
In diesem Artikel erfahren Sie:
- Was Alteryx One ist und welche Funktionen es bietet.
- Warum die Verbindung mit Web-Daten von Bright Data Workflows aussagekräftiger macht.
- Wie Sie einen automatisierten Workflow in Alteryx One mithilfe strukturierter, aktueller Web-Daten aus dem Bright Data Web Scraping definieren.
Legen wir los!
Was ist Alteryx One?
Alteryx One ist eine einheitliche, KI-gestützte Analyseplattform. Sie vereint Datenvorbereitung, Analyse, Automatisierung und KI in einer einzigen Umgebung. Im Detail hilft sie Unternehmen dabei, sich mit mehreren Datenquellen zu verbinden, wiederverwendbare Workflows zu erstellen und Erkenntnisse in großem Maßstab zu operationalisieren.
Die wichtigsten Funktionen von Alteryx One sind:
- KI-native Analyse: KI in Analyse-Workflows integrieren, um Muster zu erkennen, Erkenntnisse zu gewinnen und prädiktive Modellierung ohne separate Tools zu unterstützen.
- KI-bereite Datenvorbereitung: Daten aus mehreren Quellen verbinden, bereinigen und in vertrauenswürdige, analysebereit aufbereitete Datensätze mit integrierter Governance transformieren.
- Workflow-Automatisierung: Wiederkehrende Analyseaufgaben und End-to-End-Prozesse automatisieren, um manuellen Aufwand zu reduzieren und die Konsistenz zu verbessern.
- Einheitlicher Analyse-Arbeitsbereich: Eine einzige Umgebung bereitstellen, in der Teams Analyse-Workflows gemeinsam erstellen, ausführen und verwalten können.
- Enterprise-Governance und Sicherheit: Compliance, Herkunftsverfolgung und kontrollierten Zugriff gewährleisten, damit Analysen sicher in großen Organisationen skaliert werden können.
- Erweiterbare Integrationen: Verbindung mit Enterprise-Systemen und LLMs herstellen, um Analysen direkt in bestehende Daten-Ökosysteme einzubetten.
Wie Bright Data Alteryx One unterstützt
Alteryx One-Workflows sind nur so leistungsfähig wie die Daten, die sie verarbeiten. Die Plattform bietet zwar robuste Funktionen für Datenvorbereitung, Analyse und Automatisierung. Dennoch bestimmen letztlich die Qualität, Aktualität und Zuverlässigkeit der Eingabedaten die Genauigkeit der Ergebnisse. Hier spielt Bright Data als Web-Datenanbieter auf Enterprise-Niveau eine entscheidende Rolle!
Bright Data liefert groß angelegte, strukturierte Web-Daten über eine globale Proxy-Infrastruktur mit über 400 Millionen IPs in 195 Ländern. Mit einer Betriebszeit von 99,99 % und einer Erfolgsrate von 99,95 % bietet es die Zuverlässigkeit, die für produktionsreife Analyse-Pipelines erforderlich ist.
Für eine direkte Integration mit Alteryx One können Sie zunächst aktuelle Web-Daten über Bright Data’s Web Scraping APIs abrufen oder über Bright Data-Datensätze auf statische Web-Daten zugreifen. Diese Daten können automatisch in einem strukturierten Format an Amazon S3 (oder ein anderes gängiges Lieferziel) übermittelt werden.
Alteryx One kann diesen Datensatz dann direkt aus S3 importieren, wo er durch einen No-Code-Workflow verarbeitet wird. Abschließend werden die verarbeiteten Ergebnisse zur weiteren Verwendung zurück in S3 (oder ein beliebiges bevorzugtes Ziel) geschrieben.
Das Ergebnis ist eine automatisierte, durchgängige Analyse-Pipeline. Dabei sorgt Bright Data für eine zuverlässige Datenaufnahme auf Enterprise-Niveau, während Alteryx One diese Daten in verwertbare Erkenntnisse umwandelt.
Automatisierten Datenanalyse-Workflow in Alteryx One mit Web-Daten von Bright Data erstellen
In diesem Schritt-für-Schritt-Kapitel werden Sie durch die Einrichtung eines automatisierten Workflows in Alteryx One geführt.
Um diese Art von Web-Automatisierungs-Workflow zu demonstrieren, werden Sie auf folgende Komponenten zurückgreifen:
- Den Bright Data Yahoo Finance Scraper, um aktuelle Aktiendaten zu erfassen und für die Amazon S3-Lieferung zu konfigurieren.
- Einen Alteryx One-Workflow, der die Daten importiert, nach Volumen sortiert und in zwei Datensätze aufteilt: einen für positive Aktien und einen für negative Aktien. Anschließend werden die verarbeiteten Ergebnisse zurück in Amazon S3 geschrieben.
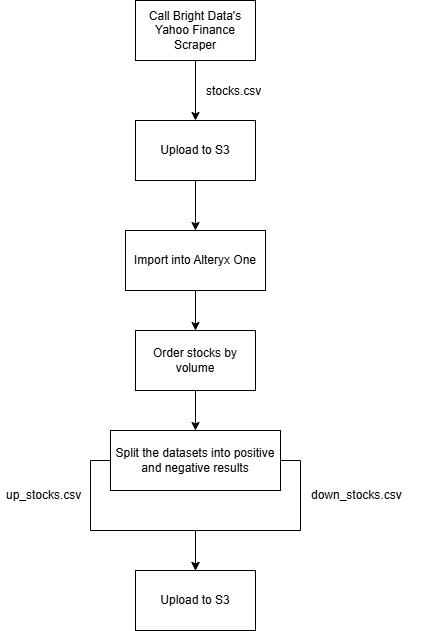
Folgen Sie den nachstehenden Anweisungen, um diesen Workflow zu erstellen!
Voraussetzungen
Um diesem Abschnitt zu folgen, stellen Sie sicher, dass Sie Folgendes haben:
- Ein Alteryx One-Konto (auch eines mit einer kostenlosen Testversion ist in Ordnung).
- Einen S3-Bucket, der in Ihrem AWS-Konto definiert ist.
- Ein Bright Data-Konto mit einem konfigurierten API-Schlüssel. Folgen Sie den offiziellen Anweisungen, um Ihren API-Schlüssel zu generieren.
In diesem Tutorial gehen wir davon aus, dass Ihr S3-Bucket den Namen bright-data-datasets trägt. Jeder andere Bucket-Name funktioniert jedoch ebenfalls.
Schritt #1: Bright Data Scraping API einrichten
Der erste Schritt in Ihrer Web-Daten-Automatisierungs-Pipeline besteht darin, Quelldaten aus dem Web abzurufen. Dazu verwenden Sie den Bright Data Yahoo Finance Scraper, um Echtzeit-Finanzdaten zu erfassen. Legen wir los!
Beginnen Sie damit, ein Bright Data-Konto zu erstellen, falls Sie noch keines haben. Andernfalls melden Sie sich bei Ihrem bestehenden Konto an. Navigieren Sie im Kontrollpanel zur Seite „Scrapers > Scrapers Library”:
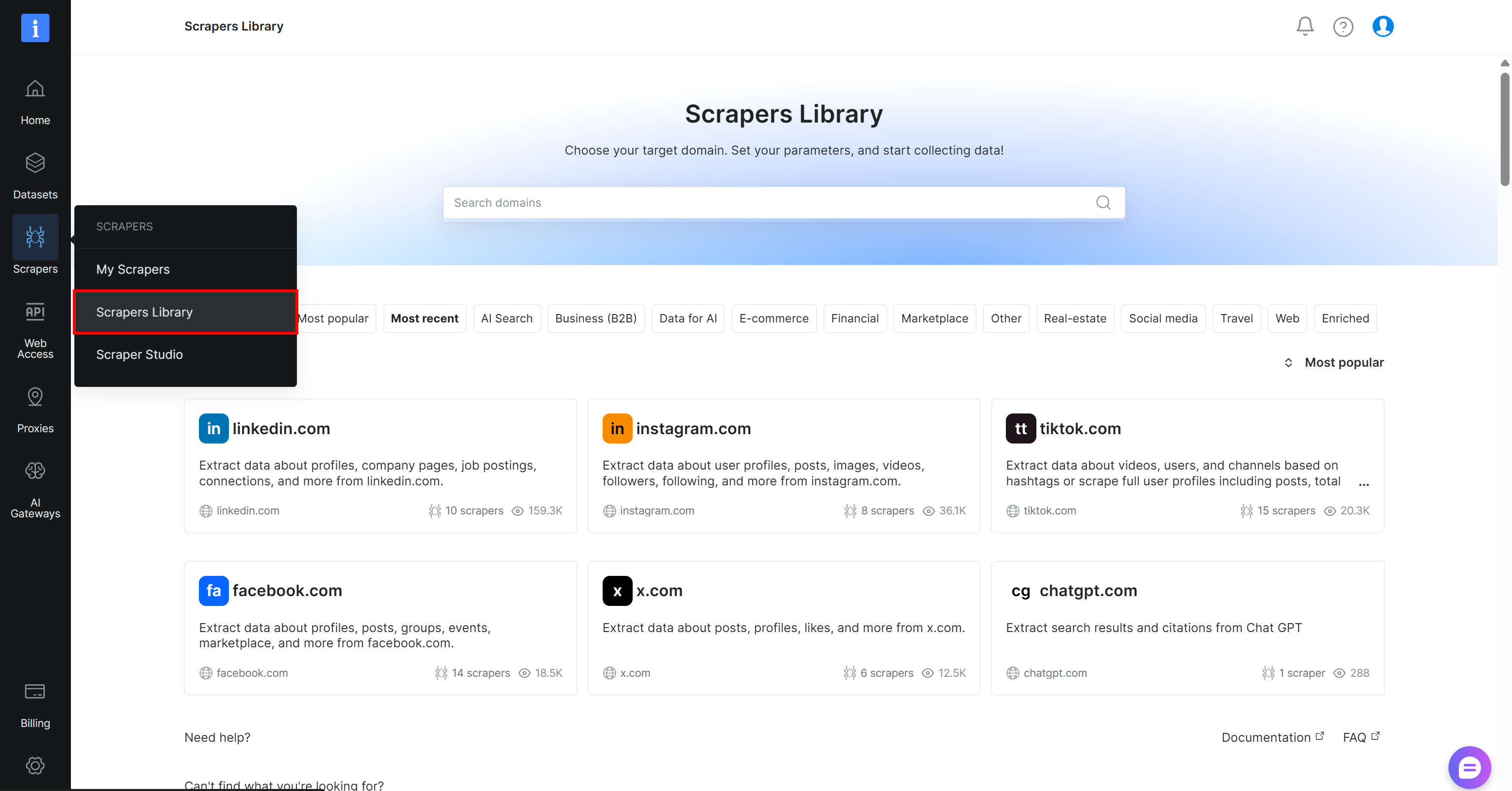
Suchen Sie nach „yahoo finance” und wählen Sie den Scraper „finance.yahoo.com” aus:
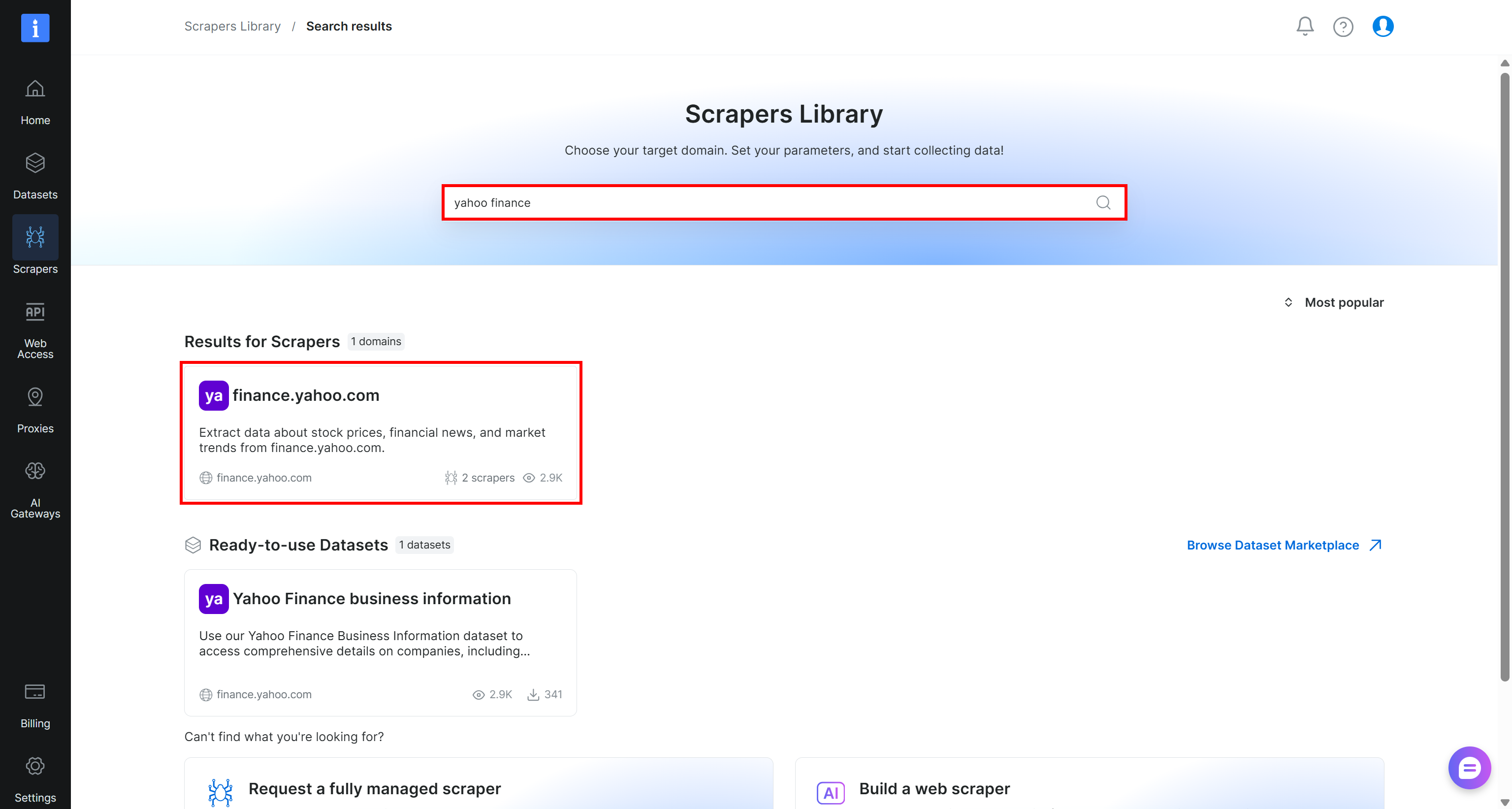
Überprüfen Sie auf der Seite des Yahoo Finance Scrapers die Eingabeanforderungen und das Ausgabeschema des Scrapers:
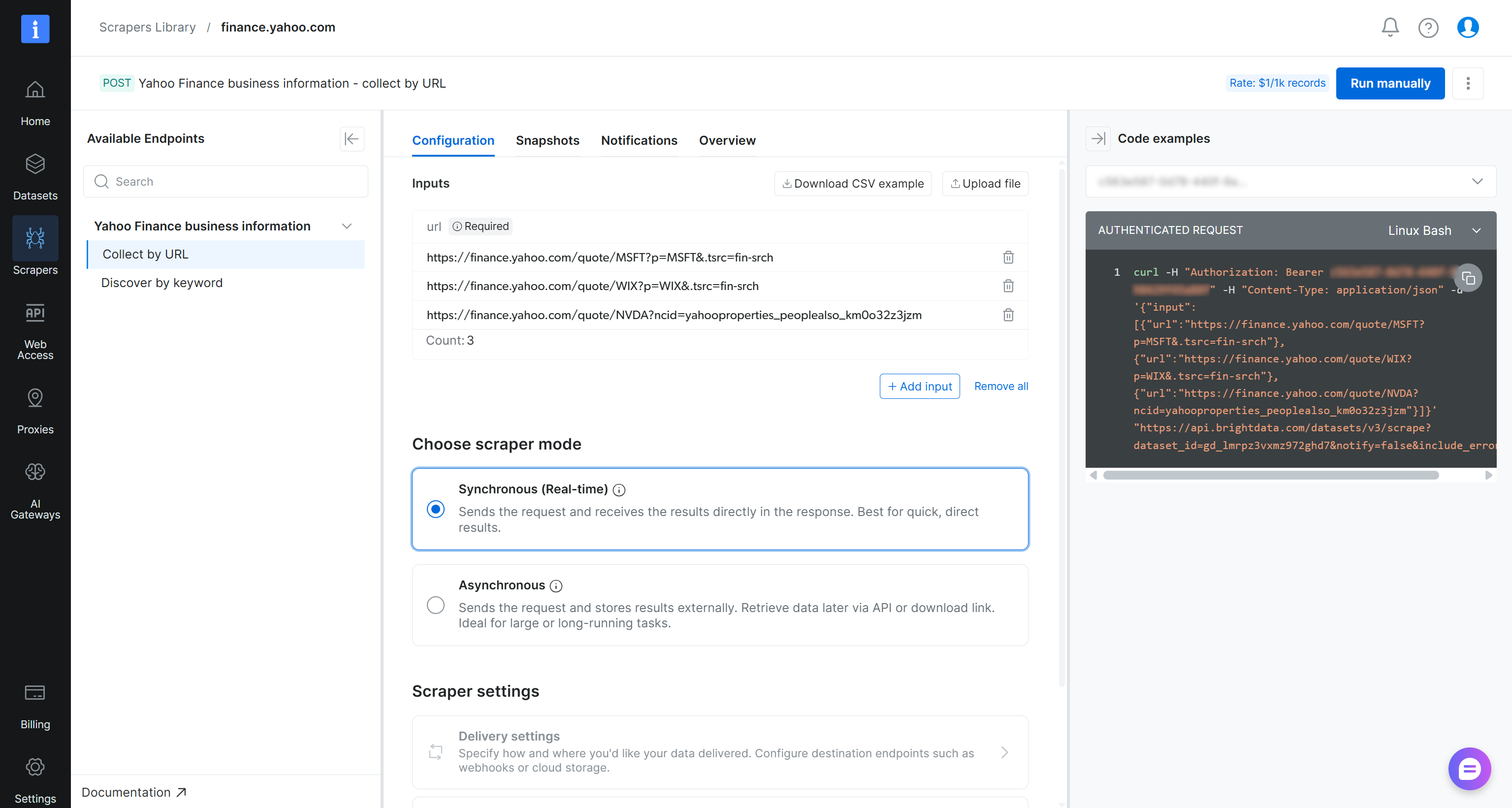
Auf hoher Ebene akzeptiert der Scraper eine oder mehrere Yahoo Finance-Aktienseiten-URLs als Eingabe und gibt strukturierte Echtzeit-Finanzdaten zurück. Genau das, was wir brauchen!
Schritt #2: S3-Lieferung konfigurieren
Bright Data Web Scraping APIs unterstützen die automatische Lieferung gescrapter Daten an Amazon S3 (sowie mehrere andere Cloud-Speicheranbieter und Liefermethoden). Um die Lieferung an Amazon S3 zu aktivieren, müssen Sie zunächst den Scraper in den asynchronen Modus umschalten.
Wählen Sie im Tab „Configuration” die Option „Asynchronous” aus. Klicken Sie dann auf „Delivery settings”:
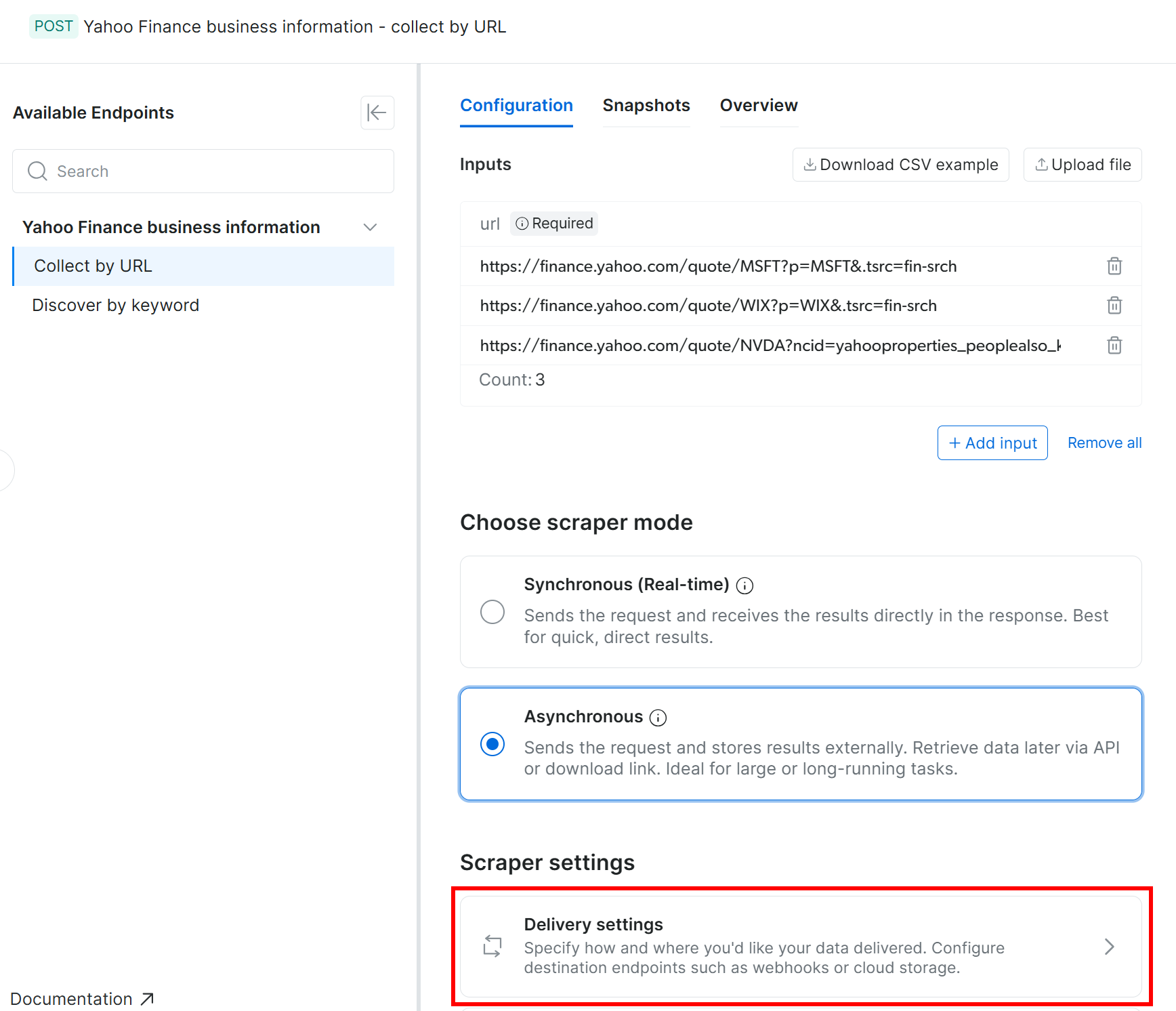
Konfigurieren Sie anschließend die Lieferung an Ihren Amazon S3-Bucket mit den folgenden Einstellungen:
- Aktivieren Sie den Schalter „Enable delivery”.
- Stellen Sie das Ausgabedatenformat auf CSV ein.
- Wählen Sie „Amazon S3″ als Speicherziel aus.
- Geben Sie Ihren S3-Bucket-Namen ein (in diesem Beispiel
bright-data-datasets). (Das Feld „Endpoint URL” können Sie leer lassen.) - Lassen Sie den „Target path” leer, um die Datei in den Stammordner des Buckets hochzuladen.
- Setzen Sie die Option „Authentication type” auf „Access keys”.
- Fügen Sie Ihren AWS Access Key ID und AWS Secret Access Key ein.
- Setzen Sie den Dateinamen auf
stocks.
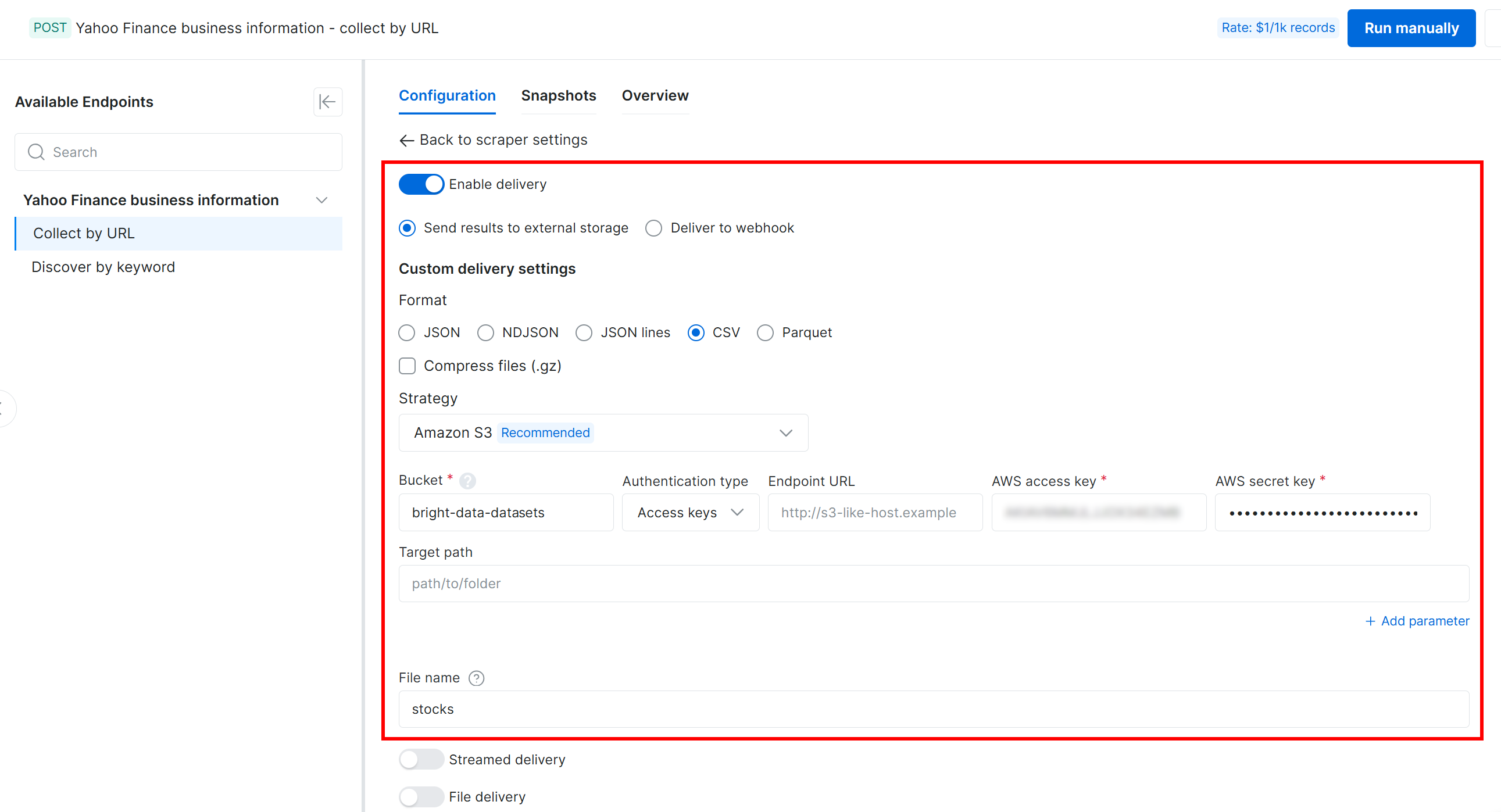
Mit dieser Konfiguration läuft die Web Scraping API im asynchronen Modus. Anstatt Daten sofort zurückzugeben, erstellt Bright Data einen Scraping-Job, der auf seiner Infrastruktur ausgeführt wird. Sobald der Job abgeschlossen ist, werden die gescrapten Daten automatisch in Ihren Amazon S3-Bucket hochgeladen. Praktisch und vollautomatisch!
Schritt #3: Web-Daten-Abrufaufgabe ausführen
Um zu überprüfen, ob der Web-Daten-Extraktions-Workflow korrekt funktioniert, fügen Sie einige Yahoo Finance-Aktien-URLs als Eingabe hinzu. In diesem Beispiel gehen wir davon aus, dass Sie die Top 10 Nasdaq-Aktien verfolgen möchten (d. h. NVDA, AAPL, GOOGL, MSFT, AMZN, TSLA, META, AVGO, WMT und AMD).
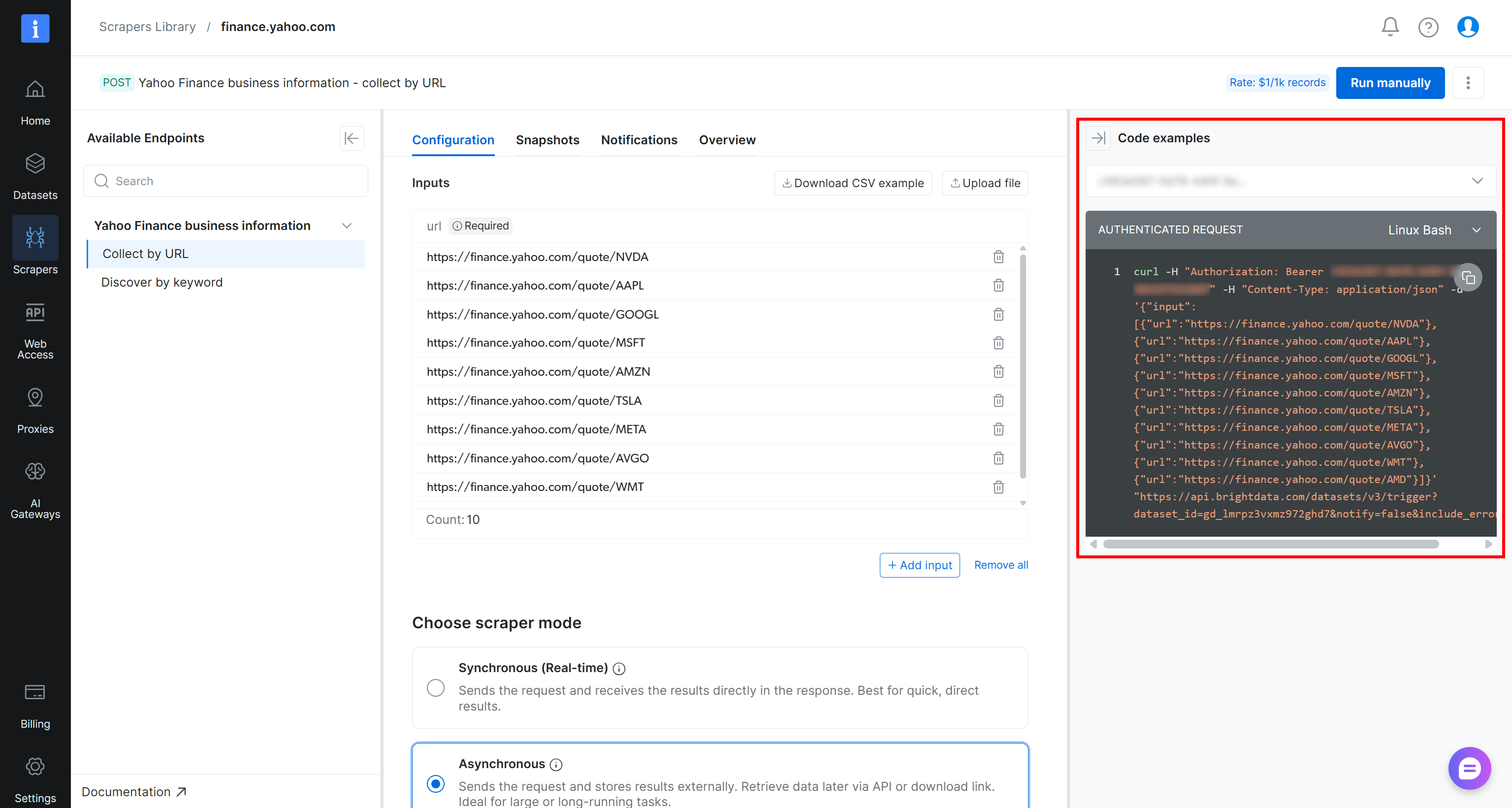
Um die Scraping-Aufgabe programmgesteuert auszulösen, können Sie den auf der Scraper-Seite bereitgestellten cURL-Snippet verwenden:
curl -H "Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>" -H "Content-Type: application/json" -d '{"input":[{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}]}' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true"Alternativ können Sie das folgende Python-Skript ausführen:
# pip install requests
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())Ersetzen Sie in beiden Fällen <YOUR_BRIGHT_DATA_API_KEY> durch Ihren Bright Data API-Schlüssel.
Hinweis: Für einen noch einfacheren Ansatz führen Sie die Aufgabe aus, indem Sie direkt im Kontrollpanel auf die Schaltfläche „Run manually” klicken.
Nach dem Auslösen wird die Scraping-Anfrage an die Cloud-Infrastruktur von Bright Data gesendet, wo die Extraktionsaufgabe beginnt. Sie können den Status in Echtzeit im Bright Data-Kontrollpanel überwachen:
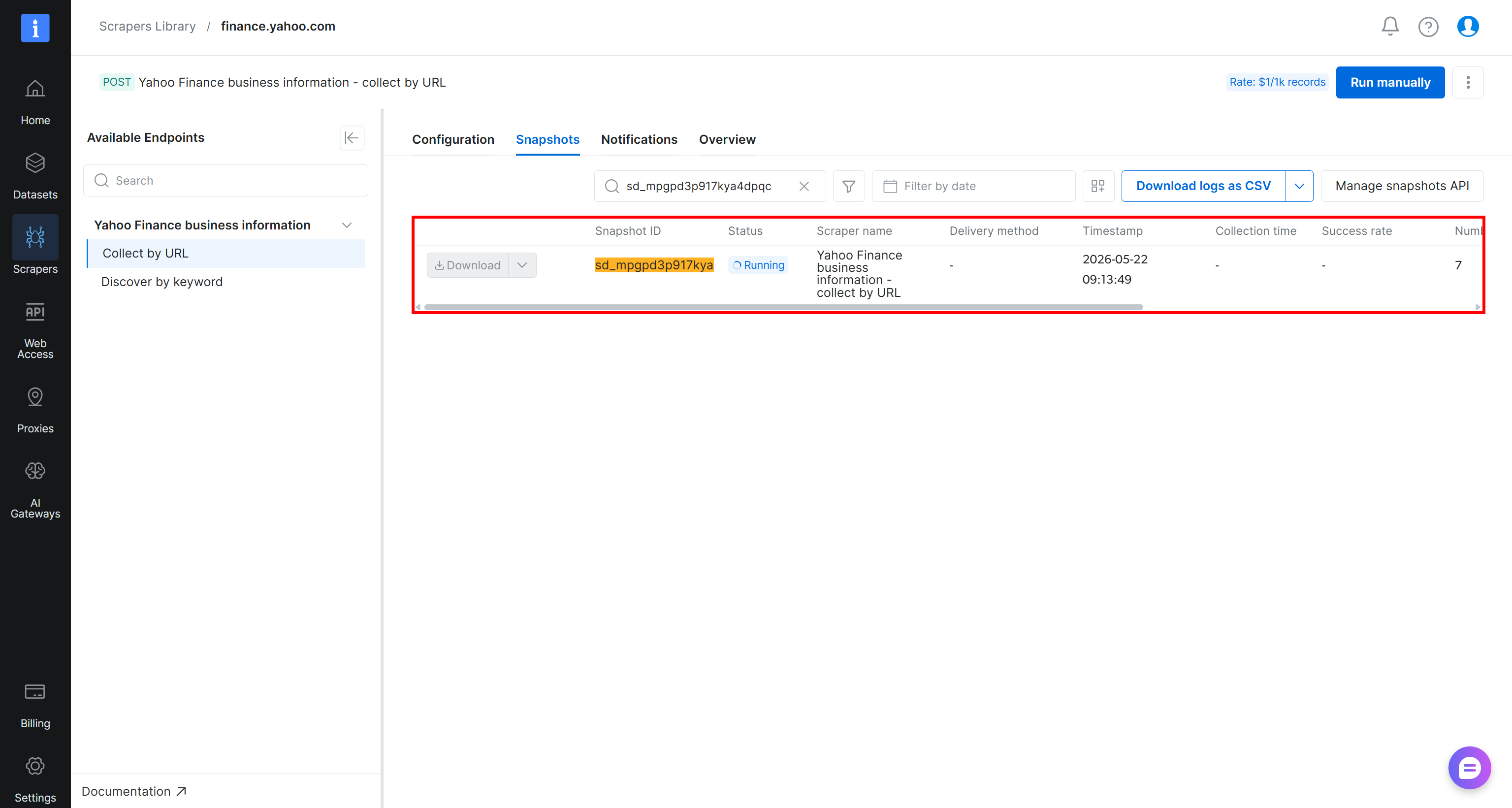
Wenn sich der Aufgabenstatus auf „Ready” ändert, öffnen Sie Ihren Amazon S3-Bucket. Sie sollten eine neue Datei namens stocks.csv bemerken:

Laden Sie die Datei stocks.csv herunter und öffnen Sie sie. Sie sehen etwas wie folgt:
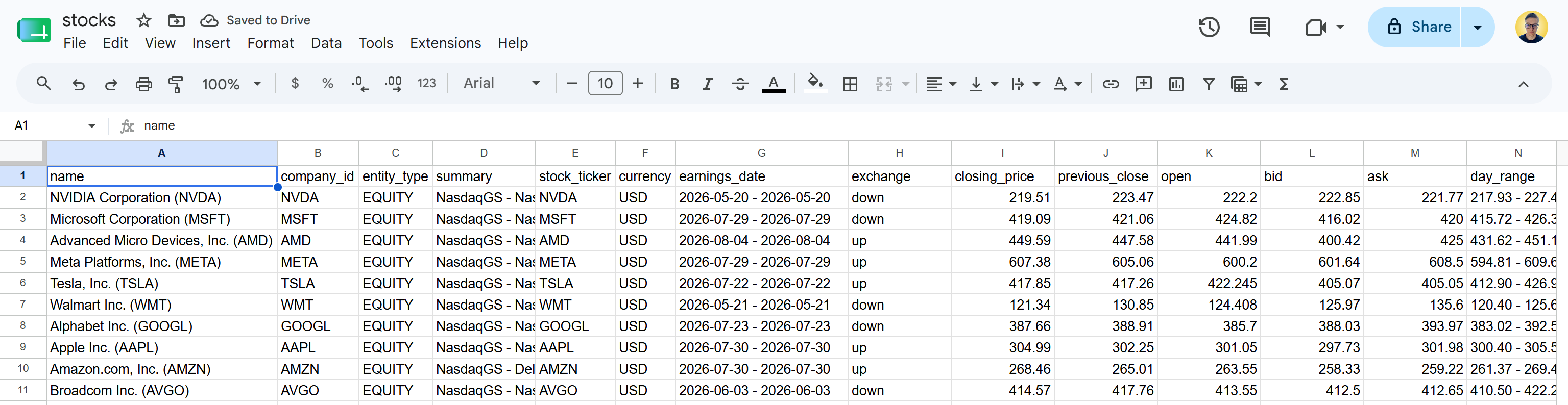
Dies sind dieselben Aktiendaten, die auf den angegebenen Yahoo Finance-Seiten verfügbar sind. Die Bright Data Yahoo Finance Scraper API hat die Aktiendaten abgerufen und in ein strukturiertes CSV-Format umgewandelt.
Um besser zu verstehen, wie die gescrapten Daten strukturiert sind und welche Spalten verfügbar sind, werfen Sie einen Blick auf den Abschnitt „Dictionary” im Tab „Overview” der Yahoo Finance Scraper-Seite:
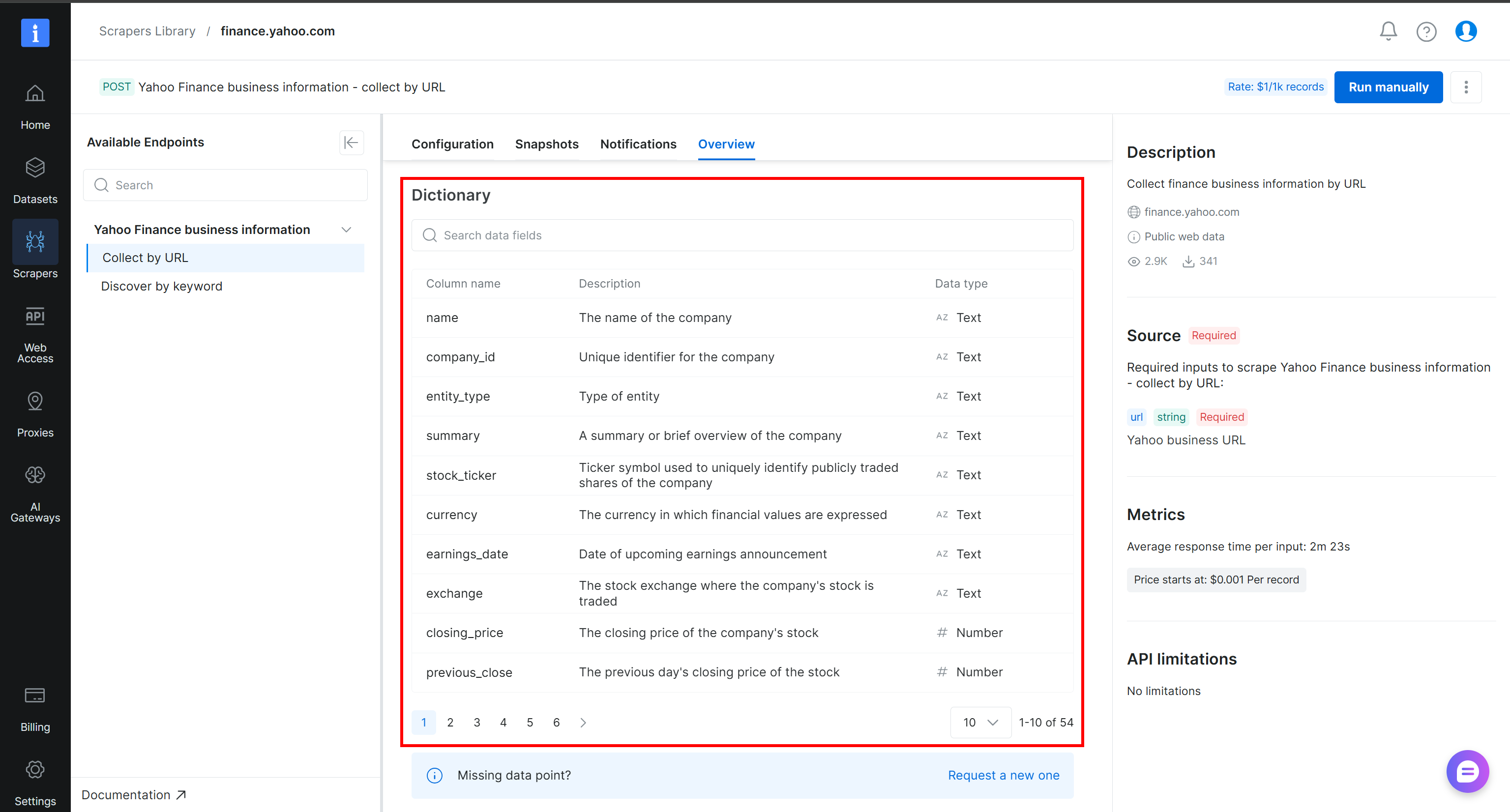
Großartig! Sie haben jetzt die Daten, die Sie benötigen, um Ihre Alteryx One Web-Daten-Pipeline zu erstellen.
Schritt #4: Alteryx One mit der S3-Datenquelle verbinden
Derzeit werden die gescrapten Quelldaten an Amazon S3 geliefert. Der nächste Schritt besteht darin, Ihr Alteryx One-Konto mit diesem S3-Bucket zu verbinden, damit Workflows bei Bedarf auf die Daten zugreifen und diese analysieren können.
Um eine Verbindung zu Ihrem Amazon S3-Bucket herzustellen, melden Sie sich bei Alteryx One an. Navigieren Sie zur Seite „Data” und öffnen Sie den Tab „Connections”. Klicken Sie dann auf „New Connection”:
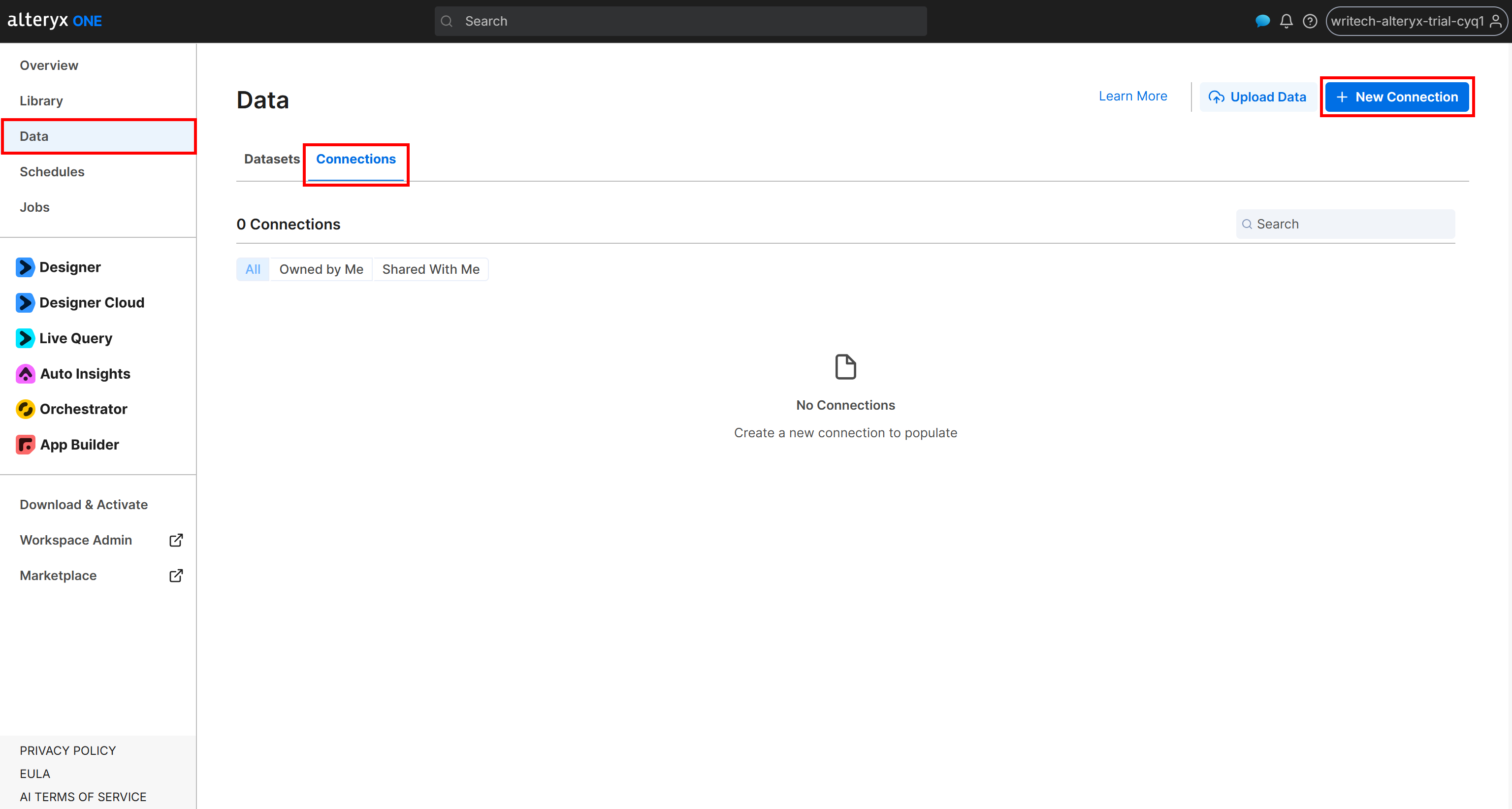
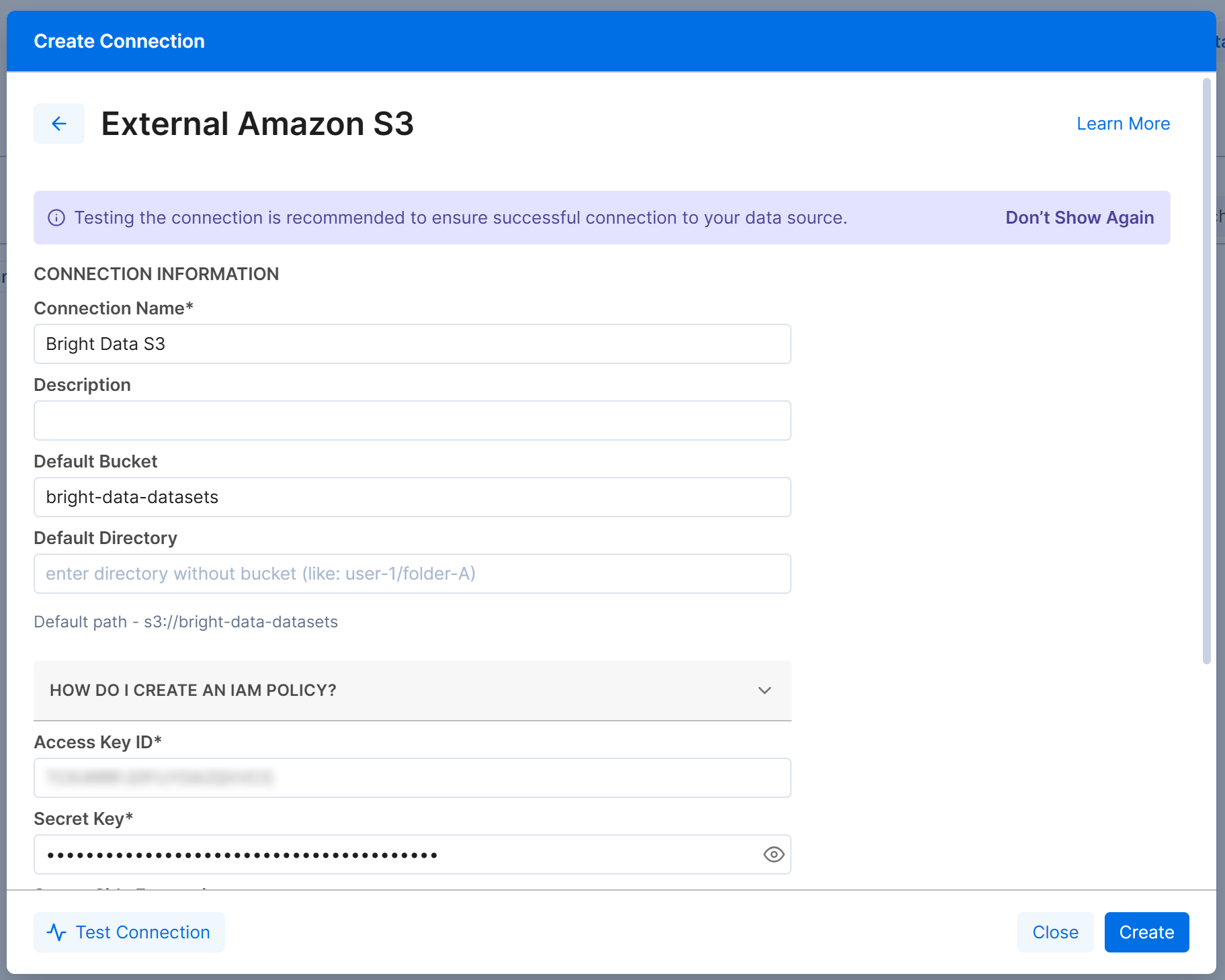
Konfigurieren Sie anschließend das Formular „External Amazon S3″ wie folgt:
- Connection Name: Bright Data S3 (oder ein beliebiger Name Ihrer Wahl).
- Default Bucket:
bright-data-datasets(oder Ihr tatsächlicher Bucket-Name). - Access Key ID und Secret Access Key: Ihr AWS Access Key ID und AWS Secret Access Key.
Klicken Sie auf „Create”, und die Amazon S3-Verbindung erscheint im Tab „Connections”:
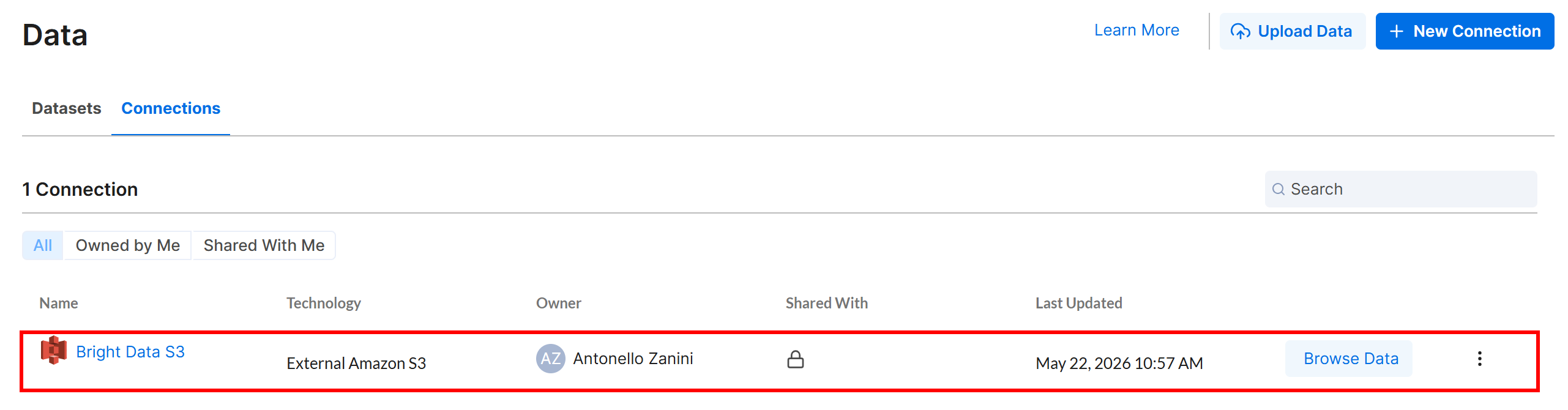
Ausgezeichnet! Jetzt ist es an der Zeit, einen Alteryx One-Workflow zu definieren, der Eingabedaten aus Ihrem Amazon S3-Bucket liest, wo die Yahoo Finance Scraper API ihre Ausgabe speichert.
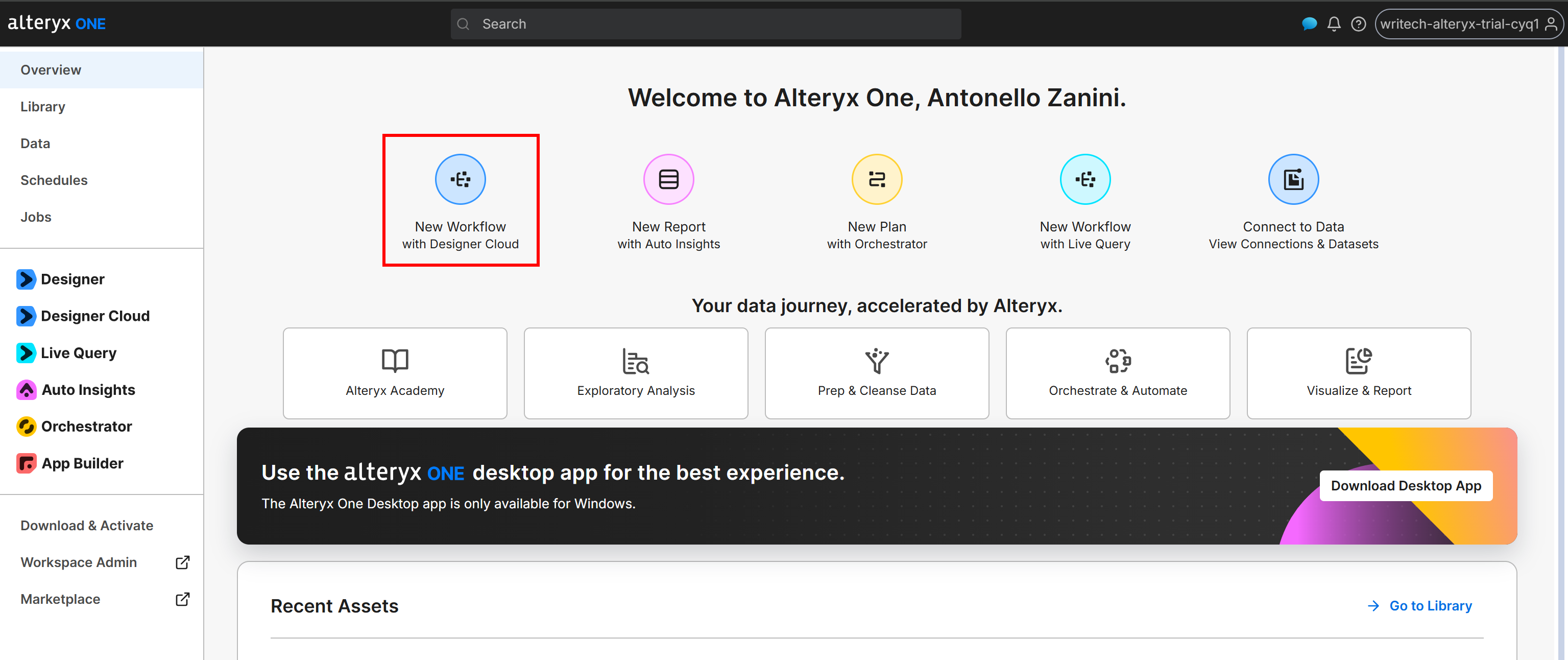
Schritt #5: Alteryx One-Workflow initialisieren
Gehen Sie zur Seite „Overview” und klicken Sie auf die Schaltfläche „New Workflow with Designer Cloud”:
Alternativ können Sie den Workflow über die Alteryx One Desktop-App erstellen.
Geben Sie Ihrem Workflow einen Namen, z. B. „Automated Stock Analyzer”:
Der erste Schritt beim Erstellen des Workflows besteht darin, die Quelldaten zu laden. Ziehen Sie dazu den Knoten „Input Data” auf die Workflow-Arbeitsfläche:

Doppelklicken Sie dann auf den Knoten, um ihn zu konfigurieren und mit Ihrem Amazon S3-Bucket zu verbinden, und wählen Sie die Datei stocks.csv aus. Folgen Sie dem Einrichtungsassistenten, um den Datensatz zu importieren. Nach Abschluss sollten Sie sehen, dass die Daten erfolgreich geladen wurden:
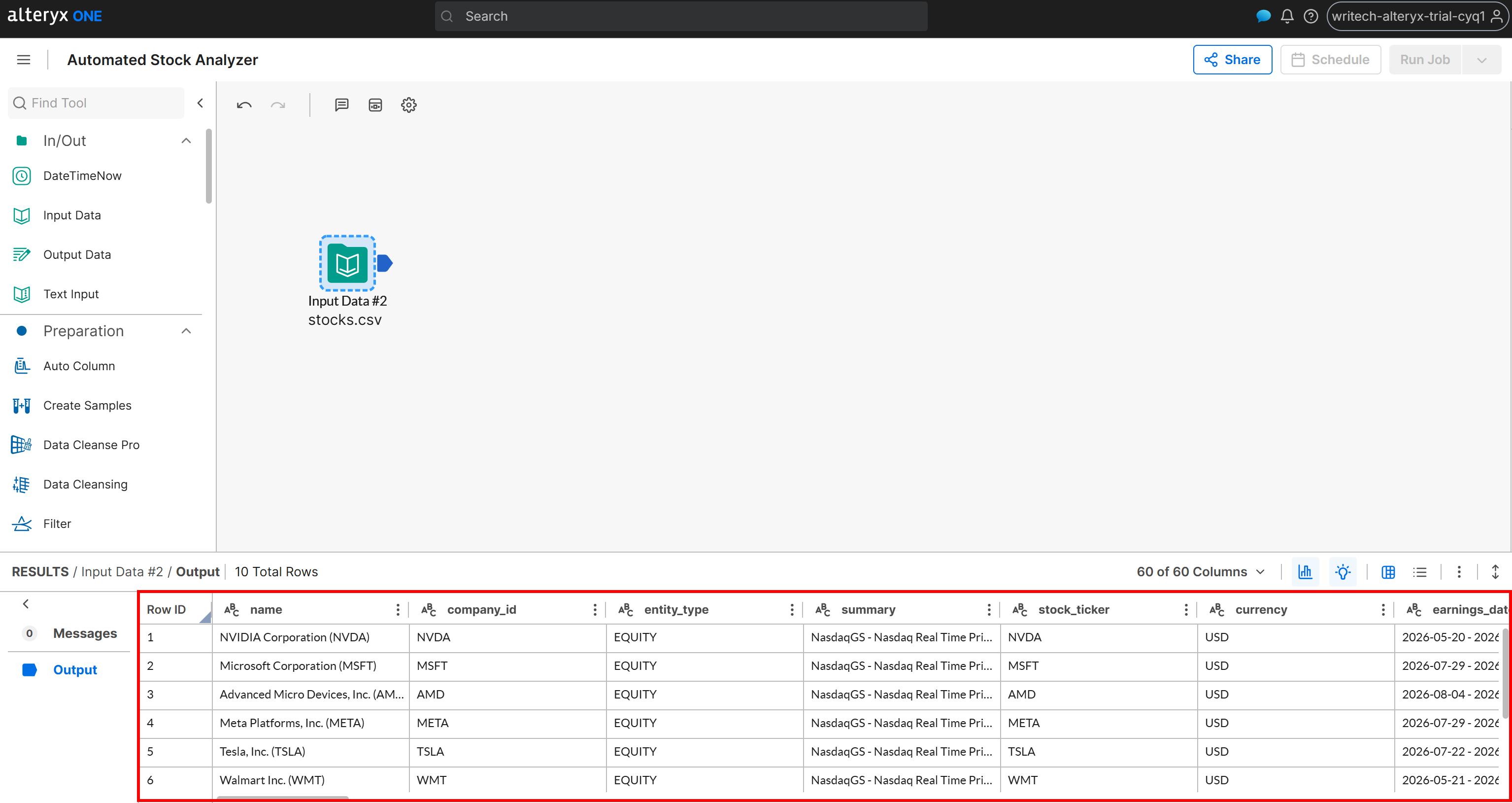
An diesem Punkt hat der Workflow Zugriff auf die gescrapten Web-Daten. Großartig! Jetzt können Sie beginnen, die Datenanalyselogik hinzuzufügen.
Schritt #6: Datenanalyselogik definieren
Angenommen, Sie möchten die Ergebnisse nach einem bestimmten Kriterium ordnen, z. B. nach dem täglichen Handelsvolumen. Fügen Sie einen Knoten „Sort” hinzu und wählen Sie in der Sortierkonfiguration die Spalte volume aus und setzen Sie die Reihenfolge auf Ascending:
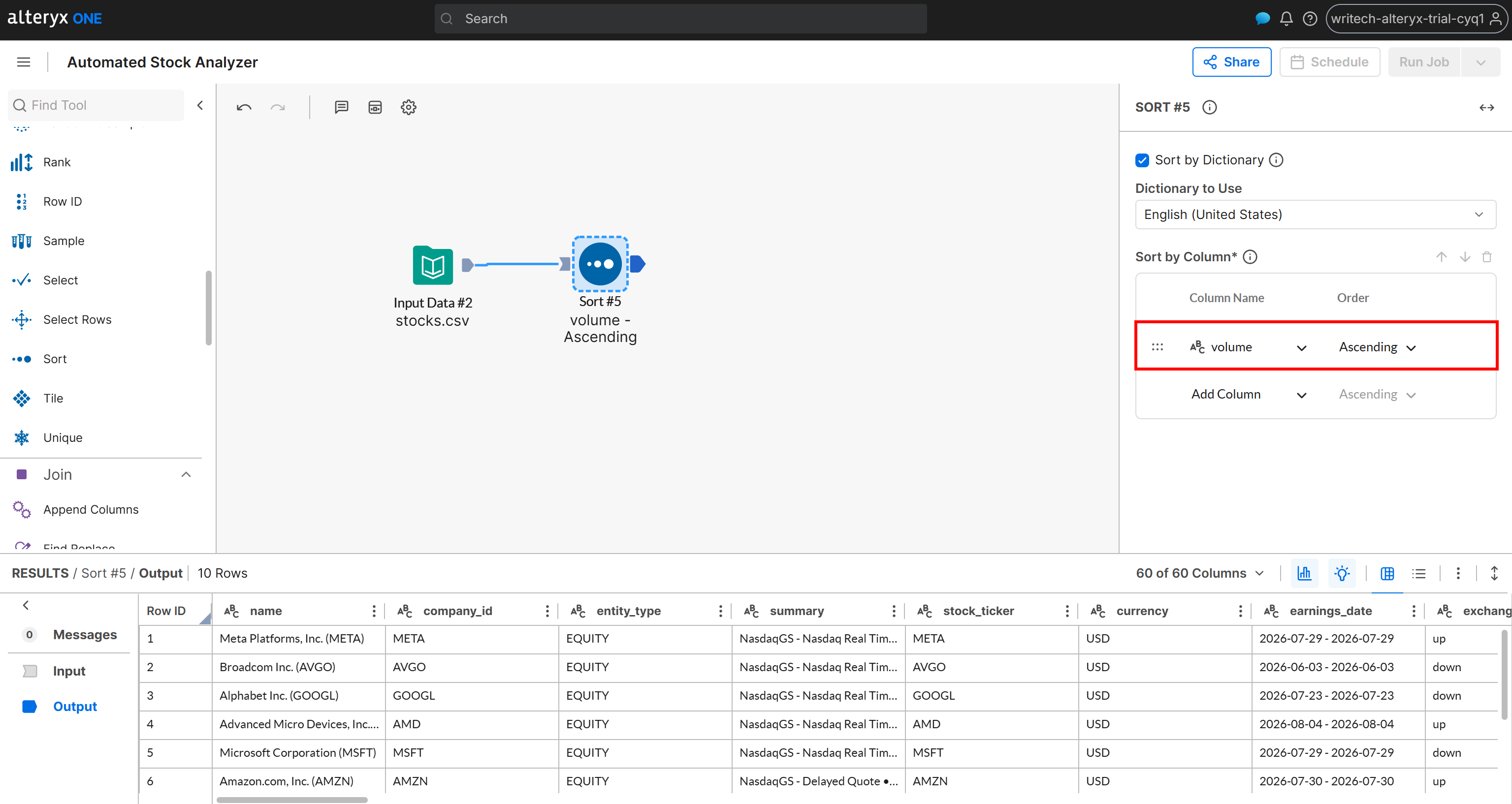
Angenommen, Sie möchten den Datensatz in zwei Gruppen aufteilen:
- Aktien, die den Tag im positiven Bereich abgeschlossen haben.
- Aktien, die den Tag im negativen Bereich abgeschlossen haben.
Klassifizieren Sie dazu Aktien danach, ob ihr Feld exchange „up” oder „down” enthält. Fügen Sie einen Knoten „Filter” hinzu und verbinden Sie ihn mit der Ausgabe des Knotens „Sort”. Definieren Sie dann eine Filterbedingung wie folgt:
- Column Name:
exchange - Operator: Equals
- Value:
up
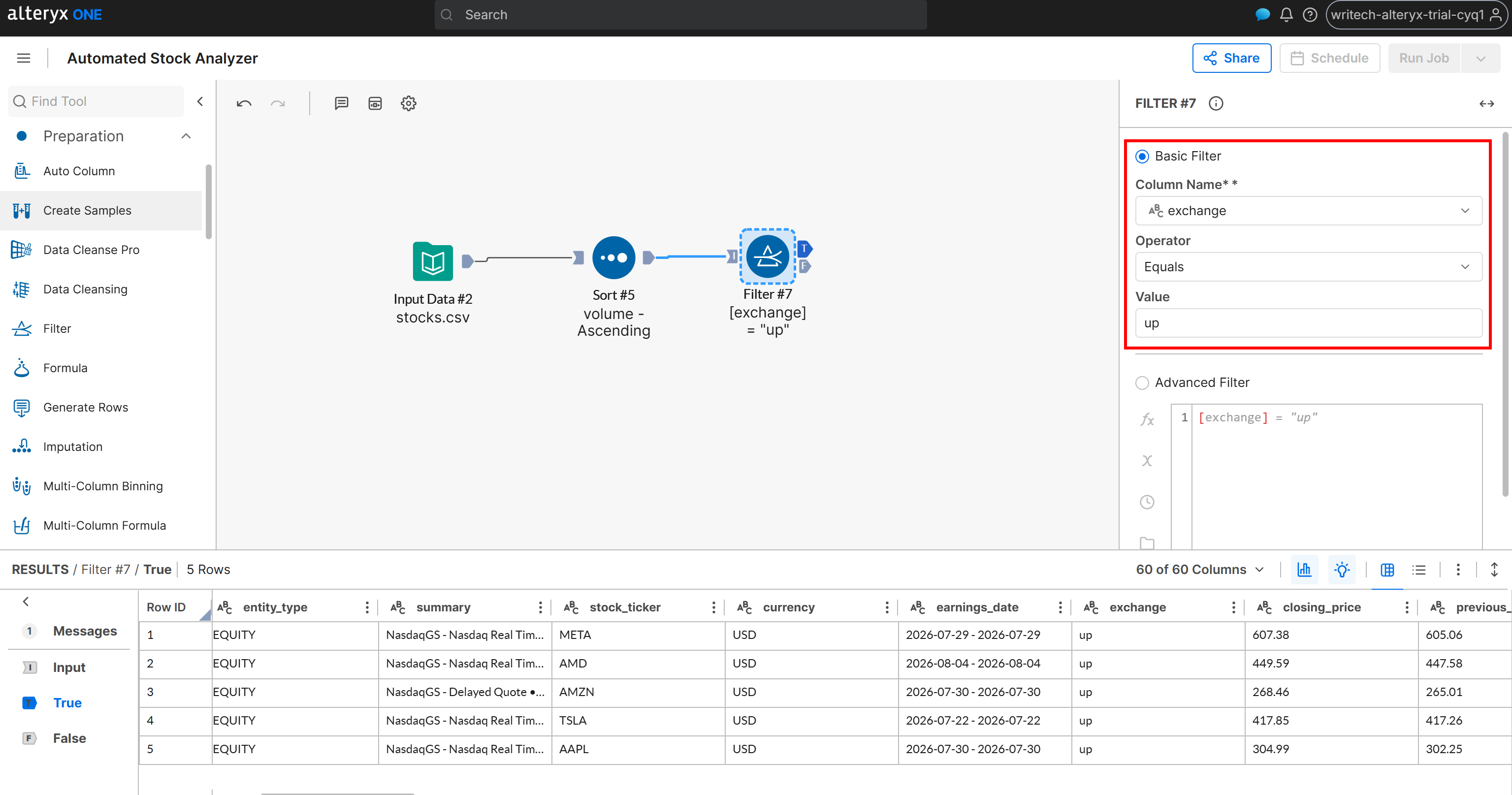
Der Filter-Knoten erzeugt zwei Ausgaben:
T(True): Enthält Aktien, bei denen das Feldexchange„up” ist.F(False): Enthält Aktien, bei denen das Feldexchangenicht „up” ist (d. h. es ist „down”).
Der letzte Schritt in diesem einfachen Web-Automatisierungs-Workflow besteht darin, die Ausgabeziele zu definieren. Kümmern wir uns darum!
Schritt #7: Ausgabedateien festlegen
Fügen Sie einen Knoten „Output Data” zur Arbeitsfläche hinzu und verbinden Sie ihn mit der Ausgabe T des Knotens „Filter”. Konfigurieren Sie den Knoten „Output Data” so, dass die Daten in Ihren Amazon S3-Bucket (oder eine andere verbundene Datenquelle) geschrieben werden. Erstellen Sie beispielsweise eine Datei namens up_stocks.csv:
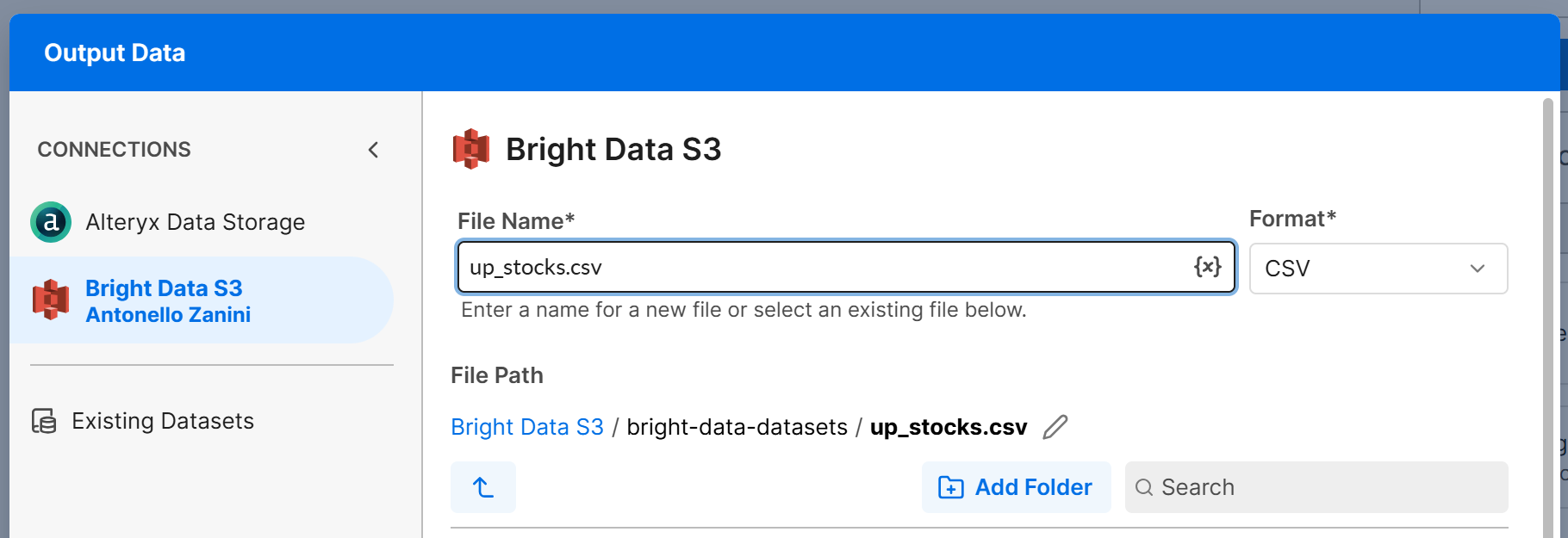
Klicken Sie auf „Next” und dann auf „Confirm”, um die Ausgabekonfiguration für den Zweig T zu speichern. Wiederholen Sie denselben Vorgang für den Zweig F und konfigurieren Sie ihn so, dass er in eine Datei down_stocks.csv schreibt.
So wird der fertige Workflow aussehen:
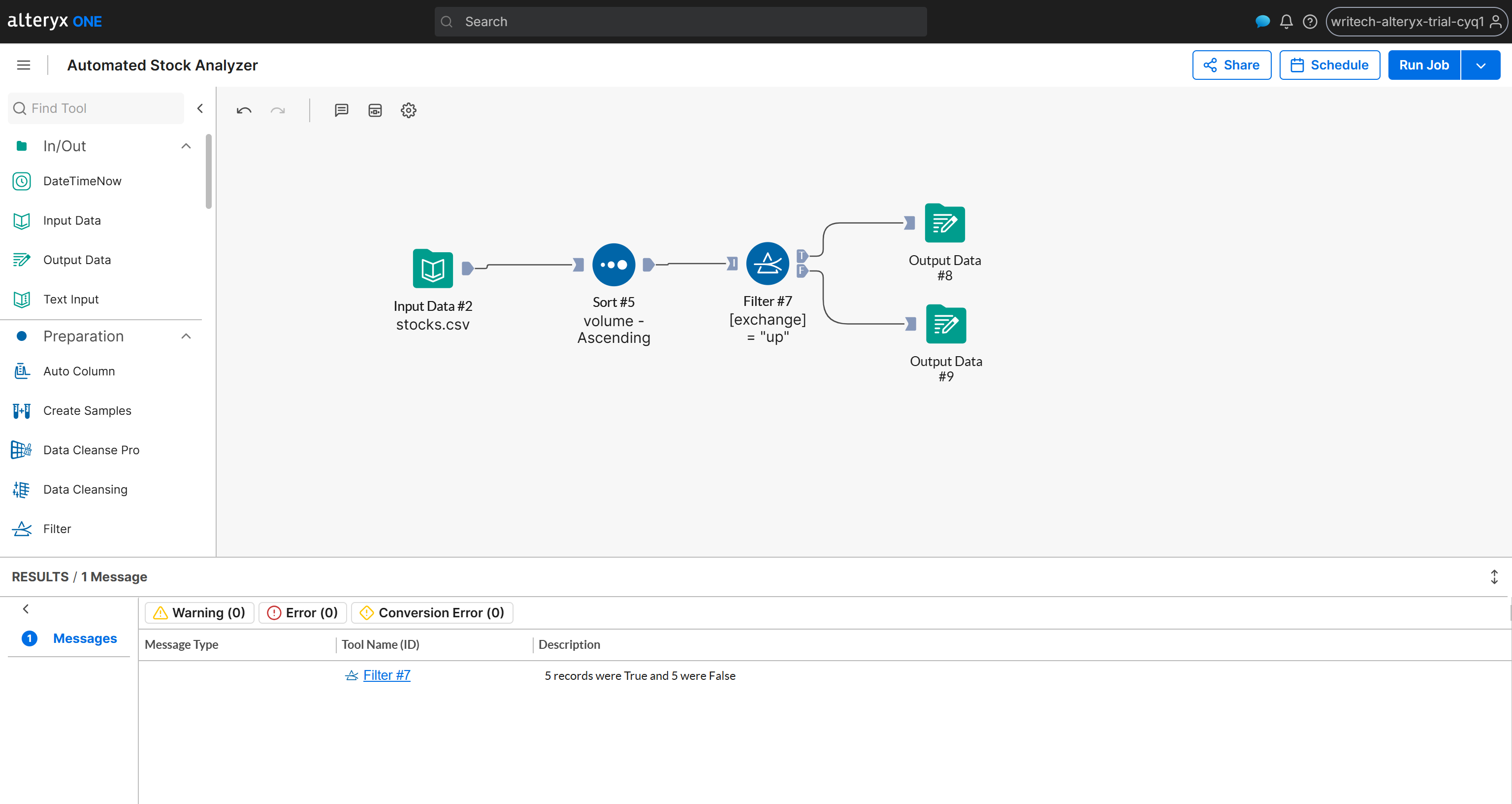
Aufgabe erfüllt! Jetzt müssen Sie nur noch den Workflow ausführen, um zu testen, ob alles wie erwartet funktioniert.
Schritt #8: Workflow starten
Klicken Sie auf die Schaltfläche „Run Job” und warten Sie, bis der von Bright Data betriebene automatisierte Web-Datenanalyse-Workflow abgeschlossen ist:

Nach Abschluss der Ausführung erhalten Sie eine Erfolgsbenachrichtigung in Alteryx One sowie eine Bestätigungs-E-Mail.
Überprüfen Sie nun die generierte Ausgabe für das Szenario T:
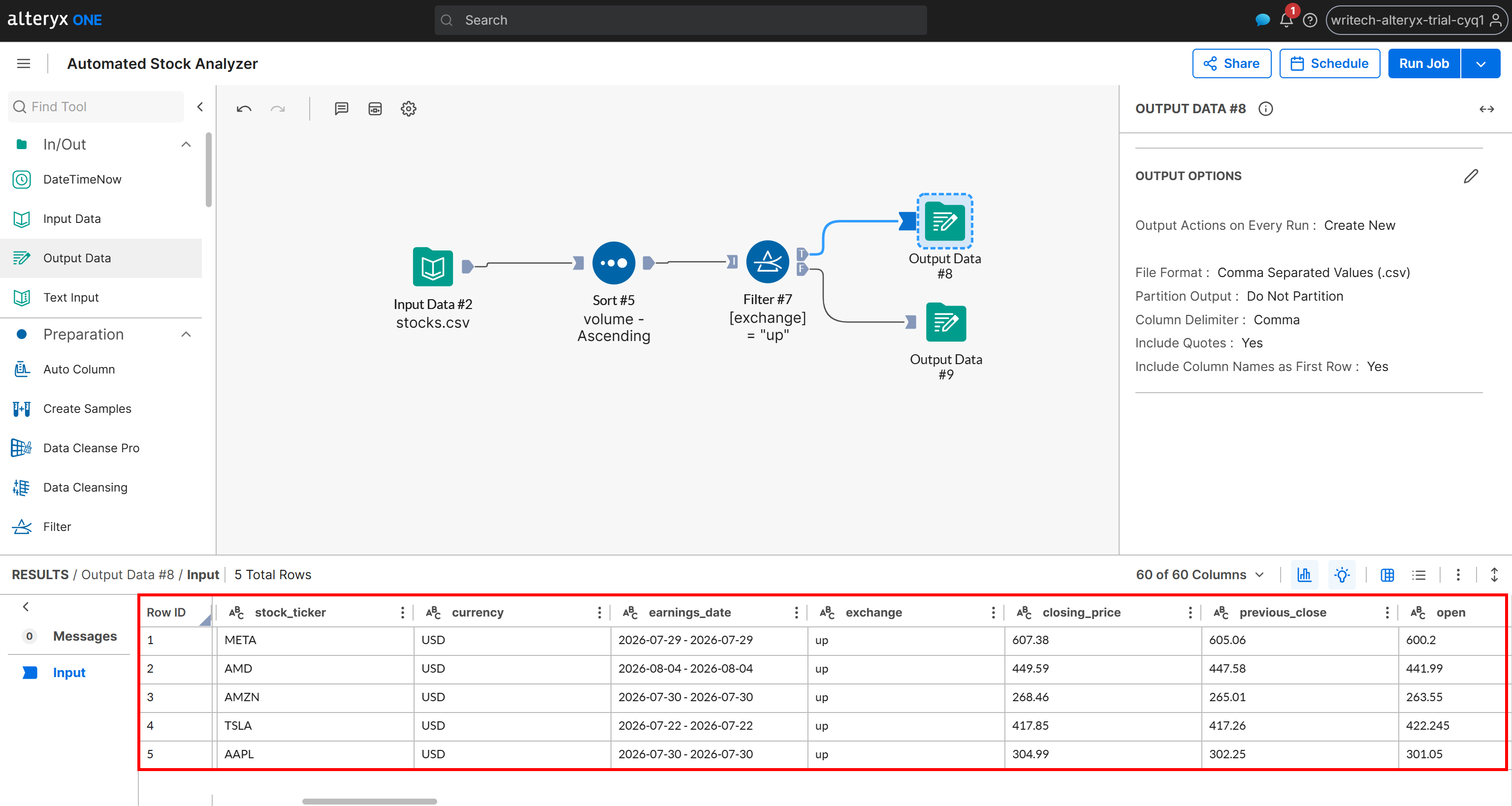
Beachten Sie, dass diese Ausgabe nur die Aktien enthält, deren Änderungsstatus „up” ist, sortiert nach Volumen in aufsteigender Reihenfolge. Dieselben Daten sind auch in der Datei up_stocks.csv verfügbar, die von der Pipeline generiert und in Ihrem Amazon S3-Bucket gespeichert wurde.
Überprüfen Sie als Nächstes die generierte Ausgabe für das Szenario F:
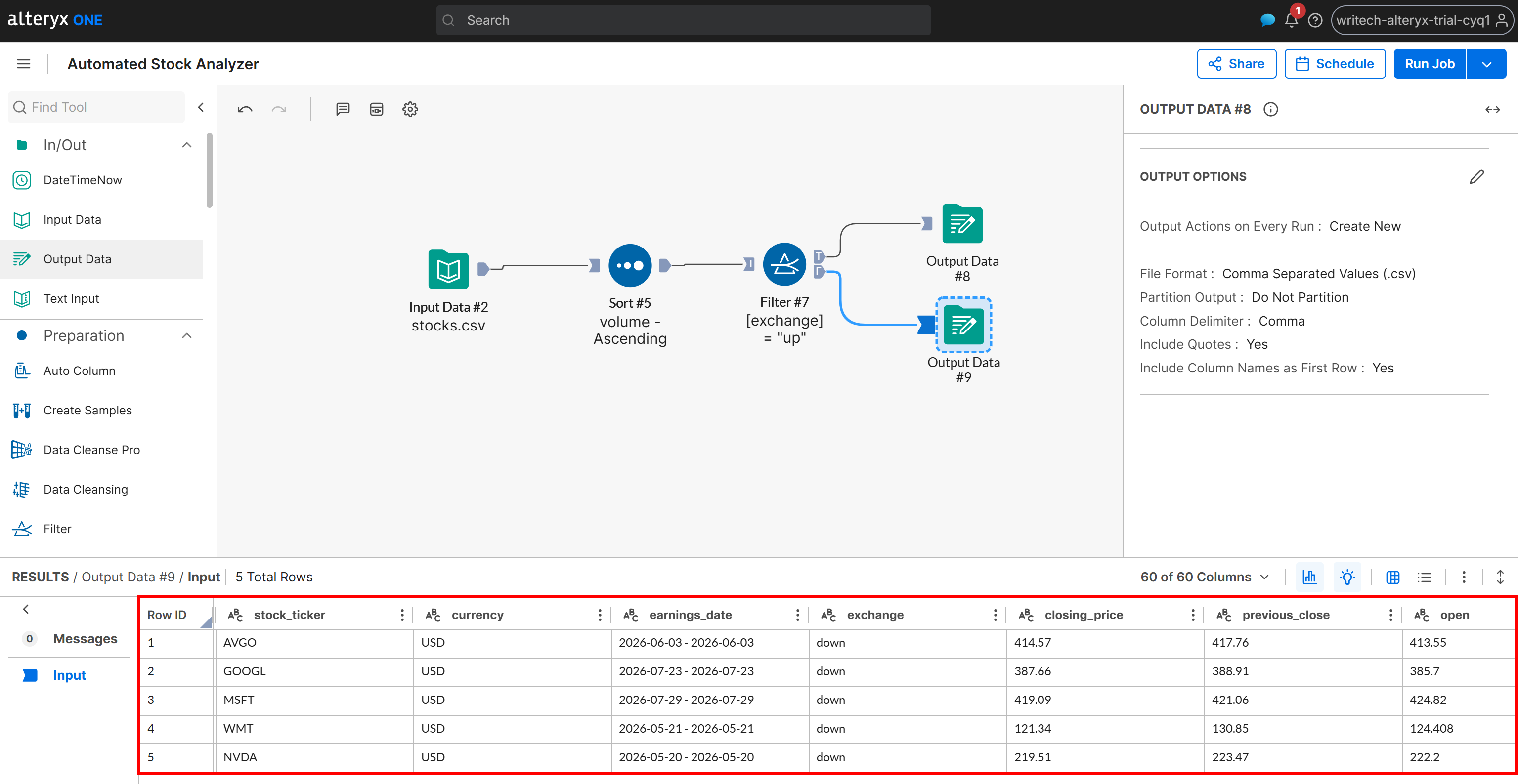
Diese Ausgabe enthält nur die Aktien, deren Änderungsstatus „down” ist, ebenfalls sortiert nach Volumen in aufsteigender Reihenfolge. Dieselben Ergebnisse werden in die Datei down_stocks.csv in Ihrem Amazon S3-Bucket geschrieben.
Et voilà! Sie haben gerade eine Web-Datenanalyse-Pipeline in Alteryx One erstellt, die von Bright Data betrieben wird. Beachten Sie, dass dies nur ein Beispiel war und viele weitere Web-Daten-Automatisierungsszenarien möglich sind.
Nächste Schritte
Bedenken Sie, dass dies nur eine einfache Datenanalyse-Pipeline mit einigen Beispielschritten war. In der Praxis können Sie sie durch das Hinzufügen weiterer Verarbeitungsknoten (einschließlich KI-Knoten) und sogar mehrerer Datenquellen deutlich komplexer gestalten.
Sie können beispielsweise andere Bright Data Web Scraping APIs so konfigurieren, dass sie in denselben Amazon S3-Bucket schreiben. Die resultierenden Datensätze können dann für die Anreicherung und weitergehende Analysen mithilfe von Join-Operationen kombiniert werden.
Um eine vollständig automatisierte, stets aktuelle Datenpipeline zu erstellen:
- Lösen Sie die Bright Data Web Scraping APIs aus, um die Quelldaten in Amazon S3 zu aktualisieren.
- Konfigurieren Sie in Bright Data einen Webhook, der die Alteryx One Workflow-Run-API aufruft.
Fazit
In diesem Tutorial haben Sie erfahren, was Alteryx One für die automatisierte Datenanalyse bietet. Konkret haben Sie gesehen, wie über Bright Data’s Web Scraping APIs abgerufene Daten über Amazon S3 in Alteryx One integriert werden können. Hochwertige Web-Daten verbessern die Genauigkeit und den Wert von Erkenntnissen erheblich und führen zu besseren Analyseergebnissen.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und entdecken Sie unsere unternehmenstauglichen Web-Datenlösungen!





