

Alle Daten sind wertvoll. Aggregierte Daten gehören zu den gefragtesten Datenarten im Internet. Google Finance enthält Unmengen an aggregierten Daten für verschiedene Finanzmärkte. Diese Daten sind für alles nützlich, von Trading-Bots bis hin zu allgemeinen Berichten.
Legen wir los!
Voraussetzungen
Wenn Sie über die richtigen Fähigkeiten verfügen, können Sie relativ einfach Daten aus Google Finance extrahieren. Um Google Finance zu scrapen, benötigen Sie Folgendes.
- Python: Sie benötigen lediglich grundlegende Python-Kenntnisse. Sie sollten wissen, wie man mit Variablen, Funktionen und Schleifen umgeht.
- Python Requests: Dies ist der Standard-HTTP-Client von Python. Er wird verwendet, um GET-, POST-, PUT- und DELETE-Anfragen im gesamten Web zu stellen.
- BeautifulSoup: BeautifulSoup bietet uns Zugriff auf einen effizienten HTML-Parser. Damit extrahieren wir unsere Daten.
Wenn Sie diese noch nicht installiert haben, können Sie Requests und BeautifulSoup mit den folgenden Befehlen installieren.
Installieren Sie Requests
pip install requests
Installieren von BeautifulSoup
pip install beautifulsoup4
Was Sie aus Google Finance scrapen sollten
Hier ist ein Screenshot der Startseite von Google Finance. Sie enthält alle kleinen Informationen über verschiedene Märkte. Wir möchten detaillierte Informationen über mehrere Märkte, nicht nur kleine Ausschnitte.
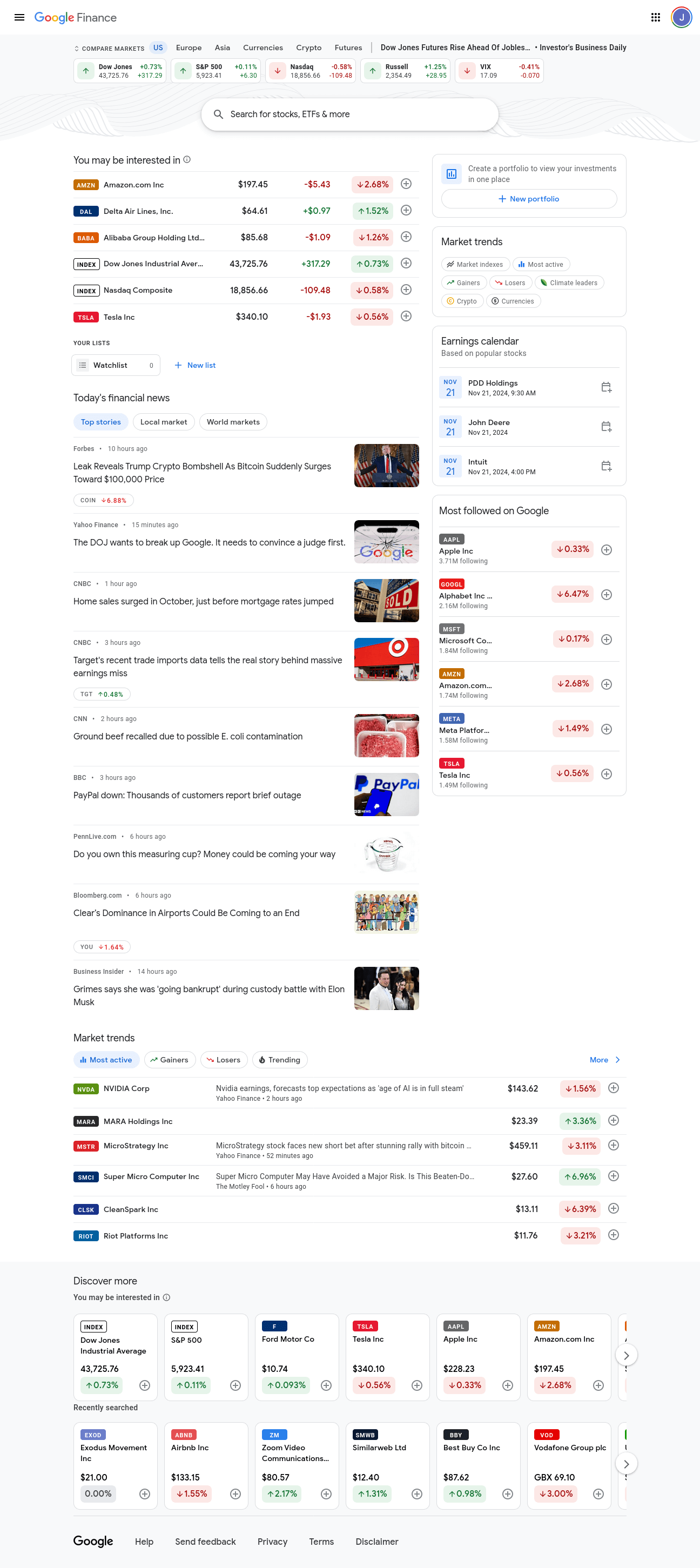
Wenn Sie ein wenig nach unten scrollen, sehen Sie auf der rechten Seite einen Abschnitt namens „Markttrends ”. Jede Blase in diesem Abschnitt enthält einen Link zu detaillierten Informationen über einen bestimmten Markt. Wir interessieren uns für die folgenden Märkte: Gewinner, Verlierer, Marktindizes, Aktivste und Kryptowährungen.
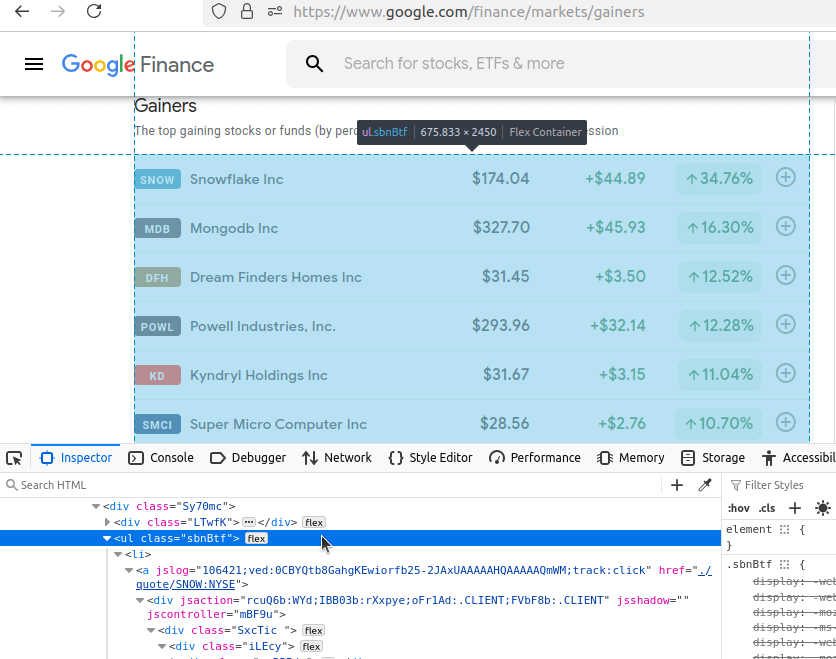
Nun klicken wir auf jede dieser Seiten und sehen sie uns an. Wir beginnen mit „Gewinner”. Wie Sie in unserer Adressleiste sehen können, lautet unsere URL: https://www.google.com/finance/markets/gainers. Wenn Sie sich die Entwicklerkonsole unten ansehen, werden Sie feststellen, dass der gesamte Datensatz in einer ul, einer unorganisierten Liste, eingebettet ist.
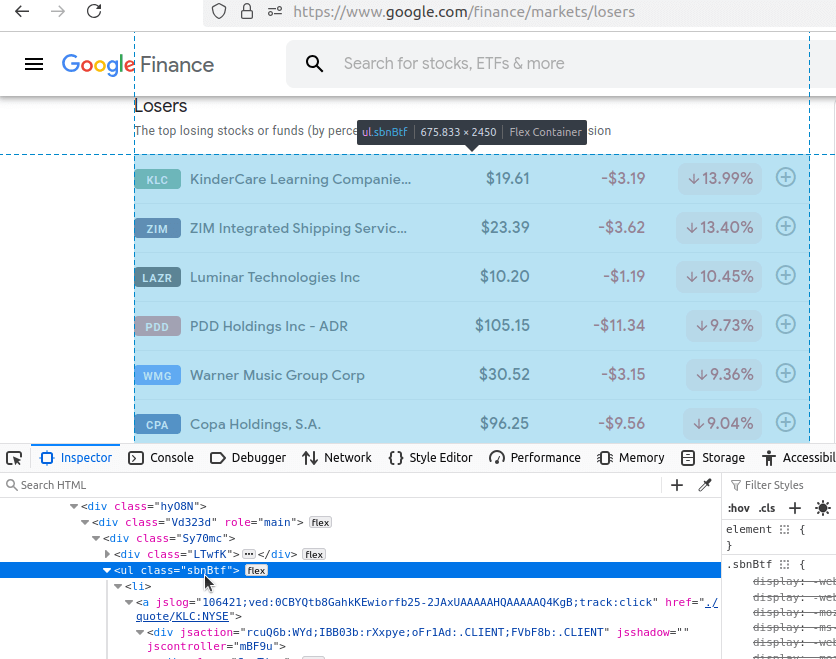
Nun sehen wir uns die Verlierer an. Unsere URL lautet: https://www.google.com/finance/markets/losers. Auch hier ist unser Datensatz in eine unorganisierte Liste eingebettet.
Hier ist derselbe Screenshot der Seite „Market indexes” (Marktindizes ). Diese Seite ist etwas Besonderes. Sie enthält mehrere ul-Elemente, daher müssen wir dies in unserem Code berücksichtigen. Die URL lautet: https://www.google.com/finance/markets/indexes. Erkennen Sie langsam ein Muster?
Die Seite „Most active“ (Aktivste ) ist unten dargestellt. Auch hier sind alle unsere Zieldaten in einem ul eingebettet. Unsere URL lautet: https://www.google.com/finance/markets/most-active.
Schauen wir uns zum Schluss noch unsere Crypto-Seite an. Wie Sie wahrscheinlich schon erwartet haben, befinden sich unsere Daten in einem ul. Unsere URL lautet: https://www.google.com/finance/markets/cryptocurrencies.
Auf jeder dieser Seiten sind unsere Zieldaten in einer unorganisierten Liste eingebettet. Um unsere Daten zu extrahieren, müssen wir diese ul- Elemente finden und die li-Elemente (Listenelemente) aus jedem einzelnen extrahieren. Sehen Sie sich unsere Basis-URL an: https://www.google.com/finance/markets. Jede Seite stammt aus dem Endpunkt „markets ”. Unser URL-Format lautet: https://www.google.com/finance/markets/{NAME_OF_MARKET}. Wir haben 5 Datensätze und 5 URLs, die alle gleich strukturiert sind. Das macht es einfach, mit nur wenigen Variablen eine Menge Daten zu scrapen.
Google Finance manuell mit Python scrapen
Wenn Sie es vermeiden können, blockiert zu werden, können Sie Google Finance mit Python Requests und BeautifulSoup scrapen. Wir müssen in der Lage sein, unsere Daten zu scrapen. Wir sollten auch in der Lage sein, sie zu speichern. Wir haben eine Vielzahl von Endpunkten, aber sie stammen alle von derselben Basis-URL: https://google.com/finance/markets/. Jedes Mal, wenn wir eine Seite abrufen, müssen wir die ul-Elemente finden und alle li-Elemente aus jeder Liste extrahieren.
Sehen wir uns die grundlegenden Funktionen an, die wir in unserem Skript verwenden werden. Wir nennen sie write_to_csv() und scrape_page(). Diese Namen sind ziemlich selbsterklärend.
Einzelne Funktionen
Sehen Sie sich write_to_csv() an.
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Daten in CSV-Datei schreiben...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{filename} erfolgreich in CSV geschrieben...")
- Unsere Funktion muss eine Liste von
Dict-Objektenin eine CSV-Datei schreiben. Wenn unsereDatenkeineListesind, konvertieren wir sie mitdata = [data]. - Jede von uns erstellte Datei stammt aus Google Finance, daher fügen wir dies beim Erstellen der Datei hinzu:
filename = f"google-finance-{filename}.csv". - Unser
Standardmodusist„w“(schreiben), aber wenn die Datei bereits existiert, ändern wir unserenModuszu„a“(anhängen). csv.DictWriter(file, fieldnames=data[0].keys())initialisiert unseren Dateischreiber.- Wenn wir uns im Schreibmodus befinden, existiert die Datei noch nicht, daher erstellen wir ihre Kopfzeilen aus dem ersten
DictderListe. - Sobald wir mit der Einrichtung fertig sind, fügen wir unsere Daten mit
writer.writerows(data)zur Datei hinzu.
Sehen wir uns nun die eigentliche Scraping-Funktion scrape_page() an. Hier geschieht das eigentliche Wunder. Wir senden unsere Anfrage an unsere formatierte URL. Dann verwenden wir BeautifulSoup, um den HTML-Code zum Parsing zu verwenden, den wir zurückerhalten. Wir erstellen eine leere Liste namens scraped_data, um unsere extrahierten Daten zu speichern. Wir suchen alle ul-Elemente auf der Seite. Anschließend extrahieren wir die li-Elemente aus jedem gefundenen ul. Allerdings gibt es dabei einen Haken. Der Text jedes Listenelements ist in mehreren div-Elementen verschachtelt. Das tatsächlich extrahierte Array enthält eine Reihe von Wiederholungen. Um dies zu umgehen, extrahieren wir die Elemente 3, 6, 8 und 11 und fügen sie mit append() an scraped_data an.
Unsere Funktion scrape_page() finden Sie im folgenden Snippet.
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
„price”: divs[8].text,
„change”: divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
- Wir senden unsere GET-Anfrage an diesen Endpunkt:
requests.get(f"https://google.com/finance/markets/{endpoint}"). - Wir verwenden den HTML-Parser von BeuatifulSoup für unsere
Antwort:soup = BeautifulSoup(response.text, "html.parser"). - Wir finden alle Tabellen auf der Seite:
tables = soup.find_all("ul"). scraped_data = []gibt uns ein Array, in dem wir unsere Ergebnisse speichern können.- Wir durchlaufen jede der gefundenen Tabellen und führen Folgendes aus: „
- Wir suchen alle Listenelemente:
table.find_all("li"). - Durchlaufen Sie jedes Listenelement und suchen Sie deren
div-Elemente. Dies gibt eine Liste namensdivszurück. - Wir extrahieren den Text aus den Elementen 3, 6, 8 und 11 aus
divsund erstellen daraus einDict. - Fügen Sie das
Dictzu unserenscraped_datahinzu. - Kryptowährungen werden anhand ihres Handelspaares bewertet. Wenn wir uns also am Endpunkt für Kryptowährungen befinden, setzen wir unsere
Währungaufn/azurück.
- Wir suchen alle Listenelemente:
- Sobald wir mit dem Parsing der Seite fertig sind, speichern wir unsere
scrape_datain einer CSV-Datei:write_to_csv(scraped_data, endpoint). Wir übergeben unseren Endpunkt als Dateinamen.
Google Finance-Daten scrapen
Wir können unsere oben genannten Funktionen in ein Skript einfügen, damit alles funktioniert. Zusätzlich zu diesen Funktionen fügen wir eine Liste von Endpunkten hinzu. Wir fügen auch ein Hauptprogramm hinzu, um unsere Laufzeit zu speichern. Kopieren Sie den folgenden Code und probieren Sie ihn aus!
import requests
from bs4 import BeautifulSoup
import csv
from pathlib import Path
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{filename} erfolgreich in CSV geschrieben...")
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
if __name__ == "__main__":
for endpoint in endpoints:
print("---------------------")
scrape_page(endpoint)
Wenn wir den obigen Code ausführen, erhalten wir die folgende Ausgabe.
---------------------
Schreiben in CSV...
Daten in CSV-Datei schreiben...
google-finance-gainers.csv erfolgreich in CSV geschrieben...
---------------------
Schreiben in CSV...
Daten in CSV-Datei schreiben...
google-finance-losers.csv erfolgreich in CSV geschrieben...
---------------------
In CSV schreiben...
Daten in CSV-Datei schreiben...
google-finance-indexes.csv erfolgreich in CSV geschrieben...
---------------------
Schreiben in CSV...
Daten in CSV-Datei schreiben...
google-finance-most-active.csv erfolgreich in CSV geschrieben...
---------------------
Schreiben in CSV...
Daten in CSV-Datei schreiben...
google-finance-cryptocurrencies.csv erfolgreich in CSV geschrieben...
Wenn Sie das Skript mit VSCode ausführen, können Sie tatsächlich sehen, wie die CSV-Dateien angezeigt werden, sobald der Scraper seine Arbeit abgeschlossen hat. Sie sind im folgenden Screenshot hervorgehoben.
Wir zeigen Ihnen auch einen Screenshot, wie jede einzelne Datei in ONLYOFFICE aussieht.
Aktivste
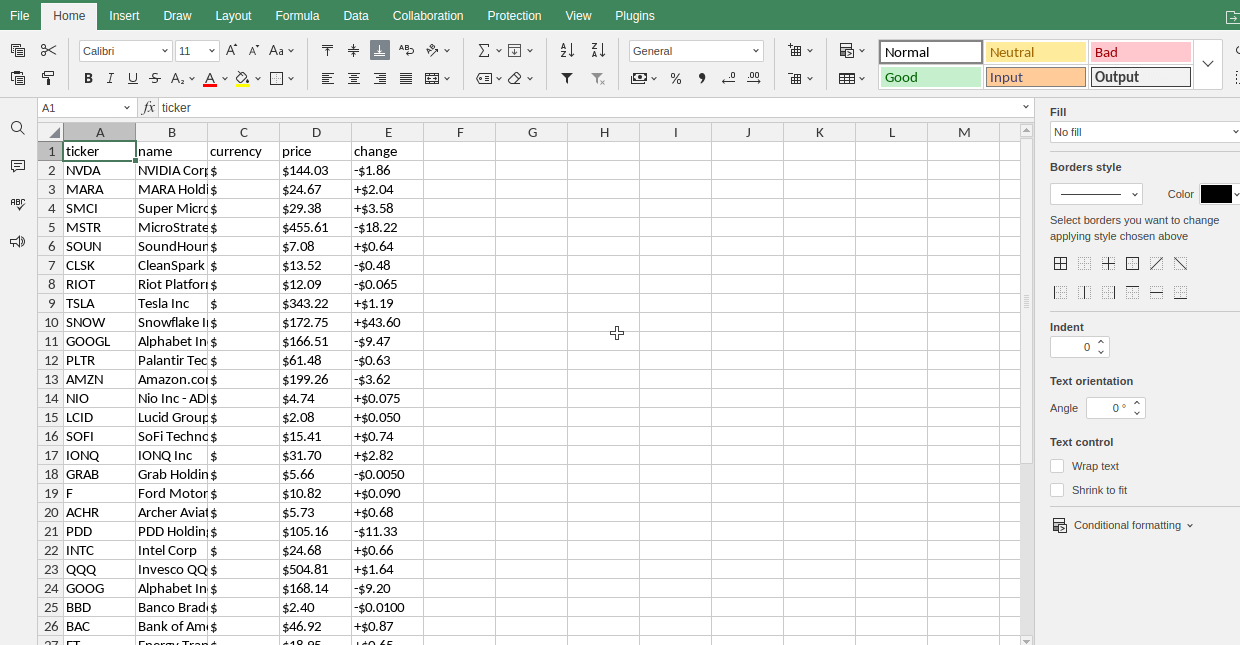
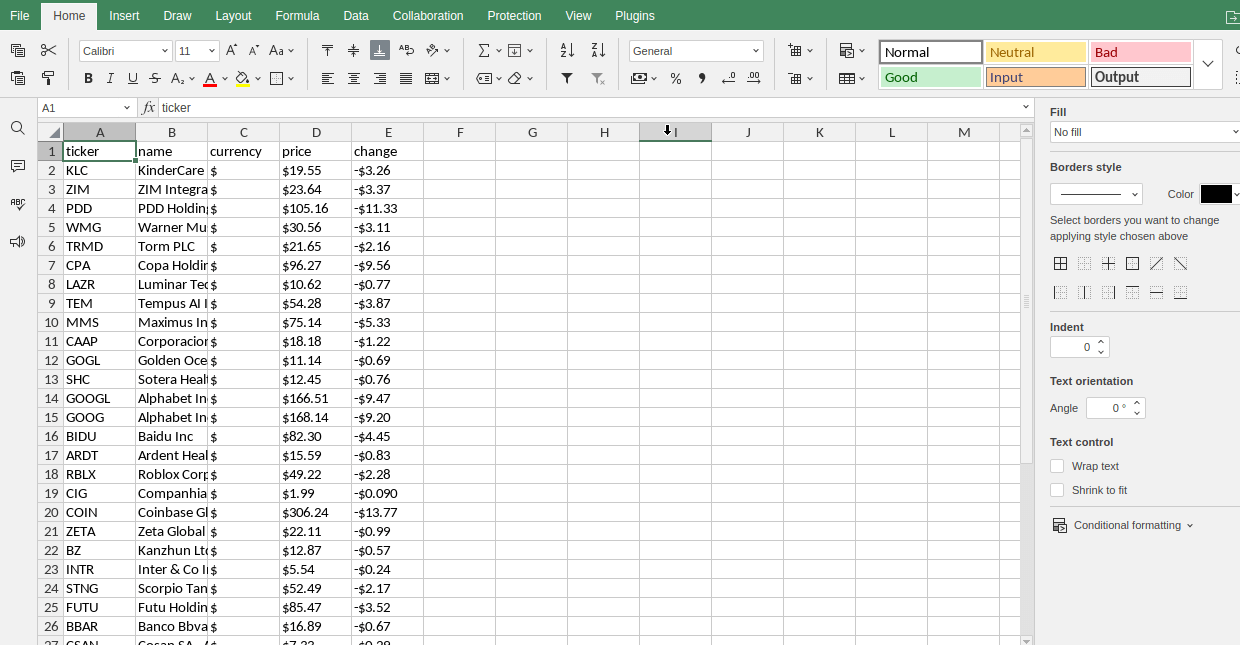
Verlierer
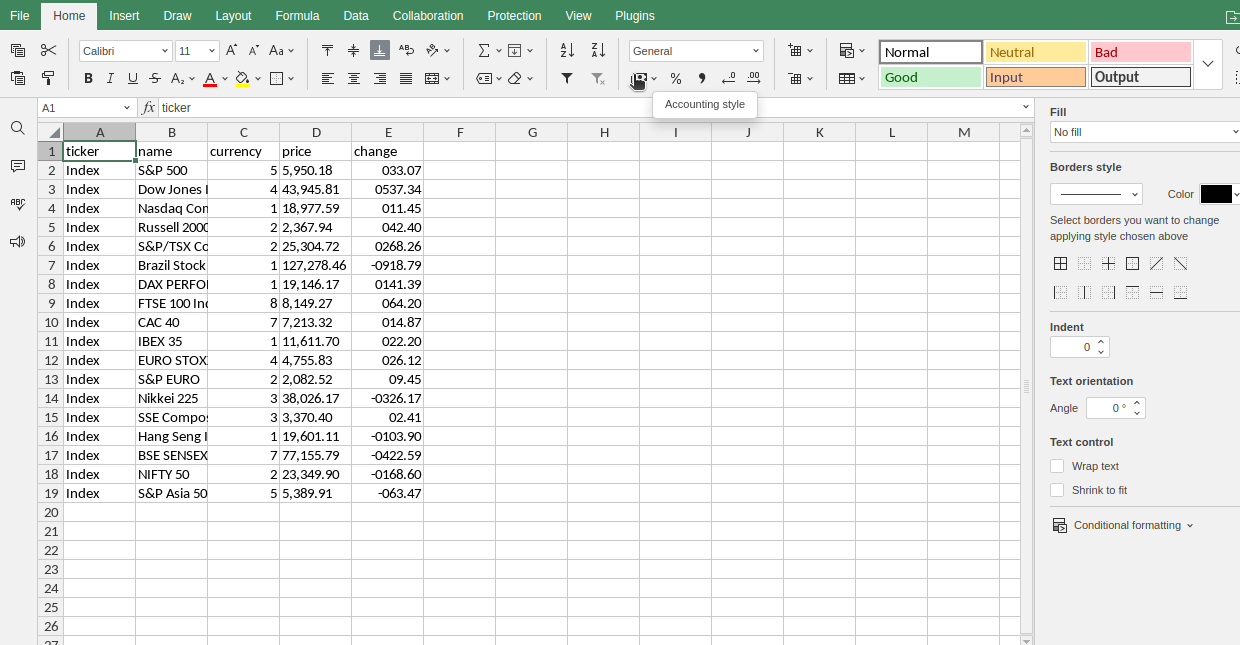
Indizes
Gewinner
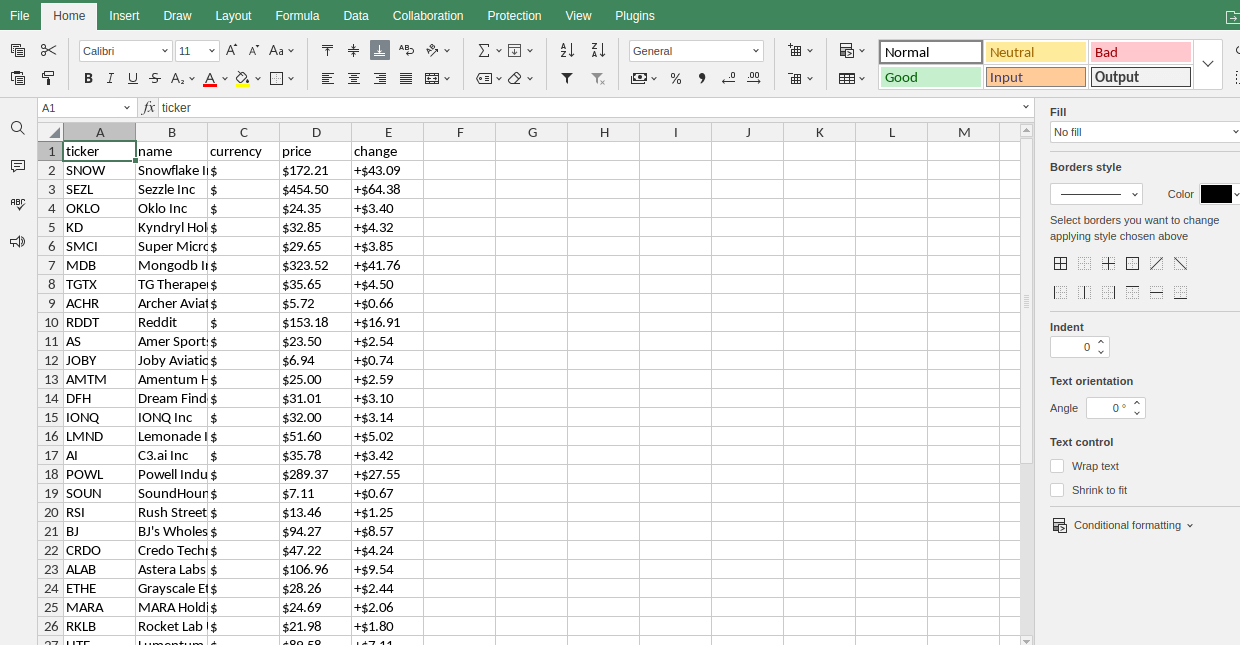
Kryptowährungen
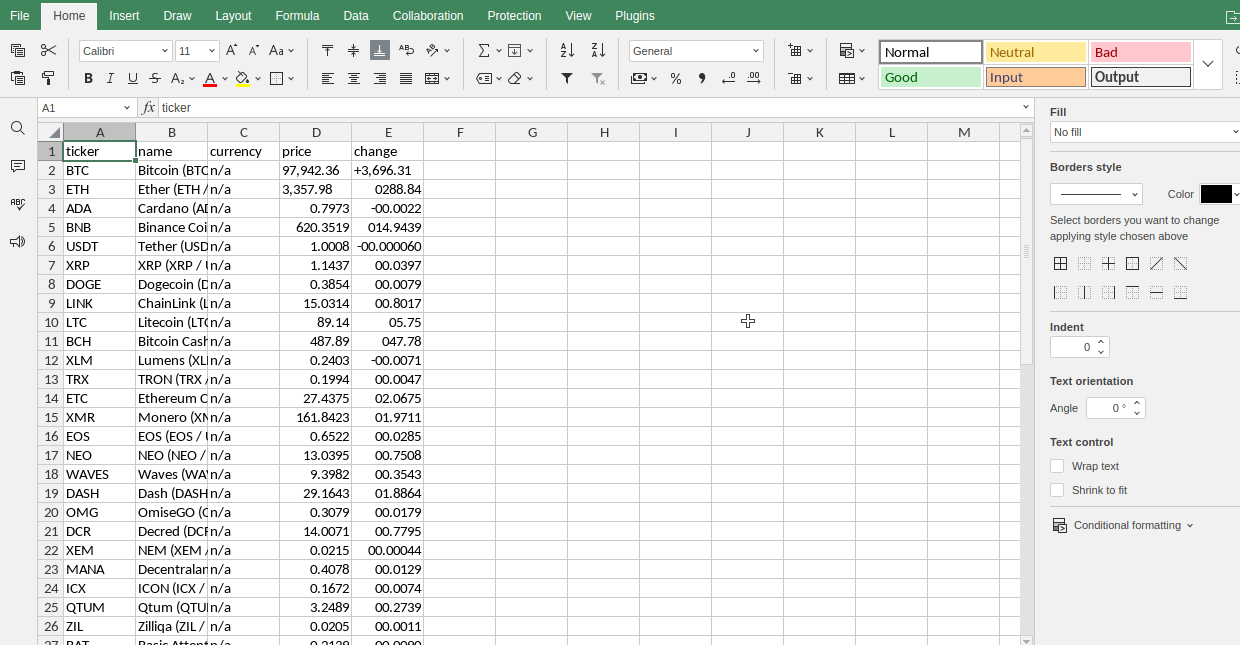
Fortgeschrittene Techniken
Umgang mit Paginierung
Traditionell wird die Paginierung mit Zahlen gehandhabt. Bei Google Finance verwenden wir tatsächlich unser Endpunkt-Array, um unsere Paginierung zu handhaben. Jeder Eintrag in unserer Endpunktliste steht für eine einzelne Seite, die wir scrapen möchten. Sehen Sie sich diese Liste noch einmal an. Lesen Sie hier mehr darüber, wie Sie die Paginierung beim Web-Scraping handhaben können.
endpoints = ["Gewinner", "Verlierer", "Indizes", "Aktivste", "Kryptowährungen"]
Schauen wir uns nun an, wie dies verwendet wird. Bei der herkömmlichen Paginierung würden Sie entweder einen Endpunkt oder einen Abfrageparameter haben, an den Sie eine Zahl übergeben. Bei diesem Scraper übergeben wir jedoch stattdessen den Endpunkt jeder Seite an unsere Basis-URL.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
Blockierungen vermeiden
Während unserer Tests sind wir auf keine Blockierungsprobleme gestoßen. Allerdings ist diese Welt nicht perfekt und es ist möglich, dass Sie in Zukunft auf solche Probleme stoßen. Es gibt eine Vielzahl von Taktiken, mit denen Sie Blockierungen umgehen können.
Gefälschte User Agents
Wenn Sie eine Anfrage an eine Website stellen (entweder mit einem Browser oder mit Python Requests), sendet Ihr HTTP-Client eine User-Agent-Zeichenfolge an den Server der Website. Diese wird verwendet, um die Anwendung zu identifizieren, die die Anfrage stellt. Um einen gefälschten User-Agent in Python festzulegen, erstellen wir eine User-Agent-Zeichenfolge. Diese fügen wir dann unseren Headern hinzu.
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
headers = {
"User-Agent": USER_AGENT
}
response = requests.get(f"https://google.com/finance/markets/{endpoint}", headers=headers)
Zeitgesteuerte Anfragen
Das Timing unserer Anfragen kann sehr viel bewirken. Wenn etwas 200 Seiten pro Minute anfordert, ist es wahrscheinlich kein Mensch. Um die Ratenbegrenzung zu umgehen und menschlicher zu wirken, können wir unseren Scraper anweisen, zwischen den Anfragen zu warten. Dadurch wirkt unsere Browsing-Aktivität viel normaler. Zunächst müssen Sie sleep aus time importieren.
from time import sleep
Als Nächstes schlafen Sie zwischen den Anfragen für eine beliebige Zeitspanne. Dadurch wird Ihr Scraper verlangsamt und wirkt menschlicher.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
sleep(5)
Erwägen Sie die Verwendung von Bright Data
Das Scraping des Internets kann sehr aufwendig sein. Bright Data ist einer der besten Anbieter von Datensätzen. Mit unseren Datensätzen ist das Scraping bereits erledigt und Sie verfügen bereits über die Berichte. Sie müssen sie nur noch herunterladen. Wir verstehen, dass Web-Scraping nicht für jeden geeignet ist und dass manche Leute einfach nur ihre Daten erhalten und verwenden möchten.
Wir haben keinen Google Finance-Datensatz, aber wir haben einen Yahoo Finance-Datensatz. Yahoo Finance bietet tatsächlich eine breitere Palette an Finanzdaten und kann Ihre Google Finance-Anforderungen problemlos erfüllen. Im Folgenden zeigen wir Ihnen, wie Sie diesen Datensatz erwerben können.
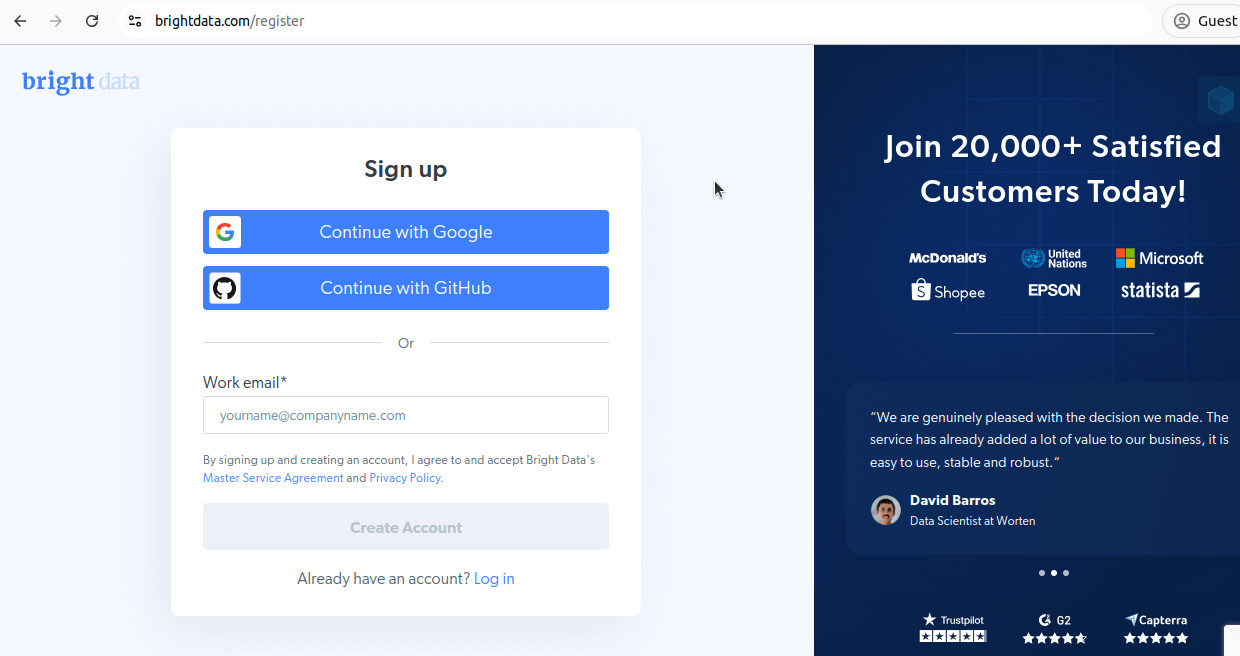
Ein Konto erstellen
Zunächst müssen Sie ein Konto erstellen. Gehen Sie dazu auf unsere Registrierungsseite und erstellen Sie ein Konto.
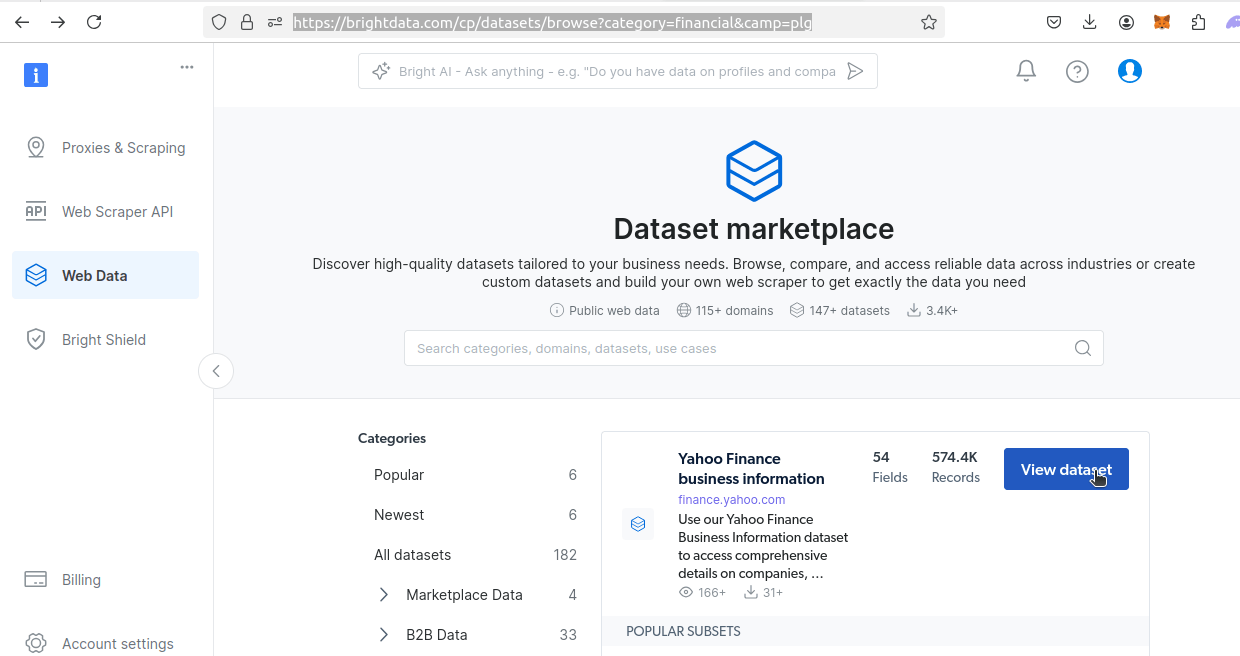
Herunterladen von Bright Data-Datensätzen
Gehen Sie als Nächstes zu unserer Seite mit Finanzdatensätzen. Suchen Sie den Datensatz von Yahoo Finance. Klicken Sie auf die Schaltfläche „Datensatz anzeigen ”.
Sobald Sie den Datensatz anzeigen, haben Sie mehrere Optionen. Sie können einen Beispieldatensatz herunterladen oder den Datensatz kaufen. Er kostet 0,0025 $ pro Datensatz, wobei der Mindestkaufpreis 500 $ beträgt. Wenn Sie den Datensatz möchten, klicken Sie auf „Weiter zum Kauf“ und durchlaufen Sie den Kaufvorgang.
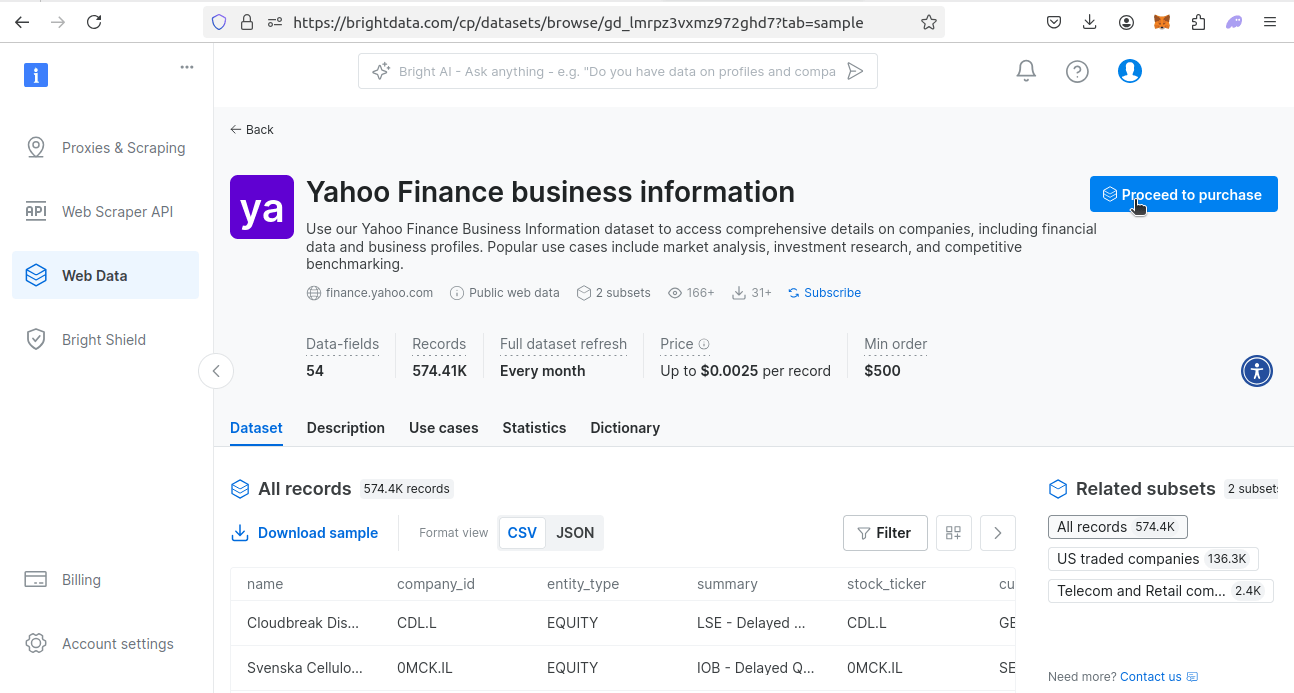
Mit unseren vorgefertigten Datensätzen ist das Scraping bereits für Sie erledigt. Sie erhalten einfach Ihre Daten und können mit Ihrem Tag weitermachen!
Fazit
Sie haben es geschafft! Aggregierte Daten sind ein sehr wertvolles Werkzeug für Menschen auf der ganzen Welt. Jetzt wissen Sie, wie Sie sie aus Google Finance scrapen können, und Sie wissen auch, wie Sie sie aus unserem Yahoo Finance-Datensatz erhalten können! Inzwischen sollten Sie wissen, wie Sie einen einfachen Scraper mit Python Requests und BeautifulSoup erstellen können. Sie sollten wissen, wie Sie die Methode find_all() beim Parsing von Seitenobjekten mit BeautifulSoup verwenden können.
Wir haben auch einige der fortgeschritteneren Methoden behandelt, wie z. B. den Umgang mit Paginierung mit Endpunkten und die Umgehung von Blockierungstechniken. Nutzen Sie dieses Wissen und erstellen Sie einen Scraper oder sparen Sie Zeit und Arbeit, indem Sie einen unserer gebrauchsfertigen Datensätze herunterladen.
Melden Sie sich jetzt an und starten Sie noch heute die Gratis-Testversion, einschließlich kostenloser Datensatz-Beispiele.






