

In diesem Tutorial lernen Sie:
- Was AWS Glue ist und was es bietet.
- Warum Bright Data dank seiner Webdatenabrufdienste ETL-Pipelines unterstützt.
- Wie Sie Bright Data in einen ETL-Job in AWS Glue integrieren können.
Lassen Sie uns loslegen!
Was ist AWS Glue?
AWS Glue ist ein serverloser Datenintegrationsdienst, der entwickelt wurde, um das Auffinden, Vorbereiten und Kombinieren von Daten aus mehreren Quellen in beliebiger Größe zu vereinfachen.
Damit können Sie ETL-Workflows (Extract, Transform, Load) für Analysen, maschinelles Lernen und Anwendungsentwicklung erstellen, ohne die Infrastruktur verwalten zu müssen. AWS Glue beschleunigt die Entwicklung von Datenpipelines und macht Daten für Analysen leicht zugänglich. Dies wird durch die Zentralisierung Ihres Datenkatalogs und die Bereitstellung visueller und code-basierter Tools zur Job-Erstellung erreicht.
Die drei wichtigsten Funktionen sind:
- Daten finden und organisieren: Schemata automatisch ableiten, Metadaten katalogisieren und Verbindungen zu Datenquellen in AWS, vor Ort und in anderen Clouds herstellen.
- Daten transformieren und bereinigen: Visueller Job-Editor, interaktive Notizbücher, Streaming-ETL-Unterstützung und integrierte ML-basierte Deduplizierung.
- Erstellen und überwachen Sie Pipelines: Planen, automatisieren und skalieren Sie Jobs und überwachen Sie Pipelines mit detaillierten Einblicken und Triggern.
Weitere Informationen finden Sie in der offiziellen Dokumentation.
Warum Sie Bright Data in Ihren AWS Glue ETL-Workflow integrieren sollten
Die Integration von Bright Data in einen AWS ETL-Workflow kann den Umfang und die Qualität Ihrer Datenpipelines erheblich erweitern.
Während sich ETL traditionell auf die Extraktion strukturierter Daten aus bekannten Quellen konzentriert, ermöglicht Bright Data den Zugriff auf strukturierte Webdaten in Echtzeit. Dadurch werden Erkenntnisse gewonnen, die sonst nur durch manuelle Erfassung oder komplexe Scraping-Infrastrukturen möglich wären.
Über die Extraktion (E) umfangreicher Webdaten hinaus kann Bright Data auch Ihre Transformationsphase (T) verbessern. Während der Transformation können Sie Datensätze anreichern, indem Sie Ihren Datensätzen Live-Markt-, Produkt- oder Sozialinformationen hinzufügen. Sie könnten beispielsweise Aktienkurskennzahlen, Preise von Wettbewerbern oder Unternehmensmetadaten zu Ihren internen Datensätzen hinzufügen.
Diese Erkenntnisse helfen Teams, fundiertere Entscheidungen zu treffen. Die Datenüberprüfung ist ein weiterer wichtiger Vorteil, da die gescraped Daten mit maßgeblichen Quellen abgeglichen werden können. So können Sie die Genauigkeit sicherstellen, bevor Sie die Daten in Ihren Zieldatenspeicher laden.
So verwenden Sie Bright Data zum Abrufen von Webdaten für einen AWS Glue ETL-Job
In diesem Abschnitt wird eine mögliche Integration von Bright Data in einen AWS Glue ETL-Job vorgestellt. Konkret erfahren Sie, wie Sie diese Beispiel-ETL-Pipeline erstellen:
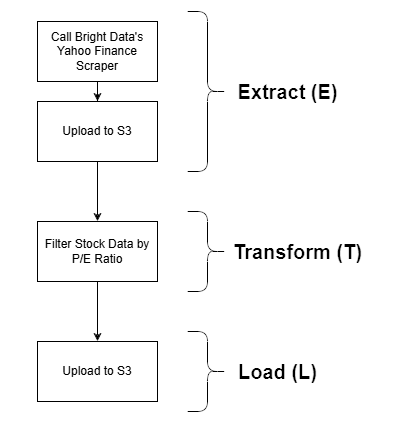
Bright Data kommt dank seiner leistungsstarken Optionen zum Abrufen von Webdaten in der Extraktionsphase (E) zum Einsatz. Der Yahoo Finance Scraper wird verwendet, um Aktienkurse abzurufen, die dann nach dem Kurs-Gewinn-Verhältnis gefiltert und schließlich in einem S3-Bucket gespeichert werden. Dies ist ein einfaches Beispiel, aber dennoch eine realistische Demonstration eines vollständigen ETL-Workflows.
Hinweis: Nach diesem Tutorial können Sie weitere Ansätze zur Integration von Bright Data in AWS Glue erkunden und in Betracht ziehen.
Befolgen Sie die nachstehenden Anweisungen, um loszulegen!
Voraussetzungen
Bevor Sie dieses Tutorial befolgen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Ein AWS-Konto (auch ein kostenloses Testkonto ist ausreichend).
- Ein Bright Data-Konto mit einem konfigurierten API-Schlüssel. Befolgen Sie die offiziellen Anweisungen, um Ihren API-Schlüssel zu generieren.
- Einen in Ihrem AWS-Konto definierten S3-Bucket.
- Grundlegende Python-Kenntnisse, um ein Skript zu schreiben, das sich in die Scraping-APIs von Bright Data integriert und die gescrapten Daten in Ihren S3-Bucket hochlädt.
- Grundlegende SQL-Kenntnisse zum Schreiben einer einfachen Abfrage in der Transformationsphase (T) der ETL-Pipeline.
Für dieses Tutorial gehen wir davon aus, dass Ihr S3-Bucket den Namen „bright-data-etl-bucket” trägt:
Es ist außerdem hilfreich, wenn Sie mit der Funktionsweise der Bright Data Web-Scraping-APIs vertraut sind.
Schritt 1: Erste Schritte mit den Bright Data Scraping-APIs
Bei der Entwicklung einer ETL-Pipeline sollten Sie natürlich mit der Extraktionsphase (E) beginnen. Der erste Schritt besteht darin, Daten mit dem Bright Data Yahoo Finance Scraper abzurufen. Daher ist es wichtig, sich damit vertraut zu machen.
Erstellen Sie zunächst ein Bright Data-Konto, falls Sie noch keines haben. Andernfalls melden Sie sich bei Ihrem bestehenden Konto an. Navigieren Sie im Kontrollfeld zum Abschnitt„Scrapers“:
Wechseln Sie anschließend zur Registerkarte „Web Scrapers Library”. Suchen Sie nach „finance” und wählen Sie die Option „Yahoo Finance Scraper”. Greifen Sie auf den verfügbaren Scraper zu:
Auf der Seite „Yahoo Finance Scraper“ können Sie die Eingabeanforderungen und das Ausgabeschema dieses Scrapers erkunden:
Das Control Panel bietet auch Code-Schnipsel in mehreren Programmiersprachen für eine schnelle Einrichtung. Der wichtigste Punkt ist, dass der Scraper eine oder mehrere Yahoo Finance-Aktienseiten als Eingabe akzeptiert und strukturierte Echtzeit-Aktien-Daten zurückgibt. Perfekt!
Schritt 2: Konfigurieren Sie die S3-Übertragung
Die Web-Scraping-APIs von Bright Data unterstützen die automatische Lieferung der gescrapten Daten an Amazon S3. Es ist daher sinnvoll, diese nützliche Funktion zu nutzen, um den Schritt der Datenerfassung zu beschleunigen. Um die Amazon S3-Lieferung zu konfigurieren, müssen Sie zunächst den asynchronen Modus aktivieren.
Wählen Sie auf der Registerkarte „Konfiguration“ die Option „Asynchron“. Klicken Sie dann auf die Schaltfläche „Lieferungseinstellungen“:
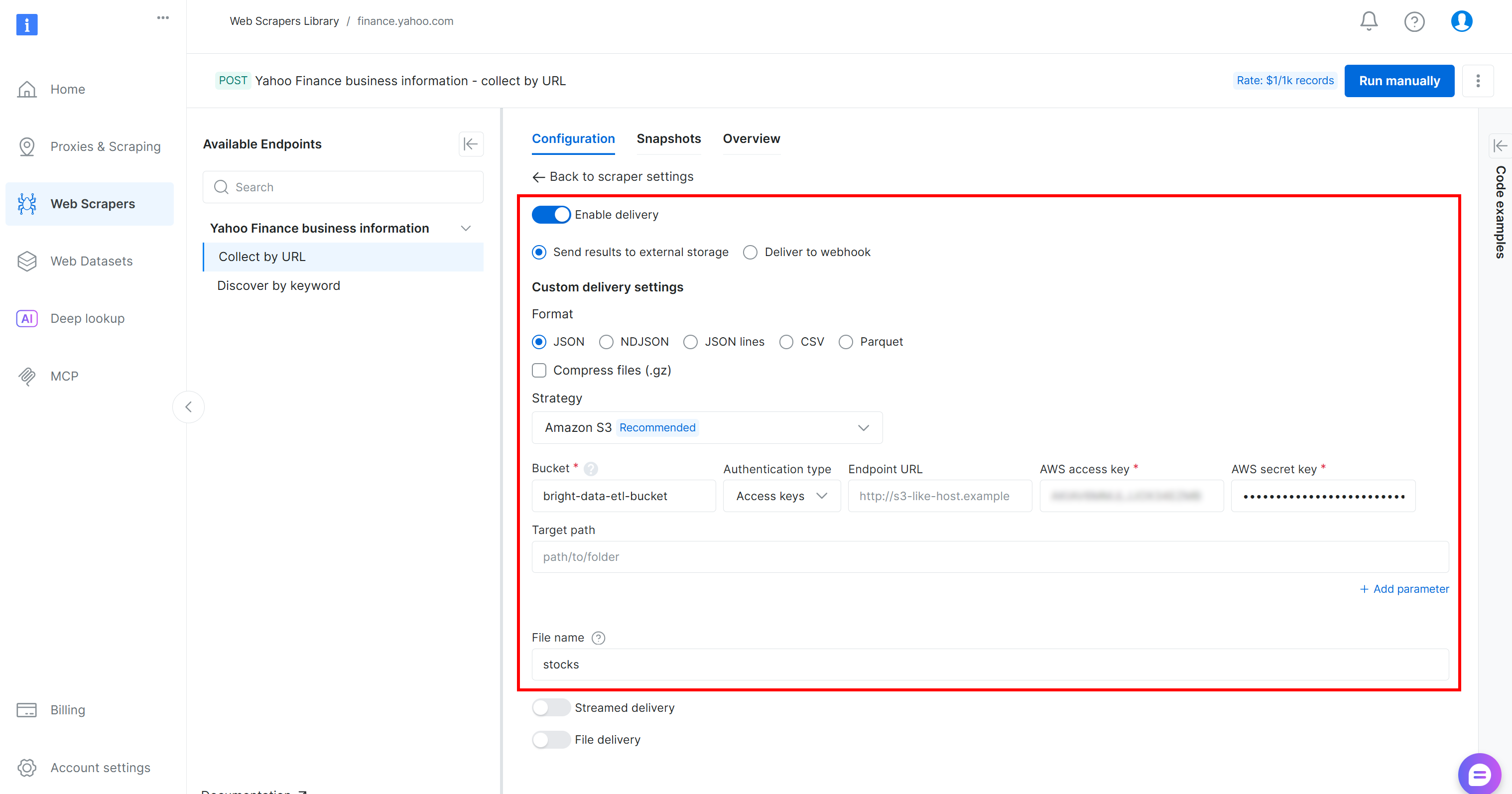
Konfigurieren Sie die Datenübermittlung an Ihren Amazon S3-Bucket, indem Sie das Formular wie folgt ausfüllen:
- Aktivieren Sie die Option „Übertragung aktivieren“.
- Legen Sie das Format auf
JSONfest. - Wählen Sie „Amazon S3“ als Speicherziel.
- Geben Sie den Namen Ihres S3-Buckets ein (in diesem Beispiel
„bright-data-etl-bucket“). (Das Feld „Endpunkt-URL“ kann leer bleiben.) - Lassen Sie das Feld „Zielpfad“ leer, um die Datei in den Stammordner des Buckets hochzuladen.
- Setzen Sie die Option „Authentifizierungstyp“ auf den Wert „Zugriffsschlüssel“.
- Fügen Sie Ihre AWS-Zugriffsschlüssel-ID und Ihren geheimen AWS-Zugriffsschlüssel ein.
- Legen Sie den Dateinamen auf
„stocks“fest.
Mit dieser Konfiguration wird die Web-Scraping-API im asynchronen Modus ausgeführt. Das bedeutet, dass Bright Data eine Scraping-Aufgabe erstellt, die auf seiner Infrastruktur ausgeführt wird. Sobald die Aufgabe abgeschlossen ist, werden die gescrapten Daten automatisch in Ihren Amazon S3-Bucket hochgeladen, wo sie von Ihrem AWS Glue ETL-Job abgerufen werden können. Fantastisch!
Schritt 3: Führen Sie die Webdaten-Extraktionslogik aus
Um zu überprüfen, ob die Webdaten-Extraktionslogik funktioniert, fügen Sie einige Yahoo Finance-Aktien-URLs hinzu (z. B. NVDA, AAPL, GOOGL, MSFT, AMZN, TSLA, META, AVGO, BRK.B, LLY) und klicken Sie auf die Schaltfläche „Manuell ausführen“: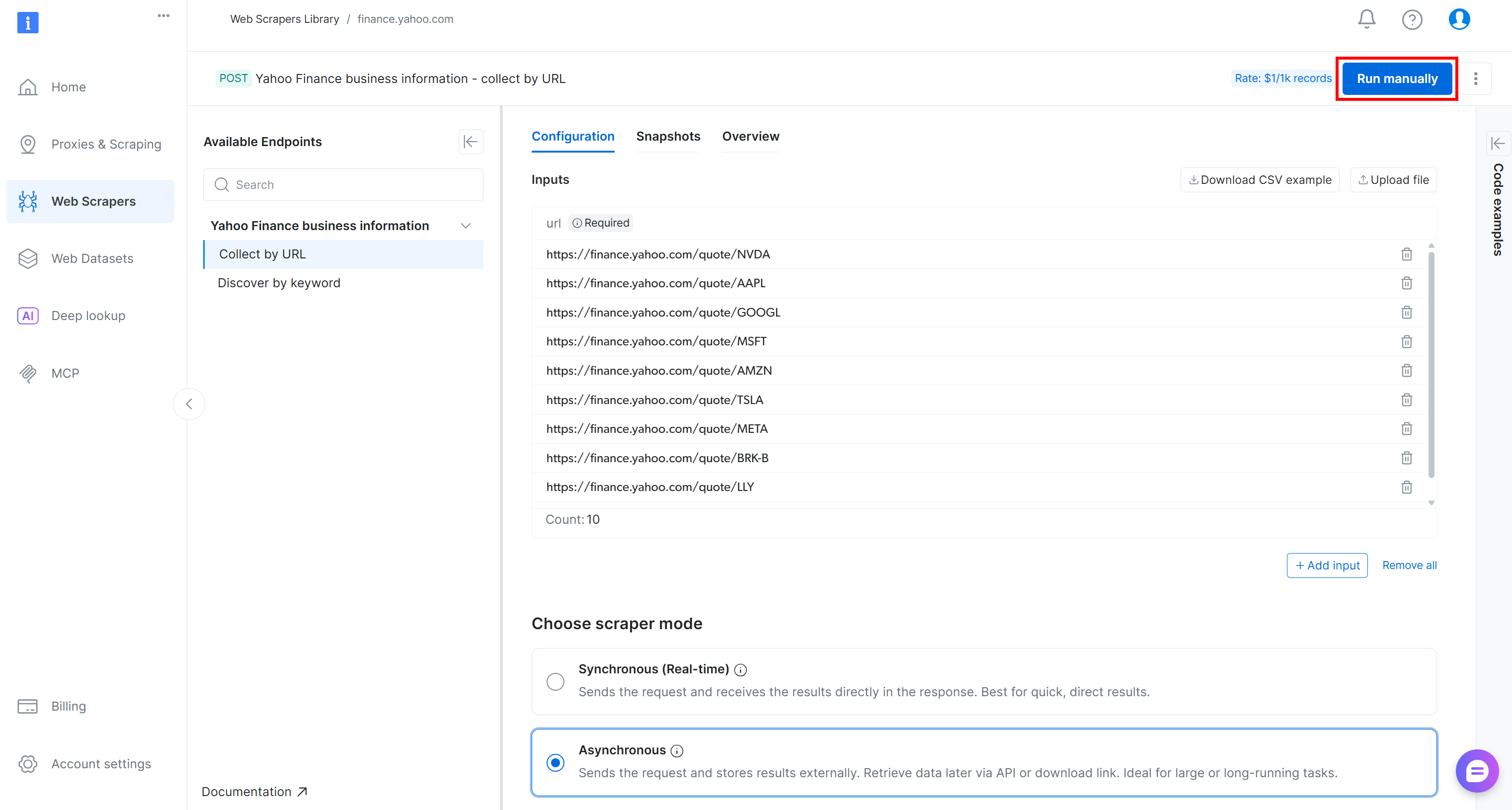
Die Scraping-API-Anfrage wird gesendet und die Scraping-Aufgabe wird in der Cloud gestartet. Sie können den Status der Aufgabe in Echtzeit über das Bright Data-Kontrollpanel überwachen:
Alternativ können Sie das gleiche Ergebnis programmgesteuert erzielen, indem Sie einen der in der Bright Data-Konsole verfügbaren Code-Schnipsel (siehe rechte Spalte) in Ihrer bevorzugten Programmiersprache ausführen:
Wenn sich der Status der Aufgabe zu „Bereit“ ändert, überprüfen Sie Ihren AWS S3-Bucket. Sie sollten eine neue Datei mit dem Namen stocks.json finden:
Wenn Sie die Datei stocks.json in Ihrem Browser öffnen, sehen Sie etwa Folgendes: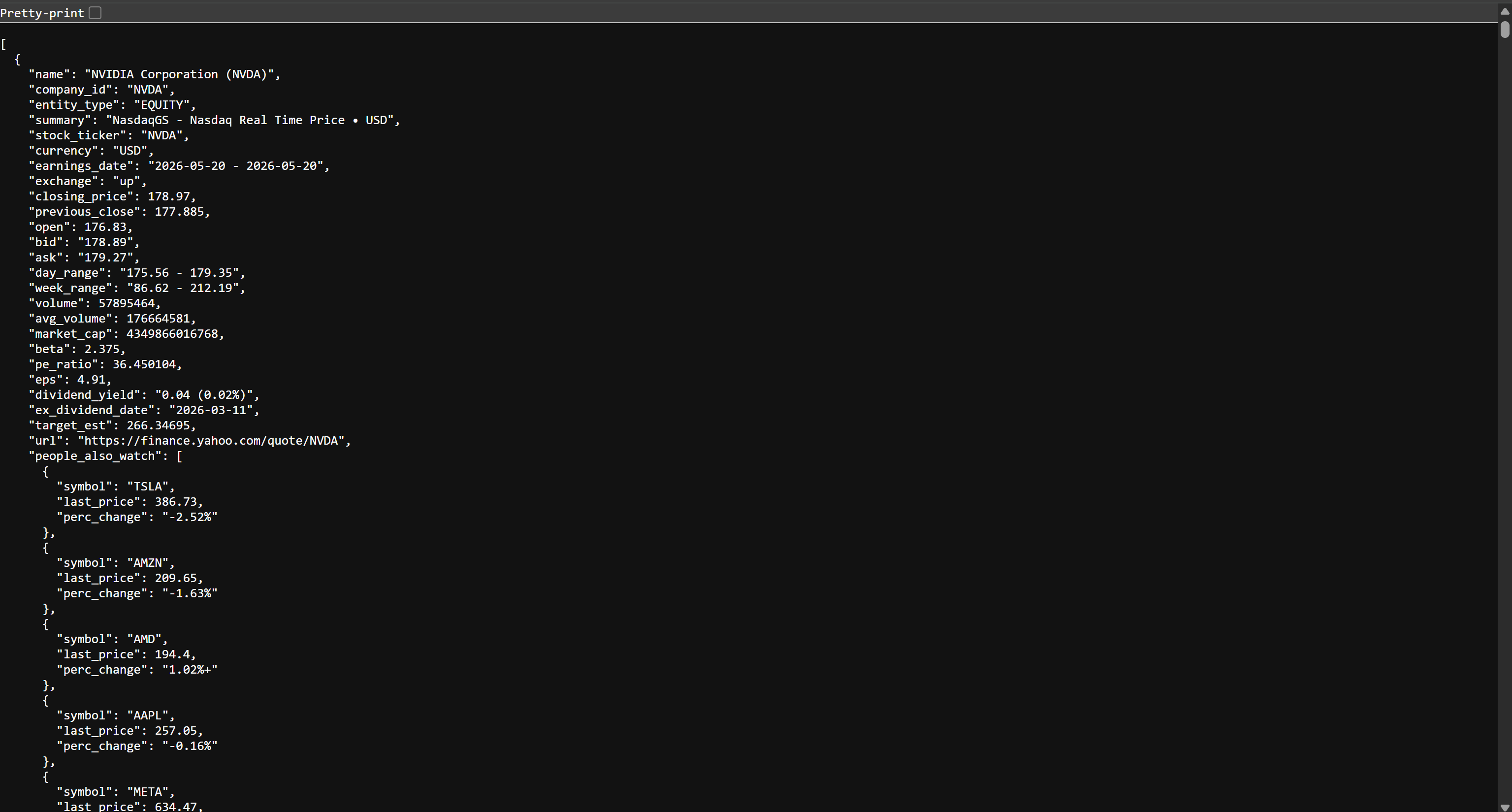
Dies sind dieselben Aktiendaten, die auch auf Yahoo Finance verfügbar sind, jedoch im JSON-Format strukturiert. Diese Daten wurden von der Bright Data Web-Scraping-API gesammelt. Mission erfüllt! Sie verfügen nun über die erforderlichen Daten, um Ihre AWS Glue ETL-Pipeline zu erstellen.
Schritt 4: Initialisieren Sie Ihren AWS Glue-Job
Melden Sie sich bei der AWS-Konsole an und suchen Sie nach dem Begriff „AWS Glue“. Wählen Sie den Dienst aus, um dessen Hauptseite zu öffnen.
Klicken Sie dort auf die Schaltfläche „Go to ETL jobs“, um AWS Glue Studio zu öffnen, die offizielle Schnittstelle zum Erstellen von ETL-Workflows:
Hier können Sie einen neuen AWS Glue-Job initialisieren. Wählen Sie für dieses Tutorial die Option „Visual ETL”. Diese Option wird für die Erstellung von Pipelines über eine vereinfachte Drag-and-Drop-Oberfläche empfohlen.
Sie gelangen dann zu einer leeren Arbeitsfläche, auf der Sie Ihren AWS Glue ETL-Workflow visuell definieren können, indem Sie verschiedene Knoten miteinander verbinden:
Geben Sie Ihrem ETL-Job einen aussagekräftigen Namen, z. B. „Bright Data Glue ETL Job“. Sobald dies erledigt ist, können Sie mit dem Aufbau Ihrer ETL-Pipeline beginnen.
Schritt 5: Erstellen Sie eine IAM-Rolle
Um einen AWS Glue-Job auszuführen, müssen Sie eine IAM-Rolle für den Zugriff auf Ressourcen wie Amazon S3 und die Verwaltung von AWS Glue bereitstellen. Diese Berechtigungen sind für Glue-Komponenten wie Jobs, Crawler und Entwicklungsendpunkte erforderlich.
Um die Rolle direkt in Glue Studio zu erstellen, gehen Sie zum Bereich „Jobdetails“ und klicken Sie auf die Schaltfläche „Neue Rolle erstellen“: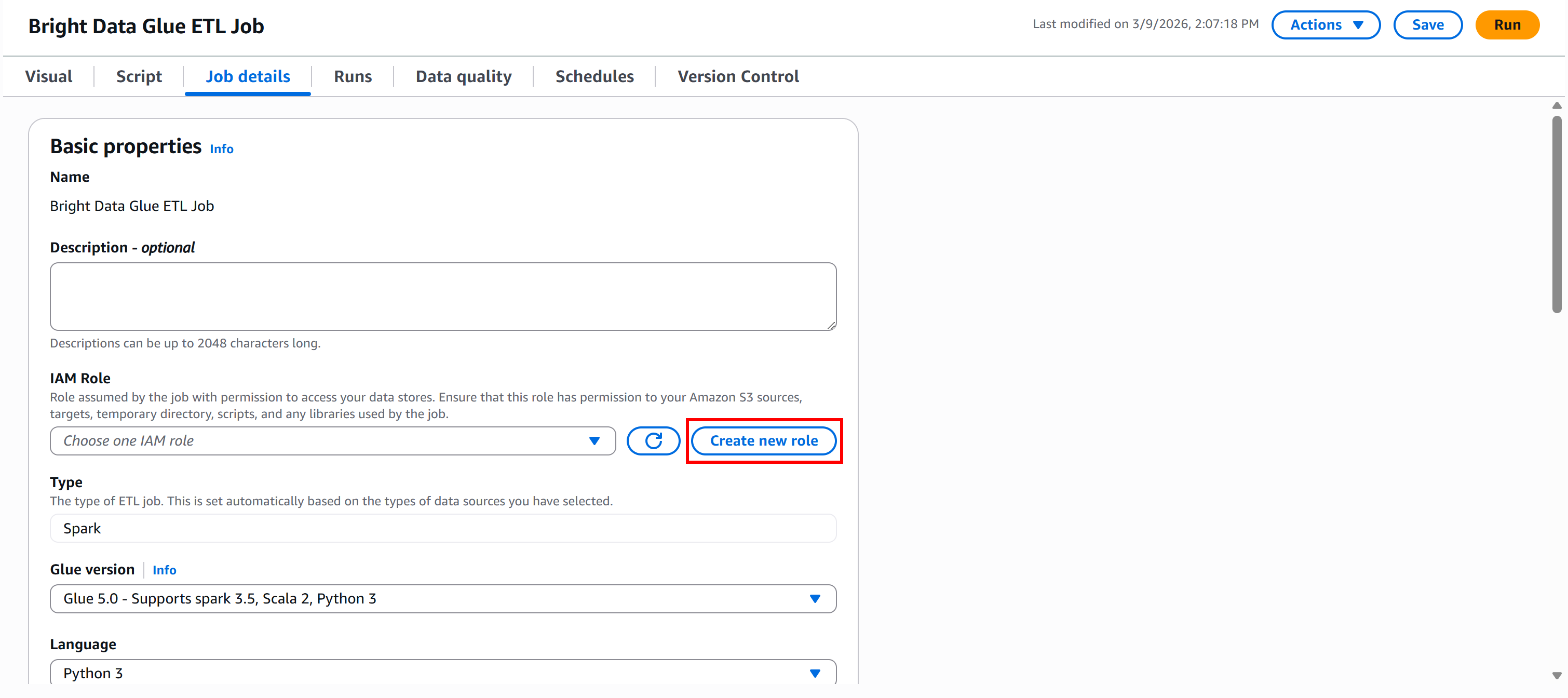
Geben Sie im Abschnitt „Rolle erstellen“ Ihrer IAM-Rolle einen aussagekräftigen Namen, z. B. „bd-glue-role“:
Standardmäßig fügt AWS die beiden erforderlichen Richtlinien hinzu:
AWSGlueConsoleFullAccess: Bietet vollständigen Zugriff auf AWS Glue über die AWS Management Console.AWSGlueServiceRole: Richtlinie für die AWS Glue-Dienstrolle, die den Zugriff auf verwandte Dienste wie EC2, S3 und Cloudwatch Logs ermöglicht.

Rufen Sie als Nächstes die ARN Ihres S3-Buckets ab. Sie finden sie auf der Seite „Eigenschaften“ Ihres Buckets in der S3-Konsole:
Diese Informationen benötigen Sie, um die von AWS Glue bereitgestellte Standardrichtlinie zu überschreiben. Fügen Sie die S3-Bucket-ARN in das Feld „Ressource“ im Texteditor „Zusätzliche Richtlinie“ auf der Seite „Rolle erstellen“ ein:
„Resource”: {
„<YOUR_S3_BUCKET_ARN>/*”
} 
Klicken Sie abschließend auf die Schaltfläche „Rolle erstellen“. Sobald die Rolle erstellt wurde, wird sie automatisch in Ihrer AWS Glue-Jobkonfiguration angezeigt: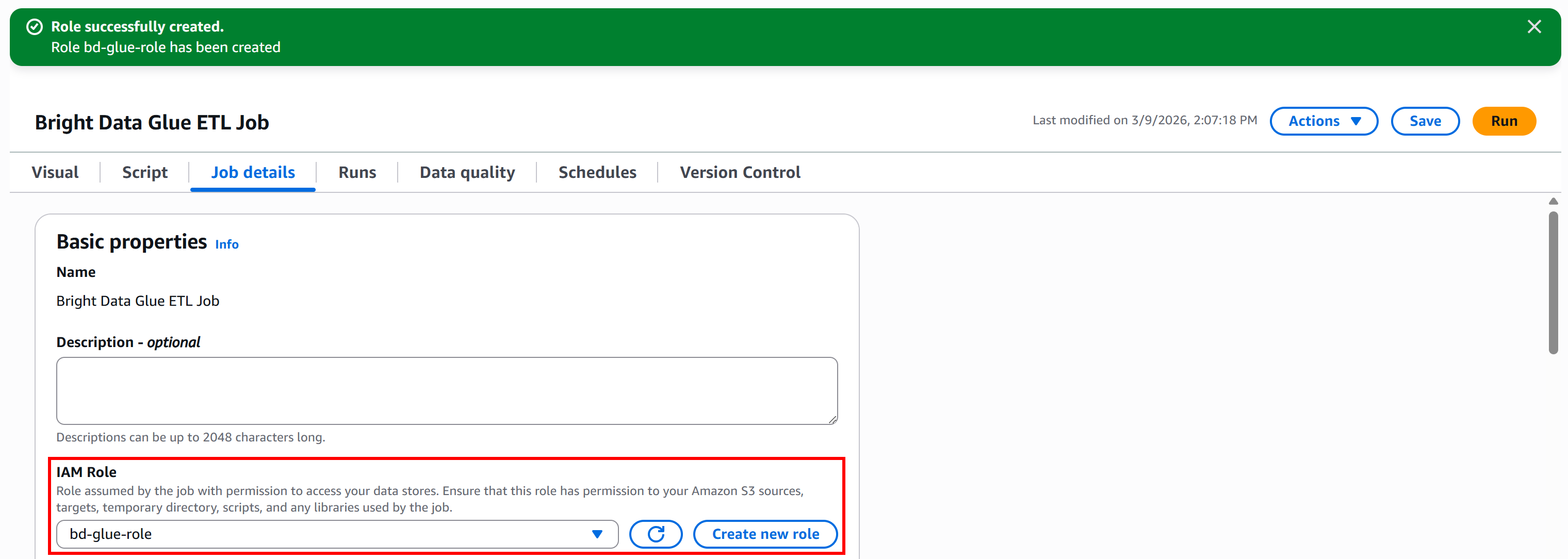
Großartig! Ihr AWS Glue-Job verfügt nun über eine IAM-Rolle mit den erforderlichen Berechtigungen für den Zugriff auf S3 und die Ausführung Ihrer ETL-Pipeline.
Schritt 6: Fügen Sie den Knoten „Extrahieren (E)“ zu Ihrer Pipeline hinzu
Die Extraktionsphase (E) der Pipeline begann, als Sie den Bright Data-Scraper ausgeführt haben, der die Aktienkurse erfasst und in Amazon S3 hochgeladen hat.
Jetzt besteht das Ziel darin, Ihre AWS Glue ETL-Pipeline mit diesen Daten zu verbinden, damit sie verarbeitet werden können. Gehen Sie dazu auf die Registerkarte „Quellen“ im Bereich „Knoten hinzufügen“ und wählen Sie den Knoten „Amazon S3“ aus.
Ein Knoten „Datenquelle – S3-Bucket – Amazon S3“ wird auf der Arbeitsfläche angezeigt. Klicken Sie darauf und konfigurieren Sie die S3-Quelle: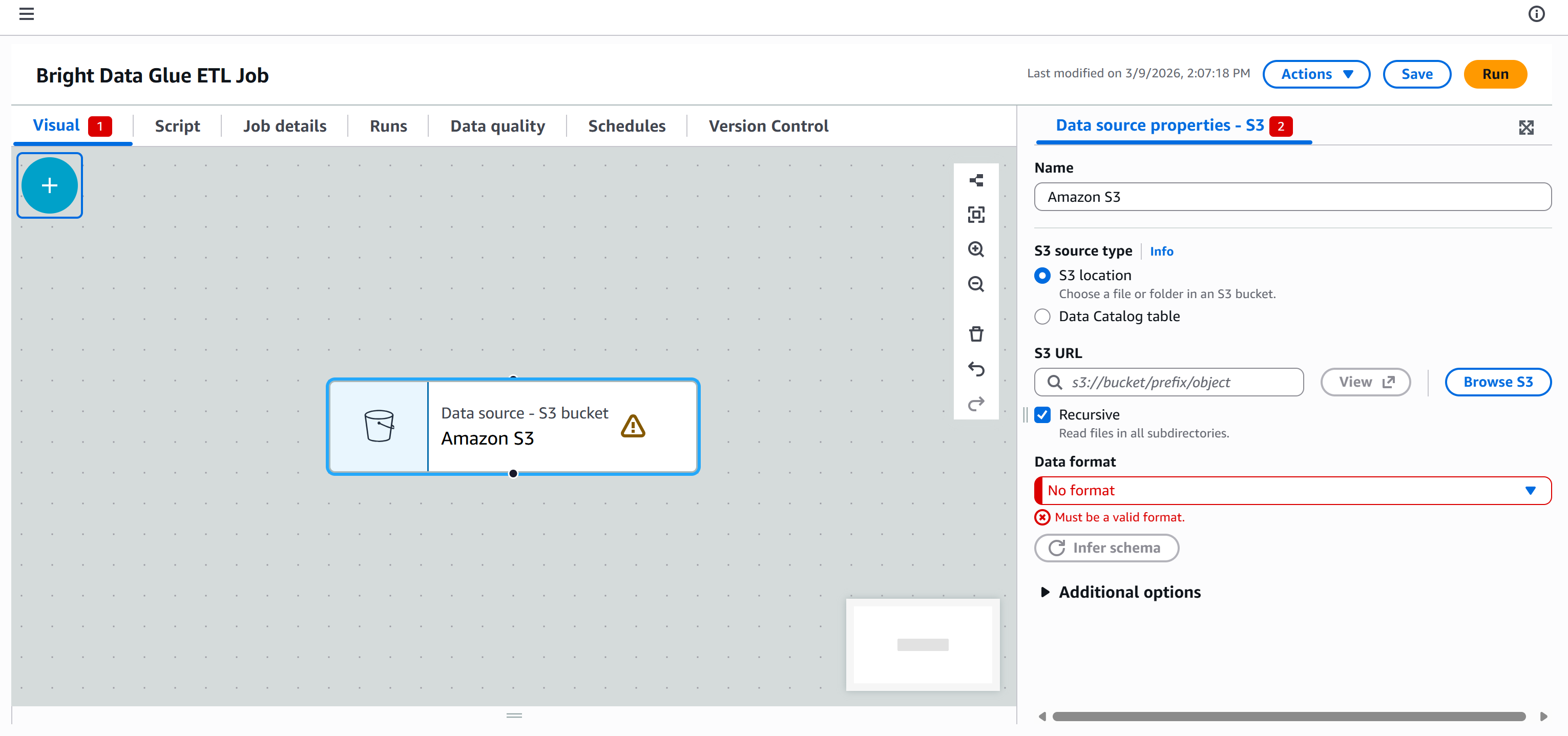
Klicken Sie auf die Schaltfläche „S3 durchsuchen“ und wählen Sie Ihren S3-Bucket aus (z. B. bright-data-etl-bucket).
Nach der Auswahl des Buckets füllt AWS Glue das Feld „S3-URL“ mit einem Eintrag wie dem folgenden:
s3://bright-data-etl-bucketStandardmäßig versucht AWS Glue, alle Dateien innerhalb des angegebenen S3-Pfads zu lesen. Da wir den genauen Namen der Eingabedatei kennen, aktualisieren Sie das Feld „S3-URL“, damit es direkt darauf verweist:
s3://bright-data-etl-bucket/stocks.jsonDadurch wird AWS Glue angewiesen, die zuvor hochgeladene Datei „stocks.json“ zu verwenden, die die mit Yahoo Finance Scraper gesammelten Daten enthält.
Konfigurieren Sie als Nächstes das Datenformat. Da es sich bei dem Eingabedatensatz um eine JSON-Datei handelt, wählen Sie „JSON” als Eingabeformat aus.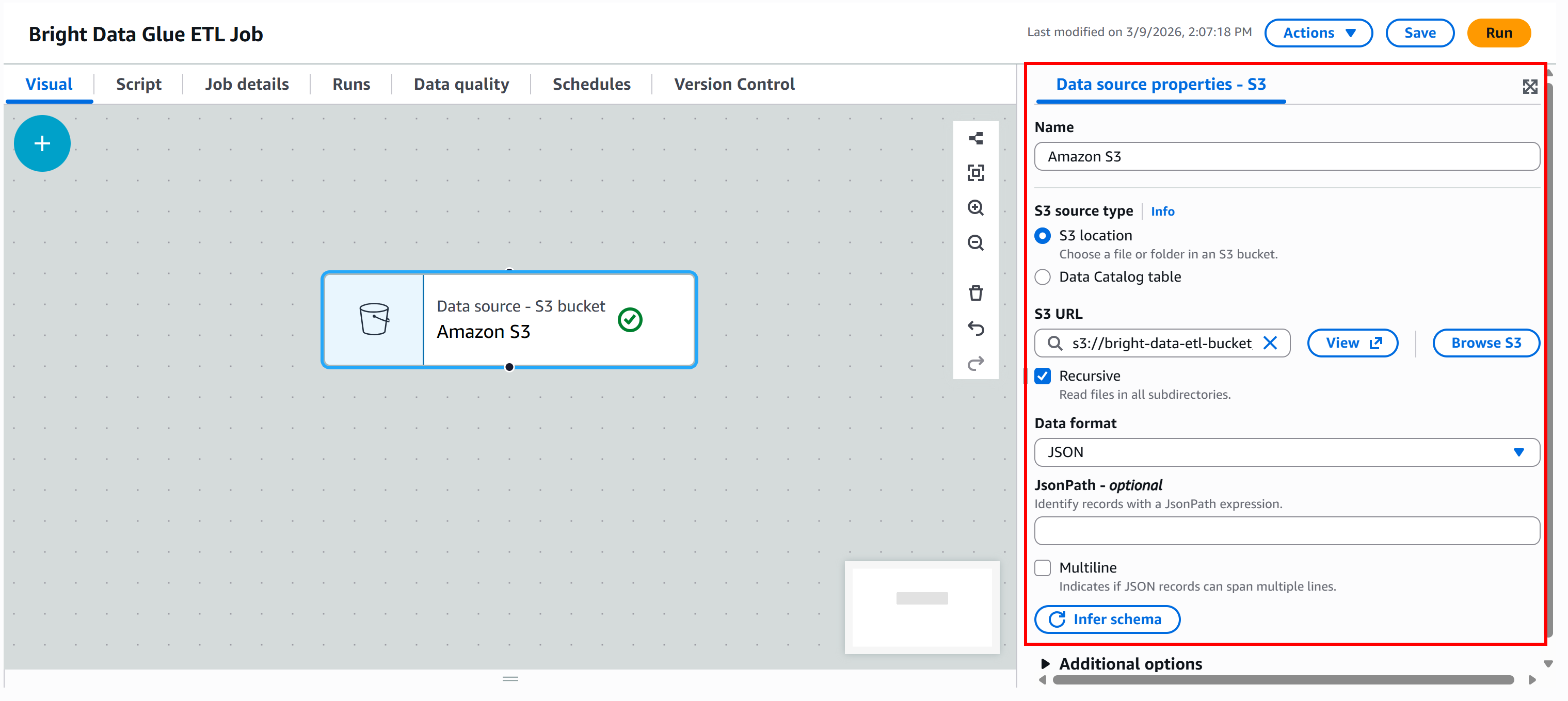
Klicken Sie dann auf die Schaltfläche „Schema ableiten“. AWS Glue analysiert automatisch die JSON-Eingabedatei und generiert das entsprechende Schema.
Im Abschnitt „Output schema“ (Ausgabeschema) des Knotens sehen Sie die aus den JSON-Daten abgeleitete Struktur:
Das abgeleitete Schema stimmt mit dem von Bright Data Yahoo Finance Scraper zurückgegebenen Ausgabedatenschema überein. Cool!
Schritt 7: Definieren Sie die Transformationslogik (T)
Wie bereits erwähnt, handelt es sich hierbei nur um ein einfaches Beispiel, daher wird der Transformationsschritt (T) minimal gehalten. Das Ziel besteht darin, die Quelldaten mithilfe einer SQL-Abfrage zu filtern und nur Unternehmen zu behalten, deren KGV unter 30 liegt.
Gehen Sie dazu auf die Registerkarte „Transformierungen“ und wählen Sie den Knoten „SQL-Abfrage“ aus:
Der Knoten wird zur Arbeitsfläche hinzugefügt. Klicken Sie darauf und konfigurieren Sie ihn so, dass der übergeordnete Knoten „Amazon S3” ist. Das bedeutet, dass die Ausgabe des Amazon S3-Knotens zur Eingabe des Knotens „SQL-Abfrage” wird. Mit anderen Worten: Sie führen eine SQL-Abfrage auf den gescrapten JSON-Daten aus.
Definieren Sie als Nächstes den Aliasnamen für den Eingabedatensatz als „stocks“ und fügen Sie diese SQL-Abfrage hinzu:
select stock_ticker, pe_ratio from stocks
WHERE pe_ratio < 30;Diese Abfrage wählt die Felder „stock_ticker“ und „pe_ratio“ aus jeder gescrapten Aktie aus und behält nur diejenigen, deren KGV unter 30 liegt.
Falls Sie sich fragen, woher diese Felder stammen: „stock_ticker“ und „pe_ratio“ sind zwei der Attribute, die vom Bright Data Yahoo Finance Scraper zurückgegeben werden (die AWS Glue im vorherigen Schritt automatisch abgeleitet hat):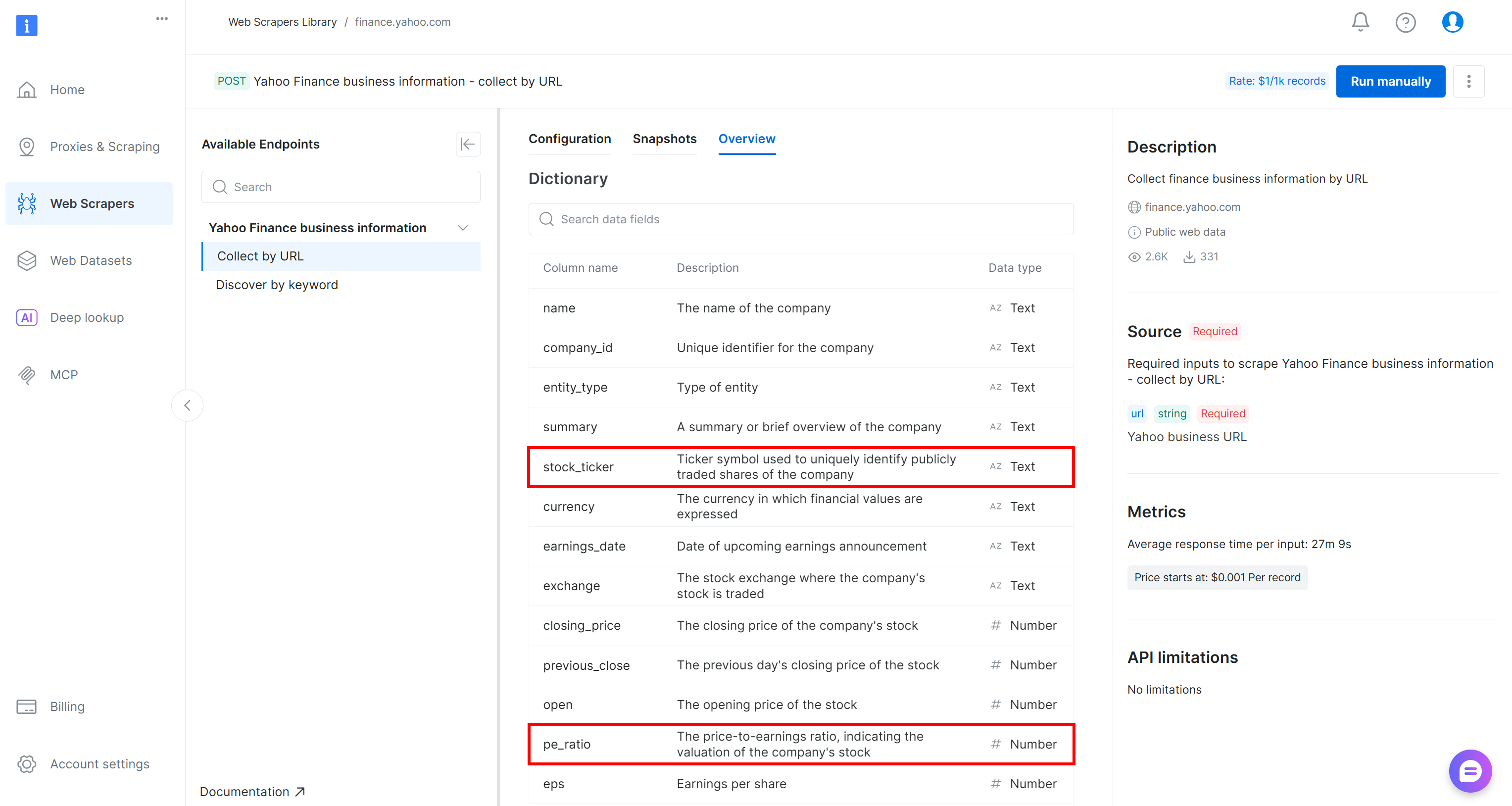
Zu diesem Zeitpunkt sollte Ihre ETL-Pipeline wie folgt aussehen: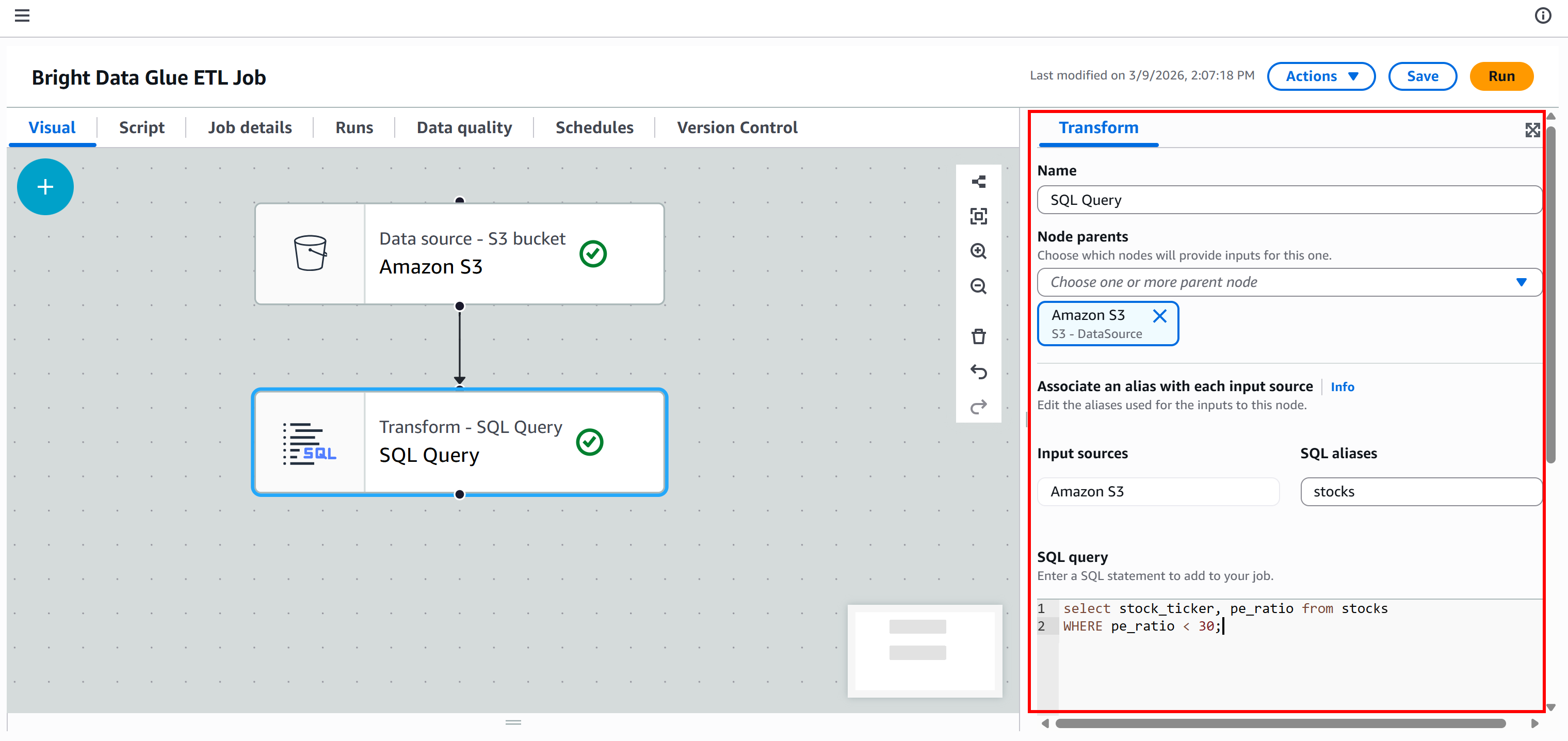
Hinweis: In realen Pipelines umfasst die Transformationsphase (T) in der Regel mehrere Schritte. Sie können diese implementieren, indem Sie mehrere Transformationsknoten hinzufügen und diese sequenziell verbinden oder indem Sie mehrere Verzweigungen im Workflow erstellen.
Schritt 8: Verbinden Sie sich in der Load-Phase (L) mit Ihrem S3-Bucket
Die Ausgabe Ihres „SQL Query”-Knotens sind die gefilterten, transformierten Daten. Der letzte Schritt besteht darin, diese Daten in Ihrem S3-Bucket zu speichern, um die Load (L) -Phase Ihrer ETL-Pipeline abzuschließen.
Fügen Sie auf der Registerkarte „Targets“ einen weiteren Amazon S3-Knoten hinzu:
Klicken Sie auf den neuen Knoten, um ihn zu konfigurieren. Legen Sie den übergeordneten Knoten als Ihren „SQL-Abfrage”-Knoten fest. Die Ausgabe des „SQL-Abfrage”-Knotens wird als Eingabe an den neuen Amazon S3-Knoten gesendet.
Definieren Sie das Ausgabeformat als „JSON“ ohne Komprimierung. Geben Sie dann den Ziel-S3-Ordner an, z. B.:
s3://bright-data-etl-bucket/output/Hinweis: Ersetzen Sie „bright-data-etl-bucket“ durch den Namen Ihres tatsächlichen S3-Buckets.
Auf diese Weise werden die transformierten Daten im Ordner „/output“ gespeichert.
Behalten Sie alle anderen Optionen als Standard bei und klicken Sie dann auf „Speichern“, um Ihren AWS Glue ETL-Job zu aktualisieren: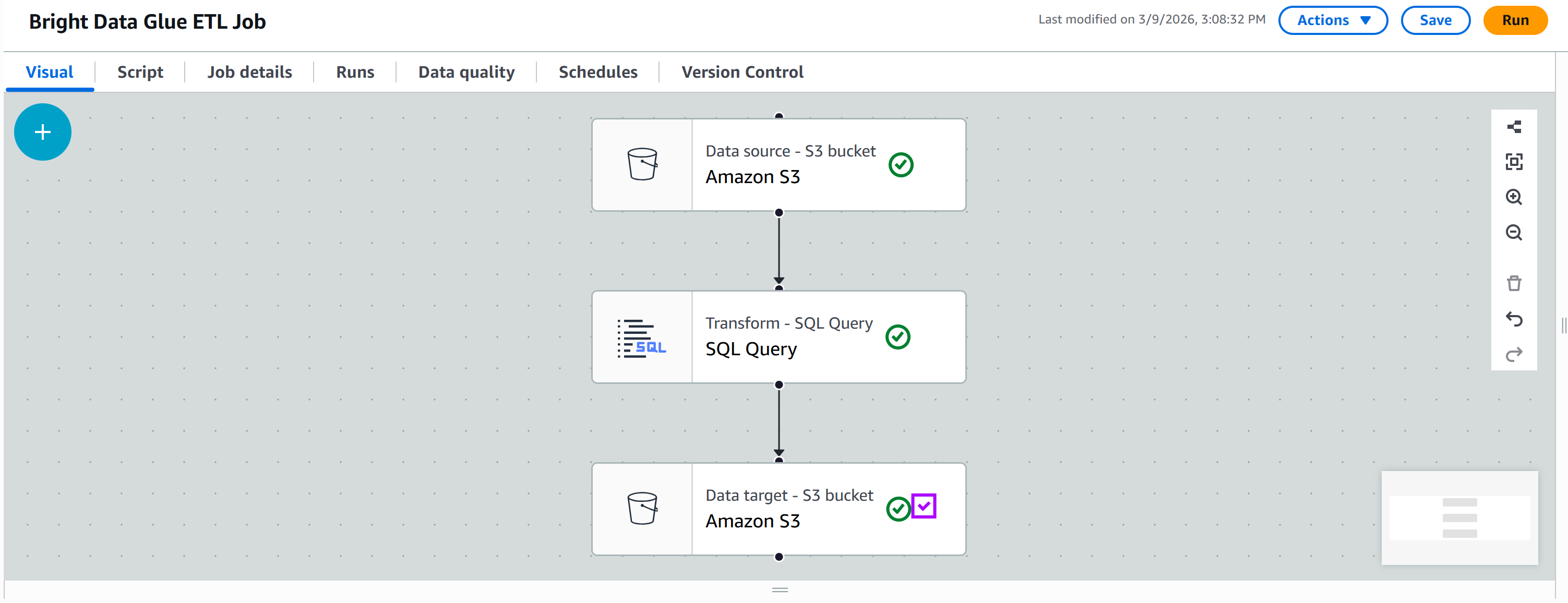
Großartig! Ihre ETL-Pipeline ist nun vollständig konfiguriert und bereit zur Ausführung.
Schritt 9: Führen Sie die Pipeline aus und sehen Sie sich die Ergebnisse an
Klicken Sie auf die Schaltfläche „Ausführen“, um Ihren AWS Glue-Job zu starten. Sie sollten eine Benachrichtigung wie diese sehen:
Wechseln Sie zur Registerkarte „Ausführungen“, um die Ausführung Ihrer Pipeline zu überwachen:
Warten Sie, bis der „Ausführungsstatus“ den Status „Erfolgreich“ erreicht hat. Dies kann über eine Minute dauern, haben Sie also etwas Geduld:
Nach Abschluss des Vorgangs wird die Ausgabedatei im Ordner „/output“ Ihres S3-Buckets angezeigt: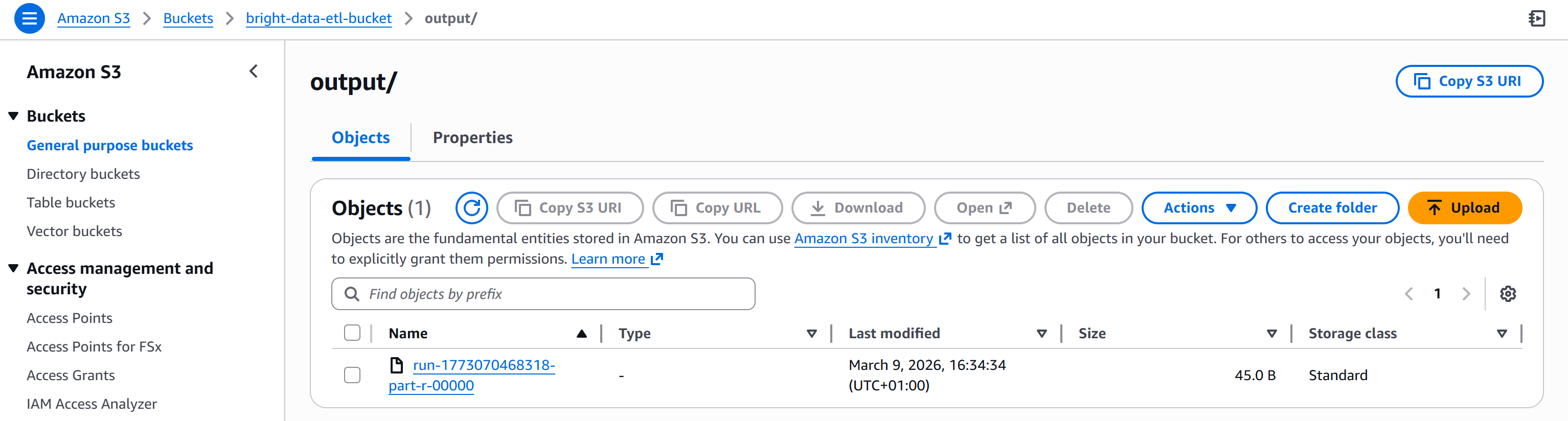
Öffnen Sie die erstellte Datei. Sie sehen eine Liste der Aktien mit einem KGV unterhalb Ihres Filtergrenzwerts (z. B. unter 30):
Wie Sie sehen können, gehören zu den resultierenden Aktien AMZN, BRK.B, META, MSFT und GOOGL.
Et voilà! Sie haben gerade eine AWS Glue ETL-Pipeline integriert mit Bright Data erstellt. Die Extraktionsphase nutzt die Web-Scraping-APIs von Bright Data, die Transformationsphase filtert die Daten mit SQL und die Ladephase speichert die Ergebnisse wieder in S3.
Weitere Ideen für die Integration von Bright Data in einen AWS Glue ETL-Job
Es besteht kein Zweifel, dass Bright Data dank seiner Funktionen zum Abrufen von Webdaten eine wichtige Rolle in der Extraktionsphase einer ETL-Pipeline spielen kann.
Bright Data kann jedoch auch über die Extraktion hinaus genutzt werden, beispielsweise in der Transform- Phase zur Datenanreicherung, -validierung oder -verifizierung. Sie könnten beispielsweise:
- Unternehmensprofile verbessern: Verwenden Sie den ZoomInfo Scraper, um firmografische Daten an Datensätze anzuhängen, die aus Webquellen extrahiert wurden.
- Mitarbeiterinformationen validieren: Integrieren Sie LinkedIn-Profile, um Berufsbezeichnungen, E-Mail-Adressen oder soziale Profile zu überprüfen.
- Preise oder Produktdetails von Wettbewerbern abrufen: Verwenden Sie den Amazon Scraper oder Amazon Reviews Scraper, um Ihren Datensatz mit Marktinformationen anzureichern.
- SEO- oder Suchdaten hinzufügen: Verwenden Sie die SERP-API, um Suchmaschinen-Rankingdaten oder Keyword-Einblicke als Teil Ihres transformierten Datensatzes sowie zur Datenüberprüfung einzubeziehen.
Wenn Sie sich fragen, wie diese Integration möglich ist, lesen Sie die offizielle Anleitung zur Definition benutzerdefinierter visueller Transformationen. Sie müssen lediglich eine JSON-Datei mit den Beschreibungen und eine Python-Datei mit der Logik für die Bright Data API-Integration hinzufügen.
Fazit
In diesem Tutorial haben Sie gelernt, was AWS Glue ist und wie Bright Data seine Funktionen durch eine Vielzahl von Web-Scraping-Lösungen erweitern kann.
Insbesondere haben Sie gesehen, wie die Web-Scraping-APIs von Bright Data sowohl die Extraktions- (E) als auch die Transformationsphase (T) einer ETL-Pipeline unterstützen können (sei es beim Abrufen von Rohdaten, beim Anreichern von Datensätzen oder beim Verifizieren von Informationen).
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und entdecken Sie unsere Webdatenlösungen!





