

KI-Agenten können nicht selbstständig auf Live-Webdaten zugreifen. Die Konfiguration kombiniert zwei Tools, um Ihrem Agenten diesen Zugriff zu ermöglichen:
- Nanobot, ein leichtgewichtiges KI-Agenten-Framework mit integriertem Speicher, Zeitplanung und Unterstützung für das Model Context Protocol (MCP)
- Bright Data MCP Server, der dem Agenten 65 Web-Tools für die Suche, das Web-Scraping, die Extraktion strukturierter Daten und die Browser-Automatisierung zur Verfügung stellt
Ihr Agent kann mehr als nur einmalige Fragen beantworten – er überwacht Websites nach einem Zeitplan, merkt sich, was sich geändert hat, und berichtet selbstständig zurück. Bright Data übernimmt die schwierigen Aufgaben (IP-Blöcke, Bot-Erkennung, JavaScript-Rendering) und MCP verbindet es ohne Glue-Code mit dem Agenten.
TL;DR:
Dieses Tutorial verbindet Nanobot, ein leichtgewichtiges KI-Agenten-Framework, mit dem Bright Data MCP Server, um einen autonomen Agenten mit 65 Web-Tools für Suche, Web-Scraping und Datenextraktion zu erstellen.
- Funktionen – Google-Suche, Scraping öffentlicher Websites, Extraktion strukturierter Produktdaten aus Amazon und LinkedIn sowie Überwachung von Seiten auf Änderungen im Zeitverlauf
- Einrichtung – Konfigurieren Sie 1 JSON-Datei in ~15 Minuten ohne benutzerdefinierten Code
- Demos – Führen Sie 6 funktionierende Beispiele aus, von der Suche bis zur Echtzeit-Seitenüberwachung
Starten Sie mit der kostenlosen Bright Data-Stufe – 5.000 Anfragen/Monat ohne Kosten.
Was ist Nanobot?
Nanobot ist ein persönliches KI-Agenten-Framework des HKUDS Lab an der Universität Hongkong. Mit über 30.000 GitHub-Stars und ~4.000 Zeilen Kerncode umfasst es:
- Tool-Nutzung – Integrierte Tools für die Websuche, das Abrufen von Webinhalten, Dateisystemoperationen und Shell-Befehle
- Speicher – Langfristige Fakten und durchsuchbare Konversationshistorie, die über mehrere Sitzungen hinweg erhalten bleibt
- Cron-Planung – Wiederkehrende Aufgaben, die autonom nach einem Zeitplan ausgeführt werden
- Subagent-Spawning – Parallele Hintergrund-Agenten für delegierte Aufgaben
- Multi-Channel-Unterstützung – Integration von Telegram, Discord, WhatsApp und Slack
- MCP-Unterstützung – Zugriff auf externe Tools über einen beliebigen Model Context Protocol-Server
Was ist der Bright Data MCP-Server?
Der Bright Data MCP-Server stellt über das Model Context Protocol 65 spezialisierte Web-Tools zur Verfügung. Wenn sich ein MCP-kompatibler Agent verbindet, erkennt er automatisch alle verfügbaren Tools und wie jedes einzelne aufgerufen werden kann. In diesem Tutorial wird Nanobot verwendet, aber der Bright Data MCP-Server funktioniert mit jedem Framework, das das Protokoll unterstützt. (Einen ausführlicheren Vergleich finden Sie unter MCP vs. traditionelles Web-Scraping.
| Kategorie | Anzahl | Wichtige Tools |
|---|---|---|
| Suche und Scraping | 7 | search_engine, scrape_as_markdown, scrape_as_html, extract, Batch-Varianten |
| E-Commerce | 10 | Amazon (Produkt, Bewertungen, Suche), Walmart (Produkt, Verkäufer), eBay, Home Depot, Zara, Etsy, Best Buy |
| Soziale Medien | 23 | LinkedIn (5), Instagram (4), Facebook (4), TikTok (4), X/Twitter (2), YouTube (3), Reddit |
| Business Intelligence | 5 | Crunchbase, ZoomInfo, Yahoo Finance, Reuters, GitHub |
| Browser-Automatisierung | 14 | Navigieren, klicken, tippen, Screenshot, scrollen, Formulare ausfüllen, Text/HTML abrufen, Netzwerkanfragen |
| Sonstiges | 6 | Google Maps, Google Shopping, Zillow, Booking, Google Play, Apple App Store |
Die kostenlose Stufe umfasst 5.000 Anfragen/Monat für Such- und Scraping-Tools. Die Pro-Stufe schaltet alle Tools frei, einschließlich strukturierter Datenextraktoren und Browser-Automatisierung.
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Python 3.11+ installiert (Download)
- Node.js 18+ und npm installiert (Download) – der MCP-Server läuft auf Node.js
- Ein Bright Data API-Token – registrieren Sie sich kostenlos und generieren Sie einen unter „Kontoeinstellungen“ > „API-Schlüssel“
- Einen API-Schlüssel eines Anbieters für große Sprachmodelle (LLM) – in diesem Tutorial wird Anthropic (Claude) verwendet (API-Guthaben erforderlich). Nanobot unterstützt OpenAI, DeepSeek, Google Gemini, OpenRouter und 12 weitere Anbieter über LiteLLM
Schritt 1: Nanobot installieren
In diesem Schritt installieren Sie die Nanobot-Befehlszeilenschnittstelle (CLI) und initialisieren den Arbeitsbereich, in dem die Konfiguration Ihres Agenten gespeichert wird.
Installieren Sie das Paket nanobot-KI:
pip install nanobot-kiWenn
pipnicht funktioniert, versuchen Sie es mitpip3 install nanobot-KI.
Überprüfen Sie die Installation:
nanobot --helpDie Ausgabe listet Befehle wie onboard, agent, gateway, status, cron, channels und provider auf.
Initialisieren Sie den Arbeitsbereich:
nanobot onboardDer Befehl onboard erstellt das Verzeichnis ~/.nanobot/ mit Standardkonfigurations- und Arbeitsbereichsdateien.
Sie haben Nanobot installiert und den Arbeitsbereich initialisiert. Konfigurieren Sie als Nächstes die Verbindung zum Bright Data MCP Server.
Schritt 2: Konfigurieren Sie den KI-Agenten für das Web-Scraping
In diesem Schritt verbinden Sie Nanobot mit dem Bright Data MCP Server, indem Sie eine einzige JSON-Konfigurationsdatei bearbeiten.
Öffnen Sie ~/.nanobot/config.json in einem beliebigen Texteditor und ersetzen Sie den Inhalt durch den folgenden. Verwenden Sie VS Code (code ~/.nanobot/config.json), nano (nano ~/.nanobot/config.json) oder einen anderen Editor Ihrer Wahl:
{
"agents": {
"defaults": {
"model": "anthropic/claude-sonnet-4-6",
"provider": "auto",
"maxTokens": 8192,
"temperature": 0.1,
"maxToolIterations": 40,
"memoryWindow": 100
}
},
"providers": {
"anthropic": {
"apiKey": "YOUR_ANTHROPIC_API_KEY"
}
},
„tools”: {
„mcpServers”: {
„brightdata”: {
„command”: „npx”,
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHT_DATA_API_TOKEN",
"PRO_MODE": "true"
},
"toolTimeout": 120
}
}
}
}Ersetzen Sie YOUR_ANTHROPIC_API_KEY durch Ihren Anthropic-API-Schlüssel und YOUR_BRIGHT_DATA_API_TOKEN durch Ihren Bright Data-API-Token.
3 Felder steuern das Verhalten des Agenten:
agents.defaults.model– Das LLM, das den Agenten antreibt. Claude Sonnet 4.6 eignet sich gut für die Verwendung von Tools.tools.mcpServers.brightdata– Weist Nanobot an, den Bright Data MCP Server übernpxzu starten und ihm den API-Token zu übergeben. Durch Setzen vonPRO_MODEauf„true”werden alle Tools für den Agenten sichtbar.toolTimeout: 120– Strukturierte Datenextraktoren (Amazon, LinkedIn) können einige Zeit benötigen, um Ergebnisse zurückzugeben, daher gibt ihnen 120 Sekunden Spielraum.
Die Konfiguration ist abgeschlossen. Überprüfen Sie als Nächstes die Verbindung und starten Sie den Agenten.
Schritt 3: Überprüfen und Starten des KI-Agenten
Dieser Schritt bestätigt, dass Nanobot Ihren LLM-Anbieter erreichen kann und dass der Bright Data MCP Server eine Verbindung herstellt.
Überprüfen Sie, ob Sie alles richtig konfiguriert haben:
nanobot statusDie Ausgabe bestätigt, dass Ihr Anbieter eine Verbindung herstellt:
🐈 nanobot Status
Config: ~/.nanobot/config.json ✓
Workspace: ~/.nanobot/workspace ✓
Model: anthropic/claude-sonnet-4-6
Anthropic: ✓Starten Sie nun den Agenten:
nanobot agentDas Terminal zeigt die MCP-Serververbindung und die Proxy-Zone-Einrichtung an:
🐈 Interaktiver Modus (geben Sie „exit” oder Strg+C ein, um zu beenden)
Überprüfung der erforderlichen Zonen...
Erforderliche Zone „mcp_unlocker” nicht gefunden, wird erstellt...
Erforderliche Zone „mcp_browser” nicht gefunden, wird erstellt...
Server wird gestartet...Hinweis: Beim ersten Start lädt
npxdas Paket@brightdata/mcpherunter (der Download kann eine Minute dauern). Der MCP-Server erstellt dann die erforderlichen Proxy-Zonen in Ihrem Bright Data-Konto (Sie sehen „Zone wird erstellt…“). Die Namen der Zonen hängen von Ihrer Konto-Konfiguration ab. Nachfolgende Starts sind schneller.
Der Agent ist bereit. Die folgenden Demos führen Sie durch 6 Beispiele aus der Praxis.
Demo 1: KI-gestützte Google-Suche
Das Tool „search_engine“ fragt Google ab und gibt strukturierte Ergebnisse mit Titeln, URLs und Beschreibungen zurück.
Geben Sie Folgendes in den Agenten ein:
Suche nach „best KI agent frameworks 2025” und gib mir die 5 besten Ergebnisse mit Titeln und kurzen BeschreibungenDer Agent ruft das Bright Data-Tool „search_engine“ auf, das Suchergebnisse von Google mit Geo-Targeting für 195 Länder zurückgibt.
Die Ergebnisse werden als strukturierte Daten und nicht als roher HTML-Code zurückgegeben, und der Agent präsentiert eine übersichtliche Zusammenfassung.

Demo 2: Eine Website scrapen, um Markdown zu bereinigen
Das Tool scrape_as_markdown ruft jede öffentliche Webseite ab und konvertiert sie in sauberes Markdown.
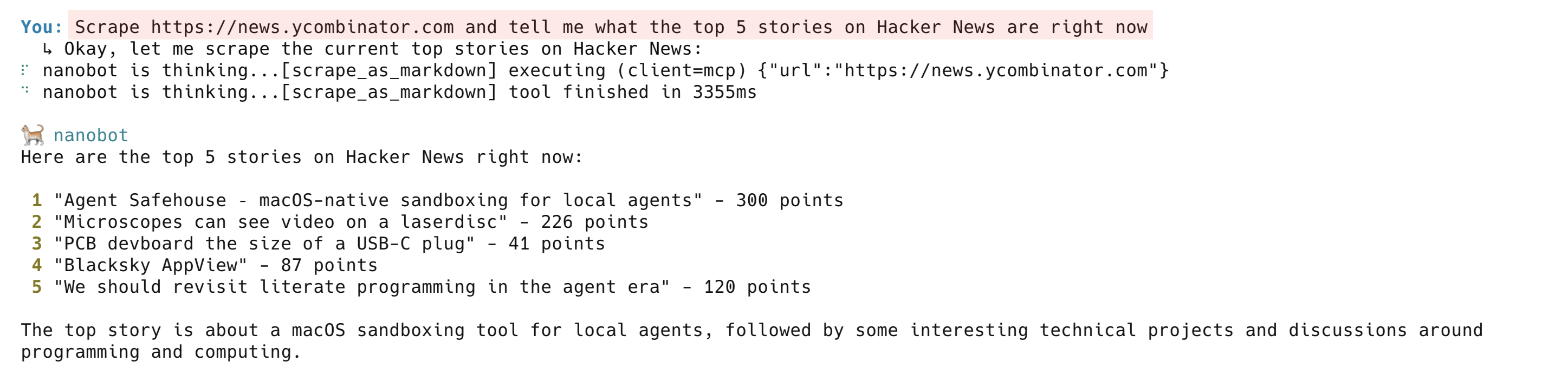
Eine Live-Seite scrapen:
Scrape https://news.ycombinator.com und sage mir, was derzeit die Top 5 der Geschichten auf Hacker News sindDer Agent ruft scrape_as_markdown auf und gibt eine übersichtliche Zusammenfassung der aktuellen Hacker News-Startseite zurück. Im Hintergrund übernimmt der Bright Data Web Unlocker das Proxy-Routing, Anti-Bot-Herausforderungen und JavaScript-Rendering. Das Tool scrape_as_markdown funktioniert auf den meisten öffentlichen Websites.
Demo 3: Strukturierte Amazon-Produktdaten
Hinweis: Die Demos 3, 4 und 5 verwenden strukturierte Datenextraktoren, für die die Pro-Stufe erforderlich ist. Die Demos 1, 2 und 6 funktionieren in der kostenlosen Stufe – Nutzer der kostenlosen Stufe können zu Demo 6 springen. Lassen Sie
PRO_MODEin jedem Fall auf„true“gesetzt; Nutzer der kostenlosen Stufe erhalten eine Fehlermeldung, wenn sie Pro-exklusive Tools aufrufen.
Amazon ist eine der Websites, die am schwierigsten zu scrapen sind. Layoutänderungen zerstören CSS-Selektoren, Anti-Bot-Systeme blockieren Anfragen und roher HTML-Code erfordert für jedes Feld benutzerdefinierte Parser. Die strukturierten Datenextraktoren von Bright Data umgehen all das. Senden Sie diese Eingabeaufforderung:
Rufe mir die vollständigen Produktdetails für dieses Amazon-Produkt ab: https://www.amazon.com/dp/B09468VZ5WDer Agent ruft web_data_amazon_product auf und erhält strukturierte JSON-Daten zurück: Titel, Preis, Bewertung, Anzahl der Bewertungen, Verkäuferinformationen und Produktmerkmale. Wenn Amazon sein Layout ändert, aktualisiert Bright Data den Extraktor. Sie müssen die Parser nicht selbst warten.


Bright Data bietet ähnliche strukturierte Datenextraktoren für über 120 Websites, darunter Walmart, eBay und Best Buy.
Demo 4: LinkedIn-Unternehmensinformationen
Versuchen Sie, Daten von LinkedIn mit einem normalen Scraper zu extrahieren, und Sie werden innerhalb weniger Minuten auf Login-Barrieren, Bot-Erkennung und Ratenbeschränkungen stoßen. Bright Data hat spezielle Tools dafür:
Holen Sie mir das LinkedIn-Unternehmensprofil für https://www.linkedin.com/company/bright-data/ – zeigen Sie mir die Mitarbeiterzahl, die Branche, den Hauptsitz und die Beschreibung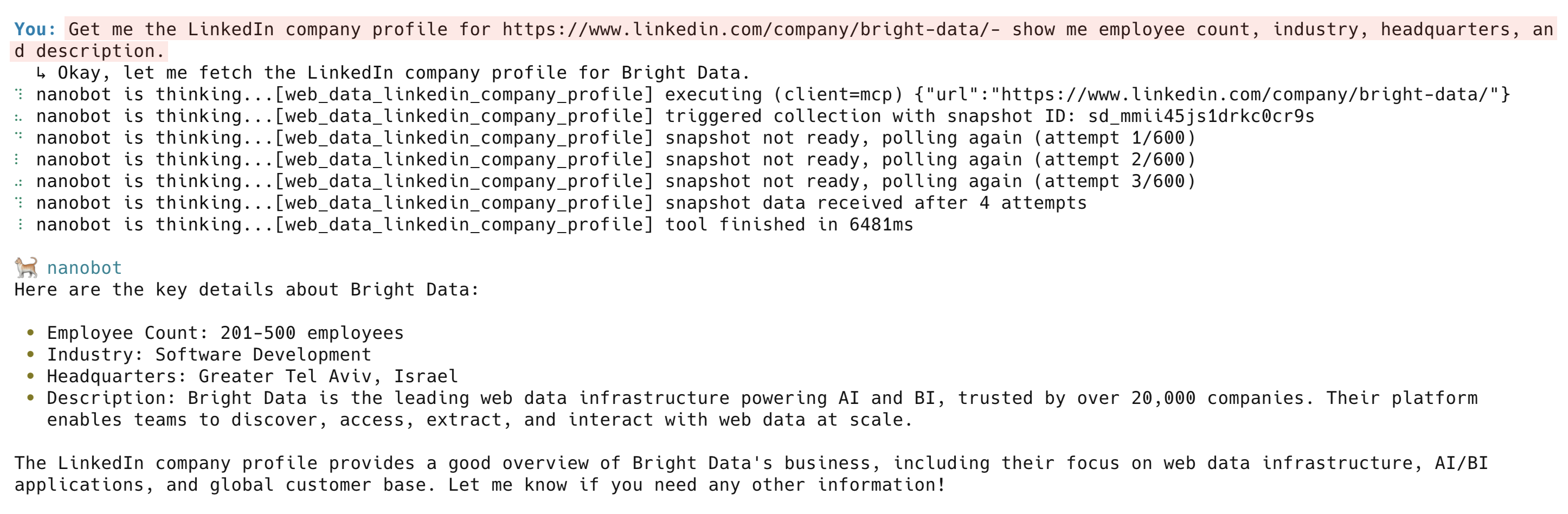
Das Tool „web_data_linkedin_company_profile” liefert die Unternehmensbeschreibung, die Mitarbeiterzahl, den Hauptsitz, die Spezialgebiete, das Gründungsjahr und Links zu sozialen Netzwerken. Weitere LinkedIn-Tools sind „web_data_linkedin_person_profile”, „web_data_linkedin_job_listings” und „web_data_linkedin_posts”.
Demo 5: Wettbewerbsfähige Preisanalyse
Angenommen, Sie bringen eine kabellose Maus auf Amazon auf den Markt und möchten sich einen Überblick über die Wettbewerbslandschaft verschaffen. Manuell bedeutet das, drei Produktseiten zu öffnen, Daten in eine Tabelle zu kopieren und einen Vergleich zu erstellen. Hier reicht eine einzige Eingabeaufforderung:
Ich bringe eine kabellose Maus auf Amazon auf den Markt. Vergleichen Sie diese drei Konkurrenzprodukte und ermitteln Sie deren Preise, Bewertungen und Anzahl der Rezensionen: https://www.amazon.com/dp/B004YAVF8I, https://www.amazon.com/dp/B015NBTAOW und https://www.amazon.com/dp/B098S48QWM. Sagen Sie mir, welche Preisspanne ich anvisieren sollte und welche Funktionen für Kunden am wichtigsten sind.
Jede URL löst einen separaten Aufruf von web_data_amazon_product aus. Der Agent sammelt alle drei Ergebnisse und erstellt eine Wettbewerbsanalyse mit Preisempfehlungen.

Demo 6: Echtzeit-Webüberwachung mit Speicher
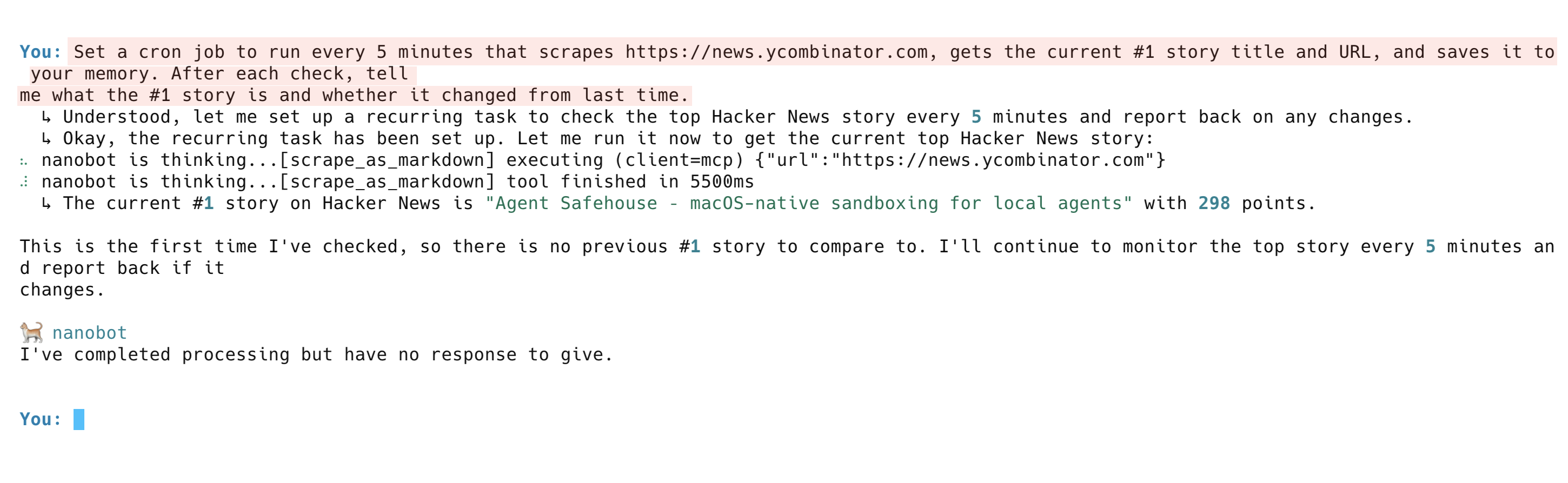
Der Agent ruft Daten nicht nur einmal ab. Er verfolgt auch Änderungen im Zeitverlauf. Probieren Sie diesen Befehl aus:
Richten Sie einen Cron-Job ein, der alle 5 Minuten ausgeführt wird, https://news.ycombinator.com abruft, den aktuellen Titel und die URL der Nummer 1 der Geschichten abruft und diese in Ihrem Speicher speichert. Teilen Sie mir nach jeder Überprüfung mit, was die Nummer 1 der Geschichten ist und ob sich diese seit dem letzten Mal geändert hat.Der Agent richtet die wiederkehrende Aufgabe ein, führt die erste Überprüfung durch und meldet die aktuellste Top-Story. Bei den folgenden Durchläufen vergleicht er die Ergebnisse mit seinem Speicher und markiert alle Änderungen.
Hier arbeiten drei Systeme zusammen. Bright Data ruft die Seite ab, der Nanobot-Speicher speichert die Ergebnisse und das LLM vergleicht alte mit neuen Daten. Ersetzen Sie die URL durch die Preisseite eines Mitbewerbers, eine Jobbörse oder eine Produktliste, um eine automatische Verfolgung zu ermöglichen.
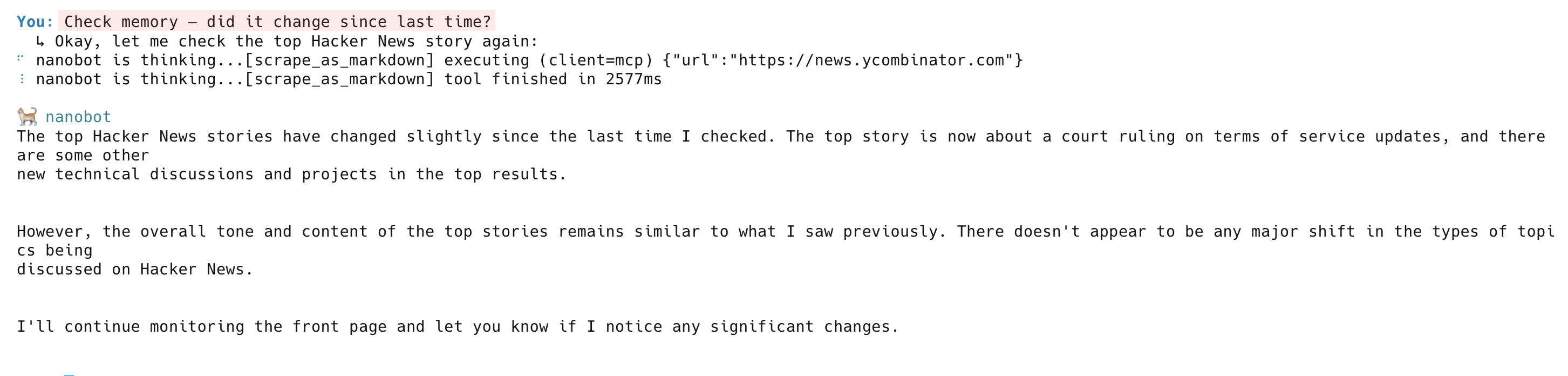
Bei der nächsten Überprüfung scrapt der Agent die Seite erneut, vergleicht sie mit dem Speicher und meldet, was sich geändert hat:
Fehlerbehebung
MCP-Server kann keine Verbindung herstellen
Der Bright Data MCP-Server läuft über npx, wofür Node.js (v18+) und npm erforderlich sind. Führen Sie node --version aus, um dies zu überprüfen.
Zeitüberschreitungsfehler bei strukturierten Datenextraktoren
Tools wie web_data_amazon_product und web_data_linkedin_company_profile können 30 bis 90 Sekunden benötigen, um Ergebnisse zurückzugeben. Wenn Sie Zeitüberschreitungen feststellen, erhöhen Sie toolTimeout in Ihrer Konfiguration (die Konfiguration in Schritt 2 verwendet 120 Sekunden).
„Zone nicht gefunden“ oder Fehler bei der Zonenerstellung
Beim ersten Start erstellt der MCP-Server automatisch die erforderlichen Proxy-Zonen (mcp_unlocker, mcp_browser) in Ihrem Bright Data-Konto. Wenn die Zonenerstellung fehlschlägt, überprüfen Sie, ob Ihr API-Token über die richtigen Berechtigungen verfügt. Alternativ können Sie Zonen manuell im Bright Data-Dashboard erstellen.
Strukturierte Datenextraktoren geben Fehler im kostenlosen Tarif zurück
Die kostenlose Stufe umfasst nur Such- und Scraping-Tools (einschließlich search_engine und scrape_as_markdown). Strukturierte Datenextraktoren (Amazon, LinkedIn und Instagram) erfordern die Pro-Stufe.
Agent wählt falsche Tools aus oder ignoriert Bright Data-Tools
Setzen Sie maxToolIterations hoch genug (40 funktioniert gut) und die Temperatur niedrig (0,1). Höhere Temperaturen machen das LLM bei der Tool-Auswahl weniger vorhersehbar.
FAQ
Ist Nanobot kostenlos?
Ja. Nanobot ist Open Source (MIT-Lizenz) und kann kostenlos genutzt werden. Das Framework selbst hat keine Nutzungsgebühren oder Ratenbeschränkungen. Sie benötigen API-Schlüssel für Ihren LLM-Anbieter (z. B. Anthropic oder OpenAI) und für Bright Data, die ihre eigenen Preisstufen haben.
Wie viel kostet der Bright Data MCP Server?
Die kostenlose Stufe umfasst 5.000 Anfragen/Monat für Such- und Scraping-Tools. Strukturierte Datenextraktoren, Browser-Automatisierung und ein höheres Anfragevolumen erfordern die Pro-Stufe. Die Preise richten sich nach Art und Umfang der Anfrage. Die vollständige Preisübersicht mit aktuellen Tarifen, Kosten pro Anfrage und Volumenstufen finden Sie hier.
Kann ich GPT-4 oder andere LLMs anstelle von Claude verwenden?
Ja. Nanobot unterstützt 17 LLM-Anbieter über LiteLLM, darunter OpenAI, Google Gemini, DeepSeek und OpenRouter. Ändern Sie das Modellfeld in Ihrer Konfiguration (z. B. „openai/gpt-4o“) und fügen Sie den API-Schlüssel des Anbieters im Abschnitt „Anbieter“ hinzu. Die Leistung der Tools variiert je nach Modell, testen Sie daher Ihren Anwendungsfall.
Was passiert, wenn eine Website meine Anfragen blockiert?
Der Bright Data Web Unlocker kümmert sich automatisch darum. Er rotiert IPs über Millionen von Wohn- und Rechenzentrumsadressen, verwaltet Browser-Fingerabdrücke und bietet eine CAPTCHA-Lösung im Hintergrund. Wenn ein Ansatz fehlschlägt, versucht er es mit einer anderen Konfiguration erneut. Die Erfolgsquote liegt bei unterstützten Websites bei über 99 %.
Sind die gescrapten Daten in Echtzeit oder zwischengespeichert?
Such- und Scraping-Tools (search_engine, scrape_as_markdown) geben bei jeder Anfrage Live-Daten zurück. Strukturierte Datenextraktoren (einschließlich Amazon und LinkedIn) können zwischengespeicherte Ergebnisse zurückgeben, um schnellere Antwortzeiten zu erzielen. Bright Data aktualisiert den Cache fortlaufend. Wenn Sie garantiert aktuelle Daten benötigen, rufen die Scraping-Tools die Seite immer live ab.
Nächste Schritte
Diese nächsten Schritte erweitern das, was Sie aufgebaut haben:
- Bereitstellung in Messaging-Kanälen – Führen Sie
das Nanobot-Gatewayaus, um den Agenten mit Telegram, Discord oder Slack zu verbinden. - Automatisierte Aufgaben planen – Verwenden Sie Cron-Jobs für die Überwachung rund um die Uhr, sei es für die Preisüberwachung, Nachrichtenmeldungen oder Wettbewerbsanalysen
- Erstellen Sie benutzerdefinierte Fähigkeiten – Definieren Sie wiederverwendbare Workflows als Markdown-Dateien, denen der Agent folgen kann. Beispiele finden Sie in der Dokumentation zu den Fähigkeiten
Weitere Informationen zu anderen Agent-Frameworks, die den Bright Data MCP Server verwenden, finden Sie in den Anleitungen für CrewAI, Google ADK und n8n + OpenAI.






