

Das Internet birgt gewaltige Datenmengen, die für Forschungs- und Geschäftsentscheidungen von unschätzbarem Wert sein können. Daher ist ein fundiertes Verständnis für die Nutzung von Tools wie Playwright ausgesprochen wichtig.
Playwright ist eine leistungsstarke Node.js -Bibliothek, die von Microsoft entwickelt wurde und mit der Daten von Websites ausgelesen werden können. In diesem Artikel lernen Sie anhand praktischer und ausführlicher Beispiele, wie Sie mit Playwright Daten von der Bright Data-Startseite scrapen können. Diese Beispiele können Sie anschließend auf eine beliebige andere Website anwenden, die Sie mit Playwright scrapen möchten.
Warum Playwright verwenden?
Web-Scraping ist kein neues Konzept. Im JavaScript-Ökosystem vereinfachen Tools wie Cheerio, Selenium, Puppeteerund Playwright das Web-Scraping.
Als neuere Web-Scraping-Bibliothek ist Playwright aufgrund der folgenden Funktionen besonders attraktiv:
Leistungsstarke Locator
Playwright verwendet Locator, die über eine eingebaute automatische Warte- und Wiederholungslogik zur Auswahl von Elementen auf einer Webseite verfügen. Die automatische Wartelogik vereinfacht die Erstellung Ihres Web-Scraping-Codes, da der manuelle Ladevorgang einer Webseite nicht länger abgewartet werden muss.
Durch die Wiederholungslogik eignet sich Playwright auch für das Scraping moderner Single-Page-Webanwendung (SPA), welche nach dem anfänglichen Seitenaufruf Daten dynamisch laden.
Verschiedene Locator-Methoden
Beim Einsatz von Locator können Sie in Playwright festlegen, welche Elemente auf der Webseite anhand verschiedener Syntaxen lokalisiert werden sollen, darunter die CSS-Selektor-Syntax, die XPath-Syntax bzw. die Inhaltselemente. Zudem können Sie Filter auf Locator anwenden, um die Suche zusätzlich zu verfeinern.
Web-Scraping mit Playwright
In diesem Abschnitt erstellen Sie ein Node.js-Projekt, installieren Playwright und lernen, wie Sie mit Playwright eine Webseite finden, mit dieser interagieren und Daten aus ihr extrahieren können.
Voraussetzungen
Die Codeausschnitte in diesem Artikel werden mit der neuesten Long-Term-Support-Version (LTS) von Node.js ausgeführt, die zum Zeitpunkt der Erstellung dieses Artikels Version 18.15.0 ist. Vergewissern Sie sich, dass Sie Node.js bereits installiert haben, bevor Sie beginnen.
Ein Code-Editor zur Hervorhebung der JavaScript-Syntax und zur automatischen Vervollständigung, wie z. B. Visual Studio Code, ist ebenfalls äußerst empfehlenswert.
Erstellung eines neuen Projekts
Öffnen Sie ein neues Terminalfenster, legen Sie einen neuen Ordner für Ihr Node.js-Projekt an und rufen Sie diesen mit folgendem Befehl auf:
mkdir playwright-demo
cd playwright-demo
Erstellen Sie nun mit folgendem npm-Befehl das gewünschte Node.js-Projekt:
npm init -y
Installation von Playwright
Nach der Erstellung eines Node.js-Projekts installieren Sie die Playwright-Bibliothek , indem Sie folgenden Befehl in Ihrem Terminalfenster ausführen:
npm install playwright
Die Installation der Bibliothek kann einige Zeit in Anspruch nehmen, da Playwright die erforderlichen Browser als Teil der Installation herunterladen muss.
Aufruf der Bright Data-Startseite
Nachdem Sie die Playwright-Bibliothek installiert haben, legen Sie in Ihrem Projektordner eine neue Datei mit der Bezeichnung index.js an. Fügen Sie anschließend folgenden Code in diese Datei ein:
// Import the Playwright library to use it
const playwright = require("playwright");
(async () => {
// Launch a new instance of a Chromium browser
const browser = await playwright.chromium.launch({
// Set headless to false so you can see how Playwright is
// interacting with the browser
headless: false,
});
// Create a new Playwright context
const context = await browser.newContext();
// Create a new page/tab in the context.
const page = await context.newPage();
// Navigate to the Bright Data home page.
await page.goto("https://brightdata.com/");
// Wait 10 seconds (or 10,000 milliseconds)
await page.waitForTimeout(10000);
// Close the browser
await browser.close();
})();
Führen Sie den Ausschnitt über folgenden Befehl in Ihrem Terminal aus:
node index.js
Daraufhin sollte sich ein Chromium -Browser öffnen und die Bright Data- Startseite laden:
Lokalisierung von Elementen
Sobald Sie über Playwright zur Startseite von Bright Data geleitet wurden, können Sie jetzt Locator zur Lokalisierung bestimmter Elemente auf der Webseite verwenden. Playwright verfügt über verschiedene Locator. In den folgenden Abschnitten erfahren Sie, wie jeder einzelne Locator funktioniert.
Lokalisierung von Elementen mit CSS-Selektoren
Mit Playwright können Sie anhand von CSS-Selektoren, einer prägnanten und zugleich leistungsstarken Syntax, die in CSS zur Anwendung von Stilen auf bestimmte HTML-Elemente der Webseite dient, Elemente auf einer Webseite lokalisieren.
Das Bright Data-Logo ist beispielsweise ein { Element in der Seitenüberschrift, dem page_header_logo_svg class zugeordnet ist:

Mithilfe dieser Informationen können Sie das SVG-Element mit einem CSS-Selektor lokalisieren:
const logoSvg = page.locator(".page_header_logo_svg");
Der Locator wird in der Variable logoSvg abgelegt und kann zu einem späteren Zeitpunkt verwendet werden, um mit dem Element zu interagieren oder Informationen aus diesem zu extrahieren.
Lokalisierung von Elementen mit XPath-Abfragen
Eine weitere Selector-Syntax, die zur Lokalisierung von Elementen in einem XML-Dokument verwendet werden kann, istXPath . Da es sich bei HTML um XML handelt, kann diese Syntax zum Auffinden von HTML-Elementen auf einer Webseite verwendet werden.
Beispielsweise können Sie mit der folgenden XPath-Abfrage dasselbe SVG-Logo auswählen, das Sie im vorherigen Abschnitt gesehen haben:
const logoSvg = page.locator("//*[@class='page_header_logo_svg']");
Die Abfrage durchsucht die Seite nach sämtlichen mit page_header_logo_svg class verknüpften Elementen und speichert deren Position in der Variablen logoSVG .
Lokalisierung von Elementen nach Rolle
HTML-Elementen können verschiedene Rollen zugewiesen werden. Diese Rollen geben einer Webseite einen semantischen Wert , der es Screenreadern und anderen Tools erleichtert, die Seite zu unterstützen. Weitere Einzelheiten zu Rollen finden Sie hier.
Der folgende Codeausschnitt zeigt auf, wie die Schaltfläche Anmelden anhand der Rolle und des Namens gefunden werden kann:
const signupButton = page.getByRole("button", {
name: "Start free trial",
});
Dieser Ausschnitt lokalisiert die Schaltfläche Kostenlose Testversion starten auf der Startseite:
const signupButton = page.getByRole("button", {
name: "Start free trial",
});Dieser Ausschnitt lokalisiert die Schaltfläche Kostenlose Testversion starten auf der Startseite:
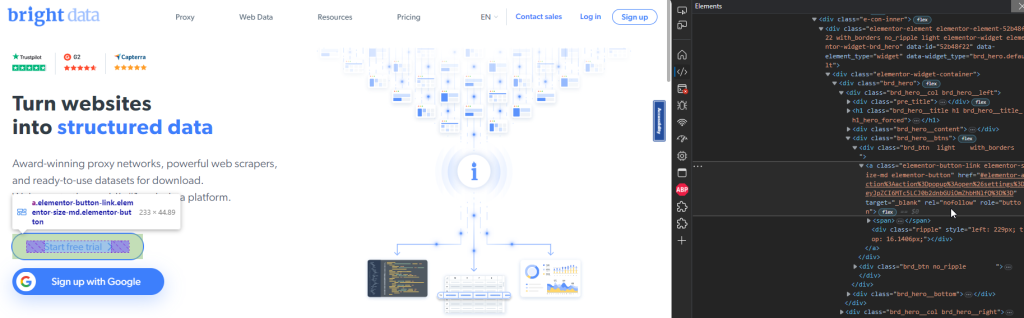
Lokalisierung von Elementen anhand von Textinhalten
Wenn ein HTML-Element kein aussagekräftiges Attribut zur Kennzeichnung besitzt, wie etwa ein id- oder class -Attribut, können Sie das Element mit der getByText -Methode über seinen Text auswählen.
Die Bright Data-Startseite verfügt beispielsweise über einen Titel im Abschnitt „Hero“ mit den Worten „Strukturierte Daten“ in blauer Schrift:
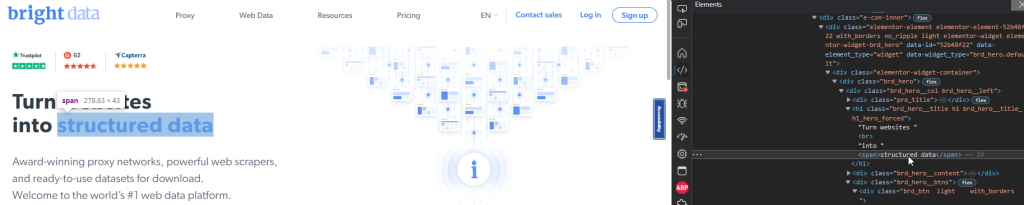
Sie können das {4} -Element, das diese Wörter enthält, mit folgendem Playwright-Ausschnitt auswählen:
const structuredData = page.getByText("structured data");
Lokalisierung von Elementen nach Beschreibung
In einem HTML-Formular haben die Eingabeelemente oft Beschreibungen. Playwright kann diese Beschreibungen verwenden, um das damit verbundene Eingabeelement mit der getByLabel -Methode zu identifizieren.
Die Anmeldeseite von Bright Data hat beispielsweise ein Eingabeelement mit einer Beschreibung, welche die Worte „Arbeits-E-Mail“ enthält:
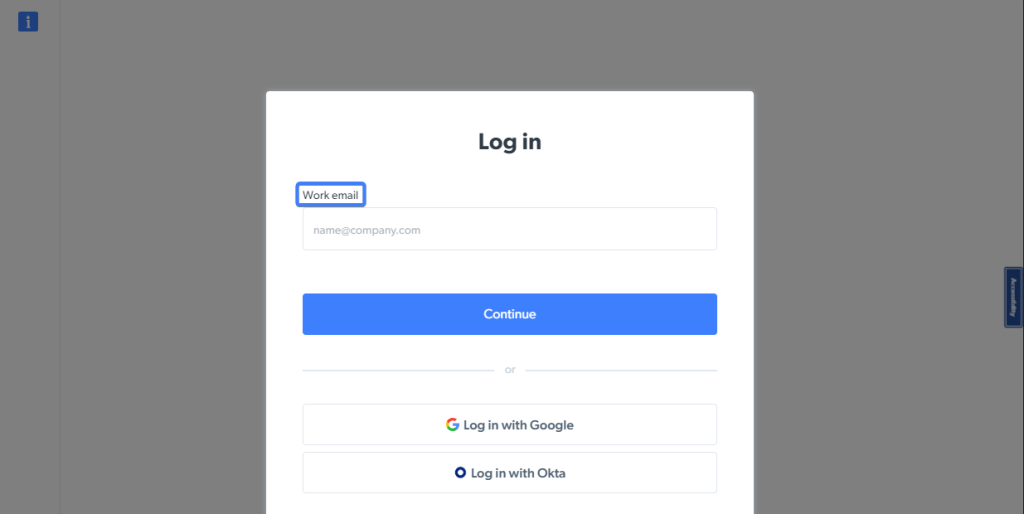
Mit dem folgenden Codeausschnitt können Sie das Eingabeelement auf der Seite lokalisieren und in einer Variablen speichern, um es später zu verwenden:
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/cp/start");
// Locate the <input> using the label
const emailInput = page.getByLabel("Work email");
Lokalisierung von Elementen nach Platzhalter
Sie können ein Eingabeelement auch anhand des angezeigten Platzhalterwerts finden, indem Sie die getByPlaceholder -Methode verwenden.
Sie werden feststellen, dass das E-Mail-Feld auf der Anmeldeseite von Bright Data über einen Platzhaltertext verfügt, der dem Benutzer einen Hinweis bezüglich der einzugebenden Informationen gibt.
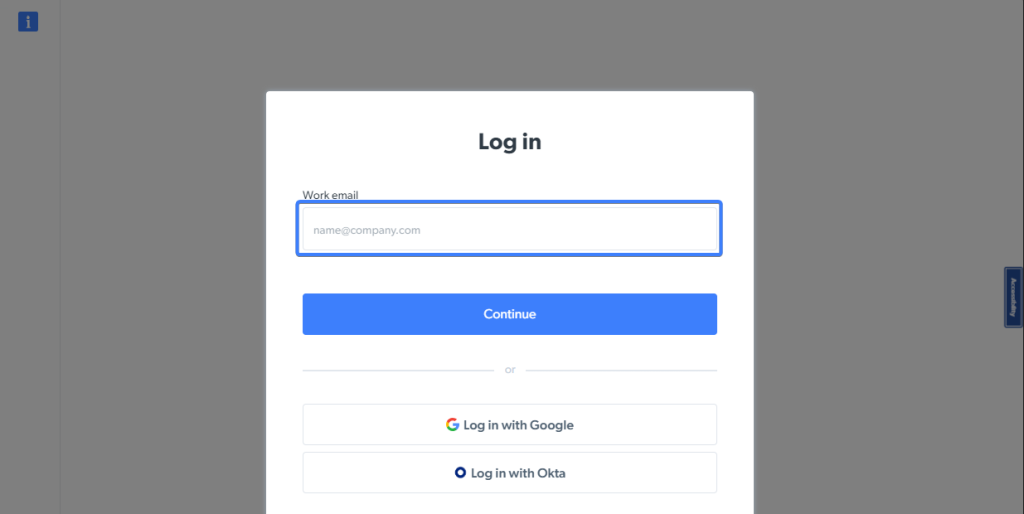
Der folgende Ausschnitt findet dieses Element über den von der Eingabe angezeigten Platzhalterwert:
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/cp/start");
// Locate the <input> using the placeholder
const emailInput = page.getByPlaceholder("[email protected]");
Lokalisierung von Elementen anhand von alt-Text
In HTML können Sie Bildern mithilfe des alt -Attributs eine Textbeschreibung zuweisen, die bei nicht geladenen Bildern angezeigt und von Screenreadern zur Beschreibung des Bildes vorgelesen wird. Mit der getByAltText -Methode von Playwright können Sie ein img -Element anhand seines alt -Attributs ausfindig machen.
Bright Data listet bspw. Branchen auf, die ihre Daten verwenden. Mithilfe des alt-Attributs „Anwendungsfall im Gesundheitswesen“ können Sie das für das Gesundheitswesen verwendete Bild abrufen:
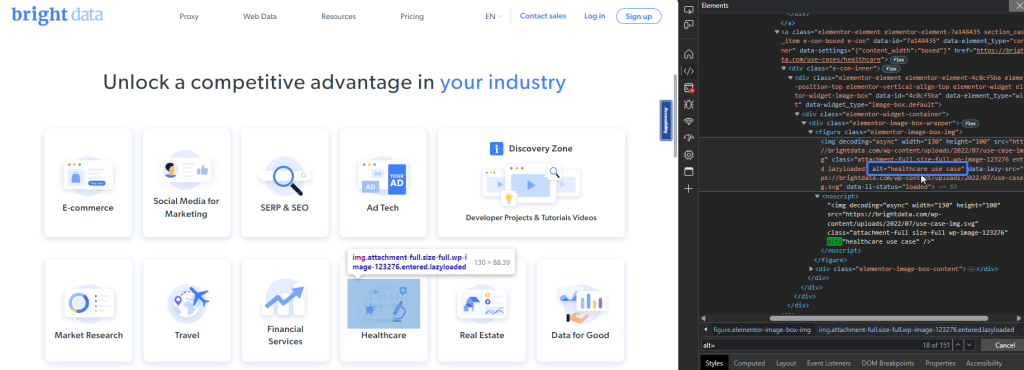
Mit dem folgenden Codeausschnitt lässt sich das Bildelement lokalisieren:
const healthcareImage = page.getByAltText("healthcare use case");
Lokalisierung von Elementen nach Titel
Der letzte Playwright-Selektor, den Sie für das Scraping nutzen können, ist die getByTitle -Methode, mit der Sie ein HTML-Element anhand seines title-Attributs lokalisieren können. Der Titelwert wird angezeigt, wenn Sie mit dem Mauszeiger über die HTML-Komponente fahren.
Die Helpdesk-Website von Bright Data enthält nämlich einen Anmeldelink mit einem title-Attribut:

Mit dem folgenden Playwright-Ausschnitt können Sie den Link anhand seines title-Attributs lokalisieren:
// Navigate to the Bright Data helpdesk webpage.
await page.goto("https://help.brightdata.com/hc/en-us");
// Locate the Sign in link using its title attribute
const signInLink = page.getByTitle("Opens a dialog");
Nachdem wir Ihnen nun einige Methoden zur Lokalisierung von Elementen auf einer Webseite mit Playwright vorgestellt haben, möchten wir Ihnen die Interaktion mit diesen Elementen und deren Extraktion von Daten näher bringen.
Interaktion mit Elementen
Sobald Sie ein Element auf einer Webseite lokalisiert haben, können Sie damit interagieren. Sie müssen sich eventuell bei einer Website anmelden, bevor Sie geschützte Seiten auslesen können.
Dieser Codeausschnitt verdeutlicht die verschiedenen Playwright-Methoden zur Interaktion mit den Elementen auf einer Webseite. Im nachfolgenden Code finden Sie eine Erklärung der einzelnen Funktionen:
// Import the Playwright library to use it
const playwright = require("playwright");
(async () => {
// Launch a new instance of a Chromium browser
const browser = await playwright.chromium.launch({
// Set headless to false so you can see how Playwright is
// interacting with the browser
headless: false,
});
// Create a new Playwright context
const context = await browser.newContext();
// Create a new page/tab in the context.
const page = await context.newPage();
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/");
// Locate and click on the signup button
await page
.locator("#hero_new")
.getByRole("button", {
name: "Start free trial",
})
.click();
// Locate the first name field and FILL in a first name
await page.locator(".hs_firstname input").fill("John");
// Locate the last name field and FILL in a last name
await page.locator(".hs_lastname input").fill("Smith");
// Locate the email field and TYPE in an email address
await page.locator(".hs_email input").type("[email protected]");
// Locate the company size field and SELECT an option
await page.locator(".hs_numemployees select").selectOption("1-9 employees");
// Locate the terms and conditions checkbox and CHECK it.
await page.locator(".legal-consent-container input").check();
// Wait 10 seconds so you can see the result.
await page.waitForTimeout(10000);
// Close the browser
await browser.close();
})();
Fügen Sie diesen Ausschnitt in Ihre index.js -Datei ein und führen Sie ihn mit folgendem Befehl erneut aus:
node index.js
Die Startseite von Bright Data wird kurz eingeblendet, bevor ein Anmeldedialog erscheint. Als Nächstes sehen Sie, wie Playwright das Anmeldeformular mithilfe der verschiedenen Methoden in diesem Ausschnitt auffüllt:
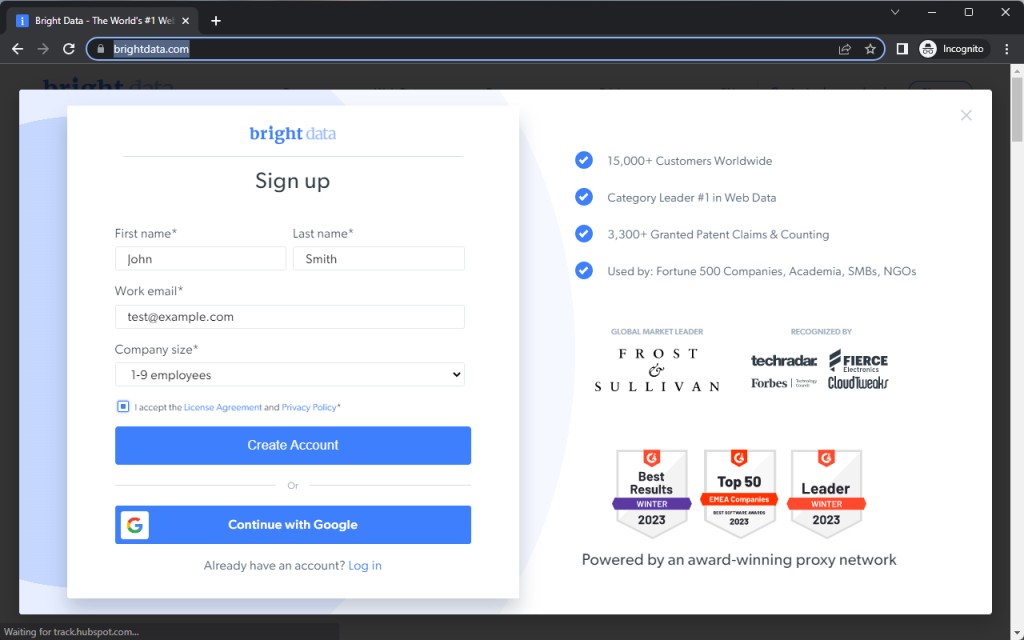
Anklicken von Elementen
Im vorherigen Ausschnitt hat Playwright zunächst auf die Schaltfläche Anmelden geklickt, um das Dialogfeld zu öffnen:
// Locate and click on the signup button
await page
.getByRole("button", {
name: "Start free trial",
})
.click();
Playwright stellt zwei Methoden zum Anklicken von Elementen zur Verfügung:
- Die
click-Methode simuliert das einmalige Anklicken eines Elements. - Die
dblclickMethode simuliert einen Doppelklick auf ein Element.
Im vorliegenden Beispiel musste nur einmal auf die Schaltfläche Anmelden geklickt werden. Aus diesem Grund verwendet der Ausschnitt die click -Methode.
Ausfüllen von Textfeldern
Für dieses Beispiel verwendet der Ausschnitt zwei Methoden für das Ausfüllen von Textfeldern im Anmeldeformular :
// Locate the first name field and FILL in a first name
await page.locator(".hs_firstname input").fill("John");
// Locate the last name field and FILL in a last name
await page.locator(".hs_lastname input").fill("Smith");
// Locate the email field and TYPE in an email address
await page.locator(".hs_email input").type("[email protected]");
Der Ausschnitt setzt die fill- und type -Methoden für verschiedene Felder ein. Beide Funktionen füllen ein Textfeld, aber sie tun dies auf etwas unterschiedliche Weise:
fill-Methodetype-Methode
In den meisten Fällen werden Sie wahrscheinlich die fill -Methode verwenden, aber gegebenenfalls können Sie auch die type -Methode nutzen, um die manuelle Werteingabe zu simulieren.
Auswahl einer Dropdown-Option
Das Anmeldeformular verfügt über ein Dropdown-Feld zur Auswahl der Unternehmensgröße, das Playwright mit „1–9 Mitarbeiter“ vorbelegt hat:
// Locate the company size field and SELECT an option
await page.locator(".hs_numemployees select").selectOption("1-9 employees");
MitPlaywright können Sie die selectOption -Methode verwenden, um Dropdown-Felder in einem Formular auszufüllen. Diese Funktion gestattet die Auswahl eines Dropdown-Elements anhand eines Wertes oder einer Beschriftung sowie die Auswahl mehrerer Optionen in einer Mehrfachauswahl.
Markieren von Optionsfeldern und Kontrollkästchen
Vor dem Absenden des Formulars müssen Sie die Allgemeinen Geschäftsbedingungen akzeptieren. Der folgende Ausschnitt markiert das entsprechende Kontrollkästchen:
// Locate the terms and conditions checkbox and CHECK it.
await page.locator(".legal-consent-container input").check();
Um ein Kontrollkästchen zu ändern, können Sie die check- und uncheck -Methodeeinsetzen:
- Die
check-Methode stellt sicher, dass das Kontrollkästchen markiert ist. - Die
uncheck-Methode gewährleistet, dass die Markierung des Kontrollkästchens aufgehoben wird.
Nachdem wir Ihnen erläutert haben, wie Sie in Playwright mit HTML-Elementen auf einer Seite interagieren können, lernen Sie im folgenden Abschnitt, wie man Daten aus einer Seite extrahiert.
Extrahieren von Daten aus Elementen
Das Extrahieren von Daten ist für Web-Scraping unerlässlich. In Playwright stehen Ihnen diverse Methoden zum Abrufen verschiedener Datentypen aus den von Ihnen gefundenen Elementen offen. In den folgenden Abschnitten werden einige dieser Methoden erläutert.
Extrahieren des inneren Textes
Mit der innerText -Methode lässt sich der Textinhalt eines Elements extrahieren. Die Bright Data-Startseite verfügt beispielsweise über ein Hero-Element am oberen Rand:
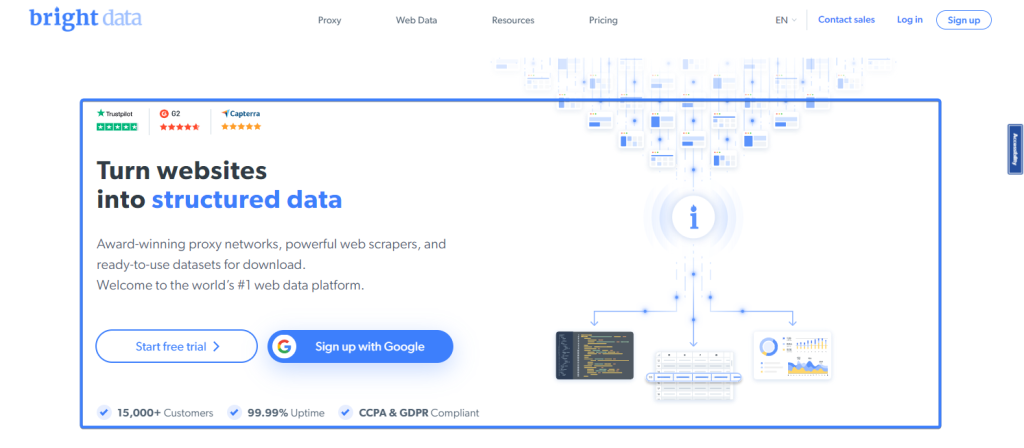
Mit dem folgenden Ausschnitt können Sie den Titel des Hero-Elements auf der Bright Data-Startseite extrahieren:
const headerText = await page.locator(".brd_hero__title.h1").innerText();
// headerText = "Turn websitesninto structured data"
Wenn Ihr Locator auf mehr als ein Element verweist, können Sie anhand der allInnerTexts -Methode den Text als String von Arrayelementen abrufen. Auf der Startseite von Bright Data finden Sie eine Auflistung der Anwendungsfälle ihrer Daten:
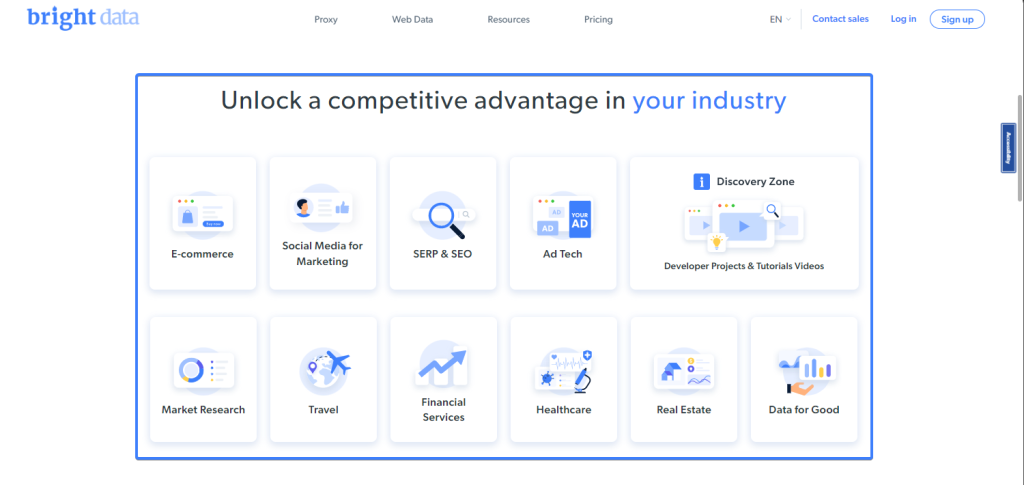
Anhand des nachfolgenden Ausschnitts können Sie eine Auflistung aller Anwendungsfälle von Bright Data extrahieren:
const useCases = await page
.locator(".section_cases_row_col .elementor-image-box-title")
.allInnerTexts();
// useCases = [
// 'E-commerce',
// 'Social Media for Marketing',
// 'SERP & SEO',
// 'Ad Tech',
// 'Market Research',
// 'Travel',
// 'Financial Services',
// 'Healthcare',
// 'Real Estate',
// 'Data for Good'
// ]
Extrahieren von innerem HTML
Playwright bietet außerdem die Möglichkeit, den inneren HTML-Code eines Elements mit der innerHTML -Methode zu extrahieren. So erhalten Sie z. B. den HTML-Code für die Fußzeile der Bright Data-Startseite mit folgendem Ausschnitt:
const footerHtml = await page.locator("#footer").innerHTML();
// footerHtml = '<div class="container"><div class="footer__logo">...'
Extrahieren von Attributwerten
Unter Umständen müssen Sie Daten aus Attributen eines HTML-Elements extrahieren, wie etwa aus dem href -Attribut eines Links. Im folgenden Playwright-Ausschnitt wird veranschaulicht, wie Sie die href -Eigenschaft des Anmeldelinks extrahieren können:
const signUpHref = await page.getByText("Log in").getAttribute("href");
// signUpHref = '/cp/start'
Screenshot von Seiten
Beim Scrapen von Daten kann es erforderlich sein, zu Prüfzwecken Screenshots zu erstellen. Hierzu eignet sich die Screenshot -Methode. Bei dieser Funktion können Sie mehrere Optionen konfigurieren, z. B. wo die Screenshot-Datei gespeichert bzw. ob ein ganzseitiger Screenshot erstellt werden soll.
Der folgende Ausschnitt erstellt einen ganzseitigen Screenshot der Bright Data-Startseite und speichert diesen anschließend:
await page.screenshot({
// Save the screenshot to the "homepage.png" file
path: "homepage.png",
// Take a screenshot of the entire page
fullPage: true,
});
Verwendung automatisierter Scraping-Dienste
In den vorangegangenen Ausschnitten wird beschrieben, wie eine Webseite lokalisiert wird, wie man mit ihr interagiert bzw. wie man Daten aus dieser Seite extrahiert. Mit diesen Methoden lassen sich praktisch sämtliche Daten aus einer Webseite auslesen. Diese Methoden erfordern jedoch einen gewissen Aufwand, da Sie zunächst die entsprechenden Elemente identifizieren müssen, bevor Sie diese lokalisieren können. Darüber hinaus müssen Sie beim Scrapen mehrerer Seiten einer einzelnen Website auf CAPTCHAs und Ratenbegrenzungen achten.
Bright Data bietet eine Reihe von Lösungen, damit Sie sich gezielt mit dem Extrahieren von Daten befassen können. BBright Data bietet eine Web-Scraper-IDE mit vorgefertigten JavaScript-Funktionen und -Vorlagen, die Ihnen beim Scrapen von beliebten Websites nützlich sind. Des Weiteren können Sie mit Web-Unlocker CAPTCHAs umgehen und mittels der Proxy-Dienste von Bright Data Ratenbegrenzungen und geografische Sperren vermeiden. Diese Dienste beseitigen zahlreiche Hindernisse in Playwright und helfen dabei, Daten schneller und einfacher auszulesen.
Fazit
In diesem Artikel haben wir Ihnen Playwright näher gebracht, eine von Microsoft entwickelte Bibliothek, die Ihnen beim Scrapen von Daten aus Webseiten von Nutzen ist. Ferner haben Sie erfahren, wie man Playwright verwendet, um Elemente auf einer Webseite zu lokalisieren, mit diesen zu interagieren und deren Daten zu extrahieren. Abschließend haben Sie gelernt, wie ein automatisierter Scraping-Dienst wie Bright Data Ihre Web-Scraping-Prozesse erheblich vereinfachen kann.





