
In diesem Leitfaden erfahren Sie:
- Was AWS Step Functions ist und warum es für die Workflow-Automatisierung wichtig ist.
- Warum Web-Scraping-Workflows für diesen AWS-Dienst gut geeignet sind.
- Wie Bright Data dabei hilft, die mit Web-Scraping verbundenen Herausforderungen zu meistern.
- Wie Sie Bright Data in AWS Step Functions integrieren können, entweder über direkte API-Aufrufe oder über eine dedizierte Lambda-Funktion.
Lassen Sie uns eintauchen!
Eine Einführung in AWS Step Functions
Bevor wir Ihnen zeigen, wie Sie AWS Step Functions zur Orchestrierung eines Web-Scraping-Workflows verwenden können, möchten wir Ihnen zunächst mehr Hintergrundinformationen zu dieser Lösung geben.
Was sind AWS Step Functions?
AWS Step Functions ist ein vollständig verwalteter Dienst, mit dem Sie komplexe Workflows über AWS-Dienste hinweg koordinieren und automatisieren können. Es handelt sich um einen visuellen Orchestrierungsdienst, der zum Erstellen verteilter Anwendungen und zum Automatisieren von Prozessen verwendet wird, indem mehrere AWS-Dienste zu serverlosen Workflows verbunden werden.
Im Kern basieren Step Functions auf Zustandsmaschinen, bei denen es sich um Workflows handelt, die aus einer Reihe von Schritten, sogenannten Zuständen, bestehen. Jeder Zustand führt eine Aufgabe aus, z. B. das Aufrufen eines AWS-Dienstes oder das Ausführen von benutzerdefiniertem Code.
Dieser Ansatz vereinfacht die Orchestrierung, Fehlerbehandlung und Überwachung, sodass Sie sich auf die Anwendungslogik statt auf die Infrastruktur konzentrieren können. Im Einzelnen bieten sie folgende Hauptvorteile:
- Vereinfachte Orchestrierung: Verwalten Sie mehrstufige Prozesse und Abhängigkeiten, ohne komplexen Code schreiben zu müssen.
- Integrierte Fehlerbehandlung: Wiederholungsversuche und Catch-Blöcke helfen Workflows, sich automatisch von Fehlern zu erholen.
- Parallele und dynamische Ausführung: Führen Sie Aufgaben gleichzeitig aus oder iterieren Sie über Datensätze, um die Verarbeitung zu beschleunigen.
- Human-in-the-Loop-Unterstützung: Fügen Sie Genehmigungsschritte oder Rückrufe in Workflows ein.
- Service-Integration: Nahtlose Verbindung mit AWS Lambda, Glue, SQS, SNS, SageMaker und mehr.
Weitere Informationen finden Sie in der offiziellen Dokumentation.
So funktioniert AWS Step Functions
Um AWS Step Functions wirklich zu verstehen, ist es hilfreich, sich auf die Kernkonzepte zu konzentrieren, die die Grundlage jedes Workflows bilden:
- Zustandsmaschine: Das Rückgrat von Step Functions. Eine Zustandsmaschine repräsentiert Ihren Workflow und speichert und aktualisiert dessen Zustand im Verlauf der Aufgaben. Sie definieren sie mit JSON und der Amazon States Language. Sie können Standard-Workflows für lang andauernde Prozesse oder Prozesse mit menschlicher Intervention oder Express-Workflows für kurze, umfangreiche Aufgaben wählen.
- Zustände: Jeder Schritt in einem Workflow. Zustände können Aufgaben ausführen (Task), Entscheidungen treffen (Choice), die Ausführung unterbrechen (Wait), Fehler oder Erfolge behandeln (Fail/Succeed), die Ausführung verzweigen (Parallel) oder Eingaben wiederholen (Map). Die Kombination der Zustände definiert Ihre Workflow-Logik.
- Aufgabenzustände: Arbeitseinheiten innerhalb eines Workflows. Serviceaufgaben automatisieren Interaktionen mit AWS-Diensten wie Lambda oder Glue. Aktivitätsaufgaben verbinden sich hingegen mit externem Code oder Menschen und sind nützlich für asynchrone Schritte oder Genehmigungen.
- Ausführung und Überwachung: Step Functions protokolliert die Eingaben, Ausgaben, Wiederholungsversuche und Fehler jedes Schritts, sodass Sie Probleme nachverfolgen und das Workflow-Verhalten überprüfen können.
Serverlose Web-Scraping-Workflow-Orchestrierung
AWS Step Functions bietet eine effektive Möglichkeit, serverlose Web-Scraping-Workflows auf skalierbare und zuverlässige Weise zu orchestrieren. Anstatt ein monolithisches Scraping-Skript zu erstellen, können Sie den Prozess in kleinere, ereignisgesteuerte Schritte unterteilen und diese über eine Zustandsmaschine koordinieren.
Ein Workflow könnte beispielsweise mit dem Auslösen einer Datenerfassungsaufgabe beginnen, mit dem Parsing und der Datenvalidierung fortfahren und die Ergebnisse dann in Diensten wie Amazon S3 oder einer Datenbank speichern. Step Functions kann diese Schritte koordinieren und gleichzeitig mit anderen AWS-Diensten wie AWS Lambda, AWS Glue oder Amazon SQS integrieren.
Dieser Ansatz bietet mehrere Vorteile: verbesserte Skalierbarkeit, integrierte Wiederholungs- und Fehlerbehandlung, parallele Verarbeitung von Scraping-Aufgaben und klare Überwachung jeder Workflow-Ausführung.
Allerdings bringt das groß angelegte Web-Scraping auch Herausforderungen mit sich. Der Grund dafür ist, dass viele Websites Anti-Bot-Schutzmaßnahmen und Anti-Scraping-Mechanismen implementieren, die automatisierte Anfragen blockieren können. Beispiele hierfür sind Rate Limiter, Fingerabdrücke, CAPTCHAs, JavaScript-Challenges und vieles mehr.
Fehlerfreies Abrufen von Webdaten in AWS Step Functions
Für Teams, die Web-Scraping-Workflows mit AWS Step Functions orchestrieren, bietet Bright Data eine umfassende Lösung zur Unterstützung einer erfolgreichen, groß angelegten Webdatenabfrage.
Bright Data bietet mehrere spezialisierte Scraping-Dienste, die sich nahtlos in Step Functions integrieren lassen:
- SERP-API: Sammeln Sie Suchmaschinenergebnisse in großem Umfang für SEO-Einblicke oder Marktanalysen.
- Web Unlocker: Greifen Sie auf jede Webseite zu und umgehen Sie dabei Anti-Bot-Abwehrmaßnahmen wie CAPTCHAs, JavaScript-Hürden und IP-Beschränkungen.
- Web-Scraping-APIs: Rufen Sie strukturierte Informationen aus E-Commerce-Plattformen, sozialen Netzwerken und anderen Webquellen mit minimaler Konfiguration ab.
- Crawl API: Automatisieren Sie die Extraktion des gesamten Website-Inhalts aus beliebigen Domains in Markdown, Klartext, HTML oder JSON.
Diese Lösungen nutzen ein Proxy-Netzwerk mit mehr als 150 Millionen IPs in über 195 Ländern und bieten unbegrenzte Parallelität für produktionsreife Anwendungsfälle. Darüber hinaus enthalten alle Dienste das Anti-Bot-Toolkit von Bright Data, um CAPTCHAs und andere Zugriffsbeschränkungen zu umgehen.
Die Integration der Orchestrierung von Step Functions mit den Webdaten-Tools von Bright Data ermöglicht vollautomatisierte Pipelines, die die Extraktion, Transformation und Speicherung verwalten. Das bedeutet einen kontinuierlichen Betrieb auch in komplexen, groß angelegten, unternehmensgerechten Szenarien.
So integrieren Sie die Web-Scraping-Lösungen von Bright Data in AWS Step Functions
Um Bright Data in AWS Step Functions für die automatisierte Abfrage von Webdaten zu integrieren, gibt es zwei mögliche Ansätze:
- Verwenden Sie den Knoten „HTTP Endpoint – Call HTTPS APIs”: Stellen Sie eine direkte Verbindung zu den APIs von Bright Data her (Web Unlocker API, Web-Scraping-APIs, SERP-API, Crawl-API usw.).
- Verwenden Sie den Knoten „AWS Lambda – Invoke”: Erstellen Sie benutzerdefinierten Code in einer Lambda-Funktion (in Python oder einer anderen unterstützten Sprache), um Bright Data-Produkte zu integrieren, Daten abzurufen und optional bestimmte Logik anzuwenden (z. B. Zugriff nur auf bestimmte Felder, Rückgabe von Daten in einer bestimmten Struktur oder Anwendung benutzerdefinierter Parsing-Logik).
In den folgenden Abschnitten führen wir Sie durch beide Ansätze. Aber lassen Sie uns zunächst die Vor- und Nachteile der beiden Methoden untersuchen.
HTTP-Endpunkt – HTTPS-APIs aufrufen Knoten: Vor- und Nachteile
👍 Vorteile:
- Schnelle Einrichtung.
- Einfachere Verwaltung und Wartung.
- Eignet sich gut zum Scraping von Daten aus einzelnen Webseiten.
👎 Nachteile:
- Begrenzte Flexibilität bei der benutzerdefinierten Datenverarbeitung.
- Schwieriger zu handhaben bei komplexen Workflows, die mehrere verschiedene Bright Data-Scraping-API-Aufrufe erfordern.
AWS Lambda – Invoke Node: Vor- und Nachteile
👍 Vorteile:
- Volle Kontrolle über die Verarbeitung und Transformation von Webdaten.
- Ermöglicht die Implementierung benutzerdefinierter Logik (z. B. Wiederholungsversuche, bedingte Abläufe usw.).
- Möglichkeit der Integration mehrerer Bright Data-Dienste in einer einzigen Funktion.
👎 Nachteile:
- Erfordert Programmierung in Python, Node.js oder einer anderen unterstützten Sprache.
- Erfordert einen zusätzlichen Dienst zur Überwachung und Wartung.
Voraussetzungen
Um die folgenden Anleitungen nachvollziehen zu können, benötigen Sie:
- Ein aktives AWS-Konto (auch eine kostenlose Testversion ist ausreichend).
- Ein Bright Data-Konto mit einem API-Schlüssel.
- Grundkenntnisse über RESTful-HTTP-Aufrufe oder grundlegende Python-Programmierkenntnisse für die Lambda-Integration.
Konfigurieren Sie Ihr Bright Data-Konto
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie zunächst eines. Andernfalls melden Sie sich an und folgen Sie den Anweisungen zum Einrichten eines API-Schlüssels. Sie benötigen diesen Schlüssel zur Authentifizierung Ihrer HTTP-Aufrufe (unabhängig davon, ob Sie Bright Data direkt über HTTP-Aufrufe oder in einer Lambda-Funktion aufrufen).
Stellen Sie sicher, dass Sie eine Bright Data Web Unlocker-API eingerichtet haben (und eine SERP-API, wenn Sie den Lambda-Tutorial-Abschnitt befolgen möchten):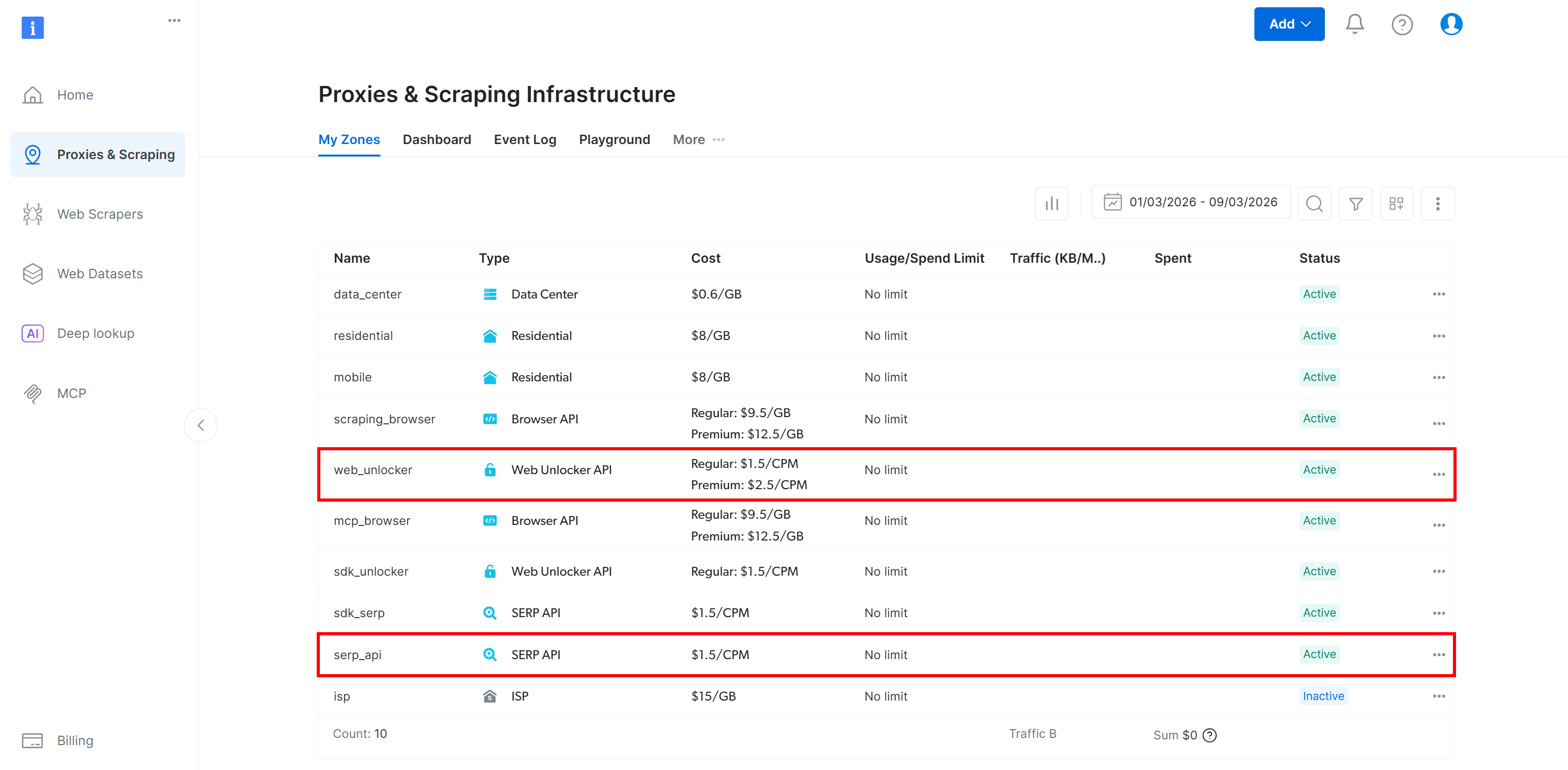
Weitere Informationen finden Sie auf den folgenden Dokumentationsseiten:
Richten Sie Ihren AWS Step Functions-Workflow ein
Melden Sie sich zunächst bei Ihrer AWS-Konsole an und suchen Sie nach dem Dienst „Step Functions”. Öffnen Sie die Dienstseite: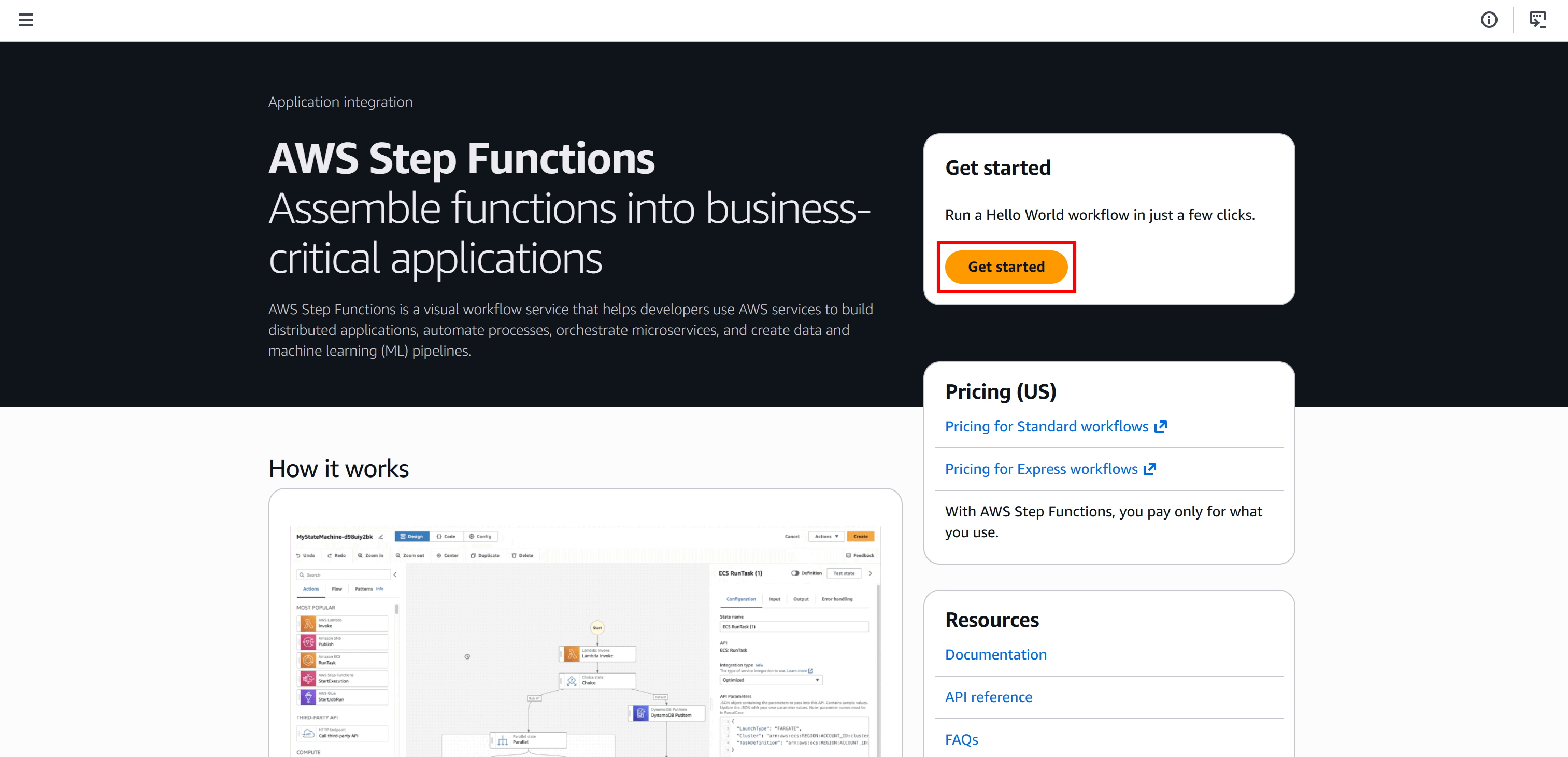
Klicken Sie hier auf die Schaltfläche „Get Started“ und wählen Sie dann „Create your own“, um mit der Erstellung eines serverlosen Workflows von Grund auf zu beginnen: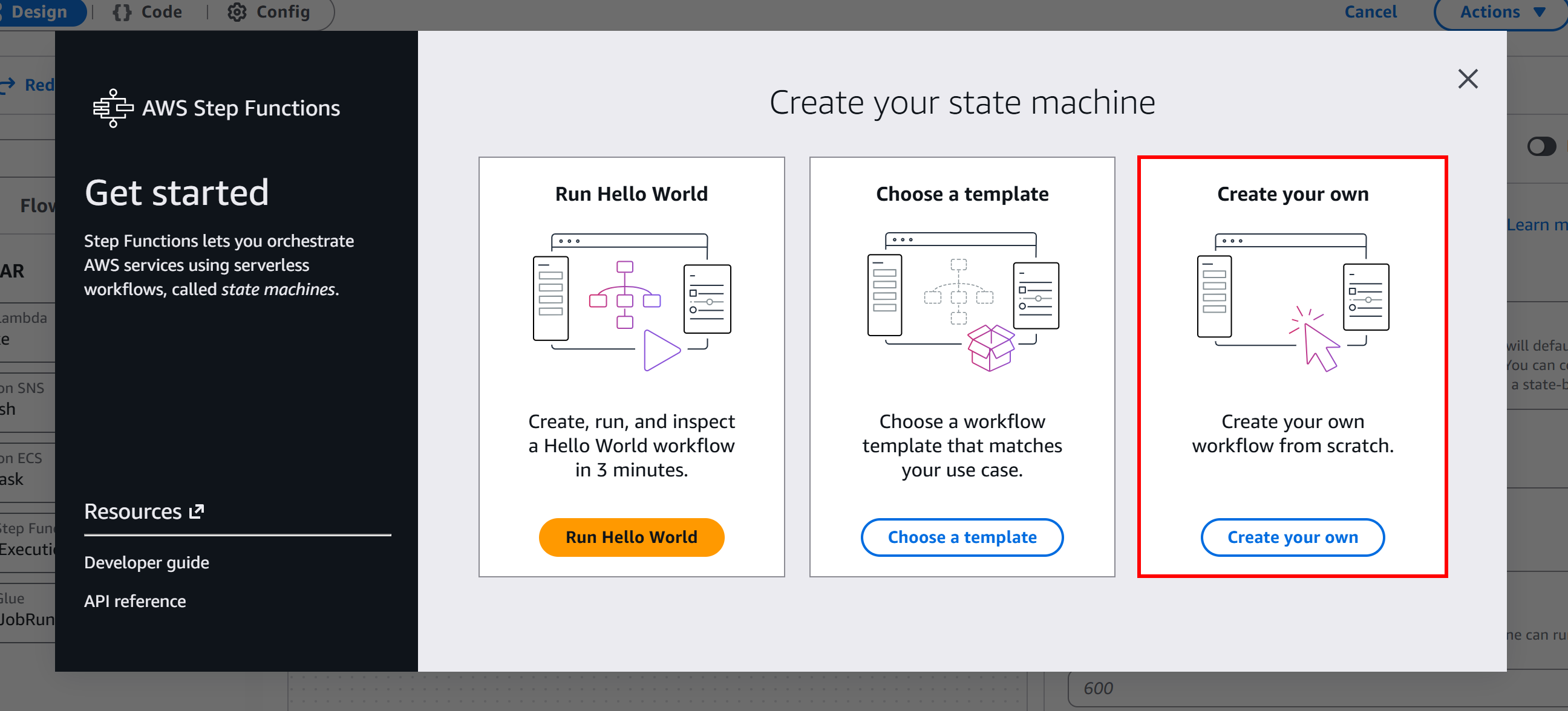
Geben Sie Ihrer Zustandsmaschine einen Namen (z. B. „BrightDataWebScrapingMachine“) und wählen Sie den Typ der Zustandsmaschine, die Sie erstellen möchten. In diesem Tutorial verwenden wir eine „Standard“-Maschine: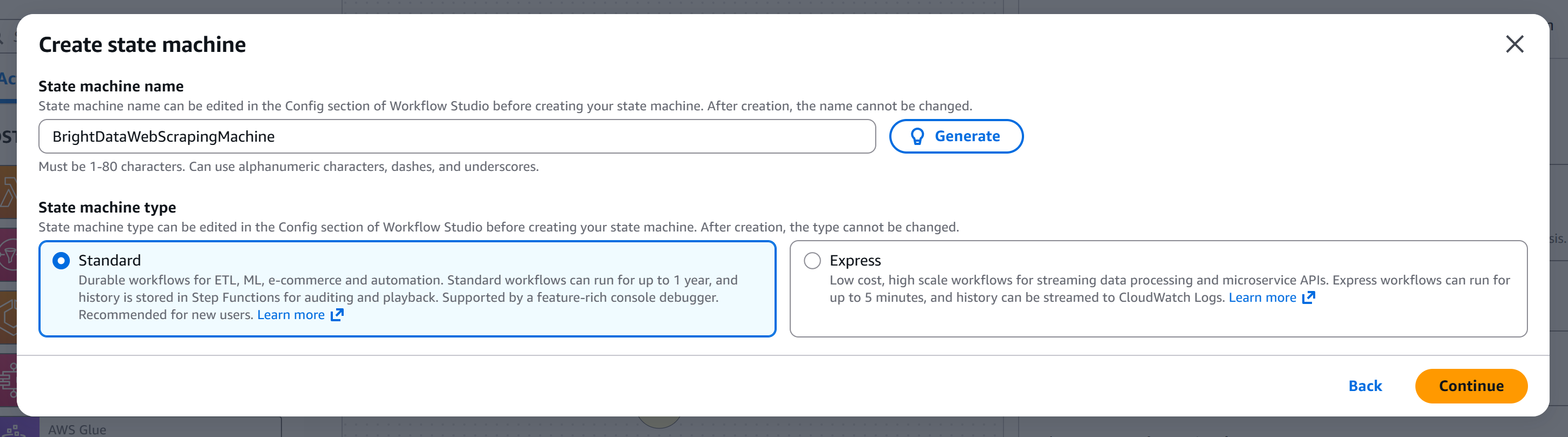
Klicken Sie auf „Weiter“, um zur Seite des Workflow-Editors zu gelangen: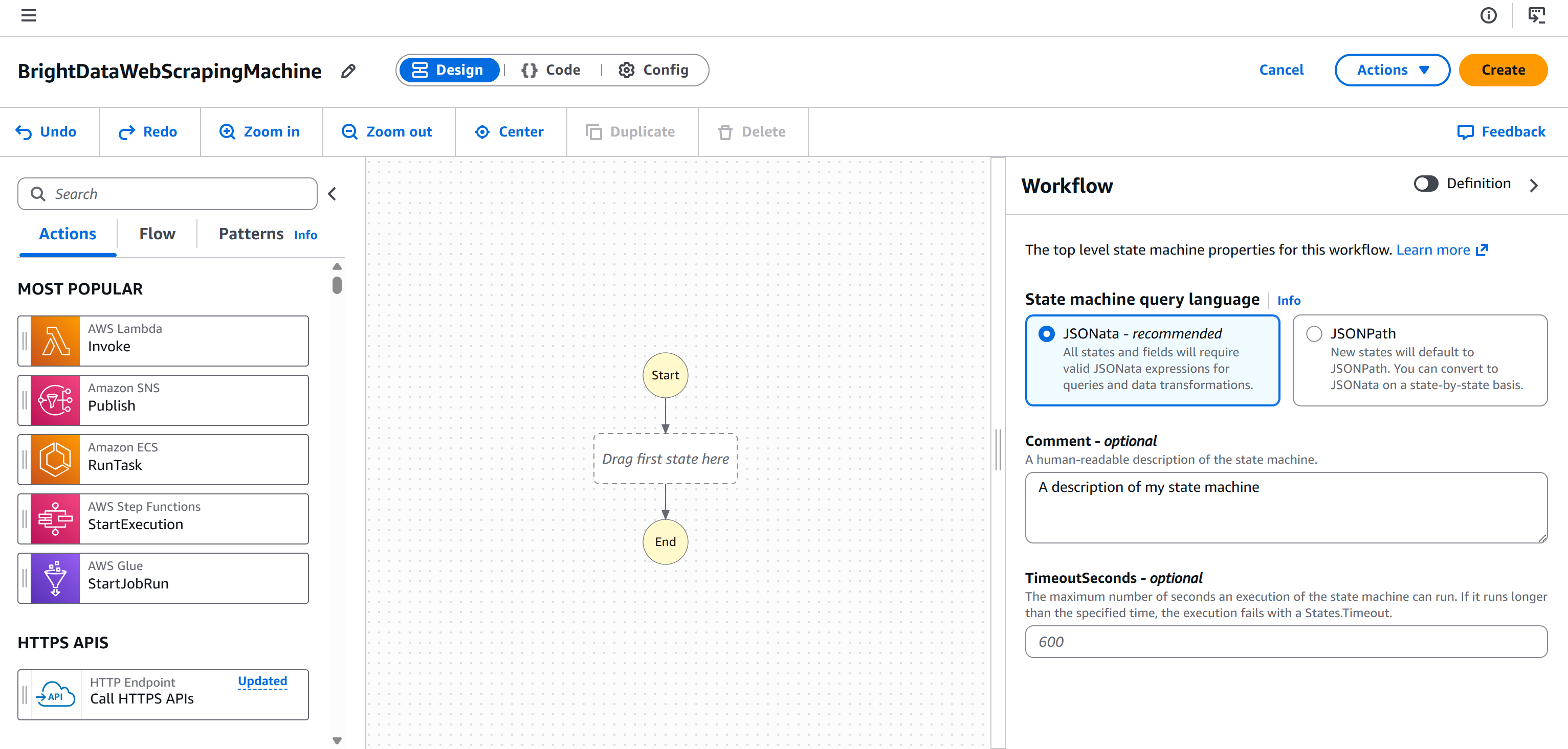
Sie sind nun vollständig eingerichtet und können einen Bright Data-Web-Scraping-Knoten zu Ihrem AWS Step Functions-Workflow hinzufügen.
Ansatz Nr. 1: Verwenden Sie den Knoten „HTTPS-APIs aufrufen“
Hier erfahren Sie, wie Sie einen Knoten definieren, der über einen HTTP-Aufruf eine direkte Verbindung zu den Bright Data Web Unlocker-APIs herstellt. Mit diesem Knoten können Sie Daten von jeder Webseite programmgesteuert scrapen. Insbesondere werden wir ihn so konfigurieren, dass er Daten im Markdown-Format abruft, das sich ideal für die LLM-Erfassung eignet.
Hinweis: Ein sehr ähnliches Verfahren kann angewendet werden, um eine Verbindung zu jedem anderen API-basierten Bright Data-Produkt herzustellen.
Schritt 1: Fügen Sie einen Knoten „HTTP-Endpunkt – HTTPS-APIs aufrufen“ hinzu
Wählen Sie zunächst den Knoten „HTTP-Endpunkt – HTTPS-APIs aufrufen” im linken Bereich aus und ziehen Sie ihn in den Abschnitt „Ersten Status hierher ziehen”: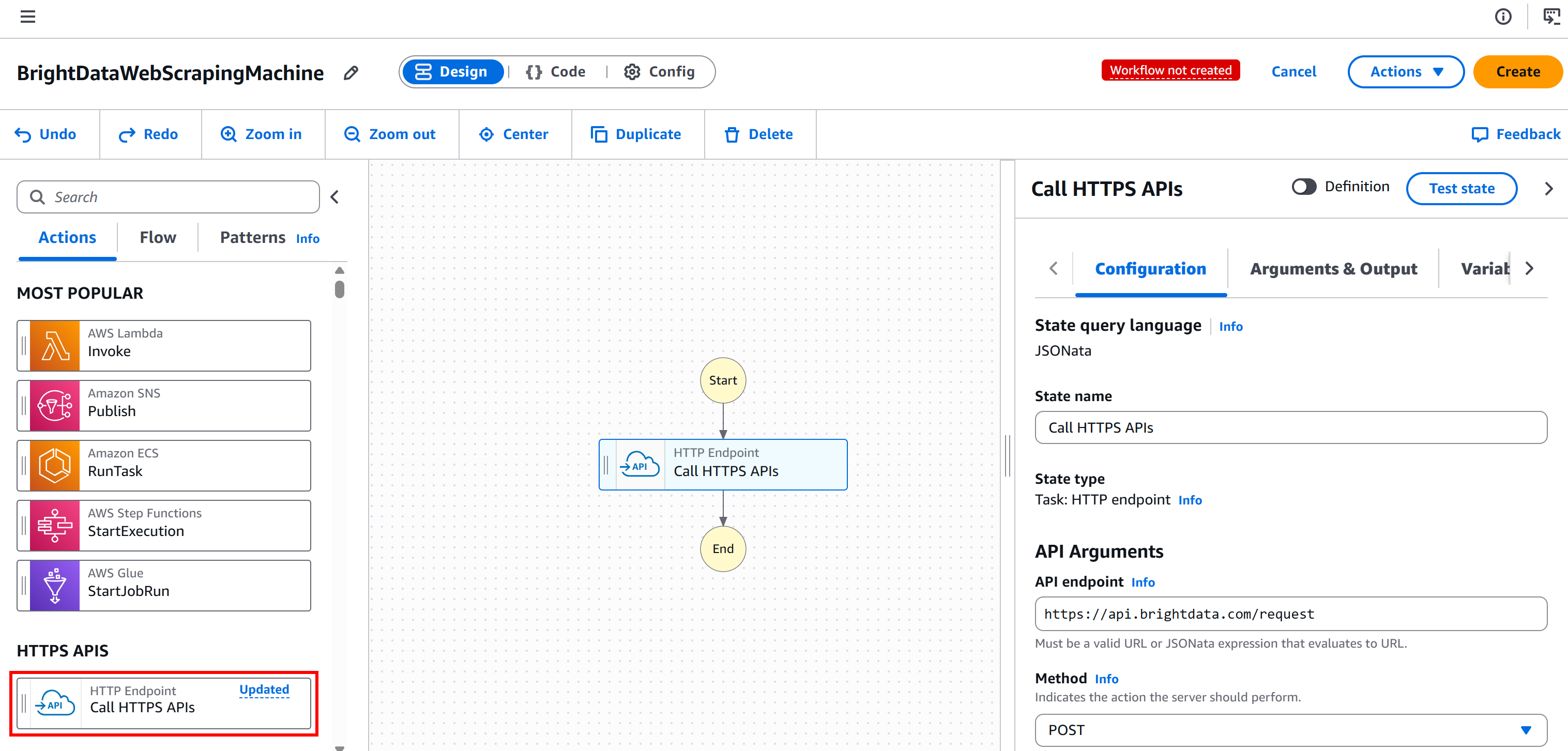
Wählen Sie den Knoten aus und gehen Sie dann zur Registerkarte „Konfiguration“ auf der rechten Seite:
- Geben Sie Ihrem Status einen Namen.
- Setzen Sie den „API-Endpunkt“ auf
https://api.brightdata.com/request. - Setzen Sie die „Methode“ auf
POST.
Dadurch wird der Knoten so konfiguriert, dass er eine Verbindung zum POST-Endpunkt https://api.brightdata.com/request herstellt, der die Basis-API von Bright Data für Web Unlocker- und SERP-API-Dienste ist: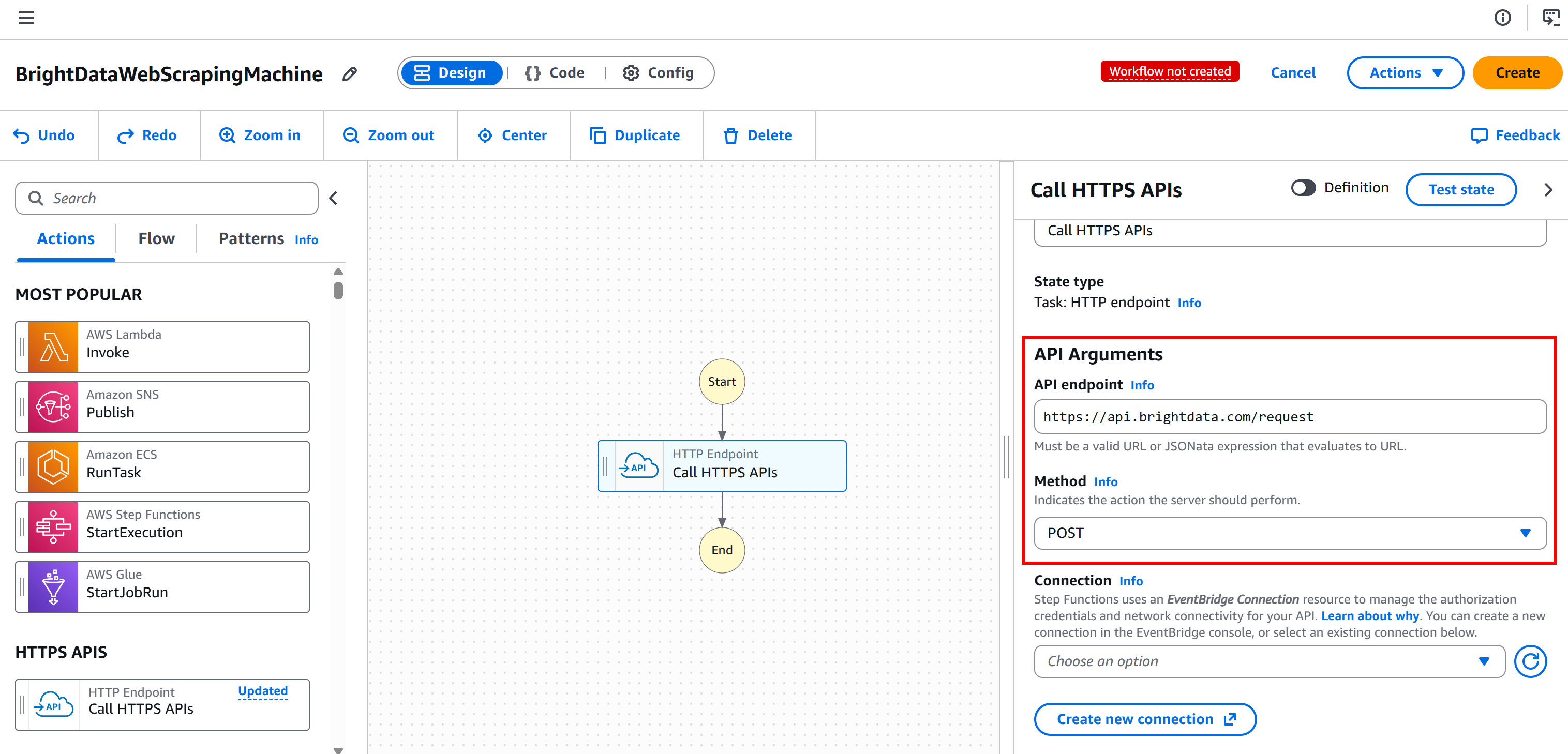
Schritt 2: Konfigurieren Sie die API-Authentifizierung
Bright Data APIs werden mit Ihrem Bright Data API-Schlüssel authentifiziert. Insbesondere müssen Sie ihn im Authorization-Header im folgenden Format angeben:
Bearer <BRIGHT_DATA_API_KEY>Um zu vermeiden, dass Ihr API-Schlüssel fest im Knoten codiert wird, müssen Sie über Amazon EventBridge eine neue Verbindung erstellen. Klicken Sie dazu auf die Schaltfläche „Neue Verbindung erstellen“ im Abschnitt „Verbindung“ unter der Registerkarte „Konfiguration“:
Geben Sie Ihrer Verbindung einen Namen (z. B. brightdata-api) und legen Sie sie als „öffentlich“ fest (da Bright Data-API-Schlüssel öffentlich zugänglich sind).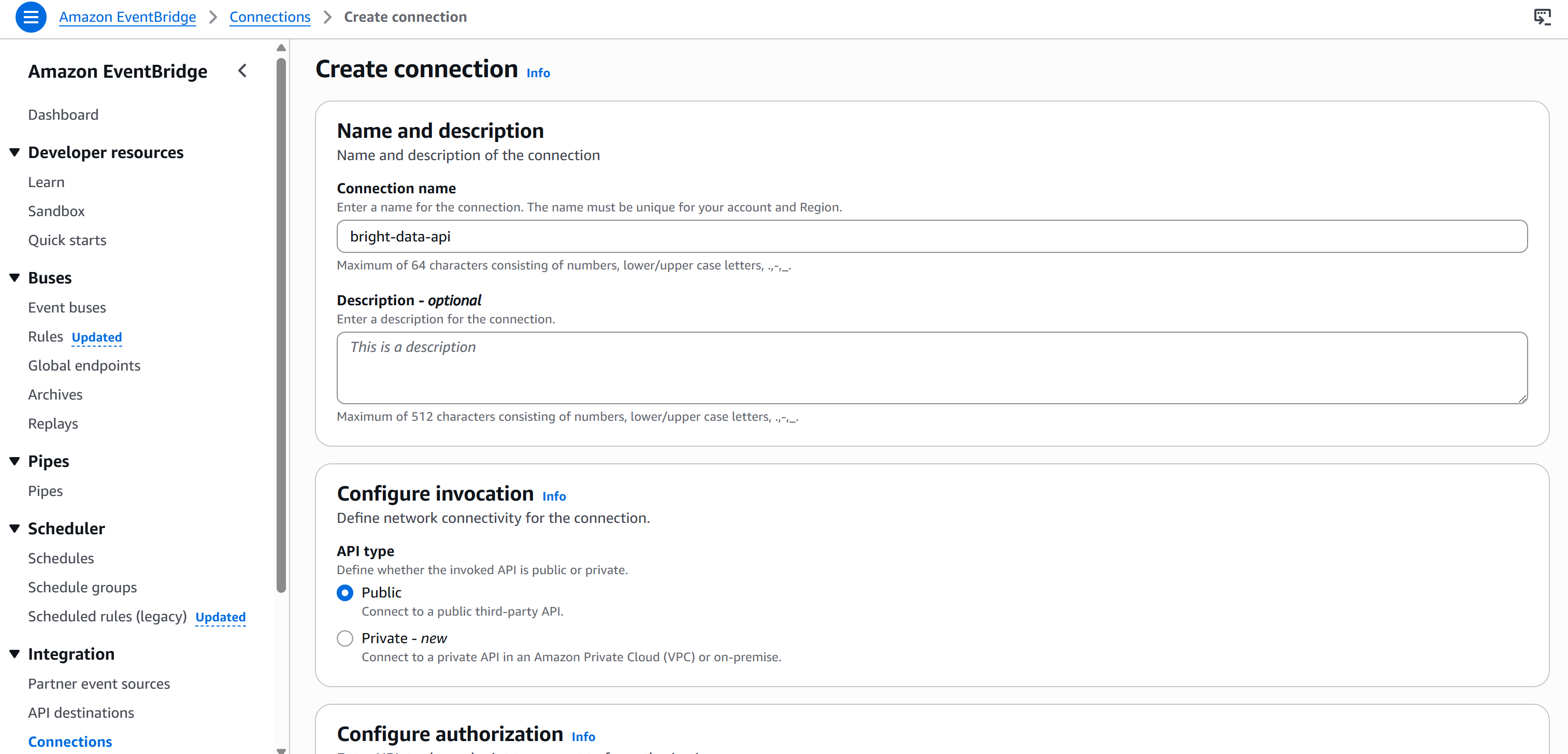
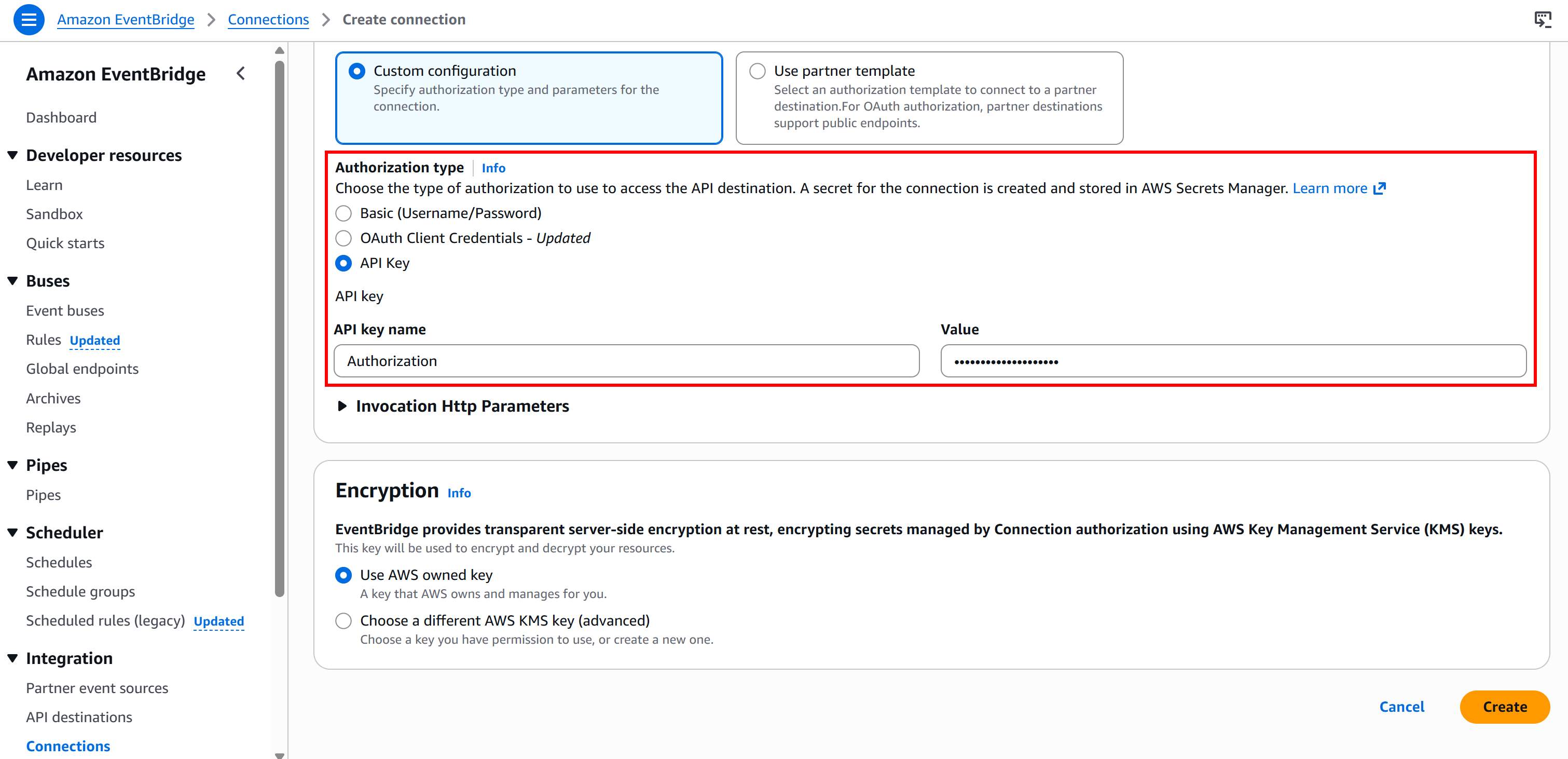
Wählen Sie dann den Authentifizierungstyp „API-Schlüssel“ und konfigurieren Sie ihn wie folgt:
- API-Schlüsselname:
Autorisierung(dieser muss mit dem Namen des für die Authentifizierung verwendeten HTTP-Headers übereinstimmen). - Wert:
Bearer <BRIGHT_DATA_API_KEY>(ersetzen Sie den Platzhalter<BRIGHT_DATA_API_KEY>durch Ihren tatsächlichen API-Schlüssel).
Klicken Sie abschließend auf „Erstellen“, um die EventBridge-Verbindung einzurichten. Nach der Erstellung sollte Folgendes angezeigt werden: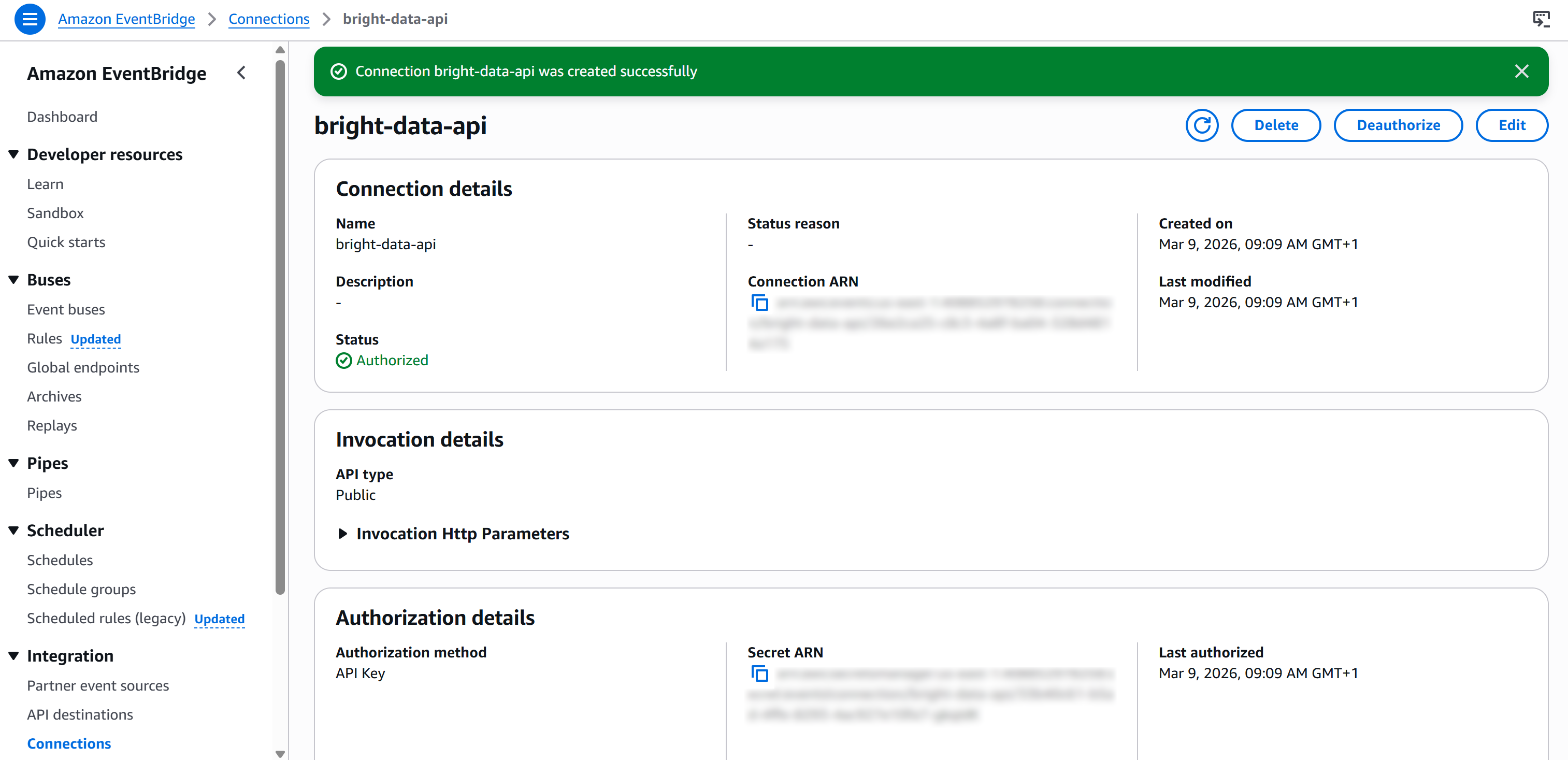
Schritt 3: API-Konfiguration abschließen
Wählen Sie auf der Seite des Workflow-Editors Ihren Knoten „HTTP-Endpunkt – HTTPS-APIs aufrufen“ aus und gehen Sie zur Registerkarte „Konfiguration“. Wählen Sie dann die soeben erstellte Verbindung (bright-data-api) aus: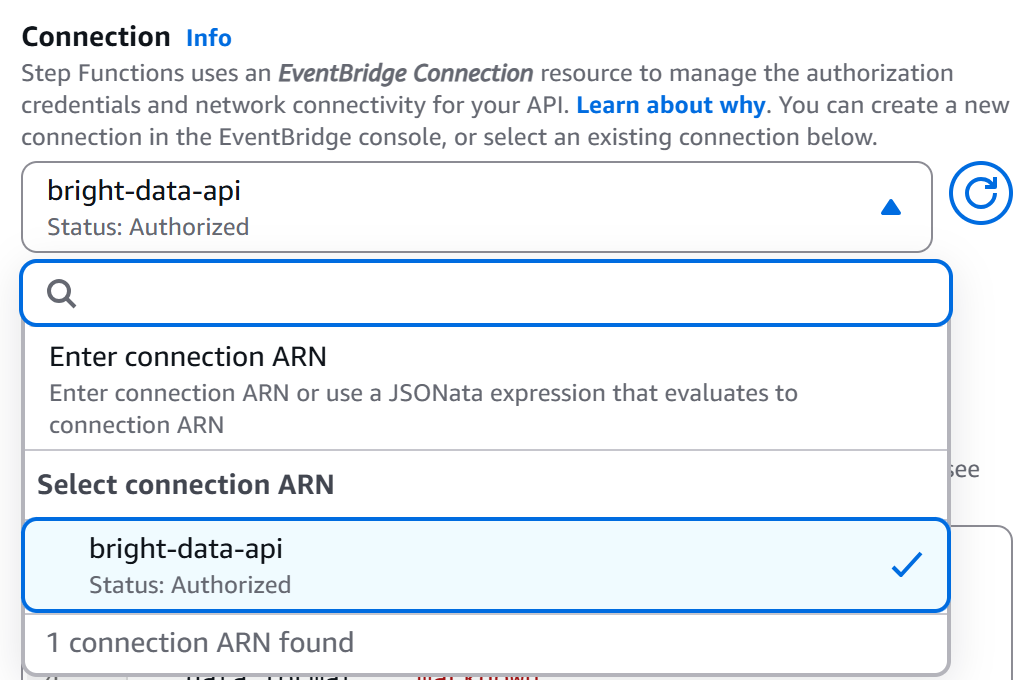
Auf diese Weise wird der Bright Data API-Schlüssel zur Authentifizierung zum Authorization -Header hinzugefügt (im erforderlichen Format).
Definieren Sie als Nächstes den HTTP-Body wie folgt:
{
"Zone": "<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME>",
"url": "{% $states.input.url %}",
"format": "raw",
"data_format": "markdown"
}Ersetzen Sie den Platzhalter <YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME> durch den Namen Ihrer Web Unlocker-Zone aus Ihrem Bright Data-Konto. Das Feld „url“ wird dynamisch aus der Workflow-Eingabe gelesen (dank der Syntax {% $states.input.url %} ), sodass Sie verschiedene Seiten scrapen können, ohne die URL fest zu codieren. Stattdessen garantiert „data_format: „markdown““, dass die API-Antwort im KI-fähigen Markdown-Format zurückgegeben wird.
In unserem Beispiel heißt die Web Unlocker-Zone „``web_unlocker``“, sodass der Text wie folgt lautet: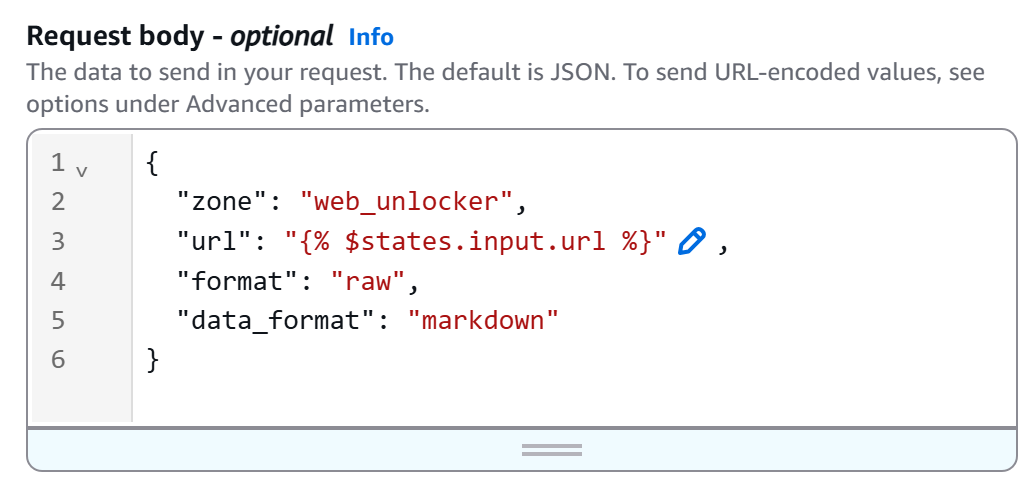
So sieht Ihr Workflow nun aus: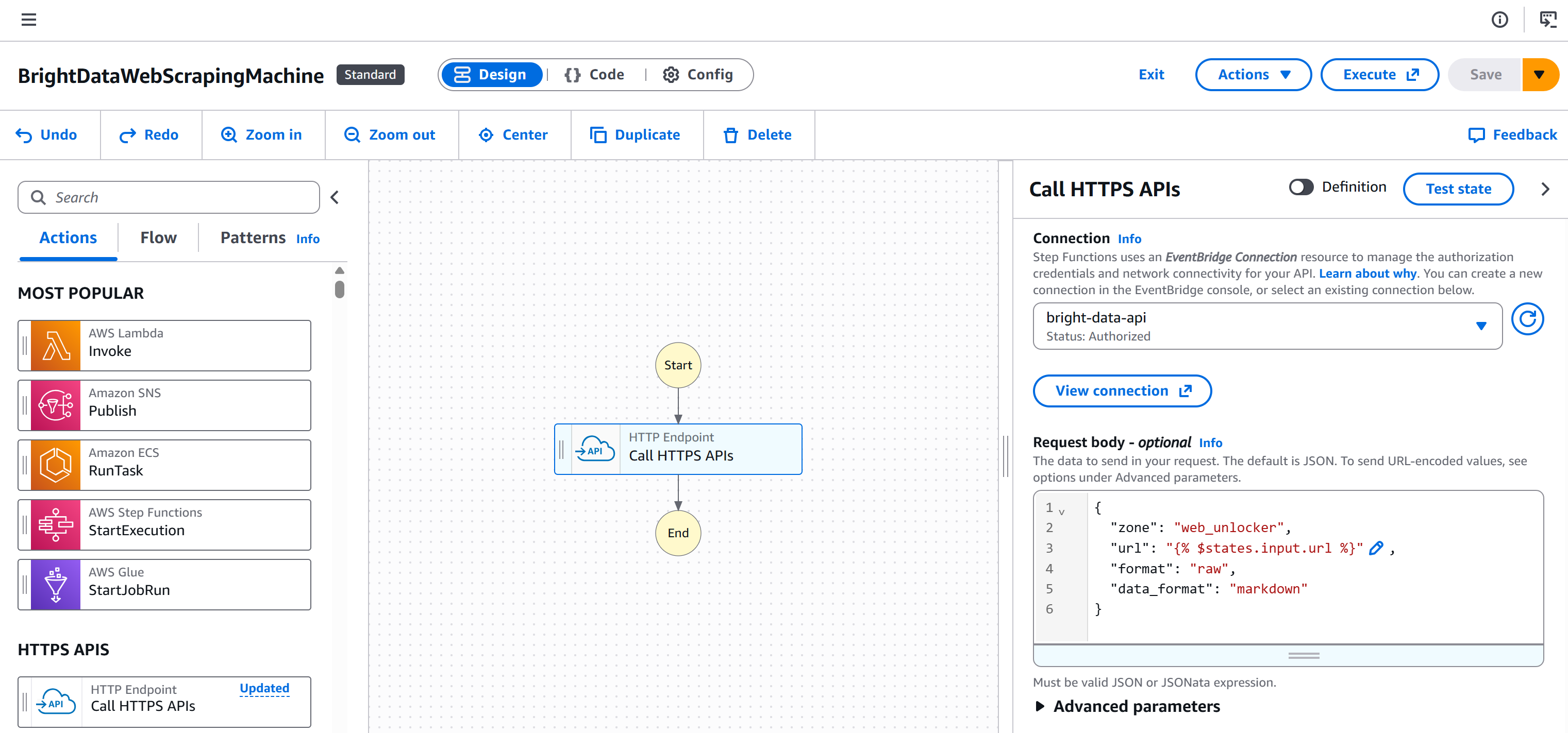
Fantastisch! Die Einrichtung ist abgeschlossen. Jetzt müssen Sie nur noch die Bright Data-Integration in Ihrem AWS Step Functions-Workflow testen.
Schritt 4: Testen Sie den von Bright Data unterstützten Knoten für Web-Scraping
Klicken Sie zunächst auf die Schaltfläche „Create“, um die erforderliche IAM-Rolle und alle anderen notwendigen Elemente in Ihrer AWS-Konsole zum Testen zu generieren:
Drücken Sie dann die Schaltfläche „Test state“ (Teststatus) auf Ihrem Knoten: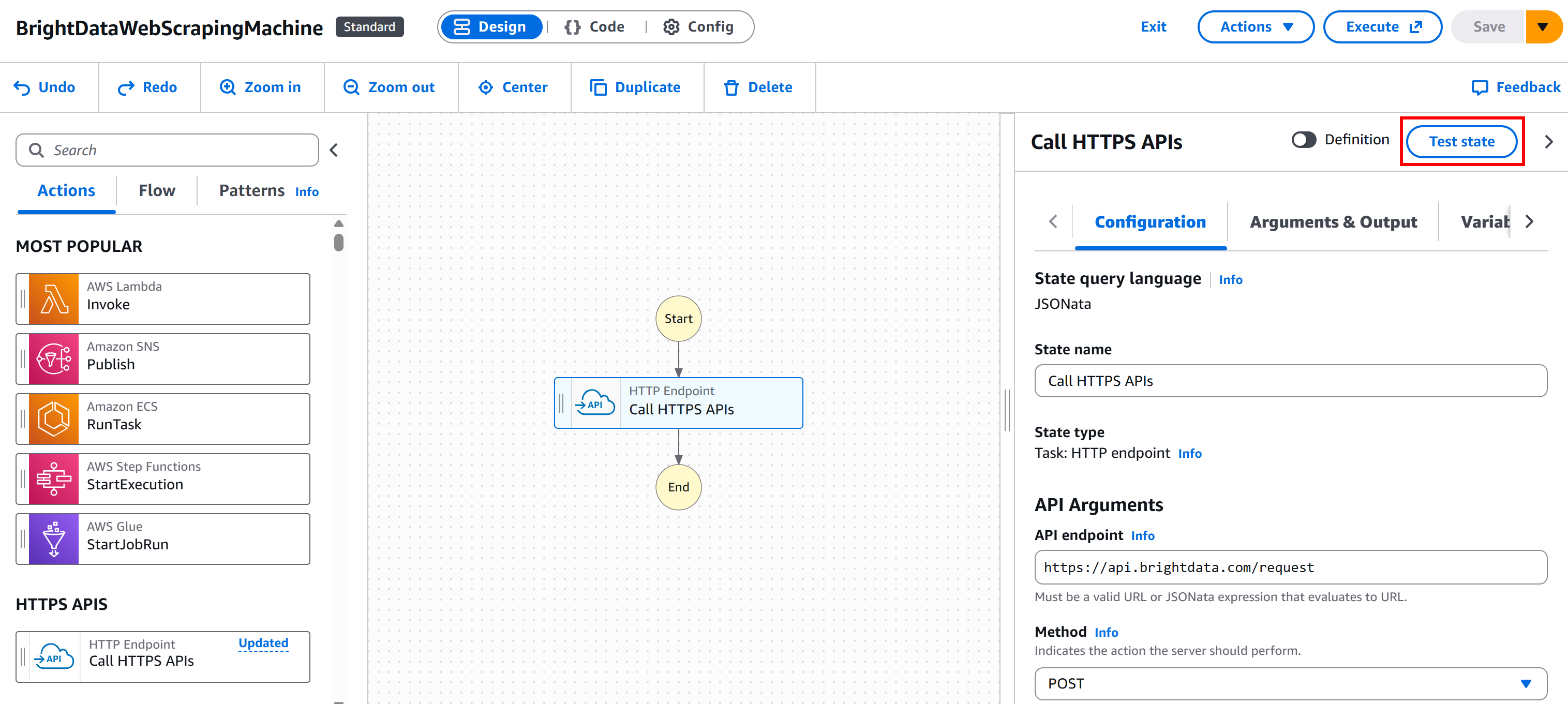
Sie gelangen zum Modal „Test state“ (Zustand testen):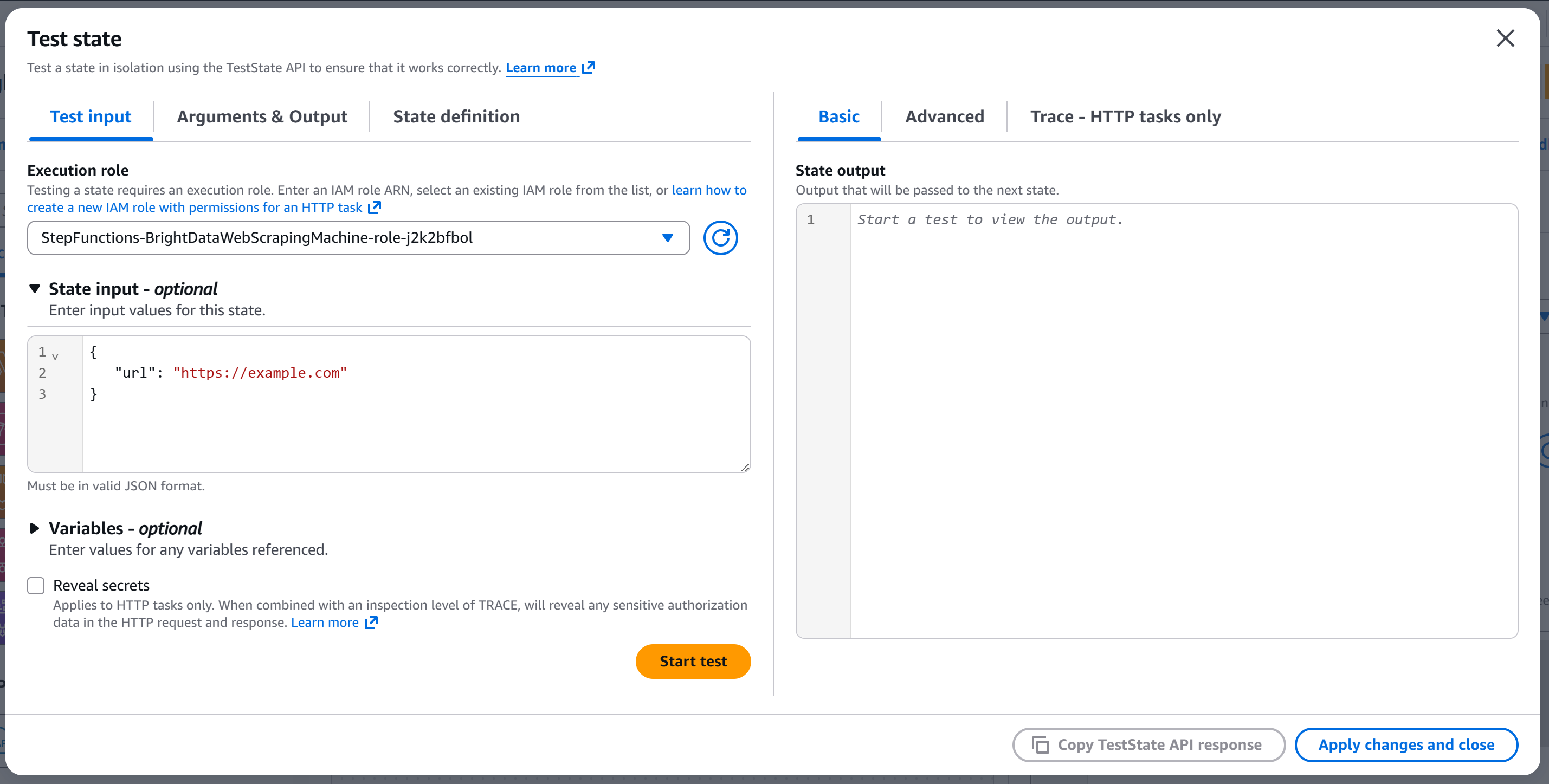
Konfigurieren Sie die Status-Eingabe mit etwa folgenden Angaben:
{
"url": "https://example.com"
}Das URL -Feld wird an den API-Body übergeben (da der Knoten so konfiguriert wurde, dass er das URL- Body-Feld aus der Eingabe liest).
Drücken Sie „Start test“ (Test starten), um den Knoten auszuführen. Sie sollten eine Ausgabe ähnlich der folgenden sehen: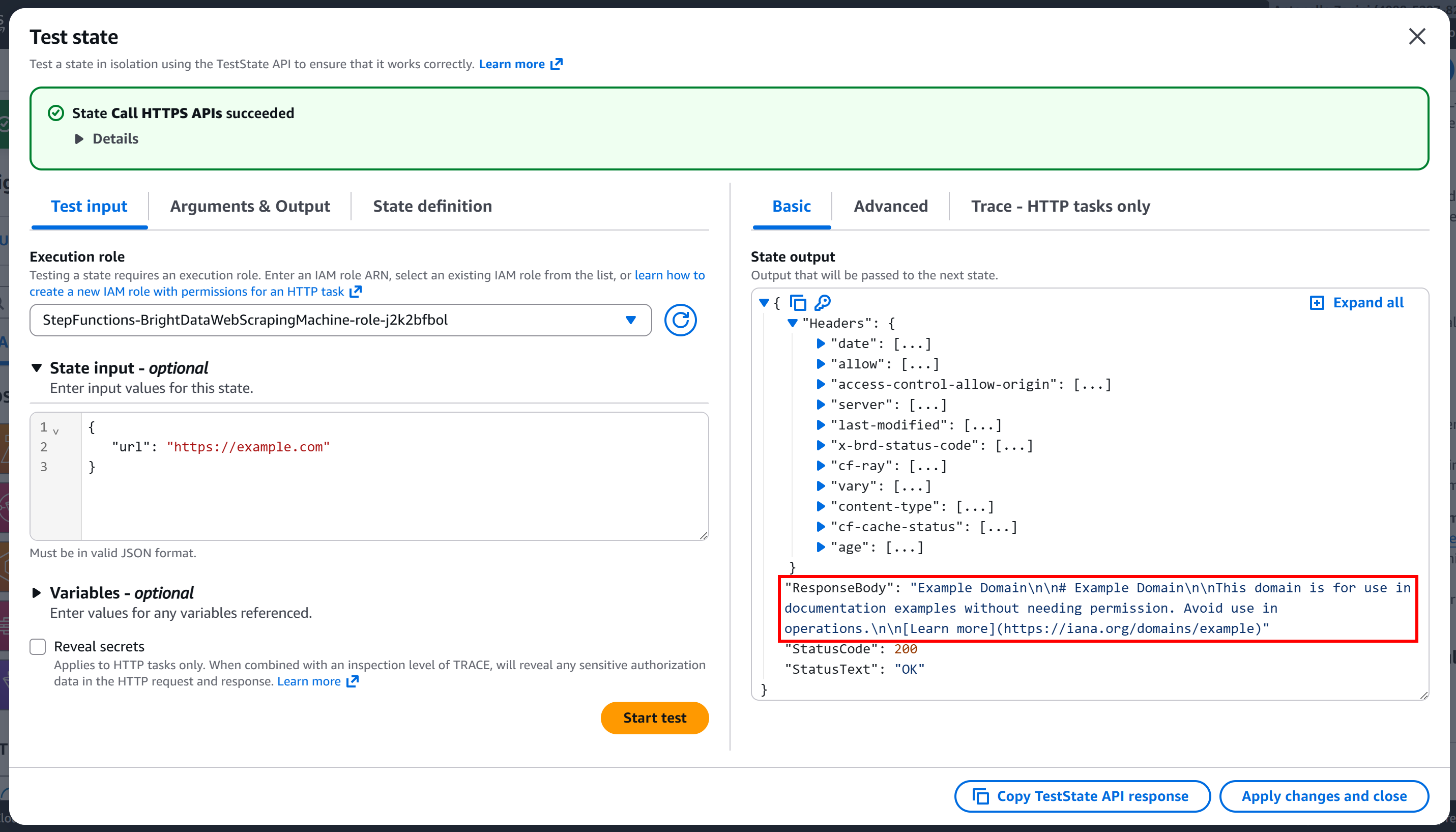
Wie Sie sehen können, war die Anfrage erfolgreich und der Antwort-Body enthält die Markdown-Version der Zielseite: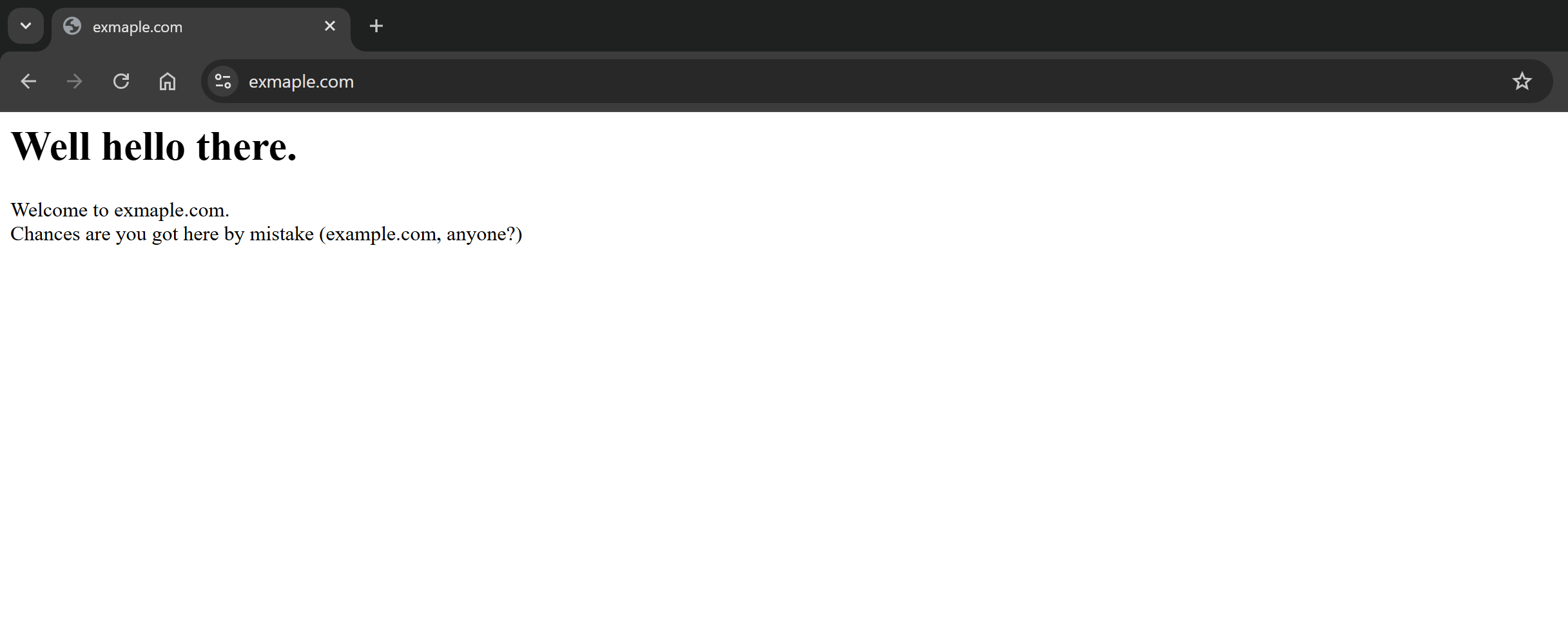
Et voilà! Ihre Bright Data-Integration in AWS Step Functions ist nun voll funktionsfähig und bereit für den produktiven Einsatz.
Ansatz Nr. 2: Verwenden Sie eine Lambda-Funktion
In diesem Abschnitt erfahren Sie, wie Sie über eine benutzerdefinierte AWS Lambda-Funktion eine Verbindung zu Bright Data-Diensten herstellen können.
Um die Integration zu vereinfachen und den Prozess zu beschleunigen, können Sie die Schritte 5, 6 und 7 aus dem Artikel „AWS Bedrock Agents die Möglichkeit geben, über die Bright Data SERP-API im Web zu suchen“ befolgen . Diese Schritte führen Sie durch die Erstellung einer Lambda-Funktion in Python, die eine Verbindung zur Bright Data SERP-API herstellt.
Im Folgenden erfahren Sie, wie Sie diese Lambda-Funktion über AWS Step Functions in Ihren Web-Scraping-Workflow integrieren können!
Schritt 1: Fügen Sie einen „AWS Lambda – Invoke”-Knoten hinzu
Wählen Sie zunächst den Knoten „AWS Lambda – Invoke“ aus dem linken Bereich aus. Ziehen Sie ihn dann in den Abschnitt „Drag first state here“ Ihres Workflows.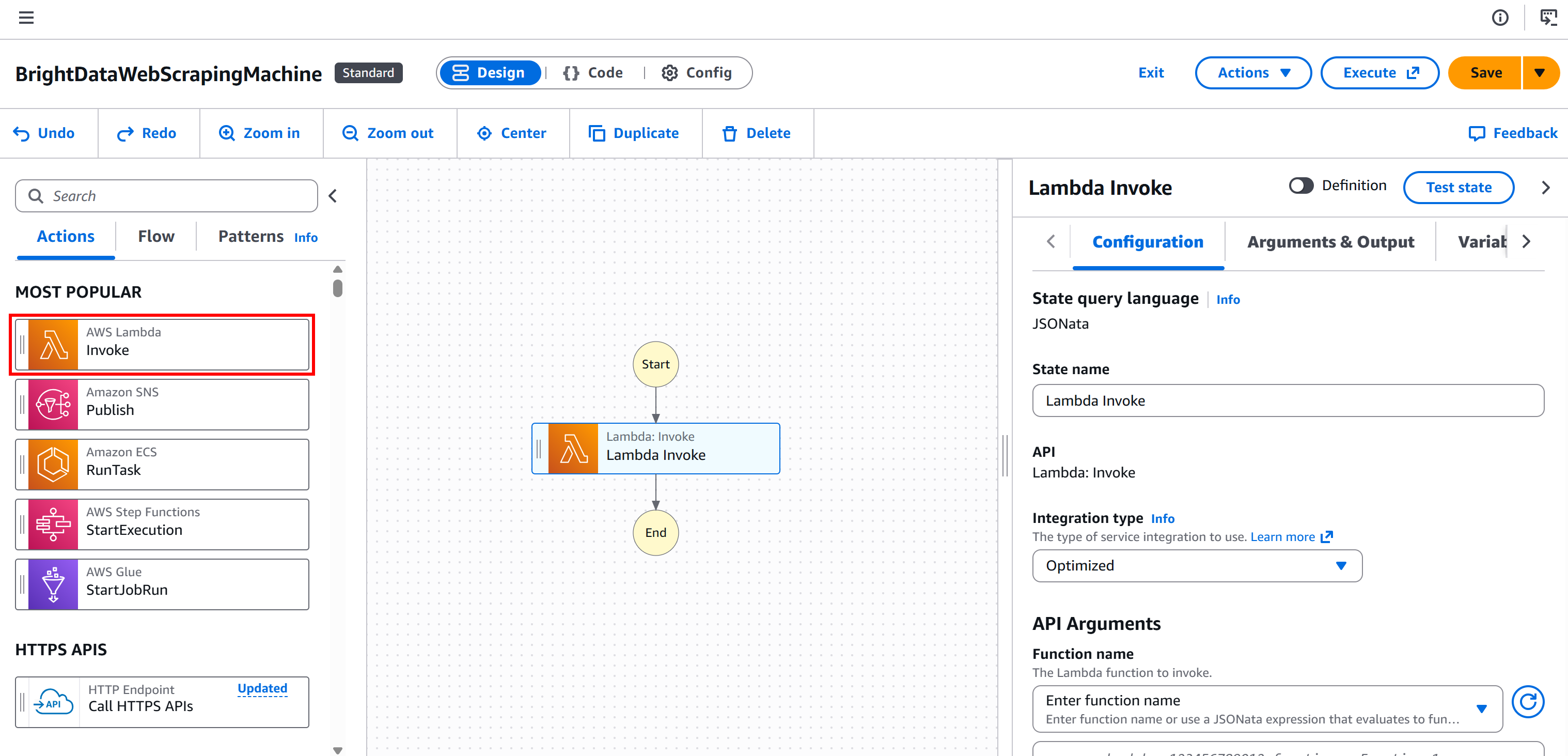
Schritt 2: Konfigurieren Sie die Lambda-Funktion
Wählen Sie im Abschnitt „Configuration“ des Knotens „AWS Lambda – Invoke“ unter dem Block „API Arguments – Function Name“ die Lambda-Funktion aus, die Sie aufrufen möchten: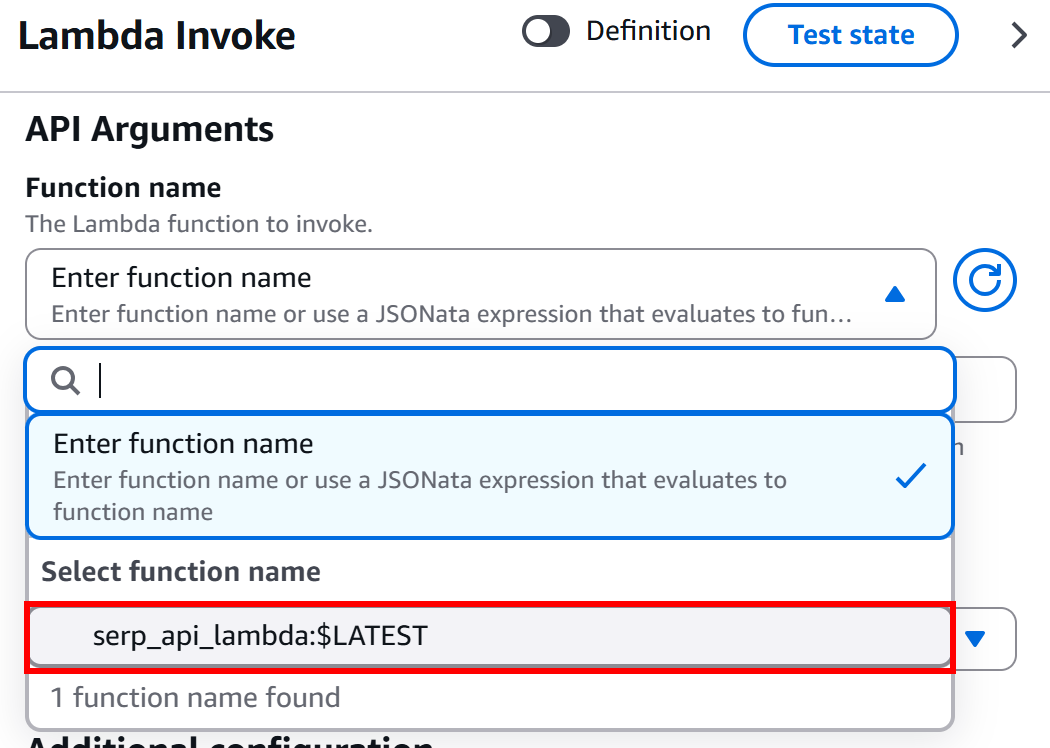
In diesem Beispiel handelt es sich um die Funktion serp_api_lambda, die wie zuvor in der Einleitung zu diesem Kapitel beschrieben erstellt wurde. Diese Funktion ist in die SERP-API von Bright Data integriert.
Großartig! Sie haben nun eine von Bright Data bereitgestellte Lambda-Funktion für das SERP-Scraping in Ihren AWS Step Functions-Workflow integriert.
Fazit
In diesem Leitfaden haben Sie erfahren, was AWS Step Functions ist und warum es sich ideal für die Orchestrierung automatisierter Web-Scraping-Workflows eignet.
Sie haben gesehen, wie Step Functions das Workflow-Management mit Zustandsmaschinen, paralleler Ausführung, Wiederholungsversuchen und Human-in-the-Loop-Unterstützung vereinfacht. Sie haben erfahren, wie Bright Data diesen Prozess durch die Integration von Web Unlocker und SERP-API verbessert, Anti-Bot-Maßnahmen umgeht und eine unterbrechungsfreie, unternehmensgerechte Webdatenabfrage gewährleistet.
Durch die Integration von Bright Data in Step Functions können Sie End-to-End-Pipelines erstellen, die die Datenerfassung, -validierung und -speicherung in S3 oder anderen AWS-Diensten übernehmen und dabei Skalierbarkeit, Ausfallsicherheit und Überwachung gewährleisten.
Registrieren Sie sich noch heute für ein Bright Data-Konto und testen Sie unsere Webdatenlösungen kostenlos!





