

TL:DR: Sie werden lernen, wie Sie einen Scraper für Yahoo Finanzen zur Extraktion von Aktiendaten erstellen, um Finanzanalysen für den Handel und Investitionen durchzuführen.
In dieser Anleitung geht es um Folgendes:
- Warum sollten Sie Finanzdaten aus dem Internet scrapen?
- Bibliotheken und Tools zum Scrapen von Finanzdaten
- Scrapen von Aktiendaten aus Yahoo Finanzen mit Selenium
Warum sollten Sie Finanzdaten aus dem Internet scrapen?
Das Scrapen von Finanzdaten aus dem Internet bietet wertvolle Einblicke, die sich in verschiedenen Szenarien als nützlich erweisen:
- Automatisierter Handel: Mit gescrapten Echtzeit- oder historischen Marktdaten – z. B. Aktienkurse und -volumen – können Entwickler automatisierte Handelsstrategien entwickeln.
- Technische Analyse: Historische Marktdaten und Indikatoren sind für technische Analysten sehr wichtig. Sie ermöglichen es, Muster und Trends zu erkennen, die eine Hilfe für Investitionsentscheidungen sind.
- Finanzmodellierung: Forscher und Analysten können relevante Daten wie Finanzberichte und Wirtschaftsindikatoren erfassen, um komplexe Modelle für die Bewertung der Unternehmensleistung, Gewinnprognosen und die Beurteilung von Investitionsmöglichkeiten zu erstellen.
- Marktforschung: Finanzdaten liefern eine Vielzahl von Informationen über Aktien, Marktindizes und Rohstoffe. Die Analyse dieser Daten hilft Forschern, Markttrends, Stimmungen und die Branchenlage zu verstehen und auf der Grundlage dieser Daten fundierte Investitionsentscheidungen zu treffen.
Wenn es um die Beobachtung des Marktes geht, ist Yahoo Finanzen eine der beliebtesten Finanz-Websites. Sie bietet Anlegern und Händlern ein breites Spektrum an Informationen und Tools, wie Echtzeit- und historische Daten über Aktien, Anleihen, Investmentfonds, Rohstoffe, Währungen und Marktindizes. Darüber hinaus bietet sie Nachrichten, Finanzberichte, Schätzungen von Analysten, Diagramme und andere wertvolle Ressourcen.
Wenn Sie Yahoo Finanzen scrapen, können Sie auf eine Fülle von Informationen zugreifen, die Sie bei Ihren Finanzanalysen, Recherchen und Entscheidungsprozessen unterstützen.
Bibliotheken und Tools zum Scrapen von Finanzdaten
Python gilt dank seiner Syntax, Benutzerfreundlichkeit und der Vielzahl an Bibliotheken als eine der besten Sprachen für das Web Scraping. Lesen Sie unsere Anleitung zum Web Scraping in Python.
Um die geeigneten Scraping-Bibliotheken aus den vielen verfügbaren auszuwählen, erkunden Sie zunächst Yahoo Finanzen in Ihrem Browser. Sie werden feststellen, dass die meisten Daten auf der Website in Echtzeit aktualisiert werden oder sich nach einer Interaktion ändern. Das bedeutet, dass die Website stark auf AJAX basiert, weshalb die Daten dynamisch geladen und aktualisiert werden, ohne dass die Seite neu geladen werden muss. Mit anderen Worten: Sie benötigen ein Tool, das JavaScript ausführen kann.
Selenium macht es möglich, dynamische Websites in Python zu scrapen. Es rendert Websites in Webbrowsern und führt programmatisch Operationen auf ihnen aus, sogar wenn sie JavaScript zum Rendern oder Abrufen von Daten verwenden.
Dank Selenium können Sie die Ziel-Website in Python scrapen. Lernen Sie jetzt, wie das geht!
Scrapen von Aktiendaten aus Yahoo Finanzen mit Selenium
Folgen Sie dieser Schritt-für-Schritt-Anleitung und lernen Sie, wie Sie ein Python-Skript für das Web-Scraping von Yahoo Finanzen erstellen.
Schritt 1: Einrichten
Bevor Sie mit dem Scrapen von Finanzdaten beginnen, sollten Sie die folgenden Voraussetzungen erfüllen:
- Python 3+ muss auf Ihrem Rechner installiert sein: Laden Sie das Installationsprogramm herunter, doppelklicken Sie darauf und folgen Sie den Anweisungen des Installationsassistenten.
- Eine Python-IDE Ihrer Wahl: PyCharm Community Edition oder Visual Studio Code mit der Erweiterung für Python reicht aus.
Als Nächstes verwenden Sie die folgenden Befehle, um ein Python-Projekt mit einer virtuellen Umgebung einzurichten:
mkdir yahoo-finance-scraper
cd yahoo-finance-scraper
python -m venv envSie initialisieren den Projektordner yahoo-finance-scraper. Fügen Sie, so wie Sie unten sehen, die Datei scraper.py darin ein:
print('Hello, World!')Jetzt fügen Sie die Logik zum Scrapen von Yahoo Finanzen hinzu. Im Moment haben Sie ein Beispielskript, das nur „Hello, World!“ ausgibt.
Starten Sie es, um zu prüfen, ob es funktioniert mit:
python scraper.pyIhr Gerät sollte Folgendes angezeigen:
Hello, World!Super, jetzt haben Sie ein Python-Projekt für Ihren Finanz-Scraper! Jetzt müssen Sie nur noch die Abhängigkeiten des Projekts hinzufügen. Installieren Sie Selenium und Webdriver Manager mit dem folgenden Befehl:
pip install selenium webdriver-managerDas kann eine Weile dauern, haben Sie also Geduld.
Webdriver Manager ist nicht unbedingt erforderlich. Diese Bibliothek ist jedoch sehr empfehlenswert, da sie die Verwaltung von Web-Treibern in Selenium erheblich erleichtert. Mit Webdriver Manager müssen Sie den Webtreiber nicht manuell herunterladen, konfigurieren und importieren.
Aktualisieren Sie scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# scraping logic...
# close the browser and free up the resources
driver.quit()Dieses Skript instanziiert einfach eine Instanz von ChromeWebDriver. Sie werden es gleich für die Implementierung der Logik für die Datenextraktion verwenden.
Schritt 2: Bauen Sie eine Verbindung zur Ziel-Website auf.
So sieht die URL einer Seite mit Börseninformationen auf Yahoo Finanzen aus:
https://finance.yahoo.com/quote/AMZNWie Sie sehen, handelt es sich um eine dynamische URL, die sich entsprechend dem Tickersymbol ändert. Falls Sie mit dem Begriff nicht vertraut sind, es handelt sich dabei um eine Abkürzung, die zur eindeutigen Identifizierung von an der Börse gehandelten Aktien verwendet wird. „AMZN“ ist zum Beispiel das Tickersymbol der Aktie von Amazon.
Ändern wir das Skript so, dass es den Ticker aus einem Befehlszeilenargument liest.
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
# read the ticker from the CLI argument
ticker_symbol = sys.argv[1]
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'sys ist eine Python-Standardbibliothek, die den Zugriff auf die Befehlszeilenargumente ermöglicht. Denken Sie daran, dass das Argument mit dem Index 0 der Name Ihres Skripts ist. Sie müssen das Argument also mit dem Index 1 ansteuern.
Nach dem Lesen des Tickers aus der CLI wird er in einem f-String verwendet, um die Ziel-URL zu erzeugen, die gescrapt werden soll.
Nehmen wir zum Beispiel an, dass der Scraper mit dem Tesla-Ticker „TSLA“ gestartet werden soll:
python scraper.py TSLA
Die URL wird Folgendes enthalten:
https://finance.yahoo.com/quote/TSLAWenn Sie das Tickersymbol in der CLI vergessen, schlägt das Programm mit der nachfolgenden Fehlermeldung fehl:
Ticker symbol CLI argument missing!Bevor Sie eine Seite in Selenium öffnen, sollten Sie die Größe des Fensters einstellen, um sicherzustellen, dass alle Elemente sichtbar sind:
driver.set_window_size(1920, 1080)Sie können nun Selenium verwenden, um sich mit der Ziel-Website zu verbinden:
driver.get(url)Die Funktion get() weist den Browser an, die gewünschte Seite aufzurufen.
So sieht Ihr Skript zum Scrapen von Yahoo Finanzen bis jetzt aus:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
# read the ticker from the CLI argument
ticker_symbol = sys.argv[1]
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# set up the window size of the controlled browser
driver.set_window_size(1920, 1080)
# visit the target page
driver.get(url)
# scraping logic...
# close the browser and free up the resources
driver.quit()Wenn Sie es starten, wird dieses Fenster für den Bruchteil einer Sekunde geöffnet, bevor es beendet wird:
Das Starten des Browsers mit der Benutzeroberfläche ist nützlich für die Fehlersuche, da Sie so überwachen können, was der Scraper auf der Website tut. Das erfordert aber auch eine Menge Ressourcen. Um das zu vermeiden, stellen Sie Chrome so ein, dass er im Headless-Modus läuft:
from selenium.webdriver.chrome.options import Options
# ...
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)Der kontrollierte Browser wird nun im Hintergrund ohne Benutzeroberfläche gestartet.
Schritt 3: Untersuchen Sie die Ziel-Website
Wenn Sie eine effektive Strategie zur Datengewinnung entwickeln wollen, müssen Sie zunächst die Ziel-Website analysieren. Öffnen Sie Ihren Browser und besuchen Sie die Aktienseite vonYahoo.
Wenn Sie in Europa ansässig sind, werden Sie in einem Fenster zunächst gefragt, ob Sie die Cookies akzeptieren möchten:
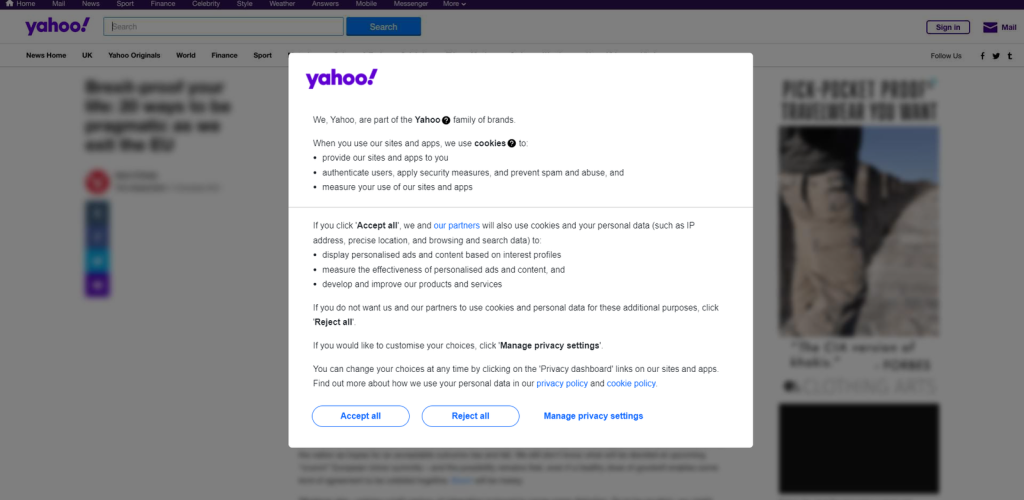
Um das Fenster zu schließen und die gewünschte Seite weiter zu besuchen, klicken Sie auf „Alle akzeptieren“ oder „Alle ablehnen“. Klicken Sie mit der rechten Maustaste auf die erste Schaltfläche und wählen Sie die Option „Inspect“ (Untersuchen), um die DevTools Ihres Browsers zu öffnen:

Hier werden Sie feststellen, dass Sie die Schaltfläche mit dem folgenden CSS-Selektor auswählen können:
.consent-overlay .accept-allVerwenden Sie diese ice-Zeilen, um mit dem Zustimmungsmodul in Selenium umzugehen:
try:
# wait up to 3 seconds for the consent modal to show up
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# click the "Accept all" button
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('Cookie consent overlay missing')WebDriverWait ermöglicht es Ihnen, zu warten, bis eine erwartete Bedingung auf der Seite angezeigt wird. Wenn innerhalb der angegebenen Zeitspanne nichts passiert, wird eine TimeoutException ausgegeben. Da die Cookie-Einblendung nur angezeigt wird, wenn Ihre IP-Adresse aus Europa stammt, können Sie die Ausnahme mit der Anweisung try-catch behandeln. Auf diese Weise läuft das Skript auch dann weiter, wenn das Zustimmungsfenster nicht angezeigt wird.
Damit das Skript funktioniert, müssen Sie die folgenden Importe hinzufügen:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutExceptionUntersuchen Sie nun die Ziel-Website in den DevTools und machen Sie sich mit ihrer DOM-Struktur vertraut.
Schritt 4: Extrahieren der Aktiendaten
Wie Sie im vorangegangenen Schritt festgestellt haben sollten, befinden sich einige der interessantesten Informationen in folgendem Abschnitt:
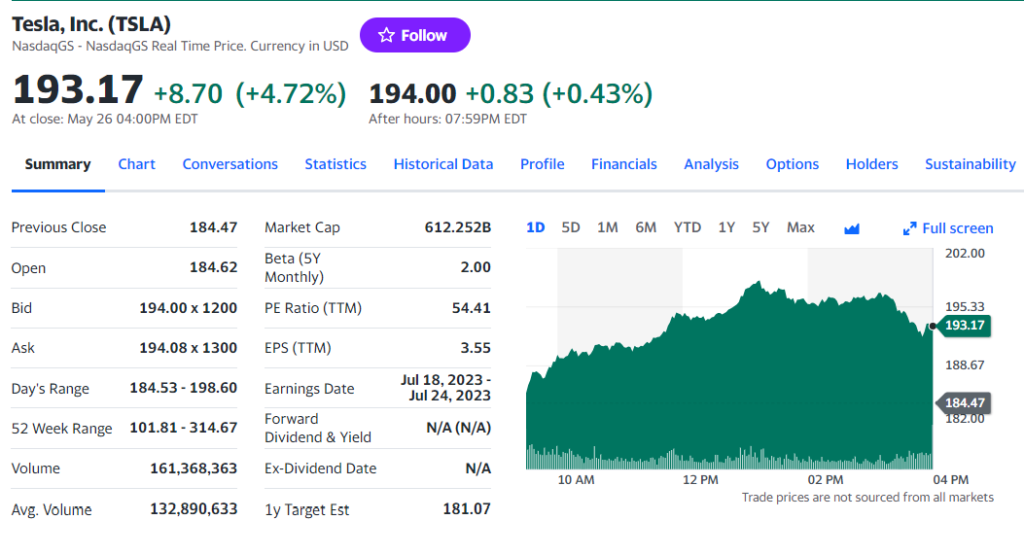
Untersuchen Sie das HTML-Preisindikator-Element:
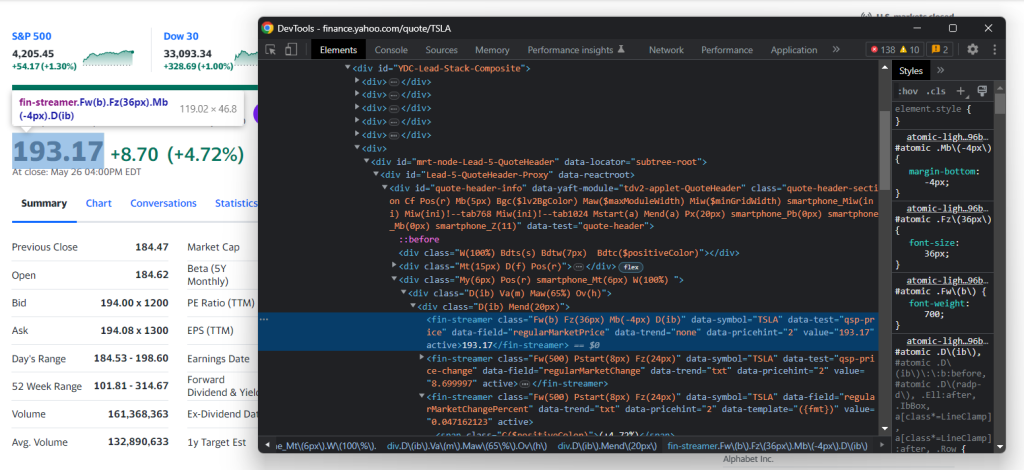
Beachten Sie, dass CSS-Klassen für die Festlegung geeigneter Selektoren in Yahoo Finanzen nicht nützlich sind. Sie scheinen einer speziellen Syntax für ein Styling-Framework zu folgen. Konzentrieren Sie sich stattdessen auf die anderen HTML-Attribute. So können Sie zum Beispiel den Aktienkurs mit dem unten stehenden CSS-Selektor abrufen:
[data-symbol="TSLA"][data-field="regularMarketPrice"]Extrahieren Sie auf ähnliche Weise alle Aktiendaten aus den Preisindikatoren mit:
regular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]')
.text
regular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]')
.text
regular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
post_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]')
.text
post_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]')
.text
post_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
Nachdem Sie ein HTML-Element mit der spezifischen CSS-Selektorstrategie ausgewählt haben, können Sie den Inhalt mit dem Feld text extrahieren. Da die Prozentfelder runde Klammern enthalten, entfernen Sie diese mit replace().
Fügen Sie die Felder dem Wörterbuch stock hinzu und geben Sie es aus, um zu überprüfen, ob das Scrapen der Finanzdaten erwartungsgemäß verläuft:
# initialize the dictionary
stock = {}
# stock price scraping logic omitted for brevity...
# add the scraped data to the dictionary
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
print(stock)Führen Sie das Skript für das Wertpapier, das Sie scrapen möchten, aus. Sie sollten etwas Ähnliches wie das sehen:
{'regular_market_price': '193.17', 'regular_market_change': '+8.70', 'regular_market_change_percent': '+4.72%', 'post_market_price': '194.00', 'post_market_change': '+0.83', 'post_market_change_percent': '+0.43%'}Weitere nützliche Informationen finden Sie in der Tabelle #quote-summary:
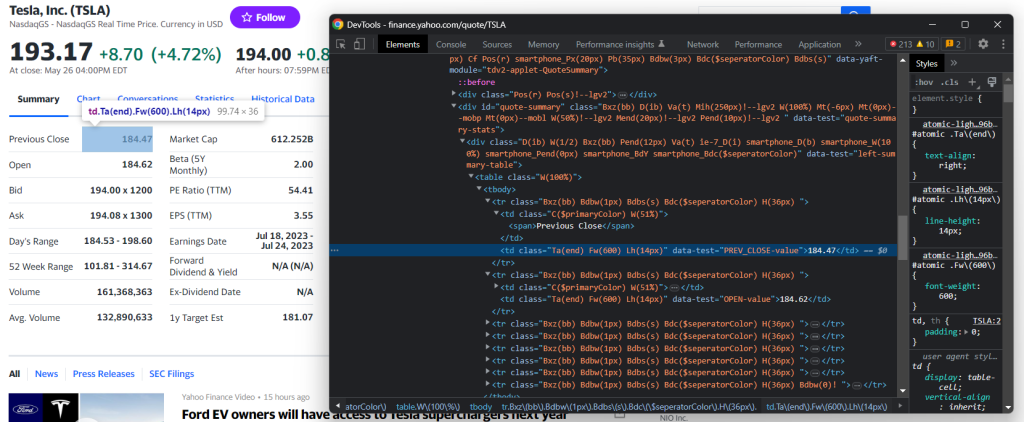
In diesem Fall können Sie jedes Datenfeld mit Hilfe des Attributs data-test wie im folgenden CSS-Selektor extrahieren:
#quote-summary [data-test="PREV_CLOSE-value"]Scrapen Sie sie alle mit:
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').textDann fügen Sie sie zu stock hinzu:
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_estGroßartig! Sie haben soeben in Python eine Finanz-Website gescrapt!
Schritt 5: Scrapen Sie mehrere Aktienkurse
Ein diversifiziertes Anlageportfolio besteht aus mehr als einem Wertpapier. Um Daten für alle abzurufen, müssen Sie Ihr Skript erweitern, um mehrere Ticker zu scrapen.
Zunächst verkapseln Sie die Scraping-Logik mit der folgenden Funktion:
def scrape_stock(driver, ticker_symbol):
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
driver.get(url)
# deal with the consent modal...
# initialize the stock dictionary with the
# ticker symbol
stock = { 'ticker': ticker_symbol }
# scraping the desired data and populate
# the stock dictionary...
return stockDurchlaufen Sie dann die CLI-Argumente des Tickers und wenden Sie die Scraping-Funktion an:
if len(sys.argv) <= 1:
print('Ticker symbol CLI arguments missing!')
sys.exit(2)
# initialize a Chrome instance with the right
# configs
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
driver.set_window_size(1150, 1000)
# the array containing all scraped data
stocks = []
# scraping all market securities
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))Am Ende des Zyklus for wird die Liste der Python-Wörterbücher stocks alle Börsendaten enthalten.
Schritt 6: Exportieren Sie die gescrapten Daten nach CSV
Sie können die erfassten Daten mit nur wenigen Codezeilen nach CSV exportieren:
import csv
# ...
# extract the name of the dictionary fields
# to use it as the header of the output CSV file
csv_header = stocks[0].keys()
# export the scraped data to CSV
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)Dieses Schnipsel erstellt die Datei stocks.csv mit open(), initialisiert sie mit einer Kopfzeile und füllt sie auf. DictWriter.writerows() wandelt jedes Wörterbuch in einen CSV-Datensatz um und hängt ihn der Ausgabedatei an.
Da csv aus der Python-Standardbibliothek stammt, müssen Sie nicht einmal eine zusätzliche Abhängigkeit installieren, um Ihr Ziel zu erreichen.
Sie sind von Rohdaten einer Website ausgegangen und haben teilweise strukturierte Daten in einer CSV-Datei gespeichert. Es ist an der Zeit, einen Blick auf den gesamten Yahoo Finanz-Scraper zu werfen.
Schritt 7: Fügen Sie alles zusammen
Hier finden Sie die komplette Datei scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import sys
import csv
def scrape_stock(driver, ticker_symbol):
# build the URL of the target page
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# visit the target page
driver.get(url)
try:
# wait up to 3 seconds for the consent modal to show up
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# click the 'Accept all' button
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('Cookie consent overlay missing')
# initialize the dictionary that will contain
# the data collected from the target page
stock = { 'ticker': ticker_symbol }
# scraping the stock data from the price indicators
regular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]')
.text
regular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]')
.text
regular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
post_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]')
.text
post_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]')
.text
post_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
# scraping the stock data from the "Summary" table
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR,
'#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').text
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_est
return stock
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Ticker symbol CLI argument missing!')
sys.exit(2)
options = Options()
options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# set up the window size of the controlled browser
driver.set_window_size(1150, 1000)
# the array containing all scraped data
stocks = []
# scraping all market securities
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))
# close the browser and free up the resources
driver.quit()
# extract the name of the dictionary fields
# to use it as the header of the output CSV file
csv_header = stocks[0].keys()
# export the scraped data to CSV
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)Mit weniger als 150 Zeilen Code haben Sie einen voll funktionsfähigen Web Scraper zum Abrufen von Daten aus Yahoo Finanzen erstellt.
Starten Sie ihn für die von Ihnen angepeilten Börsenkurse wie im folgenden Beispiel:
python scraper.py TSLA AMZN AAPL META NFLX GOOGWenn Sie mit dem Scrapen fertig sind, erscheint die Datei stocks.csv im Stammordner Ihres Projekts:

Fazit
In diesem Tutorial haben Sie erfahren, warum Yahoo Finance eines der besten Finanzportale im Web ist und wie Sie Daten daraus extrahieren können. Insbesondere haben Sie gesehen, wie Sie mit Python einen Scraper erstellen können, der Börsendaten abruft. Wie hier demonstriert, ist dies nicht komplex und erfordert nur wenige Codezeilen.
Allerdings ist Yahoo Finance eine dynamische Website, die stark auf JavaScript basiert und fortschrittliche Technologien zum Datenschutz einsetzt. Für eine reibungslose Datenerfassung auf solchen Websites empfehlen wir unsere Yahoo Finance Scraper API. Diese API übernimmt die komplexen Aufgaben beim Scraping, einschließlich CAPTCHAs, Fingerprinting und automatischen Wiederholungen. So können Sie problemlos strukturierte Finanzdaten abrufen. Starten Sie noch heute mit unserer Yahoo Finance Scraper API und vereinfachen Sie Ihren Datenerfassungsprozess.
Sie wollen sich gar nicht mit Web Scraping beschäftigen, sind aber an Finanzdaten interessiert? Dann erkunden Sie unseren Datensatzmarkt.





