

In diesem Leitfaden zu XPath vs. CSS-Selektor erfahren Sie:
- Was XPath-Ausdrücke sind, wie sie funktionieren und welche Vor- und Nachteile sie haben.
- Was CSS-Selektoren sind, wie sie funktionieren und welche Vor- und Nachteile sie haben.
- Wie XPath-Ausdrücke und CSS-Selektoren in Bezug auf Leistung, Einfachheit und Anwendungsfälle im Vergleich abschneiden.
Los geht’s!
XPath: Vollständige Analyse
Beginnen wir diesen Leitfaden zum Vergleich zwischen XPath und CSS-Selektoren mit dem ersten Element des Vergleichs, XPath.
Definition
XPath, kurz für XML Path Language, ist eine Abfragesprache zum Navigieren und Abfragen des DOM. Insbesondere bietet es eine leistungsstarke Möglichkeit, Informationen in XML-/HTML-Dokumenten zu finden und zu extrahieren.
XPath hat eine Syntax, die der eines Dateisystems ähnelt und sich auf Ausdrücke stützt, um Knoten im XML/HTML-Baum zu finden. Ein XPath-Ausdruck definiert den Pfad zu bestimmten Elementen und Attributen innerhalb der hierarchischen Struktur des Dokuments.
Syntax
Nachfolgend finden Sie eine Aufschlüsselung der wichtigsten Komponenten der XPath-Syntax:
/: Um mit der Auswahl von Knoten aus dem Stammknoten zu beginnen.//: Um Knoten im Dokument aus dem aktuellen Knoten auszuwählen, die der Auswahl entsprechen, unabhängig von ihrer Position..:Zum Auswählen des aktuellen Knotens...: Zum Auswählen des übergeordneten Knotens des aktuellen Knotens.@: Zum Auswählen von Knotenattributen.element: Um Knoten basierend auf einem bestimmten Tag (z. B.div) auszuwählen.[Bedingung]: Um Knoten basierend auf einer bestimmten Bedingung auszuwählen (z. B.[@type="submit"]).function(): Um eine bestimmte XPath-Funktion auf den Ausdruck anzuwenden (z. B. gibttext()den Textinhalt des ausgewählten Knotens zurück).
Einige Beispiele zum besseren Verständnis der XPath-Syntax sind:
//a: Wählt alle<a>-Elemente im Dokument aus.//ul/li: Wählt alle<li>-Elemente aus, die Kinder von<ul>-Elementen sind.//ul/..: Wählt alle übergeordneten Knoten von<ul>-Elementen aus.//ul/li[@category='fiction']: Wählt alle<il>-Elemente unter<ul>-Tags mit einemKategorieattributaus,das gleich„fiction”ist.//title[@lang='en']: Wählt alle<title>-Elemente mit einemlang-Attributgleich'en'an beliebiger Stelle im Dokument aus.- //title/text(): Ruft den Textinhalt aller
<title>-Elemente im Dokument ab. //div[contains(@class, 'post')]/following-sibling::div[1]: Wählt das erste<div>-Element aus, das ein Geschwisterelement jedes<div>-Elements ist,das die Klasse„post”enthält.
Beachten Sie, dass XPath-Ausdrücke auch boolesche und arithmetische Operatoren unterstützen, um mehrere Funktionen und Bedingungen zu kombinieren.
Vorteile
- Hohe Vielseitigkeit: Sie können sowohl XML- als auch HTML-Strukturen durchsuchen und so Elemente, Attribute und Textknoten präzise ansteuern. Außerdem werden sowohl die Vorwärts- als auch die Rückwärtstraversierung des DOM sowie die Auswahl von übergeordneten und gleichrangigen Knoten unterstützt.
- Viele Funktionen und Operatoren: Es verfügt über eine Vielzahl integrierter Funktionen (z. B.
contains(),concat(),count()usw.) und Operatoren (z. B.+,or,andusw.) zum Bearbeiten und Vergleichen von Daten in XML-/HTML-Dokumenten. - Unterstützung für absolute und relative Pfade: XPath-Ausdrücke beschreiben den Pfad zu den gewünschten Knoten vom Stamm des Dokuments (absolute Pfade) oder von einem bestimmten Element (relative Pfade).
- Unterstützung für die Auswahl von Textknoten: Es ermöglicht die direkte Auswahl von Textknoten und eröffnet damit die Möglichkeit, Textinhalte aus XML-/HTML-Dokumenten zu extrahieren, ohne dass ein zusätzliches Parsing erforderlich ist.
- Plattformunabhängigkeit: Es ist nicht an eine bestimmte Programmiersprache oder Plattform gebunden und unterstützt eine Vielzahl von Umgebungen, Bibliotheken, Browsern und Betriebssystemen.
Nachteile
- Komplizierte und lange Syntax: Die Syntax von XPath kann insbesondere für Anfänger eine Herausforderung darstellen. Das Schreiben des Pfads zu einem bestimmten Knoten, der tief im DOM verschachtelt ist, kann zu einem langen Ausdruck führen, der möglicherweise einige Funktionen und Operatoren enthält. Dies kann XPath-Ausdrücke fehleranfällig und schwer zu debuggen machen.
- Begrenzte Unterstützung und Popularität: Nicht alle HTML-Parsing-Bibliotheken unterstützen XPath. Das liegt daran, dass CSS-Selektoren unter Webentwicklern viel beliebter sind und Bibliotheken sich in der Regel auf diese konzentrieren. Außerdem basieren die meisten XPath-basierten Bibliotheken wie HtmlAgilityPack immer noch auf XPath 1.0, das 1999 veröffentlicht wurde. Die aktuelle Version ist XPath 3.1, veröffentlicht im Jahr 2017. Lesen Sie unseren Leitfaden zu HtmlAgilityPack, um ein Experte für Web-Scraping mit C# zu werden.
Tipps und Tricks
Mit Chrome können Sie XPath-Ausdrücke direkt im Browser testen und abrufen.
Angenommen, Sie möchten ein bestimmtes Element auf einer Webseite auswählen. Rufen Sie diese in Chrome auf, klicken Sie mit der rechten Maustaste auf den gewünschten Knoten und wählen Sie „Untersuchen:”.
Klicken Sie mit der rechten Maustaste auf das gewünschte DOM-Element und wählen Sie „Kopieren > XPath kopieren”, um einen XPath-Ausdruck dafür zu erhalten. Im obigen Beispiel erhalten Sie:
//*[@id="site-content"]/section[1]/div/div/div[1]/div[4]/a[1]
Hinweis: Dies ist nützlich, um eine Vorstellung davon zu bekommen, wie man eine effektive XPath-Auswahlstrategie entwickelt. Gleichzeitig sind automatisch generierte XPath-Ausdrücke oft zu lang und zu implementierungsorientiert. Daher können Sie sich in der Produktion nicht auf sie verlassen.
Nun möchten Sie einen XPath-Ausdruck auf der Seite testen. In Chrome gibt es zwei Möglichkeiten, dies zu tun.
Fügen Sie zunächst den XPath-Ausdruck in die Suchleiste des Abschnitts „Elemente” von DevTools ein, den Sie mit STRG/Befehl + F aktivieren können:
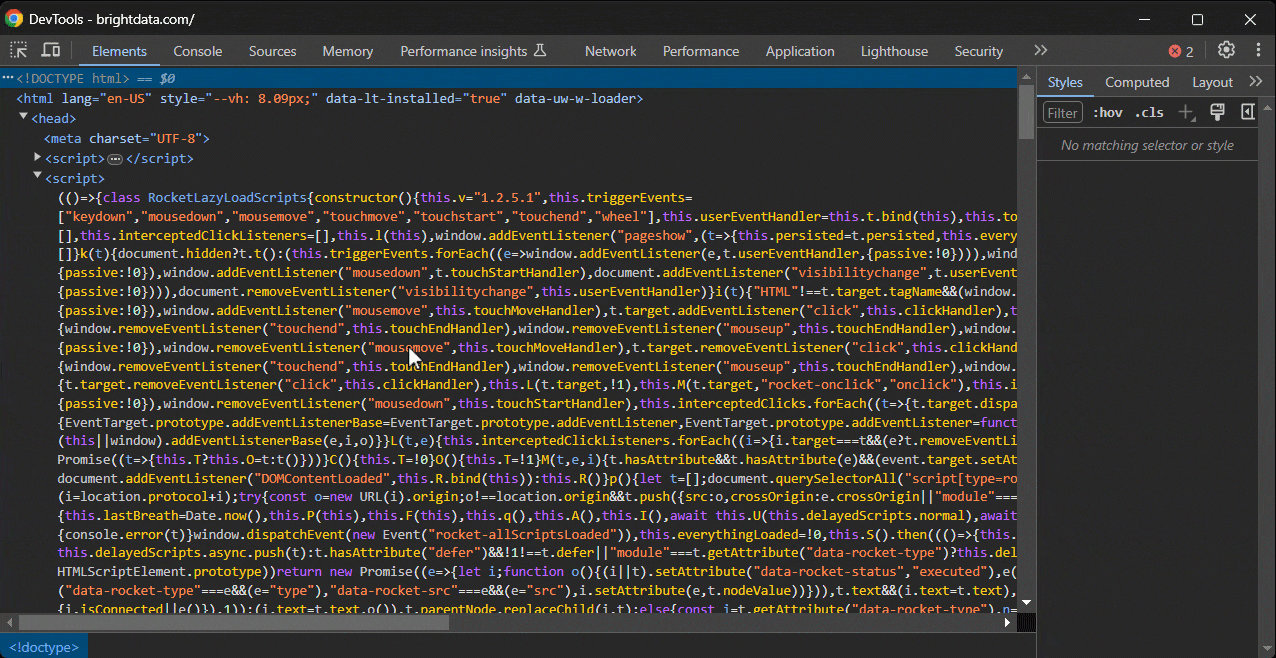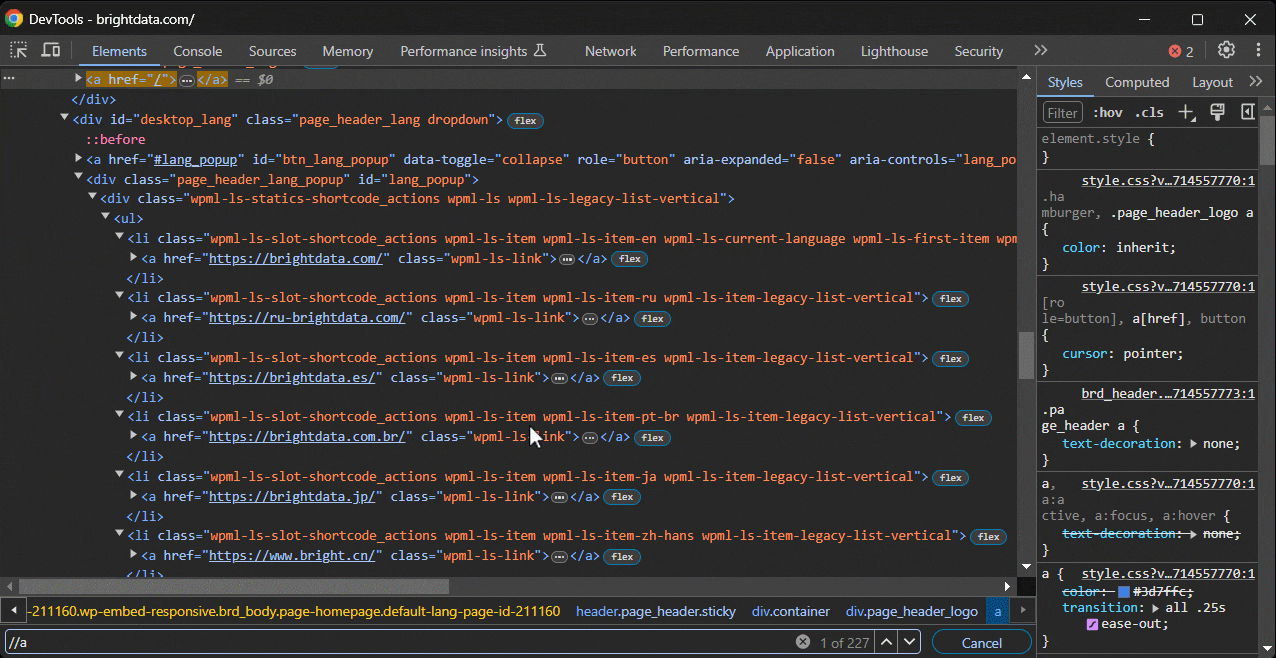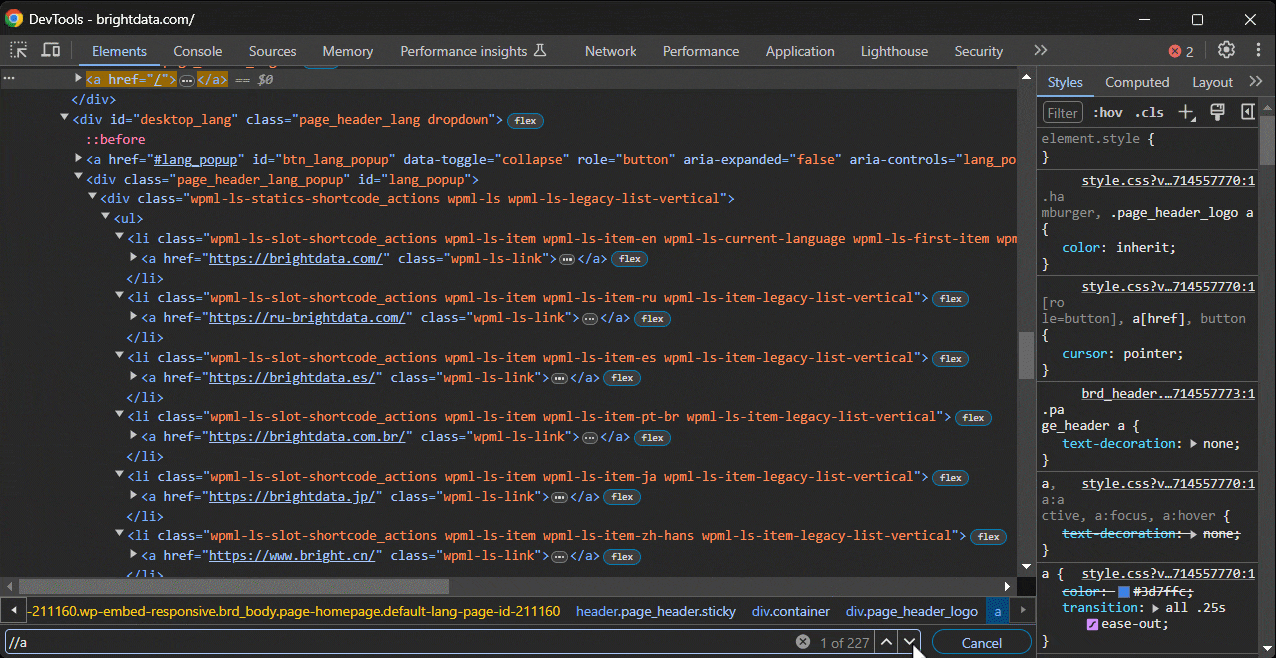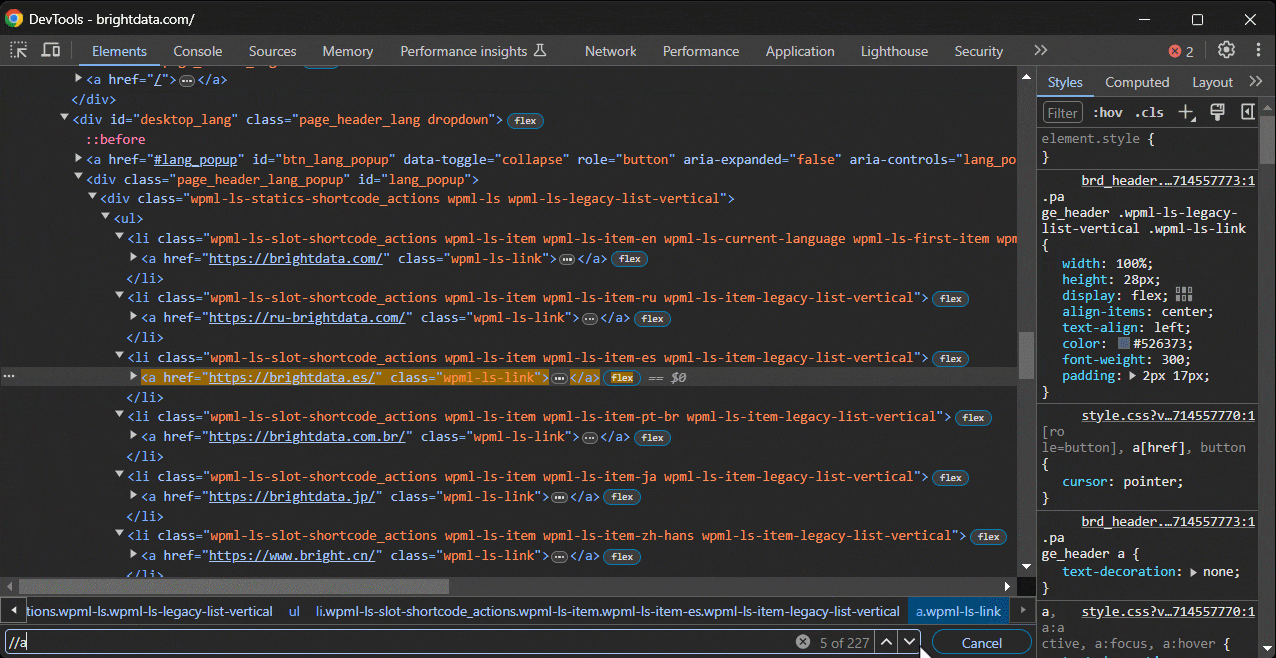
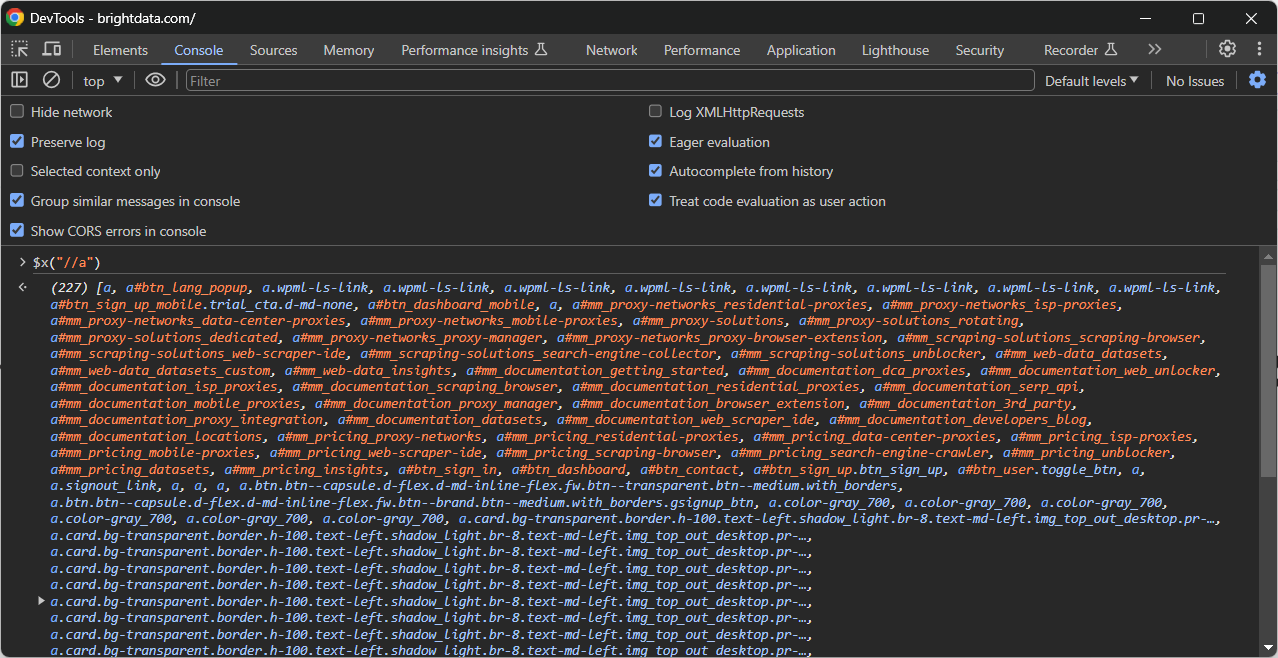
Zweitens können Sie ihn in der Konsole mit der speziellen Funktion $x() aufrufen:
CSS-Selektoren: Ausführliche Überprüfung
Setzen Sie diesen Artikel zum Vergleich zwischen XPath und CSS-Selektoren fort, indem Sie sich mit dem zweiten Element des Vergleichs, den CSS-Selektoren, befassen.
Definition
Mit CSS-Selektoren können Sie HTML-Elemente innerhalb einer Webseite auswählen. Sie sind Teil von CSS und werden verwendet, um HTML-Elemente auf Webseiten anzusprechen. Ebenso unterstützen Headless-Browser-Tools und HTML-Parsing-Bibliotheken sie als Möglichkeit, Knoten im DOM auszuwählen.
Ein CSS-Selektor kann einzelne Elemente oder Gruppen von Elementen anhand ihrer ID, Klasse, Attribute und Position in der Dokumentenstruktur ansprechen. CSS-Selektoren spielen zwar eine entscheidende Rolle bei der Anwendung von Stilen und Formatierungen auf Webseiten, sind aber auch ein hervorragendes Werkzeug für das Web-Scraping.
Syntax
Die Syntax von CSS-Selektoren lässt sich am besten anhand einiger Beispiele erklären:
- Element-Selektor: Zum Ansprechen von Elementen anhand ihres Tag-Namens. Beispielsweise wählt
palle<p>-Elemente im DOM aus. - Klassenselektor: Zum Auswählen von Elementen mit einem bestimmten Klassenattribut. Beispielsweise wählt
.highlightalle Elemente mit dem HTML-Attributclass="highlight <other_classes>"aus. - ID-Selektor: Zum Ansprechen eines bestimmten Elements anhand seines ID-Attributs. Beispielsweise wählt
#navbardas Element mitid="navbar"aus. - Attributselektor: Zum Auswählen von Elementen anhand ihrer Attribute. Beispielsweise wählt
input[type="text"]alle<input>-Elemente mit dem Attributtype="text"aus. - Nachkommen-Selektor: Zum Auswählen von Elementen, die Nachkommen eines anderen Elements sind. Beispielsweise wählt
div aalle<a>-Elemente aus, die Nachkommen von<div>-Elementen sind. - Kindselektor: Zum Ansprechen von Elementen, die direkte Kinder eines anderen Elements sind. Beispielsweise wählt
ul > lialle<li>-Elemente aus, die direkte Kinder von<ul>-Elementen sind. - Adjacent Sibling Selector: Zum Auswählen eines Elements, dem unmittelbar ein bestimmtes Geschwisterelement vorausgeht. Beispielsweise wählt
h2 + pdas<p>-Element aus, das unmittelbar auf ein<h2>-Element folgt.
Beachten Sie, dass verschiedene Browser unterschiedliche Implementierungen des CSS-Standards bieten. Informationen zur Kompatibilität eines bestimmten CSS-Operators oder einer bestimmten Syntax finden Sie auf Websites wie caniuse.com.
Vorteile
- Hervorragende Leistung: Die meisten Browser verfügen über eine spezielle CSS-Selektor-Engine, die eine hohe Leistung gewährleistet. Diese Engine wird in erster Linie für die Gestaltung verwendet, kann aber auch nützlich sein, wenn CSS-Selektoren über ein Browser-Automatisierungstool auf einer Seite verwendet werden.
- Schnell zu erlernen: Dank der intuitiven Syntax ist die Lernkurve für CSS-Selektoren selbst für Anfänger recht flach.
- Einfache und bekannte Syntax: Sie haben eine prägnante Syntax, die keine komplexen Operatoren oder Funktionen beinhaltet. Außerdem wissen die meisten Webentwickler, wie man sie verwendet, sodass sie nicht nur für das Styling eingesetzt werden können.
- Hervorragende Wartbarkeit: CSS-Selektoren sind so konzipiert, dass sie leicht zu lesen und zu aktualisieren sind, was die Code-Wartung vereinfacht.
- Umfassende Kompatibilität: Moderne Webbrowser und die besten Tools für Web-Scraping unterstützen sie. Dies gewährleistet eine konsistente Knotenauswahl über verschiedene Plattformen, Geräte und Anwendungsfälle hinweg, ohne dass umgebungsabhängige Workarounds erforderlich sind.
Nachteile
- Keine Unterstützung für erweiterte Funktionen und Operatoren: Im Gegensatz zu XPath sind CSS-Selektoren recht einfach und verfügen nicht über viele Funktionen oder Operatoren. Sie können sie beispielsweise nicht zum Auswählen von Textknoten oder zum Extrahieren von Daten aus dem DOM verwenden.
- Keine Unterstützung für die Aufwärtsdurchquerung des DOM-Baums: Sie können nur ab dem Stammknoten und nach unten gerichtet nach Elementen im DOM suchen.
Tipps und Tricks
Genau wie bei XPath kann Chrome CSS-Selektoren direkt auf einer Seite testen und generieren.
Angenommen, Sie möchten einen CSS-Selektor schreiben, der auf einen bestimmten Knoten abzielt. Rufen Sie die Zielseite in Chrome auf, klicken Sie mit der rechten Maustaste auf das gewünschte Element und wählen Sie „Untersuchen“:
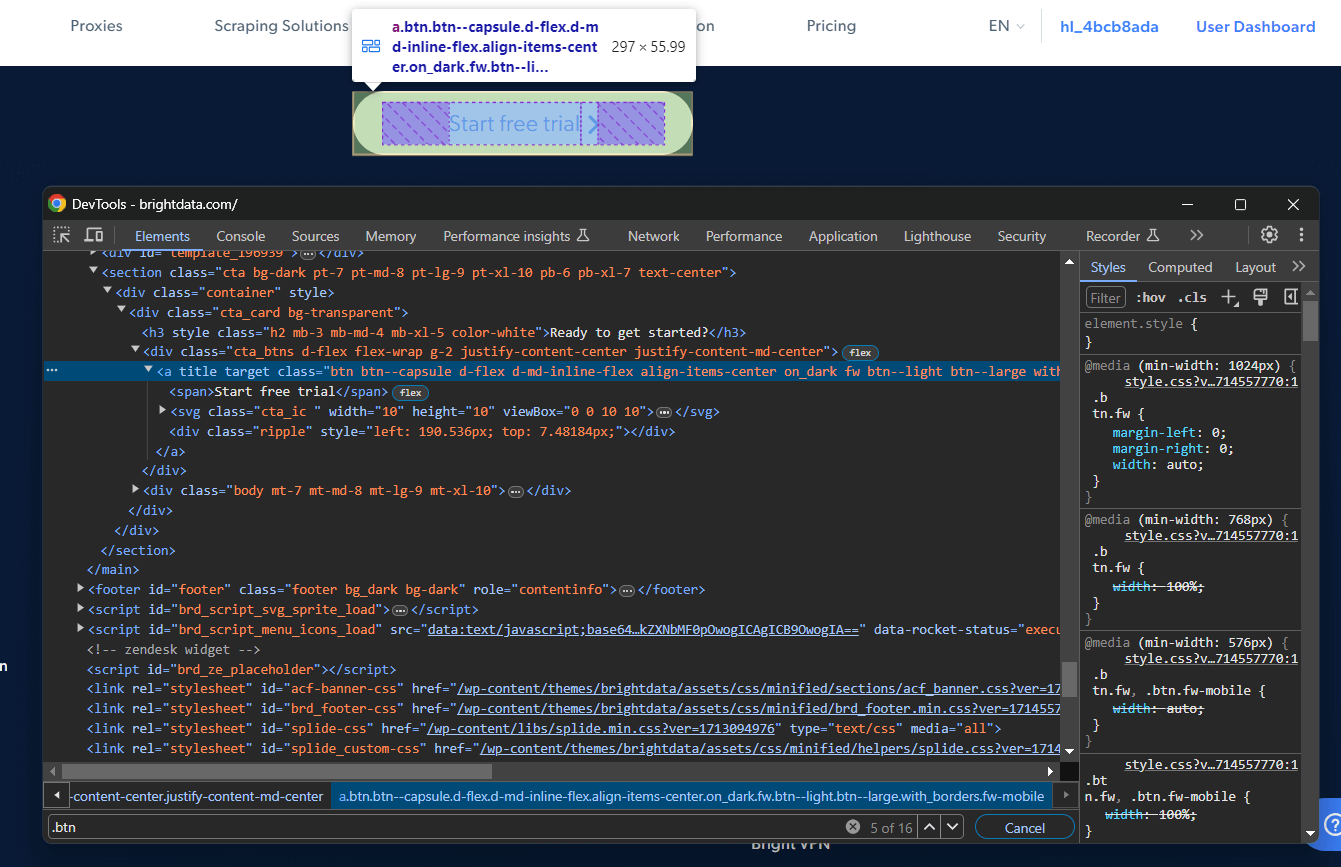
Klicken Sie mit der rechten Maustaste auf das gewünschte DOM-Element und wählen Sie „Kopieren > Selektor kopieren”, um einen vollständigen CSS-Selektor dafür zu erhalten. Im obigen Beispiel erhalten Sie:
#site-content > section.cta.bg-dark.pt-7.pt-md-8.pt-lg-9.pt-xl-10.pb-6.pb-xl-7.text-center > div > div > div.cta_btns.d-flex.flex-wrap.g-2.justify-content-center.justify-content-md-center > a
Wie Sie sehen können, ist es zu lang und implementierungsspezifisch. Obwohl es nützlich ist, um sich einen Überblick zu verschaffen, sollten Sie die mit dieser Funktion generierten CSS-Selektoren nicht in der Produktion verwenden.
Angenommen, Sie müssen einen CSS-Selektor auf einer Webseite testen. In Chrome gibt es dafür mehrere Möglichkeiten.
Der erste Ansatz besteht darin, den CSS-Selektor wie unten gezeigt in die Suchleiste einzufügen, die mit der Tastenkombination STRG/Befehl + F aktiviert werden kann:
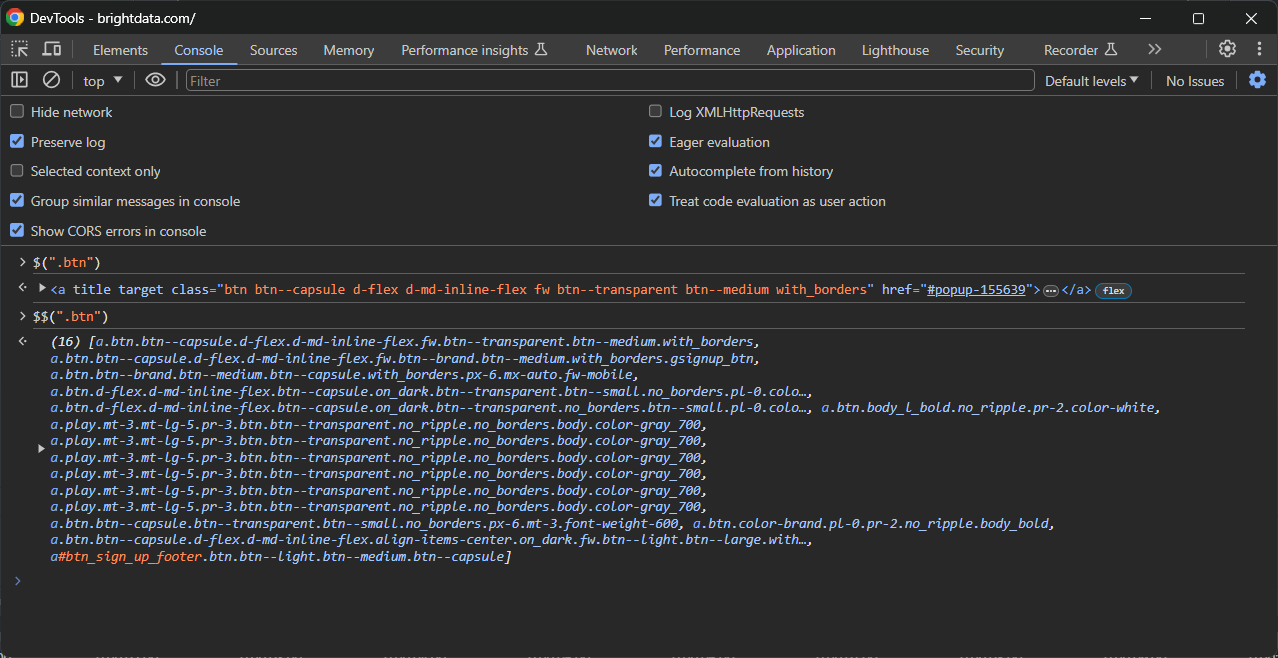
Der zweite Ansatz besteht darin, sie in der Konsole mit Hilfe dieser speziellen Funktionen zu testen:
$(): Um ein einzelnes Element mit dem angegebenen CSS-Selektor auszuwählen.- $$(): Um alle übereinstimmenden Elemente auszuwählen.
Verwenden Sie sie wie im folgenden Beispiel:
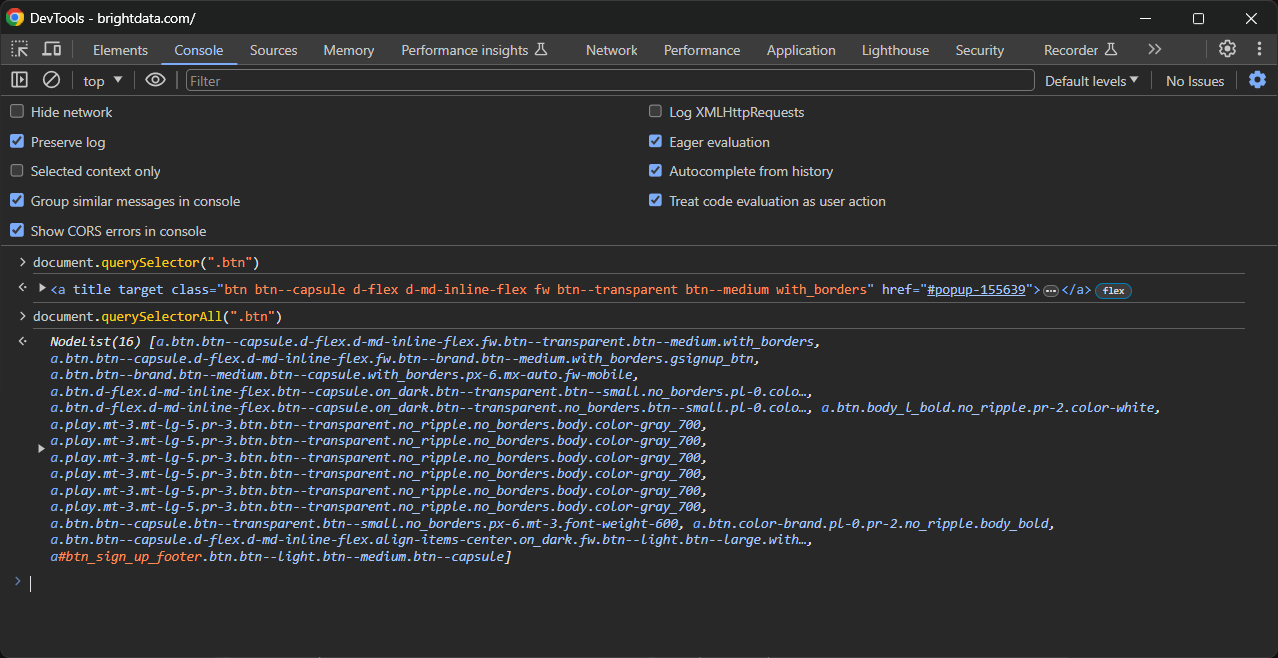
Alternativ können Sie auch die JavaScript-Funktionen querySelector() und querySelectorAll() verwenden:
XPath vs. CSS-Selektor: Direkter Vergleich
Nachdem Sie nun wissen, was XPath- und CSS-Selektoren sind, können Sie sich mit der Analyse von XPath vs. CSS-Selektor befassen.
Einen direkten Vergleich auf einen Blick finden Sie in der folgenden Übersichtstabelle:
| Aspekt | XPath | CSS-Selektoren |
| W3C-Standard | Ja | Ja |
| Aktuelle Spezifikation | XPath 3.1 (2017) | CSS Level 4 (wird ständig aktualisiert) |
| Kompatibilität | Die meisten Browser und Scraping-Tools unterstützen weiterhin XPath 1.0 | Die meisten Browser und Scraping-Tools unterstützen die neueste Spezifikation |
| Syntax | Komplex und ausführlich | Einfach und prägnant |
| Funktionen und Operatoren | Viele | Wenige |
| Auswahl von Textknoten | Unterstützt | Nicht unterstützt |
| Leistung im Browser | Mittel/Langsam | Schnell |
| Bibliotheksunterstützung | Wird in der Regel von XML-Parsing-Bibliotheken unterstützt | Wird in der Regel von den meisten HTML-Parsing-Bibliotheken unterstützt |
Einfachheit
Die XPath-Syntax erscheint im Vergleich zu CSS-Selektoren im Allgemeinen viel komplexer. Ihre Syntax ähnelt einer pfadbasierten Abfragesprache, was für Entwickler, die damit nicht vertraut sind, eine steile Lernkurve bedeutet. Allerdings bietet XPath eine präzise Kontrolle über die Elementauswahl und -durchquerung.
CSS-Selektoren sind im Allgemeinen einfacher und intuitiver, wenn es um die Auswahl von DOM-Elementen geht. Sie verwenden vertraute Muster wie Tag-Namen, Klassen und IDs, sodass sie auch für Anfänger leicht zu verstehen und zu verwenden sind. CSS-Selektoren sind in der Webentwicklung weit verbreitet, wodurch ihre Syntax recht vertraut ist.
Geschwindigkeit
Wie ein Benchmark zeigt, sind XPath-Ausdrücke, die auf DOM-Bäume in einem Browser angewendet werden, tendenziell langsamer als CSS-Selektoren. Der Grunddafür ist, dass XPath-Engines in der Regel komplexere Durchlaufoperationen durchführen müssen als CSS-Selektor-Engines. Darüber hinaus verfügen die meisten modernen Browser über hochoptimierte CSS-Selektor-Engines, die eine effiziente Auswahl von HTML-Elementen ermöglichen. Bei HTML-Parsing-Bibliotheken hängen die Leistungsunterschiede von der zugrunde liegenden Implementierung ab.
Anwendungsfälle
XPath eignet sich hervorragend für die Abfrage und Navigation von XML-Dokumenten mit XSLT oder für die einfache Datenextraktion. Seine erweiterten Funktionen können sich in bestimmten Scraping-Szenarien als nützlich erweisen, beispielsweise beim Ansprechen von übergeordneten Knoten. CSS-Selektoren werden vorwiegend für die Gestaltung von HTML-Dokumenten und die Auswahl von Knoten in modernen Web-Scraping-Skripten verwendet.
Fazit
XPath oder CSS-Selektoren? In diesem Leitfaden zu XPath- und CSS-Selektoren haben Sie gelernt, dass beide Methoden zur Auswahl von DOM-Elementen effektiv sind. XPath konzentriert sich mehr auf XML-Dokumente und bietet erweiterte Funktionen, während CSS-Selektoren hervorragend für HTML-Seiten geeignet und einfacher zu handhaben sind.
Bei der Verwendung von XPath-Ausdrücken und CSS-Selektoren beim Web-Scraping besteht das eigentliche Problem darin, dass man von Anti-Bot-Technologien blockiert wird. Unabhängig davon, welche Strategie Sie für die Knotenauswahl verwenden, können diese Systeme Ihr automatisiertes Scraping-Skript erkennen und blockieren. Glücklicherweise bietet Bright Data Ihnen mehrere erstklassige Lösungen:
- Web Scraper API: Einfach zu verwendende APIs für den programmatischen Zugriff auf strukturierte Webdaten aus Dutzenden beliebter Domains.
- Scraping-Browser: Ein cloudbasierter, steuerbarer Browser, der JavaScript-Rendering-Funktionen bietet und gleichzeitig CAPTCHAs, Browser-Fingerprinting, automatische Wiederholungsversuche und vieles mehr für Sie übernimmt. Er lässt sich in die gängigsten Automatisierungs-Browser-Bibliotheken wie Playwright und Puppeteer integrieren.
- Web Unlocker: Eine Unlocking-API, die nahtlos den rohen HTML-Code jeder Seite zurückgeben kann und dabei alle Anti-Scraping-Maßnahmen umgeht.
Sie möchten sich überhaupt nicht mit Web-Scraping beschäftigen, sind aber dennoch an Online-Daten interessiert? Entdecken Sie unsere gebrauchsfertigen Datensätze!





