

In diesem Leitfaden erfahren Sie:
- Wie Sie erkennen, ob eine Website eine komplexe Navigation hat
- Das beste Scraping-Tool für solche Szenarien
- Wie Sie gängige komplexe Navigationsmuster scrapen
Lassen Sie uns loslegen!
Wann hat eine Website eine komplexe Navigation?
Eine Website mit komplexer Navigation ist eine häufigeHerausforderung beim Web-Scraping, der wir uns als Entwickler stellen müssen. Aber was genau bedeutet „komplexe Navigation“? Beim Web-Scraping bezieht sich komplexe Navigation auf Website-Strukturen, bei denen Inhalte oder Seiten nicht leicht zugänglich sind.
Komplexe Navigationsszenarien beinhalten oft dynamische Elemente, asynchrones Laden von Daten oder benutzergesteuerte Interaktionen. Diese Aspekte können zwar die Benutzererfahrung verbessern, erschweren jedoch die Datenextraktion erheblich.
Am besten lässt sich komplexe Navigation anhand einiger Beispiele verstehen:
- JavaScript-gerenderte Navigation: Websites, die JavaScript-Frameworks (wie React, Vue.js oder Angular) verwenden, um Inhalte direkt im Browser zu generieren.
- Paginierte Inhalte: Websites, deren Daten auf mehrere Seiten verteilt sind. Dies wird noch komplexer, wenn die Paginierung numerisch über AJAX geladen wird, wodurch der Zugriff auf nachfolgende Seiten erschwert wird.
- Unendliches Scrollen: Seiten, die beim Herunterscrollen dynamisch zusätzliche Inhalte laden, wie sie häufig in Social-Media-Feeds und auf Nachrichten-Websites zu finden sind.
- Mehrstufige Menüs: Websites mit verschachtelten Menüs, die mehrere Klicks oder Hover-Aktionen erfordern, um tiefere Navigationsebenen anzuzeigen (z. B. Produktkategoriebäume auf großen E-Commerce-Plattformen).
- Interaktive Kartenoberflächen: Websites, die Informationen auf Karten oder Grafiken anzeigen, wobei Datenpunkte dynamisch geladen werden, wenn Benutzer schwenken oder zoomen.
- Registerkarten oder Akkordeons: Seiten, auf denen Inhalte unter dynamisch gerenderten Registerkarten oder zusammenklappbaren Akkordeons verborgen sind, deren Inhalt nicht direkt in die vom Server zurückgegebene HTML-Seite eingebettet ist.
- Dynamische Filter und Sortieroptionen: Websites mit komplexen Filtersystemen, bei denen die Anwendung mehrerer Filter die Artikelliste dynamisch neu lädt, ohne die URL-Struktur zu ändern.
Die besten Scraping-Tools für die Bearbeitung komplexer Navigationswebsites
Um eine Website mit komplexer Navigation effektiv zu scrapen, müssen Sie wissen, welche Tools Sie verwenden müssen. Die Aufgabe selbst ist von Natur aus schwierig, und wenn Sie nicht die richtigen Scraping-Bibliotheken verwenden, wird sie nur noch schwieriger.
Viele der oben aufgeführten komplexen Interaktionen haben Folgendes gemeinsam:
- eine Form der Benutzerinteraktion erfordern oder
- auf der Client-Seite innerhalb des Browsers ausgeführt werden.
Mit anderen Worten: Diese Aufgaben erfordern die Ausführung von JavaScript, was nur ein Browser leisten kann. Das bedeutet, dass Sie sich für solche Seiten nicht auf einfacheHTML-Parserverlassen können. Stattdessen müssen Sie ein Browser-Automatisierungstool wie Selenium, Playwright oder Puppeteer verwenden.
Mit diesen Lösungen können Sie einen Browser programmgesteuert anweisen, bestimmte Aktionen auf einer Webseite auszuführen und so das Benutzerverhalten nachzuahmen. Diese werden oft alsHeadless-Browserbezeichnet, da sie den Browser ohne grafische Oberfläche rendern können und so Systemressourcen sparen.
Entdecken Sie diebesten Headless-Browser-Tools für das Web-Scraping.
So scrapen Sie gängige komplexe Navigationsmuster
In diesem Tutorial-Abschnitt verwenden wir Selenium in Python. Sie können die Logik jedoch leicht an Playwright, Puppeteer oder jedes andere Browser-Automatisierungstool anpassen. Wir gehen auch davon aus, dass Sie bereits mit den Grundlagen desWeb-Scrapings mit Selenium vertraut sind.
Insbesondere behandeln wir, wie man die folgenden gängigen komplexen Navigationsmuster scrapt:
- Dynamische Paginierung: Websites mit paginierten Daten, die dynamisch über AJAX geladen werden.
- Schaltfläche „Mehr laden”: Ein gängiges Beispiel für JavaScript-basierte Navigation.
- Unendliches Scrollen: Eine Seite, die kontinuierlich Daten lädt, während der Benutzer nach unten scrollt.
Zeit zum Programmieren!
Dynamische Paginierung
Die Zielseite für dieses Beispiel ist die Scraping-Sandbox„Oscar-prämierte Filme: AJAX und Javascript“:
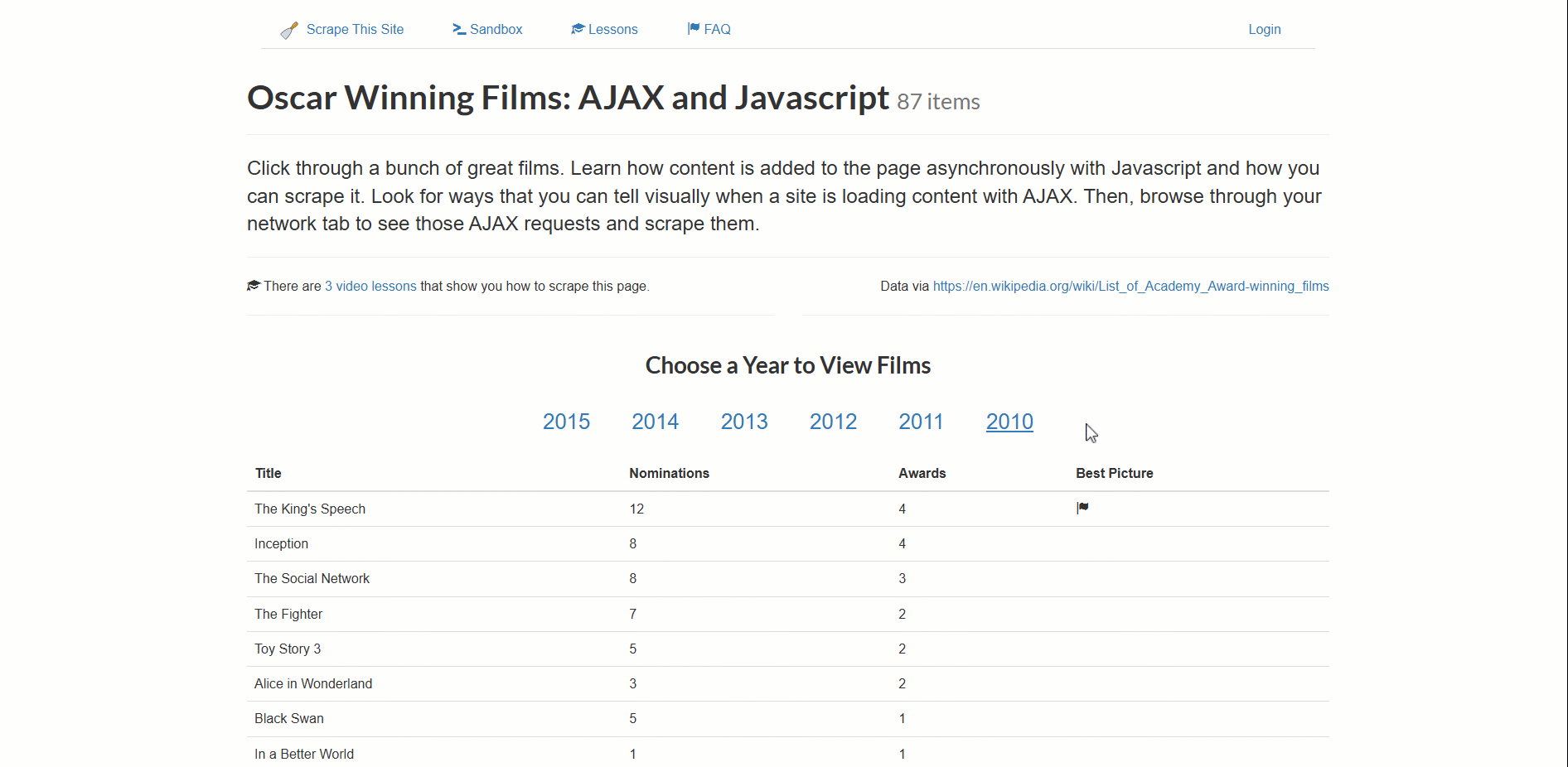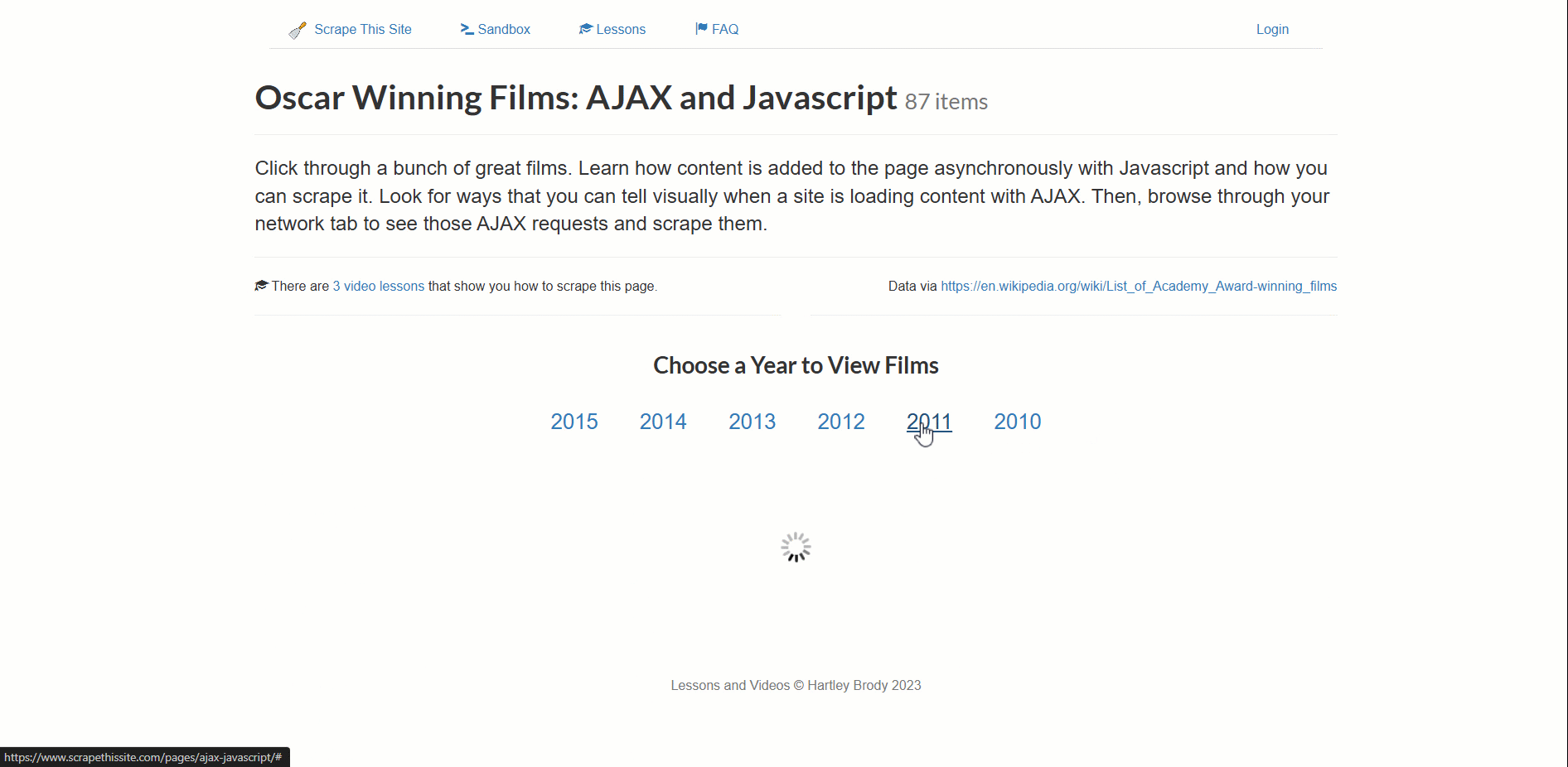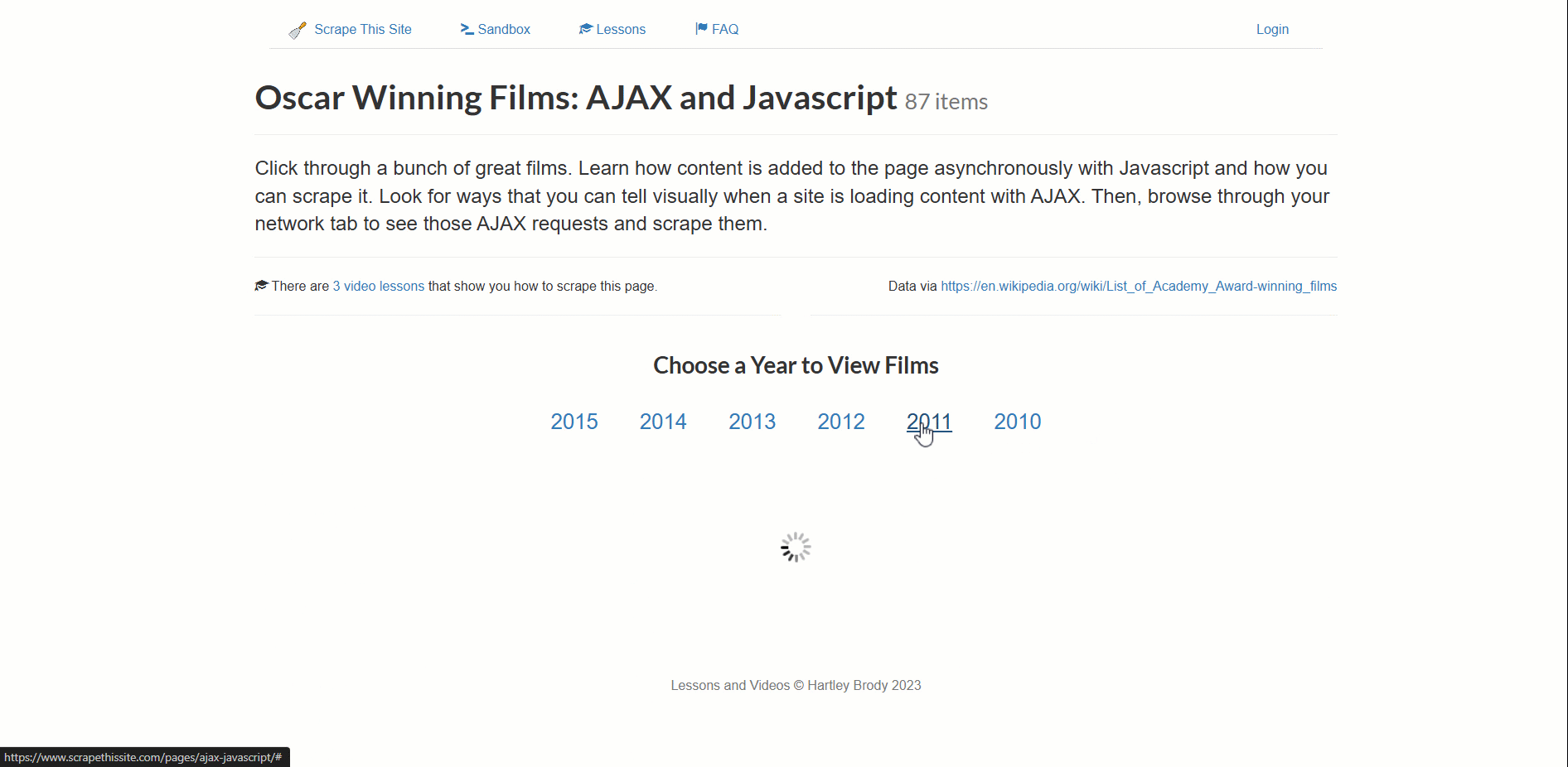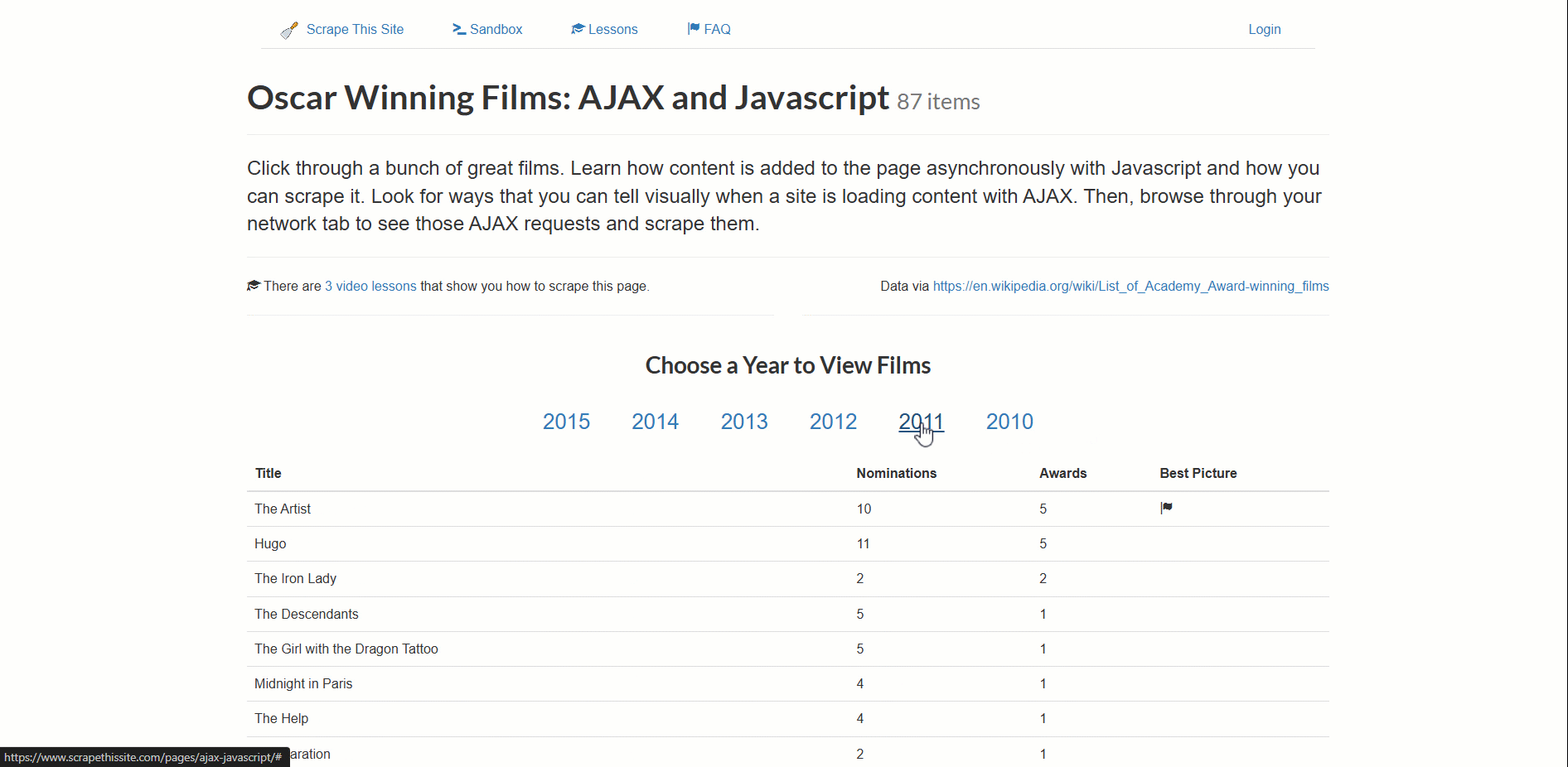
Diese Website lädt dynamisch Daten zu Oscar-prämierten Filmen, paginiert nach Jahr.
Um eine derart komplexe Navigation zu bewältigen, wird folgender Ansatz verfolgt:
- Klicken Sie auf ein neues Jahr, um das Laden der Daten auszulösen (ein Ladeelement wird angezeigt).
- Warten Sie, bis das Ladeelement verschwindet (die Daten sind nun vollständig geladen).
- Stellen Sie sicher, dass die Tabelle mit den Daten ordnungsgemäß auf der Seite gerendert wurde.
- Scrapen Sie die Daten, sobald sie verfügbar sind.
Im Detail sehen Sie unten, wie Sie diese Logik mit Selenium in Python implementieren können:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
# Chrome-Optionen für den Headless-Modus einrichten
options = Options()
options.add_argument("--headless")
# Eine Chrome-Webtreiberinstanz erstellen
driver = webdriver.Chrome(service=Service(), options=options)
# Mit der Zielseite verbinden
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# Auf die Paginierungsschaltfläche „2012” klicken
element = driver.find_element(By.ID, "2012")
element.click()
# Warten, bis der Loader nicht mehr sichtbar ist
WebDriverWait(driver, 10).until(
lambda d: d.find_element(By.CSS_SELECTOR, "#loading").get_attribute("style") == "display: none;")
# Die Daten sollten nun geladen sein...
# Warten, bis die Tabelle auf der Seite angezeigt wird
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table")))
# Wo sollen die gescrapten Daten gespeichert werden?
films = []
# Daten aus der Tabelle scrapen
table_body = driver.find_element(By.CSS_SELECTOR, "#table-body")
rows = table_body.find_elements(By.CSS_SELECTOR, ".film")
for row in rows:
title = row.find_element(By.CSS_SELECTOR, ".film-title").text
nominations = row.find_element(By.CSS_SELECTOR, ".film-nominations").text
awards = row.find_element(By.CSS_SELECTOR, ".film-awards").text
best_picture_icon = row.find_element(By.CSS_SELECTOR, ".film-best-picture").find_elements(By.TAG_NAME, "i")
best_picture = True if best_picture_icon else False
# Gescrapte Daten speichern
films.append({
"title": title,
"nominations": nominations,
"awards": awards,
"best_picture": best_picture
})
# Logik für den Datenexport...
# Browser-Treiber schließen
driver.quit()
Dies ist die Aufschlüsselung des obigen Codes:
- Der Code richtet eine Headless-Chrome-Instanz ein.
- Das Skript öffnet die Zielseite und klickt auf die Schaltfläche „2012“, um das Laden der Daten auszulösen.
- Selenium wartet mit
WebDriverWait()darauf, dass der Loader verschwindet. - Nachdem der Loader verschwunden ist, wartet das Skript darauf, dass die Tabelle angezeigt wird.
- Nachdem die Daten vollständig geladen sind, extrahiert das Skript Filmtitel, Nominierungen, Auszeichnungen und ob der Film den Oscar für den besten Film gewonnen hat. Es speichert diese Daten in einer Liste von Wörterbüchern.
Das Ergebnis lautet:
[
{
"title": "Argo",
"nominations": "7",
"awards": "3",
"best_picture": true
},
// ...
{
"title": "Curfew",
"nominations": "1",
"awards": "1",
"best_picture": false
}
]
Beachten Sie, dass es nicht immer eine einzige optimale Möglichkeit gibt, dieses Navigationsmuster zu handhaben. Je nach Verhalten der Seite können andere Optionen erforderlich sein. Beispiele hierfür sind:
- Verwenden Sie
WebDriverWait()in Kombination mit erwarteten Bedingungen, um auf das Erscheinen oder Verschwinden bestimmter HTML-Elemente zu warten. - Überwachen Sie den Traffic auf AJAX-Anfragen, um zu erkennen, wann neue Inhalte abgerufen werden. Dazu kann die Verwendung von Browser-Protokollierung erforderlich sein.
- Identifizieren Sie die durch die Paginierung ausgelöste API-Anfrage und stellen Sie direkte Anfragen, um die Daten programmgesteuert abzurufen (z. B. mithilfe der
Requests-Bibliothek).
Schaltfläche „Mehr laden”
Um komplexe JavaScript-basierte Navigationsszenarien mit Benutzerinteraktion darzustellen, haben wir das Beispiel „Load More”-Button gewählt. Das Konzept ist einfach: Eine Liste von Elementen wird angezeigt, und zusätzliche Elemente werden geladen, wenn der Button angeklickt wird.
Diesmal ist die Zielseite dieBeispielseite „Load More“aus dem Scraping-Kurs:
Um dieses komplexe Navigations-Scraping-Muster zu verarbeiten, führen Sie die folgenden Schritte aus:
- Suchen Sie die Schaltfläche „Load More“ und klicken Sie darauf.
- Warten Sie, bis die neuen Elemente auf der Seite geladen sind.
So können Sie dies mit Selenium implementieren:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Chrome-Optionen für den Headless-Modus einrichten
options = Options()
options.add_argument("--headless")
# Chrome-Webtreiberinstanz erstellen
driver = webdriver.Chrome(options=options)
# Mit der Zielseite verbinden
driver.get("https://www.scrapingcourse.com/button-click")
# Anfangszahl der Produkte erfassen
initial_product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Schaltfläche „Load More” suchen und anklicken
load_more_button = driver.find_element(By.CSS_SELECTOR, "#load-more-btn")
load_more_button.click()
# Warten, bis die Anzahl der Produktartikel auf der Seite gestiegen ist
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > initial_product_count)
# Speicherort für die gescrapten Daten
products = []
# Produktdetails scrapen
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Produktdetails extrahieren
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Gescrapte Daten speichern
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Logik zum Exportieren der Daten...
# Schließen des Browser-Treibers
driver.quit()
Um diese Navigationslogik zu verarbeiten, führt das Skript Folgendes aus:
- Die anfängliche Anzahl der Produkte auf der Seite aufzeichnen
- Klickt auf die Schaltfläche „Mehr laden“
- Wartet, bis die Produktanzahl steigt, und bestätigt damit, dass neue Artikel hinzugefügt wurden
Dieser Ansatz ist sowohl intelligent als auch generisch, da er keine genaue Kenntnis der Anzahl der zu ladenden Elemente erfordert. Beachten Sie jedoch, dass auch andere Methoden möglich sind, um ähnliche Ergebnisse zu erzielen.
Unendliches Scrollen
Unendliches Scrollen ist eine gängige Interaktion, die von vielen Websites verwendet wird, um die Benutzerinteraktion zu verbessern, insbesondere in sozialen Medien und auf E-Commerce-Plattformen. In diesem Fall ist das Ziel dieselbe Seite wie oben, jedoch mitunendlichem Scrollen anstelle einer Schaltfläche „Mehr laden“:
Die meisten Browser-Automatisierungstools (einschließlich Selenium) bieten keine direkte Methode zum Scrollen einer Seite nach unten oder oben. Stattdessen müssen Sie ein JavaScript-Skript auf der Seite ausführen, um den Scrollvorgang durchzuführen.
Die Idee besteht darin, ein benutzerdefiniertes JavaScript-Skript zu schreiben, das nach unten scrollt:
- eine bestimmte Anzahl von Malen oder
- bis keine weiteren Daten mehr zum Laden verfügbar sind.
Hinweis: Bei jedem Scrollen werden neue Daten geladen, wodurch sich die Anzahl der Elemente auf der Seite erhöht.
Anschließend können Sie den neu geladenen Inhalt scrapen.
So können Sie mit unendlichem Scrollen in Selenium umgehen:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Chrome-Optionen für den Headless-Modus einrichten
options = Options()
# options.add_argument("--headless")
# Chrome-Webtreiberinstanz erstellen
driver = webdriver.Chrome(options=options)
# Mit der Zielseite mit unendlichem Scrollen verbinden
driver.get("https://www.scrapingcourse.com/infinite-scrolling")
# Aktuelle Seitenhöhe
scroll_height = driver.execute_script("return document.body.scrollHeight")
# Anzahl der Produkte auf der Seite
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Maximale Anzahl von Scrolls
max_scrolls = 10
scroll_count = 1
# Begrenzung der Anzahl der Bildläufe auf 10
while scroll_count < max_scrolls:
# Nach unten scrollen
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Warten, bis die Anzahl der Produktartikel auf der Seite gestiegen ist
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > product_count)
# Aktualisieren der Produktanzahl
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Neue Seitenhöhe abrufen
new_scroll_height = driver.execute_script("return document.body.scrollHeight")
# Wenn kein neuer Inhalt geladen wurde
if new_scroll_height == scroll_height:
break
# Scrollhöhe aktualisieren und Scrollanzahl erhöhen
scroll_height = new_scroll_height
scroll_count += 1
# Produktdetails nach unendlichem Scrollen scrapen
products = []
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Produktdetails extrahieren
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Gescrapte Daten speichern
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# In CSV/JSON exportieren...
# Browsertreiber schließen
driver.quit()
Dieses Skript verwaltet das unendliche Scrollen, indem es zunächst die aktuelle Seitenhöhe und die Anzahl der Produkte ermittelt. Anschließend begrenzt es die Scroll-Aktionen auf maximal 10 Iterationen. In jeder Iteration wird Folgendes ausgeführt:
- Scrollt bis zum Ende der Seite
- Es wartet, bis die Anzahl der Produkte erhöht wird (was darauf hinweist, dass neue Inhalte geladen wurden).
- Es vergleicht die Seitenhöhe, um festzustellen, ob weitere Inhalte verfügbar sind
Wenn die Seitenhöhe nach dem Scrollen unverändert bleibt, wird die Schleife unterbrochen, was bedeutet, dass keine weiteren Daten mehr geladen werden können. Auf diese Weise können Sie komplexe unendliche Scrollmuster bewältigen.
Großartig! Sie sind jetzt ein Meister im Scraping von Websites mit komplexer Navigation.
Fazit
In diesem Artikel haben Sie etwas über Websites gelernt, die auf komplexen Navigationsmustern basieren, und wie Sie Selenium mit Python einsetzen können, um damit umzugehen. Dies zeigt, dass Web-Scraping eine Herausforderung sein kann, die durchAnti-Scraping-Maßnahmen noch erschwert wird.
Unternehmen sind sich des Werts ihrer Daten bewusst und schützen sie um jeden Preis. Aus diesem Grund implementieren viele Websites Maßnahmen, um automatisierte Skripte zu blockieren. Diese Lösungen können Ihre IP-Adresse nach zu vielen Anfragen blockieren, CAPTCHAs anzeigen und noch schlimmere Maßnahmen ergreifen.
Herkömmliche Browser-Automatisierungstools wie Selenium können diese Einschränkungen nicht umgehen…
Die Lösung besteht darin, einen cloudbasierten, speziell für das Scraping entwickelte Scraping-Browser wieScraping-Browser zu verwenden. Dieser Browser lässt sich in Playwright, Puppeteer, Selenium und andere Tools integrieren und wechselt bei jeder Anfrage automatisch die IP-Adresse. Er kann Browser-Fingerprinting, Wiederholungsversuche,CAPTCHA-Lösungen und vieles mehr verarbeiten. Vergessen Sie Blockierungen beim Umgang mit komplexen Websites!




