

In dieser Anleitung erfahren Sie, wie Sie einen automatisierten News Scraper mit n8n, OpenAI und dem Bright Data MCP Server erstellen. Am Ende dieses Tutorials werden Sie in der Lage sein, die folgenden Aufgaben auszuführen.
- Erstellen einer selbst gehosteten n8n-Instanz
- Gemeinschaftsknoten in n8n installieren
- Erstellen Sie Ihre eigenen Arbeitsabläufe mit n8n
- Integration von KI-Agenten mit OpenAI und n8n
- Verbinden Sie Ihren AI Agent mit Web Unlocker über den MCP Server von Bright Data
- Automatisierte E-Mails mit n8n versenden
Erste Schritte
Um zu beginnen, müssen wir eine selbst gehostete Instanz von n8n starten. Sobald sie läuft, müssen wir einen n8n-Community-Knoten installieren. Außerdem müssen wir API-Schlüssel von OpenAI und Bright Data erhalten, um unseren Scraping-Workflow auszuführen.
Starten von n8n
Erstellen Sie ein neues Speichervolumen für n8n und starten Sie es in einem Docker-Container.
# Create persistent volume
sudo docker volume create n8n_data
# Start self-hosted n8n container with support for unsigned community nodes
sudo docker run -d
--name n8n
-p 5678:5678
-v n8n_data:/home/node/.n8n
-e N8N_BASIC_AUTH_ACTIVE=false
-e N8N_ENCRYPTION_KEY="this_is_my_secure_encryption_key_1234"
-e N8N_ALLOW_LOADING_UNSIGNED_NODES=true
-e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
-e N8N_HOST="0.0.0.0"
-e N8N_PORT=5678
-e WEBHOOK_URL="http://localhost:5678"
n8nio/n8nÖffnen Sie nun http://localhost:5678/ in Ihrem Browser. Sie werden wahrscheinlich aufgefordert, sich anzumelden oder ein Login zu erstellen.

Nachdem Sie eingeloggt sind, gehen Sie zu Ihren Einstellungen und wählen Sie “Community-Knoten”. Klicken Sie dann auf die Schaltfläche “Einen Community-Knoten installieren”.

Geben Sie unter “npm-Paketname” “n8n-nodes-mcp” ein.

API-Schlüssel erhalten
Sie benötigen sowohl einen OpenAI-API-Schlüssel als auch einen Bright Data-API-Schlüssel. Mit dem OpenAI-Schlüssel kann Ihre n8n-Instanz auf LLMs wie GPT-4.1 zugreifen. Mit dem Bright Data-API-Schlüssel kann Ihr LLM auf Echtzeit-Webdaten über den MCP-Server von Bright Data zugreifen.
OpenAI API-Schlüssel
Rufen Sie die OpenAI-Entwicklerplattform auf und erstellen Sie ein Konto, falls Sie dies noch nicht getan haben. Wählen Sie “API-Schlüssel” und klicken Sie dann auf die Schaltfläche “Neuen geheimen Schlüssel erstellen”. Speichern Sie den Schlüssel an einem sicheren Ort.

Bright Data API-Schlüssel
Möglicherweise haben Sie bereits ein Konto bei Bright Data. In diesem Fall sollten Sie eine neue Web Unlocker-Zone erstellen. Wählen Sie im Bright Data-Dashboard die Option “Proxies und Scraping” und klicken Sie auf die Schaltfläche “Hinzufügen”.

Sie können auch andere Zonennamen verwenden, aber wir empfehlen Ihnen dringend, diese Zone “mcp_unlocker” zu nennen. Dieser Name ermöglicht die Zusammenarbeit mit unserem MCP-Server so gut wie von Anfang an.
Kopieren Sie in Ihren Kontoeinstellungen Ihren API-Schlüssel, und bewahren Sie ihn an einem sicheren Ort auf. Dieser Schlüssel ermöglicht den Zugriff auf alle Ihre Bright Data-Services.
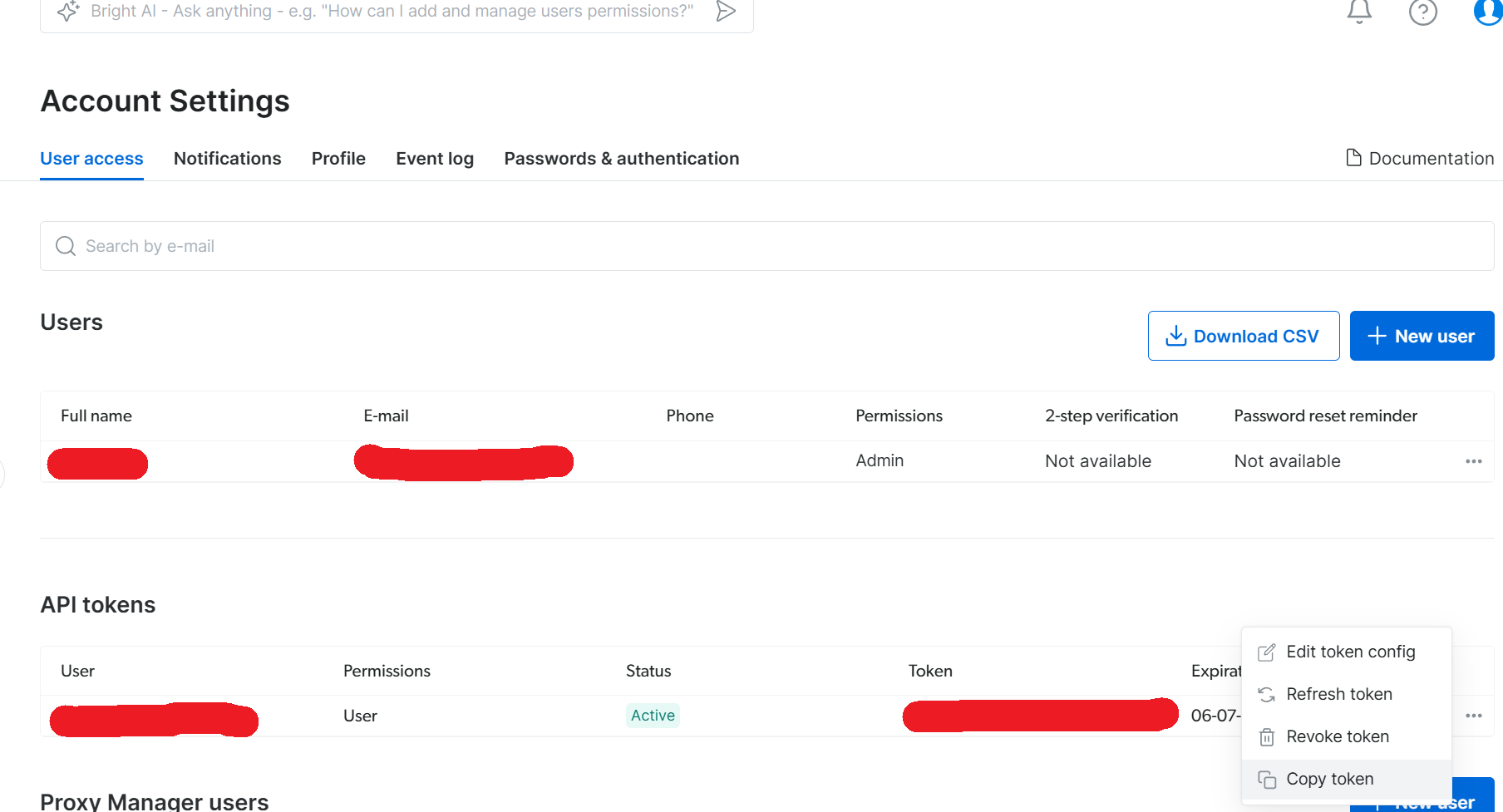
Jetzt, da wir eine selbst gehostete n8n-Instanz und die richtigen Anmeldedaten haben, ist es an der Zeit, unseren Workflow zu erstellen.
Aufbau des Arbeitsablaufs
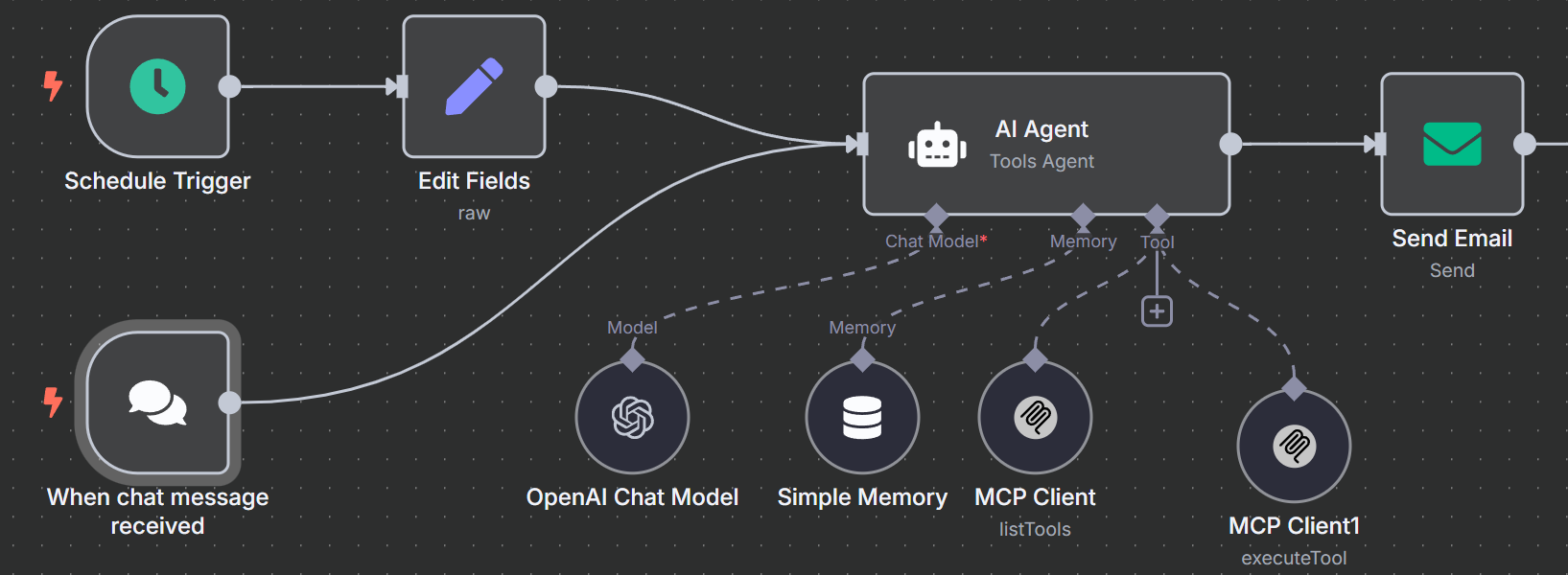
Nun werden wir unseren eigentlichen Arbeitsablauf erstellen. Klicken Sie auf die Schaltfläche “Einen neuen Arbeitsablauf erstellen”. Jetzt haben Sie eine leere Leinwand, mit der Sie arbeiten können.
1. Erstellen unseres Auslösers

Wir beginnen mit der Erstellung eines neuen Knotens. Geben Sie in der Suchleiste “Chat” ein und wählen Sie dann den Knoten “Chat-Trigger”.

Der Chat-Trigger wird nicht unser ständiger Auslöser sein, aber er erleichtert die Fehlersuche erheblich. Unser KI-Agent wird eine Eingabeaufforderung entgegennehmen. Mit dem Chat-Trigger-Knoten können Sie ganz einfach verschiedene Prompts ausprobieren, ohne Ihre Knoten bearbeiten zu müssen.
2. Hinzufügen unseres Agenten

Als nächstes müssen wir unseren Auslöseknoten mit einem KI-Agenten verbinden. Fügen Sie einen weiteren Knoten hinzu und geben Sie “ai agent” in die Suchleiste ein. Wählen Sie den KI-Agent-Knoten aus.

Dieser KI-Agent enthält im Grunde unsere gesamte Laufzeit. Der Agent erhält eine Eingabeaufforderung und führt dann unsere Scraping-Logik aus. Sie können unsere Aufforderung unten lesen. Sie können sie nach eigenem Ermessen anpassen – deshalb haben wir den Chat-Trigger hinzugefügt. Das folgende Snippet enthält die Eingabeaufforderung, die wir für diesen Workflow verwenden werden.
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.3. Verbinden eines Modells

Klicken Sie auf das “+” unter “Chat-Modell” und geben Sie “openai” in die Suchleiste ein. Wählen Sie das OpenAI-Chat-Modell aus.

Wenn Sie aufgefordert werden, Anmeldeinformationen hinzuzufügen, fügen Sie Ihren OpenAI-API-Schlüssel hinzu und speichern Sie die Anmeldeinformationen.

Als nächstes müssen wir ein Modell auswählen. Sie können aus einer Vielzahl von Modellen wählen, aber bedenken Sie, dass dies ein komplexer Arbeitsablauf für einen einzelnen Agenten ist. Mit GPT-4o hatten wir nur begrenzten Erfolg. GPT-4.1-Nano und GPT-4.1-Mini erwiesen sich beide als unzureichend. Das vollständige GPT-4.1-Modell ist zwar teurer, erwies sich aber als unglaublich kompetent – deshalb haben wir uns für dieses Modell entschieden.

4. Hinzufügen von Speicher

Um Kontextfenster zu verwalten, müssen wir Speicher hinzufügen. Wir brauchen nichts Komplexes. Wir brauchen nur einen einfachen Speicher, damit sich unser Modell über mehrere Schritte hinweg merken kann, was es gerade tut.
Wählen Sie die Option “Einfacher Speicher”, um Ihrem Modell einen Speicher zu geben.

5. Verbinden mit dem MCP von Bright Data

Um das Web zu durchsuchen, muss unser Modell eine Verbindung mit dem MCP-Server von Bright Data herstellen. Klicken Sie auf das “+” unter “Tool” und wählen Sie den MCP-Client, der oben im Abschnitt “Andere Tools” angezeigt wird.
Wenn Sie dazu aufgefordert werden, geben Sie Ihre Anmeldeinformationen für den Bright Data MCP-Server ein. Geben Sie in das Feld “Befehl” den Befehl npx ein. Dadurch kann NodeJS automatisch unseren MCP-Server erstellen und ausführen. Fügen Sie unter “Argumente” @brightdata/mcp hinzu. Geben Sie unter “Umgebungen” API_TOKEN=YOUR_BRIGHT_DATA_API_KEY ein (ersetzen Sie dies durch Ihren tatsächlichen Schlüssel).

Die Standardmethode für dieses Werkzeug ist “List Tools”. Das ist genau das, was wir tun müssen. Wenn Ihr Modell eine Verbindung herstellen kann, wird es den MCP-Server anpingen und die ihm zur Verfügung stehenden Werkzeuge auflisten.

Sobald Sie bereit sind, geben Sie eine Aufforderung in den Chat ein. Verwenden Sie eine einfache Aufforderung zur Auflistung der verfügbaren Werkzeuge.
List the tools available to youSie sollten eine Antwort erhalten, in der die für das Modell verfügbaren Werkzeuge aufgelistet sind. Wenn dies der Fall ist, sind Sie mit dem MCP-Server verbunden. Der unten stehende Ausschnitt enthält nur einen Teil der Antwort. Insgesamt sind 21 Werkzeuge für das Modell verfügbar.
Here are the tools available to me:
1. search_engine – Search Google, Bing, or Yandex and return results in markdown (URL, title, description).
2. scrape_as_markdown – Scrape any webpage and return results as Markdown.
3. scrape_as_html – Scrape any webpage and return results as HTML.
4. session_stats – Show the usage statistics for tools in this session.
5. web_data_amazon_product – Retrieve structured Amazon product data (using a product URL).6. Hinzufügen der Scraping-Tools

Klicken Sie erneut auf das “+” unter “Tool”. Wählen Sie erneut das gleiche “MCP Client Tool” aus dem Abschnitt “Andere Tools”.

Stellen Sie dieses Mal das Werkzeug auf “Werkzeug ausführen” ein.

Fügen Sie unter “Tool Name” den folgenden JavaScript-Ausdruck ein. Wir rufen die Funktion “fromAI” auf und geben den Toolnamen, die Beschreibung und den Datentyp ein.
{{ $fromAI("toolname", "the most applicable tool required to be executed as specified by the users request and list of tools available", "string") }}Fügen Sie unter den Parametern den folgenden Block hinzu. Er gibt eine Abfrage an das Modell neben Ihrer bevorzugten Suchmaschine.
{
"query": "Return the top 5 world news headlines and their links."
,
"engine": "google"
}Passen Sie nun die Parameter für den KI-Agenten selbst an. Fügen Sie die folgende Systemmeldung hinzu.
You are an expert web scraping assistant with access to Bright Data's Web Unlocker API. This gives you the ability to execute a specific set of actions. When using tools, you must share across the exact name of the tool for it to be executed.
For example, "Search Engine Scraping" should be "search_engine"
Bevor wir den Scraper tatsächlich ausführen, müssen wir die Wiederholungsversuche aktivieren. KI-Agenten sind intelligent, aber sie sind nicht perfekt. Aufträge schlagen manchmal fehl und müssen behandelt werden. Genau wie bei manuell programmierten Scrapers ist die Wiederholungslogik nicht optional, wenn Sie ein Produkt wollen, das konsistent funktioniert.

Führen Sie die folgende Eingabeaufforderung aus.
Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite.Wenn alles funktioniert, sollten Sie eine ähnliche Antwort wie die folgende erhalten.
Here are real global news headlines for today, each with a direct source link:
1. Reuters
Headline: Houthi ceasefire followed US intel showing militants sought off-ramp
Source: https://www.reuters.com/world/
2. CNN
Headline: UK police arrest man for arson after fire at PM Starmer's house
Source: https://www.cnn.com/world
3. BBC
Headline: Uruguay's José Mujica, world's 'poorest president', dies
Source: https://www.bbc.com/news/world
4. AP News
Headline: Israel-Hamas war, Russia-Ukraine War, China, Asia Pacific, Latin America, Europe, Africa (multiple global crises)
Source: https://apnews.com/world-news
5. The Guardian
Headline: Fowl play: flying duck caught in Swiss speed trap believed to be repeat offender
Source: https://www.theguardian.com/world
These headlines were selected from the main headlines of each trusted global news outlet’s world section as of today.7. Der Anfang und das Ende

Nun, da unser KI-Agent seine Aufgabe erfüllt, müssen wir den Anfang und das Ende des Arbeitsablaufs hinzufügen. Unser News Scraper sollte mit einem Scheduler arbeiten, nicht mit einer individuellen Eingabeaufforderung. Schließlich sollte unsere Ausgabe eine E-Mail über SMTP senden.
Hinzufügen des richtigen Auslösers
Suchen Sie nach dem Knoten “Zeitplanauslöser” und fügen Sie ihn zu Ihrem Workflow hinzu.

Stellen Sie ihn so ein, dass er zu der von Ihnen gewünschten Zeit ausgelöst wird. Wir haben 9:00 Uhr morgens gewählt.

Nun müssen wir unserer Auslöserlogik einen weiteren Knoten hinzufügen. Dieser Knoten wird eine Dummy-Eingabeaufforderung in unser Chat-Modell einfügen.
Fügen Sie den Knoten “Felder bearbeiten” zu Ihrem Zeitplanauslöser hinzu.

Fügen Sie dem Knoten “Felder bearbeiten” das Folgende als JSON hinzu. “sessionId” ist nur ein Dummy-Wert – Sie können keinen Chat ohne eine sessionId starten. “chatInput” enthält die Eingabeaufforderung, die wir in den LLM injizieren.
{
"sessionId": "google",
"chatInput": "Get the global news for the day. Use whichever sites and tools available to make it happen. When finished, cite your sources with direct links. I'd like a real headline from each page you cite."
}Verbinden Sie schließlich diese neuen Schritte mit Ihrem KI-Agenten. Ihr Agent kann nun durch den Planer ausgelöst werden.

Ausgabe der Ergebnisse per E-Mail
Klicken Sie auf das “+” auf der rechten Seite Ihres AI Agent-Knotens. Fügen Sie den Knoten “E-Mail senden” an das Ende Ihres Workflows an. Fügen Sie Ihre SMTP-Anmeldeinformationen hinzu und verwenden Sie dann die Parameter, um die E-Mail anzupassen.

Die E-Mail
Sie können nun auf die Schaltfläche “Workflow testen” klicken. Wenn der Workflow erfolgreich läuft, erhalten Sie eine E-Mail mit allen aktuellen Schlagzeilen. GPT-4.1

Wir gehen noch einen Schritt weiter: Scraping aktueller Websites
In seinem derzeitigen Zustand findet unser KI-Agent Schlagzeilen aus Google News mit Hilfe des Suchmaschinen-Tools des MCP-Servers. Wenn nur eine Suchmaschine verwendet wird, können die Ergebnisse uneinheitlich sein. Manchmal findet der KI-Agent echte Schlagzeilen. In anderen Fällen sieht er nur die Metadaten der Website – “Holen Sie sich die neuesten Schlagzeilen von CNN!
Anstatt unsere Extraktion auf das Suchmaschinentool zu beschränken, sollten wir ein Scraping-Tool hinzufügen. Fügen Sie zunächst ein weiteres Tool zu Ihrem Workflow hinzu. Sie sollten nun drei MCP-Clients an Ihren AI-Agenten angeschlossen haben, wie Sie in der Abbildung unten sehen.
Hinzufügen von Scraping-Tools

Nun müssen wir die Einstellungen und Parameter für dieses neue Werkzeug öffnen. Beachten Sie, dass wir die Werkzeugbeschreibung dieses Mal manuell einstellen. Wir tun dies, damit der Agent nicht verwirrt wird.
In unserer Beschreibung teilen wir dem KI-Agenten mit, dass er dieses Tool zum Scrapen von URLs verwenden soll. Unser Tool-Name ist ähnlich wie der, den wir zuvor erstellt haben.
{{ $fromAI("toolname", "the most applicable scraping tool required to be executed as specified by the users request and list of tools available", "string") }}In unseren Parametern geben wir eine URL anstelle einer Abfrage oder Suchmaschine an.
{
"url": "{{$fromAI('URL', 'url that the user would like to scrape', 'string')}}"
}Anpassen der anderen Knoten und Werkzeuge
Das Suchmaschinentool
Bei unserem Scraping-Tool legen wir die Beschreibung manuell fest, damit der KI-Agent nicht durcheinander kommt. Wir werden auch das Suchmaschinentool anpassen. Die Änderungen sind nicht sehr umfangreich, wir weisen den Agenten nur manuell an, das Suchmaschinentool zu verwenden, wenn wir diesen MCP-Client ausführen.

Felder bearbeiten: Die Dummy-Eingabeaufforderung
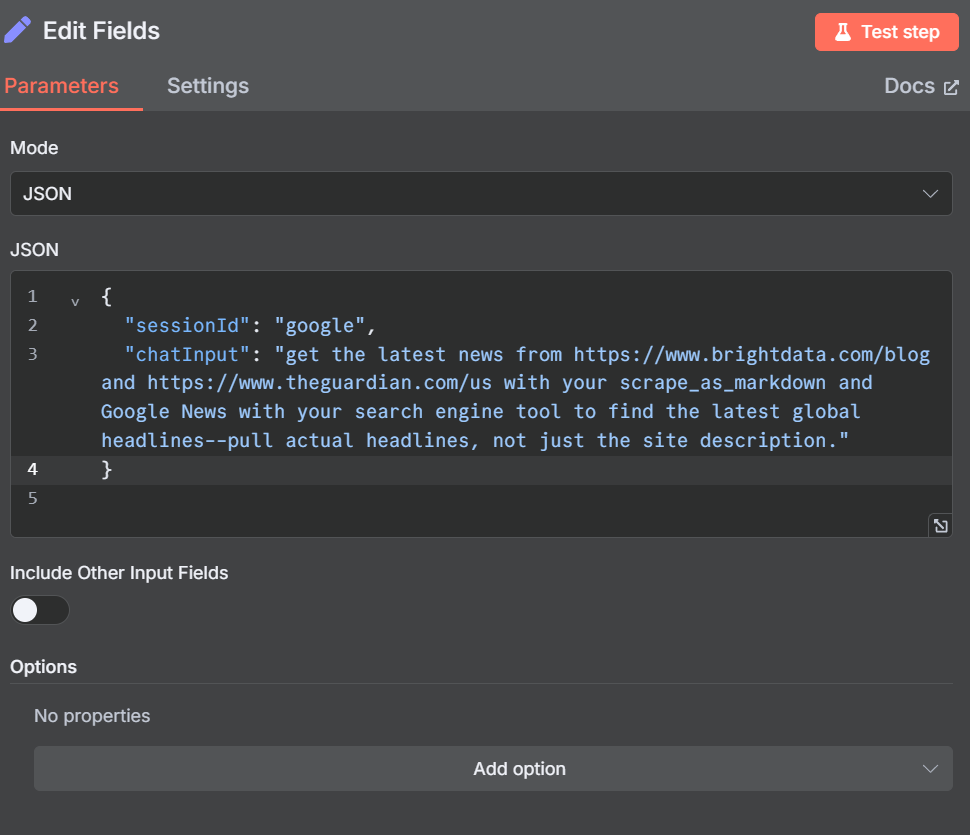
Öffnen Sie den Knoten Felder bearbeiten und passen Sie unsere Dummy-Eingabeaufforderung an.
{
"sessionId": "google",
"chatInput": "get the latest news from https://www.brightdata.com/blog and https://www.theguardian.com/us with your scrape_as_markdown and Google News with your search engine tool to find the latest global headlines--pull actual headlines, not just the site description."
}Ihre Parameter sollten wie in der folgenden Abbildung aussehen.
Ursprünglich hatten wir Reddit anstelle von The Guardian verwendet. Die LLMs von OpenAI befolgen jedoch die robots.txt-Datei. Obwohl Reddit leicht zu scrapen ist, weigert sich der KI-Agent, dies zu tun.

Der neu kuratierte Feed
Durch die Hinzufügung eines weiteren Tools haben wir unseren KI-Agenten in die Lage versetzt, tatsächlich Websites zu scrapen, nicht nur Suchmaschinenergebnisse. Werfen Sie einen Blick auf die folgende E-Mail. Sie hat ein viel übersichtlicheres Format mit einer sehr detaillierten Aufschlüsselung der Nachrichten aus jeder Quelle.

Schlussfolgerung
Durch die Kombination von n8n, OpenAI und dem Model Context Protocol (MCP) Server von Bright Data können Sie das Scraping und die Bereitstellung von Nachrichten mit leistungsstarken, KI-gesteuerten Workflows automatisieren. MCP erleichtert den Zugriff auf aktuelle, strukturierte Webdaten in Echtzeit und ermöglicht es Ihren KI-Agenten, präzise Inhalte aus jeder beliebigen Quelle zu beziehen. Im Zuge der Weiterentwicklung der KI-Automatisierung werden Tools wie MCP von Bright Data für eine effiziente, skalierbare und zuverlässige Datenerfassung unverzichtbar sein.
Bright Data empfiehlt Ihnen, unseren Artikel über Web Scraping mit MCP-Servern zu lesen. Melden Sie sich jetzt an, um Ihr kostenloses Guthaben zum Testen unserer Produkte zu erhalten.






