

In diesem Leitfaden zeigen wir Ihnen, wie Sie einen lokalen MCP-Server in Python erstellen, um Amazon-Produktdaten bei Bedarf abzurufen. Sie lernen die Grundlagen von MCP, wie Sie Ihren eigenen Server schreiben und betreiben und wie Sie ihn mit Entwickler-Tools wie Claude Desktop und Cursor IDE verbinden. Den Abschluss bildet eine praktische Bright Data MCP-Integration für KI-fähige Webdaten in Echtzeit.
Lassen Sie uns eintauchen.
Der Engpass: Warum LLMs mit der Interaktion in der realen Welt zu kämpfen haben (und wie MCP das Problem löst)
Große Sprachmodelle (Large Language Models, LLMs) sind unglaublich leistungsfähig bei der Verarbeitung und Generierung von Text aus umfangreichen Trainingsdatensätzen. Aber sie haben eine entscheidende Einschränkung: Sie können nicht nativ mit der realen Welt interagieren. Das bedeutet, dass kein Zugriff auf lokale Dateien möglich ist, keine benutzerdefinierten Skripte ausgeführt werden können und keine Live-Daten aus dem Internet abgerufen werden können.
Ein einfaches Beispiel: Bitten Sie Claude, Produktdetails von einer Amazon-Seite abzurufen, und es wird nicht dazu in der Lage sein. Warum nicht? Weil er nicht über die integrierte Fähigkeit verfügt, das Web zu durchsuchen oder externe Aktionen auszulösen.

Ohne externe Tools können LLMs keine praktischen Aufgaben ausführen, die auf Echtzeitdaten oder die Integration mit externen Systemen angewiesen sind.
An dieser Stelle kommt das Model Context Protocol (MCP) von Anthropic ins Spiel. Es ermöglicht LLMs, mit externen Tools wie Scrapern, APIs oder Skripten auf sichere und standardisierte Weise zu kommunizieren.
Hier sehen Sie den Unterschied in Aktion. Nach der Integration eines benutzerdefinierten MCP-Servers waren wir in der Lage, strukturierte Amazon-Produktdaten direkt über Claude zu extrahieren:

Machen Sie sich noch keine Gedanken darüber, wie es funktioniert – wir werden später im Leitfaden alles Schritt für Schritt durchgehen.
Warum ist MCP wichtig?
- Standardisierung: MCP bietet eine standardisierte Schnittstelle für LLM-basierte Systeme zur Verbindung mit externen Tools und Daten – ähnlich wie APIs Web-Integrationen standardisieren. Dadurch wird der Bedarf an benutzerdefinierten Integrationen drastisch reduziert und die Entwicklung beschleunigt.
- Flexibilität und Skalierbarkeit: Entwickler können LLMs oder Hosting-Plattformen austauschen, ohne Tool-Integrationen neu schreiben zu müssen. MCP unterstützt mehrere Kommunikationstransporte (z. B.
stdio), wodurch es an verschiedene Setups angepasst werden kann. - Verbesserte LLM-Fähigkeiten: Durch die Verbindung von LLMs mit Live-Daten und externen Tools ermöglicht MCP ihnen, über statische Antworten hinauszugehen. Sie können nun aktuelle, relevante Informationen zurückgeben und kontextabhängige Aktionen auslösen.
Analogie: Stellen Sie sich MCP als eine USB-Schnittstelle für LLMs vor. Genauso wie über USB verschiedene Geräte (Tastaturen, Drucker, externe Laufwerke) an jeden kompatiblen Rechner angeschlossen werden können, ohne dass spezielle Treiber erforderlich sind, ermöglicht MCP den Anschluss von LLMs an eine breite Palette von Werkzeugen über ein standardisiertes Protokoll, ohne dass jedes Mal eine individuelle Integration erforderlich ist.
Was ist das Model Context Protocol (MCP)?
Model Context Protocol (MCP) ist ein von Anthropic entwickelter offener Standard, der es großen Sprachmodellen (LLMs) ermöglicht, mit externen Tools, APIs und Datenquellen auf konsistente und sichere Weise zu interagieren. Es fungiert als universeller Konnektor, der es LLMs ermöglicht, reale Aufgaben wie das Scrapen von Websites, das Abfragen von Datenbanken oder das Auslösen von Skripten auszuführen.
MCP wurde zwar von Anthropic eingeführt, ist aber offen und erweiterbar, d. h. jeder kann den Standard implementieren oder zu ihm beitragen. Wenn Sie mit Retrieval-Augmented Generation (RAG) gearbeitet haben, werden Sie das Konzept zu schätzen wissen. MCP baut auf dieser Idee auf, indem es die Interaktionen über eine leichtgewichtige JSON-RPC-Schnittstelle standardisiert, so dass Modelle auf Live-Daten zugreifen und Maßnahmen ergreifen können.
MCP-Architektur: Wie sie funktioniert
Im Kern standardisiert MCP die Kommunikation zwischen einem KI-Modell und den externen Fähigkeiten.
Kerngedanke: Eine standardisierte Schnittstelle (in der Regel JSON-RPC 2.0 über Transporte wie stdio) ermöglicht es einem LLM (über einen Client), von externen Servern bereitgestellte Tools zu erkennen und aufzurufen.
MCP arbeitet mit einer Client-Server-Architektur mit drei Hauptkomponenten:
- MCP-Host: Die Umgebung oder Anwendung, die Interaktionen zwischen dem LLM und externen Tools initiiert und verwaltet. Beispiele sind KI-Assistenten wie Claude Desktop oder IDEs wie Cursor.
- MCP-Client: Eine Komponente innerhalb des Hosts, die Verbindungen mit MCP-Servern herstellt und aufrechterhält, die Kommunikationsprotokolle handhabt und den Datenaustausch verwaltet.
- MCP-Server: Ein Programm (das von uns Entwicklern erstellt wird), das das MCP-Protokoll implementiert und einen bestimmten Satz von Funktionen zur Verfügung stellt. Ein MCP-Server kann eine Schnittstelle zu einer Datenbank, einem Webdienst oder, in unserem Fall, einer Website (Amazon) bilden. Server stellen ihre Funktionalität auf standardisierte Weise zur Verfügung
: Polylang-Platzhalter nicht ändern
Hier ist das Diagramm der MCP-Architektur:

Bildquelle: Model Context Protocol
Bei dieser Konfiguration erzeugt der Host (Claude Desktop oder Cursor IDE) einen MCP-Client, der dann eine Verbindung zu einem externen MCP-Server herstellt. Dieser Server stellt Werkzeuge, Ressourcen und Eingabeaufforderungen zur Verfügung, mit denen die KI je nach Bedarf interagieren kann.
Kurz gesagt, funktioniert der Arbeitsablauf folgendermaßen:
- Der Benutzer sendet eine Nachricht wie “Produktinformation von diesem Amazon-Link abrufen”.
- Der MCP-Client sucht nach einem registrierten Tool, das diese Aufgabe übernehmen kann
- Der Client sendet eine strukturierte Anfrage an den MCP-Server
- Der MCP-Server führt die entsprechende Aktion aus (z. B. das Starten eines Headless-Browsers)
- Der Server sendet strukturierte Ergebnisse an den MCP-Client
- Der Client leitet die Ergebnisse an den LLM weiter, der sie dem Nutzer präsentiert
Erstellen eines benutzerdefinierten MCP-Servers
Lassen Sie uns einen Python-MCP-Server zum Scrapen von Amazon-Produktseiten bauen.

Dieser Server stellt zwei Tools zur Verfügung: eines zum Herunterladen von HTML und ein weiteres zum Extrahieren strukturierter Informationen. Sie werden mit dem Server über einen LLM-Client in Cursor oder Claude Desktop interagieren.
Schritt 1: Einrichten der Umgebung
Stellen Sie zunächst sicher, dass Sie Python 3 installiert haben. Erstellen und aktivieren Sie dann eine virtuelle Umgebung:
python -m venv mcp-amazon-scraper
# On macOS/Linux:
source mcp-amazon-scraper/bin/activate
# On Windows:
.mcp-amazon-scraperScriptsactivateInstallieren Sie die erforderlichen Bibliotheken: das MCP Python SDK, Playwright und LXML.
pip install mcp playwright lxml
# Install browser binaries for Playwright
python -m playwright installDies installiert:
- mcp: Python SDK für Model Context Protocol Server und Clients, das alle Details der JSON-RPC-Kommunikation behandelt
- playwright: Browser-Automatisierungsbibliothek, die Headless-Browser-Funktionen für das Rendering und Scraping von JavaScript-lastigen Websites bietet
- lxml: Schnelle XML/HTML-Parsing-Bibliothek, die das Extrahieren spezifischer Datenelemente aus Webseiten mittels XPath-Abfragen erleichtert
Kurz gesagt, das MCP Python SDK(mcp) kümmert sich um alle Protokolldetails und ermöglicht es Ihnen, Tools bereitzustellen, die Claude oder Cursor über natürlichsprachliche Eingabeaufforderungen aufrufen können. Playwright ermöglicht es uns, Webseiten vollständig zu rendern (einschließlich JavaScript-Inhalte), und lxml bietet uns leistungsstarke HTML-Parsing-Funktionen.
Schritt 2: Initialisieren des MCP-Servers
Erstellen Sie eine Python-Datei namens amazon_scraper_mcp.py. Beginnen Sie mit dem Importieren der notwendigen Module und der Initialisierung des FastMCP-Servers:
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")Dadurch wird eine Instanz des MCP-Servers erstellt. Jetzt fügen wir ihm Werkzeuge hinzu.
Schritt 3: Implementierung des Tools fetch_page
Dieses Tool nimmt eine URL als Eingabe, verwendet Playwright, um zu der Seite zu navigieren, wartet, bis der Inhalt geladen ist, lädt den HTML-Code herunter und speichert ihn in unserer temporären Datei.
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_messageDiese asynchrone Funktion verwendet Playwright, um potenzielles JavaScript-Rendering auf Amazon-Seiten zu verarbeiten. Der @mcp.tool() -Dekorator registriert diese Funktion als ein aufrufbares Tool innerhalb unseres Servers.
Schritt 4: Implementierung des Tools extract_info
Dieses Tool liest die von fetch_page gespeicherte HTML-Datei, parst sie mithilfe von LXML- und XPath-Selektoren und gibt ein Wörterbuch mit den extrahierten Produktdetails zurück.
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}Diese Funktion verwendet LXML’s fromstring, um den HTML-Code zu parsen und robuste XPath-Selektoren, um die gewünschten Elemente zu finden
Schritt 5: Starten Sie den Server
Fügen Sie schließlich die folgenden Zeilen am Ende Ihres amazon_scraper_mcp.py-Skripts hinzu, um den Server über den stdio-Transportmechanismus zu starten, der Standard für lokale MCP-Server ist, die mit Clients wie Claude Desktop oder Cursor kommunizieren.
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")Vollständiger Code(amazon_scraper_mcp.py)
import os
import asyncio
from lxml import html as lxml_html
from mcp.server.fastmcp import FastMCP
from playwright.async_api import async_playwright
# Define a temporary file path for the HTML content
HTML_FILE = os.path.join(os.getenv("TMPDIR", "/tmp"), "amazon_product_page.html")
# Initialize the MCP server with a descriptive name
mcp = FastMCP("Amazon Product Scraper")
print("MCP Server Initialized: Amazon Product Scraper")
@mcp.tool()
async def fetch_page(url: str) -> str:
"""
Fetches the HTML content of the given Amazon product URL using Playwright
and saves it to a temporary file. Returns a status message.
"""
print(f"Executing fetch_page for URL: {url}")
try:
async with async_playwright() as p:
# Launch headless Chromium browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the URL with a generous timeout
await page.goto(url, timeout=90000, wait_until="domcontentloaded")
# Wait for a key element (e.g., body) to ensure basic loading
await page.wait_for_selector("body", timeout=30000)
# Add a small delay for any dynamic content rendering via JavaScript
await asyncio.sleep(5)
html_content = await page.content()
with open(HTML_FILE, "w", encoding="utf-8") as f:
f.write(html_content)
await browser.close()
print(f"Successfully fetched and saved HTML to {HTML_FILE}")
return f"HTML content for {url} downloaded and saved successfully to {HTML_FILE}."
except Exception as e:
error_message = f"Error fetching page {url}: {str(e)}"
print(error_message)
return error_message
def _extract_xpath(tree, xpath, default="N/A"):
"""Helper function to extract text using XPath, returning default if not found."""
try:
# Use text_content() to get text from node and children, strip whitespace
result = tree.xpath(xpath)
if result:
return result[0].text_content().strip()
return default
except Exception:
return default
def _extract_price(price_str):
"""Helper function to parse price string into a float."""
if price_str == "N/A":
return None
try:
# Remove currency symbols and commas, handle potential whitespace
cleaned_price = "".join(filter(str.isdigit or str.__eq__("."), price_str))
return float(cleaned_price)
except (ValueError, TypeError):
return None
@mcp.tool()
def extract_info() -> dict:
"""
Parses the saved HTML file (downloaded by fetch_page) to extract
Amazon product details like title, price, rating, features, etc.
Returns a dictionary of the extracted data.
"""
print(f"Executing extract_info from file: {HTML_FILE}")
if not os.path.exists(HTML_FILE):
return {
"error": f"HTML file not found at {HTML_FILE}. Please run fetch_page first."
}
try:
with open(HTML_FILE, "r", encoding="utf-8") as f:
page_html = f.read()
tree = lxml_html.fromstring(page_html)
# --- XPath Selectors for Amazon Product Details ---
title = _extract_xpath(tree, '//span[@id="productTitle"]')
# Handle different price structures (main price, sale price)
price_whole = _extract_xpath(tree, '//span[contains(@class, "a-price-whole")]')
price_fraction = _extract_xpath(
tree, '//span[contains(@class, "a-price-fraction")]'
)
price_str = (
f"{price_whole}.{price_fraction}"
if price_whole != "N/A"
else _extract_xpath(tree, '//span[contains(@class,"a-offscreen")]')
) # Fallback to offscreen if needed
price = _extract_price(price_str)
# Original price (strike-through)
original_price_str = _extract_xpath(
tree, '//span[@class="a-price a-text-price"]//span[@class="a-offscreen"]'
)
original_price = _extract_price(original_price_str)
# Rating
rating_text = _extract_xpath(tree, '//span[@id="acrPopover"]/@title')
rating = None
if rating_text != "N/A":
try:
rating = float(rating_text.split()[0])
except (ValueError, IndexError):
rating = None
# Review Count
reviews_text = _extract_xpath(tree, '//span[@id="acrCustomerReviewText"]')
review_count = None
if reviews_text != "N/A":
try:
review_count = int(reviews_text.split()[0].replace(",", ""))
except (ValueError, IndexError):
review_count = None
# Availability
availability = _extract_xpath(
tree,
'//div[@id="availability"]//span/text()',
)
# Features (bullet points)
feature_elements = tree.xpath(
'//div[@id="feature-bullets"]//li//span[@class="a-list-item"]'
)
features = [
elem.text_content().strip()
for elem in feature_elements
if elem.text_content().strip()
]
# Calculate Discount
discount = None
if price and original_price and original_price > price:
discount = round(((original_price - price) / original_price) * 100)
extracted_data = {
"title": title,
"price": price,
"original_price": original_price,
"discount_percent": discount,
"rating_stars": rating,
"review_count": review_count,
"features": features,
"availability": availability.strip(),
}
print(f"Successfully extracted data: {extracted_data}")
return extracted_data
except Exception as e:
error_message = f"Error parsing HTML: {str(e)}"
print(error_message) # Added for logging
return {"error": error_message}
if __name__ == "__main__":
print("Starting MCP Server with stdio transport...")
# Run the server, listening via standard input/output
mcp.run(transport="stdio")Integrieren Ihres benutzerdefinierten MCP-Servers
Nachdem das Serverskript nun fertig ist, können wir es mit MCP-Clients wie Claude Desktop und Cursor verbinden.
Verbinden mit Claude Desktop
Schritt 1: Öffnen Sie Claude Desktop.
Schritt 2: Navigieren Sie zu Einstellungen -> Entwickler -> Konfig bearbeiten. Dadurch wird die Datei claude_desktop_config.json in Ihrem Standardtexteditor geöffnet.

Schritt 3: Fügen Sie einen Eintrag für Ihren Server unter dem Schlüssel mcpServers hinzu. Stellen Sie sicher, dass Sie den Pfad in args durch den absoluten Pfad zu Ihrer amazon_scraper_mcp.py-Datei ersetzen.
{
"mcpServers": {
"amazon_product_scraper": {
"command": "python", // Or python3 if needed
"args": ["/full/path/to/your/amazon_scraper_mcp.py"], // <-- IMPORTANT: Use the correct absolute path
}
}
}Schritt 4: Speichern Sie die Datei claude_desktop_config.json und schließen Sie Claude Desktop vollständig und öffnen Sie sie erneut, damit die Änderungen wirksam werden.
Schritt 5: In Claude Desktop sollten Sie nun ein kleines Werkzeugsymbol (wie ein Hammer 🔨) im Chat-Eingabebereich sehen.
Schritt 6: Ein Klick darauf sollte Ihren “Amazon Product Scraper” mit seinen Tools fetch_page und extract_info auflisten.

Schritt 7: Senden Sie eine Aufforderung, zum Beispiel: “Ermitteln Sie den aktuellen Preis, den ursprünglichen Preis und die Bewertung für dieses Amazon-Produkt: https://www.amazon.com/dp/B09C13PZX7″.
Schritt 8: Claude erkennt, dass hierfür externe Tools erforderlich sind, und fragt Sie nach der Erlaubnis, zuerst fetch_page und dann extract_info auszuführen. Klicken Sie für jedes Tool auf “Für diesen Chat zulassen”.

Schritt 9: Nach Erteilung der Berechtigungen führt der MCP-Server die Tools aus. Claude empfängt dann die strukturierten Daten und präsentiert sie im Chat.

🔥 Toll, Sie haben Ihren ersten MCP-Server erfolgreich aufgebaut und integriert!
Verbinden mit Cursor
Der Prozess für Cursor (eine AI-first IDE) ist ähnlich.
Schritt 1: Cursor öffnen.
Schritt 2: Gehen Sie zu Einstellungen ⚙️ und navigieren Sie zum Abschnitt MCP.

Schritt 3: Klicken Sie auf “+Hinzufügen eines neuen globalen MCP-Servers”. Daraufhin wird die Konfigurationsdatei mcp.json geöffnet. Fügen Sie einen Eintrag für Ihren Server hinzu, wobei Sie wiederum den absoluten Pfad zu Ihrem Skript angeben.
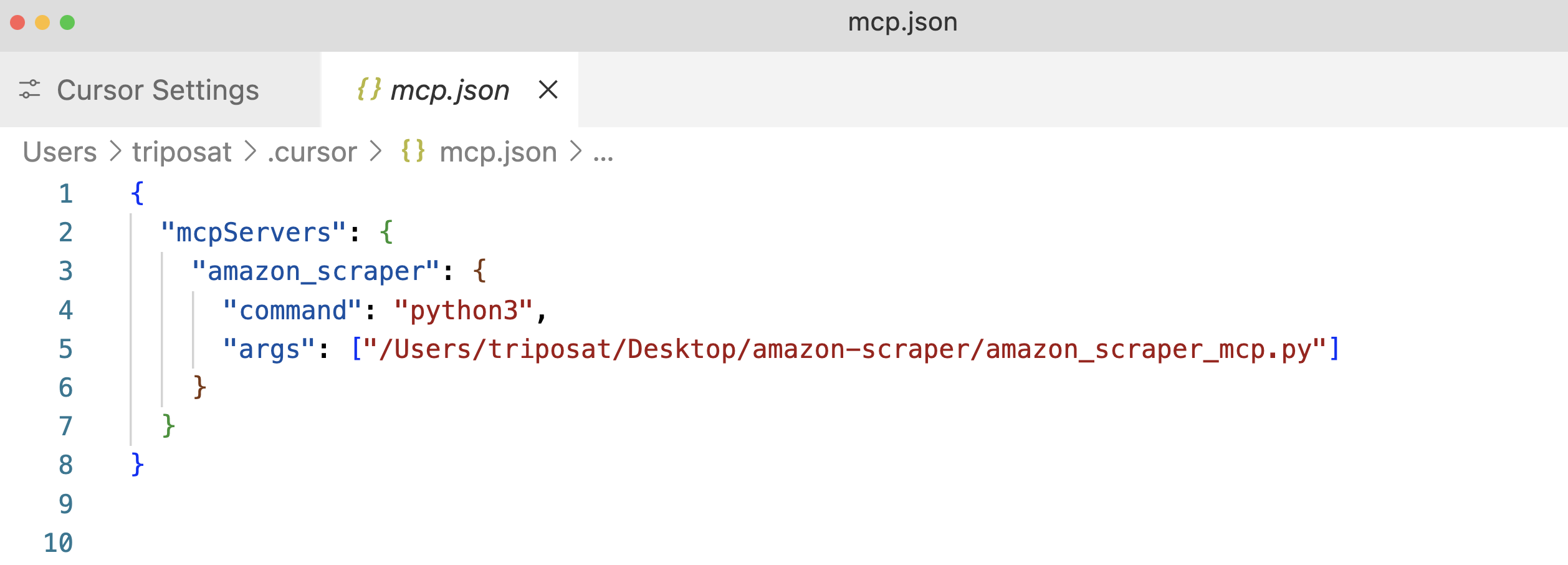
Schritt 4: Speichern Sie die Datei mcp.json und Sie sollten Ihren “amazon_product_scraper” aufgeführt sehen, hoffentlich mit einem grünen Punkt, der anzeigt, dass er läuft und verbunden ist.

Schritt 5: Verwenden Sie die Chat-Funktion von Cursor(Cmd+l oder Strg+l).
Schritt 6: Senden Sie eine Eingabeaufforderung, zum Beispiel: “Extrahiere alle verfügbaren Produktdaten von dieser Amazon URL: https://www.amazon.com/dp/B09C13PZX7. Formatieren Sie die Ausgabe als strukturiertes JSON-Objekt”.
Schritt 7: Ähnlich wie bei Claude Desktop bittet der Cursor um die Erlaubnis, die Tools fetch_page und extract_info auszuführen. Genehmigen Sie diese Anfragen (“Run Tool”).
Schritt 8: Der Cursor zeigt den Interaktionsfluss, die Aufrufe an Ihre MCP-Tools und schließlich die strukturierten JSON-Daten an, die von Ihrem extract_info-Tool zurückgegeben werden.

Hier ist ein Beispiel für die JSON-Ausgabe von Cursor:
{
"title": "Razer Basilisk V3 Customizable Ergonomic Gaming Mouse: Fastest Gaming Mouse Switch - Chroma RGB Lighting - 26K DPI Optical Sensor - 11 Programmable Buttons - HyperScroll Tilt Wheel - Classic Black",
"price": 39.99,
"original_price": 69.99,
"discount_percent": 43,
"rating_stars": 4.6,
"review_count": 7782,
"features": [
"ICONIC ERGONOMIC DESIGN WITH THUMB REST — PC gaming mouse favored by millions worldwide with a form factor that perfectly supports the hand while its buttons are optimally positioned for quick and easy access",
"11 PROGRAMMABLE BUTTONS — Assign macros and secondary functions across 11 programmable buttons to execute essential actions like push-to-talk, ping, and more",
"HYPERSCROLL TILT WHEEL — Speed through content with a scroll wheel that free-spins until its stopped or switch to tactile mode for more precision and satisfying feedback that's ideal for cycling through weapons or skills",
"11 RAZER CHROMA RGB LIGHTING ZONES — Customize each zone from over 16.8 million colors and countless lighting effects, all while it reacts dynamically with over 150 Chroma integrated games",
"OPTICAL MOUSE SWITCHES GEN 2 — With zero unintended misclicks these switches provide crisp, responsive execution at a blistering 0.2ms actuation speed for up to 70 million clicks",
"FOCUS+ 26K DPI OPTICAL SENSOR — Best-in-class mouse sensor with intelligent functions flawlessly tracks movement with zero smoothing, allowing for crisp response and pixel-precise accuracy",
// ... (other features)
],
"availability": "In Stock"
}Dies zeigt die Flexibilität von MCP – ein und derselbe Server arbeitet nahtlos mit verschiedenen Client-Anwendungen zusammen.
Integration von Bright Data’s MCP für KI-gesteuerte Webdatenextraktion
Benutzerdefinierte MCP-Server bieten volle Kontrolle, sind jedoch mit Herausforderungen verbunden, wie z. B. der Verwaltung der Proxy-Infrastruktur, der Handhabung anspruchsvoller Anti-Bot-Mechanismen und der Gewährleistung der Skalierbarkeit. Bright Data löst diese Probleme mit seiner produktionsreifen, vorkonfigurierten MCP-Lösung, die für eine nahtlose Integration mit KI-Agenten und LLMs konzipiert ist.
Die Integration des Model Context Protocol (MCP) in Bright Data bietet LLMs und KI-Agenten einen nahtlosen Echtzeit-Zugang zu öffentlichen Webdaten, die für KI-Workflows maßgeschneidert sind. Durch die Verbindung mit dem MCP von Bright Data können Ihre Apps und Modelle SERP-Ergebnisse von allen wichtigen Suchmaschinen abrufen und den Zugriff auf schwer zugängliche Websites nahtlos freischalten.
Die Model Context Protocol (MCP)-Lösung von Bright Data verbindet Ihre Anwendung mit einer Reihe leistungsfähiger Tools zur Extraktion von Webdaten – darunter Web Unlocker, SERP API, Web Scraper API und Scraping Browser – und bietet damiteine umfassende Infrastruktur, die:
- Liefert KI-reife Daten: Automatisches Abrufen und Formatieren von Webinhalten, wodurch zusätzliche Vorverarbeitungsschritte reduziert werden.
- Garantiert Skalierbarkeit und Zuverlässigkeit: Nutzt eine robuste Infrastruktur, um große Mengen an Anfragen ohne Leistungseinbußen zu bewältigen.
- Umgeht Sperren und CAPTCHAs: Verwendet fortschrittliche Anti-Bot-Strategien, um selbst auf den am stärksten geschützten Websites zu navigieren und Inhalte abzurufen.
- Bietet globale IP-Abdeckung: Nutzt ein riesiges Proxy-Netzwerk, das 195 Länder umfasst, um auf geografisch eingeschränkte Inhalte zuzugreifen.
- Vereinfacht die Integration: Minimiert den Konfigurationsaufwand durch nahtlose Zusammenarbeit mit allen MCP-Clients.
Voraussetzungen für Bright Data MCP
Bevor Sie mit der Integration von Bright Data MCP beginnen, sollten Sie sich vergewissern, dass Sie über die folgenden Informationen verfügen:
- Bright Data-Konto: Registrieren Sie sich unter brightdata.com. Neue Benutzer erhalten kostenloses Guthaben für Tests.
- API-Token: Beziehen Sie Ihr API-Token aus Ihren Bright Data-Kontoeinstellungen(Seite “Benutzereinstellungen“).
- Web Unlocker-Zone: Erstellen Sie eine Web Unlocker-Proxy-Zone in Ihrem Bright Data-Bedienfeld. Geben Sie ihr einen einprägsamen Namen, z. B.
mcp_unlocker(Sie können diesen Namen später über Umgebungsvariablen überschreiben, falls erforderlich). - (Optional) Scraping-Browser-Zone: Wenn Sie erweiterte Browser-Automatisierungsfunktionen benötigen (z. B. für komplexe JavaScript-Interaktionen oder Screenshots), erstellen Sie eine Scraping-Browser-Zone. Beachten Sie die Authentifizierungsdaten (Benutzername und Passwort) für diese Zone (auf der Registerkarte Übersicht ), normalerweise im Format
brd-customer-ACCOUNT_ID-zone-ZONE_NAME:PASSWORD.
Schnellstart: Konfigurieren von Bright Data MCP für Claude Desktop
Schritt 1: Der Bright Data MCP-Server wird normalerweise mit npx ausgeführt, das mit Node.js geliefert wird. Installieren Sie Node.js, falls Sie es noch nicht von der offiziellen Website haben.
Schritt 2: Öffnen Sie Claude Desktop -> Einstellungen -> Entwickler -> Konfig bearbeiten(claude_desktop_config.json).
Schritt 3: Fügen Sie die Bright Data-Serverkonfiguration unter mcpServers hinzu. Ersetzen Sie die Platzhalter durch Ihre tatsächlichen Anmeldedaten.
{
"mcpServers": {
"Bright Data": { // Choose a name for the server
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_BRIGHTDATA_API_TOKEN", // Paste your API token here
"WEB_UNLOCKER_ZONE": "mcp_unlocker", // Your Web Unlocker zone name
// Optional: Add if using Scraping Browser tools
"BROWSER_AUTH": "brd-customer-ACCOUNTID-zone-YOURZONE:PASSWORD"
}
}
}
}Schritt 4: Speichern Sie die Konfigurationsdatei und starten Sie Claude Desktop neu.
Schritt 5: Bewegen Sie den Mauszeiger über das Hammersymbol (🔨) in Claude Desktop. Sie sollten nun mehrere MCP-Werkzeuge sehen.

Versuchen wir, Daten von Zillow zu extrahieren, einer Website, die dafür bekannt ist, dass sie Scraper möglicherweise blockiert. Aufforderung an Claude: “Extrahiere die wichtigsten Eigenschaftsdaten im JSON-Format von dieser Zillow-URL: https://www.zillow.com/apartments/arverne-ny/the-tides-at-arverne-by-the-sea/ChWHPZ/”.

Erlauben Sie Claude, die erforderlichen Bright Data MCP-Tools zu verwenden. Der MCP-Server von Bright Data übernimmt die zugrunde liegende Komplexität (Proxy-Rotation, JavaScript-Rendering über Scraping Browser, falls erforderlich).
Der Server von Bright Data führt die Extraktion durch und liefert strukturierte Daten, die Claude präsentiert.

Hier ist ein Ausschnitt der möglichen Ausgabe:
{
"propertyInfo": {
"name": "The Tides At Arverne By The Sea",
"address": "190 Beach 69th St, Arverne, NY 11692",
"propertyType": "Apartment building",
// ... more info
},
"rentPrices": {
"studio": { "startingPrice": "$2,750", /* ... */ },
"oneBed": { "startingPrice": "$2,900", /* ... */ },
"twoBed": { "startingPrice": "$3,350", /* ... */ }
},
// ... amenities, policies, etc.
}🔥 Das ist großartig!
Ein weiteres Beispiel: Schlagzeilen der Hacker News
Eine einfachere Abfrage:“Gib mir die Titel der letzten 5 Nachrichtenartikel von Hacker News“.

Dies zeigt, wie der MCP-Server von Bright Data den Zugriff auf dynamische oder stark geschützte Webinhalte direkt in Ihrem AI-Workflow vereinfacht.
Schlussfolgerung
Wie wir in diesem Leitfaden erläutert haben, stellt das Model Context Protocol von Anthropic einen grundlegenden Wandel in der Art und Weise dar, wie KI-Systeme mit der Außenwelt interagieren. Wie wir gesehen haben, können Sie benutzerdefinierte MCP-Server für bestimmte Aufgaben erstellen, wie z. B. unseren Amazon Scraper. Die MCP-Integration von Bright Data verbessert dies weiter, indem sie Web-Scraping-Funktionen auf Unternehmensniveau bietet, die Anti-Bot-Schutzmaßnahmen umgehen und KI-fähige strukturierte Daten bereitstellen.
Wir haben auch einige der besten Ressourcen zu KI und großen Sprachmodellen (LLMs) ausgewählt. Schauen Sie sich diese unbedingt an, um mehr zu erfahren:





