

Die Finanzmärkte erzeugen jede Sekunde riesige Datenmengen. Die NASDAQ ist eine der größten Börsen der Welt und beherbergt große Unternehmen wie Apple, Microsoft, Tesla und Amazon.
Wenn Sie Handelsalgorithmen, Forschungs-Dashboards oder Fintech-Anwendungen entwickeln, bietet die Erfassung dieser Finanzdaten sowohl große Chancen als auch technische Herausforderungen. In diesem Leitfaden werden drei bewährte Methoden zur Erfassung von Finanzdaten von der NASDAQ vorgestellt: direkter API-Zugriff über interne Endpunkte, Implementierung einer skalierbaren Unternehmens-Proxy-Infrastruktur und Verwendung von KI-gestütztem Web-Scraping mit MCP (Model Context Protocol).
Verstehen der NASDAQ-Datenlandschaft
Die NASDAQ bietet umfassende Marktdaten, die sich perfekt für Forschung, Backtesting und analytische Anwendungen eignen. Hier sehen Sie, worauf Sie normalerweise zugreifen können:
- Kursdaten – letzter Handelskurs, täglicher Höchst-/Tiefstkurs, Eröffnungs-/Schlusskurs, Handelsvolumen und prozentuale Veränderungen für börsennotierte Aktien
- Historische Daten – tägliche OHLC-Daten (Open, High, Low, Close), Dividendenhistorie, Aktiensplits und historische Handelsvolumina
- Unternehmensinformationen – Grundlegende Unternehmensangaben, Sektorklassifizierungen und Links zu SEC-Einreichungen und Unternehmensnachrichten
- Zusätzliche Funktionen – interaktive Diagramme, Ertragskalender und Daten zu institutionellen Beteiligungen
Händler und Anleger nutzen Backtesting, um die historische Leistung von Strategien zu analysieren, bevor sie sie im Live-Handel einsetzen. Unternehmen nutzen diese Marktdaten für Wettbewerbsinformationen, um die Aktivitäten ihrer Mitbewerber zu verfolgen und Markttrends und -chancen zu erkennen. Für weitergehende Szenarien können Sie unsere umfassenden Anwendungsfälle für Finanzdaten erkunden.
Nun wollen wir sehen, wie wir diese Daten abrufen können.
Methodik der Datenextraktion
Moderne Finanzseiten wie NASDAQ, Yahoo Finance und Google Finance sind als einseitige Anwendungen aufgebaut, die JavaScript zur Darstellung dynamischer Inhalte verwenden. Anstatt sprödes HTML zu parsen, ist es robuster, ihre internen JSON-API-Endpunkte direkt aufzurufen, da JSON-Antworten sauberer und stabiler sind.
Hier erfahren Sie, wie Sie die JSON-Endpunkte der NASDAQ identifizieren können:
- Öffnen Sie eine beliebige Tickerseite (z. B. https://www.nasdaq.com/market-activity/stocks/aapl) und öffnen Sie die Entwicklertools Ihres Browsers.
- Wählen Sie auf der Registerkarte Netzwerk den Filter Fetch/XHR, um den API-Datenverkehr zu isolieren.
- Laden Sie die Seite neu, um alle Anfragen zu erfassen.
Nach dem Neuladen sehen Sie Anfragen wie Marktinfo, Chart, Watchlist und einige andere.
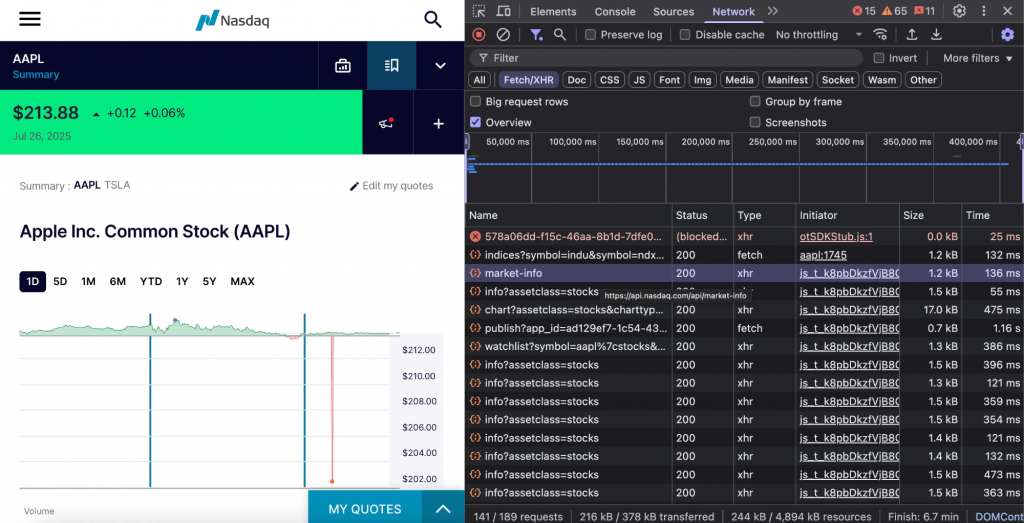
Klicken Sie auf eine beliebige Anfrage, um die JSON-Nutzdaten zu inspizieren. Die Anfrage market-info beispielsweise zeigt eine umfassende Datenstruktur mit Echtzeit-Marktinformationen an.
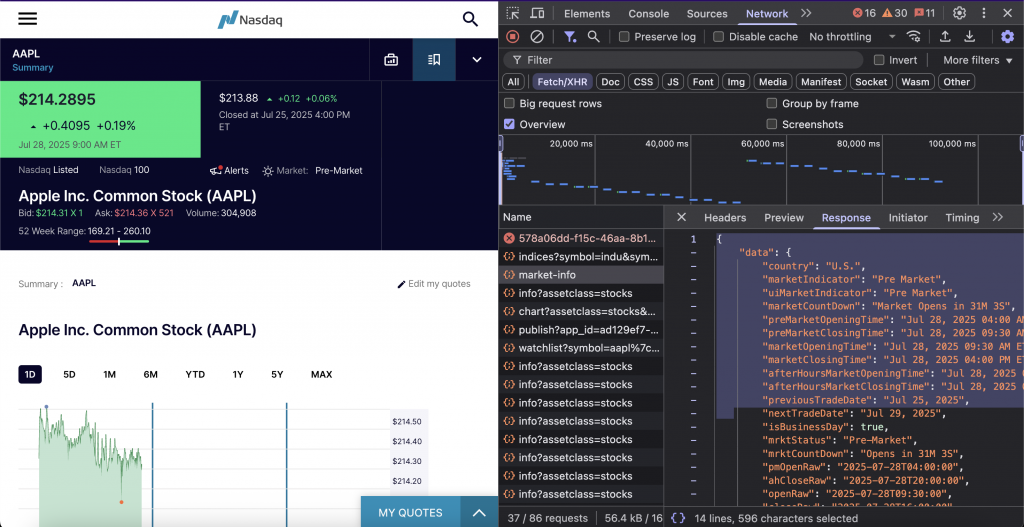
Nachdem wir diese Endpunkte identifiziert haben, können wir nun die erforderlichen Tools einrichten.
Voraussetzungen
- Python 3.x
- Ein Code-Editor (VS Code, PyCharm, usw.)
- Grundlegende Vertrautheit mit den Chrome Developer Tools
- Kenntnisse der Grundlagen des Scraping in Python und der Datenextraktionsbibliotheken
- Die
requests-Bibliothek. Installieren Sie sie mit dem Befehlpip install requests
Wenn Sie noch nicht mit der requests-Bibliothek vertraut sind, finden Sie in unserem Python requests guide alle Techniken, die wir in diesem Tutorial verwenden werden.
Mit diesen Werkzeugen können wir nun die erste Methode ausprobieren.
Methode 1 – Web Scraping mit direktem API-Zugang
Die wichtigsten Endpunkte, die wir verwenden werden, liefern umfassende Marktdaten durch saubere JSON-Antworten.
Marktstatus und Handelsplan
Dieser Endpunkt liefert den US-Marktstatus mit Countdown-Informationen und vollständigen Handelsplänen. Er deckt die regulären Stunden, die vorbörslichen und die nachbörslichen Sitzungen ab und bietet vorherige und nächste Handelsdaten in mehreren Zeitstempelformaten für eine einfache Integration.
Der Endpunkt ist https://api.nasdaq.com/api/market-info.
Hier ist eine einfache Umsetzung:
import requests
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
response = requests.get('https://api.nasdaq.com/api/market-info', headers=headers)
print(response.json())Die API liefert Daten zum Marktstatus wie folgt:
{
"data": {
"country": "U.S.",
"marketIndicator": "Market Open",
"uiMarketIndicator": "Market Open",
"marketCountDown": "Market Closes in 3H 7M",
"preMarketOpeningTime": "Jul 29, 2026 04:00 AM ET",
"preMarketClosingTime": "Jul 29, 2026 09:30 AM ET",
"marketOpeningTime": "Jul 29, 2026 09:30 AM ET",
"marketClosingTime": "Jul 29, 2026 04:00 PM ET",
"afterHoursMarketOpeningTime": "Jul 29, 2026 04:00 PM ET",
"afterHoursMarketClosingTime": "Jul 29, 2026 08:00 PM ET",
"previousTradeDate": "Jul 28, 2026",
"nextTradeDate": "Jul 30, 2026",
"isBusinessDay": true,
"mrktStatus": "Open",
"mrktCountDown": "Closes in 3H 7M",
"pmOpenRaw": "2026-07-29T04:00:00",
"ahCloseRaw": "2026-07-29T20:00:00",
"openRaw": "2026-07-29T09:30:00",
"closeRaw": "2026-07-29T16:00:00"
}
}Großartig! Dies zeigt den API-Ansatz für den Abruf von Echtzeit-Marktzeitdaten.
Börsenkursdaten
Der NASDAQ-Kursendpunkt bietet detaillierte Aktiendaten für jedes börsennotierte Unternehmen, einschließlich der neuesten Kurse, Handelsvolumen, Unternehmensinformationen und Marktstatistiken.
Der Endpunkt lautet https://api.nasdaq.com/api/quote/{symbol}/info?assetclass=stocks. Er erfordert das Tickersymbol der Aktie (AAPL, TSLA) und die Assetclass Aktien für Aktiendaten.
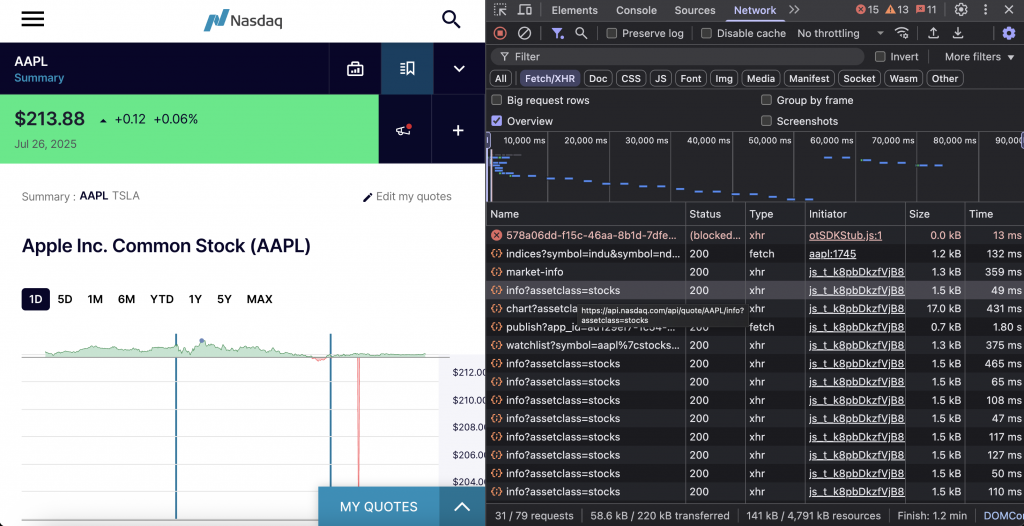
Hier ist der einfache Code-Schnipsel:
import requests
def get_stock_info(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/info?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
stock_info = get_stock_info('AAPL', headers)
print(stock_info)Die API gibt Aktienkursdaten wie folgt zurück:
{
"data": {
"symbol": "AAPL",
"companyName": "Apple Inc. Common Stock",
"stockType": "Common Stock",
"exchange": "NASDAQ-GS",
"isNasdaqListed": true,
"isNasdaq100": true,
"isHeld": false,
"primaryData": {
"lastSalePrice": "$211.9388",
"netChange": "-2.1112",
"percentageChange": "-0.99%",
"deltaIndicator": "down",
"lastTradeTimestamp": "Jul 29, 2026 12:51 PM ET",
"isRealTime": true,
"bidPrice": "$211.93",
"askPrice": "$211.94",
"bidSize": "112",
"askSize": "235",
"volume": "23,153,569",
"currency": null
},
"secondaryData": null,
"marketStatus": "Open",
"assetClass": "STOCKS",
"keyStats": {
"fiftyTwoWeekHighLow": {
"label": "52 Week Range:",
"value": "169.21 - 260.10"
},
"dayrange": {
"label": "High/Low:",
"value": "211.51 - 214.81"
}
},
"notifications": [
{
"headline": "UPCOMING EVENTS",
"eventTypes": [
{
"message": "Earnings Date : Jul 31, 2026",
"eventName": "Earnings Date",
"url": {
"label": "AAPL Earnings Date : Jul 31, 2026",
"value": "/market-activity/stocks/AAPL/earnings"
},
"id": "upcoming_events"
}
]
}
]
}
}Unternehmensgrundlagen und Schlüsselkennzahlen
Die Zusammenfassungs-API der NASDAQ liefert wichtige Finanzdaten, einschließlich Marktkapitalisierung, Handelsvolumen, Dividendeninformationen und Sektorklassifizierung für jedes Aktiensymbol.
Wenn Sie eine NASDAQ-Unternehmensseite besuchen und zum Abschnitt “Eckdaten” blättern, ruft Ihr Browser einen bestimmten Endpunkt auf. Dieser Endpunkt lautet https://api.nasdaq.com/api/quote/{SYMBOL}/summary?assetclass=stocks und enthält alle Fundamentaldaten des Unternehmens.
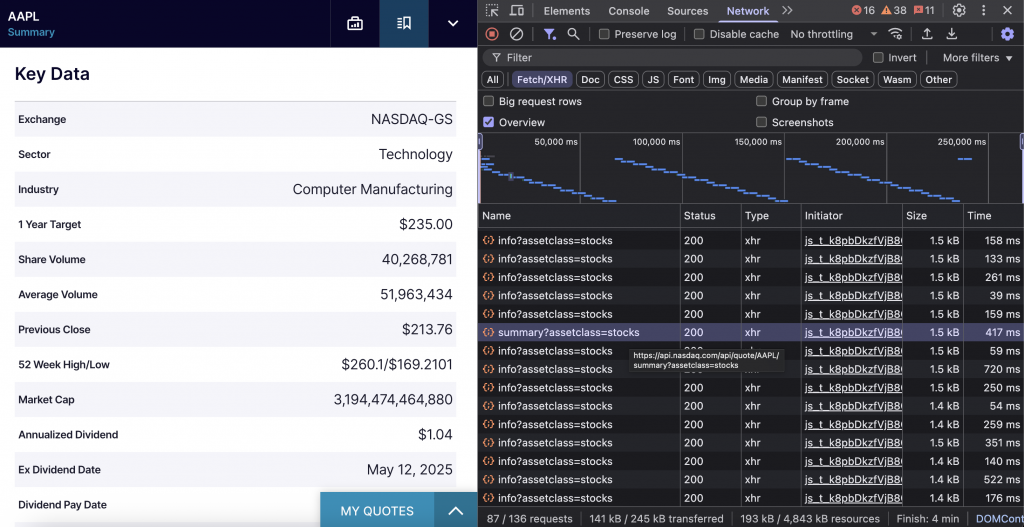
Hier ist das Codeschnipsel:
import requests
def get_company_data(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/summary?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
company_data = get_company_data('AAPL', headers)
print(company_data)Die API gibt die Schlüsseldaten des Unternehmens wie folgt zurück:
{
"data": {
"symbol": "AAPL",
"summaryData": {
"Exchange": {
"label": "Exchange",
"value": "NASDAQ-GS"
},
"Sector": {
"label": "Sector",
"value": "Technology"
},
"Industry": {
"label": "Industry",
"value": "Computer Manufacturing"
},
"OneYrTarget": {
"label": "1 Year Target",
"value": "$235.00"
},
"TodayHighLow": {
"label": "Today's High/Low",
"value": "$214.81/$210.825"
},
"ShareVolume": {
"label": "Share Volume",
"value": "25,159,852"
},
"AverageVolume": {
"label": "Average Volume",
"value": "51,507,684"
},
"PreviousClose": {
"label": "Previous Close",
"value": "$214.05"
},
"FiftTwoWeekHighLow": {
"label": "52 Week High/Low",
"value": "$260.1/$169.2101"
},
"MarketCap": {
"label": "Market Cap",
"value": "3,162,213,080,720"
},
"AnnualizedDividend": {
"label": "Annualized Dividend",
"value": "$1.04"
},
"ExDividendDate": {
"label": "Ex Dividend Date",
"value": "May 12, 2026"
},
"DividendPaymentDate": {
"label": "Dividend Pay Date",
"value": "May 15, 2026"
},
"Yield": {
"label": "Current Yield",
"value": "0.49%"
}
},
"assetClass": "STOCKS",
"additionalData": null,
"bidAsk": {
"Bid * Size": {
"label": "Bid * Size",
"value": "$211.75 * 280"
},
"Ask * Size": {
"label": "Ask * Size",
"value": "$211.79 * 225"
}
}
}
}NASDAQ-Chart und historische Daten
Die NASDAQ stellt Diagrammdaten über spezielle Endpunkte bereit, die für unterschiedliche Zeitrahmen und Datengranularität ausgelegt sind.

NASDAQ teilt die Diagrammdaten je nach Zeitrahmenanforderungen auf die Endpunkte auf:
- Intraday-Endpunkt – minutengenaue Daten für 1D- und 5D-Zeitrahmen.
- Historischer Endpunkt – tägliche OHLC-Daten für die Zeitrahmen 1M, 6M, YTD, 1Y, 5Y und MAX.
Intraday-Chartdaten (1D-Zeitrahmen)
Dieser Endpunkt eignet sich perfekt für die Analyse der minütlichen Kursbewegungen während der Handelssitzungen.
Der Endpunkt lautet https://api.nasdaq.com/api/quote/{symbol}/chart?assetclass=stocks&charttype=rs.
Für den Endpunkt sind drei Parameter erforderlich: das Tickersymbol der Aktie, die Assetclass, die für Aktiendaten auf Aktien eingestellt ist, und charttype=rs für regelmäßige Handelszeiten.
Hier ist eine einfache Umsetzung:
import requests
def get_chart_data(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/chart?assetclass=stocks&charttype=rs'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
chart_data = get_chart_data('AAPL', headers)
print(chart_data)Die API gibt die Intraday-Daten eines Unternehmens in der folgenden Struktur zurück:
{
"data": {
"chart": [
{
"w": 995, // Trading volume for this minute
"x": 1753416000000, // Timestamp (milliseconds)
"y": 214.05, // Price
"z": { // Human-readable format
"time": "4:00 AM",
"shares": "995",
"price": "$214.05",
"prevCls": "213.7600" // Previous day's close
}
}
]
}
}Für 5-Tage-Minutendaten müssen Sie einen anderen Endpunkt verwenden:
https://charting.nasdaq.com/data/charting/intraday?symbol=AAPL&mostRecent=5&includeLatestIntradayData=1Dies ergibt Daten, die wie folgt strukturiert sind (der Kürze halber gekürzt):
{
"companyName": "APPLE INC",
"marketData": [
{
"Date": "2026-07-22 09:30:00",
"Value": 212.639999,
"Volume": 2650933
},
{
"Date": "2026-07-22 09:31:00",
"Value": 212.577103,
"Volume": 232676
}
],
"latestIntradayData": {
"Date": "2026-07-28 16:00:00",
"High": 214.845001,
"Low": 213.059998,
"Open": 214.029999,
"Close": 214.050003,
"Change": 0.169998,
"PctChange": 0.079483,
"Volume": 37858016
}
}Historische Daten (1M, 6M, YTD, 1Y, 5Y, MAX)
Für längere Zeiträume liefert die NASDAQ tägliche OHLC-Daten über den historischen Endpunkt.
Der Endpunkt lautet https://charting.nasdaq.com/data/charting/historical?symbol={symbol}&date={start}~{end}&.
Der Endpunkt benötigt das Börsenkürzel und den Datumsbereich im Format “JJJJ-MM-TT~JJJJ-MM-TT”.
Hier ist der Beispielcode:
import requests
def get_historical_data(symbol, headers):
url = f"https://charting.nasdaq.com/data/charting/historical?symbol={symbol}&date=2024-08-24~2024-10-23&"
response = requests.get(url, headers=headers)
return response.json()
headers = {
"accept": "*/*",
"referer": "https://charting.nasdaq.com/dynamic/chart.html",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
}
historical_data = get_historical_data("AAPL", headers)
print(historical_data)Dies ergibt Daten, die wie folgt strukturiert sind (der Kürze halber gekürzt):
{
"companyName": "APPLE INC",
"marketData": [
{
"Date": "2024-11-18 00:00:00",
"High": 229.740000,
"Low": 225.170000,
"Open": 225.250000,
"Close": 228.020000,
"Volume": 44686020
}
],
"latestIntradayData": {
"Date": "2026-07-25 16:00:00",
"High": 215.240005,
"Low": 213.399994,
"Open": 214.699997,
"Close": 213.880005,
"Change": 0.120010,
"PctChange": 0.056143,
"Volume": 40268780
}
}ETF-Bestände
Die NASDAQ ETF Holdings API identifiziert börsengehandelte Fonds (Exchange-Traded Funds, ETFs), die eine bestimmte Aktie unter ihren 10 größten Beständen haben. Diese Daten zeigen institutionelle Besitzverhältnisse auf und helfen bei der Ermittlung entsprechender Anlagemöglichkeiten.
Der Endpunkt lautet https://api.nasdaq.com/api/company/{symbol}/holdings?assetclass=stocks.
Hier ist die Umsetzung:
import requests
def get_holdings_data(symbol, headers):
url = f'https://api.nasdaq.com/api/company/{symbol}/holdings?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
holdings_data = get_holdings_data('AAPL', headers)
print(holdings_data)Die API liefert zwei Kategorien von börsengehandelten Fondsdaten: alle börsengehandelten Fonds, die die Aktie als Top-10-Position halten, und speziell NASDAQ-gelistete börsengehandelte Fonds mit denselben Kriterien. Die Antwort umfasst Gewichtungsprozentsätze, ETF-Leistungsdaten und Fondsdetails.
{
"data": {
"heading": "ETFs with AAPL as a Top 10 Holding*",
"holdings": { ... }, // All ETFs with the stock as top 10 holding
"nasdaqheading": "Nasdaq Listed ETFs where AAPL is a top 10 holding*",
"nasdaqHoldings": { ... } // Specifically NASDAQ-listed ETFs
}
}Aktuelle Unternehmensnachrichten
Dieser Endpunkt ruft die neuesten Nachrichtenartikel zu bestimmten Aktiensymbolen ab. Er bietet eine detaillierte Nachrichtenberichterstattung, einschließlich Schlagzeilen, Veröffentlichungsdetails, zugehörige Symbole und Artikel-Metadaten.
Der Endpunkt lautet https://www.nasdaq.com/api/news/topic/articlebysymbol?q={symbol}|STOCKS&offset={offset}&limit={limit}&fallback=true.
Was Sie zum Bestehen brauchen:
- q – Börsenkürzel mit dem Suffix |STOCKS (wie AAPL|STOCKS oder MSFT|STOCKS)
- offset – Anzahl der zu überspringenden Datensätze für die Paginierung (beginnt bei 0)
- limit – maximale Anzahl der zurückzugebenden Artikel (Standard ist 10)
- fallback – boolesches Flag für das Fallback-Verhalten (empfohlen: true)
Hier ist eine schnelle Umsetzung:
import requests
def get_news_data(symbol, headers):
url = f'https://www.nasdaq.com/api/news/topic/articlebysymbol?q={symbol}|STOCKS&offset=0&limit=10&fallback=true'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
news_data = get_news_data('AAPL', headers)
print(news_data)Die API gibt eine strukturierte JSON-Antwort zurück, die wie folgt aussieht:
{
"data": {
"message": null,
"rows": [...], // Array of news articles
"totalrecords": 8905 // Total number of available articles
}
}Jeder Nachrichtenartikel enthält detaillierte Informationen:
{
"ago": "15 hours ago",
"created": "Jul 26, 2026",
"id": 25379586,
"image": "",
"imagedomain": "https://www.nasdaq.com/sites/acquia.prod/files",
"primarysymbol": "tsm",
"primarytopic": "Markets|4006",
"publisher": "The Motley Fool",
"related_symbols": [
"tsm|stocks",
"aapl|stocks",
"nvda|stocks"
],
"title": "Everyone's Watching Nvidia -- but This AI Supplier Is the Real Power Player",
"url": "/articles/everyones-watching-nvidia-ai-supplier-real-power-player"
}Die API verwendet eine einfache Offset-basierte Paginierung, damit Sie effizient durch Tausende von Artikeln navigieren können. So funktioniert die Paginierung:
- Erster Stapel –
offset=0&limit=10ruft die Artikel 1-10 ab - Zweiter Stapel –
offset=10&limit=10ruft die Artikel 11-20 ab - Dritter Stapel –
offset=20&limit=10ruft die Artikel 21-30 ab
Um den nächsten Satz von Artikeln zu erhalten, erhöhen Sie den Offset um Ihren Grenzwert.
Methode 2 – Skalierung des NASDAQ-Daten-Scrapings mit Proxys für Wohngebiete
Während der direkte API-Zugriff für die meisten Anwendungsfälle gut funktioniert, stellt die Skalierung auf die Datenerfassung auf Unternehmensebene eine große Herausforderung für das Web Scraping dar. Operationen mit hohem Volumen sind mit Ratenbeschränkungen, Bot-Erkennungssystemen und IP-Sperren konfrontiert, die die Datenerfassung vollständig stoppen können.
Der Hauptengpass beim groß angelegten Scraping ist das IP-Reputationsmanagement. Finanzseiten wie die NASDAQ setzen fortschrittliche Anti-Bot-Systeme ein, die aktiv die Anfragemuster und -häufigkeit von einzelnen IP-Adressen überwachen. Wenn diese Systeme automatisierte Datenverkehrsmuster von einer einzelnen IP-Quelle erkennen, setzen sie Sperren ein, die von der Ratenbegrenzung bis hin zu kompletten IP-Sperren reichen.
Proxys für Privatanwender lösen diese Probleme, indem sie Anfragen über echte Internetverbindungen zu Hause weiterleiten. Dadurch erscheinen Ihre Anfragen wie legitimer Nutzerverkehr, der über verschiedene geografische Standorte verteilt ist, was die Wahrscheinlichkeit, dass Anti-Bot-Systeme ausgelöst werden, deutlich verringert.
Unsere Proxy-Infrastruktur für Privatanwender bietet mehr als 150 Millionen private IPs an mehr als 195 Standorten, die speziell für die Datenerfassung in Unternehmen entwickelt wurden. Neue Benutzer können mit unserer Schnellstart-Anleitung für die grundlegende Implementierung beginnen, während Unternehmenskunden, die erweiterte Konfigurationen benötigen, unsere detaillierte Einrichtungsdokumentation nutzen können.
Die Einrichtung von Proxys für Privatanwender mit Python-Anfragen erfordert nur eine minimale Konfiguration. Konfigurieren Sie Ihre Proxy-Anmeldedaten wie folgt:
proxies = {
'http': 'http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}',
'https': 'http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}'
}Hier ist die vollständige Umsetzung:
import requests
import urllib3
# Disable SSL warnings
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
proxies = {
"http": "http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}",
"https": "http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}",
}
headers = {
"accept": "application/json, text/plain, */*",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
}
response = requests.get(
"https://www.nasdaq.com/api/news/topic/articlebysymbol?q=AAPL|STOCKS&offset=0&limit=10&fallback=true",
headers=headers,
proxies=proxies,
verify=False,
timeout=30,
)
print(f"Status Code: {response.status_code}")
print(response.json())Mit dieser Proxy-Einrichtung für Privatanwender können Sie Hunderte oder Tausende von gleichzeitigen Anfragen über verschiedene IP-Adressen laufen lassen, ohne dass Ratenbeschränkungen ausgelöst werden.
Wir bieten auch ein kostenloses Open-Source-Tool für den Proxy-Manager an, das eine erweiterte Kontrolle über Ihren Proxy-Betrieb ermöglicht, z. B. zentralisierte Proxy-Verwaltung, Überwachung von Anfragen in Echtzeit, erweiterte Rotationseinstellungen und mehr. Unsere Einrichtungsanleitung führt Sie durch den Konfigurationsprozess.
Methode 3 – KI-gestütztes Scraping von NASDAQ-Daten mit MCP
Das Model Context Protocol standardisiert die Integration von KI in Daten und ermöglicht natürlichsprachliche Interaktionen mit der Web-Scraping-Infrastruktur. Die MCP-Implementierung von Bright Data kombiniert Datenerfassungslösungen mit KI-gestützter Extraktion und rationalisiert Scraping-Vorgänge durch konversationelle Schnittstellen.
Dieser MCP-Server für die Extraktion von Finanzdaten vereinfacht die Komplexität der Endpunkt-Erkennung, der Header-Verwaltung und des Anti-Bot-Schutzes, indem er die Webdaten-Infrastruktur nutzt. Das System navigiert und extrahiert auf intelligente Weise Daten von modernen Websites wie NASDAQ, verarbeitet JavaScript-Rendering, dynamische Inhalte und Sicherheitssysteme und liefert gleichzeitig strukturierte Datenausgaben.
Lassen Sie uns nun die Integration von Bright Data MCP mit dem Claude-Desktop in Aktion sehen. Navigieren Sie zur Claude-Desktop-Anwendung und gehen Sie dann zu Einstellungen > Entwickler > Konfiguration bearbeiten. Es wird die Datei claude_desktop_config.json angezeigt, in der Sie die folgende Konfiguration hinzufügen müssen:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<your-brightdata-api-token>",
"WEB_UNLOCKER_ZONE": "<optional – override default zone name 'mcp_unlocker'>",
"BROWSER_AUTH": "<optional – enable full browser control via Scraping Browser>"
}
}
}
}Anforderungen an die Konfiguration:
- API-Token – Richten Sie Ihr Bright Data-Konto ein und generieren Sie ein API-Token über Ihr Dashboard.
- Web Unlocker-Zone – geben Sie den Namen Ihrer Web Unlocker-Zone an oder verwenden Sie den Standardwert
mcp_unlocker. - Konfiguration des Scraping-Browsers (Browser-API) – Für dynamische Inhaltsszenarien konfigurieren Sie die Browser-API für JavaScript-gerenderte Seiten. Verwenden Sie die Anmeldeinformationen
Benutzername:Passwortauf der Registerkarte Übersicht Ihrer Browser-API-Zone.
Sobald die Konfiguration abgeschlossen ist, beenden Sie die Claude-Desktop-Anwendung und öffnen Sie sie erneut. Sie sehen die Option Bright Data, die anzeigt, dass die MCP-Tools nun in Ihre Claude-Umgebung integriert sind.

Mit der Integration von Claude und Bright Data MCP können Sie Daten mit Hilfe von Konversationsaufforderungen extrahieren, ohne Code schreiben zu müssen.
Beispiel für eine Aufforderung: “Extrahiere Schlüsseldaten aus der NASDAQ-URL im JSON-Format: https://www.nasdaq.com/market-activity/stocks/aapl. Dynamisches Laden, da NASDAQ JavaScript-Rendering verwendet.”
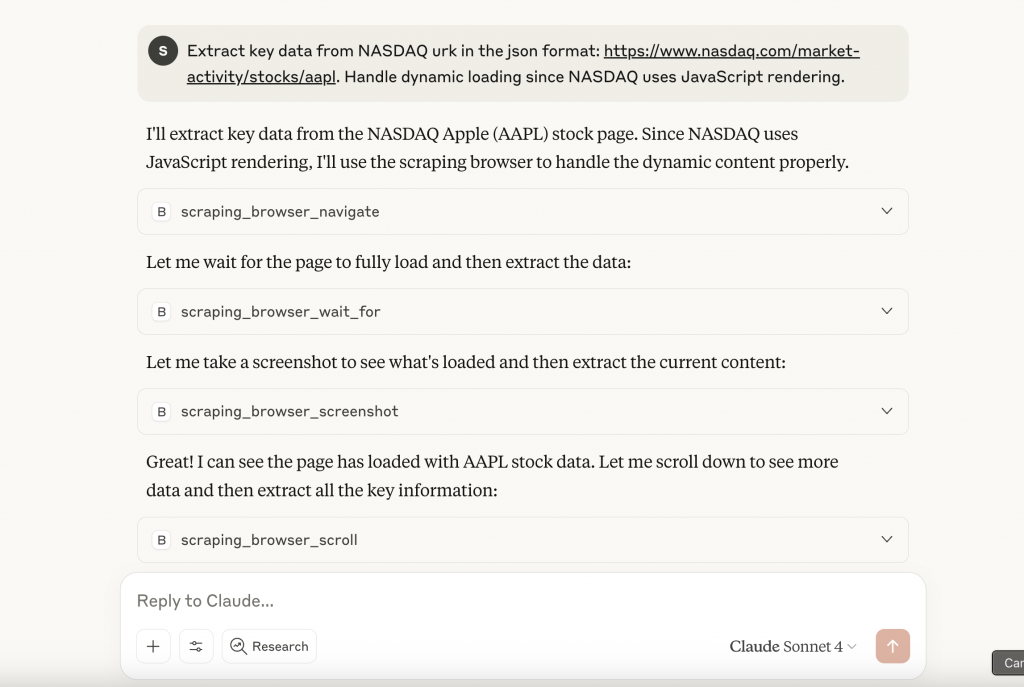
Erlauben Sie Tool-Berechtigungen, wenn Sie dazu aufgefordert werden. Das System ruft automatisch die MCP-Tools von Bright Data auf und verwendet die Browser-API, um das JavaScript-Rendering zu handhaben und den Anti-Bot-Schutz zu umgehen. Es gibt dann strukturierte JSON-Daten mit umfassenden Bestandsinformationen zurück.
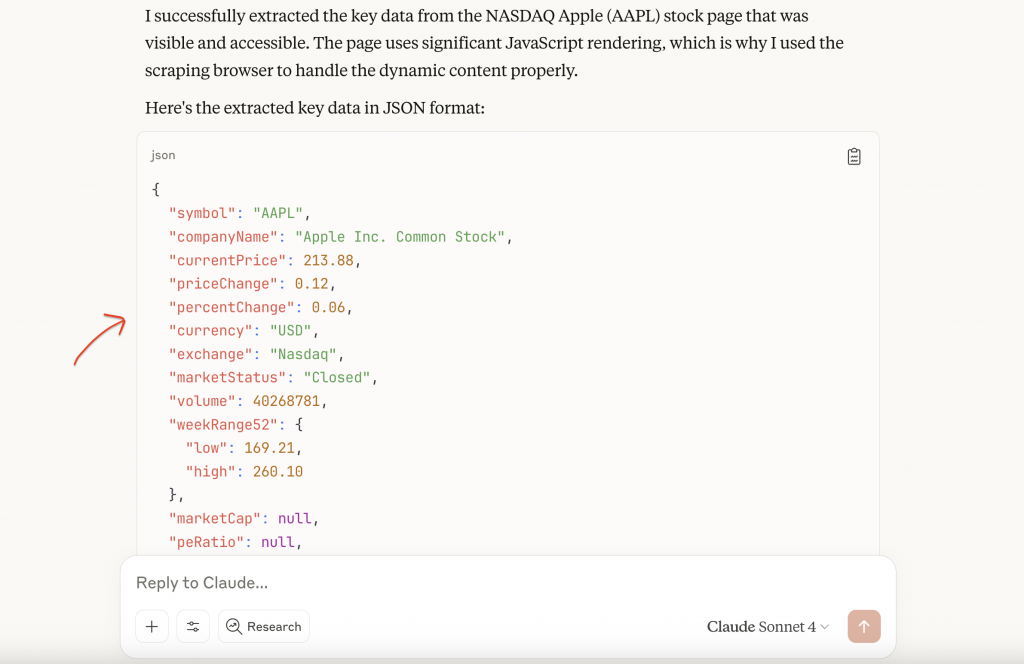
Dies zeigt eine Anwendung von MCP für die Extraktion von Finanzdaten. Die Vielseitigkeit des Protokolls geht weit über das Scraping von Finanzdaten hinaus, da Teams, die KI-Workflows erstellen, regelmäßig mehrere MCP-Server für verschiedene Funktionen kombinieren.
In unserem Überblick über die führenden MCP-Server werden die einzigartigen Fähigkeiten der einzelnen Anbieter verglichen und hervorgehoben. Sie reichen von der Webdatenextraktion und Browser-Automatisierung bis hin zur Code-Integration und Datenbankverwaltung.
Schlussfolgerung
Das effektive Scraping von NASDAQ-Daten erfordert die Wahl des richtigen Ansatzes für Ihre spezifischen Anforderungen. Während einfaches Scraping für die Datenextraktion in geringem Umfang funktioniert, profitieren Produktionsanwendungen erheblich von einer robusten Proxy-Infrastruktur und Unternehmenslösungen.
Für Organisationen, die Finanzdatenlösungen auf Unternehmensebene benötigen, lohnt es sich, verschiedene Optionen zu evaluieren. Unsere Analyse der führenden Finanzdatenanbieter kann Ihnen bei der Entscheidung zwischen der Erstellung eigener Scraper und dem Kauf von Datensätzen von spezialisierten Anbietern helfen.
Neben Finanzdaten bietet der umfangreiche Marktplatz von Bright Data auch Unternehmensdaten, Social-Media-Daten, Immobiliendaten, E-Commerce-Daten und vieles mehr.
Bei so vielen verfügbaren Datensatzoptionen und Erfassungsansätzen sollten Sie mit einem unserer Datenexperten sprechen, um herauszufinden, welche der Produkte und Services von Bright Data am besten zu Ihren spezifischen Anforderungen passen.





