

In diesem Leitfaden finden Sie die folgenden Informationen:
- Was JavaScript-lastige Websites sind.
- Herausforderungen und Methoden, um sie über das Browser-Rendering zu scrapen.
- Wie das Abfangen von AJAX-Aufrufen funktioniert und welche Einschränkungen es gibt.
- Die moderne Lösung für das Scraping von JavaScript-lastigen Websites.
Lasst uns eintauchen!
Was ist eine JavaScript-lastige Website?
Im Bereich des Web Scraping gilt eine Website als “JavaScript-lastig”, wenn die zu sammelnden Daten nicht im ursprünglichen, vom Server zurückgegebenen HTML-Dokument enthalten sind. Stattdessen wird der eigentliche Inhalt dynamisch abgerufen und von JavaScript im Browser des Benutzers gerendert.
Die Art und Weise, wie eine Website JavaScript verwendet, wirkt sich direkt darauf aus, wie Sie vorgehen müssen, um ihre Daten zu extrahieren. In der Regel folgen JavaScript-basierte Websites diesen drei Hauptmustern:
- Single-Page-Anwendungen (SPAs): Bei einer SPA handelt es sich um eine einzige Webseite, die auf JavaScript angewiesen ist, um bestimmte Abschnitte mit neuen Inhalten vom Server zu aktualisieren. Mit anderen Worten, die gesamte Webanwendung ist nur eine einzige Webseite, die nicht bei jeder Benutzerinteraktion neu geladen wird.
- Benutzergesteuerte Interaktionen: Der Inhalt erscheint nur, wenn Sie bestimmte Aktionen durchführen. Beispiele dafür sind “Mehr laden”-Schaltflächen und dynamische Seitenumbrüche.
- Asynchrone Daten: Viele Websites laden aus Geschwindigkeitsgründen zunächst ein grundlegendes Seitenlayout und führen dann im Hintergrund AJAX-Aufrufe zum Abrufen von Daten durch. Dieser Mechanismus wird häufig für Live-Aktualisierungen verwendet, z. B. für die Aktualisierung von Aktienkursen ohne Neuladen der Seite.
Scraping von JavaScript-lastigen Websites über vollständiges Browser-Rendering
Mit Tools zur Browser-Automatisierung können Sie Skripte schreiben, die Webbrowser starten und steuern. Dadurch können sie das JavaScript ausführen, das zum vollständigen Rendern einer Seite erforderlich ist. Anschließend können Sie die von diesen Tools bereitgestellten APIs für die Auswahl von HTML-Elementen und die Datenextraktion nutzen, um die benötigten Daten abzurufen.
Dies ist der grundlegende Ansatz für das Scraping von JavaScript-lastigen Websites, und wir werden ihn in den folgenden Abschnitten vorstellen:
- Wie Automatisierungswerkzeuge funktionieren.
- Was die Modi “Headless” und “Headful” sind.
- Herausforderungen und Lösungen bei diesem Ansatz.
- Die am häufigsten verwendeten Browser-Automatisierungstools.
Wie Automatisierungswerkzeuge funktionieren
Browser-Automatisierungstools verwenden ein Protokoll (z. B. CDP oder BiDi), um Befehle direkt an einen Browser zu senden. Einfacher ausgedrückt: Sie stellen eine vollständige API zur Verfügung, um Befehle wie “Navigiere zu dieser URL”, “Finde dieses Element” und “Klicke auf diese Schaltfläche” zu erteilen.
Der Browser führt diese Befehle auf der Seite aus und führt dabei jedes JavaScript aus, das für die in Ihrem Scraping-Skript beschriebenen Interaktionen benötigt wird. Das Browser-Automatisierungswerkzeug kann auch auf das gerenderte DOM(Document Object Model) zugreifen. Dort können Sie die Daten finden, die Sie auslesen wollen.
Kopflose vs. “kopflose” Browser
Wenn Sie einen Browser automatisieren, müssen Sie entscheiden, wie er laufen soll. In der Regel haben Sie die Wahl zwischen zwei Modi:
- Kopfvoll: Der Browser startet mit seiner vollständigen grafischen Oberfläche, genau wie wenn ein menschlicher Benutzer ihn öffnet. Sie können das Browserfenster auf Ihrem Bildschirm sehen und beobachten, wie Ihr Skript in Echtzeit klickt, tippt und navigiert. Dies ist hilfreich, um visuell zu bestätigen, dass Ihr Skript wie erwartet funktioniert. Außerdem kann Ihre Automatisierung für Anti-Bot-Systeme eher wie eine echte Benutzeraktivität aussehen. Andererseits ist die Ausführung eines Browsers mit einer grafischen Benutzeroberfläche ressourcenintensiv (wir alle wissen, wie speicherhungrig Browser sein können), was Ihr Web Scraping verlangsamt.
- Kopflos: Der Browser läuft im Hintergrund ohne sichtbare Oberfläche. Er verbraucht weniger Systemressourcen und ist viel schneller. Dies ist der Standard für Produktionsscraper, insbesondere wenn Hunderte von parallelen Instanzen auf einem Server laufen. Der Nachteil ist, dass ein Browser ohne grafische Benutzeroberfläche verdächtig wirken kann, wenn er nicht sorgfältig konfiguriert wird. Entdecken Sie die besten Headless-Browser auf dem Markt.
Herausforderungen und Lösungen beim Browser-Rendering
Die Automatisierung eines Browsers ist nur der erste Schritt im Umgang mit JavaScript-lastigen Websites. Beim Scraping solcher Websites werden Sie unweigerlich mit zwei großen Kategorien von Herausforderungen konfrontiert, darunter:
- Komplexe Navigation: Scraping-Skripte müssen mehr sein als nur Befehlsempfänger. Sie müssen so programmiert werden, dass sie die gesamte Nutzerreise abdecken. Das bedeutet, dass Sie Code für das Scraping komplexer Navigationsabläufe schreiben müssen, wie z. B. das Warten auf das Laden neuer Inhalte und den Umgang mit unendlichem Scrollen. Das Scraping von JavaScript-lastigen Websites umfasst die Handhabung mehrseitiger Formulare, Dropdown-Menüs und vieles mehr.
- Umgehen von Anti-Bot-Systemen: Wenn die Browser-Automatisierung nicht richtig angewendet wird, ist sie ein rotes Tuch, das Anti-Bot-Systeme erkennen können. Um in einem Scraping-Szenario mit Browser-Automatisierungstools erfolgreich zu sein, muss Ihr Scraper irgendwie menschlich erscheinen, indem er Herausforderungen wie diese meistert:
- Browser-Fingerprinting: Anti-Bots analysieren Hunderte von Datenpunkten aus dem Browser des Kunden, um eine eindeutige Signatur zu erstellen. Dazu gehören Ihre User-Agent-Zeichenfolge, Bildschirmauflösung, installierte Schriftarten, WebGL-Rendering-Fähigkeiten und vieles mehr. Eine standardmäßige Automatisierungseinstellung ist leicht zu erkennen. Die Einstellung eines nicht kopflosen User-Agents ist ein guter Tipp. Möglicherweise benötigen Sie auch spezielle Tools wie undetected-chromedriver, das verschiedene Browseroptionen so verändert, dass sie wie der Browser eines normalen Benutzers aussehen.
- Verhaltensanalyse: Anti-Bots beobachten auch, wie der Scraper mit der Seite interagiert. Ein Skript, das 5 Millisekunden nach dem Laden einer Seite auf eine Schaltfläche klickt, ist offensichtlich nicht menschlich. Wenn das Verhalten als roboterhaft eingestuft wird, kann das Abwehrsystem Sie sperren.
- CAPTCHAs: CAPTCHAs sind oft die ultimative Hürde für Scraping-Methoden, die auf Browser-Automatisierung beruhen. Das liegt daran, dass Standard-Automatisierungsskripte sie nicht eigenständig auflösen können. Um dies zu überwinden, müssen CAPTCHA-Auflösungsdienste integriert werden.
Weitere Hinweise finden Sie in unserem Leitfaden zum Scraping dynamischer Websites.
Die besten Browser-Automatisierungs-Frameworks
Die drei vorherrschenden Frameworks für die Browser-Automatisierung sind:
- Playwright: Es ist ein modernes Framework von Microsoft. Es ist von Grund auf so konzipiert, dass es die Komplexität moderner Websites bewältigen kann. Das macht es zu einer ersten Wahl für neue Scraping-Projekte. Es ist in JavaScript, Python, C# und Java verfügbar und wird von der Community in weiteren Sprachen unterstützt. Das macht Web Scraping mit Playwright zu einer guten Wahl für die meisten Entwickler.
- Selenium: Es ist der Open-Source-Titan der Web-Automatisierung. Seine größten Stärken liegen in seiner Vielseitigkeit. Insbesondere unterstützt es fast jede Programmiersprache und jeden Browser und verfügt über ein breites und ausgereiftes Ökosystem. Aus diesem Grund wird Selenium hauptsächlich als Browser-Automatisierungstool für Scraping verwendet.
- Puppeteer: Es handelt sich um eine von Google entwickelte Bibliothek, die über das CDP(Chrome DevTools Protocol) eine granulare Kontrolle über Chrome und Chromium-basierte Browser ermöglicht. Sie unterstützt jetzt auch Firefox. Mit dieser Bibliothek können Sie wie ein normaler Benutzer erscheinen, indem Sie das Benutzerverhalten in einem kontrollierten Browser simulieren. Dadurch wird Puppeteer häufig für Web-Scraping verwendet.
Wie diese (und andere) Lösungen im Vergleich abschneiden, erfahren Sie in unserem Repository über die besten Browser-Automatisierungstools.
Alternative Methode: Replizieren von AJAX-Aufrufen
Anstatt die Kosten für das Rendering einer gesamten visuellen Webseite im Browser zu tragen, können Sie einen detektivischen Ansatz wählen. Sie können stattdessen die direkten API-Aufrufe des Frontends der Website an das Backend identifizieren und sie selbst replizieren.
Diese API-Aufrufe liefern in der Regel die Rohdaten, die die Website später auf der Seite wiedergibt, so dass Sie sie direkt ansprechen können. Diese Technik beruht auf der Nachahmung von AJAX-Aufrufen und ist allgemein als API-Web-Scraping bekannt.
Schauen wir mal, wie es funktioniert!
So funktioniert die AJAX-Aufrufreplikation
Die AJAX-Replikation ist eine praktische Scraping-Technik. Die Kernidee besteht darin, das Rendering der gesamten Seite zu umgehen, indem die Netzwerkanfragen (in der Regel AJAX-Aufrufe) nachgeahmt werden, die die Webanwendung zum Abrufen von Daten aus ihrem Backend tätigt.
Dies umfasst im Wesentlichen zwei Schritte:
- Schnüffeln: Öffnen Sie die Entwicklertools Ihres Browsers (normalerweise die Registerkarte “Netzwerk” mit aktiviertem Filter “Fetch/XHR”) und interagieren Sie mit der Website. Beobachten Sie, welche API-Aufrufe im Hintergrund gemacht werden, wenn neue Daten geladen werden. Zum Beispiel während des unendlichen Scrollens oder beim Klicken auf die Schaltfläche “Mehr laden”.
- Wiederholen Sie: Sobald Sie die richtige API-Anfrage identifiziert haben, notieren Sie die URL, die HTTP-Methode (GET, POST usw.), die Header und die Nutzdaten (falls vorhanden). Dann wiederholen Sie diese Anfrage in Ihrem Scraping-Skript mit einem HTTP-Client wie Requests in Python.
Diese API-Endpunkte geben Daten in der Regel in einem strukturierten Format zurück, meistens JSON. Dies ist ein enormer Vorteil, da Sie auf die JSON-Daten zugreifen können, ohne dass Sie HTML extra parsen müssen.
Sehen Sie sich zum Beispiel den API-Aufruf einer Website an, die unendliches Scrollen verwendet, um mehr Daten zu laden:
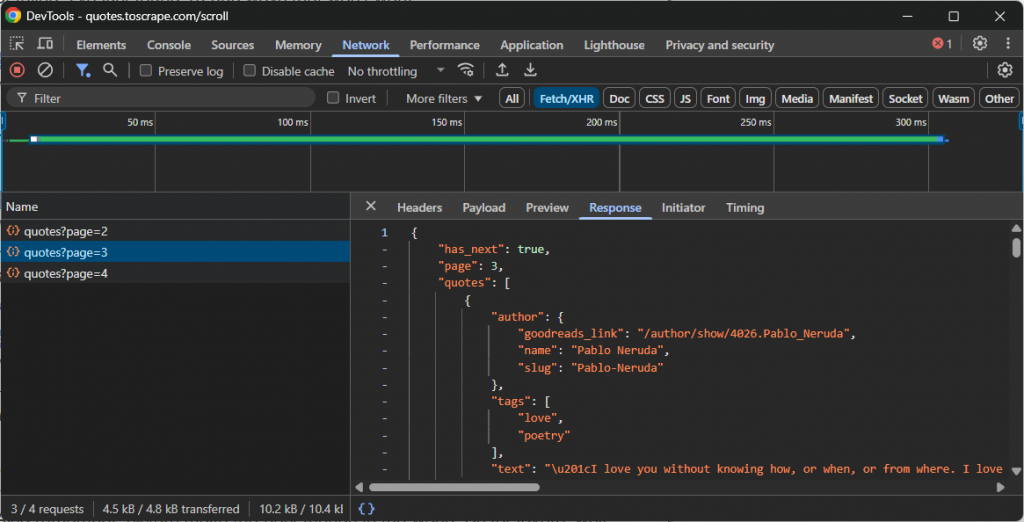
In diesem Fall können Sie ein einfaches Scraping-Skript schreiben, das den obigen API-Aufruf zum unendlichen Scrollen reproduziert und dann auf die Daten zugreift.
Hauptherausforderungen beim Abfangen von AJAX-Aufrufen
Wenn es funktioniert, ist dieser Ansatz schnell, effektiv und einfach. Dennoch bringt sie einige Herausforderungen mit sich:
- Verschlüsselte Nutzdaten: Die API kann verschlüsselte Nutzdaten erfordern oder kein sauberes, lesbares JSON zurückgeben. Es könnte sich um eine verschlüsselte Zeichenfolge handeln, die eine bestimmte JavaScript-Funktion zu entschlüsseln weiß. Dies ist eine Anti-Scraping-Maßnahme, die Reverse Engineering erfordert.
- Dynamische Endpunkte und Header: API-Endpunkte und die Art ihres Aufrufs (z. B. Setzen der richtigen Header, Hinzufügen der richtigen Nutzdaten usw.) ändern sich mit der Zeit. Die größte Herausforderung bei dieser Lösung besteht darin, dass jede Weiterentwicklung der API den Scraper beschädigt. Dies erfordert Code-Wartung, um die Funktionalität wiederherzustellen, was bei den meisten (aber nicht allen, wie wir gleich sehen werden) Web-Scraping-Ansätzen ein häufiges Problem darstellt.
- TLS-Fingerprinting: Die fortschrittlichsten Anti-Bots analysieren den “TLS-Handshake”, d. h. die digitale Signatur des Programms. Sie können leicht zwischen einer Anfrage von Chrome und einer Anfrage von einem Standard-Python-Skript unterscheiden. Um dies zu umgehen, benötigen Sie spezielle Tools, die die TLS-Signatur eines Browsers imitieren können.
Ein moderner Ansatz zum Scraping von JavaScript-lastigen Websites: KI-gestützte Browser-Scraping-Agenten
Die bisher beschriebenen Methoden stehen noch vor großen Herausforderungen. Eine modernere Lösung für das Scraping von JavaScript-lastigen Websites erfordert einen Paradigmenwechsel. Die Idee ist, vom Schreiben imperativer Befehle zur Definition deklarativer Ziele unter Verwendung KI-gesteuerter Browser-Agenten überzugehen.
Ein Agent-Browser ist ein Browser, der in ein LLM integriert ist und den Inhalt, den Kontext und das visuelle Layout der Seite versteht. Dies ändert die Herangehensweise an Web-Scraping grundlegend, insbesondere bei JavaScript-lastigen Websites.
Diese Websites erfordern in der Regel komplexe Benutzerinteraktionen, um die gewünschten Daten zu laden. Traditionell müssten Sie Logik einfügen, um diese Interaktionen in Ihren Skripten zu replizieren. Dieser Ansatz ist von Natur aus spröde und wartungsintensiv. Das Problem ist, dass Sie bei jeder Änderung des Benutzerflusses Ihre Automatisierungslogik manuell aktualisieren müssen.
Dank der KI-gesteuerten Browser-Agenten können Sie all das vermeiden. Eine einfache beschreibende Eingabeaufforderung kann eine effektive Automatisierung auslösen, die sich selbst dann anpasst, wenn sich die Benutzeroberfläche oder der Ablauf der Website ändert. Diese Flexibilität ist ein enormer Vorteil und öffnet die Tür zu vielen anderen Automatisierungsmöglichkeiten, weshalb die agentenbasierte KI schnell an Bedeutung gewinnt.
Ganz gleich, wie leistungsfähig Ihre KI-Browseragentenbibliothek ist, Ihre Scraping-Logik hängt immer noch von normalen Browsern ab. Das bedeutet, dass Sie anfällig für Probleme wie Browser-Fingerprinting und CAPTCHAs bleiben. Auch die Skalierung solcher Lösungen wird aufgrund von Ratenbeschränkungen und IP-Sperren schwierig.
Die wirkliche Lösung ist eine Cloud-basierte, KI-fähige Scraping-Plattform, die mit jeder Agentenbibliothek integriert werden kann und so konzipiert ist, dass sie nicht blockiert wird. Genau das bietet der Agent Browser von Bright Data.
Mit Agent Browser können Sie KI-gesteuerte Workflows auf entfernten Browsern ausführen, die nie blockiert werden. Er ist unbegrenzt skalierbar, unterstützt sowohl den Headless- als auch den Headful-Modus und wird durch das zuverlässigste Proxy-Netzwerk der Welt unterstützt.
Schlussfolgerung
In diesem Artikel haben Sie erfahren, was JavaScript-lastige Websites sind und welche Herausforderungen und Lösungen es für das Scrapen von Daten aus diesen Websites gibt. Jede beschriebene Implementierung hat ihre Grenzen, aber die beste ist die Verwendung eines Agenten-Browsers.
Wie bereits erwähnt, ermöglicht der Agent Browser von Bright Data die Lösung aller gängigen Scraping-Probleme bei gleichzeitiger Integration mit den beliebtesten Agentic AI-Bibliotheken.
Wenn Sie erweiterte KI-Scraping-Agenten verwenden, benötigen Sie zuverlässige Tools zum Abrufen, Validieren und Umwandeln von Webinhalten. All diese Funktionen und mehr finden Sie in der KI-Infrastruktur von Bright Data.
Erstellen Sie ein Bright Data-Konto und testen Sie alle unsere Produkte und Services für die Entwicklung von KI-Agenten!





