

In diesem Leitfaden erfahren Sie mehr:
- Warum GPT Vision eine gute Wahl für Datenextraktionsaufgaben ist, die über traditionelle Parsing-Techniken hinausgehen.
- Wie man visuelles Web Scraping mit GPT Vision in Python durchführt.
- Die wichtigsten Einschränkungen dieses Ansatzes und wie man sie umgehen kann.
Lasst uns eintauchen!
Warum GPT Vision für Data Scraping verwenden?
GPT Vision ist ein multimodales KI-Modell, das sowohl Text als auch Bilder versteht. Diese Fähigkeiten sind in den neuesten OpenAI-Modellen verfügbar. Durch die Übergabe eines Bildes an GPT Vision können Sie visuelle Datenextraktion durchführen, ideal für Szenarien, in denen die traditionelle Datenanalyse versagt.
Beim regulären Parsen von Daten werden benutzerdefinierte Regeln geschrieben, um Daten aus Dokumenten abzurufen (z. B. CSS-Selektoren oder XPath-Ausdrücke, um Daten aus HTML-Seiten zu erhalten). Das Problem besteht nun darin, dass Informationen visuell in Bildern, Bannern oder komplexen UI-Elementen eingebettet sein können, auf die mit Standard-Parsing-Techniken nicht zugegriffen werden kann.
GPT Vision hilft Ihnen, Daten aus diesen schwer zugänglichen Quellen zu extrahieren. Die beiden häufigsten Anwendungsfälle sind:
- Visuelles Web Scraping: Extrahieren Sie Webinhalte direkt aus Screenshots von Seiten, ohne sich Gedanken über Seitenänderungen oder visuelle Elemente auf der Seite zu machen.
- Bildbasierte Dokumentenextraktion: Rufen Sie strukturierte Daten aus Screenshots oder Scans von lokalen Dateien wie Lebensläufen, Rechnungen, Speisekarten und Quittungen ab.
Einen nicht-visuellen Ansatz finden Sie in unserer Anleitung zum Web-Scraping mit ChatGPT.
Wie man mit GPT Vision in Python Daten aus Screenshots extrahiert
In diesem Abschnitt erfahren Sie Schritt für Schritt, wie Sie ein GPT Vision Web Scraping Skript erstellen. Im Einzelnen wird der Scraper diese Aufgaben automatisieren:
- Verwenden Sie Playwright, um eine Verbindung mit der Zielwebseite herzustellen.
- Machen Sie einen Screenshot des Bereichs, aus dem Sie Daten extrahieren möchten.
- Übergeben Sie das Bildschirmfoto an GPT Vision und fordern Sie es auf, strukturierte Daten zu extrahieren.
- Exportieren Sie die extrahierten Daten in eine JSON-Datei.
Das Ziel ist eine bestimmte Produktseite aus “Books to Scrape”:
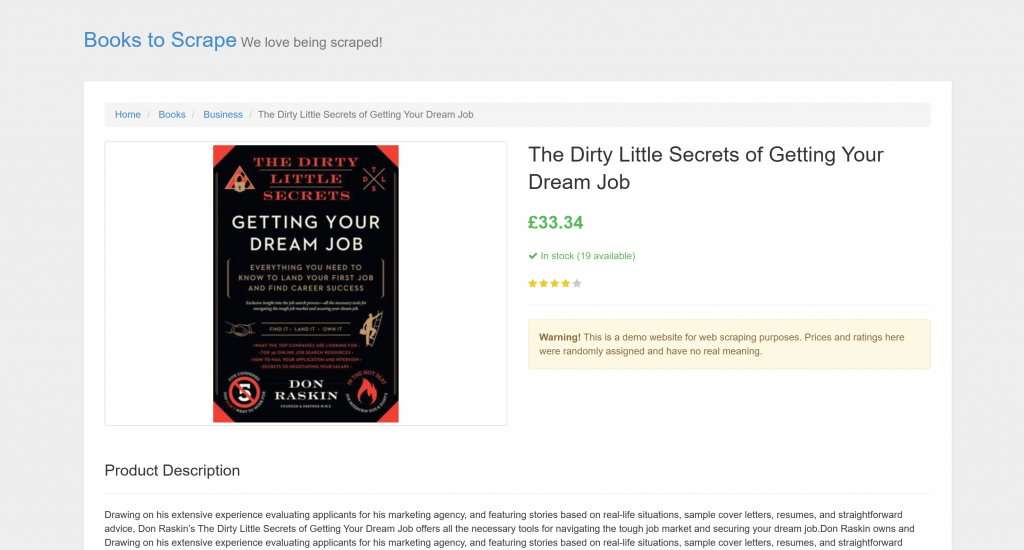
Diese Seite eignet sich perfekt für Tests, da sie automatische Scraping-Bots ausdrücklich willkommen heißt. Außerdem enthält sie visuelle Elemente wie das Sterne-Bewertungs-Widget, die mit herkömmlichen Parsing-Methoden nur schwer zu bewältigen sind.
Hinweis: Das Beispiel-Snippet wird der Einfachheit halber in Python geschrieben, da das OpenAI Python SDK weit verbreitet ist. Sie können jedoch die gleichen Ergebnisse mit dem JavaScript OpenAI SDK oder einer anderen unterstützten Sprache erzielen.
Führen Sie die folgenden Schritte aus, um zu erfahren, wie Sie mit GPT Vision Webdaten scrapen können!
Voraussetzungen
Bevor Sie beginnen, vergewissern Sie sich, dass Sie alles haben:
- Python 3.8 oder höher muss auf Ihrem Rechner installiert sein.
- Ein OpenAI API-Schlüssel für den Zugriff auf die GPT Vision API.
Um Ihren OpenAI-API-Schlüssel zu erhalten, folgen Sie der offiziellen Anleitung.
Auch das folgende Hintergrundwissen wird Ihnen helfen, diesen Artikel optimal zu nutzen:
- Grundlegende Kenntnisse der Browser-Automatisierung, insbesondere mit Playwright.
- Vertrautheit mit der Funktionsweise von GPT Vision.
Hinweis: Für diesen Ansatz ist ein Browser-Automatisierungstool wie Playwright erforderlich. Der Grund dafür ist, dass Sie die Zielseite in einem Browser rendern müssen. Sobald die Seite geladen ist, können Sie dann einen Screenshot des gewünschten Abschnitts machen. Dies kann mit der Playwright-Screenshots-API erfolgen.
Schritt #1: Erstellen Sie Ihr Python-Projekt
Führen Sie den folgenden Befehl in Ihrem Terminal aus, um einen neuen Ordner für Ihr Scraping-Projekt zu erstellen:
mkdir gpt-vision-scrapergpt-vision-scraper/ wird als Hauptprojektordner für die Erstellung Ihres Web Scrapers mit GPT Vision dienen.
Navigieren Sie in den Ordner und erstellen Sie darin eine virtuelle Python-Umgebung:
cd gpt-vision-scraper
python -m venv venvÖffnen Sie den Projektordner in Ihrer bevorzugten Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition ist ausreichend.
Erstellen Sie innerhalb des Projektordners eine scraper.py-Datei:
gpt-vision-scraper
├─── venv/
└─── scraper.py # <------------Zu diesem Zeitpunkt ist scraper.py nur eine leere Datei. Bald wird sie die Logik für visuelles LLM-Web-Scraping über GPT Vision enthalten.
Als Nächstes aktivieren Sie die virtuelle Umgebung in Ihrem Terminal. Unter Linux oder macOS starten Sie:
source venv/bin/activateUnter Windows können Sie die gleiche Funktion ausführen:
venv/Scripts/activateKlasse! Ihre Python-Umgebung ist nun bereit für visuelles Scraping mit GPT Vision.
Hinweis: In den folgenden Schritten wird Ihnen gezeigt, wie Sie die erforderlichen Abhängigkeiten installieren. Wenn Sie sie alle auf einmal installieren möchten, führen Sie diesen Befehl aus:
pip install playwright openaiDann:
python -m playwright installGroßartig! Ihre Python-Umgebung ist nun eingerichtet.
Schritt 2: Verbinden mit der Zielsite
Zunächst müssen Sie Playwright anweisen, die Zielsite mit einem kontrollierten Browser zu besuchen. Installieren Sie in Ihrer aktivierten virtuellen Umgebung Playwright mit:
pip install playwright Schließen Sie dann die Installation ab, indem Sie die erforderlichen Browser-Binärdateien herunterladen:
python -m playwright installAls nächstes importieren Sie Playwright in Ihr Skript und verwenden die Funktion goto(), um zur Zielseite zu navigieren:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Screenshotting logic...
# Close the browser and release its resources
browser.close()Wenn Sie mit dieser API nicht vertraut sind, lesen Sie unseren Artikel über Web Scraping mit Playwright.
Großartig! Sie haben jetzt ein Playwright-Skript, das sich erfolgreich mit der Zielseite verbindet. Es ist Zeit, einen Screenshot davon zu machen.
Schritt #3: Machen Sie einen Screenshot der Seite
Bevor Sie die Logik für die Aufnahme eines Screenshots schreiben, sollten Sie bedenken, dass OpenAI Gebühren auf Basis der Token-Nutzung erhebt. Mit anderen Worten: Je größer Ihr Eingabe-Screenshot ist, desto mehr werden Sie ausgeben.
Um die Kosten gering zu halten, ist es am besten, den Screenshot auf die HTML-Elemente zu beschränken, die die Daten enthalten, die Sie interessieren. Das ist möglich, da Playwright knotenbasierte Screenshots unterstützt. Ein eingeschränkter Screenshot hilft GPT Vision außerdem, sich auf relevante Inhalte zu konzentrieren, was das Risiko von Halluzinationen verringert.
Beginnen Sie damit, die Zielseite in Ihrem Browser zu öffnen und sich mit ihrer Struktur vertraut zu machen. Klicken Sie dann mit der rechten Maustaste auf den Inhalt und wählen Sie “Inspect”, um die DevTools des Browsers zu öffnen:
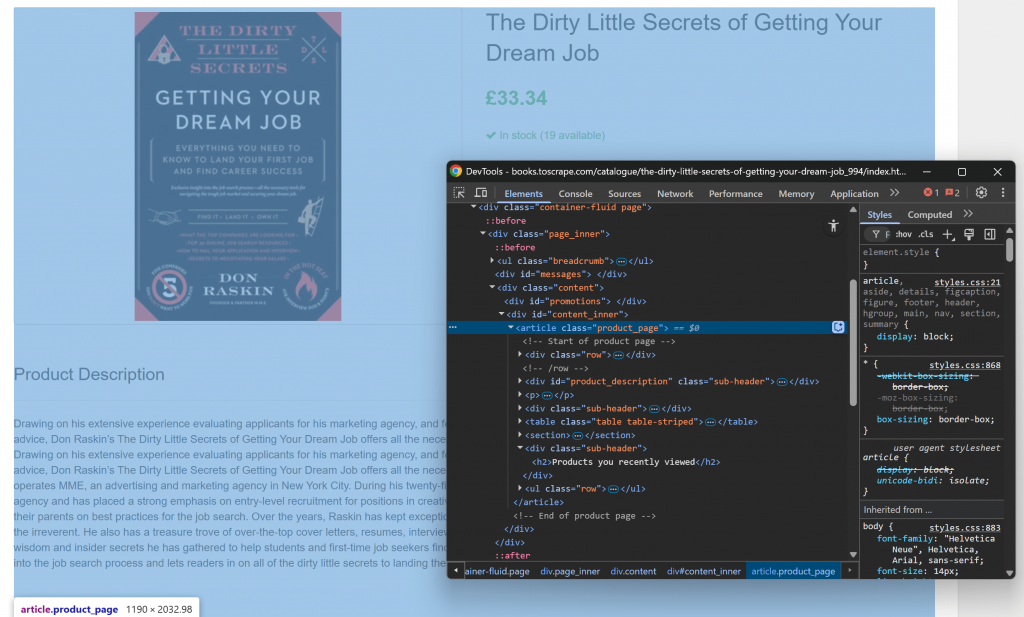
Sie werden feststellen, dass der Großteil des relevanten Inhalts im HTML-Element .product_page enthalten ist.
Da dieses Element dynamisch geladen oder mit JavaScript aufgedeckt werden kann, sollten Sie darauf warten, bevor Sie es erfassen:
product_page_element = page.locator(".product_page")
product_page_element.wait_for()Standardmäßig wartet wait_for() bis zu 30 Sekunden, bis das Element im DOM erscheint. Dieser Mikroschritt ist von grundlegender Bedeutung, da Sie keinen leeren oder unsichtbaren Abschnitt fotografieren möchten.
Verwenden Sie nun die Methode screenshot() für den ausgewählten Locator, um einen Screenshot nur von diesem Element zu machen:
product_page_element.screenshot(path=SCREENSHOT_PATH)Hier ist SCREENSHOT_PATH eine Variable, die den Namen der Ausgabedatei enthält, z. B.:
SCREENSHOT_PATH = "product_page.png"Es ist eine gute Idee, diese Informationen in einer Variablen zu speichern, da Sie sie bald wieder benötigen werden.
Wenn Sie das Skript starten, erzeugt es eine Datei mit dem Namen product_page.png, die Folgendes enthält:
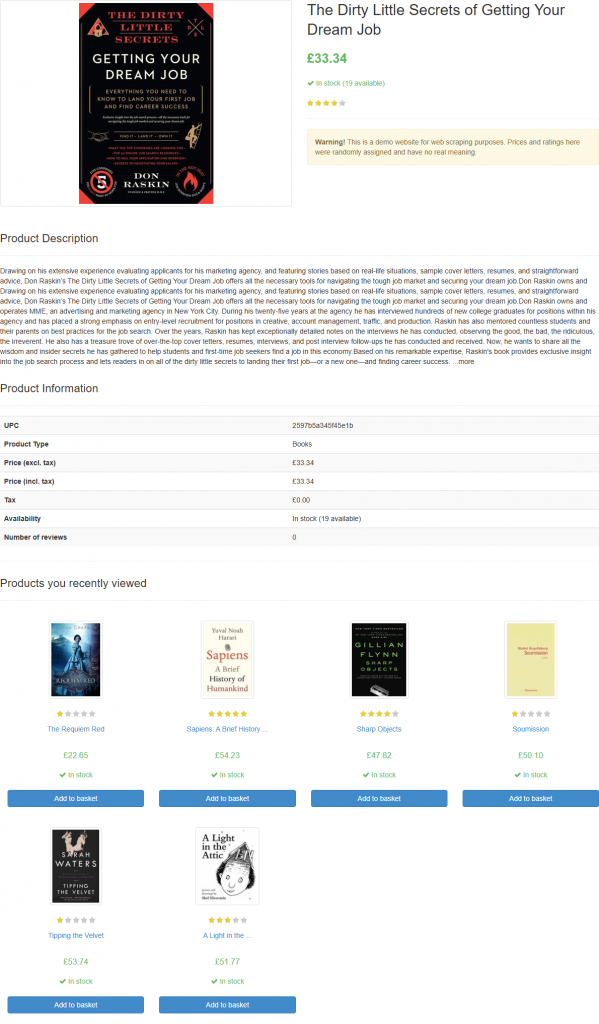
Hinweis: Es empfiehlt sich, den Screenshot in einer Datei zu speichern, da Sie ihn später möglicherweise mit anderen Techniken oder Modellen erneut analysieren möchten.
Fantastisch! Der Teil mit den Bildschirmfotos ist vorbei.
Schritt #4: OpenAI in Python konfigurieren
Um GPT Vision für Web Scraping einzusetzen, können Sie das OpenAI Python SDK verwenden. Installieren Sie mit Ihrer aktivierten virtuellen Umgebung das openai-Paket:
pip install openaiAls nächstes importieren Sie den OpenAI-Client in scraper.py:
from openai import OpenAIFahren Sie mit der Initialisierung einer OpenAI-Client-Instanz fort:
client = OpenAI()Dies ermöglicht Ihnen eine einfachere Verbindung zur OpenAI API, einschließlich Vision APIs. Standardmäßig sucht der OpenAI() -Konstruktor nach Ihrem API-Schlüssel in der Umgebungsvariablen OPENAI_API_KEY. Die Einstellung dieser Umgebungsvariable ist der empfohlene Weg, um die Authentifizierung sicher zu konfigurieren.
Für Entwicklungs- oder Testzwecke können Sie den Schlüssel alternativ auch direkt in den Code einfügen:
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)Ersetzen Sie den Platzhalter durch Ihren tatsächlichen OpenAI-API-Schlüssel.
Wunderbar! Ihre OpenAI-Einrichtung ist nun abgeschlossen und Sie sind bereit, GPT Vision für Web Scraping zu verwenden.
Schritt #5: Senden Sie die GPT Vision Scraping-Anfrage
GPT Vision akzeptiert Eingabebilder in verschiedenen Formaten, einschließlich öffentlicher Bild-URLs. Da Sie mit einer lokalen Datei arbeiten, müssen Sie das Bild an den OpenAI-Server senden, indem Sie es in einen Base64-kodierten String konvertieren.
Um Ihre Screenshot-Datei in Base64 zu konvertieren, schreiben Sie den folgenden Code:
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8") Dies erfordert diesen Import aus der Python-Standardbibliothek:
import base64Übergeben Sie nun das kodierte Bild an GPT Vision für visuelles Web Scraping:
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)Hinweis: Im obigen Beispiel wird das Modell gpt-4.1 verwendet, aber Sie können jedes OpenAI-Modell verwenden , das visuelle Fähigkeiten unterstützt.
Beachten Sie, dass GPT Vision direkt in die Antwort-API integriert ist. Das bedeutet, dass Sie nichts Besonderes konfigurieren müssen. Fügen Sie einfach Ihr Base64-Bild mit "type" ein : "input_image" ein, und schon können Sie loslegen.
Die oben verwendete Aufforderung zum Scrapen lautet:
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.Möglicherweise kennen Sie die genaue Struktur der Zielseite nicht, so dass Sie die Aufforderung recht allgemein halten sollten (aber dennoch auf das Ziel ausgerichtet). Hier haben wir das Modell ausdrücklich angewiesen, Abschnitte zu ignorieren, an denen wir nicht interessiert sind. Außerdem haben wir es gebeten, ein JSON-Objekt mit sauberen, gut strukturierten Schlüsselnamen zurückzugeben.
Beachten Sie, dass die OpenAI Responses API-Anfrage so konfiguriert ist, dass sie im JSON-Modus arbeitet. Auf diese Weise können Sie sicherstellen, dass das Modell eine Ausgabe im JSON-Foramt erzeugt. Damit diese Funktion funktioniert, muss Ihre Eingabeaufforderung eine Anweisung zur Rückgabe von Daten im JSON-Format enthalten:
Return the data in JSON format using lowercase snake_case attribute names.Andernfalls scheitert die Anfrage mit:
openai.BadRequestError: Error code: 400 - {
'error': {
'message': "Response input messages must contain the word 'json' in some form to use 'text.format' of type 'json_object'.",
'type': 'invalid_request_error',
'param': 'input',
'code': None
}
}Sobald die Anfrage erfolgreich abgeschlossen ist, können Sie auf die geparsten strukturierten Daten zugreifen:
json_product_data = response.output_textOptional kann die resultierende Zeichenkette geparst werden, um sie in ein Python-Wörterbuch zu konvertieren:
import json
product_data = json.loads(json_product_data)Die GPT Vision-Datenanalyselogik ist abgeschlossen! Es bleibt nur noch, die gescrapten Daten in eine lokale JSON-Datei zu exportieren.
Schritt #6: Exportieren Sie die gescrapten Daten
Schreiben Sie den vom GPT Vision API-Aufruf erzeugten JSON-String mit:
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)Dadurch wird eine Datei product.json erstellt, in der die visuell extrahierten Daten gespeichert werden.
Gut gemacht! Ihr mit GPT Vision betriebener Web Scraper ist jetzt fertig.
Schritt #7: Alles zusammenfügen
Nachfolgend finden Sie den endgültigen Code von scraper.py:
from playwright.sync_api import sync_playwright
from openai import OpenAI
import base64
# Where to store the page screenshot
SCREENSHOT_PATH = "product_page.png"
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Wait for the product page element to be on the DOM
product_page_element = page.locator(".product_page")
product_page_element.wait_for()
# Take a full screenshot of the element
product_page_element.screenshot(path=SCREENSHOT_PATH)
# Close the browser and release its resources
browser.close()
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot from the filesystem
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the data extraction request via GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)
# Extract the output data and export it to a JSON file
json_product_data = response.output_text
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)Wahnsinn! In weniger als 65 Zeilen Code haben Sie gerade visuelles Web Scraping mit GPT Vision durchgeführt.
Führen Sie den GPT Vision Scraper mit aus:
python scraper.pyDas Skript braucht eine Weile und schreibt dann eine Datei product.json in den Ordner Ihres Projekts. Öffnen Sie sie, und Sie sollten sehen:
{
"title": "The Dirty Little Secrets of Getting Your Dream Job",
"price_gbp": "£33.34",
"availability": "In stock (19 available)",
"rating": "4/5",
"description": "Drawing on his extensive experience evaluating applicants for his marketing agency, and featuring stories based on real-life situations, sample cover letters, resumes, and straightforward advice, Don Raskin’s The Dirty Little Secrets of Getting Your Dream Job offers all the necessary tools for navigating the tough job market and securing your dream job... [omitted for brevity]",
"product_information": {
"upc": "2597b5a345f45e1b",
"product_type": "Books",
"price_excl_tax": "£33.34",
"price_incl_tax": "£33.34",
"tax": "£0.00",
"availability": "In stock (19 available)"
}
}Beachten Sie, wie erfolgreich alle Produktinformationen auf der Seite, einschließlich der Bewertung, aus dem rein visuellen Element extrahiert wurden:
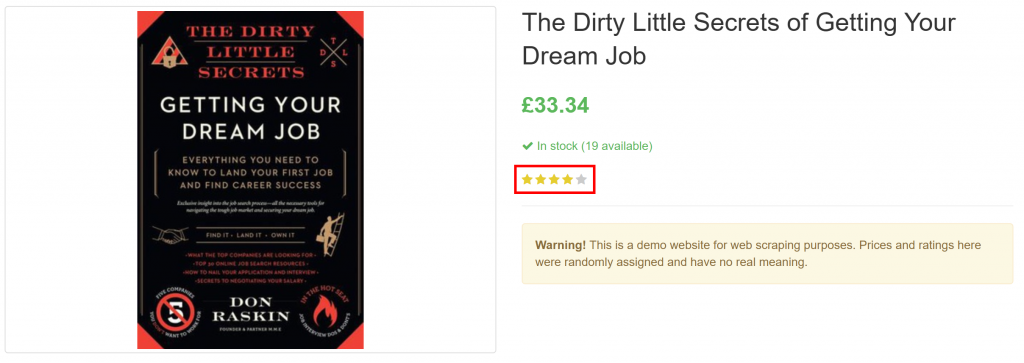
Et voilà! GPT Vision war in der Lage, einen Screenshot in eine sauber strukturierte JSON-Datei umzuwandeln.
Nächste Schritte
Um Ihren GPT Vision Scraper zu verbessern, sollten Sie die folgenden Optimierungen in Betracht ziehen:
- Machen Sie es wiederverwendbar: Überarbeiten Sie das Skript so, dass es die Ziel-URL, den CSS-Selektor des Elements, auf das gewartet werden soll, und die LLM-Eingabeaufforderung aus der CLI akzeptiert. Auf diese Weise können Sie verschiedene Seiten scrapen, ohne den Code zu ändern.
- Sichern Sie Ihren API-Schlüssel: Anstatt Ihren OpenAI-API-Schlüssel fest zu kodieren, speichern Sie ihn in einer
.env-Dateiund laden Sie sie mit dem Paketpython-dotenv. Alternativ können Sie ihn auch als globale Umgebungsvariable namensOPENAI_API_KEYfestlegen. Beide Methoden helfen, Ihre Anmeldedaten zu schützen und Ihre Codebasis sicher zu halten.
Überwindung der größten Einschränkung des visuellen Web Scraping
Die größte Herausforderung bei diesem Web-Scraping-Ansatz liegt im Schritt des Screenshotings. Während es auf einer Sandbox-Site wie “Books to Scrape” einwandfrei funktionierte, sieht die Realität auf echten Websites anders aus.
Viele moderne Websites setzen Anti-Scraping-Maßnahmen ein, die Ihr Skript blockieren können , bevor Sie die Seite aufrufen können. Selbst wenn Ihr Scraper erfolgreich auf die Seite zugreift, kann es sein, dass Sie eine Fehlermeldung oder eine menschliche Überprüfungsanfrage erhalten. Das passiert zum Beispiel bei der Verwendung von Vanilla Playwright auf Websites wie G2.com:

Diese Probleme können durch Browser-Fingerprinting, IP-Reputation, Ratenbegrenzung, CAPTCHA-Herausforderungen und vieles mehr verursacht werden.
Die robusteste Art, solche Sperren zu umgehen, ist die Verwendung einer speziellen Web Unlocking API!
Der Web Unlocker von Bright Data ist ein leistungsstarker Scraping-Endpunkt, der von einem Proxy-Netzwerk mit über 150 Millionen IPs unterstützt wird. Er bietet insbesondere Fingerprint-Spoofing, JavaScript-Rendering, CAPTCHA-Lösungsfunktionen und viele andere Funktionen. Es unterstützt sogar die Erfassung von Screenshots, was bedeutet, dass Sie die manuelle Playwright-Screenshotting-Logik komplett überspringen können.
Angenommen, Sie möchten die durchschnittliche Sternebewertung von der G2-Verkäuferseite von Bright Data extrahieren:
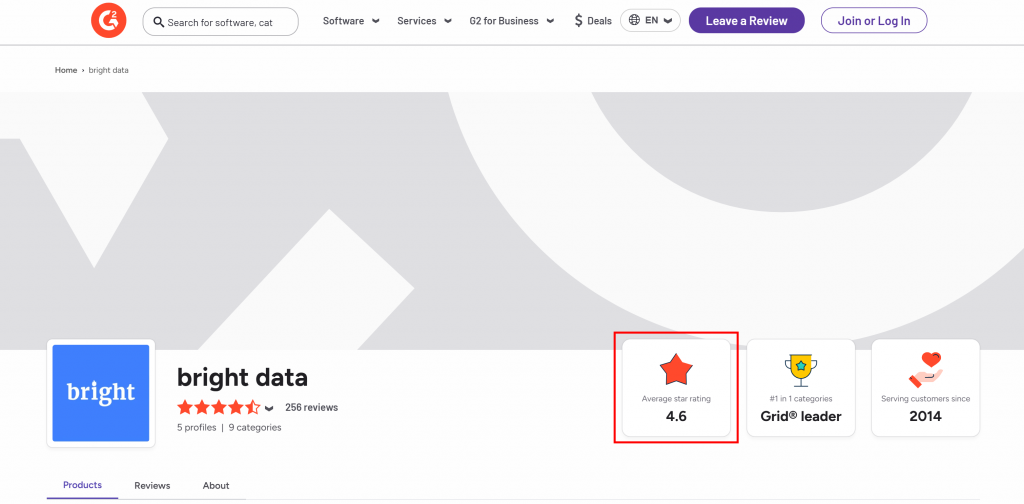
Um loszulegen, richten Sie Web Unlocker wie in der Dokumentation beschrieben ein und rufen Sie Ihren Bright Data API-Schlüssel ab. Verwenden Sie GPT Vision zusammen mit Web Unlocker wie folgt:
# pip install requests
import requests
from openai import OpenAI
import base64
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
# Get a screenshot of the target page using Bright Data Web Unlocker
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": "web_unlocker", # Replace with your Web Unlocker zone name
"url": "https://www.g2.com/sellers/bright-data", # Your target page
"format": "raw",
"data_format": "screenshot" # Enable the screenshotting mode
}
response = requests.post(url, headers=headers, json=payload)
# Where to store the scraped screenshot
SCREENSHOT_PATH = "screenshot.png"
# Save the screenshot to a file (e.g., for further analysis in the future)
with open(SCREENSHOT_PATH, "wb") as f:
f.write(response.content)
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot file and convert its contents to Base64
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the scraping request using GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Return the average star rating from the following image.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
)
print(response.output_text)Führen Sie das obige Skript aus, und es wird eine Ausgabe wie folgt erzeugt:
The average star rating from the image is 4.6.Diese Informationen sind korrekt, wie Sie in der von Web Unlocker generierten screenshot.png Datei sehen können:
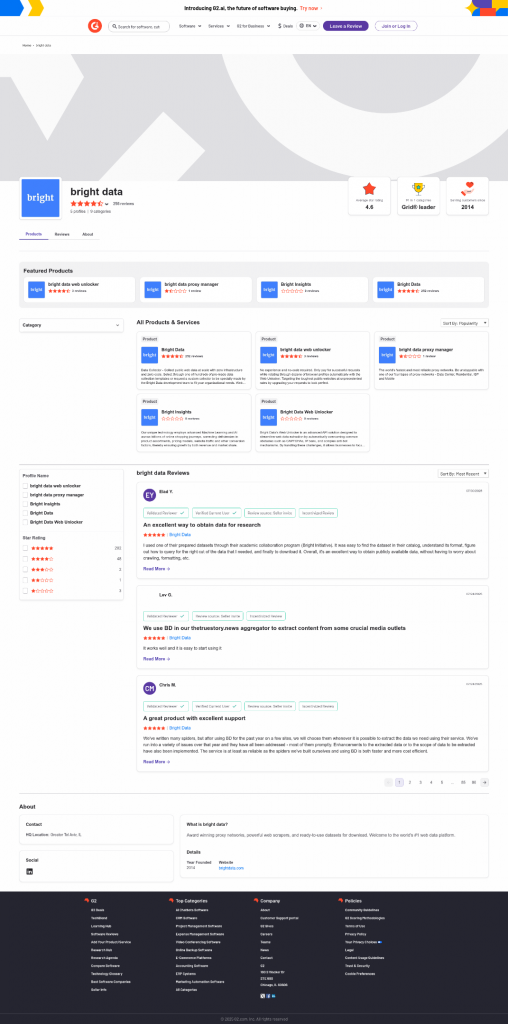
Beachten Sie, dass Sie Web Unlocker verwenden können, um den vollständig freigeschalteten HTML-Code der Seite abzurufen oder sogar den Inhalt in einem AI-optimierten Markdown-Format zu erhalten.
Und einfach so – keine Blockaden mehr, keine Kopfschmerzen mehr. Sie haben jetzt einen produktionsreifen, von GPT Vision betriebenen Web Scraper, der sogar auf geschützten Websites funktioniert.
Sehen Sie, wie das OpenAI SDK und der Web Unlocker in einem komplexeren Scraping-Szenario zusammenarbeiten.
Schlussfolgerung
In diesem Tutorial haben Sie gelernt, wie Sie GPT Vision mit den Screenshot-Funktionen von Playwright kombinieren, um einen KI-gestützten Web Scraper zu erstellen. Die größte Herausforderung (d. h. die Blockierung beim Erstellen von Screenshots) wurde mit der Bright Data Web Unlocker API gelöst.
Wie bereits erwähnt, ermöglicht die Kombination von GPT Vision mit der Screenshot-Funktionalität der Web Unlocker API die visuelle Extraktion von Daten aus beliebigen Websites. Und das alles, ohne eigenen Parsing-Code zu schreiben. Dies ist nur eines der vielen Szenarien, die von den KI-Produkten und -Services von Bright Data abgedeckt werden.
Erstellen Sie ein kostenloses Bright Data-Konto und experimentieren Sie mit unseren Datenlösungen!




