

Beim Web-Scraping stößt man häufig auf Paginierung, bei der Inhalte auf mehrere Seiten verteilt sind. Der Umgang mit dieser Paginierung kann eine Herausforderung sein, da verschiedene Websites unterschiedliche Paginierungstechniken verwenden.
In diesem Artikel erkläre ich die gängigen Paginierungstechniken und zeige anhand eines praktischen Code-Beispiels, wie man damit umgeht.
Was ist Paginierung?
Websites wie E-Commerce-Plattformen, Jobbörsen und soziale Medien verwenden Paginierung, um große Datenmengen zu verwalten. Die Anzeige aller Inhalte auf einer Seite würde die Ladezeiten erheblich verlängern und zu viel Speicherplatz beanspruchen. Die Paginierung teilt den Inhalt auf mehrere Seiten auf und bietet Navigationsoptionen wie „Weiter“, Seitenzahlen oder automatisches Laden beim Scrollen. Dadurch wird das Surfen schneller und übersichtlicher.
Arten der Paginierung
Die Komplexität der Paginierung kann variieren und reicht von einfacher nummerierter Paginierung bis hin zu fortgeschritteneren Techniken wie unendlichem Scrollen oder dynamischem Laden von Inhalten. Nach meiner Erfahrung gibt es drei Hauptarten der Paginierung, die meiner Meinung nach am häufigsten auf Websites verwendet werden:
- Nummerierte Paginierung: Benutzer navigieren mithilfe nummerierter Links durch einzelne Seiten.
- Klick-zum-Laden-Paginierung: Benutzer klicken auf eine Schaltfläche (z. B. „Mehr laden“), um zusätzliche Inhalte zu laden.
- Infinite Scrolling: Der Inhalt wird automatisch geladen, wenn Benutzer auf der Seite nach unten scrollen.
Schauen wir uns diese Arten einmal genauer an!
Nummerierte Paginierung
Dies ist die gängigste Paginierungstechnik, die oft als „Nächste und vorherige Paginierung“, „Pfeil-Paginierung“ oder „URL-basierte Paginierung“ bezeichnet wird. Trotz der unterschiedlichen Bezeichnungen ist die Grundidee dieselbe: Die Seiten sind über nummerierte Links miteinander verbunden. Sie können navigieren, indem Sie die Seitenzahl in der URL ändern. Um zu wissen, wann die Paginierung beendet ist, können Sie überprüfen, ob die Schaltfläche „Weiter“ deaktiviert ist oder ob keine neuen Daten verfügbar sind.
In der Regel sieht das so aus:

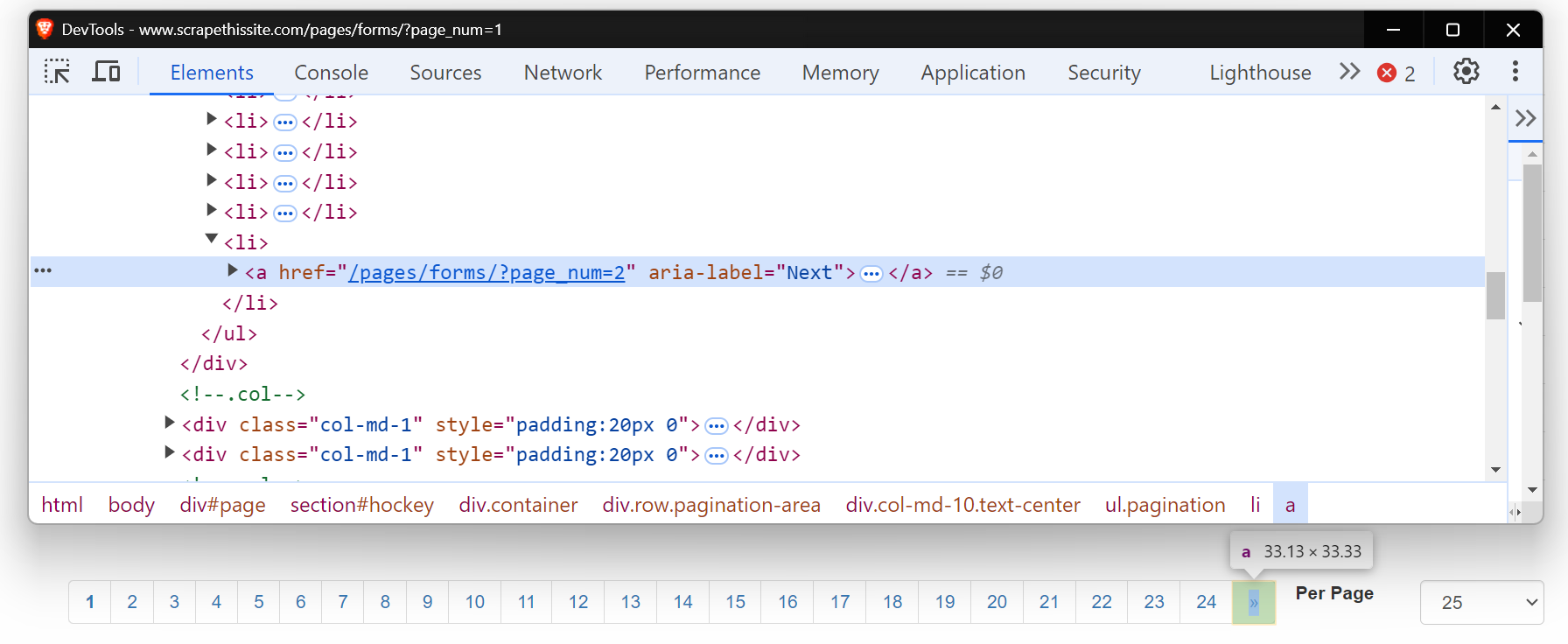
Nehmen wir ein Beispiel! Wir navigieren durch alle Seiten der Website Scrapethesite. Die Paginierungsleiste für diese Website umfasst insgesamt 24 Seiten.

Sie werden feststellen, dass sich die URL beim Klicken auf die Schaltfläche „>>“ wie folgt ändert:
- 1. Seite: https://www.scrapethissite.com/pages/forms/
- 2. Seite: https://www.scrapethissite.com/pages/forms/?page_num=2
- 3. Seite: https://www.scrapethissite.com/pages/forms/?page_num=3
Sehen Sie sich nun den HTML-Code dieser Schaltfläche „Weiter” an. Es handelt sich um einen Anker-Tag (<a>) mit einem href-Attribut, das auf die nächste Seite verweist. Das Attribut aria-label zeigt an, dass die Schaltfläche „Weiter” noch aktiv ist.
Wenn keine weiteren Seiten vorhanden sind, fehlt das aria-label, was das Ende der Paginierung anzeigt.
Beginnen wir damit, einen einfachen Web-Scraper zu schreiben, um durch diese Seiten zu navigieren. Richten Sie zunächst Ihre Umgebung ein, indem Sie die erforderlichen Pakete installieren. Eine ausführliche Anleitung zum Web-Scraping mit Python finden Sie in diesem Blogbeitrag.
pip install requests beautifulsoup4 lxmlHier ist der Code zum Paginieren jeder Seite:
import requests
from bs4 import BeautifulSoup
base_url = "https://www.scrapethissite.com/pages/forms/?page_num="
# Beginne mit Seite 1
page_num = 1
while True:
url = f"{base_url}{page_num}"
response = requests.get(url)
soup = BeautifulSoup(response.content, "lxml")
print(f"Derzeit auf Seite: {page_num}")
# Prüfen, ob die Schaltfläche „Weiter” vorhanden ist
next_button = soup.find("a", {"aria-label": "Next"})
if next_button:
# Zur nächsten Seite wechseln
page_num += 1
else:
# Keine weiteren Seiten, Schleife beenden
print("Letzte Seite erreicht.")
breakDieser Code navigiert durch die Seiten, indem er überprüft, ob die Schaltfläche „Weiter” (mit aria-label="Weiter") vorhanden ist. Ist die Schaltfläche vorhanden, erhöht er die Seite_Nummer und stellt eine neue Anfrage mit der aktualisierten URL. Die Schleife wird fortgesetzt, bis die Schaltfläche „Weiter” nicht mehr gefunden wird, was die letzte Seite anzeigt.
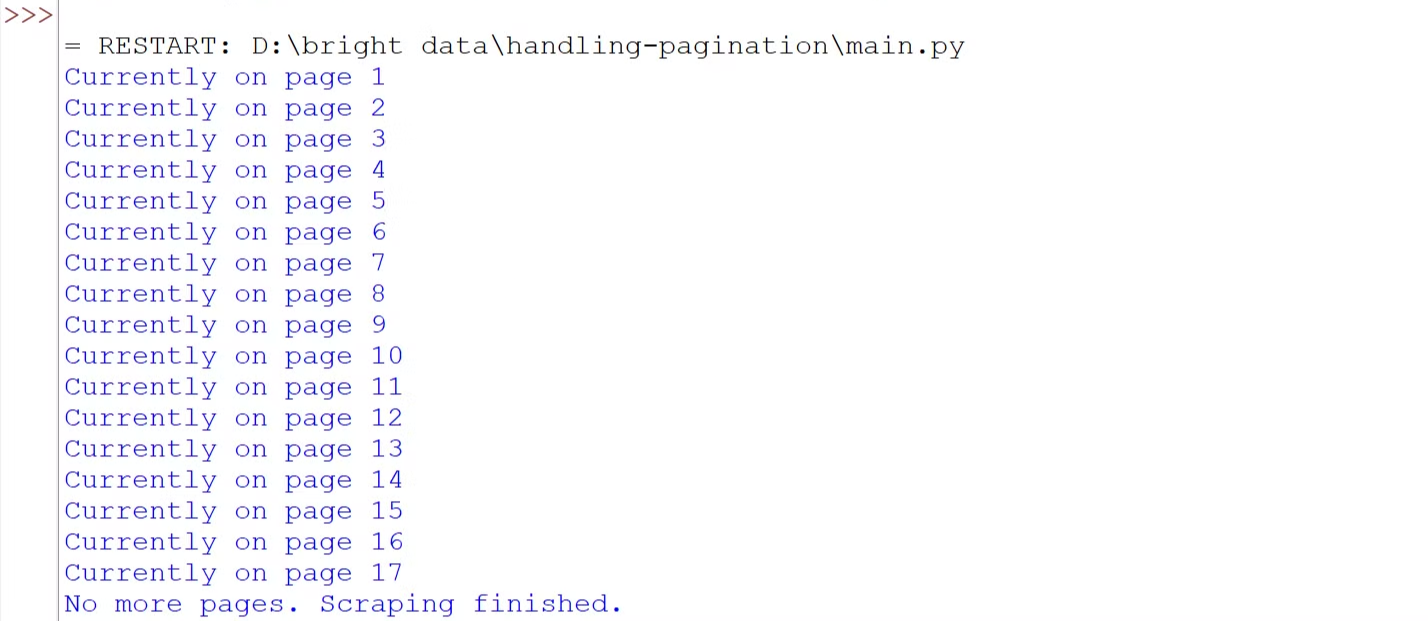
Führen Sie den Code aus, und Sie werden sehen, dass wir erfolgreich alle Seiten durchlaufen haben.

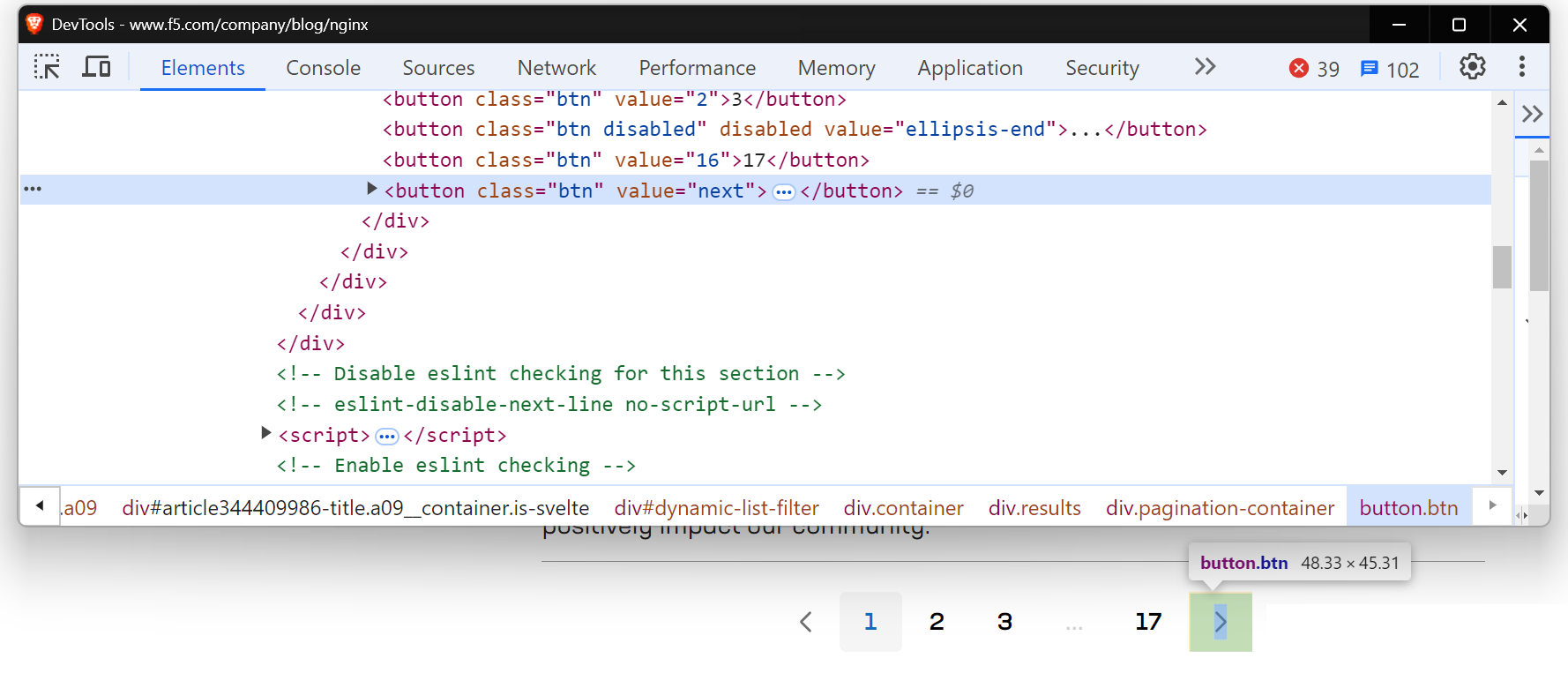
Einige Websites haben eine Schaltfläche „Weiter“, die die URL nicht ändert, aber dennoch neue Inhalte auf derselben Seite lädt. In solchen Fällen funktionieren herkömmliche Web-Scraping-Methoden möglicherweise nicht gut. Tools wie Selenium oder Playwright sind besser geeignet, da sie mit der Seite interagieren und Aktionen wie das Klicken auf Schaltflächen simulieren können, um die dynamisch geladenen Inhalte abzurufen. Weitere Informationen zur Verwendung von Selenium für solche Aufgaben finden Sie in dieser ausführlichen Anleitung.
Eine ähnliche Situation tritt auf, wenn Sie versuchen, die NGINX -Blogseite zu scrapen.
Verwenden wir Playwright, um dynamisch geladene Inhalte zu verarbeiten. Wenn Sie Playwright noch nicht kennen, lesen Sie diese hilfreiche Anleitung für den Einstieg.
Bevor Sie den Code schreiben, führen Sie den folgenden Befehl aus, um Playwright auf Ihrem Rechner einzurichten:
pip install playwright
playwright installHier ist der Code:
import asyncio
from playwright.async_api import async_playwright
# Asynchrone Funktion definieren
async def scrape_nginx_blog():
async with async_playwright() as p:
# Chromium-Browserinstanz im Headless-Modus starten
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Zur NGINX-Blogseite navigieren
await page.goto("https://www.f5.com/company/blog/nginx")
page_num = 1
while True:
print(f"Derzeit auf Seite {page_num}")
# Suche die Schaltfläche „Weiter” mithilfe eines Schaltflächen-Lokalisierers mit dem Wert „next”
next_button = page.locator('button[value="next"]')
# Überprüfen Sie, ob die Schaltfläche „Weiter” aktiviert ist.
if await next_button.is_enabled():
await next_button.click() # Klicken Sie auf die Schaltfläche „Weiter”, um zur nächsten Seite zu gelangen.
await page.wait_for_timeout(
2000
) # Warten Sie 2 Sekunden, damit neue Inhalte geladen werden können.
page_num += 1
else:
print("Keine weiteren Seiten. Scraping abgeschlossen.")
break # Beenden Sie die Schleife, wenn keine weiteren Seiten verfügbar sind.
await browser.close() # Schließen Sie den Browser.
# Führen Sie die asynchrone Scraping-Funktion aus.
asyncio.run(scrape_nginx_blog())Der Code verwendet asynchrones Playwright, um durch alle Seiten zu navigieren. Er tritt in eine Schleife ein, die nach der Schaltfläche „Weiter” sucht. Wenn die Schaltfläche aktiviert ist, klickt er darauf, um zur nächsten Seite zu gelangen, und wartet, bis der Inhalt geladen ist. Dieser Vorgang wiederholt sich, bis keine Seiten mehr verfügbar sind. Schließlich wird der Browser geschlossen, sobald das Scraping abgeschlossen ist.
Führen Sie den Code aus, und Sie werden sehen, dass wir erfolgreich alle Seiten durchlaufen haben.
Klick-zum-Laden-Paginierung
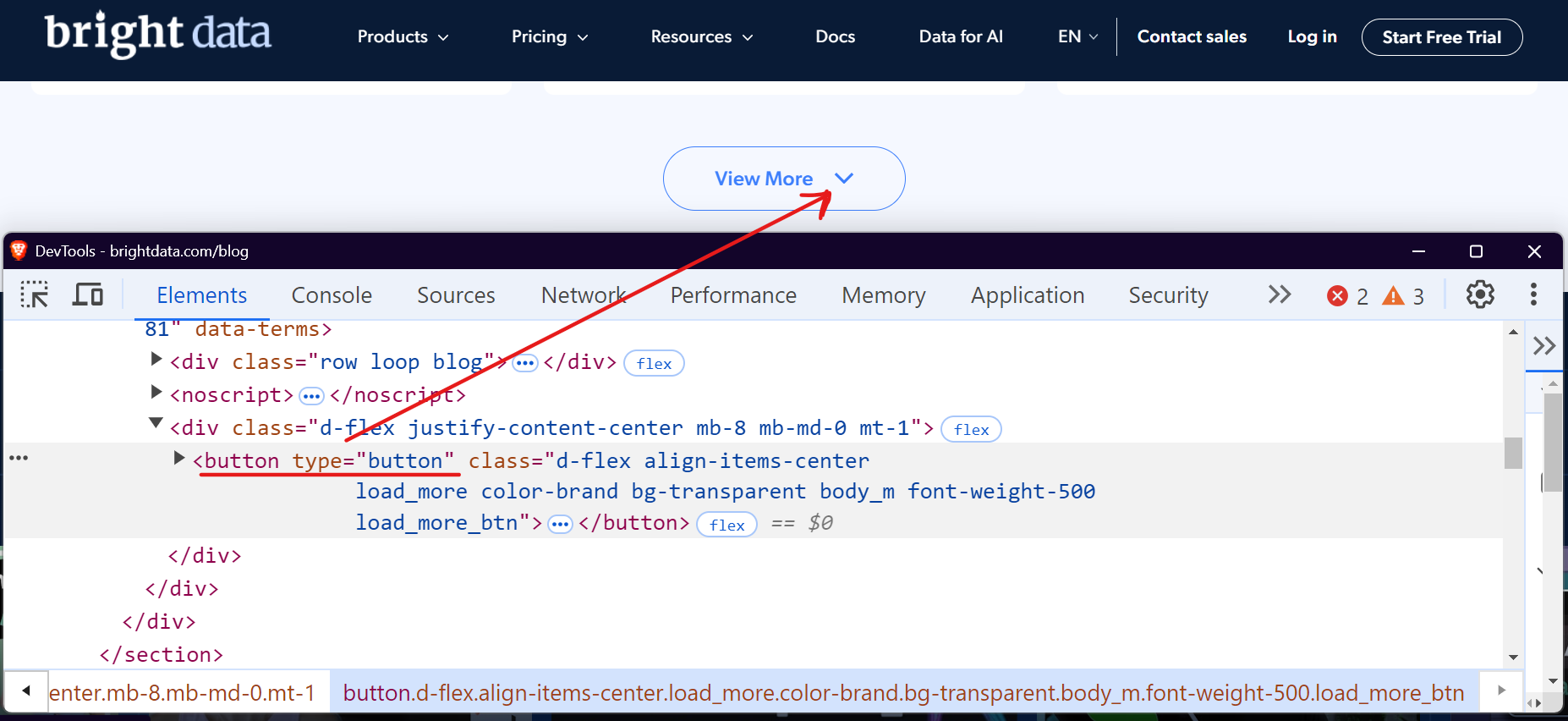
Auf vielen Websites haben Sie wahrscheinlich schon Schaltflächen wie „Mehr laden”, „Mehr anzeigen” oder „Mehr anzeigen” gesehen. Dies sind Beispiele für Click-to-Load-Paginierung, die häufig auf modernen Websites verwendet wird. Diese Schaltflächen laden Inhalte dynamisch über JavaScript. Die größte Herausforderung besteht dabei darin, die Benutzerinteraktion zu simulieren – also den Vorgang des Klickens auf die Schaltfläche zum Laden weiterer Inhalte zu automatisieren.
Nehmen wir als Beispiel den Blog-Bereich von Bright Data. Wenn Sie diesen besuchen und nach unten scrollen, sehen Sie eine Schaltfläche „Mehr anzeigen“, die Blog-Beiträge lädt, wenn Sie darauf klicken.
Sie können Tools wie Selenium oder Playwright verwenden, um diesen Vorgang zu automatisieren, indem Sie wiederholt auf die Schaltfläche „Mehr laden“ klicken, bis keine weiteren Inhalte mehr verfügbar sind. Sehen wir uns an, wie wir dies mit Playwright ganz einfach bewerkstelligen können.
import asyncio
from playwright.async_api import async_playwright
async def scrape_brightdata_blog():
async with async_playwright() as p:
# Starten Sie einen Headless-Browser.
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Zum Bright Data-Blog navigieren
await page.goto("https://brightdata.com/blog")
page_num = 1
while True:
print(f"Derzeit auf Seite {page_num}")
# Die Schaltfläche „Mehr anzeigen” suchen
view_more_button = page.locator("button.load_more_btn")
# Prüfen, ob die Schaltfläche sichtbar und aktiviert ist
if (
await view_more_button.count() > 0
and await view_more_button.is_visible()
):
await view_more_button.click()
await page.wait_for_timeout(2000)
page_num += 1
else:
print("Keine weiteren Seiten zum Laden. Scraping abgeschlossen.")
break
# Browser schließen
await browser.close()
# Scraping-Funktion ausführen
asyncio.run(scrape_brightdata_blog())Der Code lokalisiert die Schaltfläche „View More“ mithilfe des CSS-Selektors button.load_more_btn. Anschließend überprüft er mit count() > 0 und is_visible(), ob die Schaltfläche vorhanden und sichtbar ist. Ist die Schaltfläche sichtbar, interagiert er mit ihr mithilfe der Methode click() und wartet 2 Sekunden, damit neue Inhalte geladen werden können. Dieser Vorgang wiederholt sich in einer Schleife, bis die Schaltfläche nicht mehr sichtbar ist.
Führen Sie den Code aus, und Sie werden sehen, dass wir erfolgreich alle Seiten durchlaufen haben.

Wir haben alle 52 Seiten aus dem Blog-Bereich von Bright Data erfolgreich gescrapt. Dies zeigt, dass die Website insgesamt 52 Seiten hat, was wir erst nach dem Scraping-Vorgang festgestellt haben. Es ist jedoch möglich, die Gesamtzahl der Seiten vor dem Scraping zu erfahren.
Öffnen Sie dazu die Entwicklertools, navigieren Sie zur Registerkarte „Netzwerk“ und filtern Sie die Anfragen, indem Sie „Fetch/XHR“ auswählen. Klicken Sie dann erneut auf die Schaltfläche „Mehr anzeigen“ und Sie werden feststellen, dass eine AJAX-Anfrage ausgelöst wird.
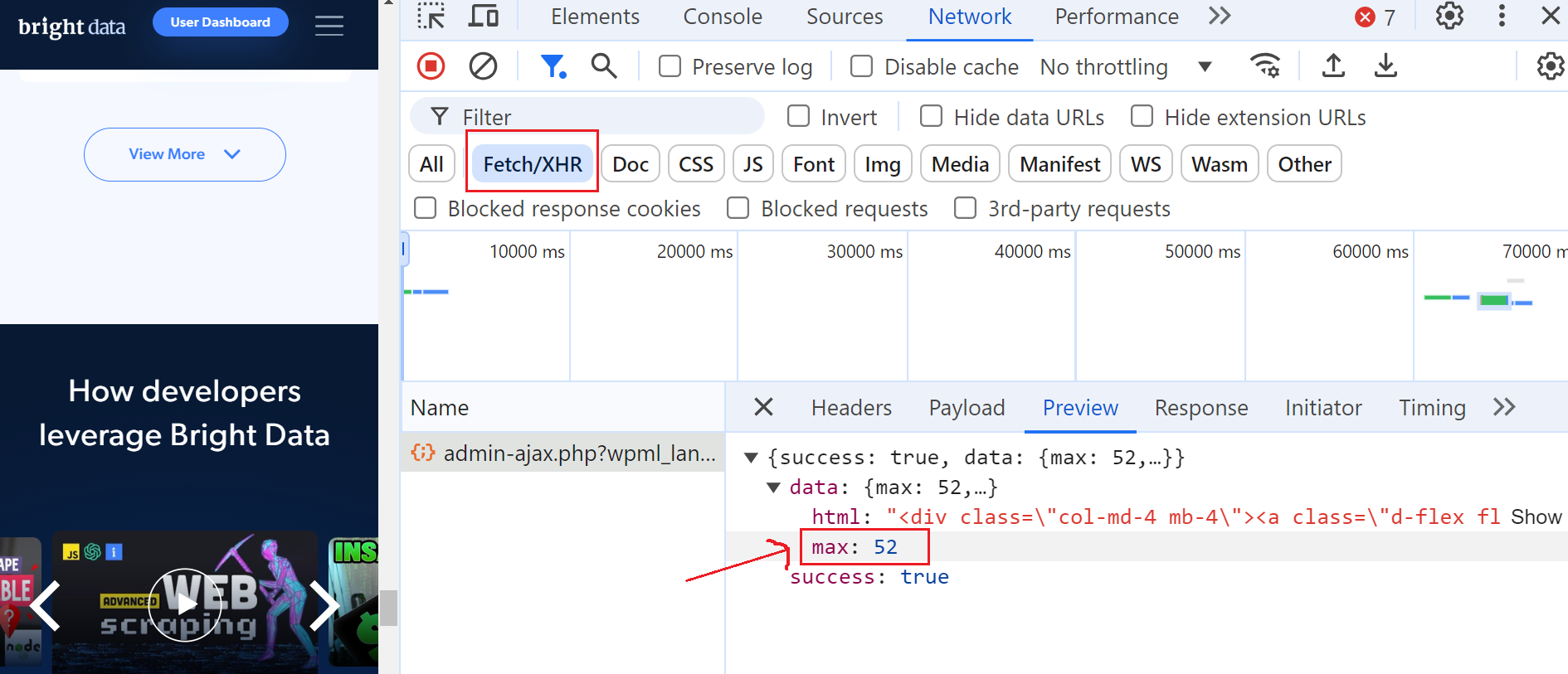
Klicken Sie auf diese Anfrage und navigieren Sie zum Abschnitt „Vorschau“, wo Sie sehen, dass die maximale Anzahl von Seiten 52 beträgt. Gehen Sie dann zum Abschnitt „Nutzlast“ und Sie werden feststellen, dass es 6 Blog-Beiträge pro Seite gibt und wir uns derzeit auf Seite 3 befinden.
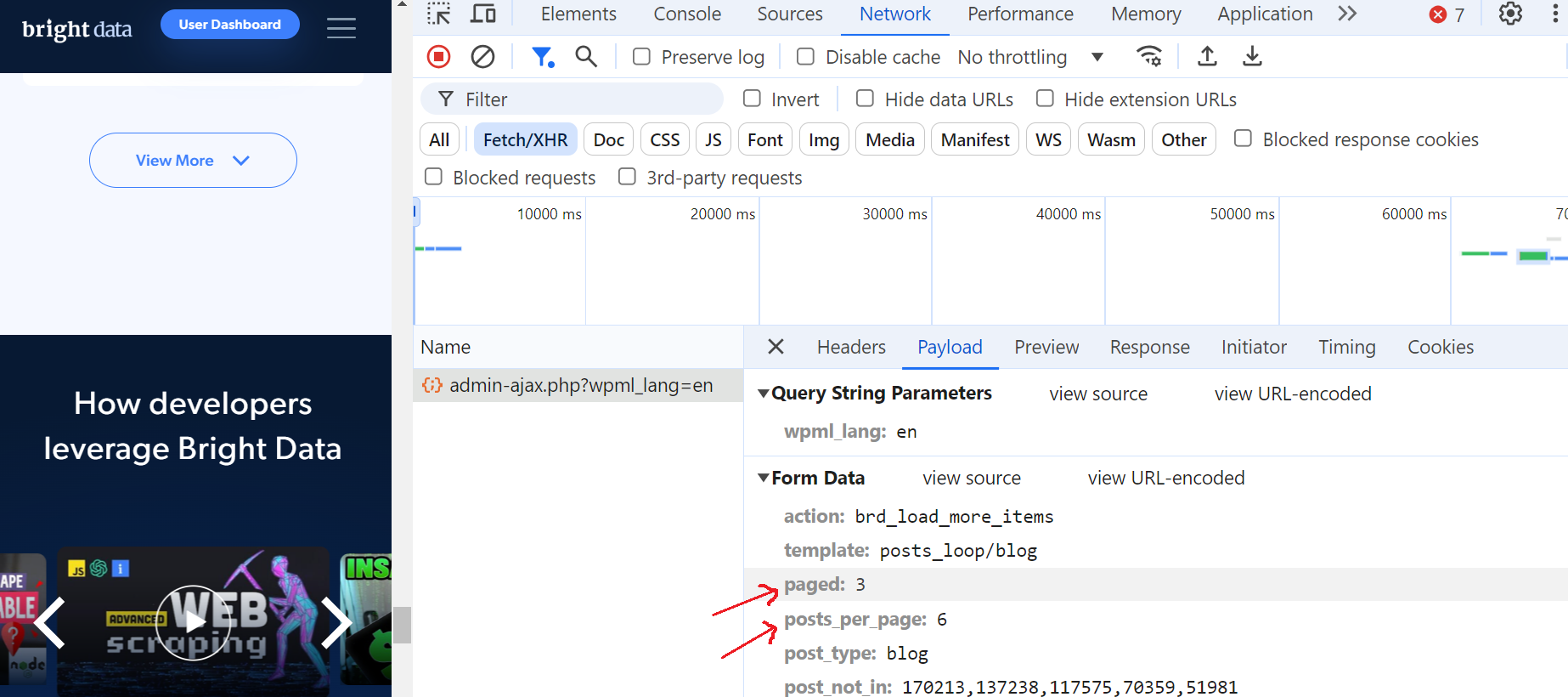
Das ist fantastisch!
Unendliche Bildlauf-Paginierung
Anstelle von „Vorherige/Nächste“-Schaltflächen verwenden viele Websites heute unendliches Scrollen, was die Benutzererfahrung verbessert, da nicht mehr durch mehrere Seiten geklickt werden muss. Diese Technik lädt automatisch neue Inhalte, wenn der Benutzer nach unten scrollt. Für Scraper stellt dies jedoch eine besondere Herausforderung dar, da DOM-Änderungen überwacht und AJAX-Anfragen verarbeitet werden müssen.
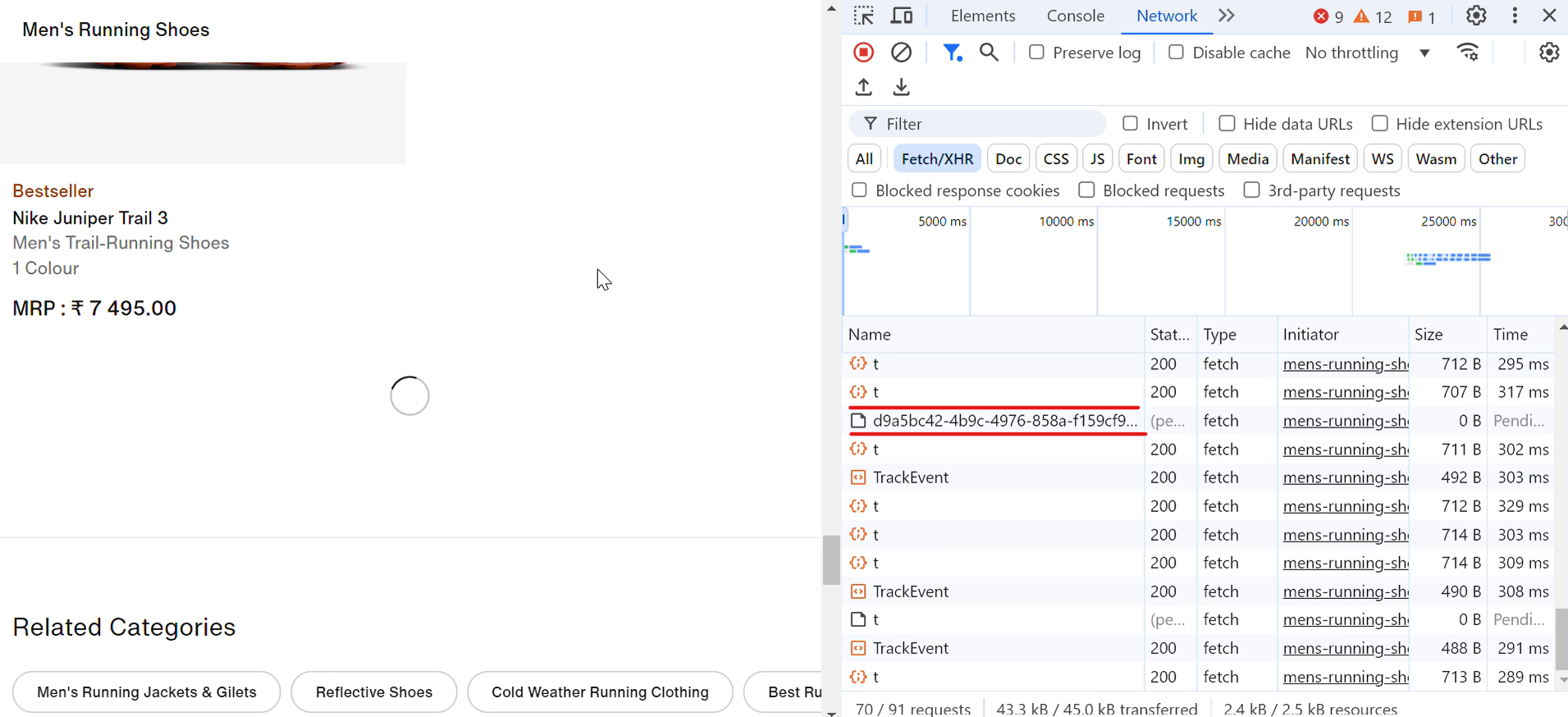
Nehmen wir ein Beispiel aus der Praxis. Wenn Sie die Nike-Website besuchen, werden Sie feststellen, dass Schuhe automatisch geladen werden, wenn Sie nach unten scrollen. Bei jedem Scrollen erscheint kurz ein Ladesymbol, und im Handumdrehen werden weitere Schuhe angezeigt, wie in der folgenden Abbildung dargestellt:
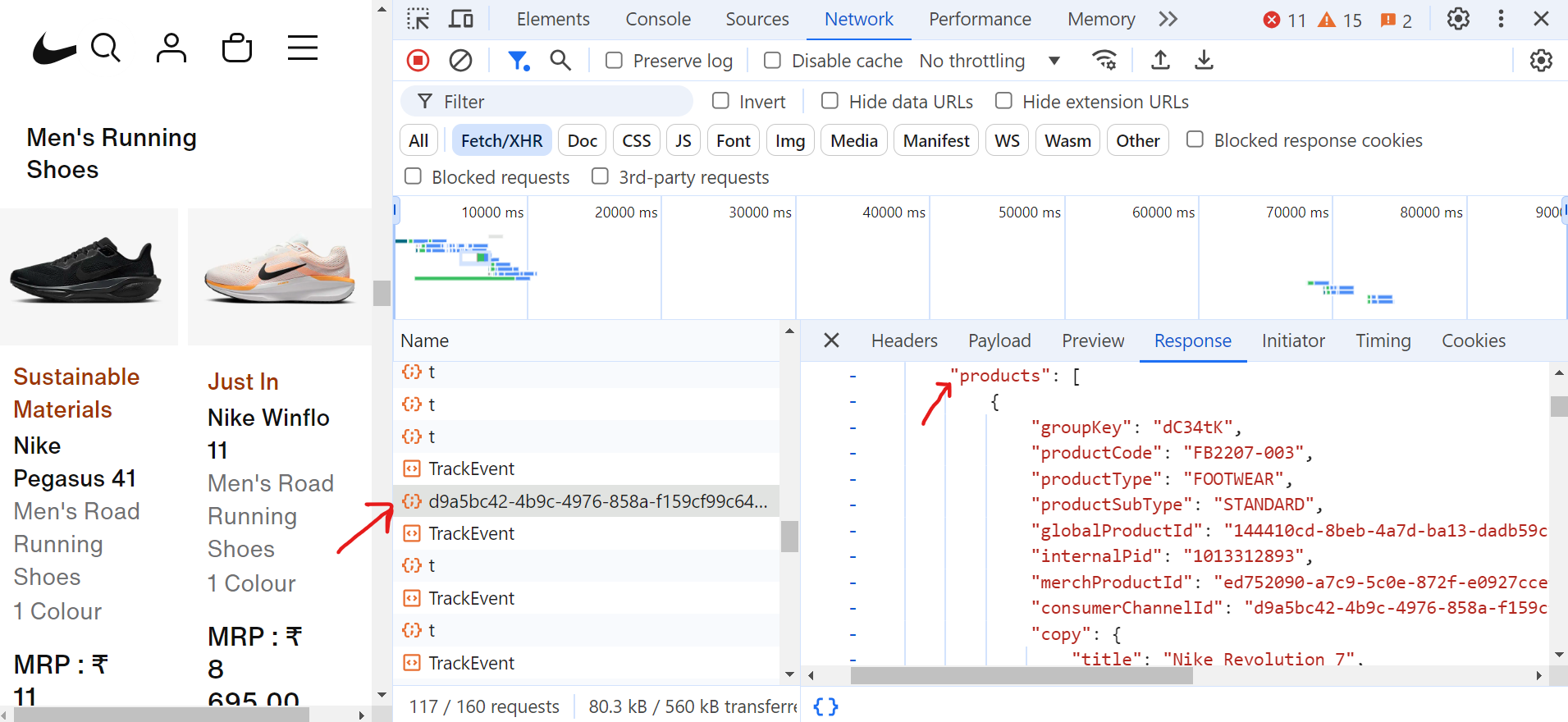
Wenn Sie auf die Anfrage (d9a5bc) klicken, finden Sie alle Daten für die aktuelle Seite auf der Registerkarte „Response” (Antwort).
Um die Paginierung zu verarbeiten, müssen Sie nun so lange nach unten scrollen, bis Sie das Ende der Seite erreichen. Während Sie scrollen, sendet der Browser viele Anfragen, aber nur einige dieser Fetch/XHR-Anfragen enthalten die tatsächlich benötigten Daten.
Hier ist der Code, der die Paginierung verarbeitet und die Titel der Schuhe extrahiert:
import asyncio
from urllib.parse import parse_qs, urlparse
from playwright.async_api import async_playwright
async def scroll_to_bottom(page) -> None:
"""Scroll to the bottom of the page until no more content is loaded."""
last_height = await page.evaluate("document.body.scrollHeight")
scroll_count = 0
while True:
# Nach unten scrollen
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(2) # Warten, bis neue Inhalte geladen sind
scroll_count += 1
print(f"Scroll-Iteration: {scroll_count}")
# Prüfen, ob sich die Scroll-Höhe geändert hat
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
print("Ende der Seite erreicht.")
break # Beenden, wenn keine neuen Inhalte geladen wurden
last_height = new_height
async def extract_product_data(response, extracted_products) -> None:
"""Produktdaten aus der Antwort extrahieren."""
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
if "queryType" in query_params and query_params["queryType"][0] == "PRODUCTS":
data = await response.json()
for grouping in data.get("productGroupings", []):
for product in grouping.get("products", []):
title = product.get("copy", {}).get("title")
extracted_products.append({"title": title})
async def scrape_shoes(target_url: str) -> None:
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
extracted_products = []
# Listener für Produktdatenantworten einrichten
page.on(
"response",
lambda response: extract_product_data(
response, extracted_products),
)
# Zur Seite navigieren und zum Ende scrollen
print("Navigieren zur Seite...")
await page.goto(target_url, wait_until="domcontentloaded")
await asyncio.sleep(2)
await scroll_to_bottom(page)
# Speichern der Produkttitel in einer Textdatei
with open("product_titles.txt", "w") as title_file:
for product in extracted_products:
title_file.write(product["title"] + "n")
print(f"Scraping abgeschlossen!")
await browser.close()
if __name__ == "__main__":
asyncio.run(
scrape_shoes(
"https://www.nike.com/in/w/mens-running-shoes-37v7jznik1zy7ok")
)Im Code scrollt die Funktion scroll_to_bottom kontinuierlich zum Ende der Seite, um weitere Inhalte zu laden. Zunächst wird die aktuelle Scroll-Höhe aufgezeichnet, dann wird wiederholt nach unten gescrollt. Nach jedem Scroll wird überprüft, ob sich die neue Scroll-Höhe von der zuletzt aufgezeichneten Höhe unterscheidet. Bleibt die Höhe unverändert, wird davon ausgegangen, dass keine weiteren Inhalte geladen werden, und die Schleife wird beendet. Dieser Ansatz stellt sicher, dass alle verfügbaren Produkte vollständig geladen sind, bevor der Scraping-Prozess fortgesetzt wird.
Das passiert, wenn Sie den Code ausführen:

Nach erfolgreicher Ausführung des Codes wird eine neue Textdatei erstellt, die alle Titel der Nike-Schuhe enthält.
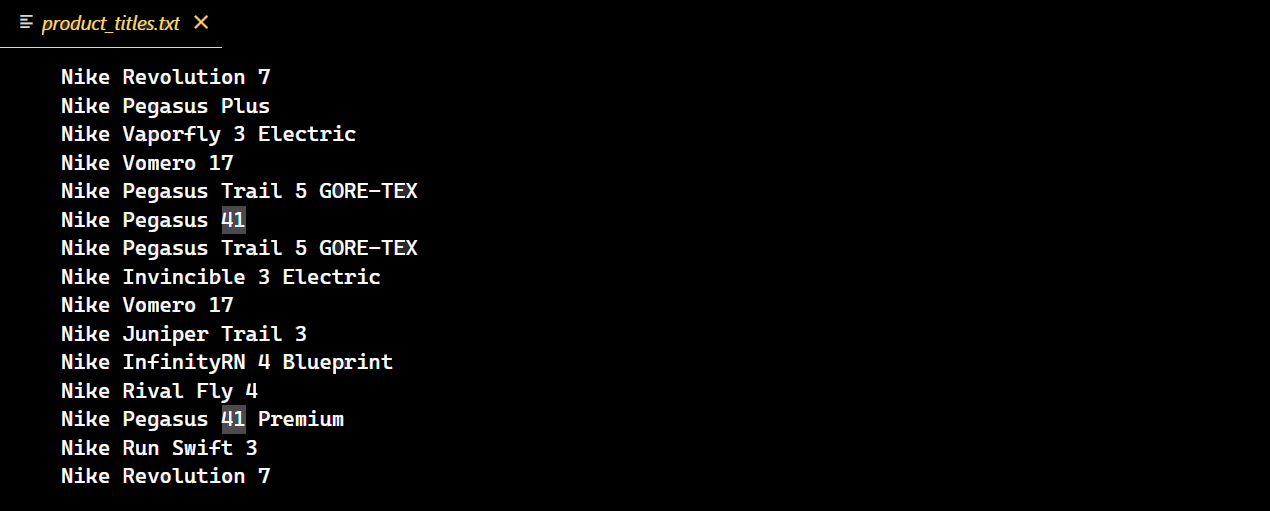
Herausforderungen bei der Paginierung
Das Risiko, blockiert zu werden, steigt bei paginierten Inhalten, und einige Websites blockieren Sie möglicherweise bereits nach einer Seite. Wenn Sie beispielsweise versuchen, Glassdoor zu scrapen, können verschiedene Herausforderungen beim Web-Scraping auftreten, darunter die Cloudflare-CAPTCHA-Herausforderung, wie ich selbst erfahren habe.
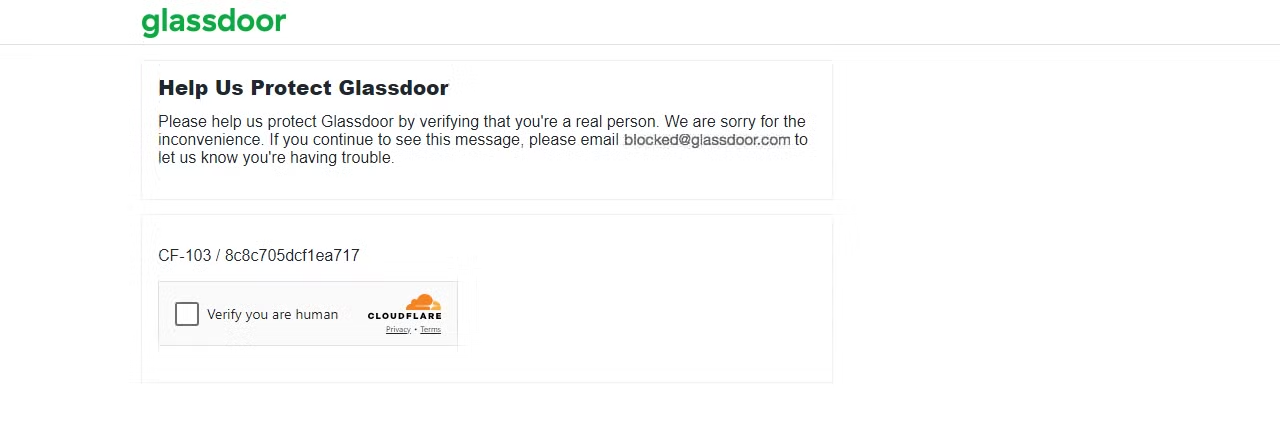
Senden wir eine Anfrage an die Glassdoor-Seite und sehen wir, was passiert.
import requests
url = "https://www.glassdoor.com/"
response = requests.get(url)
print(f"Status code: {response.status_code}")Das Ergebnis ist ein 403-Statuscode.
Dies zeigt, dass Glassdoor Ihre Anfrage als von einem Bot oder Scraper stammend erkannt hat, was zu einer CAPTCHA-Herausforderung führt. Wenn Sie weiterhin mehrere Anfragen senden, könnte Ihre IP-Adresse sofort gesperrt werden.
Um diese Sperren zu umgehen und die benötigten Daten effektiv zu extrahieren, können Sie in Python Requests Proxys verwenden, um IP-Sperren zu vermeiden, oder einen echten Browser imitieren, indem Sie den User Agent rotieren. Es ist jedoch wichtig zu beachten, dass keine dieser Methoden garantieren kann, dass eine erweiterte Bot-Erkennung umgangen wird.
Was ist also die ultimative Lösung? Lassen Sie uns als Nächstes darauf eingehen!
Bright Data Solutions integrieren
Bright Data ist eine hervorragende Lösung, um ausgefeilte Anti-Bot-Maßnahmen zu umgehen. Es lässt sich mit nur wenigen Zeilen Code nahtlos in Ihr Projekt integrieren und bietet eine Reihe von Lösungen für alle fortschrittlichen Anti-Bot-Mechanismen.
Eine dieser Lösungen ist die Web-Scraper-API, die die Datenextraktion von jeder Website vereinfacht, indem sie automatisch die IP-Rotation und die CAPTCHA-Lösung übernimmt. So können Sie sich auf die Datenanalyse konzentrieren, anstatt sich mit den Feinheiten der Datenbeschaffung zu beschäftigen.
In unserem Fall stießen wir beispielsweise auf Herausforderungen, als wir versuchten, das CAPTCHA auf Glassdoor zu umgehen. Um dies zu bewerkstelligen, können Sie die Glassdoor-Scraper-API von Bright Data verwenden, die speziell dafür entwickelt wurde, solche Hindernisse zu umgehen und Daten nahtlos von der Website zu extrahieren.
Um mit der Glassdoor Scraper API zu beginnen, führen Sie die folgenden Schritte aus:
Erstellen Sie zunächst ein Konto. Besuchen Sie die Website von Bright Data, klicken Sie auf „Gratis testen“ und folgen Sie den Anweisungen zur Anmeldung. Nach der Anmeldung werden Sie zu Ihrem Dashboard weitergeleitet, wo Sie einige kostenlose Credits erhalten.
Gehen Sie nun zum Abschnitt „Web Scraper API“ und wählen Sie „Glassdoor“ unter der Kategorie „B2B-Daten“ aus. Dort finden Sie verschiedene Optionen zur Datenerfassung, z. B. das Erfassen von Unternehmen nach URL oder das Erfassen von Stellenangeboten nach URL.
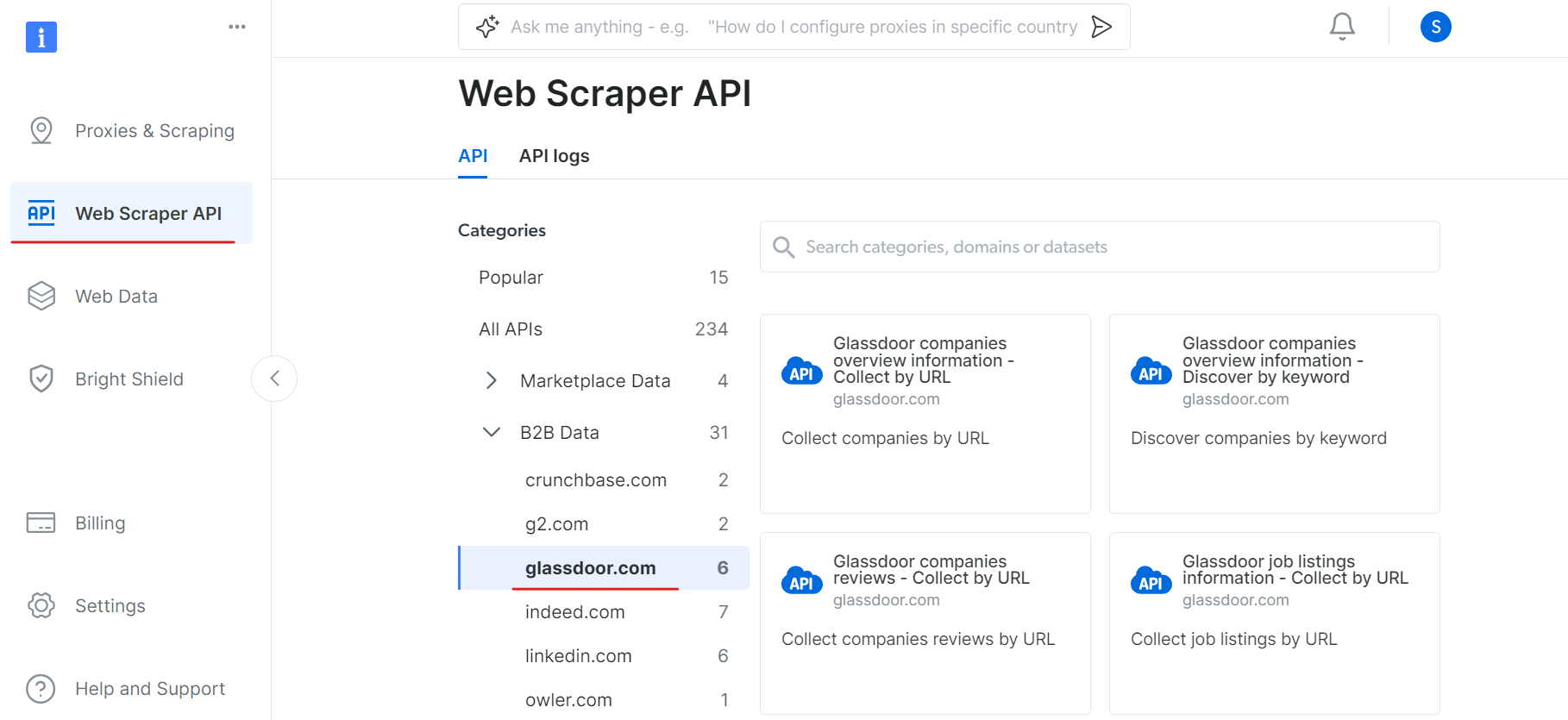
Unter „Glassdoor-Unternehmensübersicht“ erhalten Sie Ihren API-Token und kopieren Ihre Datensatz-ID (z. B. gd_l7j0bx501ockwldaqf).
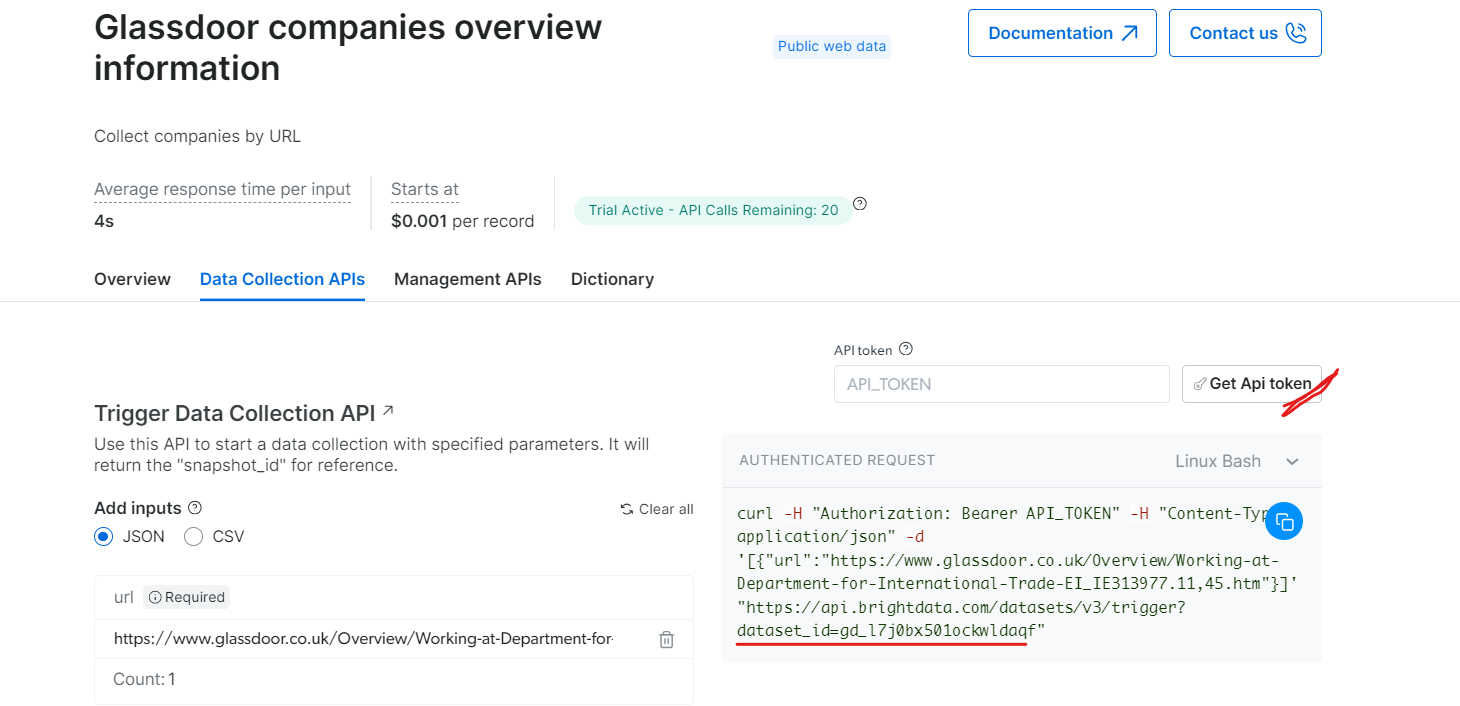
Hier ist ein einfacher Code-Ausschnitt, der zeigt, wie Sie Unternehmensdaten extrahieren können, indem Sie die URL, den API-Token und die Datensatz-ID angeben.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Löst einen Datensatz mithilfe der BrightData-API aus.
Argumente:
api_token (str): Der API-Token für die Authentifizierung.
dataset_id (str): Die Datensatz-ID, die ausgelöst werden soll.
company_url (str): Die URL der zu analysierenden Unternehmensseite.
Rückgabewerte:
dict: Die JSON-Antwort der API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/Datensätze/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "https://www.glassdoor.com/"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)Nach Ausführung des Codes erhalten Sie eine Snapshot-ID wie unten gezeigt:

Verwenden Sie die Snapshot-ID, um die tatsächlichen Daten des Unternehmens abzurufen. Führen Sie den folgenden Befehl in Ihrem Terminal aus. Für Windows verwenden Sie:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/Datensätze/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Für Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/Datensätze/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Nach Ausführung des Befehls erhalten Sie die gewünschten Daten.
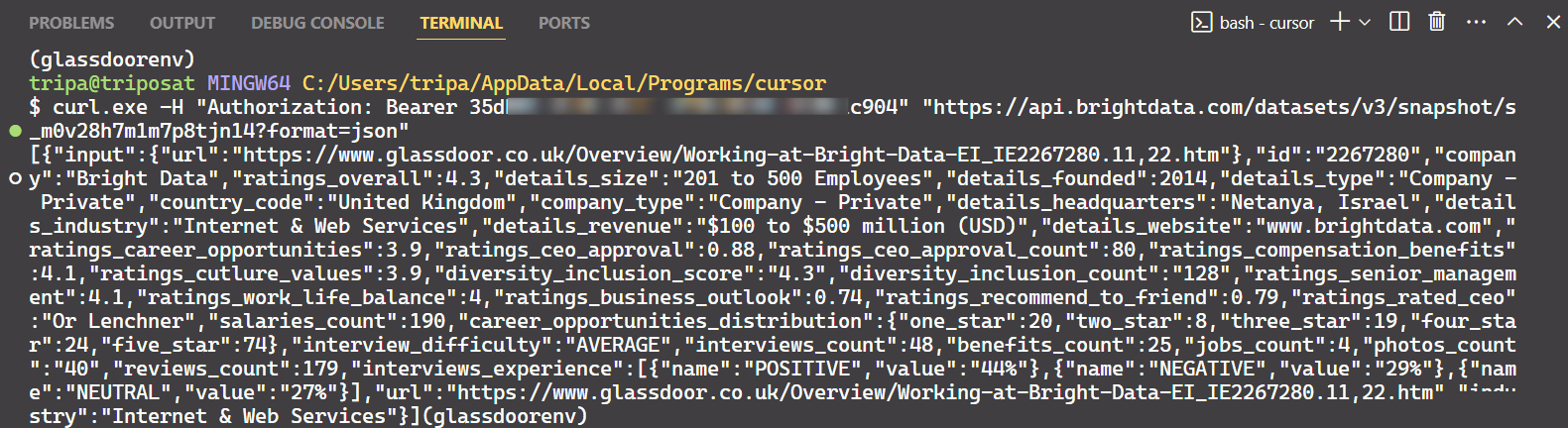
Das ist alles!
Auf ähnliche Weise können Sie verschiedene Arten von Daten aus Glassdoor extrahieren, indem Sie den Code ändern. Ich habe eine Methode erklärt, aber es gibt noch fünf weitere Möglichkeiten, dies zu tun. Ich empfehle Ihnen daher, diese Optionen zu erkunden, um die gewünschten Daten zu scrapen. Jede Methode ist auf bestimmte Datenanforderungen zugeschnitten und hilft Ihnen, genau die Daten zu erhalten, die Sie benötigen.
Fazit
In diesem Artikel wurden verschiedene Paginierungsmethoden behandelt, die häufig auf modernen Websites verwendet werden, z. B. nummerierte Paginierung, „Load More”-Buttons und Infinite Scroll. Außerdem wurden Code-Beispiele für die effektive Implementierung dieser Paginierungstechniken bereitgestellt. Während die Paginierung ein Teil des Web-Scrapings war, stellte die Umgehung der Anti-Bot-Erkennung eine erhebliche Herausforderung dar.
Die Umgehung fortschrittlicher Anti-Bot-Erkennungen kann recht komplex sein und führt oft zu unterschiedlichen Erfolgen. Die Tools von Bright Data bieten eine optimierte, kostengünstige Lösung, darunter Web Unlocker, Scraping-Browser und Web Scraper APIs für alle Ihre Web-Scraping-Anforderungen. Mit nur wenigen Zeilen Code können Sie eine höhere Erfolgsquote erzielen, ohne sich um komplizierte Anti-Bot-Maßnahmen kümmern zu müssen.
Sie möchten sich überhaupt nicht mit dem Scraping-Prozess befassen? Schauen Sie sich unseren Marktplatz für Datensätze an!
Melden Sie sich noch heute für eine kostenlose Testversion an.





