

In diesem Artikel erfahren Sie alles über RAG, einschließlich seiner Rolle bei der Verbesserung von LLM-Antworten und seinen Komponenten.
Was ist RAG?
RAG ist eine Technik des maschinellen Lernens (ML), die traditionelle LLMs einen Schritt weiterbringt, indem sie diese mit Suchsystemen (auch bekannt als Retrieval-Systemen) verknüpft. Anstatt sich nur auf ihre festen Trainingsdaten zu verlassen, können RAG-basierte Modelle auf externe Quellen wie Datenbanken, Dokumente oder sogar das Internet zurückgreifen, um relevante Informationen zu finden und die Qualität ihrer Antworten zu verbessern. Diese Mischung aus sofortiger Informationsbeschaffung und Sprachgenerierung macht die Antworten genauer und aktueller.
Abruf + Generierung
RAG kombiniert drei Komponenten: ein Such- oder Abrufsystem, das Sprachmodell selbst und einen Prozess, der beide miteinander verbindet. Bei einer Anfrage nutzt das RAG-System zunächst die Abrufkomponente, um relevante Daten außerhalb des Trainingsdatensatzes des Sprachmodells zu finden. Anschließend wird die ursprüngliche Eingabeaufforderung modifiziert, um sie mit diesen Daten zu ergänzen. Die aktualisierte Eingabeaufforderung wird an die Generierungskomponente (das LLM) weitergeleitet, die sowohl ihre eigenen gelernten Muster als auch neue Inhalte verwendet, um eine Antwort zu liefern. Auf diese Weise ist die Ausgabe nicht nur ein Produkt des bereits vorhandenen Trainings, sondern basiert auf echten, verifizierten Informationen, die direkt aus Quellen stammen.
RAG kombiniert auf clevere Weise die Leistungsfähigkeit von Retrieval und Generation und bietet eine intelligente Lösung für die Mängel traditioneller Sprachmodelle. Es liefert zuverlässigere, genauere Antworten und kann sich an verschiedene Themen anpassen, wodurch es sich ideal für Anwendungen eignet, bei denen Informationen aktuell oder spezialisiert sein müssen.
Warum LLMs eine Erweiterung benötigen
LLMs sind zwar beeindruckend darin, menschenähnliche Antworten zu generieren, aber sie sind nicht ohne Mängel.
Risiko von Halluzinationen
Eine der größten Herausforderungen für LLMs ist das Risiko von Halluzinationen, bei denen das Modell überzeugende, aber falsche Informationen generiert. Dies geschieht, weil LLMs auf großen, statischen Datensätzen trainiert werden und keinen Echtzeit-Zugriff auf Aktualisierungen oder Fakten außerhalb ihres Trainingsfensters haben.
Darüber hinaus sind LLMs, wenn man genau hinschaut, keine Problemlösungsmaschinen, sondern Modelle zur Textvervollständigung. Ihr Endziel ist es, eine Antwort zu generieren, die der richtigen Antwort auf die gegebene Eingabe am ehesten entspricht; die Antwort muss nicht unbedingt korrekt sein. Da sie keine deterministischen Algorithmen verwenden, um zu einer Antwort zu gelangen,kommt es zwangsläufigirgendwannzu Halluzinationen.
Überprüfung von Informationen
Darüber hinaus können LLMs neue Informationen nicht überprüfen oder ihre Antworten mit Live-Quellen abgleichen, sodass es leicht zu Übersehen oder Falschdarstellungen von Fakten kommen kann.
Wissensbegrenzung
Eine weitere Einschränkung ist der Wissensabbruch. Da LLMs mit Daten trainiert werden, die nur bis zu einem bestimmten Zeitpunkt reichen, fehlt ihnen von Natur aus das Bewusstsein für Ereignisse oder Entdeckungen, die nach dem Abbruch stattfinden.
Glaubwürdige Quellen
LLMs haben auch Schwierigkeiten, glaubwürdige Quellen zu zitieren, was dazu führen kann, dass Nutzer die Richtigkeit ihrer Antworten anzweifeln. Ohne Zugang zu aktuellen Quellen oder einer Möglichkeit, die Informationen zu validieren, können diese Modelle mit ihrer Vertrauenswürdigkeit zu kämpfen haben.
RAG: Die Lösung für die Einschränkungen von LLMs
Wie bereits erwähnt, wurde RAG entwickelt, um die Einschränkungen von LLMs zu beheben, indem seine Antworten auf realen, aktuellen Daten basieren.
Aktuelle Informationen aus relevanten Quellen
Wenn ein LLM eine Anfrage erhält, kann es dank RAG nicht nur auf seine statischen Trainingsdaten zurückgreifen, sondern auch aktuelle Informationen aus kontextuell relevanten externen Quellen einbeziehen. Diese Konfiguration reduziert das Risiko von Halluzinationen effektiv, da die Antworten auf tatsächlichen Dokumenten und Daten basieren. Da RAG aktiv externe Quellen abfragt, kann es Fragen zu aktuellen Ereignissen, neuen Technologien oder anderen Informationen beantworten, die ein Standard-LLM aufgrund seiner begrenzten Kenntnisse nicht beantworten könnte. In einem Kundensupport-Szenario kann RAG beispielsweise die neuesten Richtlinienaktualisierungen aus einer Wissensdatenbank abrufen und so sicherstellen, dass die Antworten mit der aktuellen Dokumentation des Unternehmens übereinstimmen.
Verbesserte Transparenz
Neben der Genauigkeit verbessert RAG auch die Transparenz seiner Antworten durch die Angabe von Quellen. Da es Daten aus spezifischen, relevanten Dokumenten bezieht, liefert es eine klarere Argumentationskette, sodass Benutzer sehen können, woher die Informationen stammen. Diese Überprüfbarkeit verbessert nicht nur das Vertrauen der Benutzer, sondern macht RAG-gestützte Modelle auch in Bereichen wie Rechts- und Finanzdienstleistungen nützlicher, in denen Benutzer klare, gut begründete Antworten benötigen.
Wichtige Anwendungsfälle von RAG
RAG glänzt in Anwendungen, in denen genaue, aktuelle Informationen entscheidend sind, insbesondere in sich schnell verändernden Bereichen. Hier sind einige der beliebtesten Anwendungsfälle von RAG.
Automatisierung des Kundensupports
RAG verändert den Kundensupport, indem es auf die Wissensdatenbank und die Hilfeartikel eines Unternehmens zurückgreift. Es liefert sofortige Antworten auf Kundenanfragen und greift dabei auf die aktuellsten Dokumente, Produktinformationen und Tipps zur Fehlerbehebung zurück. Das bedeutet, dass Kunden präzise Antworten erhalten, die auf ihre spezifischen Bedürfnisse zugeschnitten sind – ohne die Support-Mitarbeiter mit Routinefragen zu überfordern.
Rechts- und Finanzdienstleistungen
Diese Branchen benötigen Informationen, die nicht nur präzise sind, sondern auch auf glaubwürdige Quellen zurückgeführt werden können. Ein Jurist kann beispielsweise RAG nutzen, um relevante Rechtsprechung oder Vorschriften abzurufen, wenn er sich eine Meinung bildet. Finanzanalysten können RAG nutzen, um aktuelle Marktberichte oder Daten abzurufen und ihren Kunden zeitnahe und durch konkrete Informationen untermauerte Einblicke zu liefern.
Recherche und Erstellung von Inhalten
Autoren, Journalisten und Forscher können RAG nutzen, um genaue Referenzen aus vertrauenswürdigen Quellen abzurufen, wodurch der Prozess der Faktenprüfung und Informationsbeschaffung vereinfacht und beschleunigt wird. Ob beim Verfassen eines Artikels oder beim Zusammenstellen von Daten für eine Studie – RAG ermöglicht den schnellen Zugriff auf relevantes und glaubwürdiges Material, sodass sich die Urheber auf die Erstellung hochwertiger Inhalte konzentrieren können.
Konversationsagenten und Chatbots
Durch die Integration von RAG können Gesprächsagenten und Chatbots genauere, kontextbezogene Antworten liefern und so die Benutzererfahrung verbessern. Beispielsweise könnte ein Chatbot im Gesundheitswesen Informationen über aktuelle medizinische Studien abrufen oder ein Bot für den technischen Support die neuesten Details zu Firmware-Updates für Geräte bereitstellen. Die Fähigkeit von RAG, Live-Datenabruf mit Sprachgenerierung zu kombinieren, verbessert sowohl die Qualität als auch die Zuverlässigkeit der Antworten.
Erfahren Sie mehr über die Erstellung eines RAG-Chatbots mit GPT-Modellen.
Herausforderungen und Einschränkungen von RAG
RAG bietet zwar einen erheblichen Mehrwert für Sprachmodelle, bringt jedoch auch eine Reihe von Herausforderungen mit sich.
Qualität und Genauigkeit
Ein großes Problem ist die Qualität und Genauigkeit der Informationen, die zur Ergänzung der Eingabe abgerufen werden. Da RAG auf externe Quellen angewiesen ist, ist die Antwort des Modells nur so gut wie die Daten, die es abruft. Die generierte Antwort könnte dennoch unzureichend sein, wenn das Abrufsystem irrelevante oder ungenaue Dokumente zurückgibt. Die Gewährleistung einer hohen Qualität des Abrufs ist wichtig und erfordert oft Feinabstimmungen und regelmäßige Aktualisierungen, um die Relevanz und Genauigkeit der Daten zu gewährleisten.
Rechenaufwand und Komplexität
Weitere Herausforderungen sind die Rechenkosten und die Komplexität, die mit dem Betrieb eines RAG-Systems verbunden sind. Im Gegensatz zu eigenständigen LLMs benötigt RAG sowohl ein leistungsfähiges Abrufsystem als auch ein Modell, das die abgerufenen Informationen leicht integrieren kann, was ressourcenintensiv sein kann. Diese erhöhte Rechenlast kann die Antwortzeiten verlangsamen, insbesondere wenn große Datenmengen in Echtzeit durchsucht oder verarbeitet werden müssen. Unternehmen, die RAG implementieren, müssen oft ein Gleichgewicht zwischen Genauigkeit und Leistung finden und Wege finden, den Abruf ohne Einbußen bei der Geschwindigkeit einzurichten.
Der Erfolg von RAG hängt stark vom Zugang zu strukturierten, zuverlässigen Datenquellen ab. Ohne vertrauenswürdige und gut organisierte externe Datenbanken kann es für das Abrufsystem schwierig sein, nützliche Informationen zu finden. Darüber hinaus sind nicht alle Datenquellen leicht zugänglich oder erschwinglich, was für kleinere Unternehmen ein Hindernis darstellen kann.
Trotz dieser Herausforderungen kann RAG mit einer sorgfältigen Einrichtung und zuverlässigen Datenquellen dennoch transformative Vorteile für eine Vielzahl von Anwendungen bieten.
RAG-Implementierung in der Praxis
Die Einrichtung eines RAG-Systems erfordert die Verbindung eines Sprachmodells mit einem effektiven Abrufmechanismus, um den Zugriff auf externe Daten zu ermöglichen.
Der Prozess beginnt mit der Einrichtung einer übergeordneten Architektur, die ein Suchsystem mit dem Sprachmodell kombiniert. Wenn ein Benutzer eine Anfrage einreicht, durchsucht das Abrufsystem externe Quellen nach relevanten Informationen und sendet diese Informationen zusammen mit der Eingabeaufforderung an das LLM, das auf der Grundlage seines eigenen Wissens und der abgerufenen Daten eine Antwort generiert. Dieser Ansatz stellt sicher, dass die Antworten sowohl fundiert als auch kontextbezogen auf aktuellen, zuverlässigen Informationen basieren.
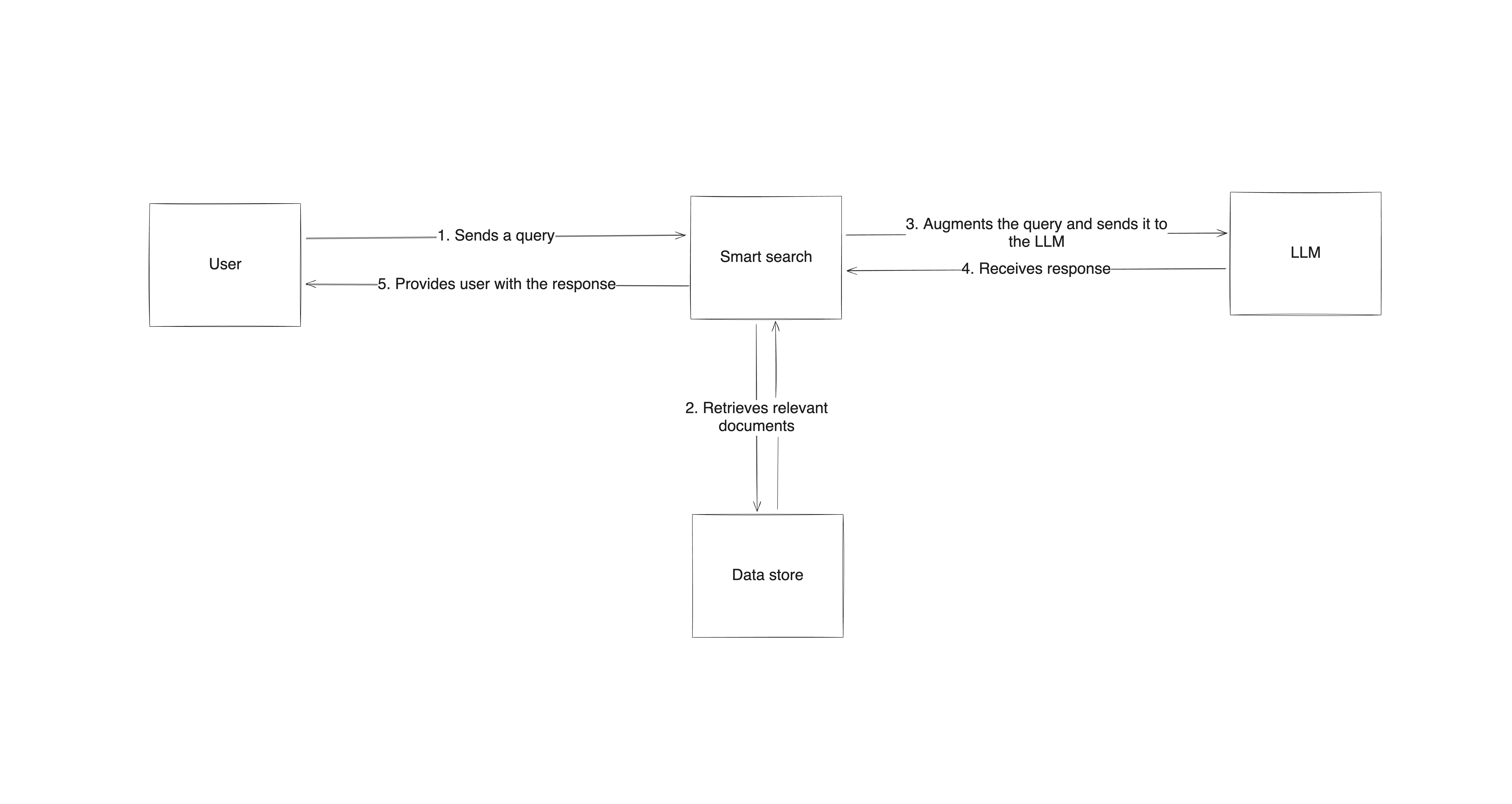
Die Implementierung von RAG erfordert spezielle Tools und Frameworks
In der Praxis erfordert die Implementierung von RAG spezifische Tools und Frameworks, die das Abrufen von Informationen, deren Verarbeitung und die Generierung der Antwort übernehmen können. Bibliotheken wieLangChainundHaystacksind beliebte Optionen, da sie vorgefertigte Komponenten für die Integration der Abfrage in den Prozess der Antwortgenerierung bieten.
LangChain bietet beispielsweise Tools zumStrukturieren von Eingabeaufforderungen,zum Abrufen von Daten undzumdirektenWeiterleiten der Ergebnissean ein LLM, während Haystack aufleistungsstarkes Abrufen spezialisiert ist und es Ihnen ermöglicht, Informationen aus Datenbanken, Dokumenten oder sogar dem Internet abzurufen. Sie können diese Tools für die Arbeit mit verschiedenen Datenquellen anpassen, wodurch sie für verschiedene RAG-Anwendungen sehr flexibel einsetzbar sind.
RAG ist ein Framework, das auf einem bestehenden LLM aufbaut
Wenn man es aus der Ferne betrachtet, hat RAG im Gegensatz zu Techniken wieFine-Tuning keinen Einfluss auf die Struktur oder die Bestandteile Ihres primären LLM. Es handelt sich lediglich um ein Framework, das auf Ihrem bestehenden LLM aufbaut und dazu beiträgt, die Qualität der Prompts zu verbessern, die Sie an das Modell senden. Einige argumentieren,dass RAG nur glorifiziertes Prompt Engineering ist, und man kann verstehen, woher sie kommen, wenn man sich die ursprüngliche Eingabeaufforderung ansieht, die in ein RAG-System eingegeben wird, und sie mit der erweiterten Eingabeaufforderung vergleicht, die es generiert, bevor es die endgültige Antwort generiert. Hier ist ein kurzes (und extrem vereinfachtes) Beispiel, um dies besser zu verstehen:
- Roh-Prompt
Was sind die neuesten Auswirkungen des Klimawandels auf Korallenriffe?
- Antwort (von einem LLM ohne RAG)
Korallenriffe sind von steigenden Temperaturen und der Versauerung der Ozeane betroffen, was zu Korallenbleiche führt und marine Ökosysteme stört.
- Erweiterte Eingabeaufforderung (mit RAG)
Unter Verwendung der abgerufenen Daten: „Ein Bericht der NOAA aus dem Jahr 2024 hebt hervor, dass die Erwärmung der Ozeane zu massiven Korallenbleichen in der Karibik und im Pazifik geführt hat, wodurch die Korallenbedeckung in den betroffenen Regionen um 40 % zurückgegangen ist. Die Versauerung schwächt außerdem die Korallenskelette und macht sie anfälliger für Sturmschäden.“ Beantworten Sie folgende Frage: Was sind die neuesten Auswirkungen des Klimawandels auf Korallenriffe?
- Antwort (von einem LLM mit RAG)
Jüngste Berichte der NOAA zeigen, dass die Erwärmung der Ozeane zu massiven Bleicheereignissen führt, insbesondere in der Karibik und im Pazifik, wo die Korallenbedeckung in einigen Gebieten um 40 % zurückgegangen ist. Die Versauerung schädigt auch die Korallenskelette und erhöht ihre Anfälligkeit.
Dies scheint zwar das Argument zu stützen, aber es ist wichtig zu betonen, dass es im Rahmen der RAG-Konfiguration vor allem darum geht, dem LLM die richtigen Daten im Kontext der ursprünglichen Anfrage zu liefern. Je nach Datenspeicher kann Ihre Suchkomponente so einfach wie eine SQL-Abfrage oder so komplex wie eine Google-Suche und ein Web-Crawling sein. Sobald Sie die Daten haben, müssen Sie diese korrekt und effizient priorisieren und zusammenfassen, bevor Sie sie an die Eingabeaufforderung anhängen. Diese beiden Schritte machen RAG viel komplexer als möglicherweise jede andere Technik des Prompt Engineering.
Die Implementierung von RAG erfordert eine große Menge hochwertiger Daten
Was den Datenspeicher selbst betrifft, so benötigen die meisten RAG-Systeme einen solchen, und es ist hilfreich, wenn die große Datenmenge genau, aktuell und domänenspezifisch ist. Die Erstellung und Pflege solcher Datensätze ist zeitaufwändig und schwierig. Öffentliche Datenanbieter wieBright Data können dies vereinfachen, indem sie umfangreiche Datensätze bereitstellen, die sicherstellen, dass das Abrufsystem mit aktuellen, hochwertigen Informationen arbeitet.
Diese Quellen können alles von Webdaten bis hin zu strukturierten Datensätzen umfassen, was die Relevanz des Modells erheblich verbessert. Durch die Integration mit Bright Data-Datensätzen haben RAG-Modelle Zugriff auf die neuesten Informationen, was nicht nur die Genauigkeit der Antworten verbessert, sondern auch in Bereichen hilft, in denen Echtzeitdaten unerlässlich sind, wie z. B. Wettersysteme oder Logistik und Lieferkettenmanagement.
Wie Bright Data bei der Abfrage öffentlicher Daten helfen kann
Als Anbieter hochwertiger öffentlicher Datensätze aus dem gesamten Web kann Bright Data eine wertvolle Ressource für RAG-Systeme sein. Da RAG auf hochwertige, aktuelle Informationen angewiesen ist, ermöglichen die Datensätze von Bright Data das Abrufen relevanter Inhalte für verschiedene Anwendungen, von aktuellen Ereignissen bis hin zu Nischenrecherchen.
Strukturierte Daten aus verschiedenen Bereichen
Die Datensätze von Bright Data umfassen strukturierte Daten aus verschiedenen Sektoren, wie E-Commerce, Finanzmärkte und Nachrichten, die in RAG-Systeme integriert werden können, um die Genauigkeit und Relevanz des Modells zu verbessern. Dies kann dazu beitragen, dass LLMs präzise auf Fragen antworten können, die aktuelle oder branchenspezifische Informationen erfordern, was für Bereiche wie Kundensupport und Wettbewerbsanalyse von entscheidender Bedeutung ist.
Zugriff auf und Filterung von öffentlichen Daten in großem Umfang
Wenn Sie selbst Daten aus dem Internet sammeln möchten, können Ihnen die Bright DataAPIunddie umfangreiche Proxy-Infrastrukturdabei helfen, auf öffentliche Daten in großem Umfang zuzugreifen und diese zu filtern, während Sie gleichzeitig die Richtlinien zur Datennutzung einhalten. Dies kann für RAG-Anwendungen, die ein dynamisches Abrufen von Informationen erfordern, sehr nützlich sein. Beispielsweise könnte ein RAG-Setup für Finanzdienstleistungen kontinuierlich aktualisierte Börsendaten oder regulatorische Nachrichten abrufen und so die Fähigkeit des Modells verbessern, Echtzeit-Einblicke zu liefern.
Die Verwendung von Bright Data als Datenquelle in Ihrem RAG-System entlastet Sie von der Pflege Ihres Datenspeichers, sodass Sie sich auf die Verfeinerung der Prompt-Erweiterung und die Generierung von Antworten konzentrieren können.
Fazit
RAG stellt einen bedeutenden Fortschritt in den Fähigkeiten von LLMs dar und ermöglicht es ihnen, wichtige Einschränkungen wie Wissenslücken und Halluzinationen zu überwinden, indem Echtzeitdaten aus externen Quellen einbezogen werden. Durch RAG erhalten Modelle Zugriff auf aktuelle, verifizierte Informationen, was sowohl die Relevanz als auch die Zuverlässigkeit ihrer Antworten verbessert. Diese Technik verwandelt Sprachmodelle von statischen Wissensspeichern in dynamische, kontextbewusste Agenten.
Wenn Sie hochwertige Echtzeitdaten in RAG-Implementierungen integrieren, können Sie die Genauigkeit, Relevanz und Vertrauenswürdigkeit Ihrer KI-Anwendungen verbessern. Ob im Kundensupport, in der Finanzanalyse, im Gesundheitswesen oder in anderen Branchen – der Einsatz von RAG kann dazu beitragen, die Endbenutzererfahrung erheblich zu verbessern.
Bright Data erleichtert die Entwicklung von RAG-Implementierungen, indem es eine skalierbare Lösung für die Beschaffung zuverlässiger, strukturierter öffentlicher Daten anbietet. Mit seinem umfangreichen Angebot an Datensätzen unterstützt Bright Data RAG-Systeme dabei, genaue und aktuelle Antworten für verschiedene Branchen und Anwendungen zu liefern.
Melden Sie sich jetzt an und testen Sie gratis, einschließlich kostenloser Datensatz-Beispiele, die Sie herunterladen können!





