

Von autonomen Forschungsassistenten bis hin zu Agenten, die ganze Arbeitsabläufe verwalten – KI-Agenten sind schnell mehr als nur ein Trend geworden; sie prägen die Zukunft der Arbeit, der Entwicklung und der Entscheidungsfindung. Hinter jedem fähigen Agenten steht jedoch ein sorgfältig aufgebauter Tech-Stack, ein mehrschichtiges System von Tools, das es diesen Agenten ermöglicht, zu denken, zu handeln und sich anzupassen.
Was treibt die nächste Generation der Automatisierung an?
Für Entwickler ist es unerlässlich, diesen Stack zu verstehen. Es geht nicht nur darum, welche Tools gerade im Trend liegen, sondern auch darum, wie sie zusammenarbeiten, wo der wahre Wert liegt und welche grundlegenden Elemente vorhanden sein müssen, damit Agenten zuverlässig arbeiten können.
Bei Bright Data arbeiten wir mit KI-Teams aus verschiedenen Branchen zusammen, und eines ist klar: Jeder Agent beginnt mit Daten. In diesem Artikel gehen wir die Kernschichten des Tech-Stacks für KI-Agenten durch, beginnend mit der wichtigsten: Datenerfassung und -integration.
Datenerfassung und -integration
Der erste Schritt zum Aufbau intelligenterer Agenten
Bevor ein KI-Agent denken, planen oder handeln kann, muss er die Welt verstehen, in der er agiert. Dieses Verständnis beginnt mit Daten aus der realen Welt, in Echtzeit und oft unstrukturiert. Ob es darum geht, ein Modell zu trainieren, ein RAG-System (Retrieval-Augmented Generation) zu betreiben oder einen Agenten in die Lage zu versetzen, auf Live-Marktveränderungen zu reagieren – Daten sind der Treibstoff.
Hier kommt Bright Data ins Spiel.
Wir bieten die Infrastruktur, mit der KI-Teams das öffentliche Web in großem Umfang, präzise und unter Einhaltung der Vorschriften nutzen können. Unsere Tools sind so konzipiert, dass sie die Datenerfassung nicht nur möglich, sondern auch nahtlos machen.
Die Rolle von Bright Data im Stack
- Search API – Zeigt relevante Webinhalte in Echtzeit an, ideal für RAG- und LLM-gestützte Suche.
- Unlocker-API – Umgeht Anti-Bot-Schutzmaßnahmen, um einen zuverlässigen Zugriff auf öffentliche Datenquellen zu gewährleisten.
- Web Scraper API – Extrahiert strukturierte Daten aus über 120.000 Websites, die sofort verwendet werden können.
- Custom Scraper – Maßgeschneiderte Lösungen für Nischenbranchen und spezifische Anforderungen von Agenten.
- Datensatz-Marktplatz – Vorab gesammelte Datensätze für schnelles Prototyping oder Modell-Feinabstimmung.
- KI Annotations – Human-in-the-Loop-Dienste zum Beschriften und Verfeinern von Trainingsdaten.
„Wenn KI-Agenten das Gehirn sind, dann ist Bright Data die Augen.“
Anwendungsfall: E-Commerce-Intelligence-Agent
Ein Einzelhandelsunternehmen entwickelt einen KI-Agenten, um die Preise und Produktverfügbarkeit der Wettbewerber zu überwachen. Mithilfe der Web Scraper API und der Unlocker API von Bright Data sammelt der Agent Echtzeitdaten von den Websites der Wettbewerber und speist sie in eine Preisberechnungsmaschine ein, die die Angebote dynamisch anpasst.
KI-Agent Full Techstack
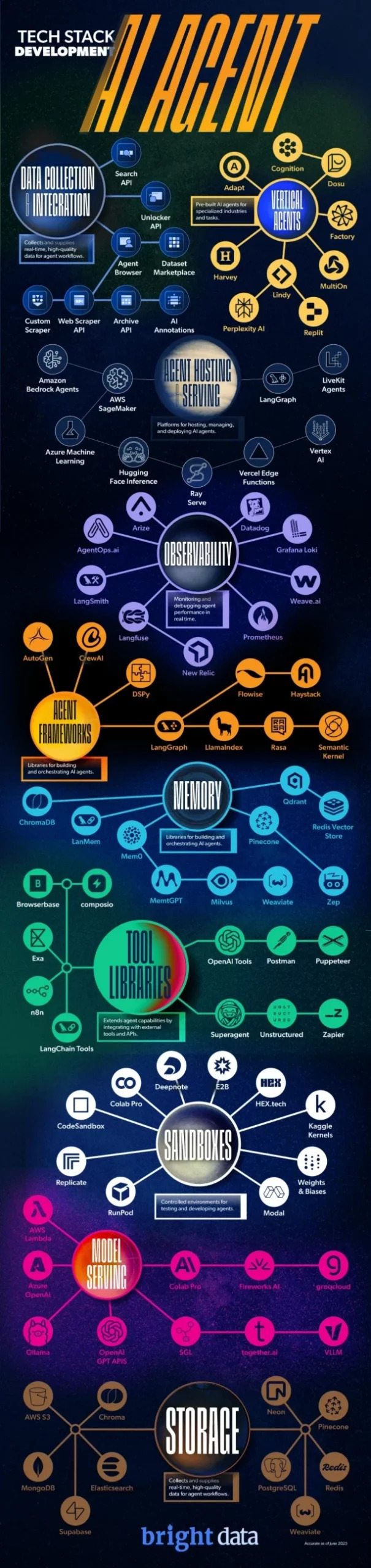
Agent-Hosting-Services
Wo KI-Agenten zum Leben erweckt werden
Sobald ein Agent Zugriff auf Daten hat, benötigt er einen Ort, an dem er in einer digitalen Umgebung arbeiten kann, in der er Schlussfolgerungen ziehen, Entscheidungen treffen und Maßnahmen ergreifen kann. Das ist die Aufgabe von Agent-Hosting-Diensten: Sie stellen die Infrastruktur bereit, die statische Modelle in dynamische, autonome Systeme verwandelt.
Diese Plattformen verwalten alles von der Orchestrierung bis zur Ausführung und stellen sicher, dass Agenten skalierbar sind, mit APIs interagieren und kontinuierlich arbeiten können.
Was Entwickler verwenden
- LangGraph – Eine graphbasierte Laufzeitumgebung zum Erstellen von zustandsbehafteten, mehrstufigen Agent-Workflows.
- Hugging Face Inference Endpoints – Hostet und bedient Modelle und Agenten mit Tools wie Transformers Agents für Echtzeit-Interaktionen.
- AWS (Bedrock, Lambda, SageMaker) – Bietet eine flexible, skalierbare Infrastruktur für die Bereitstellung und Verwaltung von Agenten in großem Maßstab.
Hosting-Plattformen sind die Betriebssysteme der Agentenwelt, aber selbst der am besten gehostete Agent ist nur so gut wie die Daten, auf denen er basiert.
Beobachtbarkeit
KI-Agenten transparent, nachvollziehbar und vertrauenswürdig machen
Da Agenten immer autonomer werden, ist es unerlässlich zu verstehen, was sie tun und warum. Beobachtbarkeitstools helfen Entwicklern, die Leistung zu überwachen, Entscheidungen nachzuverfolgen und Probleme in Echtzeit zu beheben.
Was Entwickler verwenden
- LangSmith (LangChain) – Verfolgt, debuggt und bewertet LLM-gestützte Workflows.
- Weights & Biases – Verfolgt die Modellleistung, Experimente und das Verhalten von Agenten im Zeitverlauf.
- WhyLabs – Überwacht Datenabweichungen und Modellanomalien in Produktionsumgebungen.
Durch Beobachtbarkeit werden Agenten von Black Boxes zu Glass Boxes, wodurch Entwickler die Transparenz erhalten, die sie benötigen, um Vertrauen aufzubauen und sicher zu iterieren.
Agent-Frameworks
Die Blaupausen für die Entwicklung intelligenterer, leistungsfähigerer Agenten
Frameworks definieren, wie Agenten strukturiert sind, wie sie denken, mit Tools interagieren und mit anderen Agenten zusammenarbeiten. Mit zunehmender Komplexität der Agenten entwickeln sich Frameworks weiter, um Multi-Agenten-Systeme, Aufgabenzerlegung und dynamische Planung zu unterstützen.
Was Entwickler verwenden
- Crew KI – Ermöglicht die Zusammenarbeit von Agententeams, wobei jedes Team definierte Rollen und Verantwortlichkeiten hat.
- LangGraph – Unterstützt Verzweigungslogik und zustandsbehaftete Workflows für komplexes Agentenverhalten.
- DSPy – Ein deklaratives Framework zur Optimierung und Feinabstimmung von LLM-Pipelines.
Frameworks geben Agenten ihre Struktur und Logik, aber sie sind auf genaue Echtzeitdaten angewiesen, um effektiv zu funktionieren.
Speicher
Wie Agenten sich erinnern, lernen und kontextbewusst bleiben
Speichersysteme ermöglichen es Agenten, den Kontext zu behalten, vergangene Interaktionen abzurufen und ein langfristiges Verständnis aufzubauen. Der Speicher, der in der Regel von Vektordatenbanken gespeist wird, ist für Personalisierung, Kontinuität und komplexes Denken unerlässlich.
Was Entwickler verwenden
- ChromaDB – Leichtgewichtig und ideal für die lokale Entwicklung.
- Qdrant – Skalierbare, produktionsreife Vektorsuche mit hybrider Filterung.
- Weaviate – Modular und ML-freundlich, wird häufig in Unternehmensumgebungen eingesetzt.
Der Speicher ermöglicht es Agenten zu lernen und sich anzupassen, aber er ist nur so nützlich wie die Daten, die er speichert, was die Notwendigkeit hochwertiger Eingaben von Anfang an unterstreicht.
Tool-Bibliotheken
Wie Agenten in der realen Welt agieren
Tool-Bibliotheken geben Agenten die Möglichkeit, mit externen System-APIs, Datenbanken, Suchmaschinen und mehr zu interagieren. Dadurch werden Sprachmodelle zu handlungsfähigen Agenten.
Was Entwickler verwenden
- LangChain – Ein robustes Ökosystem für die Verkettung von LLMs mit Tools, Speicher und Workflows.
- OpenAI Functions – Ermöglicht es Agenten, externe Tools direkt aus GPT-Modellen heraus aufzurufen.
- Exa – Ermöglicht die Echtzeit-Websuche, die häufig in Forschungsagenten und RAG-Systemen verwendet wird.
Tool-Bibliotheken machen Agenten nützlich, aber ihre Effektivität hängt von der Qualität der Daten ab, mit denen sie interagieren.
Sandboxes
Wo Agenten sicher Code ausführen und Ideen testen können
Agenten müssen zunehmend Code schreiben und ausführen, sei es für Datenanalysen, Simulationen oder dynamische Entscheidungsfindungen. Sandboxes bieten sichere, isolierte Umgebungen, um genau das zu tun.
Was Entwickler verwenden
- OpenAI Code Interpreter – Führt Python sicher innerhalb von GPT-4 für datenintensive Aufgaben aus.
- Replit – Eine cloudbasierte Programmierumgebung mit KI-Integration.
- Modal – Serverlose Infrastruktur, die gleichzeitig als sichere Codeausführungsschicht dient.
Sandboxes ermöglichen es Agenten, Probleme zu durchdenken und umsetzbare Ergebnisse zu generieren, aber auch hier hängt die Qualität dieser Ergebnisse von der Qualität der Eingaben ab.
Modellbereitstellung
Das zweite Gehirn: Wo Entscheidungen getroffen werden
Wenn Daten das erste Gehirn des KI-Agenten sind, dann ist das Modell-Serving die zweite Art, wie Agenten denken.
Hier werden LLMs gehostet und abgerufen, die das Denken und die Sprachgenerierung bereitstellen, die jede Entscheidung des Agenten antreiben. Die Leistung, Latenz und Genauigkeit dieser Ebene wirken sich direkt auf die Effektivität des Agenten aus.
Was Entwickler verwenden
- OpenAI (GPT-4, GPT-4o) – Industriestandard für allgemeine Schlussfolgerungen und multimodale Fähigkeiten.
- Anthropic (Claude) – Bekannt für lange Kontextfenster und ein auf Ausrichtung fokussiertes Design.
- Mistral – Open-Weight-Modelle, die hohe Leistung zu geringeren Kosten bieten.
- Groq – Ultra-niedrige Latenzzeit für Echtzeit-Agentenantworten.
- AWS ( SageMaker, Bedrock) – Skalierbare Infrastruktur für proprietäre und offene Modelle.
Beim Modell-Serving werden Erkenntnisse in Maßnahmen umgesetzt, aber selbst die besten Modelle benötigen hochwertige Echtzeitdaten, um effektiv zu argumentieren.
Speicher
Wo Agenten ihre Historie, ihr Wissen und ihren Status speichern
Speichersysteme unterstützen die langfristige Persistenz von Interaktionen, speichern Ausgaben und halten den Status über mehrere Sitzungen hinweg aufrecht. Sie sind für Reproduzierbarkeit, Compliance und kontinuierliche Verbesserung unerlässlich.
Was Entwickler verwenden
- Amazon S3 – Die erste Wahl für skalierbaren Objektspeicher.
- Google Cloud Storage (GCS) – Sicher und in die KI-Tools von Google integriert.
- Vektor-Datenbanken (z. B. Qdrant, Weaviate) – Speichern Einbettungen und semantischen Kontext für die Abfrage.
Speicher sorgen dafür, dass Agenten aus der Vergangenheit lernen und im Laufe der Zeit skalieren können, aber der Wert der gespeicherten Daten hängt von der Qualität der gesammelten Daten ab.
Ihre Agenten sind nur so intelligent wie ihre Daten
KI-Agenten sind nur so leistungsfähig wie die Informationen, auf denen sie basieren. Sie können denken, planen und handeln, aber nur, wenn sie zum richtigen Zeitpunkt Zugriff auf die richtigen Daten haben. Ohne diese Daten wird selbst der ausgefeilteste Tech-Stack zu einem geschlossenen Kreislauf: leistungsstark, aber losgelöst von der realen Welt.
Deshalb sind Daten nicht nur ein Teil des Stacks, sondern dessen Grundlage. Und im heutigen KI-Ökosystem ist die wertvollste Datenquelle das öffentliche Internet.
Bei Bright Data machen wir diese Daten zugänglich.
Unsere Tools unterstützen den ersten und wichtigsten Schritt im Arbeitsablauf von KI-Agenten: die Datenerfassung und -integration. Wir verbinden Agenten in Echtzeit mit dem öffentlichen Internet und liefern ihnen die strukturierten, zuverlässigen und skalierbaren Daten, die sie benötigen, um die Welt zu verstehen, fundierte Entscheidungen zu treffen und sinnvolle Maßnahmen zu ergreifen.
Jede Ebene des Tech-Stacks – Agent-Frameworks, Speichersysteme, Tool-Bibliotheken, Model Serving – hängt von dieser Grundlage ab. Denn ohne genaue, aktuelle Informationen können sich Agenten nicht anpassen, personalisieren oder ihre Aufgaben erfüllen.
In gewisser Weise haben Ihre Agenten zwei Gehirne:
- Die Daten: Was sie wissen.
- Das Modell: wie sie denken.
Bevor Ihre Agenten handeln können, müssen sie verstehen.
Bevor sie verstehen können, müssen sie sehen können.
Bright Data ist ihre Sicht auf die Welt.
Nächster Schritt
Entdecken Sie, wie Bright Data Ihre KI-Agenten unterstützen kann: https://brightdata.com/ai/produkte-für-KI





