

In diesem Leitfaden erfahren Sie:
- Was Undetected ChromeDriver ist und wie es nützlich sein kann
- Wie es die Bot-Erkennung minimiert
- Wie man es mit Python für das Web-Scraping verwendet
- Fortgeschrittene Verwendung und Methoden
- Die wichtigsten Einschränkungen und Nachteile
- Ähnliche Technologien
Lassen Sie uns eintauchen!
Was ist Undetected ChromeDriver?
Undetected ChromeDriverist eine Python-Bibliothek, die eine optimierte Version von Seleniums ChromeDriver bereitstellt. Diese wurde gepatcht, um die Erkennung durch Anti-Bot-Dienste wie die folgenden zu einschränken:
- Imperva
- DataDome
- Distil Networks
Es kann auch dabei helfen, bestimmte Cloudflare-Schutzmaßnahmen zu umgehen, obwohl dies schwieriger sein kann. Weitere Informationen finden Sie in unserer Anleitungzum Umgehen von Cloudflare.
Wenn Sie schon einmalBrowser-Automatisierungstoolswie Selenium verwendet haben, wissen Sie, dass Sie damit Browser programmgesteuert steuern können. Um dies zu ermöglichen, konfigurieren sie Browser anders als normale Benutzereinstellungen.
Anti-Bot-Systeme suchen nach diesen Unterschieden oder „Lecks“, um automatisierte Browser-Bots zu identifizieren. Undetected ChromeDriver patcht Chrome-Treiber, um diese verräterischen Anzeichen zu minimieren und die Bot-Erkennung zu reduzieren. Das macht es ideal für das Web-Scraping von Websites, die durchAnti-Scraping-Maßnahmen geschützt sind!
So funktioniert es
Undetected ChromeDriver reduziert die Erkennung durch Cloudflare, Imperva, DataDome und ähnliche Lösungen durch den Einsatz der folgenden Techniken:
- Umbenennung von Selenium-Variablen, um die von echten Browsern verwendeten zu imitieren
- Verwendung legitimer, realer User-Agent-Strings, um eine Erkennung zu vermeiden
- Ermöglichen der Simulation natürlicher menschlicher Interaktionen durch den Benutzer
- Cookies und Sitzungen beim Navigieren auf Websites ordnungsgemäß verwalten
- Ermöglichen der Verwendung von Proxys, um IP-Blockierungen zu umgehen und Ratenbegrenzungen zu verhindern
Diese Methoden helfen dem von der Bibliothek gesteuerten Browser, verschiedene Anti-Scraping-Maßnahmen effektiv zu umgehen.
Verwendung von Undetected ChromeDriver für Web-Scraping: Schritt-für-Schritt-Anleitung
Die meisten Websites verwenden fortschrittliche Anti-Bot-Maßnahmen, um automatisierte Skripte am Zugriff auf ihre Seiten zu hindern. Diese Mechanismen stoppen auchWeb-Scraping-Botseffektiv.
Angenommen, Sie möchten den Titel und die Beschreibung der folgendenGoDaddy-Produktseite scrapen:
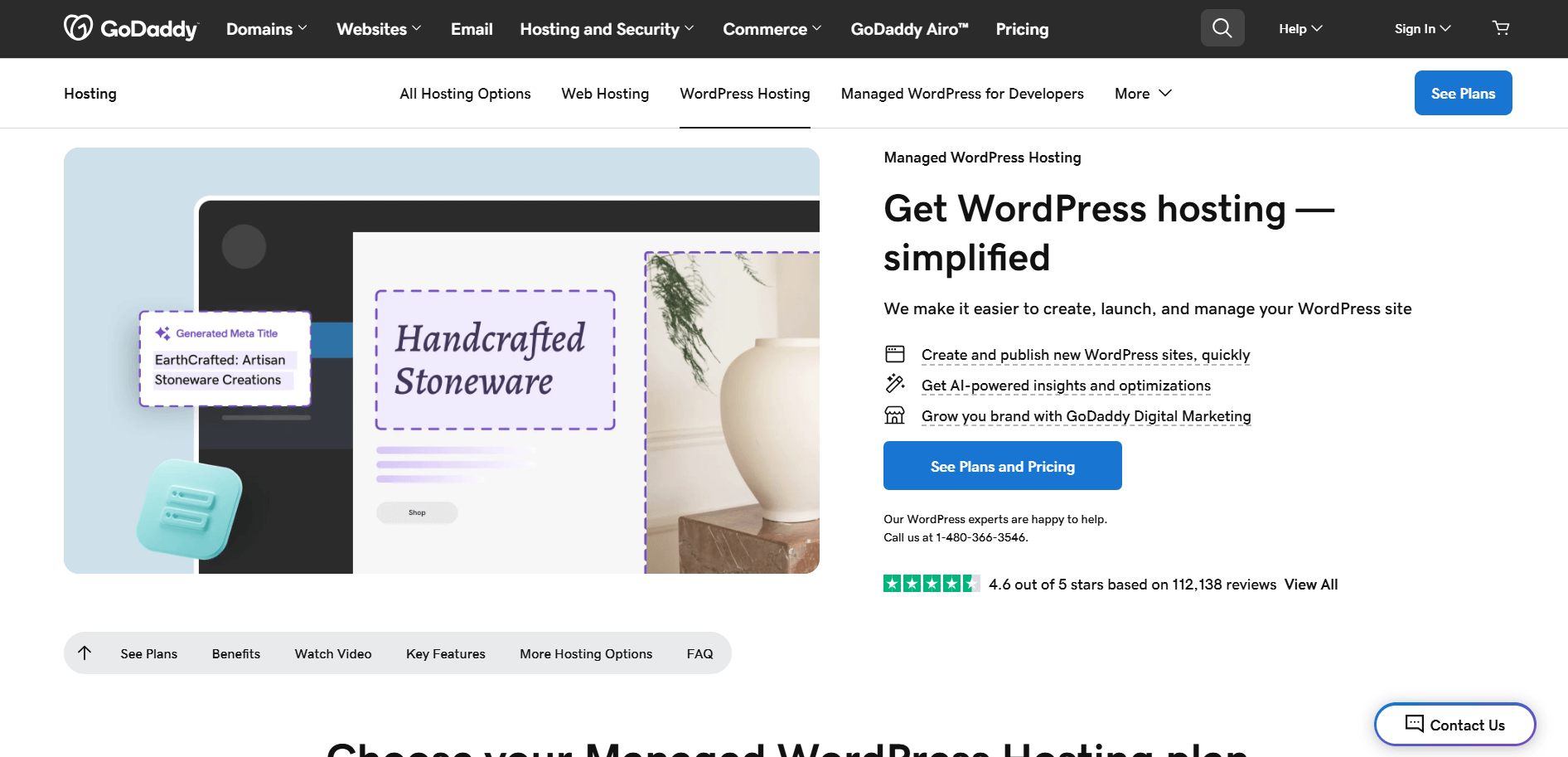
Mit einfachem Selenium in Python sieht Ihr Scraping-Skript in etwa so aus:
# pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# Konfigurieren Sie eine Chrome-Instanz, um im Headless-Modus zu starten.
options = Options()
options.add_argument("--headless")
# Erstellen Sie eine Chrome-Webtreiberinstanz
driver = webdriver.Chrome(service=Service(), options=options)
# Verbinden Sie sich mit der Zielseite
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# Scraping-Logik...
# Schließen Sie den Browser
driver.quit()
Wenn Sie mit dieser Logik nicht vertraut sind, lesen Sie unseren Leitfaden zumSelenium-Web-Scraping.
Wenn Sie das Skript ausführen, schlägt es aufgrund dieser Fehlerseite fehl:

Mit anderen Worten: Das Selenium-Skript wurde von einer Anti-Bot-Lösung (in diesem Beispiel Akamai) blockiert.
Wie können Sie dieses Problem umgehen? Die Antwort lautet: Undetected ChromeDriver!
Befolgen Sie die folgenden Schritte, um zu erfahren, wie Sie die Python-Bibliothek undetected_chromedriver für das Web-Scraping verwenden können.
Schritt 1: Voraussetzungen und Projekteinrichtung
Undetected ChromeDriver hat die folgenden Voraussetzungen:
- Aktuelle Version von Chrome
- Python 3.6+: Wenn Python 3.6 oder höher nicht auf Ihrem Computer installiert ist,laden Sie es von der offiziellen Website herunterund befolgen Sie die Installationsanweisungen.
Hinweis: Die Bibliothek lädt die Treiber-Binärdatei automatisch herunter und patcht sie für Sie, sodass SieChromeDriver nicht manuell herunterladen müssen.
Erstellen Sie nun mit dem folgenden Befehl ein Verzeichnis für Ihr Projekt:
mkdir undetected-chromedriver-Scraper
Das Verzeichnis „undetected-chromedriver-scraper” dient als Projektordner für Ihren Python-Scraper.
Navigieren Sie dorthin und initialisieren Sie einevirtuelle Umgebung:
cd undetected-chromedriver-Scraper
python -m venv env
Öffnen Sie den Projektordner in Ihrer bevorzugten Python-IDE.Visual Studio Code mit der Python-ErweiterungoderPyCharm Community Editionsind beide eine gute Wahl.
Erstellen Sie als Nächstes eine Datei„scraper.py”im Projektordner und folgen Sie dabei der unten gezeigten Struktur:
Derzeit istscraper.pyein leeres Python-Skript. In Kürze werden Sie die Scraping-Logik hinzufügen.
Aktivieren Sie die virtuelle Umgebung im Terminal Ihrer IDE. Unter Linux oder macOS verwenden Sie:
./env/bin/activate
Unter Windows führen Sie stattdessen folgenden Befehl aus:
env/Scripts/activate
Großartig! Sie haben nun eine Python-Umgebung, die für das Web-Scraping über die Browser-Automatisierung bereit ist.
Schritt 2: Undetected ChromeDriver installieren
Installieren Sie in einer aktivierten virtuellen Umgebung Undetected ChromeDriver über das pip-Paketundetected_chromedriver:
pip install undetected_chromedriver
Im Hintergrund installiert diese Bibliothek automatisch Selenium, da es eine ihrer Abhängigkeiten ist. Sie müssen Selenium also nicht separat installieren. Das bedeutet auch, dass Sie standardmäßig Zugriff auf alle Selenium-Importe haben.
Schritt 3: Ersteinrichtung
Importieren Sie undetected_chromedriver:
import undetected_chromedriver as uc
Anschließend können Sie einen Chrome WebDriver mit folgendem Befehl initialisieren:
driver = uc.Chrome()
Genau wie bei Selenium wird dadurch ein Browserfenster geöffnet, das Sie mit der Selenium-API steuern können. Das bedeutet, dass das Treiberobjekt alle Standardmethoden von Selenium sowie einige zusätzliche Funktionen bereitstellt, auf die wir später noch eingehen werden.
Der wesentliche Unterschied besteht darin, dass diese Version des Chrome-Treibers gepatcht ist, um bestimmte Anti-Bot-Lösungen zu umgehen.
Um den Treiber zu schließen, rufen Sie einfach die Methode quit() auf:
driver.quit()
So sieht eine grundlegende Undetected ChromeDriver-Konfiguration aus:
import undetected_chromedriver as uc
# Initialisieren einer Chrome-Instanz
driver = uc.Chrome()
# Scraping-Logik...
# Schließen des Browsers und Freigeben seiner Ressourcen
driver.quit()
Fantastisch! Sie sind nun bereit, Web-Scraping direkt im Browser durchzuführen.
Schritt 4: Für das Web-Scraping verwenden
Warnung: Dieser Abschnitt folgt denselben Schritten wie eine Standard-Selenium-Einrichtung. Wenn Sie bereits mit Selenium-Web-Scraping vertraut sind, können Sie gerne zum nächsten Abschnitt mit dem endgültigen Code übergehen.
Verwenden Sie zunächst die Methode get(), um den Browser zu Ihrer Zielseite zu navigieren:
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
Rufen Sie anschließend die Seite im Inkognito-Modus Ihres Browsers auf und überprüfen Sie das Element, das Sie scrapen möchten:
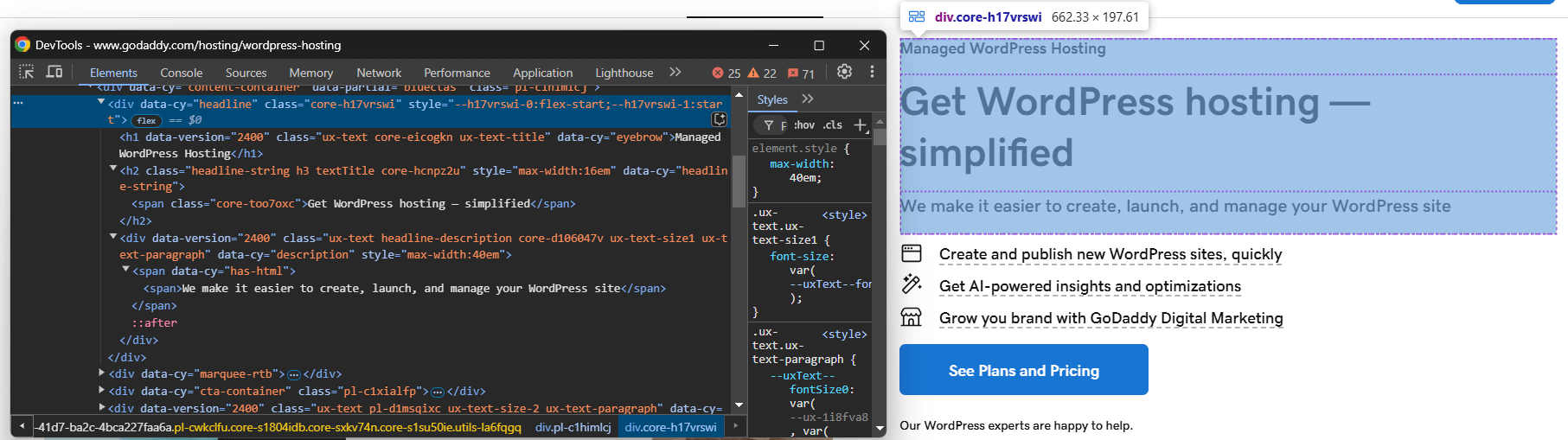
Angenommen, Sie möchten den Produkttitel, den Slogan und die Beschreibung extrahieren.
Sie können all diese Informationen mit dem folgenden Code scrapen:
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
Damit der obige Code funktioniert, müssen Sie By aus Selenium importieren:
from selenium.webdriver.common.by import By
Speichern Sie nun die gescrapten Daten in einem Python-Wörterbuch:
product = {
"title": title,
"tagline": tagline,
"description": description
}
Exportieren Sie die Daten schließlich in eine JSON-Datei:
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)
Vergessen Sie nicht, json aus der Python-Standardbibliothek zu importieren:
import json
Und schon sind Sie fertig! Sie haben gerade die grundlegende Logik des Web-Scraping-Prozesses von Undetected ChromeDriver implementiert.
Schritt 5: Alles zusammenfügen
Dies ist das endgültige Scraping-Skript:
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Erstellen Sie eine Chrome-Webtreiberinstanz.
driver = uc.Chrome()
# Stellen Sie eine Verbindung zur Zielseite her.
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# Scraping-Logik
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
# Füllen Sie ein Wörterbuch mit den gescrapten Daten.
product = {
"title": title,
"tagline": tagline,
"description": description
}
# Exportieren Sie die gescrapten Daten nach JSON.
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)
# Schließen Sie den Browser und geben Sie seine Ressourcen frei.
driver.quit()
Ausführen mit:
python3 Scraper.py
Oder unter Windows:
python Scraper.py
Dadurch wird ein Browser geöffnet, der die Zielwebseite anzeigt, nicht die Fehlerseite wie bei Vanilla Selenium:
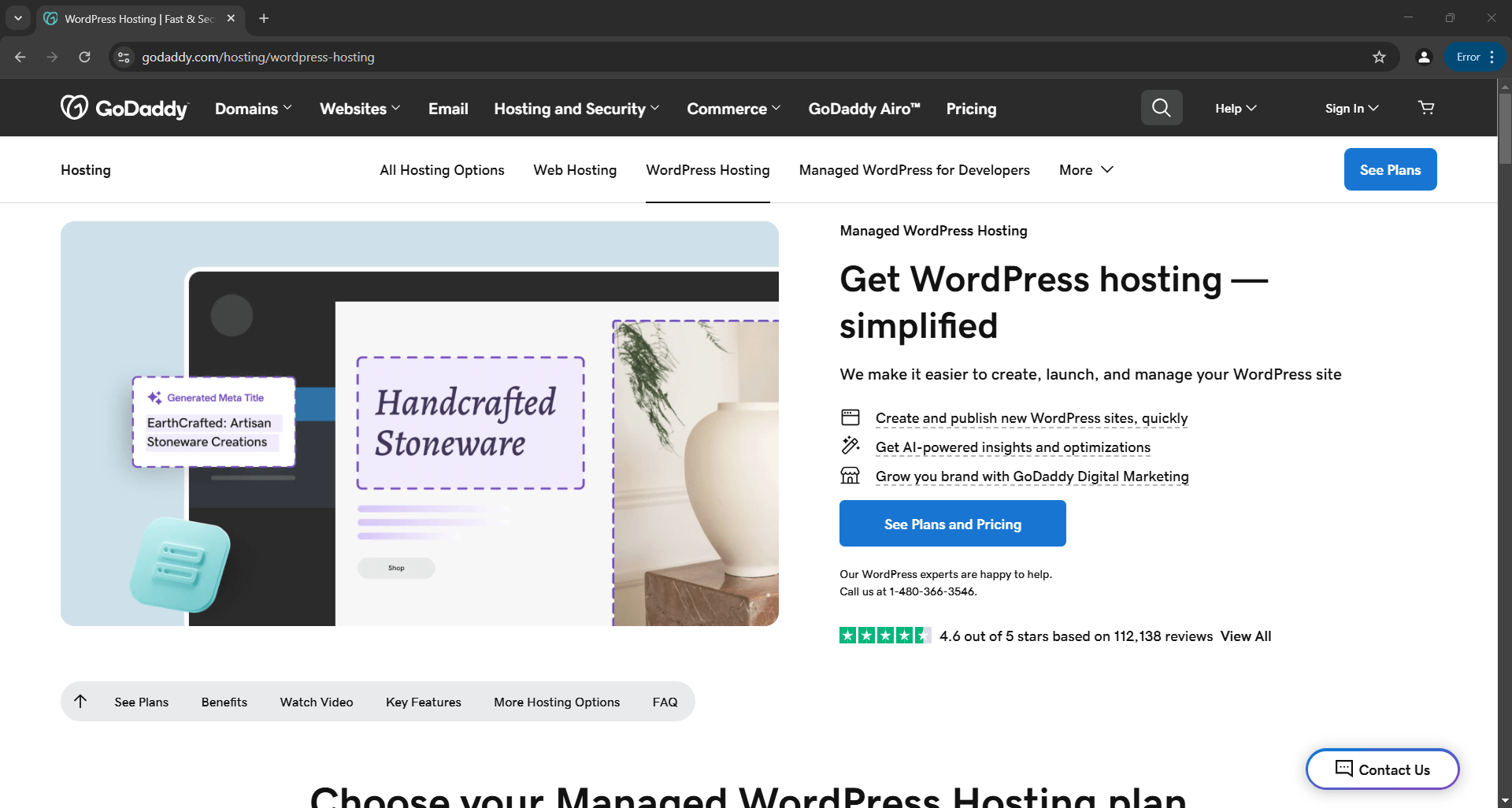
Das Skript extrahiert Daten aus der Seite und erstellt die folgende Datei product.json:
{
"title": "Managed WordPress Hosting",
"tagline": "Get WordPress hosting — simplified",
"description": "We make it easier to create, launch, and manage your WordPress site"
}
undetected_chromedriver: Erweiterte Verwendung
Nachdem Sie nun wissen, wie die Bibliothek funktioniert, können Sie einige fortgeschrittenere Szenarien ausprobieren.
Auswahl einer bestimmten Chrome-Version
Sie können eine bestimmte Chrome-Version für die Bibliothek festlegen, indem Sie das Argument version_main setzen:
import undetected_chromedriver as uc
# Geben Sie die Zielversion von Chrome an.
driver = uc.Chrome(version_main=105)
Beachten Sie, dass die Bibliothek auch mit anderen Chromium-basierten Browsern funktioniert, dies jedoch einige zusätzliche Anpassungen erfordert.
mit Sytnax
Um zu vermeiden, dass Sie die Methodequit()manuell aufrufen müssen, wenn Sie den Treiber nicht mehr benötigen, können Sie diewith-Syntaxwie unten gezeigt verwenden:
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("<YOUR_URL>")
Wenn der Code innerhalb des with-Blocks abgeschlossen ist, schließt Python den Browser automatisch für Sie.
Hinweis: Diese Syntax wird ab Version 3.1.0 unterstützt.
Proxy-Integration
Die Syntax zum Hinzufügen eines Proxys zu Undetected ChromeDriver ähnelt der von regulärem Selenium. Übergeben Sie einfach Ihre Proxy-URL an das Flag --proxy-server, wie unten gezeigt:
import undetected_chromedriver as uc
proxy_url = "<YOUR_PROXY_URL>"
options = uc.ChromeOptions()
options.add_argument(f"--proxy-server={proxy}")
Hinweis: Chrome unterstützt keine authentifizierten Proxys über das Flag --proxy-server.
Erweiterte API
undetected_chromedriver erweitert die reguläre Selenium-Funktionalität um einige Methoden, darunter:
WebElement.click_safe(): Verwenden Sie diese Methode, wenn das Klicken auf einen Link eine Erkennung auslöst. Die Funktion funktioniert zwar nicht garantiert, bietet jedoch einen alternativen Ansatz für sicherere Klicks.WebElement.children(tag=None, recursive=False): Mit dieser Methode können Sie leicht untergeordnete Elemente finden. Beispiel:
# Holen Sie sich das sechste untergeordnete Element (eines beliebigen Tags) innerhalb des Hauptteils und suchen Sie dann rekursiv alle <img>-Elemente.
images = body.children()[6].children("img", True)
Einschränkungen der Python-Bibliothek undetected_chromedriver
Obwohl undetected_chromedriver eine leistungsstarke Python-Bibliothek ist, weist sie einige bekannte Einschränkungen auf. Hier sind die wichtigsten, die Sie beachten sollten!
IP-Blöcke
Auf der GitHub-Seite der Bibliothek wird deutlich darauf hingewiesen:Das Paket verbirgt Ihre IP-Adresse nicht. Wenn Sie also ein Skript von einem Rechenzentrum aus ausführen, ist die Wahrscheinlichkeit hoch, dass es dennoch erkannt wird. Ebenso können Sie blockiert werden, wenn Ihre private IP-Adresse einen schlechten Ruf hat!

Um Ihre IP zu verbergen, müssen Sie den kontrollierten Browser mit einem Proxy-Server integrieren, wie zuvor gezeigt.
Keine Unterstützung für GUI-Navigation
Aufgrund der inneren Funktionsweise des Moduls müssen Sie programmgesteuert mit der Methode get() browsen. Vermeiden Sie die Verwendung der Browser-GUI für die manuelle Navigation – die Interaktion mit der Seite über Ihre Tastatur oder Maus erhöht das Risiko einer Erkennung!
Die gleiche Regel gilt für den Umgang mit neuen Tabs. Wenn Sie mit mehreren Tabs arbeiten müssen, öffnen Sie einen neuen Tab mit einer leeren Seite unter Verwendung der URL data: ( ja, einschließlich des Kommas) , die vom Treiber akzeptiert wird. Fahren Sie danach mit Ihrer üblichen Automatisierungslogik fort.
Nur wenn Sie diese Richtlinien einhalten, können Sie die Erkennung minimieren und reibungslosere Web-Scraping-Sitzungen genießen.
Eingeschränkte Unterstützung für den Headless-Modus
Offiziell wird der Headless-Modus von der Bibliothek „undetected_chromedriver“ nicht vollständig unterstützt. Sie können jedoch mit der folgenden Syntax damit experimentieren:
driver = uc.Chrome(headless=True)
Der Autor hat im Changelog der Version 3.4.5 angekündigt, dass der Headless-Modus funktionieren und die Umgehung von Bots garantieren sollte. Dennoch ist er weiterhin instabil. Verwenden Sie diese Funktion mit Vorsicht und führen Sie gründliche Tests durch, um sicherzustellen, dass sie Ihren Scraping-Anforderungen entspricht.
Stabilitätsprobleme
Wie auf der PyPI-Seite des Pakets erwähnt, können die Ergebnisse aufgrund zahlreicher Faktoren variieren. Es werden keine Garantien gegeben, außer der kontinuierlichen Bemühungen, Erkennungsalgorithmen zu verstehen und ihnen entgegenzuwirken.
Das bedeutet, dass ein Skript, das heute Distil, Cloudflare, Imperva, DataDome oder hCaptcha erfolgreich umgeht, morgen möglicherweise fehlschlägt, wenn die Anti-Bot-Lösungen aktualisiert werden:
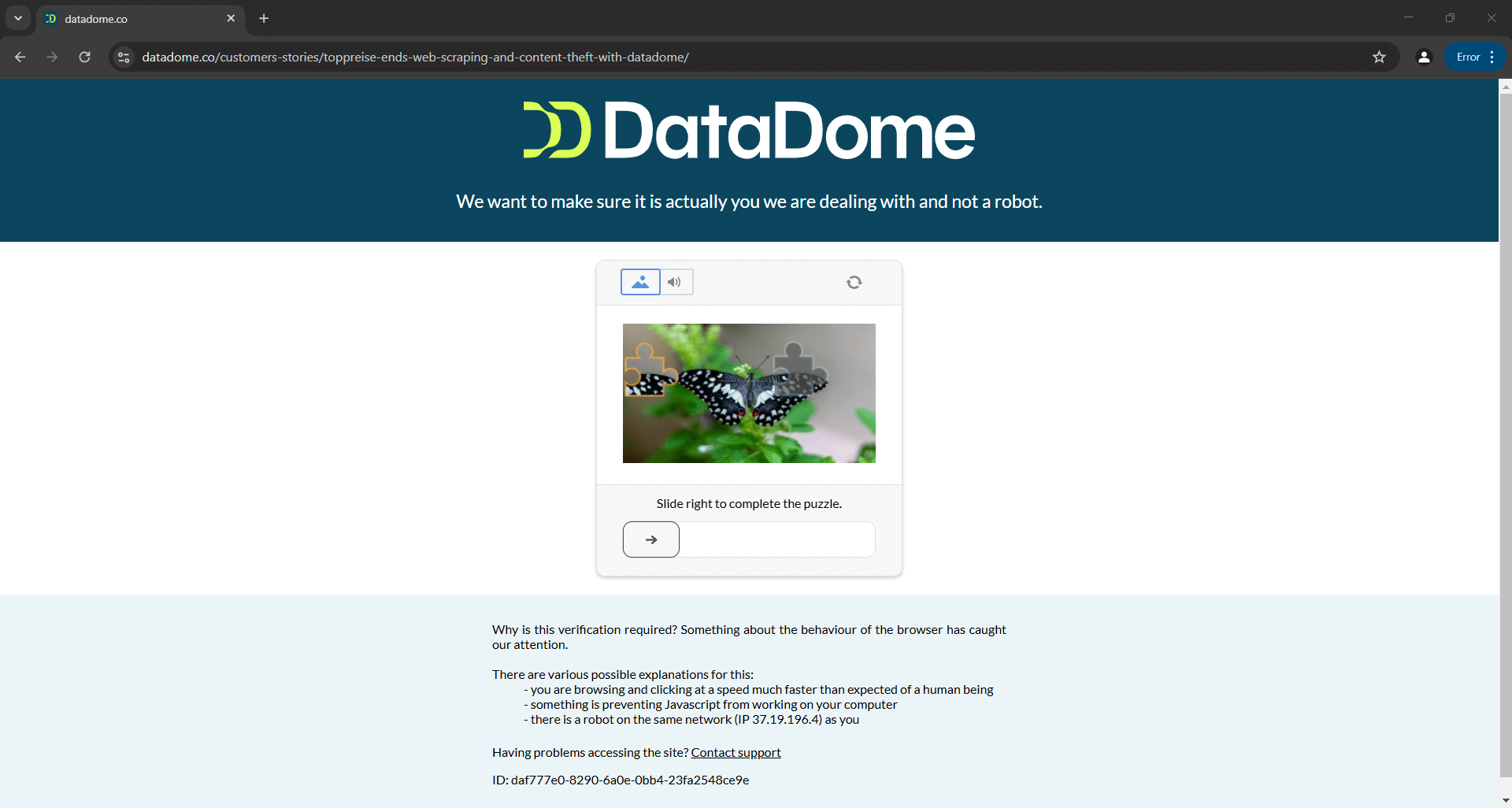
Das obige Bild ist das Ergebnis eines Skripts, das in der offiziellen Dokumentation bereitgestellt wird. Dies zeigt, dass selbst Skripte, die von den Entwicklern des Tools erstellt wurden, möglicherweise nicht immer wie erwartet funktionieren. Im Detail hat das Skript ein CAPTCHA ausgelöst, das Ihre Automatisierungslogik leicht stoppen kann.
Weitere Informationen finden Sie in unserem Leitfaden zumUmgehen von CAPTCHAs in Python.
Weiterführende Literatur
Undetected ChromeDriver ist nicht die einzige Bibliothek, die Browser-Treiber modifiziert, um eine Erkennung zu verhindern. Wenn Sie daran interessiert sind, ähnliche Tools zu entdecken oder mehr über dieses Thema zu erfahren, lesen Sie diese Anleitungen:
- Vermeiden Sie Blockierungen mit Puppeteer Stealth
- Bot-Erkennung mit Playwright Stealth vermeiden
- Leitfaden zum Web-Scraping mit SeleniumBase
Fazit
In diesem Artikel haben Sie gelernt, wie Sie mit Undetected ChromeDriver mit der Bot-Erkennung in Selenium umgehen können. Diese Bibliothek bietet eine gepatchte Version von ChromeDriver für das Web-Scraping, ohne blockiert zu werden.
Das Problem ist, dass fortschrittliche Anti-Bot-Technologien wie Cloudflare Ihre Skripte weiterhin erkennen und blockieren können. Bibliotheken wie undetected_chromedriver sind instabil – heute funktionieren sie vielleicht noch, morgen aber möglicherweise nicht mehr.
Das Problem liegt nicht bei der API von Selenium zur Steuerung eines Browsers, sondern bei den Einstellungen des Browsers selbst. Das bedeutet, dass die Lösung ein cloudbasierter, stets aktualisierter, skalierbarer Browser mit integrierter Anti-Bot-Bypass-Funktionalität ist. Dieser Browser existiert und heißtScraping-Browser!
Der Scraping-Browser von Bright Data ist ein hoch skalierbarer Cloud-Browser, der mitSelenium,Puppeteer,Playwright und anderen funktioniert. Er kann Browser-Fingerprinting, CAPTCHA-Auflösung und automatische Wiederholungsversuche für Sie übernehmen. Außerdem wechselt er bei jeder Anfrage automatisch die Exit-IP. Möglich wird dies durch das weltweite Proxy-Netzwerk, das Folgendes umfasst:
- Datacenter-Proxys– Über 770.000 Rechenzentrums-IPs.
- Residential-Proxys– Über 72 Millionen Residential-IPs in mehr als 195 Ländern.
- ISP-Proxys– Über 700.000 ISP-IPs.
- Mobile-Proxy– Über 7 Millionen mobile IPs.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unseren Scraping-Browser auszuprobieren oder unsere Proxys zu testen.




