

In diesem Leitfaden erfahren Sie mehr:
- Warum Gemini eine großartige Lösung für AI-gestütztes Web Scraping ist
- Wie man damit eine Website in Python scrapen kann (Anleitung)
- Die größte Einschränkung dieser Art von Web-Scraping und wie man sie überwinden kann
Lasst uns eintauchen!
Warum Gemini für Web Scraping verwenden?
Gemini ist eine von Google entwickelte Familie von multimodalen KI-Modellen, die Text, Bilder, Audio, Videos und Code analysieren und interpretieren können. Die Verwendung von Gemini für das Web Scraping vereinfacht die Datenextraktion durch die Automatisierung der Interpretation und Strukturierung unstrukturierter Inhalte. Dadurch entfällt der manuelle Aufwand – vor allem beim Parsen von Daten.
Im Einzelnen sind dies einige der häufigsten Anwendungsfälle für Gemini beim Web Scraping:
- Seiten, die häufig ihre Struktur ändern: Gemini kann dynamische Seiten verarbeiten, bei denen sich das Layout oder die Datenelemente häufig ändern, wie z. B. bei E-Commerce-Seiten wie Amazon.
- Seiten mit einer Menge unstrukturierter Daten: Sie eignet sich hervorragend zum Extrahieren nützlicher Informationen aus großen Mengen unstrukturierten Textes.
- Seiten, bei denen das Schreiben einer eigenen Parsing-Logik schwierig ist: Für Seiten mit komplexen oder unvorhersehbaren Strukturen kann Gemini den Prozess automatisieren, ohne dass komplizierte Parsing-Regeln erforderlich sind.
Übliche Einsatzszenarien für Gemini beim Web Scraping sind:
- RAG (Retrieval-Augmented Generation): Die Kombination von Echtzeit-Datenabfragen zur Verbesserung der KI-Einsichten. Ein vollständiges Beispiel für die Verwendung einer ähnlichen KI-Technologie finden Sie in unserem Tutorial zur Erstellung eines RAG-Chatbots anhand von SERP-Daten.
- Scraping von sozialen Medien: Sammeln von strukturierten Daten von Plattformen mit dynamischen Inhalten.
- Aggregation von Inhalten: Sammeln von Nachrichten, Artikeln oder Blogbeiträgen aus mehreren Quellen, um Zusammenfassungen oder Analysen zu erstellen.
Weitere Informationen finden Sie in unserem Leitfaden zur Verwendung von KI für Web Scraping.
Web Scraping mit Gemini in Python: Schritt-für-Schritt-Anleitung
Als Zielseite für diesen Abschnitt wird eine bestimmte Produktseite aus der Sandbox “Ecommerce Test Site to Learn Web Scraping” verwendet:
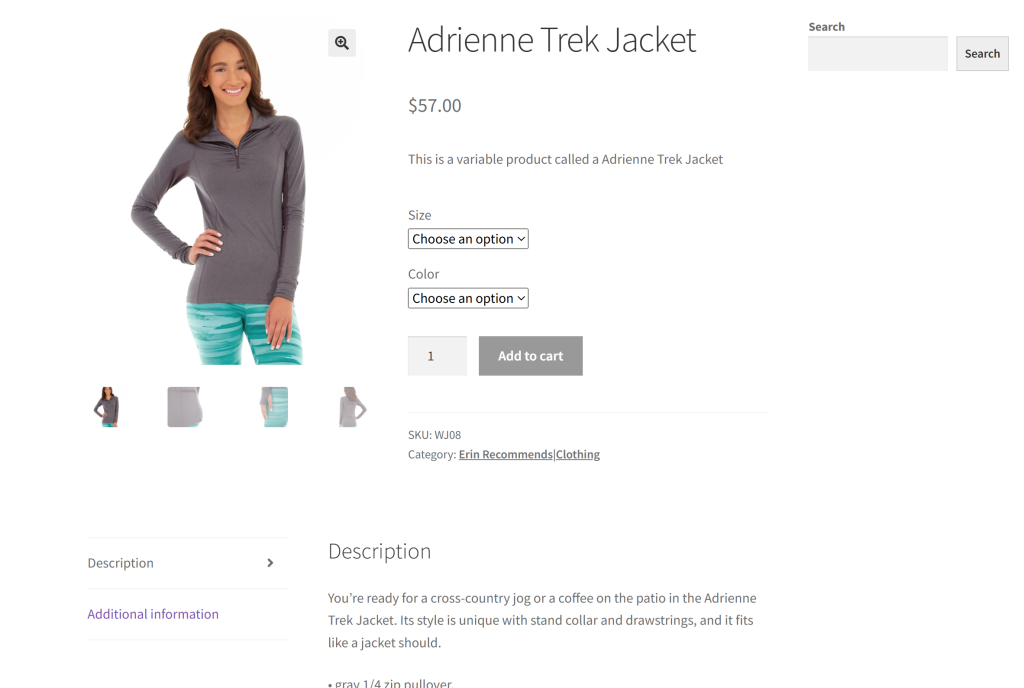
Dies ist ein großartiges Beispiel, da die meisten E-Commerce-Produktseiten verschiedene Arten von Daten anzeigen oder unterschiedliche Strukturen haben. Das macht das E-Commerce-Web-Scraping so schwierig, und hier kann KI helfen.
Das Ziel unseres Gemini-betriebenen Scrapers ist es, KI zu nutzen, um Produktdetails von der Seite zu extrahieren, ohne manuelle Parsing-Logik zu schreiben. Die über KI abgerufenen Produktdaten umfassen:
- SKU
- Name
- Bilder
- Preis
- Beschreibung
- Größen
- Farben
- Kategorie
Führen Sie die folgenden Schritte aus, um zu erfahren, wie Sie Web Scraping mit Gemini durchführen können!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, vergewissern Sie sich, dass Sie Python 3 auf Ihrem Computer installiert haben. Andernfalls laden Sie es herunter und folgen Sie dem Installationsassistenten.
Rufen Sie nun den folgenden Befehl auf, um einen Ordner für Ihr Scraping-Projekt zu erstellen:
mkdir gemini-scrapergemini-scraper steht für den Projektordner Ihres Python-Gemini-gesteuerten Web Scrapers.
Navigieren Sie im Terminal dorthin, und initialisieren Sie eine virtuelle Umgebung darin:
cd gemini-scraper
python -m venv venvLaden Sie den Projektordner in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind zwei gute Optionen.
Erstellen Sie eine scraper.py-Datei im Projektordner, die nun diese Dateistruktur enthalten sollte:

Derzeit ist scraper.py ein leeres Python-Skript, aber es wird bald die gewünschte LLM-Scraping-Logik enthalten.
Aktivieren Sie im Terminal der IDE die virtuelle Umgebung. Unter Linux oder macOS führen Sie diesen Befehl aus:
./venv/bin/activateFühren Sie unter Windows eine entsprechende Funktion aus:
venv/Scripts/activateWunderbar! Sie haben jetzt eine Python-Umgebung für Web Scraping mit Gemini.
Schritt #2: Gemini konfigurieren
Gemini bietet eine API, die Sie mit jedem HTTP-Client aufrufen können – auch mit Anfragen. Dennoch ist es am besten, eine Verbindung über das offizielle Google AI Python SDK für die Gemini-API herzustellen. Um es zu installieren, führen Sie den folgenden Befehl in der aktivierten virtuellen Umgebung aus:
pip install google-generativeaiDann importieren Sie es in Ihre scraper.py-Datei:
import google.generativeai as genaiDamit das SDK funktioniert, benötigen Sie einen Gemini-API-Schlüssel. Wenn Sie Ihren API-Schlüssel noch nicht abgerufen haben
noch nicht erhalten haben, folgen Sie der offiziellen Google-Dokumentation. Loggen Sie sich insbesondere in Ihr Google-Konto ein und melden Sie sich bei Google AI Studio an. Navigieren Sie zur Seite“Get API Key“(API-Schlüssel abrufen) und Sie werden das folgende Modal sehen:
Klicken Sie auf die Schaltfläche “API-Schlüssel abrufen”, und der folgende Abschnitt wird angezeigt:
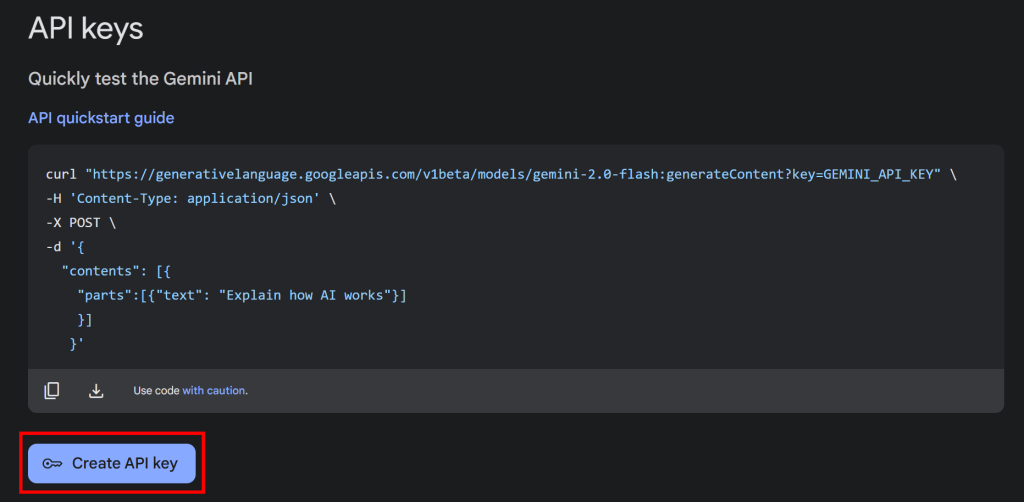
Klicken Sie nun auf “API-Schlüssel erstellen”, um Ihren Gemini-API-Schlüssel zu generieren:
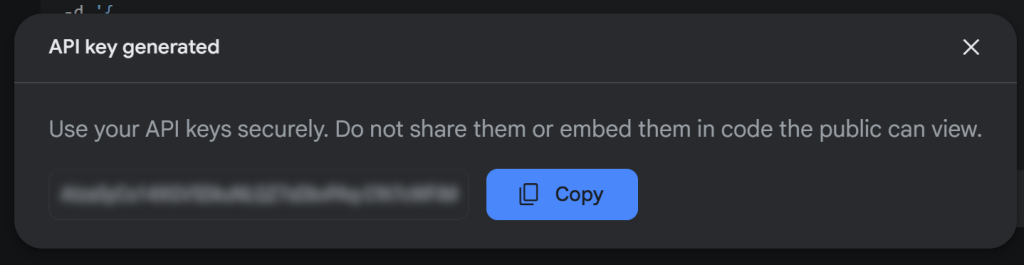
Kopieren Sie den Schlüssel und bewahren Sie ihn an einem sicheren Ort auf.
Hinweis: Die kostenlose Gemini-Stufe ist für dieses Beispiel ausreichend. Die kostenpflichtige Stufe ist nur erforderlich, wenn Sie höhere Ratengrenzen benötigen oder sicherstellen möchten, dass Ihre Eingabeaufforderungen und Antworten nicht zur Verbesserung von Google-Produkten verwendet werden. Weitere Einzelheiten finden Sie auf der Gemini-Abrechnungsseite.
Um den Gemini-API-Schlüssel in Python zu verwenden, können Sie ihn entweder als Umgebungsvariable setzen:
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Alternativ können Sie sie auch direkt in Ihrem Python-Skript als Konstante speichern:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Und übergeben Sie es als Konfiguration an genai, wie folgt:
genai.configure(api_key=GEMINI_API_KEY)In diesem Fall werden wir den zweiten Ansatz verfolgen. Beachten Sie jedoch, dass beide Methoden funktionieren, da google-generativeai automatisch versucht, den API-Schlüssel aus GEMINI_API_KEY zu lesen, wenn Sie ihn nicht manuell übergeben.
Erstaunlich! Sie können jetzt das Gemini SDK verwenden, um API-Anfragen an den LLM in Python zu stellen.
Schritt #3: Holen Sie sich den HTML-Code der Zielseite
Um sich mit dem Zielserver zu verbinden und den HTML-Code seiner Webseiten abzurufen, verwenden wir Requests, den beliebtesten HTTP-Client in Python. Installieren Sie ihn in einer aktivierten virtuellen Umgebung mit:
pip install requestsDann importieren Sie es in scraper.py:
import requestsVerwenden Sie es, um eine GET-Anfrage an die Zielseite zu senden und deren HTML-Dokument abzurufen:
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)response.content enthält nun den rohen HTML-Code der Seite. Es ist an der Zeit, es zu analysieren und Daten daraus zu extrahieren!
Schritt 4: Konvertieren von HTML in Markdown
Wenn Sie andere AI-Scraping-Technologien wie Crawl4AI vergleichen, werden Sie feststellen, dass sie die Verwendung von CSS-Selektoren zur Auswahl von HTML-Elementen ermöglichen. Diese Bibliotheken wandeln dann den HTML-Code der ausgewählten Elemente in Markdown-Text um. Schließlich verarbeiten sie diesen Text mit einem LLM.
Haben Sie sich jemals gefragt, warum? Nun, es gibt zwei Hauptgründe für dieses Verhalten:
- Um die Anzahl der an die KI gesendeten Token zu reduzieren, was Ihnen hilft, Geld zu sparen (da nicht alle LLM-Anbieter wie Gemini kostenlos sind).
- Beschleunigung der KI-Verarbeitung, da weniger Eingabedaten geringere Rechenkosten und schnellere Antworten bedeuten.
Eine vollständige Anleitung finden Sie in unserem Leitfaden zum Web Scraping mit CrawlAI und DeepSeek.
Versuchen wir, diese Logik nachzuvollziehen und zu sehen, ob sie tatsächlich Sinn macht. Prüfen Sie zunächst die Zielseite, indem Sie sie in einem Inkognito-Fenster öffnen (um eine neue Sitzung zu starten). Klicken Sie dann mit der rechten Maustaste auf eine beliebige Stelle der Seite und wählen Sie die Option “Untersuchen”.
Untersuchen Sie die Struktur der Seite. Sie werden sehen, dass alle relevanten Daten in dem HTML-Element enthalten sind, das durch den CSS-Selektor #main gekennzeichnet ist:
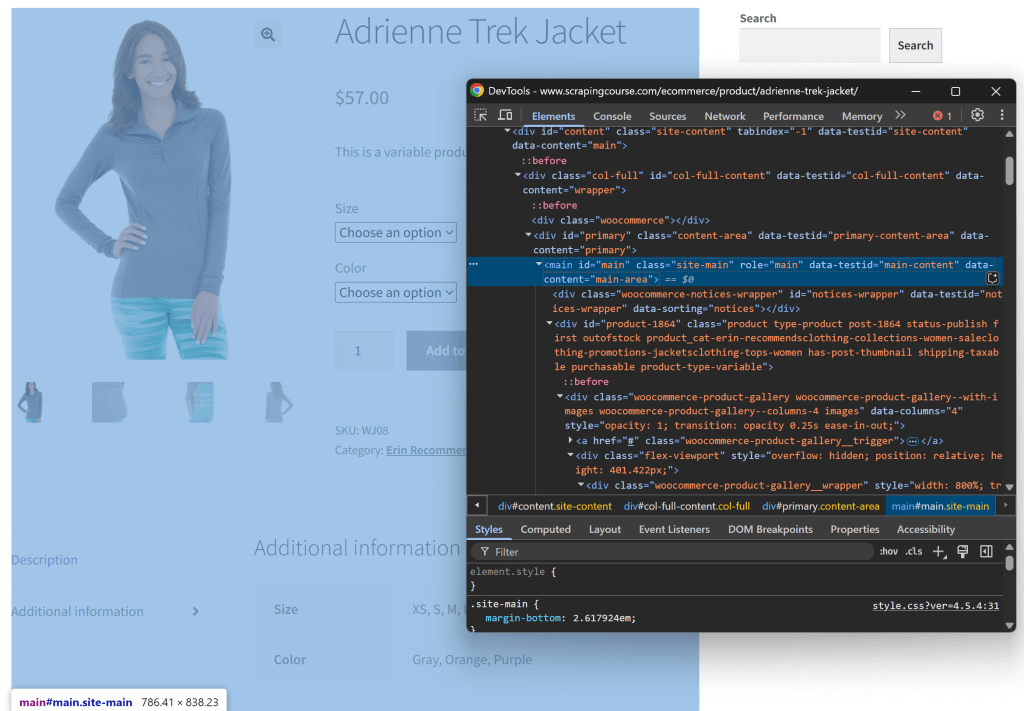
Sie könnten den gesamten HTML-Rohtext an Gemini senden, aber das würde eine Menge unnötiger Informationen (wie Kopf- und Fußzeilen) einbringen. Indem Sie stattdessen nur den #main-Inhalt übergeben, reduzieren Sie das Rauschen und verhindern KI-Halluzinationen.
Um nur #main auszuwählen, benötigen Sie ein Python-HTML-Parsing-Tool, wie z.B. Beautiful Soup. Also, installieren Sie es mit:
pip install beautifulsoup4Wenn Sie mit der Syntax nicht vertraut sind, lesen Sie unseren Leitfaden zu Beautiful Soup Web Scraping.
Nun importieren Sie es in scraper.py:
from bs4 import BeautifulSoupVerwenden Sie Beautiful Soup, um das über Requests abgerufene Roh-HTML zu analysieren, das Element #main auszuwählen und dessen HTML zu extrahieren:
# Parse the HTML with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)Wenn Sie main_html ausdrucken, sehen Sie etwas wie dieses:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
</main>Überprüfen Sie nun, wie viele Token diese HTML generieren würde, und schätzen Sie die Kosten, wenn Sie die kostenpflichtige Stufe von Gemini nutzen würden. Verwenden Sie dazu ein Tool wie Token Calculator:
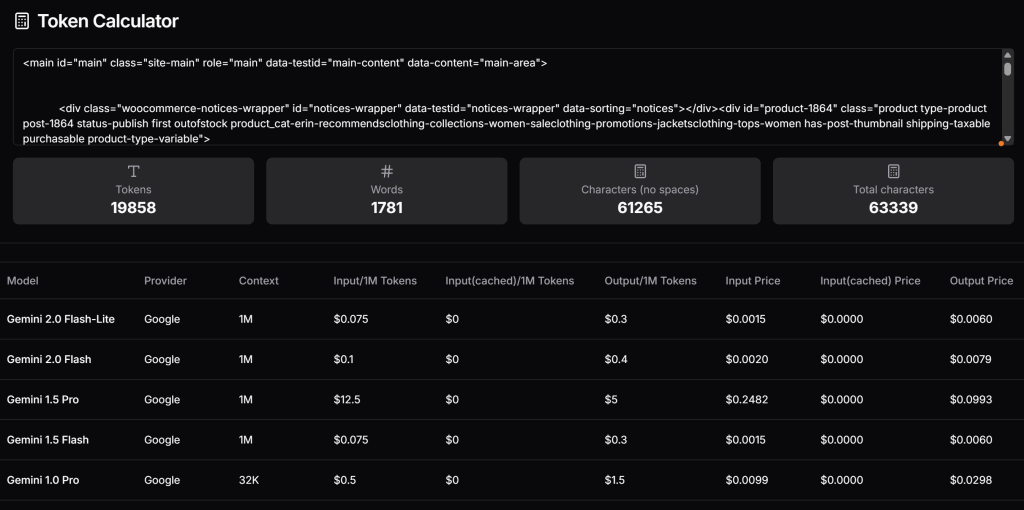
Wie Sie sehen können, entspricht dieser Ansatz fast 20.000 Token, die für Gemini 1.5 Pro etwa $0,25 pro Anfrage kosten. Bei einem groß angelegten Scraping-Projekt kann das leicht zu einem Problem werden!
Versuchen Sie, das extrahierte HTML in Markdown zu konvertieren – ähnlich wie bei Crawl4AI. Installieren Sie zunächst eine HTML-zu-Markdown-Bibliothek wie markdownify:
pip install markdownifyImportieren Sie markdownify in scraper.py:
from markdownify import markdownifyVerwenden Sie anschließend markdownify, um das extrahierte HTML in Markdown zu konvertieren:
main_markdown = markdownify(main_html)Die resultierende main_markdown-Zeichenkette enthält etwa Folgendes:
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back.jpg)
Adrienne Trek Jacket
====================
$57.00
This is a variable product called a Adrienne Trek Jacket
| | |
| --- | --- |
| Size | Choose an optionXSSMLXL |
| Color | Choose an optionGrayOrangePurple[Clear](#) |
Adrienne Trek Jacket quantity
Add to cart
SKU: WJ08
Category: [Erin Recommends|Clothing](https://www.scrapingcourse.com/ecommerce/product-category/clothing/women/tops-women/jacketsclothing-tops-women/promotions-jacketsclothing-tops-women/women-saleclothing-promotions-jacketsclothing-tops-women/collections-women-saleclothing-promotions-jacketsclothing-tops-women/erin-recommendsclothing-collections-women-saleclothing-promotions-jacketsclothing-tops-women/)
* [Description](#tab-description)
* [Additional information](#tab-additional_information)
Description
-----------
You’re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.
* gray 1/4 zip pullover.
* Comfortable, relaxed fit.
* Front zip for venting.
* Spacious, kangaroo pockets.
* 27″ body length.
* 95% Organic Cotton / 5% Spandex.
Additional information
----------------------
| | |
| --- | --- |
| Size | XS, S, M, L, XL |
| Color | Gray, Orange, Purple |Diese Markdown-Version der Eingabedaten ist wesentlich kleiner als das ursprüngliche #main HTML und enthält dennoch alle für das Scraping benötigten Schlüsseldaten.
Verwenden Sie erneut den Token-Rechner, um zu überprüfen, wie viele Token die neue Eingabe verbrauchen würde:
Wow, wir haben 19.858 Token auf 765 Token reduziert – eine Reduzierung um 95 %!
Schritt Nr. 5: Verwenden Sie den LLM zum Extrahieren von Daten
Um Web Scraping mit Gemini durchzuführen, gehen Sie folgendermaßen vor:
- Schreiben Sie eine gut strukturierte Eingabeaufforderung, um die gewünschten Daten aus der Markdown-Eingabe zu extrahieren. Stellen Sie sicher, dass Sie die Attribute definieren, die das Ergebnis haben soll.
- Senden Sie eine Anfrage an ein Gemini LLM-Modell mit
genaiund konfigurieren Sie es so, dass die Anfrage JSON-formatierte Daten zurückgibt. - Parsen Sie das zurückgegebene JSON.
Implementieren Sie die obige Logik mit diesen Codezeilen:
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)Die Variable prompt weist Gemini an, strukturierte Daten aus dem Inhalt von main_markdown zu extrahieren. Anschließend wird mit genai.GenerativeModel() das Modell "gemini-2.0-flash-lite" für die Durchführung der LLM-Anfrage festgelegt. Schließlich wird der rohe Antwortstring im JSON-Format mit json.loads() in ein brauchbares Python-Wörterbuch umgewandelt.
Beachten Sie die Konfiguration "application/json", um Gemini anzuweisen, JSON-Daten zurückzugeben.
Vergessen Sie nicht, json aus der Python-Standardbibliothek zu importieren:
import jsonNachdem Sie nun die gescrapten Daten in einem product_data-Wörterbuch haben, können Sie auf die Felder für die weitere Datenverarbeitung zugreifen, wie im folgenden Beispiel:
price = product_data["price"]
price_eur = price * USD_EUR
# ...Fantastisch! Sie haben soeben Gemini für Web Scraping eingesetzt. Jetzt müssen Sie nur noch die gescrapten Daten exportieren.
Schritt #6: Exportieren Sie die gescrapten Daten
Derzeit sind die ausgewerteten Daten in einem Python-Wörterbuch gespeichert. Um sie in eine JSON-Datei zu exportieren, verwenden Sie den folgenden Code:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Dadurch wird eine Datei product.json erstellt, die die ausgewerteten Daten im JSON-Format enthält.
Herzlichen Glückwunsch! Der von Gemini betriebene Web Scraper ist fertig.
Schritt #7: Alles zusammenfügen
Nachfolgend finden Sie den vollständigen Code Ihres Gemini Scraping-Skripts:
import google.generativeai as genai
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
# Your Gemini API key
GEMINI_API_KEY = "<YOUR_GEMINI_API_KEY>"
# Set up the Google Gemini API
genai.configure(api_key=GEMINI_API_KEY)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:nn
JSON ATTRIBUTES: n
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Starten Sie das Skript mit:
python scraper.pyNach der Ausführung erscheint eine Datei product.json in Ihrem Projektordner. Wenn Sie sie öffnen, sehen Sie strukturierte Daten wie diese:
{
"sku": "WJ08",
"name": "Adrienne Trek Jacket",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back-416x516.jpg"
],
"price": "$57.00",
"description": "Youu2019re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.nnu2022 gray 1/4 zip pullover. nu2022 Comfortable, relaxed fit. nu2022 Front zip for venting. nu2022 Spacious, kangaroo pockets. nu2022 27u2033 body length. nu2022 95% Organic Cotton / 5% Spandex.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Gray",
"Orange",
"Purple"
],
"category": "Erin Recommends|Clothing"
}Et voilà! Sie sind von unstrukturierten Daten in einer HTML-Seite ausgegangen und haben sie nun in einer strukturierten JSON-Datei, dank Gemini-powered Web Scraping.
Nächste Schritte
Um Ihren Gemini-Schaber auf die nächste Stufe zu heben, sollten Sie diese Verbesserungen in Betracht ziehen:
- Machen Sie es wiederverwendbar: Ändern Sie das Skript so, dass es die Eingabeaufforderung und die Ziel-URL als Befehlszeilenargumente akzeptiert. Dadurch wird es universell einsetzbar und kann für verschiedene Nutzungsszenarien angepasst werden.
- Implementieren Sie Web-Crawling: Erweitern Sie den Scraper, um mehrseitige Websites zu verarbeiten, indem Sie Logik für Crawling und Paginierung hinzufügen.
- Sichere API-Anmeldeinformationen: Speichern Sie Ihren Gemini-API-Schlüssel in einer
.env-Dateiund verwenden Siepython-dotenv, um sie zu laden. Dies verhindert die Offenlegung Ihres API-Schlüssels im Code.
Überwindung der Hauptbeschränkung dieses Web-Scraping-Ansatzes
Was ist die größte Einschränkung dieses Ansatzes für Web Scraping? Die HTTP-Anfrage, die von requests!
Sicher, im obigen Beispiel hat es perfekt funktioniert – aber das liegt daran, dass die Zielsite nur eine Spielwiese für Web Scraping ist. In Wirklichkeit wissen Unternehmen und Website-Besitzer, wie wertvoll ihre Daten sind, selbst wenn sie öffentlich zugänglich sind. Um sie zu schützen, setzen sie Anti-Scraping-Maßnahmen ein, die Ihre automatisierten HTTP-Anfragen leicht blockieren können.
Außerdem funktioniert der obige Ansatz nicht bei dynamischen Websites, die auf JavaScript für das Rendering oder den asynchronen Abruf von Daten angewiesen sind. Daher brauchen Websites nicht einmal fortschrittliche Anti-Scraping-Frameworks, um Ihren Scraper zu stoppen. Die Verwendung von JavaScript-basiertem Laden von Inhalten ist ausreichend.
Die Lösung für all diese Probleme? Eine Web Unlocking API!
Eine Web Unlocker API ist ein HTTP-Endpunkt, den Sie von jedem HTTP-Client aus aufrufen können. Der entscheidende Unterschied? Er gibt den vollständig entsperrten HTML-Code jeder URL zurück, die Sie an ihn weitergeben – und umgeht damit jede Anti-Scraping-Sperre. Ganz gleich, wie viele Schutzmechanismen eine Zielsite hat, eine einfache Anfrage an Web Unlocker holt den HTML-Code der Seite für Sie ab.
Um mit diesem Tool zu beginnen und Ihren API-Schlüssel abzurufen, folgen Sie der offiziellen Web Unlocker-Dokumentation. Ersetzen Sie dann Ihren bestehenden Anforderungscode aus “Schritt #3” durch diese Zeilen:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)Und einfach so – keine Sperren mehr, keine Einschränkungen mehr! Sie können jetzt das Web mit Gemini scrapen, ohne sich Sorgen zu machen, dass Sie gestoppt werden.
Schlussfolgerung
In diesem Blogbeitrag haben Sie erfahren, wie Sie Gemini in Kombination mit Requests und anderen Tools verwenden können, um einen KI-gestützten Scraper zu erstellen. Eine der größten Herausforderungen beim Web-Scraping ist das Risiko, blockiert zu werden. Dieses Problem wurde mit der Web Unlocker API von Bright Data gelöst.
Wie hier erläutert, können Sie durch die Kombination von Gemini und der Web Unlocker API Daten von jeder beliebigen Website extrahieren, ohne dass eine benutzerdefinierte Parsing-Logik erforderlich ist. Dies ist nur eines von vielen Szenarien, die die Produkte und Services von Bright Data unterstützen und Ihnen helfen, effektives KI-gesteuertes Web Scraping zu implementieren.
Entdecken Sie unsere anderen Web Scraping Tools:
- Proxy-Dienste: Vier verschiedene Arten von Proxys zur Umgehung von Standortbeschränkungen, darunter mehr als 150 Millionen private IPs
- Web Scraper APIs: Spezielle Endpunkte zum Extrahieren von frischen, strukturierten Webdaten aus über 100 beliebten Domains.
- SERP-API: API zur Verwaltung aller laufenden Freischaltungen für SERP und Extraktion einer Seite
- Scraping-Browser: Puppeteer-, Selenium- und Playwright-kompatibler Browser mit integrierten Freischaltaktivitäten
Melden Sie sich jetzt bei Bright Data an und testen Sie unsere Proxy-Services und Scraping-Produkte kostenlos!





