

In diesem Artikel erfahren Sie:
- Was CloakBrowser ist, was es bietet und wie es funktioniert.
- Was die Bright Data Browser API ist, welche Funktionen sie bietet und welche Infrastrukturvorteile sie mitbringt.
- Wie die beiden Lösungen Stealth-Browsing und Fingerprint-Management angehen.
- Die verschiedenen Infrastrukturmodelle, auf die sich die beiden Tools stützen.
- Die unterstützten Integrationen und Tools, mit denen sowohl CloakBrowser als auch die Browser API verwendet werden können.
- Eine abschließende Vergleichstabelle CloakBrowser vs. Bright Data Browser API auf einen Blick.
Legen wir los!
Überblick über CloakBrowser
Bevor wir in den Vergleich CloakBrowser vs. Bright Data Browser API einsteigen, sollten Sie verstehen, was CloakBrowser zu bieten hat.
Was ist CloakBrowser?

CloakBrowser ist ein Open-Source-Stealth-Browser, der auf einer angepassten Chromium-Binärdatei basiert. Er fungiert als Browser-Automatisierungs- und Web-Scraping-Lösung.
Im Gegensatz zu herkömmlichen Stealth-Plugins, die auf JavaScript-Injektionen, Browser-Patches oder Konfigurationsanpassungen setzen, modifiziert CloakBrowser Browser-Fingerprints direkt auf der Ebene des Chromium-C++-Quellcodes. Dieser Ansatz zielt darauf ab, ein konsistenteres und realistischeres Browserverhalten zu erzeugen.
Dieses Tool funktioniert als direkter Ersatz für Playwright und Puppeteer. Es umfasst integriertes Fingerprint-Management, Simulation menschenähnlicher Interaktionen, Proxy-Unterstützung, persistente Browserprofile und Integrationen mit KI-Agenten und Automatisierungs-Frameworks.
In den letzten Wochen hat das Projekt erheblich an Dynamik gewonnen. Es wuchs von einigen tausend GitHub-Sternen auf mehr als 21.200 Sterne zum Zeitpunkt der Erstellung dieses Artikels.
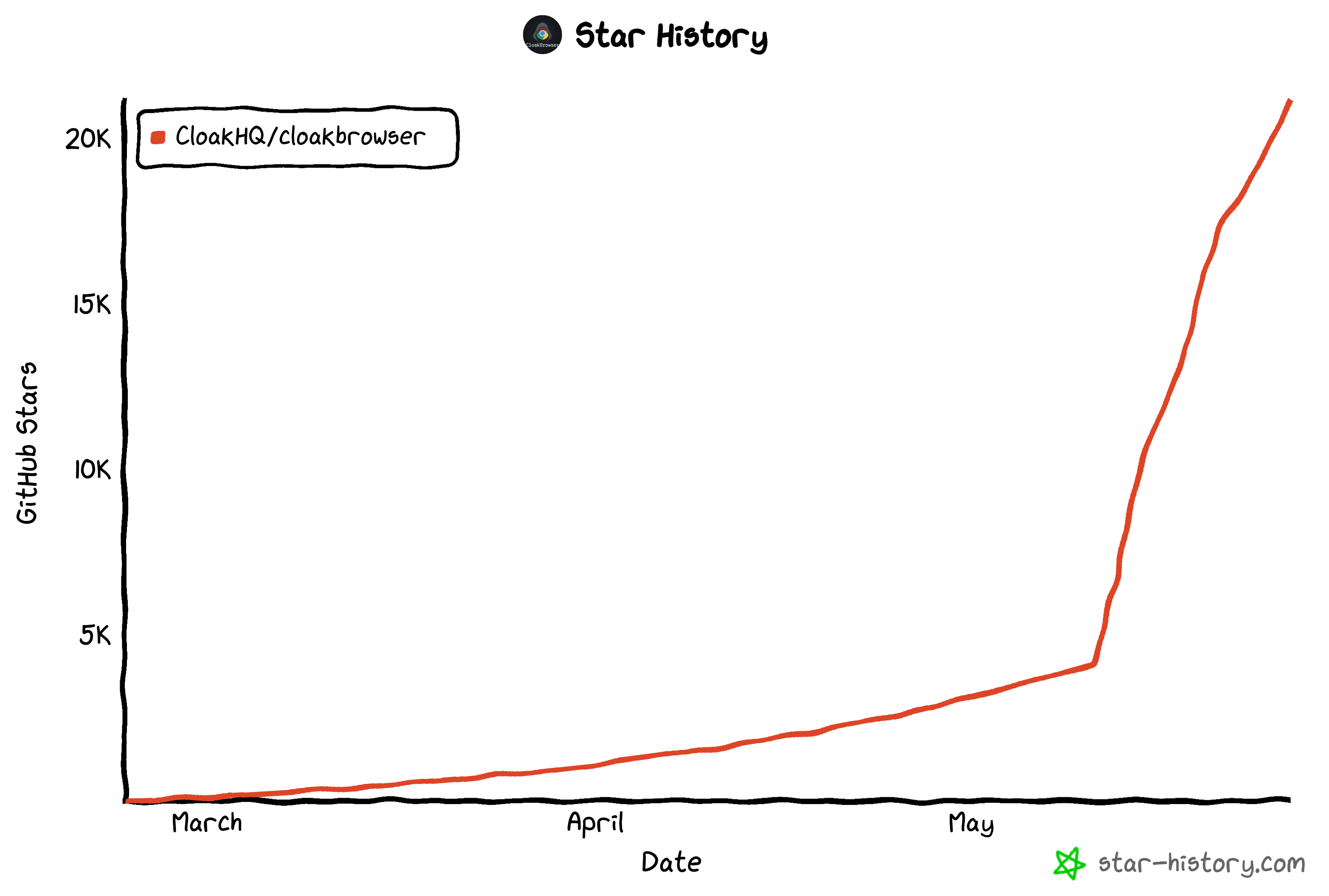
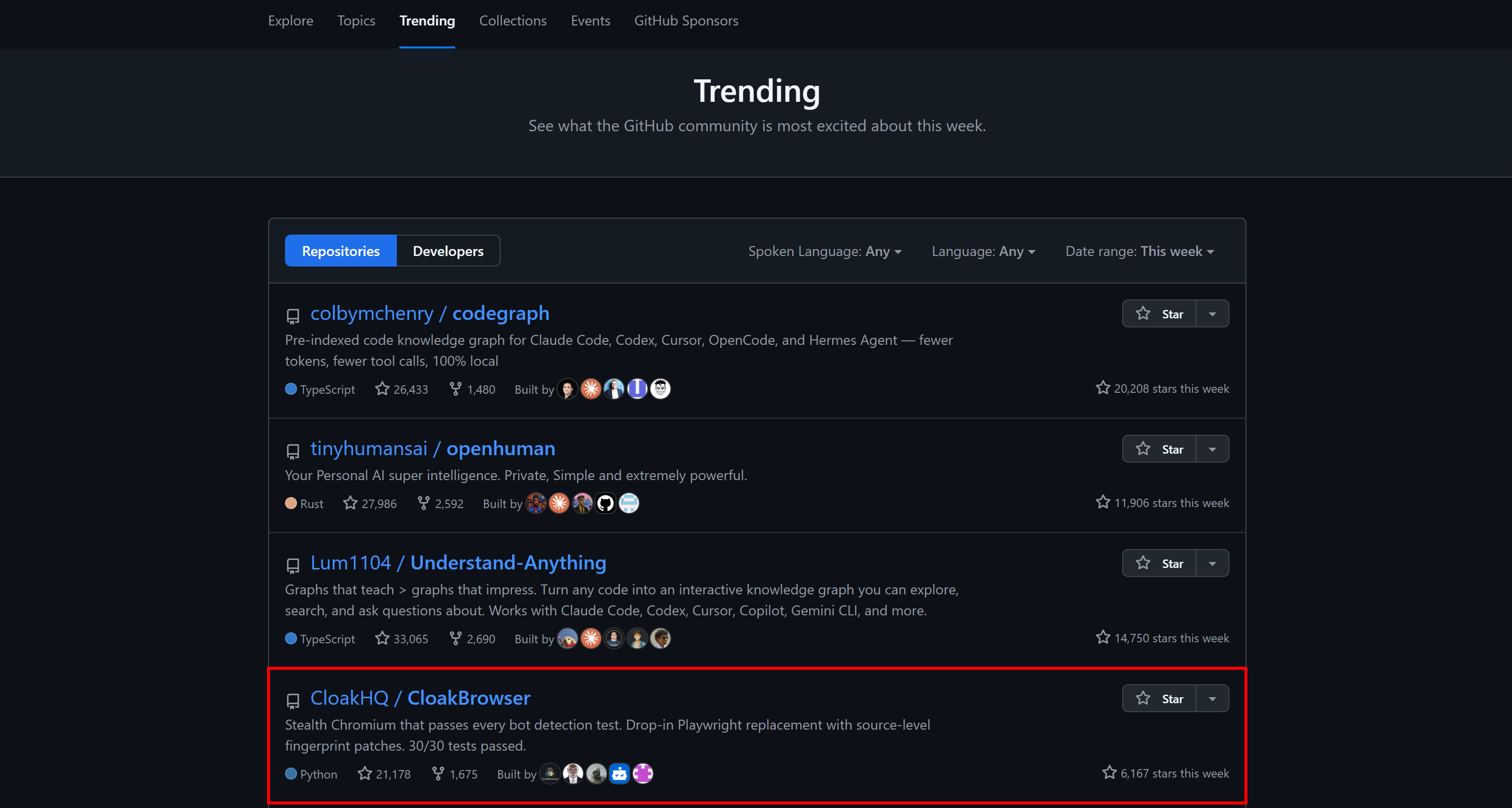
Es erschien sogar in GitHubs wöchentlich trendenden Repositories auf der gesamten Plattform:
Hauptfunktionen
Dies sind die wichtigsten Funktionen des CloakBrowser-Projekts:
- Fingerprint-Patching auf Quellcode-Ebene in Chromium: Wendet 58+ C++-Modifikationen an GPU, Canvas, WebGL, Audio, Schriftarten und Timing-Signalen direkt in der Browser-Engine an.
- Automatisches Binär-Management: Lädt automatisch den angepassten Chromium-Build für Sie herunter, ohne manuelle Einrichtung erforderlich.
- Direkter Ersatz für Playwright und Puppeteer: Behält dieselbe API bei, sodass bestehender Automatisierungscode nur durch Änderung weniger Codezeilen weiter funktioniert.
- Menschenähnliche Interaktions-Engine: Simuliert realistische Mausbewegungen, Tastatur-Timing, Scroll-Verhalten und Klick-Dynamik über ein einzelnes
humanize=True-Flag. - Erweiterte Proxy-Unterstützung: Unterstützt HTTP- und SOCKS5-Proxys mit Authentifizierung sowie optionale GeoIP-basierte Zeitzone und Locale-Anpassung.
- Persistente Browserprofile: Kann Cookies,
localStorageund Cache sitzungsübergreifend beibehalten, um langlebige authentifizierte Workflows zu ermöglichen. - Fingerprint-Steuerungssystem: Verwendet deterministische oder zufällige Seeds, um konsistente oder rotierende Browser-Identitäten über Sitzungen hinweg zu generieren.
- Hohe Erfolgsrate bei Bot-Erkennung: Besteht in Benchmark-Tests wichtige Systeme wie reCAPTCHA v3, Cloudflare Turnstile, FingerprintJS und BrowserScan.
Wie CloakBrowser funktioniert
CloakBrowser funktioniert als dünne Automatisierungsschicht auf einem angepassten Chromium-basierten Browser. So funktioniert es:
- Sie installieren CloakBrowser über
pipodernpm. - Beim ersten Start wird automatisch eine vorkompilierte Chromium-Binärdatei für Ihr Betriebssystem heruntergeladen.
- Jede nachfolgende Sitzung startet in diesem angepassten Browser.
- Ihr bestehender Code bleibt unverändert und verwendet weiterhin Standard-Playwright- oder Puppeteer-APIs.
Hinweis: CloakBrowser kann auch über Docker eingerichtet und über Standard-Tools wie Playwright, Puppeteer, Selenium oder ein beliebiges CDP-kompatibles Framework verbunden werden.
Die Chromium-Binärdatei enthält Dutzende von Low-Level-C++-Modifikationen, die Browser-Fingerprint-Signale anpassen oder maskieren. Sie reduziert auch die Automatisierungserkennung durch Änderung interner Browser- und CDP-Level-Signale. Diese Änderungen werden direkt in die heruntergeladenen Chromium-Binärdateien kompiliert.
Eine wichtige Konsequenz dieses Designs ist, dass nur die Wrapper-Schicht Open Source ist, während die Browser-Binärdatei als vorkompiliertes Artefakt verteilt wird. Dies schränkt die direkte Inspektion oder das Reverse Engineering der Fingerprinting-Logik ein (durch Unternehmen hinter WAFs und anderen Anti-Bot-Lösungen), da die kritischen Modifikationen in kompiliertem Code eingebettet sind.
Erste Schritte
Beginnen Sie mit der Installation von CloakBrowser. In Python führen Sie aus:
pip install cloakbrowserOder in einem Node.js-Projekt installieren Sie es mit:
npm install cloakbrowserNach der Installation können Sie die Standard-Playwright- oder Puppeteer-APIs verwenden. Nachfolgend ein Playwright-ähnliches Python-Beispiel:
# pip install cloakbrowser
from cloakbrowser import launch
browser = launch()
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Erwartetes Ergebnis: "Example Domain"
browser.close()Oder äquivalent in JavaScript:
// npm install cloakbrowser
import { launch } from "cloakbrowser";
const browser = await launch();
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Erwartetes Ergebnis: "Example Domain"
await browser.close();Beachten Sie, dass die Automatisierungslogik identisch mit regulärem Playwright oder Puppeteer bleibt. CloakBrowser ändert nur, wie der Browser gestartet wird, nicht wie Sie Automatisierungscode schreiben.
Der einzige Unterschied ist die launch()-Funktion, die eine CloakBrowser-Sitzung initialisiert. Standardmäßig startet sie eine Headless-Browser-Sitzung mit der Standard-Stealth-Konfiguration. Für mehr Kontrolle sehen Sie sich die verfügbaren Argumente der launch()-Funktion an.
Wenn Sie Ihr Skript zum ersten Mal ausführen, führt CloakBrowser folgendes aus:
- Erkennt Ihr Betriebssystem.
- Lädt eine vorkompilierte Chromium-basierte Binärdatei für Ihre Plattform herunter.
- Speichert sie lokal für die spätere Verwendung im Cache.
Von diesem Punkt an startet jeder launch()-Aufruf die angepasste Chromium-Binärdatei über Playwright oder Puppeteer.
Preisgestaltung
CloakBrowser hat keine Abonnementgebühren, Nutzungslimits oder kostenpflichtige Stufen. Sie können es also frei installieren und verwenden. Die tatsächlichen Kosten entstehen jedoch durch die umgebende Infrastruktur.
Für eine skalierbare Nutzung müssen Sie auf Integrationen mit vertrauenswürdigen Drittanbieter-Proxy-Anbietern zurückgreifen. Proxys sind für verteilte Automatisierungsworkloads unerlässlich und können je nach Traffic-Volumen und geografischer Abdeckung zu den Hauptbetriebskosten werden.
Außerdem wird CloakBrowser in Produktionsumgebungen häufig auf mehreren Servern mit Docker bereitgestellt. Dies ermöglicht horizontale Skalierung, bringt jedoch auch zusätzlichen Aufwand mit sich, einschließlich Container-Orchestrierung, Instanzverwaltung, Monitoring und laufender Wartung.
Obwohl CloakBrowser selbst kostenlos ist, steigen Betriebskomplexität und Infrastrukturkosten mit zunehmender Skalierung.
Einführung in die Browser API von Bright Data
Setzen Sie den Vergleich CloakBrowser vs. Bright Data Browser API fort, indem Sie tiefer in die Browser API eintauchen.
Was ist die Browser API?
Bright Datas Browser API ist eine cloud-verwaltete Browser-Automatisierung, optimiert für groß angelegte, produktionsreife Web-Interaktion und Datenerfassung.
Anstatt lokale Browser-Infrastruktur zu betreiben und zu warten, ermöglicht sie die Verbindung Ihrer bestehenden Playwright-, Puppeteer- oder Selenium-Skripte mit vollständig gehosteten Stealth-Browsern. Diese Browser werden automatisch skaliert und in der Cloud gewartet.
Im Kern ist sie für Szenarien konzipiert, in denen Zuverlässigkeit, Unblocking-Fähigkeit und Skalierung entscheidend sind. Häufige Anwendungsfälle sind dynamisches Web-Scraping, automatisiertes QA/Testing, Lead-Generierung und mehr.
Sie wird durch Bright Datas riesiges Proxy-Netzwerk mit 400 Mio.+ IPs unterstützt, was starke Geo-Verteilung, IP-Rotation sowie unbegrenzte Parallelität und Skalierbarkeit ermöglicht. Die Lösung verarbeitet CAPTCHA-Lösung, Fingerprinting, Sitzungsverwaltung und JavaScript-Rendering sofort einsatzbereit. Dank dieser Funktionen erzielt sie hohe Erfolgsraten bei stark geschützten Websites.
Die Browser API unterstützt alle CDP-kompatiblen Tools sowie moderne KI-Agenten-Workflows über Web MCP. Das bedeutet, sie ist auch für autonome Agenten geeignet, die in Echtzeit browsen, klicken und Informationen extrahieren müssen.
Hauptfunktionen
Dies sind die wichtigsten Funktionen der Bright Data Browser API:
- Cloud-verwaltete Browser-Infrastruktur: Vollständig gehostete Browser laufen in der Cloud, was lokale Einrichtung, Proxy-Verwaltung und Infrastrukturwartung überflüssig macht.
- Kompatibilität mit Playwright, Puppeteer, Selenium: Die direkte Integration mit den meisten Browser-Automatisierungs-Frameworks ermöglicht die Wiederverwendung bestehender Skripte mit minimalen Änderungen und eine schnelle Migration.
- Integrierte CAPTCHA-Lösung: Erkennt und löst CAPTCHAs und Challenge-Response-Systeme automatisch, reduziert Scraping-Unterbrechungen und macht externe Dienste überflüssig.
- Zugang zum groß angelegten Proxy-Netzwerk: Nutzt einen Residential-IP-Pool mit 400 Mio.+ Adressen für geo-verteilte Anfragen und reduziert Blockierungen und Erkennung.
- Browser-Fingerprint-Emulation: Simuliert echte Benutzer-Browser-Eigenschaften, um das Erkennungsrisiko zu reduzieren und die Zuverlässigkeit gegenüber fortgeschrittenen Anti-Bot-Systemen zu verbessern.
- Auto-Skalierungs-Infrastruktur: Stellt Browser-Sitzungen dynamisch nach Bedarf bereit und unterstützt hohe Parallelitäts-Workloads ohne manuelle Skalierung.
- Chrome DevTools-Debugging: Ermöglicht die Sitzungsinspektion mit DevTools, sodass Sie Logs, Netzwerkanfragen und Browser-Verhalten während der Scraping-Ausführung überwachen können.
- Geolokalisierungs-Targeting: Ermöglicht präzises Targeting auf Länder-, Stadt- oder ASN-Ebene für den Zugriff auf lokalisierte Inhalte, Tests regionaler Erfahrungen und genaues Scraping geo-eingeschränkter Daten.
- Automatische Wiederherstellung: Stellt Sitzungen wieder her, um die Kontinuität zu gewährleisten, reduziert Ausfallzeiten und verbessert die Robustheit in instabilen oder blockierten Umgebungen.
- KI-Agenten-Kompatibilität (über Web MCP): Unterstützt autonome Browser-Agenten, die in der Lage sind, zu navigieren, zu klicken, zu scrollen und Web-Daten zu extrahieren, und ermöglicht so fortgeschrittene KI-gesteuerte Automatisierungs-Workflows.
- Datenintegritäts-Validierung: Stellt sicher, dass extrahierte Daten durch integrierte Validierungsmechanismen konsistent und zuverlässig sind, was die Qualität für nachgelagerte Analysen und Produktions-Pipelines verbessert.
Weitere Informationen finden Sie in der offiziellen Dokumentation.
Wie die Browser API funktioniert
Die Browser API funktioniert, indem Ihre Browser-Automatisierungsskripte in vollständig verwalteten cloud-basierten Browsern ausgeführt werden. Sie verbinden sich über einen einzelnen CDP-Endpunkt, und Ihr Code wird remote in echten Browser-Umgebungen ausgeführt. Im Grunde interagieren Sie mit dem Browser, als wäre er lokal, aber Ausführung, Skalierung und Unblocking werden vollständig verwaltet und erfolgen in der Cloud.
Im Hintergrund verwaltet die Plattform die gesamte Infrastrukturkomplexität. Sie verwaltet automatisch Proxy-Rotation, Browser-Fingerprinting, Sitzungsverarbeitung, CAPTCHA-Lösung und mehr. Jede Sitzung läuft in einer skalierbaren Cloud-Umgebung, die Ressourcen dynamisch nach Bedarf zuweisen kann. Das bedeutet hohe Parallelität ohne manuelle Einrichtung.
Erste Schritte
Zunächst müssen Sie eine Browser-API-Zone in Ihrem Bright Data-Konto konfigurieren. Falls Sie dies noch nicht getan haben, erstellen Sie ein Bright Data-Konto. Andernfalls melden Sie sich einfach an.
Wählen Sie im Bright Data Control Panel die Option “Web Access > Create an API”:
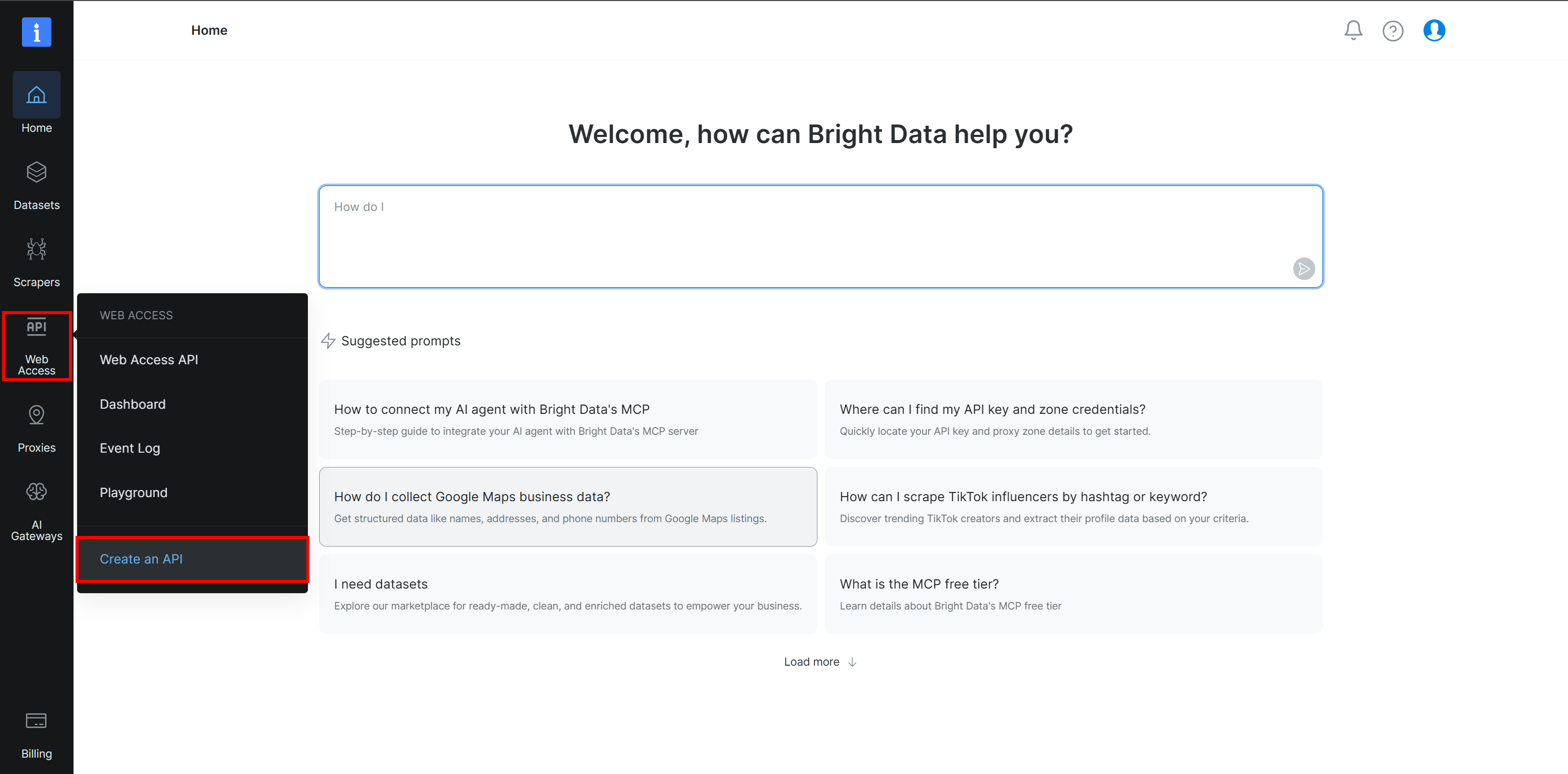 Create an API'”/>
Create an API'”/>Wählen Sie auf der Seite “Web Access API > Add API” den Typ “Browser API”:
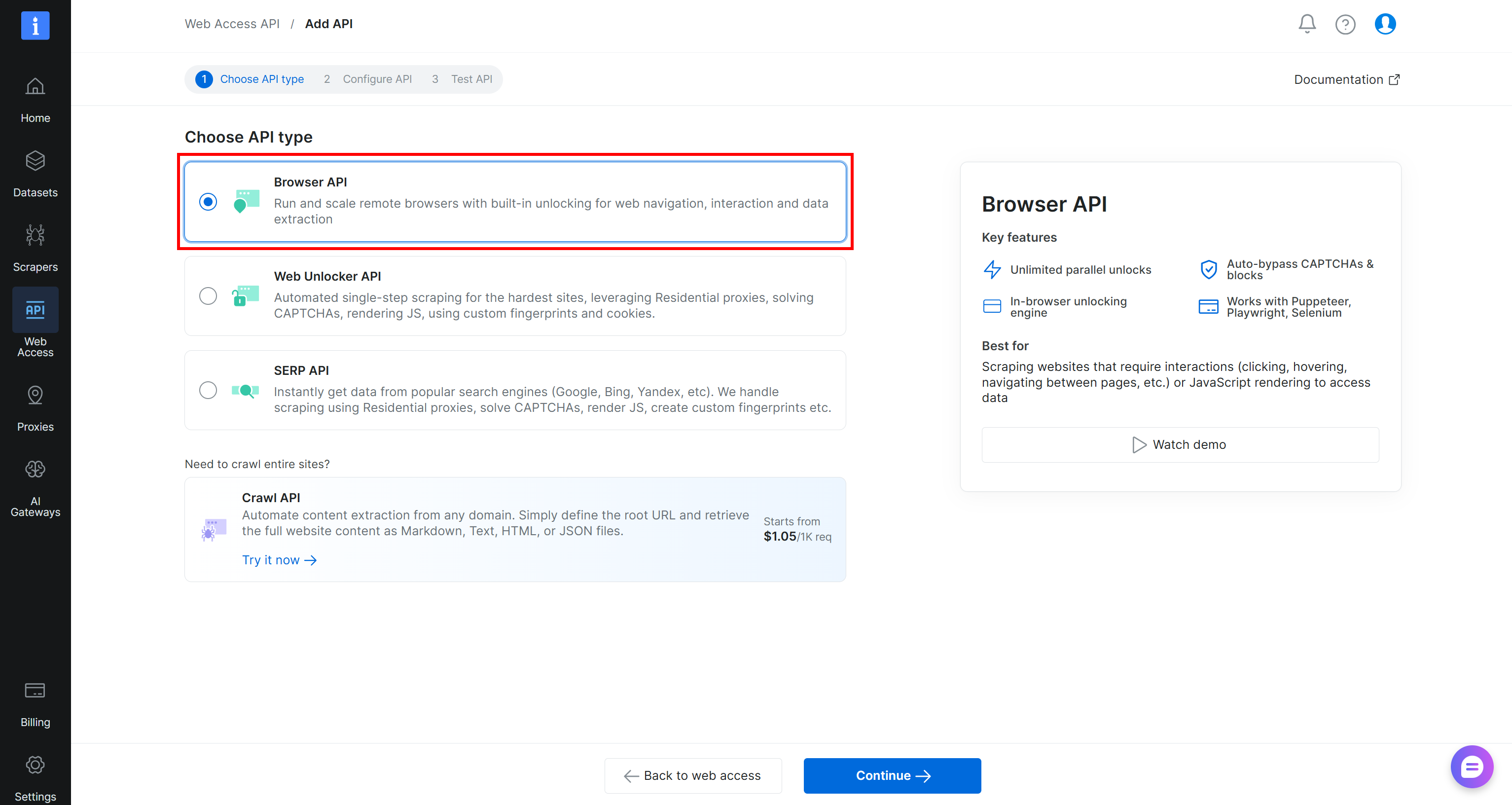
Folgen Sie dem Assistenten, geben Sie Ihrer Browser-API-Zone einen Namen (z.B. browser_api) und konfigurieren Sie sie nach Bedarf. Schließen Sie den Einrichtungsablauf ab, und Sie erhalten Ihre Puppeteer-, Playwright- und Selenium-Verbindungs-URLs:
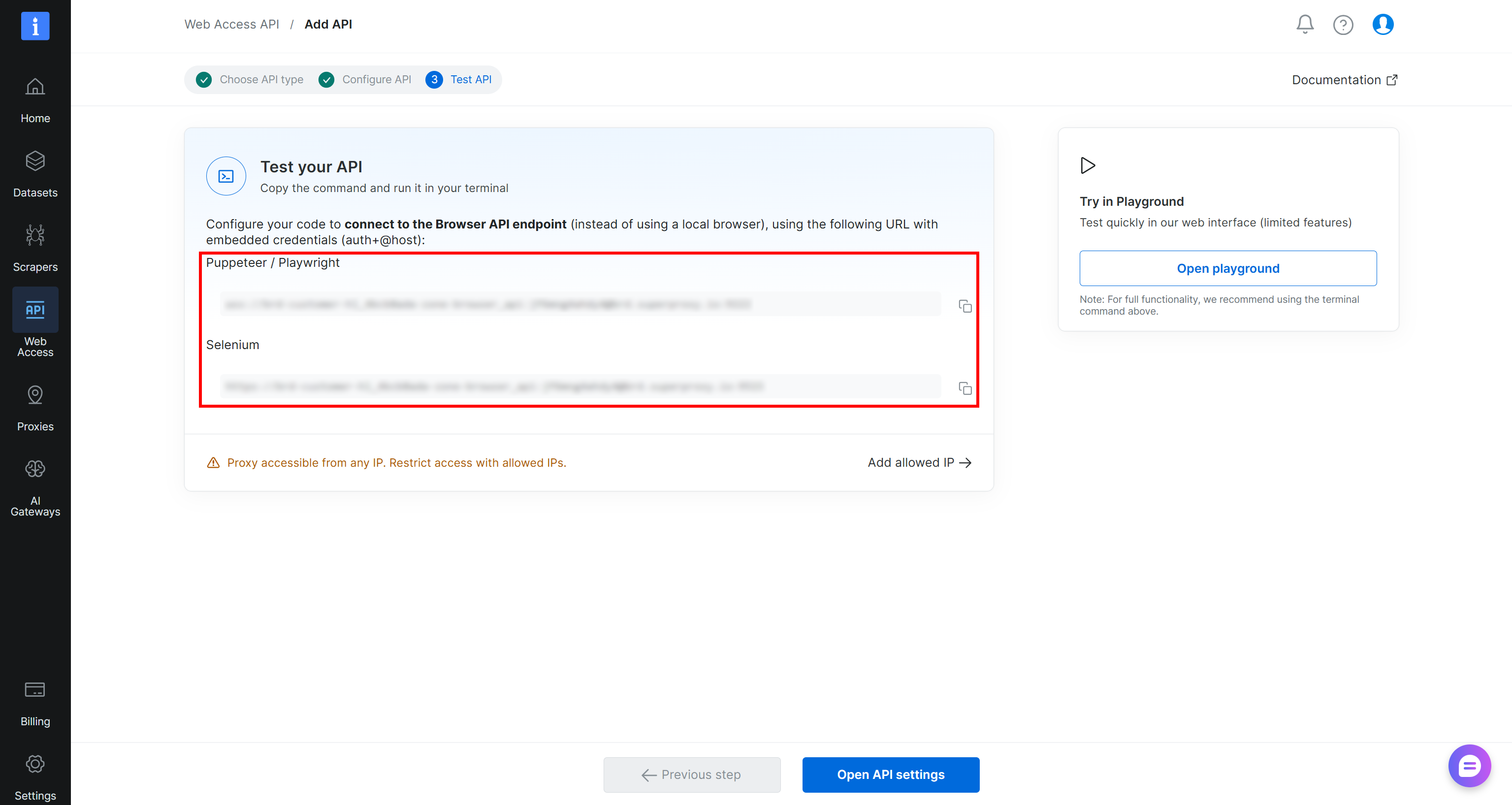
Drücken Sie dann die Schaltfläche “Open API settings”, um auf den Browser API Playground zuzugreifen. Hier finden Sie gebrauchsfertige Snippets für die Integration mit gängigen Browser-Automatisierungs-Frameworks und Programmiersprachen:
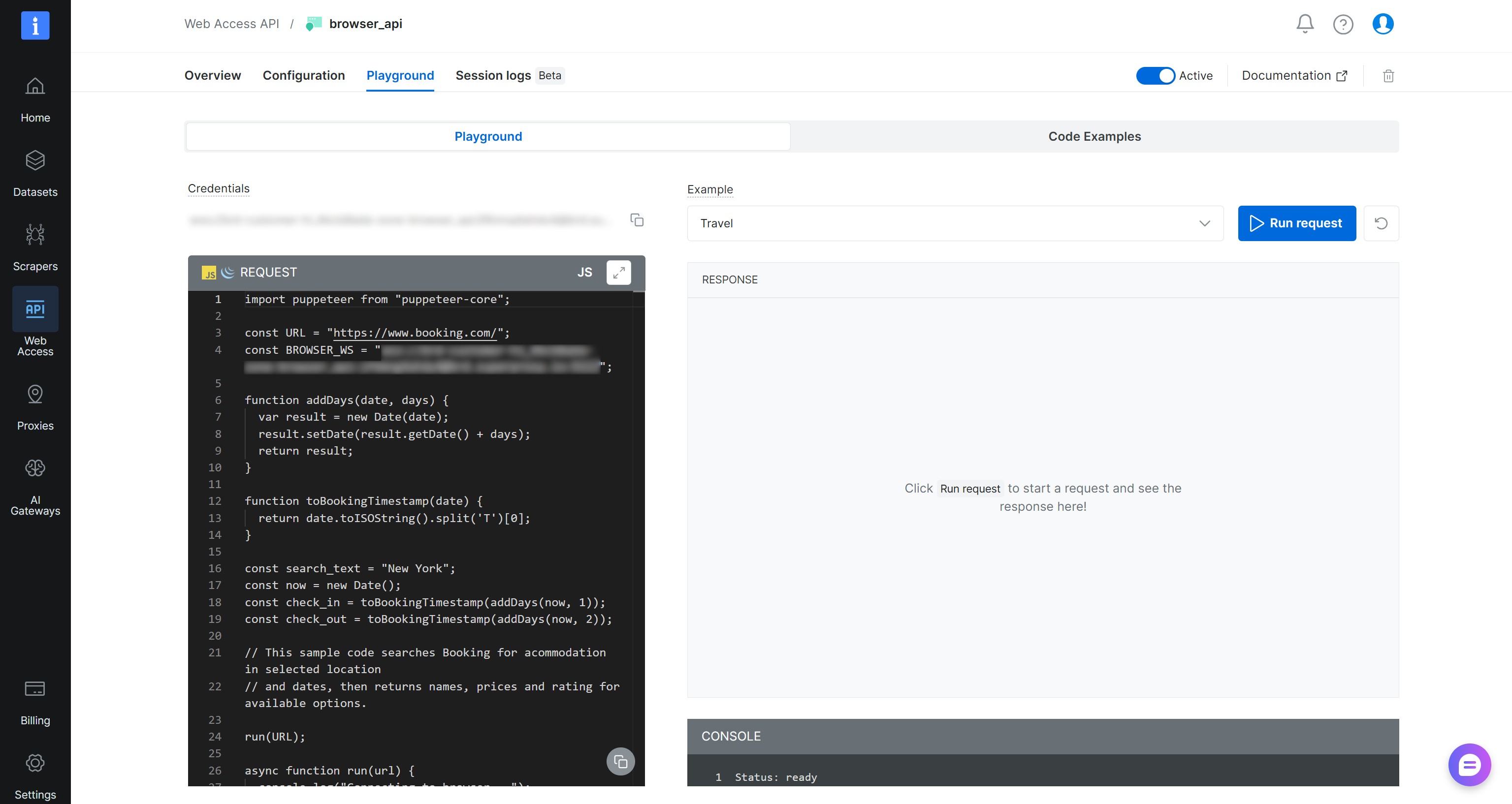
Verwenden Sie die Remote-Verbindungs-URL, um über CDP in Playwright mit Python wie folgt eine Verbindung herzustellen:
# pip install playwright
from playwright.sync_api import sync_playwright
# Ersetzen Sie dies durch Ihre Browser-API-Verbindungs-URL
BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222"
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(BROWSER_API_CDP)
page = browser.new_page()
page.goto("https://example.com")
print(page.title()) # Erwartetes Ergebnis: "Example Domain"
browser.close()Oder äquivalent in JavaScript:
// npm install playwright
const { chromium } = require("playwright");
# Ersetzen Sie dies durch Ihre Browser-API-Verbindungs-URL
const BROWSER_API_CDP = "wss://brd-customer-USER-zone-BROWSER_API_ZONE_NAME:[email protected]:9222";
(async () => {
const browser = await chromium.connectOverCDP(BROWSER_API_CDP);
const page = await browser.newPage();
await page.goto("https://example.com");
console.log(await page.title()); // Erwartetes Ergebnis: "Example Domain"
await browser.close();
})();Die Automatisierungslogik bleibt identisch mit Standard-Playwright oder Puppeteer. Die einzige Änderung ist, wie Sie sich mit dem Browser verbinden. Durch die Verwendung von connect_over_cdp()/connectOverCDP() leiten Sie die Ausführung an vollständig verwaltete Browser-API-Cloud-Instanzen um (anstatt auf einen lokalen Browser zu setzen).
Preisgestaltung
Die Browser API basiert auf einem Bezahlung-pro-Traffic-Modell, bei dem nur für die GB an Daten abgerechnet wird, die durch die Cloud-Browser-Infrastruktur übertragen werden. Im Detail folgt die Browser-API-Preisgestaltung diesen Plänen:
| Plan | Preis |
|---|---|
| Bezahlung pro Nutzung (ohne Verpflichtung, nutzungsbasierte Abrechnung) | $8/GB |
| 71 GB inklusive | $499/Monat ($7/GB) |
| 166 GB inklusive | $999/Monat ($6/GB) |
| 399 GB inklusive | $1.999/Monat ($5/GB) |
Es fallen keine Gebühren für Browser-Instanzen, Ausführungszeit oder Parallelität an. Alle Länder werden zum gleichen Tarif abgerechnet, was die Preisgestaltung über Geographien hinweg vorhersehbar macht. Die einzige Ausnahme sind Premium-Domains, die aufgrund zusätzlicher Unblocking-Komplexität höhere Kosten pro GB verursachen.
Hinweis: Sie können die Browser API sowie alle anderen Bright Data-Produkte auch kostenlos über eine Testversion testen.
Da die Preisgestaltung direkt vom Traffic abhängt, ist die Optimierung der Bandbreite für Kosteneffizienz und Leistung wichtig. Lesen Sie den offiziellen Leitfaden zur Bandbreitenoptimierung.
Unterschiedliche Ansätze beim Stealth-Browsing
Sowohl CloakBrowser als auch die Browser API zielen darauf ab, Bot-Erkennung zu reduzieren. Dennoch verfolgen sie zwei grundlegend unterschiedliche Ansätze beim Stealth-Browsing und Fingerprint-Management.
CloakBrowser erreicht die Umgehung von Anti-Bot-Maßnahmen durch eine modifizierte, lokal laufende Chromium-Binärdatei. Es generiert beim Start einen kohärenten Browser-Fingerprint und täuscht erkennbare Signale wie GPU, Bildschirmgröße, Schriftarten, Canvas, WebGL, Audio und Hardware-Spezifikationen vor.
Sie können die Identitätspersistenz auch über deterministische Fingerprint-Seeds steuern und spezifische Attribute über Launch-Flags feinabstimmen. Dies macht CloakBrowser besonders geeignet, wenn Sie präzise Fingerprint-Kontrolle und reproduzierbare Browser-Identitäten über Sitzungen hinweg benötigen.
Im Gegensatz dazu liefert die Browser API Stealth durch vollständig verwaltete Cloud-Browser. Anstatt Low-Level-Fingerprint-Flags freizulegen, verwaltet sie das Browser-Fingerprinting im Hintergrund. Gleichzeitig stellt sie Konfigurationen und benutzerdefinierte CDP-Aktionen zur Steuerung erweiterter Verhaltensweisen bereit. Diese ermöglichen die Emulation bestimmter Geräte, Änderung der Geolokalisierung, Blockierung von Anzeigen, Konfiguration der CAPTCHA-Lösung und mehr.
Die Infrastrukturlücke
CloakBrowser bietet Ihnen eine stealth-fähige lokale Chromium-Binärdatei. Alles darum herum bleibt jedoch Ihre Verantwortung. Das bedeutet, wenn Sie Automatisierung in großem Maßstab betreiben möchten, müssen Sie Maschinen bereitstellen, Browser-Parallelität verwalten, Proxys konfigurieren und rotieren, Fehler überwachen und vieles mehr.
Sicher, es werden Docker-Images bereitgestellt, die die CloakBrowser-Umgebung und Browser-Server zur Verbindung über CDP freigeben. Aber von einem Docker-Image zu einer wirklich skalierbaren Browser-Infrastruktur zu gelangen, ist eine andere Herausforderung. Dies erfordert Engineering-Kenntnisse, Infrastruktur-Expertise und ein Budget, das nicht alle Teams haben.
Bright Datas Browser API verfolgt einen völlig anderen Ansatz. Anstatt Ihnen einen zu verwaltenden Browser zu geben, bietet sie eine vollständig verwaltete Browser-Infrastruktur in der Cloud. Proxy-Rotation, Browser-Orchestrierung, Skalierung, Parallelität und Monitoring werden alle verwaltet. Sie verbinden einfach Ihr Browser-Automatisierungsskript oder Ihren KI-Agenten mit einem Remote-Endpunkt, und Bright Data übernimmt die gesamte Betriebskomplexität für Sie.
Insbesondere wird die Browser API durch Bright Datas SLA-gesicherte unternehmenstaugliche Infrastruktur unterstützt. Sie bietet 99,99% Betriebszeit, unbegrenzte Parallelität, 99,95% Erfolgsrate, unbegrenzte Skalierbarkeit und Einhaltung von DSGVO, CCPA und anderen Datenschutz- und Sicherheitsvorschriften.
Diese Unterscheidung ist der Kernpunkt des gesamten Vergleichs CloakBrowser vs. Browser API. CloakBrowser ist zweifellos ein großartiges Tool. Dennoch ist die Browser API das einzige der beiden, das wirklich als vollständige Browser-Automatisierungsinfrastruktur betrachtet werden kann.
Das ist auch der größte Vorteil der Browser API im Vergleich zu CloakBrowser. Indem sie den Betriebsaufwand von Anfang an reduziert, können Sie sich auf die Automatisierungslogik konzentrieren, die am wichtigsten ist.
Unterstützte Integrationen
CloakBrowser unterstützt nativ Playwright- und Puppeteer-Skripte. Es erfordert jedoch eine zusätzliche Abhängigkeit (cloakbrowser), während es weiterhin auf Standard-Playwright-Systemabhängigkeiten angewiesen ist.
Über native APIs hinaus stellt CloakBrowser einen CDP-kompatiblen Browser über eine Docker-basierte Server-Einrichtung bereit. Auf diese Weise kann es mit jedem CDP-konformen Tool integriert werden. Es unterstützt auch nativ einige KI-Agenten-Frameworks wie CrawAI, Browser Use und LangChain.
Die Browser API unterstützt Playwright, Puppeteer und Selenium, jedoch ohne zusätzliche Abhängigkeiten. Darüber hinaus ist sie vollständig kompatibel mit allen CDP-basierten Tools, einschließlich Browser Use, Stagehand, Agent Browser und ähnlichen KI-basierten Automatisierungs-Frameworks.
Außerdem wird Bright Datas Browser API über Web MCP-Tools bereitgestellt. Diese umfassen:
| Tool | Beschreibung |
|---|---|
scraping_browser_navigate |
Öffnet oder verwendet eine Sitzung und navigiert zu einer URL, setzt das Netzwerk-Tracking zurück |
scraping_browser_go_back |
Navigiert zurück und gibt aktualisierte URL und Titel zurück |
scraping_browser_go_forward |
Navigiert vorwärts und gibt aktualisierte URL und Titel zurück |
scraping_browser_snapshot |
Erstellt einen ARIA-Snapshot mit interaktiven Element-Refs |
scraping_browser_click_ref |
Klickt auf ein Element anhand seiner ARIA-Ref |
scraping_browser_screenshot |
Erstellt einen Seiten- oder Vollseiten-Screenshot |
scraping_browser_wait_for_ref |
Wartet auf Element-Sichtbarkeit per ARIA-Ref |
scraping_browser_get_text |
Extrahiert sichtbaren Text aus dem Seiteninhalt |
scraping_browser_get_html |
Ruft den HTML-Inhalt der Seite ab |
scraping_browser_scroll |
Scrollt zum Ende der Seite |
scraping_browser_scroll_to_ref |
Scrollt zu einem bestimmten referenzierten Element |
Die MCP-Unterstützung macht die Browser API zu einem agentischen Browser und erweitert die Kompatibilität auf ein breites Ökosystem von KI-Agenten-Frameworks. Zu den unterstützten Lösungen gehören LangChain, Agno, OpenClaw, LlamaIndex, CrewAI, Dify, Mastra, Claude Code, Codex, Claude Desktop und 70+ andere.
Bright Data Browser API vs. CloakBrowser: Direkter Vergleich
Vergleichen Sie die beiden Lösungen in der abschließenden Tabelle CloakBrowser vs. Bright Data Browser API:
| Aspekt | CloakBrowser | Bright Data Browser API |
|---|---|---|
| Kernkonzept | Lokale Stealth-Chromium-Binärdatei | Vollständig verwaltete Cloud-Browser-Infrastruktur |
| Art | Open-Source-Wrapper + proprietäre gepatchte Browser-Binärdateien | Proprietär |
| Abhängigkeiten | Erfordert cloakbrowser + Systemabhängigkeiten |
Keine zusätzlichen Abhängigkeiten |
| CDP-Unterstützung | ✔️ (über Docker-Server) | ✔️ (nativer Cloud-CDP-Endpunkt) |
| Stealth-Ansatz | Fingerprint-Patching auf Quellcode-Ebene in Chromium | Verwaltetes Fingerprinting |
| Fingerprint-Kontrolle | Hohe Kontrolle über Seeds und Launch-Flags | Steuerung über CDP-Aktionen zur Geräteemulatierung |
| Proxy-Verwaltung | Externer Proxy-Anbieter erforderlich | Integriertes Proxy-Netzwerk mit 400 Mio.+ IPs |
| CAPTCHA-Behandlung | Nicht nativ | Integrierte CAPTCHA-Lösung |
| Framework-Unterstützung | Playwright, Puppeteer, CDP-kompatible Tools | Playwright, Puppeteer, Selenium, CDP-kompatible Tools |
| KI-Agenten-Integration | Unterstützt einige KI-Frameworks (Browser Use, LangChain, CrawAI) | Breites Ökosystem über Web MCP (LangChain, LlamaIndex, CrewAI, Agno, Claude und 70+ andere) |
| Infrastrukturverantwortung | Vom Benutzer verwaltet | Vollständig von Bright Data verwaltet |
| Skalierung | Manuelle horizontale Skalierung erforderlich | Automatische elastische Skalierung mit unbegrenzter Parallelität |
| Betriebszeit-Garantien | Abhängig von der Benutzer-Infrastruktur | 99,99% SLA-gesicherte Betriebszeit |
| Kostenmodell | Software kostenlos, Infrastruktur separate Kosten | Bezahlung-pro-GB Traffic-basierte Preisgestaltung |
Abschließendes Urteil
Sowohl CloakBrowser als auch die Browser API sind leistungsstarke, stealth-fähige Browser-Automatisierungslösungen. CloakBrowser ist mit seiner Open-Source-Natur am besten geeignet, wenn Sie maximale lokale Kontrolle über Browser-Fingerprints und eine vollständig selbstverwaltete Infrastruktur benötigen. Es ist besonders nützlich für experimentelle oder hochgradig angepasste Setups.
Für Scraping im Produktionsmaßstab, zuverlässige Automatisierung oder Integration mit KI-Agenten sollte Bright Datas Browser API die erste Wahl sein. Ihre vollständig verwaltete Infrastruktur, integrierte Unblocking-Fähigkeiten und elastische Skalierung reduzieren den Betriebsaufwand. Das macht sie deutlich praktischer für Teams, die sich auf die Automatisierungslogik konzentrieren möchten, anstatt auf das Infrastrukturmanagement.
Fazit
In diesem Vergleichsartikel Bright Data Browser API vs. CloakBrowser haben Sie gelernt, was beide Tools sind, welche Funktionen sie bieten und wie sie funktionieren, sowie wie viel sie kosten.
CloakBrowser ist eine Open-Source-Browser-Automatisierungslösung, die hervorragend ist, wenn Sie Low-Level-Kontrolle wünschen. Dagegen ist die Browser API besser für zuverlässigere, unternehmenstaugliche oder agentische Browser-Automatisierungsintegrationen geeignet.
Entdecken Sie die Browser API noch heute und beginnen Sie, sie in Ihre Automatisierungsskripte zu integrieren.
Erstellen Sie ein Bright Data-Konto und erkunden Sie unsere KI-fähigen Web-Daten-Automatisierungslösungen!




