

In diesem Leitfaden erfahren Sie mehr:
- Was die
Browser-Bibliothekfür die Entwicklung von KI-Agenten ist - Warum seine Möglichkeiten durch den von ihm kontrollierten Browser begrenzt sind
- Wie man diese Einschränkungen mit einem Scraping-Browser überwindet
- Wie man einen KI-Agenten erstellt, der im Browser arbeitet und dank der Integration mit Scraping Browser Blockaden vermeidet
Lasst uns eintauchen!
Was ist Browser-Nutzung?
Browser Use ist ein Open-Source-Python-Projekt, das Websites für KI-Agenten zugänglich macht. Es identifiziert alle interaktiven Elemente auf einer Webseite und ermöglicht es Agenten, sinnvolle Interaktionen mit ihnen durchzuführen. Kurz gesagt, die Browser-Use-Bibliothek ermöglicht es KI, Ihren Browser programmatisch zu steuern und mit ihm zu interagieren.
Im Einzelnen bietet es die folgenden Hauptfunktionen:
- Leistungsstarke Browser-Automatisierung: Kombiniert fortschrittliche KI mit robuster Browser-Automatisierung, um Web-Interaktionen für KI-Agenten zu vereinfachen.
- Vision + HTML-Extraktion: Integriert visuelles Verständnis und HTML-Struktur-Extraktion für eine effektivere Navigation und Entscheidungsfindung.
- Multi-Tab-Verwaltung: Kann mit mehreren Browser-Tabs umgehen und öffnet so die Tür für komplexe Workflows und parallele Aufgaben.
- Elementverfolgung: Verfolgt angeklickte Elemente mithilfe von XPath und kann die genauen Aktionen wiederholen, die von einem LLM ausgeführt werden, um Konsistenz zu gewährleisten.
- Benutzerdefinierte Aktionen: Unterstützt die Definition von benutzerdefinierten Aktionen wie das Speichern in Dateien, das Schreiben in Datenbanken, das Senden von Benachrichtigungen oder die Verarbeitung von Eingaben.
- Selbstkorrekturmechanismus: Ein eingebautes System zur Fehlerbehandlung und automatischen Wiederherstellung sorgt für eine zuverlässigere Automatisierungspipeline.
- Unterstützung für jeden LLM: Ist mit allen wichtigen LLMs über LangChain kompatibel, einschließlich GPT-4, Claude 3 und Llama 2.
Grenzen der Browser-Nutzung bei der Entwicklung von KI-Agenten
Browser Use ist eine bahnbrechende Technologie, die in der IT-Community eine beispiellose Wirkung erzielt hat. Es ist keine Überraschung, dass das Projekt in nur wenigen Monaten über 60.000 GitHub-Sterne erreicht hat:

Darüber hinaus sicherte sich das Team, das dahinter steht, eine Startfinanzierung von über 17 Millionen Dollar, was viel über das Potenzial und die Aussichten dieses Projekts aussagt.
Es ist jedoch wichtig zu wissen, dass die von Browser Use angebotenen Browser-Steuerungsmöglichkeiten nicht auf Magie beruhen. Stattdessen kombiniert die Bibliothek visuelle Eingaben mit KI-Steuerung, um Browser über Playwrightzu automatisieren – einfunktionsreiches Browser-Automatisierungs-Framework, das jedoch gewisse Einschränkungen aufweist.
Wie wir in unseren früheren Artikeln über Playwright-Web-Scraping dargelegt haben, gehen die Einschränkungen nicht vom Automatisierungs-Framework selbst aus. Ganz im Gegenteil, sie kommen von den Browsern, die es kontrolliert. Insbesondere starten Tools wie Playwright Browser mit speziellen Konfigurationen und Instrumenten, die die Automatisierung ermöglichen. Das Problem ist, dass diese Einstellungen auch für Anti-Bot-Erkennungssysteme angreifbar sind.
Dies ist ein großes Problem, insbesondere bei der Entwicklung von KI-Agenten, die mit gut geschützten Websites interagieren müssen. Nehmen wir zum Beispiel an, Sie möchten Browser Use nutzen, um einen KI-Agenten zu erstellen, der für Sie bestimmte Artikel in einen Einkaufswagen bei Amazon legt. Das ist das Ergebnis, das Sie wahrscheinlich erhalten werden:

Wie Sie sehen können, kann das Amazon Anti-Bot-System Ihre KI-Automatisierung erkennen und stoppen. Insbesondere kann die E-Commerce-Plattform das herausfordernde Amazon CAPTCHA anzeigen oder mit der Fehlerseite “Sorry, something went wrong on our end” reagieren:

In solchen Fällen ist es für Ihren KI-Agenten “Game Over”. Browser Use ist zwar ein erstaunliches und leistungsstarkes Werkzeug, aber um sein volles Potenzial auszuschöpfen, bedarf es durchdachter Anpassungen. Das ultimative Ziel ist es, die Auslösung von Anti-Bot-Systemen zu vermeiden, damit Ihre KI-Automatisierung wie gewünscht funktionieren kann.
Warum ein Scraping-Browser die Lösung ist
Jetzt werden Sie vielleicht denken: “Warum nicht einfach den Browser optimieren, der die Browser-Nutzung über Playwright steuert, und spezielle Flags verwenden, um die Wahrscheinlichkeit einer Erkennung zu verringern?” Das ist in der Tat möglich, und es ist Teil der Strategie, die von Bibliotheken wie Playwright Stealth verwendet wird.
Die Umgehung der Anti-Bot-Erkennung ist jedoch weitaus komplexer als das Umlegen von ein paar Flaggen…
Dazu gehören Faktoren wie IP-Reputation, Ratenbegrenzung, Browser-Fingerprinting und andere fortschrittliche Aspekte. Sie können ausgeklügelte Anti-Bot-Systeme nicht einfach mit ein paar manuellen Tricks überlisten. Was Sie wirklich brauchen, ist eine Lösung, die von Grund auf so konzipiert ist, dass sie für Anti-Bot- und Anti-Scraping-Systeme unauffindbar ist. Und genau hier kommt ein Scraping-Browser ins Spiel!
Scraping-Browser-Lösungen bieten unglaublich effektive Anti-Detektionsfunktionen. Welcher ist nun der beste Anti-Detect-Browser auf dem Markt? Der Scraping-Browser von Bright Data!
Scraping Browser ist ein Cloud-basierter Webbrowser der nächsten Generation, der Folgendes bietet:
- Zuverlässige TLS-Fingerabdrücke, um sich mit echten Benutzern zu vermischen
- Unbegrenzte Skalierbarkeit für hohe Scraping-Mengen
- Automatische IP-Rotation, unterstützt durch ein 400M+ IP-Proxy-Netzwerk
- Integrierte Wiederholungslogik für die ordnungsgemäße Bearbeitung fehlgeschlagener Anfragen
- CAPTCHA-Lösungsfunktionen, sofort einsatzbereit
- Ein umfassendes Anti-Bot-Bypass-Toolkit
Scraping Browser ist mit allen wichtigen Browser-Automatisierungsbibliotheken integriert – einschließlich Playwright, Puppeteer und Selenium. Es ist also vollständig kompatibel mit der Browser-Nutzung, da diese Bibliothek auf Playwright aufbaut.
Durch die Integration von Scraping Browser in Browser Use können Sie die Amazon-Sperren umgehen, auf die Sie zuvor gestoßen sind – oder ähnliche Sperren auf jeder anderen Website vermeiden.
Wie man die Browser-Nutzung mit einem Scraping-Browser integriert
In diesem Tutorial lernen Sie, wie Sie Browser Use mit dem Scraping-Browser von Bright Data integrieren können. Wir werden einen OpenAI-gesteuerten KI-Agenten erstellen, der Artikel zum Amazon-Warenkorb hinzufügen kann.
Dies ist nur ein Beispiel, das die Leistungsfähigkeit der KI-gesteuerten Browser-Automatisierung zeigt. Beachten Sie, dass der KI-Agent mit anderen Websites interagieren kann, je nach Ihren Bedürfnissen und Zielsetzungen. Wichtig ist, dass er Ihnen viel Zeit und Mühe erspart, indem er mühsame Vorgänge für Sie ausführt.
Im Einzelnen wird der Amazon-KI-Agent, den wir bauen wollen, in der Lage sein:
- Verbinden Sie sich mit Amazon über eine Remote-Scraping-Browser-Instanz, um Erkennung und Blockierungen zu vermeiden.
- Lesen Sie eine Liste von Elementen aus der Aufforderung.
- Suchen Sie, wählen Sie die richtigen Produkte aus und fügen Sie sie automatisch Ihrem Warenkorb hinzu.
- Besuchen Sie den Warenkorb und geben Sie einen Überblick über die gesamte Bestellung.
Folgen Sie den nachstehenden Schritten, um zu sehen, wie Sie Browser Use mit Scraping Browser nutzen können!
Voraussetzungen
Um diesem Tutorial folgen zu können, benötigen Sie folgende Voraussetzungen:
- Ein Bright Data-Konto.
- Ein API-Schlüssel von einem unterstützten KI-Anbieter wie OpenAI, Anthropic, Gemini, DeepSeek, Grok oder Novita.
- Grundkenntnisse der asynchronen Programmierung in Python und der Browser-Automatisierung.
Wenn Sie noch kein Konto bei Bright Data oder einem KI-Anbieter haben, brauchen Sie sich keine Sorgen zu machen. Wir zeigen Ihnen in den folgenden Schritten, wie Sie diese erstellen können.
Schritt 1: Projekt einrichten
Bevor wir beginnen, müssen Sie sicherstellen, dass Sie Python 3 auf Ihrem System installiert haben. Andernfalls laden Sie es von der offiziellen Website herunter und folgen Sie den Installationsanweisungen.
Öffnen Sie Ihr Terminal und erstellen Sie einen neuen Ordner für Ihr KI-Agentenprojekt:
mkdir browser-use-amazon-agentDer Ordner browser-use-amazon-agent enthält den gesamten Code für Ihren Python-basierten KI-Agenten.
Navigieren Sie in den Projektordner und richten Sie darin eine virtuelle Umgebung ein:
cd browser-use-amazon-agent
python -m venv venvÖffnen Sie nun den Projektordner in Ihrer bevorzugten Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind beide eine gute Wahl.
Erstellen Sie im Ordner browser-use-amazon-agent eine neue Python-Datei namens agent.py. Ihre Projektstruktur sollte nun wie folgt aussehen:
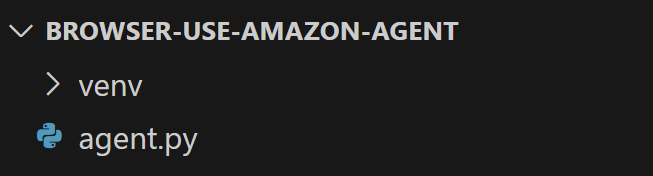
Zu diesem Zeitpunkt ist agent.py nur ein leeres Skript, aber es wird bald Ihre komplette KI-Browser-Automatisierungslogik enthalten.
Aktivieren Sie im Terminal Ihrer IDE die virtuelle Umgebung. Unter Linux/macOS führen Sie aus:
source venv/bin/activateUnter Windows führen Sie entsprechend aus:
venv/Scripts/activateSie sind bereit! Ihre Python-Umgebung ist nun bereit für den Aufbau eines KI-Agenten mit Browser Use und Scraping Browser.
Schritt #2: Einrichten von Umgebungsvariablen Lesen
Ihr Projekt wird mit Drittanbieterdiensten wie Bright Data und dem von Ihnen gewählten KI-Anbieter integriert. Anstatt API-Schlüssel und Verbindungsgeheimnisse direkt in Ihrem Python-Code zu kodieren, ist es am besten, sie aus Umgebungsvariablen zu laden.
Um diese Aufgabe zu vereinfachen, werden wir die Bibliothek python-dotenv verwenden. Installieren Sie sie in der aktivierten virtuellen Umgebung mit:
pip install python-dotenvImportieren Sie in Ihrer agent.py-Datei die Bibliothek und laden Sie die Umgebungsvariablen mit load_dotenv():
from dotenv import load_dotenv
load_dotenv()Sie können nun Variablen aus einer lokalen .env-Datei lesen. Fügen Sie sie zu Ihrem Projekt hinzu:

Mit dieser Codezeile können Sie nun in Ihrem Code auf diese Umgebungsvariablen zugreifen:
env_value = os.getenv("<ENV_NAME>")Vergessen Sie nicht, os aus der Python-Standardbibliothek zu importieren:
import osGroßartig! Sie sind nun bereit, die Geheimnisse für die Integration mit Diensten von Drittanbietern sicher aus den envs.
Schritt #3: Start mit Browser-Nutzung
Wenn Ihre virtuelle Umgebung aktiviert ist, installieren Sie browser-use:
pip install browser-useDa die Bibliothek auf mehrere Abhängigkeiten angewiesen ist, kann dies einige Minuten dauern. Haben Sie also Geduld.
Da browser-use Playwright unter der Haube verwendet, müssen Sie möglicherweise auch die Browser-Abhängigkeiten von Playwright installieren. Führen Sie dazu den folgenden Befehl aus:
python -m playwright installDadurch werden die erforderlichen Browser-Binärdateien heruntergeladen und alles eingerichtet, was Playwright benötigt, um korrekt zu funktionieren.
Importieren Sie nun die benötigten Klassen aus browser-use:
from browser_use import Agent, Browser, BrowserConfigWir werden diese Klassen in Kürze verwenden, um die Automatisierungslogik des KI-Agenten für den Browser aufzubauen.
Da browser-use eine asynchrone API bietet, müssen Sie Ihre agent.py mit einem asynchronen Einstiegspunkt initialisieren:
# other imports..
import asyncio
async def main():
# AI agent logic...
if __name__ == "__main__":
asyncio.run(main())Das obige Snippet verwendet die asyncio-Bibliothek von Python, um asynchrone Tasks auszuführen, was für die Arbeit mit Browser-Nutzung erforderlich ist.
Gut gemacht! Der nächste Schritt besteht darin, den Scraping Browser zu konfigurieren und in Ihr Skript zu integrieren.
Schritt Nr. 4: Scraping-Browser einrichten
Allgemeine Anweisungen zur Integration finden Sie in der offiziellen Dokumentation zum Scraping Browser. Andernfalls folgen Sie den nachstehenden Schritten.
Um loszulegen, erstellen Sie ein Bright Data-Konto, falls Sie dies noch nicht getan haben. Melden Sie sich an, rufen Sie das Benutzer-Dashboard auf und klicken Sie auf die Schaltfläche “Proxy-Produkte abrufen”:
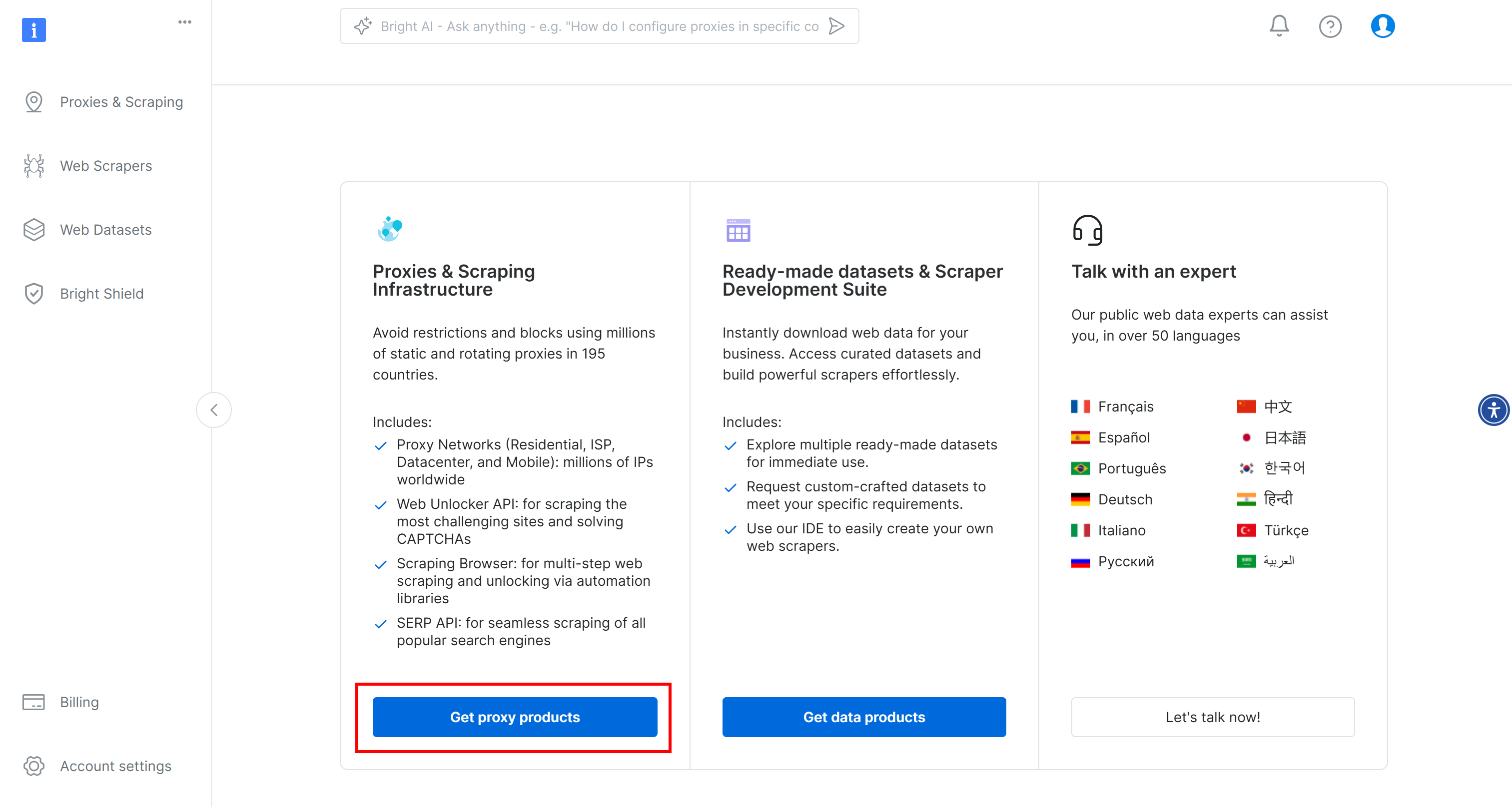
Suchen Sie auf der Seite “Proxies & Scraping Infrastructure” die Tabelle “My Zones” und wählen Sie die Zeile aus, die sich auf den Typ “Scraping Browser” bezieht:

Wenn Sie eine solche Zeile nicht sehen, bedeutet dies, dass Sie die Scraping-Browser-Zone noch nicht konfiguriert haben. Scrollen Sie in diesem Fall nach unten, bis Sie die Karte “Browser-API” finden, und drücken Sie die Schaltfläche “Get Started”:

Folgen Sie dann der Anleitung, um den Scraping-Browser zum ersten Mal zu konfigurieren.
Sobald Sie die Produktseite erreicht haben, aktivieren Sie sie, indem Sie den Ein/Aus-Schalter umlegen:

Gehen Sie nun auf die Registerkarte “Konfiguration” und stellen Sie sicher, dass sowohl “Premium-Domains” als auch “CAPTCHA Solver” aktiviert sind, um maximale Effektivität zu erzielen:

Wechseln Sie zur Registerkarte “Übersicht” und kopieren Sie die Verbindungszeichenfolge für den Playwright Scraping Browser:

Fügen Sie diese Verbindungszeichenfolge in Ihre .env-Datei ein:
SBR_CDP_URL="<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"Ersetzen Sie durch den Wert, den Sie gerade kopiert haben.
Laden Sie nun in Ihrer agent.py-Datei die Umgebungsvariable mit:
SBR_CDP_URL = os.getenv("SBR_CDP_URL")Erstaunlich! Sie können Scraping Browser jetzt innerhalb des Browsers verwenden. Bevor wir uns damit beschäftigen, sollten wir die Integrationen von Drittanbietern vervollständigen, indem wir OpenAI zu Ihrem Skript hinzufügen.
Schritt Nr. 5: Mit OpenAI loslegen
Haftungsausschluss: Der folgende Schritt konzentriert sich auf die Integration von OpenAI, aber Sie können die folgenden Anweisungen leicht für jeden anderen von Browser Use unterstützten KI-Anbieter anpassen.
Um die KI-Funktionen im Browser nutzen zu können, benötigen Sie einen gültigen API-Schlüssel eines externen KI-Anbieters. Hier werden wir OpenAI verwenden. Wenn Sie noch keinen API-Schlüssel erstellt haben, folgen Sie der offiziellen Anleitung von OpenAI, um einen zu erstellen.
Sobald Sie Ihren Schlüssel haben, fügen Sie ihn zu Ihrer .env-Datei hinzu:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"Stellen Sie sicher, dass Sie durch Ihren tatsächlichen API-Schlüssel ersetzen.
Als nächstes importieren Sie die Klasse ChatOpenAI aus langchain_openai in agent.py:
from langchain_openai import ChatOpenAIBeachten Sie, dass Browser Use sich auf LangChain verlässt, um AI-Integrationen zu handhaben. Selbst wenn Sie also langchain_openai nicht explizit in Ihrem Projekt installiert haben, steht es bereits zur Verwendung bereit. Weitere Anleitungen finden Sie in unserem Tutorial zur Integration von Bright Data in LangChain-Workflows.
Richten Sie die OpenAI-Integration unter Verwendung des gpt-4o-Modells mit ein:
llm = ChatOpenAI(model="gpt-4o")Eine zusätzliche Konfiguration ist nicht erforderlich. Das liegt daran, dass langchain_openai den API-Schlüssel automatisch aus der Umgebungsvariablen OPENAI_API_KEY liest.
Für die Integration mit anderen KI-Modellen oder -Anbietern lesen Sie bitte die offizielle Dokumentation zur Browser-Nutzung.
Schritt #6: Scraping Browser in die Browser-Nutzung einbinden
Um eine Verbindung zu einem entfernten Browser im Browser-Betrieb herzustellen, müssen Sie das BrowserConfig-Objekt wie folgt verwenden:
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)Diese Konfiguration weist Playwright an, eine Verbindung mit der entfernten Bright Data Scraping Browser-Instanz herzustellen.
Schritt #7: Definieren Sie die zu automatisierende Aufgabe
Nun ist es an der Zeit, die Aufgabe zu definieren, die Ihr KI-Agent im Browser in natürlicher Sprache ausführen soll.
Vergewissern Sie sich vorher, dass Sie das Ziel klar vor Augen haben. In diesem Fall nehmen wir an, dass der KI-Agent Folgendes tun soll:
- Mit Amazon.de verbinden.
- PlayStation 5-Konsole und Astro Bot PS5-Spiel in den Warenkorb legen.
- Rufen Sie die Warenkorb-Seite auf und erstellen Sie eine Zusammenfassung der aktuellen Bestellung.
Wenn Sie nur diese grundlegenden Anweisungen an Browser Use geben, kann es sein, dass die Dinge nicht wie erwartet laufen. Das liegt daran, dass es für einige Produkte mehrere Versionen gibt, dass Sie auf einigen Seiten aufgefordert werden, eine zusätzliche Versicherung abzuschließen, dass einige Artikel nicht verfügbar sind usw.
Daher ist es sinnvoll, zusätzliche Notizen hinzuzufügen, um die Entscheidungen des KI-Agenten in diesen Situationen zu unterstützen.
Um die Leistung zu verbessern, ist es außerdem hilfreich, die wichtigsten Schritte klar in Worten zu umreißen.
Vor diesem Hintergrund lässt sich die Aufgabe, die Ihr KI-Agent im Browser erfüllen sollte, wie folgt beschreiben:
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""Beachten Sie, dass diese Version detailliert genug ist, um den KI-Agenten durch gängige Szenarien zu führen und zu verhindern, dass er stecken bleibt.
Wunderbar! Sehen Sie, wie Sie diese Aufgabe starten.
Schritt #8: Starten Sie den AI Task
Initialisieren Sie ein Agent-Objekt für die Browser-Nutzung mit der Aufgabendefinition Ihres KI-Agenten:
agent = Agent(
task=task,
llm=llm,
browser=browser,
)Sie können den Agenten nun mit ausführen:
await agent.run()Vergessen Sie auch nicht, den von Playwright gesteuerten Browser zu schließen, wenn die Aufgabe abgeschlossen ist, um seine Ressourcen freizugeben:
await browser.close()Perfekt! Die Integration von Browser Use + Bright Data Scraping Browser ist nun vollständig eingerichtet. Jetzt müssen Sie nur noch alles zusammenfügen und den kompletten Code ausführen.
Schritt #9: Alles zusammenfügen
Ihre agent.py-Datei sollte enthalten:
from dotenv import load_dotenv
import os
from browser_use import Agent, Browser, BrowserConfig
from browser_use.browser.context import BrowserContextConfig, BrowserContext
import asyncio
from langchain_openai import ChatOpenAI
# Load the environment variables from the .env file
load_dotenv()
async def main():
# Read the remote URL of Scraping Browser from the envs
SBR_CDP_URL = os.getenv("SBR_CDP_URL")
# Set up the AI engine
llm = ChatOpenAI(model="gpt-4o")
# Configure the browser automation to connect to a remote Scraping Browser instance
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(config=config)
# The task you want to automate in the browser
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""
# Initialize a new AI browser agent with the configured browser
agent = Agent(
task=task,
llm=llm,
browser=browser,
)
# Start the AI agent
await agent.run()
# Close the browser when the task is complete
await browser.close()
if __name__ == "__main__":
asyncio.run(main())Et voilà! In weniger als 100 Codezeilen haben Sie einen leistungsstarken KI-Agenten erstellt, der die Browser-Nutzung mit dem Scraping-Browser von Bright Data kombiniert.
Um Ihren KI-Agenten auszuführen, führen Sie aus:
python agent.pyNach dem Start protokolliert browser-use alles, was er tut. Da der Scraping-Browser in der Cloud ausgeführt wird und es keine visuelle Schnittstelle gibt, sind diese Protokolle wichtig, um zu verstehen, was der Agent tut.
Hier ist ein kurzer Auszug, wie die Protokolle aussehen könnten:
INFO [agent] 📍 Step 1
INFO [browser] 🔌 Connecting to remote browser via CDP wss://brd-customer-hl_4bcb8ada-zone-scraping_browser:[email protected]:9222
INFO [agent] 🤷 Eval: Unknown - Task has just started, beginning with navigating to Amazon.
INFO [agent] 🧠 Memory: Step 1: Navigate to Amazon's website. Open tab to Amazon's main page.
INFO [agent] 🎯 Next goal: Navigate to Amazon's website by opening the following URL: https://www.amazon.com/.
INFO [agent] 🛠️ Action 1/1: {"go_to_url":{"url":"https://www.amazon.com/"}}
INFO [controller] 🔗 Navigated to https://www.amazon.com/
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Navigated to Amazon homepage. The search bar is available for input.
INFO [agent] 🧠 Memory: On the Amazon homepage, ready to search for items. 0 out of 2 items added to cart.
INFO [agent] 🎯 Next goal: Search for the 'PlayStation 5 (Slim) console' in the search bar.
INFO [agent] 🛠️ Action 1/2: {"input_text":{"index":2,"text":"PlayStation 5 (Slim) console"}}
INFO [agent] 🛠️ Action 2/2: {"click_element_by_index":{"index":4}}
INFO [controller] ⌨️ Input PlayStation 5 (Slim) console into index 2
INFO [agent] Something new appeared after action 1 / 2
# Omitted for brevity...
INFO [agent] 📍 Step 14
INFO [agent] 👍 Eval: Success - Extracted the order summary from the cart page.
INFO [agent] 🧠 Memory: Amazon cart page shows both items: PlayStation 5 Slim and Astro Bot PS5 game added successfully. Extracted item names, quantities, costs, subtotal, and delivery details.
INFO [agent] 🎯 Next goal: Finalize the task by summarizing the order details.
INFO [agent] 🛠️ Action 1/1: {"done":{"text":"Order Summary:nnItems in Cart:n1. Name: Astro Bot PS5n Quantity: 11n Cost: $58.95nn2. Name: PlayStation®5 console (slim)n Quantity: 1n Cost: $499.00nnSubtotal: $557.95nDelivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.nnTotal Cost: $557.95","success":true}}
INFO [agent] 📄 Result: Order Summary:
Items in Cart:
1. Name: Astro Bot PS5
Quantity: 1
Cost: $58.95
2. Name: PlayStation®5 console (slim)
Quantity: 1
Cost: $499.00
Subtotal: $557.95
Delivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.Wie Sie sehen können, hat der KI-Agent erfolgreich die gewünschten Artikel gefunden, sie dem Warenkorb hinzugefügt und eine saubere Zusammenfassung erstellt. Und das alles ohne Sperren oder Verbote von Amazon, dank des Scraping Browsers!
browser-use enthält auch Funktionen zur Aufzeichnung der Browser-Sitzung zu Debugging-Zwecken. Dies funktioniert zwar noch nicht mit dem Remote-Browser, aber wenn es so wäre, würden Sie eine faszinierende Wiedergabe des KI-Agenten in Aktion sehen:
Wahrhaft hypnotisierend – und ein aufregender Einblick in die Fortschritte, die das KI-gestützte Browsing gemacht hat.
Schritt #10: Nächste Schritte
Der Amazon-KI-Agent, den wir hier gebaut haben, ist nur ein Ausgangspunkt – ein Proof of Concept, um zu zeigen, was möglich ist. Um ihn produktionsreif zu machen, haben wir einige Ideen für Verbesserungen:
- Verbinden Sie sich mit Ihrem Amazon-Konto: Erlauben Sie dem Agenten, sich anzumelden, damit er auf personalisierte Funktionen wie Bestellhistorie und Empfehlungen zugreifen kann.
- Implementieren Sie einen Einkaufs-Workflow: Erweitern Sie den Agenten, um Einkäufe tatsächlich abzuschließen. Dazu gehören die Auswahl von Versandoptionen, die Anwendung von Promo-Codes oder Geschenkkarten und die Bestätigung der Zahlung.
- Senden Sie eine Bestätigung oder einen Bericht per E-Mail: Bevor eine Zahlungstransaktion abgeschlossen wird, könnte der Agent eine detaillierte Zusammenfassung des Warenkorbs und der geplanten Aktionen zur Genehmigung durch den Benutzer per E-Mail versenden. So behalten Sie die Kontrolle und haben eine zusätzliche Ebene der Verantwortlichkeit.
- Lesen Sie Artikel aus einer Wunschliste oder Eingabeliste: Lassen Sie den Agenten Artikel dynamisch aus einer gespeicherten Amazon-Wunschliste, einer lokalen Datei (z. B. JSON oder CSV) oder einem entfernten API-Endpunkt laden.
Schlussfolgerung
In diesem Blogbeitrag haben Sie gelernt, wie man die beliebte Browse-Use-Bibliothek in Kombination mit einer Scraping-Browser-API verwendet, um einen hocheffektiven KI-Agenten in Python zu erstellen.
Wie gezeigt, können Sie durch die Kombination von Browse Use mit dem Scraping Browser von Bright Data KI-Agenten erstellen, die zuverlässig mit praktisch jeder Website interagieren können. Dies ist nur ein Beispiel dafür, wie die Tools und Services von Bright Data eine fortschrittliche KI-gesteuerte Automatisierung ermöglichen können.
Entdecken Sie unsere Lösungen für die Entwicklung von KI-Agenten:
- Autonome KI-Agenten: Suche, Zugriff und Interaktion mit jeder Website in Echtzeit über eine Reihe leistungsstarker APIs.
- Vertikale KI-Anwendungen: Erstellen Sie zuverlässige, benutzerdefinierte Datenpipelines, um Webdaten aus branchenspezifischen Quellen zu extrahieren.
- Grundlegende Modelle: Greifen Sie auf konforme, webbasierte Datensätze zu, um Pre-Training, Bewertung und Feinabstimmung zu unterstützen.
- Multimodale KI: Nutzen Sie den weltweit größten Bestand an Bildern, Videos und Audiodateien, die für KI optimiert sind.
- Datenanbieter: Verbinden Sie sich mit vertrauenswürdigen Anbietern, um hochwertige, KI-fähige Datensätze in großem Umfang zu beziehen.
- Datenpakete: Erhalten Sie kuratierte, gebrauchsfertige, strukturierte, angereicherte und kommentierte Datensätze.
Weitere Informationen finden Sie in unserem KI-Hub.
Erstellen Sie ein Bright Data-Konto und testen Sie alle unsere Produkte und Services für die Entwicklung von KI-Agenten!




