

Diese Anleitung behandelt folgende Themen:
- Erste Schritte beim Web Scraping mit R
Erste Schritte beim Web Scraping mit R
Zunächst gilt es zu verstehen, welche Werkzeuge in diesem R-Tutorial verwendet werden.
Die Tools: R und rvest
R ist eine umfangreiche, einfach zu bedienende Bibliothek für statistische Analysen und Datenvisualisierungen, die nützliche Tools für die Datenverarbeitung und dynamische Typisierung bereitstellt.
rvest (abgeleitet vom englischen Begriff „harvest“, zu Deutsch „ernten“) ist nicht zuletzt dank seiner äußerst benutzerfreundlichen Oberfläche eines der beliebtesten, wenn nicht sogar das beliebteste R-Paket mit Web-Scraping-Funktionen. Mit Vanilla rvest können Sie Daten aus einer einzigen Webseite extrahieren, was für den Einstieg ideal geeignet ist. Zum Scrapen mehrerer Seiten können Sie das Paket später mit der Bibliothek polite erweitern.
Einrichten der Entwicklungsumgebung
Falls Sie noch nicht mit R innerhalb von RStudio arbeiten, befolgen Sie bitte die hier beschriebene Installationsanleitung.
Öffnen Sie anschließend die Konsole und installieren Sie rvest:
install.packages("rvest")
Da es sich um einen Teil der tidyverse-Sammlung handelt, wird von offizieller Seite empfohlen, die integrierten Funktionen von rvest mit anderen Paketen der Sammlung zu erweitern (z. B. mit magrittr zur Verbesserung der Code-Lesbarkeit oder mit xml2 für die Arbeit mit HTML und XML). Hierfür können Sie tidyverse direkt installieren:
install.packages("tidyverse")Zum Verständnis der Webseite
Web Scraping ist eine Technik zum Auslesen von Website-Daten mithilfe rechtskonformer automatisierter Prozesse.
Von dieser Definition lassen sich drei wichtige Überlegungen ableiten:
- Daten gibt es in verschiedenen Formaten.
- Websites zeigen Informationen auf sehr unterschiedliche Weise an.
- Gescrapte Daten müssen legal zugänglich sein.
Wer verstehen will, wie eine URL gescrapt wird, muss zunächst wissen, wie der Inhalt der Webseite mithilfe der Auszeichnungssprache HTML und der Stylesheet-Sprache CSS dargestellt wird.
Der HTML-Code gibt Inhalt und Struktur der Webseite vor. Diese wird beim Laden im Webbrowser als baumartiges Document Object Model (DOM) dargestellt, wobei der Inhalt durch so genannte „Tags“ organisiert wird. Die Tags sind hierarchisch aufgebaut, wobei jedes Tag eine bestimmte Funktion hat, die auf alle Inhalte innerhalb der einleitenden () und abschließenden () Angaben angewendet wird:
<!DOCTYPE html>
<html lang="en-gb" class="a-ws a-js a-audio a-video a-canvas a-svg a-drag-drop a-geolocation a-history a-webworker a-autofocus a-input-placeholder a-textarea-placeholder a-local-storage a-gradients a-transform3d -scrolling a-text-shadow a-text-stroke a-box-shadow a-border-radius a-border-image a-opacity a-transform a-transition a-ember" data-19ax5a9jf="dingo" data-aui-build-date="3.22.2-2022-12-01">
▶<head>..</head>
▶<body class="a-aui_72554-c a-aui_accordion_a11y_role_354025-c a-aui_killswitch_csa_logger_372963-c a-aui_launch_2021_ally_fixes_392482-t1 a-aui_pci_risk_banner_210084-c a-aui_preload_261698-c a-aui_rel_noreferrer_noopener_309527-c a-aui_template_weblab_cache_333406-c a-aui_tnr_v2_180836-c a-meter-animate" style="padding-bottom: 0px;">..</body>
</html>Das <html>-Tag ist der kleinste Bestandteil einer Webseite, in den die Tags <head> und <body> eingebettet sind. <head> und <body> wiederum sind anderen Tags innerhalb dieser Tags übergeordnet. <div> (für ein Block-Element) und <p> (für einen Absatz) gehören dabei zu den häufigsten untergeordneten Tags.
Im oben gezeigten Bildausschnitt sehen Sie die „Attribute“, die mit jedem HTML-“Element“ verknüpft sind: lang, class und style sind vordefiniert, während die mit data- beginnenden Attribute für Amazon zugeschnitten sind.
class ist neben dem Attribut id für das Web Scraping von besonderem Interesse, da beide es uns ermöglichen, eine Gruppe von Elementen bzw. ein bestimmtes Element anzusteuern. Ursprünglich war dies für das Styling in CSS vorgesehen.
Mit CSS wird die Gestaltung der Webseite festgelegt. Von der Farbgebung über die Positionierung bis hin zur Größenanpassung können Sie jedes HTML-Element auswählen und seinen Styling-Eigenschaften neue Werte zuweisen. Außerdem können Sie das CSS-Styling innerhalb des HTML-Elements mit dem style-Attribut anwenden (wie im obigen Bildausschnitt zu sehen):
<body .. style="padding-bottom: 0px;">In reinem CSS würde dies wie folgt geschrieben werden:
body {padding-bottom: 0px;}
Dabei ist body der „Selektor“, padding-bottom die „Eigenschaft“ und 0px der „Wert“.
Jedes Tag, jede Klasse, oder ID kann als CSS-Selektor verwendet werden.
Benutzer können dynamisch mit den auf der Webseite angezeigten Inhalten interagieren, indem sie über das script-Tag die von der Programmiersprache JavaScript bereitgestellten Funktionen nutzen. Nach einer Benutzerinteraktion kann sich der angezeigte Inhalt ändern und es können neue Inhalte erscheinen. Fortgeschrittene Web Scraper können Benutzerinteraktionen imitieren, worauf wir später noch eingehen werden.
DevTools
Die gängigsten Webbrowser bieten integrierte Entwicklertools, die die Erfassung und Live-Aktualisierung technischer Informationen auf einer Webseite zur Protokollierung, Fehlersuche, Prüfung und Leistungsanalyse ermöglichen. In diesem Tutorial verwenden wir die DevTools von Chrome.
Die Entwicklertools finden Sie in der rechten oberen Ecke des Browsers unter dem Menüpunkt „Weitere Tools“:
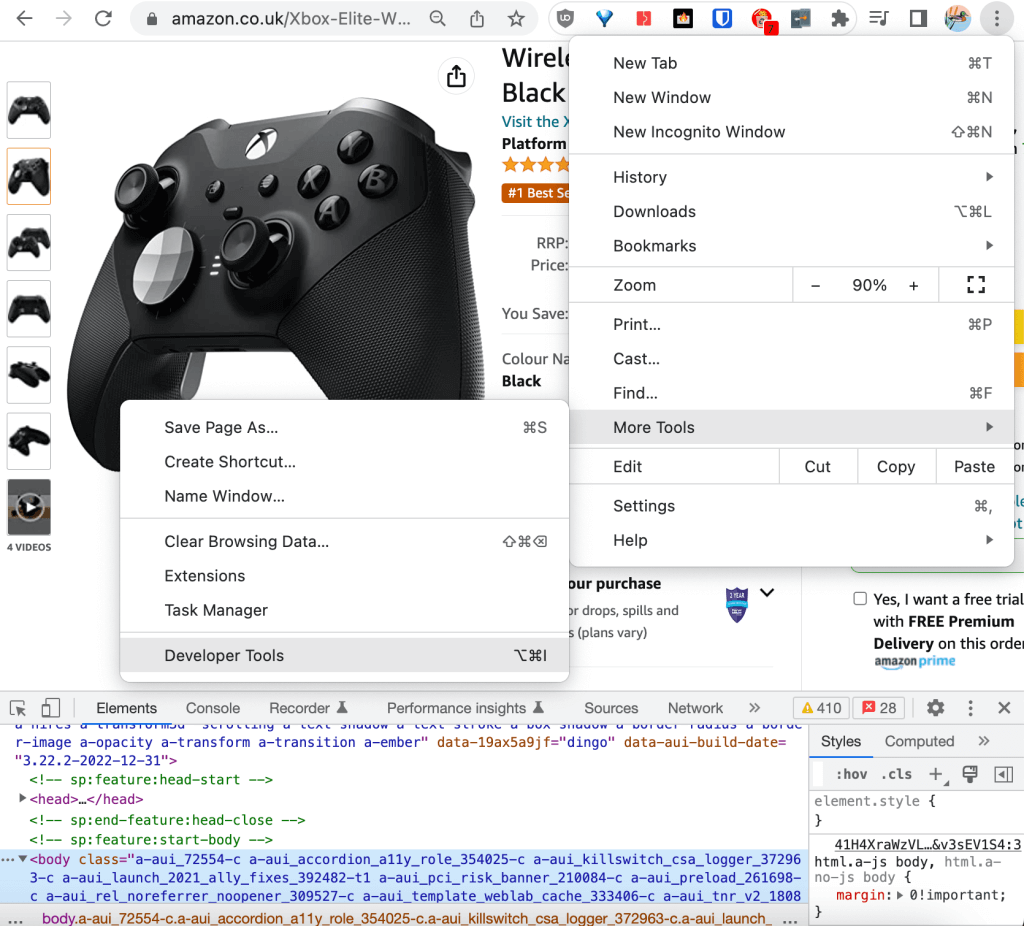
In den Entwicklertools können Sie in der Registerkarte Elemente durch den HTML-Quelltext scrollen. Beim Scrollen durch die HTML-Zeilen wird das entsprechende gerenderte Element auf der Webseite blau unterlegt angezeigt:
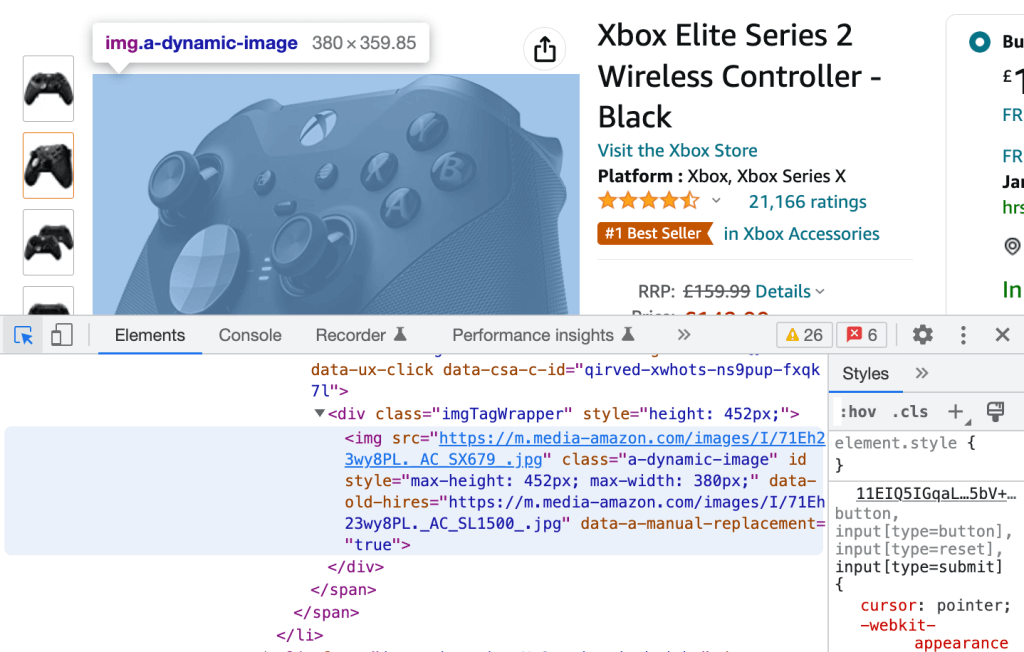
Umgekehrt können Sie auf das Symbol in der linken oberen Ecke klicken und ein beliebiges gerendertes Element auf der Webseite auswählen, um dessen (ebenfalls blau hervorgehobenen) HTML-Quellcode angezeigt zu bekommen.
Diese beiden Vorgänge sind alles, was Sie zum Extrahieren der CSS-Deskriptoren für unser praktisches Tutorial benötigen.
Eingehende Erläuterung des Web Scrapings mit R: Tutorial
In diesem Abschnitt erfahren Sie, wie Sie mit Web Scraping die Amazon-URL auslesen können, um Produktbewertungen zu extrahieren.
Voraussetzungen
Vergewissern Sie sich, dass in Ihrer RStudio-Umgebung folgende Komponenten installiert sind:
- R = 4.2.2
- rvest = 1.0.3
- tidyverse = 1.3.2
Interaktive Erkundung der Webseite
Sie können die DevTools von Chrome verwenden, um den HTML-Code Ihrer URL zu durchsuchen und eine Liste aller Klassen und IDs der HTML-Elemente zu erstellen, welche die für uns interessanten Informationen (d. h. die Produktbewertungen) enthalten:

Jede Kundenrezension entspricht einem div-Element mit einer id in folgendem Format:
customer_review_$INTERNAL_ID.
Der HTML-Inhalt des div-Elements, das zu der im obigen Screenshot gezeigten Kundenrezension gehört, lautet wie folgt:
<div id="customer_review-R2U9LWUSIPY0GS" class="a-section celwidget" data-csa-c-id="kj23dv-axnw47-69iej3-apdvzi" data-cel-widget="customer_review-R2U9LWUSIPY0GS">
<div data-hook="genome-widget" class="a-row a-spacing-mini">..</div>
<div class="a-row">
<a class="a-link-normal" title="4.0 out of 5 stars" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-4 review-rating">
<span class="a-icon-alt">4.0 out of 5 stars</span>
</i>
</a>
<span class="a-letter-space"></span>
<a data-hook="review-title" class="a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold" href="https://www.amazon.co.uk/gp/customer-reviews/R2U9LWUSIPY0GS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07SR4R8K1">
<span>Very good controller if a little overpriced</span>
</a>
</div>
<span data-hook="review-date" class="a-size-base a-color-secondary review-date">..</span>
<div class="a-row a-spacing-mini review-data review-format-strip">..</div>
<div class="a-row a-spacing-small review-data">
<span data-hook="review-body" class="a-size-base review-text">
<div data-a-expander-name="review_text_read_more" data-a-expander-collapsed-height="300" class="a-expander-collapsed-height a-row a-expander-container a-expander-partial-collapse-container" style="max-height:300px">
<div data-hook="review-collapsed" aria-expanded="false" class="a-expander-content reviewText review-text-content a-expander-partial-collapse-content">
<span>In all honesty I'm not sure why the price is quite as high ….</span>
</div>
…</div>
…</span>
…</div>
…</div>
Jedes Inhaltselement, an dem Sie im Zusammenhang mit den Kundenrezensionen interessiert sind, hat seine eigene Klasse: review-title-content für den Titel, review-text-content für den Textkörper und review-rating für die Bewertung.
Sie könnten prüfen, ob die Klasse im Dokument eindeutig ist, und direkt den „einfachen Selektor“ verwenden. Sicherer ist es, stattdessen den CSS-Deskriptor zu verwenden, der auch dann eindeutig bleibt, wenn die Klasse in Zukunft neuen Elementen zugewiesen wird.
Rufen Sie einfach den CSS-Deskriptor auf, indem Sie in den Entwicklertools mit der rechten Maustaste auf das Element klicken und die Option „Selektor kopieren“ auswählen:
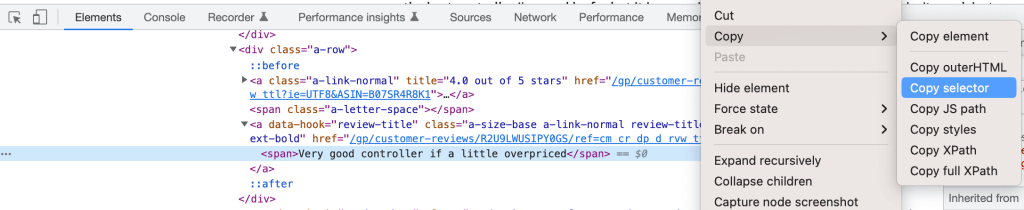
Sie können Ihre drei Selektoren wie folgt definieren:
customer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold > spanfür den Titelcustomer_review-R2U9LWUSIPY0GS > div.a-row.a-spacing-small.review-data > span > div > div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content > spanfür den Textkörpercustomer_review-R2U9LWUSIPY0GS > div:nth-child(2) > a:nth-child(1) > i.review-rating > spanfür die Bewertung *.review-ratingwurde zur Verbesserung der Kohärenz manuell hinzugefügt.
CSS-Selektor vs. XPath beim Web Scraping
Wir haben uns entschieden, in diesem Tutorial einen CSS-Selektor zu verwenden, um Elemente für das Web Scraping zu identifizieren. Eine andere gängige Methode ist die Verwendung von XPath, d. h. des XML-Pfads, der ein Element über seinen vollständigen Pfad im DOM identifiziert.
Sie können den vollständigen XPath nach demselben Verfahren wie für den CSS-Selektor extrahieren. Der Titel der Rezension lautet beispielsweise:
/html/body/div[2]/div[3]/div[6]/div[32]/div/div/div[2]/div/div[2]/span[2]/div/div/div[3]/div[3]/div/div[1]/div/div/div[2]/a[2]/span
Ein CSS-Selektor ist etwas schneller, während XPath eine etwas bessere Abwärtskompatibilität aufweist. Abgesehen von diesen geringfügigen Unterschieden hängt die Entscheidung für das eine oder das andere Verfahren eher von persönlichen Vorlieben als von technischen Aspekten ab.
Programmatische Extraktion von Informationen aus der Webseite
Zwar könnte man direkt die Konsole verwenden, um zu erkunden, wie man ein Web Scraping der URL durchführt, doch aus Gründen der Nachvollziehbarkeit und Reproduzierbarkeit werden wir stattdessen ein Skript erstellen und dieses mit dem Befehl source() über die Konsole ausführen.
Im Anschluss an die Erstellung des Skripts müssen Sie zunächst die installierten Bibliotheken laden:
library(”rvest”)
library(”tidyverse”)Danach können Sie die Inhalte, die Sie interessieren, wie folgt programmatisch extrahieren. Erstellen Sie zunächst eine Variable, in der Sie die zu durchsuchende URL speichern:
HtmlLink <- "https://www.amazon.co.uk/Xbox-Elite-Wireless-Controller-2/dp/B07SR4R8K1/ref=sr_1_1_sspa?crid=3F4M36E0LDQF3"
Im nächsten Schritt extrahieren Sie die Amazon Standard Identification Number (ASIN) aus der URL, um diese als eindeutige Produkt-ID zu verwenden:
ASIN <- str_match(HtmlLink, "/dp/([A-Za-z0-9]+)/")[,2]
Die Verwendung von RegEx zur Bereinigung des durch Web Scraping extrahierten Textes ist üblich und wird zur Gewährleistung der Datenqualität empfohlen.
Laden Sie nun den HTML-Inhalt der Webseite herunter:
HTMLContent <- read_html(HtmlLink)
Die Funktion read_html() ist Teil des xml2-Pakets.
Wenn Sie die Inhalte über die Funktion print() ausdrucken, werden Sie feststellen, dass sie mit der zuvor analysierten Struktur des HTML-Quellcodes korrespondieren:
{html_document}
<html lang="en-gb" class="a-no-js" data-19ax5a9jf="dingo">
[1] <head>n<meta http-equiv="Content-Type" content="text/ht ...
[2] <body class="a-aui_72554-c a-aui_accordion_a11y_role_354 ...
Nun können Sie die drei relevanten Knoten für alle Produktbewertungen auf der Seite extrahieren. Verwenden Sie die von den DevTools von Chrome bereitgestellten CSS-Deskriptoren, die so modifiziert wurden, dass die spezifische Kennung der Kundenrezension #customer_review-R2U9LWUSIPY0GS und der Konnektor „>“ aus der Zeichenkette entfernt werden. Außerdem können Sie die Funktionen html_nodes() und html_text() von rvest nutzen, um den HTML-Inhalt in separaten Objekten zu speichern.
Die folgenden Befehle dienen zum Extrahieren der Titel der Kundenrezensionen:
review_title <- HTMLContent %>%
html_nodes("div:nth-child(2) a.a-size-base.a-link-normal.review-title.a-color-base.review-title-content.a-text-bold span") %>%
html_text()
Beispiel für einen Eintrag unter review_title: „Sehr guter Controller, allerdings etwas überteuert“.
Der folgende Code extrahiert des Texts der Kundenrezensionen:
review_body <- HTMLContent %>%
html_nodes("div.a-row.a-spacing-small.review-data span div div.a-expander-content.reviewText.review-text-content.a-expander-partial-collapse-content span") %>%
html_text()
Beispiel: Ein Eintrag unter review_body beginnt mit den Worten „Um ehrlich zu sein, bin ich mir nicht sicher, was den Preis rechtfertigt“.
Mit folgenden Befehlen können Sie die Sternebewertung extrahieren:
review_rating <- HTMLContent %>%
html_nodes("div:nth-child(2) a:nth-child(1) i.review-rating span") %>%
html_text()
Beispiel für einen Eintrag unter review_rating: „4,0 von 5 Sternen“.
Zur Verbesserung der Qualität dieser Variablen extrahieren Sie nur die Bewertung „4,0“ und wandeln sie in um in int:
review_rating <- substr(review_rating, 1, 3) %>% as.integer()
Die Pipe-Funktionalität %>% wird durch das magrittr-Toolkit bereitgestellt.
Jetzt gilt es, die gescrapten Inhalte in ein tibble für die Datenanalyse zu exportieren. tibble ist ein R-Paket, das ebenfalls Teil der tidyverse-Sammlung ist und zur Bearbeitung und Ausgabe von Datenrahmen verwendet wird.
df <- tibble(review_title, review_body, review_rating)
Der ausgegebene Datenrahmen sieht wie folgt aus:

Abschließend empfiehlt es sich, den Code in die Funktion scrape_amazon <- function(HtmlLink) umzuformulieren, um die Best Practices zu erfüllen und den Code optimal auf die Skalierung auf mehrere URLs vorzubereiten.
Skalierung auf mehrere URLs
Nach der Erstellung der Web-Scraping-Vorlage können Sie mittels Web-Crawling und Scraping eine Liste von URLs für alle Produkte der wichtigsten Wettbewerber auf Amazon erstellen.
Beim Skalieren auf mehrere URLs zur Erzielung einer produktiven Lösung müssen die technischen Anforderungen der Anwendung umrissen werden.
Genau definierte technische Anforderungen stellen sicher, dass die geschäftlichen Anforderungen ordnungsgemäß unterstützt werden und eine nahtlose Integration in Ihre bestehenden Systeme erfolgt.
Entsprechend den spezifischen technischen Anforderungen muss die Scraping-Funktion aktualisiert werden, um eine Kombination aus folgenden Möglichkeiten zu unterstützen:
- Echtzeit- oder Batch-Prozess
- Ausgabeziel(e), wie z. B. E-Mail, API, Webhook oder Cloud-Speicher
- Ausgabeziel(e), wie z. B. E-Mail, API, Webhook oder Cloud-Speicher
Wie bereits erwähnt, können Sie rvest mit polite erweitern, um mehrere Webseiten zu scrapen. polite erstellt und verwaltet eine Web-Harvesting-Sitzung über drei Hauptfunktionen, unter vollständiger Berücksichtigung der robots.txt-Datei des Webhosts sowie mit integrierter Ratenbegrenzung und Antwort-Caching:
bow()legt die Scraping-Sitzung für eine bestimmte URL an, d. h. sie meldet Sie beim Webhost an und bittet um Erlaubnis zum Scrapen.scrape()greift auf den HTML-Code der URL zu. Sie können diese Funktion zum Abrufen bestimmter Inhalte anhtml_nodes()undhtml_text()von rvest weiterleiten.nod()aktualisiert die Sitzungs-URL für die nächste Seite, ohne dass eine Sitzung neu erstellt werden muss.
Ein Zitat von der Website: „Die drei wichtigsten Pfeiler einer polite-Sitzung lauten: um Erlaubnis bitten, mit Bedacht vorgehen und nie zweimal fragen.“
Nächster Schritt: Vorgefertigt oder selbst erstellt?
Um einen hochmodernen Web Scraper entwickeln zu können, der aussagekräftige Daten für ein Unternehmen extrahieren kann, müssen einige Voraussetzungen gegeben sein:
- Ein Team von Datenspezialisten mit Erfahrung im Bereich der Extraktion von Webdaten
- Ein Team von DevOps-Ingenieuren mit Erfahrung im Proxy-Management und bei der Umgehung von Anti-Bots, um CAPTCHAs zu überwinden und weniger öffentlich zugängliche Websites aufrufen zu können
- Ein Team von Dateningenieuren mit Fachkenntnissen im Aufbau einer Infrastruktur für die Echtzeit- und Batch-Datenextraktion
- Ein Team von Rechtsexperten, die mit den gesetzlichen Bestimmungen zum Datenschutz (wie z. B. DSGVO und CCPA) vertraut sind
Inhalte für das Web haben verschiedene Formate, und es ist schwierig, zwei Websites mit genau der gleichen Struktur zu finden. Je komplexer eine Website aufgebaut ist und je mehr Funktionen und Daten abgefragt werden müssen, desto mehr Programmierkenntnisse sind erforderlich, ganz zu schweigen vom zusätzlichen Zeit- und Ressourcenaufwand für eine solche Lösung.
Im Normalfall sollten zumindest die folgenden erweiterten Funktionen implementiert werden:
- Minimierung der Wahrscheinlichkeit von CAPTCHAs und Bot-Erkennung: Ein relativ einfacher Ansatz besteht darin, ein zufälliges sleep() hinzuzufügen, um eine Überlastung der Webserver und regelmäßige Anfragemuster zu vermeiden. Effektiver ist die Verwendung eines user_agent oder Proxy-Servers zur Verteilung der Anfragen auf unterschiedliche IPs.
- Scraping von JavaScript-gesteuerten Websites: In unserem Amazon-Beispiel ändert sich die URL bei Auswahl einer bestimmten Produktvariante nicht. Dies ist für das Scraping von Produktbewertungen akzeptabel, da diese geteilt werden, aber nicht für das Scraping von Produktspezifikationen. Zur Nachahmung von Benutzerinteraktionen auf dynamischen Webseiten können Sie ein Tool wie RSelenium verwenden, das die Navigation im Webbrowser automatisiert.
Wenn Sie mit begrenzten Ressourcen auf Webdaten zugreifen, die Qualität der Daten gewährleisten oder erweiterte Anwendungsfälle erschließen möchten, kann ein vorgefertigter Web Scraper die richtige Wahl sein.
Der Web Scraper von Bright Data bietet Vorlagen für zahlreiche Websites und verfügt über modernste Funktionen, einschließlich einer wesentlich fortschrittlicheren Implementierung des vorgestellten Amazon Scraper!





