unserem Leitfaden zu User-Agents für Web Scraping.
Wie jeder andere HTTP-Client verwendet CPR einen Platzhalterwert für User-Agent. Da sich dies stark von den Agents unterscheidet, die in gängigen Browsern verwendet werden, können Anti-Bot-Systeme Sie leicht erkennen. Um zu verhindern, dass Sie aus diesem Grund blockiert werden, können Sie in CPR einen gültigen User-Agent setzen mit:
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/121.21.21.da/31/3das/32/1"}, headers);
Die HTTP-Anfrage, die über Get() gestellt wurde, wird nun so aussehen, als käme sie von Google Chrome 113.
Das ist, was scraper.cpp derzeit enthält:
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make the HTTP request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// scraping logic...
}
Schritt 5: Parsen Sie den HTML-Inhalt mit libxml.
Um das vom Server zurückgegebene HTML-Dokument leicht durchsuchbar zu machen, sollten Sie es zuerst parsen.
Um dies zu erreichen, übergeben Sie dazu seine C-String-Darstellung an die Funktion libxml2 htmlReadMemory():
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
Die Variable doc macht jetzt die von libxml2 angebotene DOM-Exploration-API verfügbar. Im Einzelnen können Sie HTML-Elemente auf der Seite über XPath-Selektoren abrufen. Zum Zeitpunkt der Erstellung dieses Artikels unterstützt libxml2 keine CSS-Selektoren.
Schritt 6: Definieren Sie die XPath-Selektoren, um die gewünschten HTML-Elemente zu erhalten.
Um eine effektive XPath-Auswahlstrategie für die HTML-Nodes von Interesse zu definieren, müssen Sie das DOM der Zielseite analysieren. Öffnen Sie die Startseite von Bright Data im Browser, klicken Sie mit der rechten Maustaste auf eine der Branchenkarten und wählen Sie „Inspect (Prüfen)“. Dadurch wird der DevTools-Bereich geöffnet:
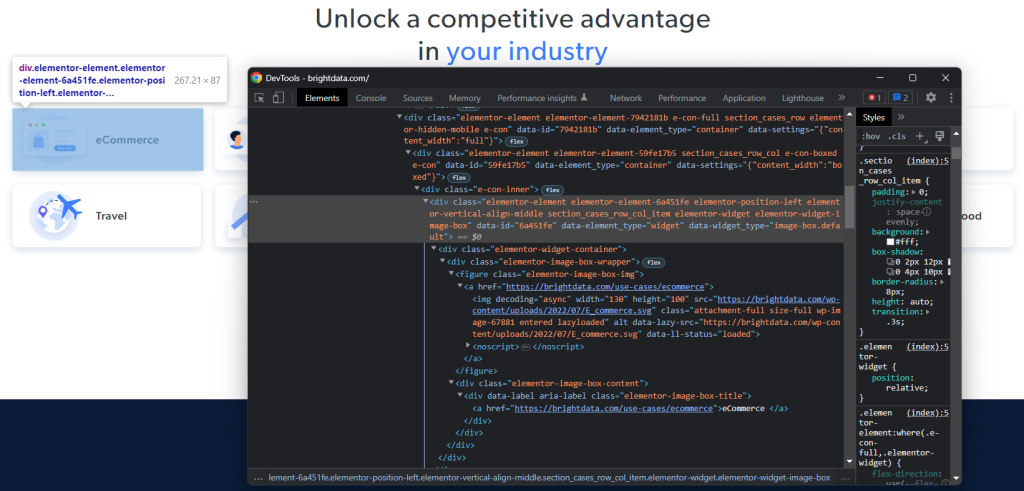
Erkunden Sie den HTML-Code und Sie werden feststellen, dass jede Branchenkarte ein <div>-Element ist, das Folgendes enthält:
- Ein
<figure>-Element mit einem<img>, das das Bild der Branche darstellt, und einem<a>, das die URL zur Branchenseite enthält. - Ein
<div>-HTML-Element, das den Branchennamen in einem<a>speichert.
Für jede Karte besteht das Ziel des C++-Scrapers darin, Folgendes zu extrahieren:
- Die Branchenbild-URL
- Die URL der Branchenseite
- Den Branchennamen
Um die richtigen XPath-Selektoren zu definieren, sollten Sie Ihre Aufmerksamkeit auf die DOM-Struktur der Elemente von Interesse richten. Sie werden feststellen, dass Sie mit dem folgenden XPath-Selektor alle Branchenkarten abrufen können:
//div[contains(@class, 'section_cases_row_col_item')]
Wenn Sie Zweifel haben, testen Sie die XPath-Anweisungen in der Browserkonsole mit $x():
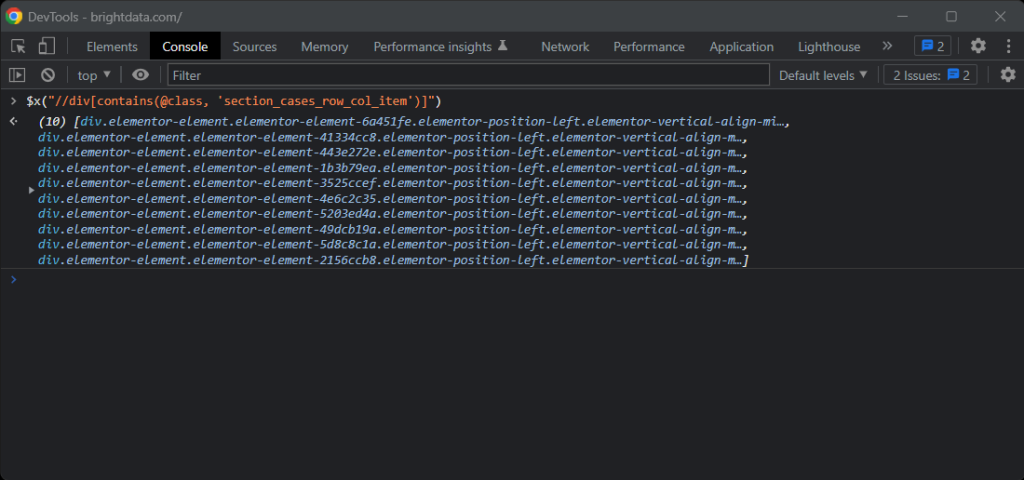
Wenn Sie eine Karte erhalten, können Sie die gewünschten Nodes mit Folgendem erhalten:
.//figure/a/img.//figure/a.//div[contains(@class, 'elementor-image-box-title')]/a
Schritt 7: Scrapen Sie Daten von einer Webseite mit libxml2.
Sie können nun libxml2 verwenden, um die zuvor definierten XPath-Selektoren anzuwenden und die gewünschten Daten von der Ziel-HTML-Webseite zu erhalten.
Zuerst benötigen Sie eine Datenstruktur, in deren Instanzen die gescrapten Daten gespeichert werden:
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
In C++ können Sie mit einem struct mehrere Datenattribute unter demselben Namen in einem Speicherblock bündeln.
Initialisieren Sie dann ein Array von IndustryCards in der Funktion main() :
std::vector<IndustryCard> industry_cards;
Dadurch werden alle Scraping-Datenobjekte gespeichert.
Füllen Sie diesen vector mit der folgenden C++-Web-Scraping-Logik:
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
Das obige Snippet wählt die Branchenkarten aus, indem der zuvor mit xmlXPathEvalExpression() definierte XPath-Selektor angewendet wird. Anschließend werden die Karten durchlaufen und ein ähnlicher Ansatz angewandt, um die untergeordneten Elemente von Interesse der einzelnen Karten zu erhalten. Als Nächstes werden die URL des Branchenbildes, die URL der Seite und der Name aus ihnen ausgelesen. Schließlich gibt es die von libxml2 zugewiesenen Ressourcen frei.
Wie Sie sehen können, ist Web-Scraping mit C++ mit libxml2 nicht so komplex. Dank xmlGetProp() und xmlNodeGetContent() können Sie den Wert eines HTML-Attributs bzw. den Inhalt eines Nodes abrufen.
Jetzt, da Sie wissen, wie Data Scraping in C++ funktioniert, haben Sie die Tools, um noch einen Schritt weiter zu gehen und auch die Branchenseiten zu scrapen. Sie müssen nur den hier entdeckten Links folgen und eine neue Scaping-Logik entwickeln. Darum geht es beim Web Scraping.
Fantastisch! Sie haben gerade Ihre Ziele erreicht. Das Tutorial ist aber noch nicht zu Ende.
Schritt 7: Exportieren Sie die gescrapten Daten nach CSV.
Am Ende der for() -Schleife speichert industry_cards die gescrapten Daten in struct-Instanzen. Wie Sie sich vorstellen können, ist dies nicht das beste Format, um Daten für andere Teams bereitzustellen. Aus diesem Grund sollten Sie die abgerufenen Daten in CSV konvertieren.
Sie können einen vector wie folgt in eine CSV-Datei mit integrierten C++-Funktionen exportieren:
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
Der obige Code erstellt eine output.csv-Datei und initialisiert sie mit dem Header-Datensatz. Dann iteriert es über das Array industry_cards, konvertiert jedes Element in eine Zeichenfolge im CSV-Format und hängt sie an die Ausgabedatei an.
Erstellen Sie Ihr Scraping-C++-Skript, führen Sie es aus und Sie werden die folgende output.csv-Datei im Stammverzeichnis Ihres Projekts sehen:
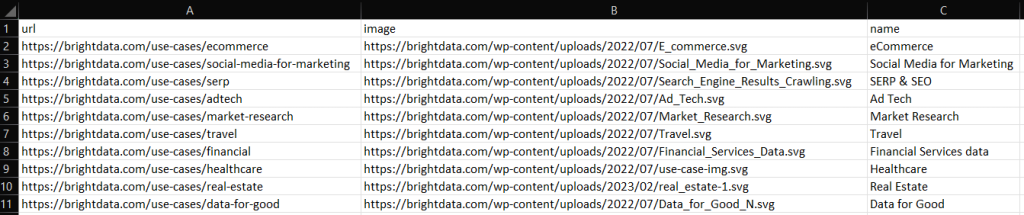
Gut gemacht! Jetzt wissen Sie, wie Sie gescrapte Daten in C++ nach CSV exportieren!
Schritt 8: Fügen Sie alles zusammen.
Hier ist der gesamte C++-Scraper:
// scraper.cpp
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
#include <vector>
// define a struct where to store the scraped data
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
int main()
{
// define the user agent for the GET request
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// make an HTTP GET request to retrieve the target page
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// parse the HTML document returned by the server
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
// define an array to store all retrieved data
std::vector<IndustryCard> industry_cards;
// set the libxml2 context to the current document
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// select all industry card HTML elements
// with an XPath selector
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// iterate over the list of industry card elements
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// get the current element of the loop
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// set the libxml2 context to the current element
// to limit the XPath selectors to its children
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// instantiate an IndustryCard struct with the collected data
IndustryCard industry_card = {image, url, name};
// add the object with the scraped data to the vector
industry_cards.push_back(industry_card);
}
// free up the resource allocated by libxml2
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
// initialize the CSV output file
std::ofstream csv_file("output.csv");
// write the CSV header
csv_file << "url,image,name" << std::endl;
// poupulate the CSV output file
for (IndustryCard industry_card : industry_cards)
{
// transfrom each industry card record to a CSV record
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// free up the file resources
csv_file.close();
return 0;
}
Und voilà! In rund 80 Codezeilen können Sie ein Data-Scaping-Skript in C++ erstellen!
Fazit
In diesem Tutorial haben wir gelernt, warum C++ eine effiziente Sprache zum Scrapen des Webs ist. Obwohl es nicht so viele Scraping-Bibliotheken gibt wie in anderen Sprachen, gibt es einige. Und hier hatten Sie die Gelegenheit zu sehen, welche am beliebtesten sind. Als Nächstes haben Sie sich angesehen, wie Sie mit CPR und libxml2 einen Spider in C++ erstellen können, der Daten von einem echten Ziel sammeln kann.
Mit Web Scraping sind jedoch viele Herausforderungen verbunden. Tatsächlich implementieren immer mehr Websites Anti-Bot- und Anti-Scraping-Technologien, um ihre Daten zu schützen. Diese Tools sind in der Lage, die automatisierten Anfragen zu erkennen, die von Ihrem Scraping-C++-Skript ausgeführt werden, und sie zu sperren. Zum Glück gibt es viele automatisierte Lösungen für Ihre Datenerfassungsanforderungen. Kontaktieren Sie uns, um herauszufinden, was die beste Lösung für Ihren Anwendungsfall ist.
Sie möchten sich überhaupt nicht mit Web Scraping befassen, interessieren sich aber für Webdaten? Entdecken Sie unsere gebrauchsfertigen Datensätze.






