

Web-Scraping befindet sich an einem Wendepunkt, da herkömmliche Methoden durch ausgeklügelte Anti-Bot-Abwehrsysteme vereitelt werden und Entwickler ständig brüchige Skripte patchen müssen. Auch wenn sie noch funktionieren, sind ihre Grenzen klar, vor allem im Vergleich zu modernen, KI-nativen Scraping-Infrastrukturen, die Ausfallsicherheit und Skalierbarkeit bieten. Da der Markt für KI-Agenten bis 2030 von 7,84 Milliarden Dollar auf 52,62 Milliarden Dollar anwachsen wird, liegt die Zukunft des Datenzugriffs in intelligenten, autonomen Systemen.
Durch die Kombination des autonomen Agenten-Frameworks von CrewAI mit der robusten Infrastruktur von Bright Data erhalten Sie einen Scraping-Stack, der die Gründe für Anti-Bot-Barrieren kennt und diese überwindet. In diesem Tutorial erstellen Sie einen KI-gesteuerten Scraping-Agenten, der zuverlässige Echtzeitdaten liefert.
Die Grenzen des Old-School-Scraping
Herkömmliches Scraping ist brüchig – es beruht auf statischen CSS- oder XPath-Selektoren, die bei jeder Front-End-Änderung zerstört werden. Zu den wichtigsten Herausforderungen gehören:
- Anti-Bot-Verteidigung. CAPTCHAs, IP-Drosselung und Fingerprinting blockieren einfache Crawler.
- JavaScript-lastige Seiten. React, Angular und Vue bauen das DOM im Browser auf, sodass rohe HTTP-Aufrufe die meisten Inhalte verfehlen.
- Unstrukturiertes HTML. Inkonsistentes HTML und verstreute Inline-Daten erfordern vor der Verwendung ein umfangreiches Parsing und Post-Processing.
- Skalierungsengpässe. Die Orchestrierung von Proxys, Wiederholungsversuchen und kontinuierlichen Patches wird zu einer anstrengenden, nicht enden wollenden operativen Belastung.
Wie CrewAI und Bright Data das Scraping rationalisieren
Der Aufbau eines autonomen Scrapers beruht auf zwei Säulen: einem anpassungsfähigen “Gehirn” und einem widerstandsfähigen “Körper”.
- CrewAI (Das Gehirn). Eine Open-Source-Multi-Agenten-Laufzeitumgebung, mit der Sie eine “Crew” von Agenten zusammenstellen können, die End-to-End-Scraping-Aufträge planen, überdenken und koordinieren können.
- Bright Data MCP (Der Körper). Ein Live-Daten-Gateway, das jede Anfrage durch den Unlocker-Stack von Bright Data leitet – IPs rotieren, CAPTCHAs lösen und Headless-Browser ausführen -, sodass LLMs auf einen Schlag sauberes HTML oder JSON erhalten. Die Implementierung von Bright Data ist die branchenführende Quelle für zuverlässige Daten für KI-Agenten.
Mit dieser Kombination aus Gehirn und Körper können Ihre Mitarbeiter an praktisch jedem Ort denken, abrufen und sich anpassen.
Was ist CrewAI?
CrewAI ist ein Open-Source-Framework für die Orchestrierung kooperativer KI-Agenten. Sie definieren die Rolle, das Ziel und die Werkzeuge jedes Agenten und gruppieren sie dann in einer Crew, um mehrstufige Workflows auszuführen.
Kernbestandteile:
- Agent. Ein LLM-gesteuerter Mitarbeiter mit einer Rolle, einem Ziel und einer optionalen Hintergrundgeschichte, die dem Modell einen Domänenkontext verleiht.
- Aufgabe. Ein einzelner, gut eingegrenzter Auftrag für einen Agenten sowie ein erwarteter_Output, der als Qualitätsmerkmal dient.
- Werkzeug. Jeder Callable, den der Agent aufrufen kann – ein HTTP-Fetch, eine DB-Abfrage oder der MCP-Endpunkt von Bright Data für Scraping.
- Mannschaft. Die Gesamtheit der Agenten und ihrer Aufgaben, die auf ein Ziel hinarbeiten.
- Prozess. Der Ausführungsplan – sequentiell, parallel oder hierarchisch – der die Reihenfolge der Aufgaben, die Delegation und die Wiederholungen steuert.
Dies spiegelt ein echtes Team wider: Spezialisten bearbeiten ihren Teil, geben Ergebnisse weiter und eskalieren bei Bedarf.
Was ist das Model Context Protocol (MCP)?
MCP ist ein offener JSON-RPC 2.0-Standard, mit dem KI-Agenten externe Tools und Datenquellen über eine einzige, strukturierte Schnittstelle aufrufen können. Stellen Sie sich das wie einen USB-C-Anschluss für Modelle vor – ein Stecker, viele Geräte.
Der MCP-Server von Bright Data setzt diesen Standard in die Praxis um, indem er einen Agenten direkt in den Scraping-Stack von Bright Data einbindet, wodurch das Web-Scraping mit MCP nicht nur leistungsfähiger, sondern auch viel einfacher ist als mit herkömmlichen Stacks:
- Umgehung von Anti-Bots. Anfragen fließen durch Web Unlocker und einen Pool von mehr als 150 Millionen rotierenden privaten IPs aus 195 Ländern.
- Unterstützung für dynamische Websites. Ein speziell entwickelter Scraping-Browser rendert JavaScript, so dass die Agenten das vollständig geladene DOM sehen.
- Strukturierte Ergebnisse. Viele Tools geben sauberes JSON zurück, so dass benutzerdefinierte Parser entfallen.
Der Server veröffentlicht mehr als 50 fertige Tools – von generischen URL-Abfragen bis hin zu Site-spezifischen Scrapern – so dass Ihr CrewAI-Agent mit einem einzigen Aufruf Produktpreise, SERP-Daten oder DOM-Snapshots abrufen kann.
Aufbau Ihres ersten AI Scraping Agenten
Lassen Sie uns einen CrewAI-Agenten erstellen, der Details von einer Amazon-Produktseite extrahiert und sie als strukturiertes JSON zurückgibt. Sie können denselben Stack leicht auf eine andere Website umleiten, indem Sie nur einige Zeilen ändern.
Voraussetzungen
- Python 3.11 – Empfohlen für Stabilität.
- Node.js + npm – Erforderlich für die Ausführung des Bright Data MCP-Servers; Download von der offiziellen Website.
- Virtuelle Python-Umgebung – Hält Abhängigkeiten isoliert; siehe die
venv-Dokumente. - Bright Data-Konto – Melden Sie sich an und erstellen Sie ein API-Token (kostenlose Testkredite sind verfügbar).
- Google Gemini API-Schlüssel – Erstellen Sie einen Schlüssel in Google AI Studio (klicken Sie auf + API-Schlüssel erstellen). Die kostenlose Stufe erlaubt 15 Anfragen pro Minute und 500 Anfragen pro Tag. Es ist kein Abrechnungsprofil erforderlich.
Überblick über die Architektur
Environment Setup → LLM Config → MCP Server Init →
Agent Definition → Task Definition → Crew Execution → JSON OutputSchritt 1. Einrichtung der Umgebung und Importe
mkdir crewai-bd-scraper && cd crewai-bd-scraper
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
from dotenv import load_dotenv
load_dotenv() # Load credentials from .envSchritt 2. API-Schlüssel und -Zonen konfigurieren
Erstellen Sie eine .env-Datei in Ihrem Projektstamm:
BRIGHT_DATA_API_TOKEN="…"
WEB_UNLOCKER_ZONE="…"
BROWSER_ZONE="…"
GEMINI_API_KEY="…"Sie benötigen:
- API-Token. Erzeugen Sie ein neues API-Token.
- Web Unlocker Zone. Erstellen Sie eine neue Web Unlocker-Zone. Wenn Sie dies nicht tun, wird eine Standardzone namens
mcp_unlockerfür Sie erstellt. - Browser-API-Zone. Erstellen Sie eine neue Browser-API-Zone. Wird nur für JavaScript-lastige Ziele benötigt. Kopieren Sie die Zeichenfolge für den Benutzernamen, die auf der Registerkarte Übersicht der Zone angezeigt wird.
- Google Gemini API-Schlüssel. Bereits erstellt in Voraussetzungen.
Schritt 3. LLM-Konfiguration (Gemini)
Konfigurieren Sie den LLM (Gemini 1.5 Flash) für eine deterministische Ausgabe:
llm = LLM(
model="gemini/gemini-1.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=0.1,
)Schritt 4. Bright Data MCP-Einrichtung
Konfigurieren Sie den Bright Data MCP-Server. Dadurch wird CrewAI mitgeteilt, wie der Server zu starten und die Anmeldeinformationen zu übergeben sind:
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)Dieser startet *npx @brightdata/mcp* als Unterprozess und stellt mehr als 50 Werkzeuge (≈ 57 zum Zeitpunkt der Erstellung dieses Dokuments) über den MCP-Standard zur Verfügung.
Schritt 5. Definition von Agenten und Aufgaben
Hier definieren wir die Persona des Agenten und die spezifische Aufgabe, die er erfüllen muss. Effektive CrewAI-Implementierungen folgen der 80/20-Regel: 80 % des Aufwands entfallen auf die Aufgabengestaltung, 20 % auf die Definition des Agenten.
def build_scraper_agent(mcp_tools):
return Agent(
role="Senior E-commerce Data Extractor",
goal=(
"Return a JSON object with snake_case keys containing: title, current_price, "
"original_price, discount, rating, review_count, last_month_bought, "
"availability, product_id, image_url, brand, and key_features for the "
"target product page. Ensure strict schema validation."
),
backstory=(
"Veteran web-scraping engineer with years of experience reverse-"
"engineering Amazon, Walmart, and Shopify layouts. Skilled in "
"Bright Data MCP, proxy rotation, CAPTCHA avoidance, and strict "
"JSON-schema validation."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
def build_scraping_task(agent):
return Task(
description=(
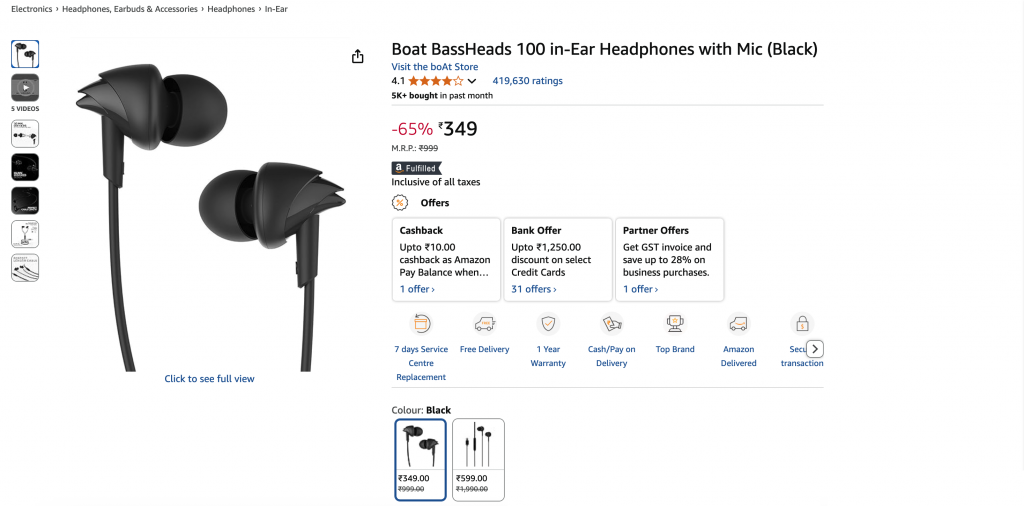
"Extract product data from https://www.amazon.in/dp/B071Z8M4KX "
"and return it as structured JSON."
),
expected_output="""{
"title": "Product name",
"current_price": "$99.99",
"original_price": "$199.99",
"discount": "50%",
"last_month_bought": 150,
"rating": 4.5,
"review_count": 1000,
"availability": "In Stock",
"product_id": "ABC123",
"image_url": "https://example.in/image.jpg",
"brand": "BrandName",
"key_features": ["Feature 1", "Feature 2"],
}""",
agent=agent,
)Nachfolgend wird die Funktion der einzelnen Parameter erläutert:
- role – Kurze Berufsbezeichnung, die CrewAI in jede Systemabfrage einfügt.
- goal – Nord-Stern-Ziel; CrewAI vergleicht es nach jeder Schleife, um zu entscheiden, ob angehalten werden soll.
- Hintergrundgeschichte – Bereichskontext, der den Ton angibt und Halluzinationen reduziert.
- tools – Liste der
BaseTool-Objekte(z. B. MCPsearch_engine,scrape_as_markdown). - llm – Modell, das CrewAI für jeden Zyklus Denken → Planen → Handeln → Antworten verwendet.
- max_iter – Harte Obergrenze für die internen Schleifen des Agenten (Standardwert 20 in v0.30 +).
- verbose – Streamt jede Eingabeaufforderung, jeden Gedanken und jeden Werkzeugaufruf nach stdout (nützlich für die Fehlersuche).
- Beschreibung – In jeder Runde werden handlungsorientierte Anweisungen gegeben.
- expected_output – Formaler Vertrag für eine gültige Antwort (striktes JSON verwenden, kein Komma am Ende).
- agent – Bindet diese Aufgabe an eine bestimmte
Agent-InstanzfürCrew.kickoff().
Schritt 6. Zusammenstellung der Crew und Durchführung
Dieser Teil fügt den Bearbeiter und die Aufgabe zu einer Crew zusammen und führt den Workflow aus.
def scrape_product_data():
"""Assembles and runs the scraping crew."""
with MCPServerAdapter(server_params) as mcp_tools:
scraper_agent = build_scraper_agent(mcp_tools)
scraping_task = build_scraping_task(scraper_agent)
crew = Crew(
agents=[scraper_agent],
tasks=[scraping_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
try:
result = scrape_product_data()
print("n[SUCCESS] Scraping completed!")
print("Extracted product data:")
print(result)
except Exception as e:
print(f"n[ERROR] Scraping failed: {str(e)}")Schritt 7. Ausführen des Abstreifers
Führen Sie das Skript von Ihrem Terminal aus. In der Konsole sehen Sie den Denkprozess des Agenten, wie er die Aufgabe plant und ausführt.
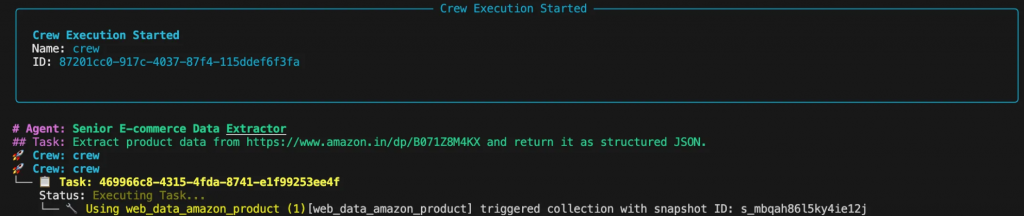
Die endgültige Ausgabe wird ein sauberes JSON-Objekt sein:
{
"title": "Boat BassHeads 100 in-Ear Headphones with Mic (Black)",
"current_price": "₹349",
"original_price": "₹999",
"discount": "-65%",
"rating": 4.1,
"review_count": 419630,
"last_month_bought": 5000,
"availability": "In stock",
"product_id": "B071Z8M4KX",
"image_url": "https://m.media-amazon.com/images/I/513ugd16C6L._SL1500_.jpg",
"brand": "boAt",
"key_features": [
"10mm dynamic driver",
"HD microphone",
"1.2 m cable",
"Comfortable fit",
"1 year warranty"
]
}Anpassung an andere Ziele
Die wahre Stärke eines agentenbasierten Designs ist seine Flexibilität. Möchten Sie LinkedIn-Beiträge statt Amazon-Produkte scrapen? Aktualisieren Sie einfach die Rolle, das Ziel und die Hintergrundgeschichte des Agenten sowie die Aufgabenbeschreibung und den erwarteten Output. Alles andere – einschließlich des zugrunde liegenden Codes und der Infrastruktur – bleibt genau gleich.
role = "Senior LinkedIn Post Extractor"
goal = (
"Return a JSON object containing: author_name, author_title, "
"author_profile_url, post_content, post_date, likes_count, "
"and comments_count"
)
backstory = (
"Seasoned social-data engineer specializing in LinkedIn data "
"extraction using Bright Data MCP. Produces clean, structured "
"JSON output."
)
description = (
"Extract post data from LinkedIn post (ID: orlenchner_agents-"
"brightdata-activity-7336402761892122625-h5Oa) and return "
"structured JSON."
)
expected_output = """{
"author_name": "Post author's full display name",
"author_title": "Author's job title/headline",
"author_profile_url": "Author's profile URL",
"post_content": "Complete post text with formatting",
"post_date": "ISO 8601 UTC timestamp",
"likes_count": "Number of post likes",
"comments_count": "Number of post comments",
}"""Die Ausgabe wird ein sauberes JSON-Objekt sein:
{
"author_name": "Or Lenchner",
"author_title": "CEO at Bright Data - Keeping public web data, public.",
"author_profile_url": "https://il.linkedin.com/in/orlenchner",
"post_content": "NEW PRODUCT! There’s a consensus that the future internet will be run by automated #Agents , automating the activity on behalf of “their” humans. AI solved the automation part (or at least shows strong indications), but the number one problem is ensuring smooth access to every website at scale without being blocked. browser.ai is the solution → Your Agent always gains access to any website with a simple prompt. Agents using Bright Data are already executing hundreds of millions of web actions daily on our browser infrastructure. #BrightData has long been the go-to for major LLM companies, providing the tools and scale they need to train and deploy such technologies. With browser.ai , we’re taking that foundation and tailoring it specifically for AI agents, optimizing our APIs, proxy networks, and serverless browsers to handle their unique demands. The web isn’t fully prepared for this shift yet, but we are. browser.ai immediate focus is to ensure *smooth* access to any website (DONE!), while phase two will be all about *fast* access (wip). https://browser.ai/",
"post_date": "2026-06-05T14:45:22.155Z",
"likes_count": 119,
"comments_count": 7
}Optimierung der Kosten
Der MCP von Bright Data ist nutzungsabhängig, d. h., jede zusätzliche Anforderung erhöht Ihre Rechnung. Einige wenige Design-Entscheidungen halten die Kosten im Zaum:
- Gezieltes Scraping. Fordern Sie nur die Felder an, die Sie benötigen, anstatt ganze Seiten oder Datensätze zu crawlen.
- Zwischenspeichern. Aktivieren Sie den CrewAI Cache
(cache_function), um Aufrufe zu überspringen, wenn sich der Inhalt nicht geändert hat, und sparen Sie so Zeit und Credits. - Effiziente Werkzeugauswahl. Standardmäßig wird die Web Unlocker-Zone verwendet und nur dann zu einer Browser-API-Zone gewechselt, wenn JavaScript-Rendering erforderlich ist.
- Setzen Sie
max_iter. Geben Sie jedem Agenten eine vernünftige Obergrenze, damit er nicht ewig auf einer kaputten Seite schleifen kann. (Sie können Anfragen auch mitmax_rpmdrosseln.)
Wenn Sie diese Praktiken befolgen, bleiben Ihre CrewAI Agenten sicher, zuverlässig und kosteneffizient und sind bereit für produktive Workloads auf Bright Data MCP.
Was kommt als Nächstes?
Das MCP-Ökosystem wird weiter ausgebaut: Die Responses API von OpenAI und das Gemini SDK von Google DeepMind sprechen jetzt nativ MCP, was eine langfristige Kompatibilität und weitere Investitionen garantiert.
CrewAI führt multimodale Agenten, umfangreicheres Debugging und RBAC für Unternehmen ein, während der MCP-Server von Bright Data mehr als 60 vorgefertigte Tools bereitstellt und weiter wächst.
Zusammen ermöglichen Agenten-Frameworks und standardisierter Datenzugriff eine neue Welle von Web-Intelligenz für KI-gestützte Anwendungen. Anleitungen zum Einbinden von MCP in das OpenAI Agents SDK unterstreichen, wie wichtig solide Datenleitungen geworden sind.
Letztendlich bauen Sie nicht nur einen Scraper, sondern orchestrieren einen adaptiven Daten-Workflow, der für das zukünftige Web entwickelt wurde.
Sie brauchen mehr Umfang? Überspringen Sie die Pflege der Scraper und die Bekämpfung von Blockierungen – fordern Sie einfach strukturierte Daten an:
- Crawl-API – Extraktion ganzer Websites in großem Umfang.
- Web Scraper APIs – über 120 domänenspezifische Endpunkte.
- SERP API – müheloses Scraping von Suchmaschinen.
- Dataset Marketplace – frische, geprüfte Datensätze auf Anfrage.
Sind Sie bereit für die Entwicklung von KI-Anwendungen der nächsten Generation? Entdecken Sie die gesamte KI-Produktsuite von Bright Data und sehen Sie, was ein nahtloser Live-Web-Zugriff für Ihre Agenten bedeutet. Wenn Sie tiefer eintauchen möchten, lesen Sie unsere MCP-Leitfäden für Qwen-Agent und Google ADK.






