
Angesichts des anhaltenden exponentiellen Wachstums der digitalen Wirtschaft ist das Sammeln von Daten aus verschiedenen Quellen wie APIs, Websites und Datenbanken wichtiger denn je.
Eine übliche Methode zum Extrahieren von Daten ist mittels Web-Scraping. Beim Web-Scraping werden automatisierte Tools verwendet, um Webseiten abzurufen und deren Inhalt zu analysieren, um bestimmte Informationen für die weitere Analyse und Verwendung zu extrahieren. Zu den häufigsten Anwendungsfällen gehören Marktforschung, Preisüberwachung und Datenaggregation.
Die Implementierung von Web-Scraping umfasst den Umgang mit dynamischen Inhalten, die Verwaltung von Sitzungen und Cookies, den Umgang mit Anti-Scraping-Maßnahmen und die Sicherstellung der Einhaltung gesetzlicher Vorschriften. Diese Herausforderungen erfordern fortschrittliche Tools und Techniken für eine effektive Datenextraktion. ChatGPT kann bei dieser Komplexität helfen, indem es seine Funktionen zur Verarbeitung natürlicher Sprache nutzt, um Code zu generieren und Fehler zu beheben.
In diesem Artikel erfahren Sie, wie Sie ChatGPT verwenden, um Scraping-Code für Websites zu generieren, die hauptsächlich auf statischen HTML-Inhalt basieren, und für komplexe Websites, die komplexere Techniken zur Seitengenerierung verwenden.
Voraussetzungen
Bevor Sie dieses Tutorial beginnen, stellen Sie sicher, das Sie über Folgendes verfügen:
- Vertrautheit mit Python
- Eine Python-Umgebung, die auf Ihrem Computer mit Visual Studio Code installiert und konfiguriert wurde.
- Ein ChatGPT -Konto
Wenn Sie ChatGPT verwenden, um Ihre Web-Scraping-Skripte zu generieren, gibt es zwei Hauptschritte:
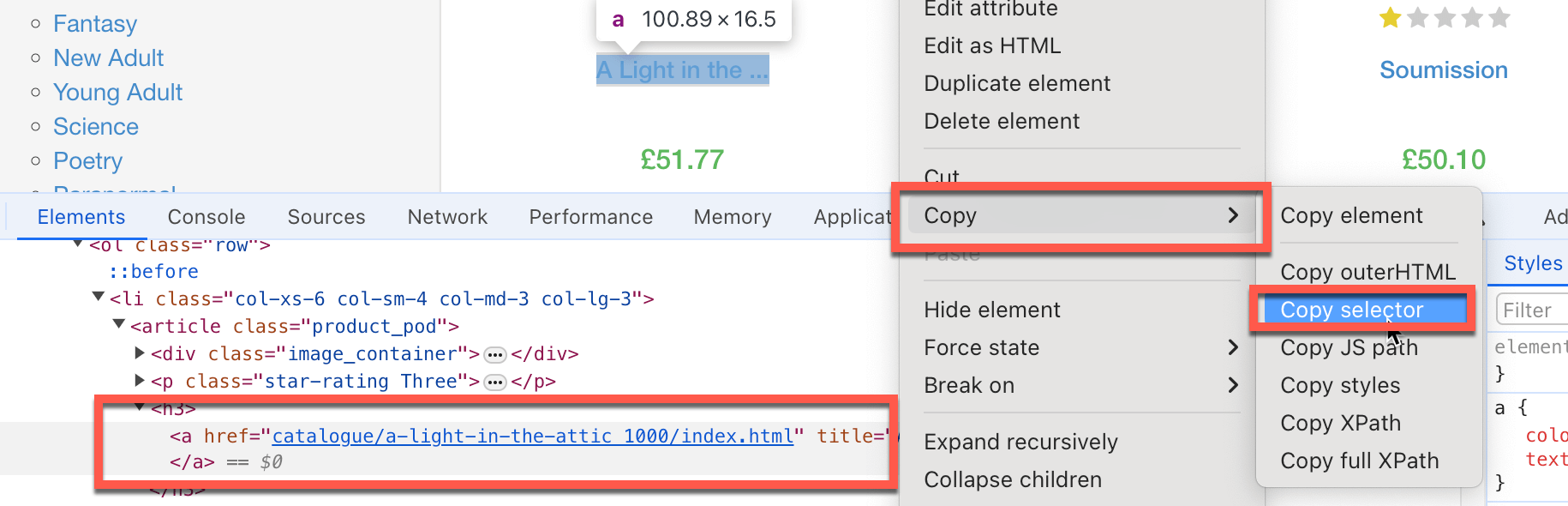
- Dokumentieren Sie jeden Schritt, dem der Code folgen muss, um die zu scrapenden Informationen zu finden, z. B. welche HTML-Elemente als Ziel verwendet werden sollen, welche Textfelder gefüllt werden und welche Schaltflächen Sie anklicken müssen. Oft müssen Sie den spezifischen HTML-Elementselektor kopieren. Klicken Sie dazu mit der rechten Maustaste auf das jeweilige Seitenelement, das Sie scrapen möchten, und klicken Sie dann auf Inspizieren; Chrome hebt das spezifische DOM-Element hervor. Klicken Sie mit der rechten Maustaste darauf und wählen Sie Kopieren > Selektor kopieren, sodass der HTML-Selektorpfad in Ihre Zwischenablage kopiert wird:
- Erstellen Sie spezifische und detaillierte ChatGPT-Aufforderungen, um den Scraping-Code zu generieren.
- Führen Sie den generierten Code aus und testen Sie ihn.
Scrapen von Websites mit statischem HTML mit ChatGPT
Nun, da Sie mit dem allgemeinen Arbeitsablauf vertraut sind, lassen Sie uns ChatGPT verwenden, um einige Websites mit statischen HTML-Elementen zu scrapen. Um loszulegen, scrapen Sie den Buchtitel und die Preise von https://books.toscrape.com.
Zunächst müssen Sie die HTML-Elemente identifizieren, die die benötigten Daten enthalten:
- Der Selektor für den Buchtitel ist
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a. - Der Selektor für den Buchpreis ist *
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color.
Als Nächstes müssen Sie spezifische und detaillierte ChatGPT-Aufforderungen erstellen, um den Scraping-Code zu generieren. Dazu müssen Sie ChatGPT anweisen, alle benötigten Python-Pakete zu installieren, es durch das Extrahieren von HTML-Selektoren (die Sie zuvor identifiziert haben) führen und es dann bitten, die Daten als Excel-Datei zu speichern.
Vergessen Sie nicht, die ChatGPT-Version auf GPT-4o zu setzen.
Sie können so etwas in ChatGPT eingeben:
Sie sind ein Experte für Web-Scraping und verwenden die Beautiful Soup-Bibliothek von Python und alle erforderlichen Automatisierungstools. Ich möchte, dass Sie ein detailliertes Schritt-für-Schritt-Skript zum Scrapen von
https://books.toscrape.comerstellen. Bitte gehen Sie wie folgt vor:
- Installieren Sie alle erforderlichen Python-Pakete.
- Extrahieren Sie den Buchtitel, der den HTML-Selektor
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > ahat, und den Buchpreis (nur die Zahl, nichts anderes), der den Selektor#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_colorhat.- Extrahieren Sie die Liste aller Buchtitel und -preise und speichern Sie sie in einer Excel-Datei.
- Scrapen Sie nur die erste Seite.
Bitte beachten Sie: Möglicherweise erhalten Sie eine etwas andere Antwort.
In der Antwort weist ChatGPT Sie an, den folgenden Befehl auszuführen, um die Beautiful Soup-Bibliothek, die Web-Scraping durchführt, und die Pandas-Bibliothek, eine umfassende Datenanalysebibliothek, die Daten als Excel speichert, zu installieren:
pip3 install requests beautifulsoup4 pandas openpyxl
Sie werden feststellen, dass ChatGPT auch vorschlägt, openpyxl zu installieren, aber das wird hier nicht benötigt.
ChatGPT bietet auch den folgenden Web-Scraping-Code:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL of the website
url = 'https://books.toscrape.com'
# Send a GET request to the website
response = requests.get(url)
if response.status_code == 200:
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, 'html.parser')
# Initialize lists to store the titles and prices
book_titles = []
book_prices = []
# Extract the first book title and price using the provided selectors
book_title_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a"
book_price_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color"
title_element = soup.select_one(book_title_selector)
price_element = soup.select_one(book_price_selector)
if title_element and price_element:
book_titles.append(title_element.get('title'))
book_prices.append(price_element.text.strip()[1:])
# Extract all book titles and prices on the first page
books = soup.select('section > div:nth-child(2) > ol > li')
for book in books:
title = book.select_one('h3 > a')
price = book.select_one('div.product_price > p.price_color')
if title and price:
book_titles.append(title.get('title'))
book_prices.append(price.text.strip()[1:])
# Create a DataFrame from the lists
df = pd.DataFrame({
'Title': book_titles,
'Price': book_prices
})
# Save the DataFrame to an Excel file
df.to_excel('books_scraped.xlsx', index=False)
print('Data has been successfully scraped and saved to books_scraped.xlsx')
else:
print('Failed to retrieve the webpage')
Dieser Code importiert das Modul requests, das HTTP-Aufrufe an die Website durchführt, die es scrapt. Er importiert auch Pandas-Pakete, die gescrapte Daten in Excel-Dateien speichern. Der Code definiert die Basis-URL der Website und die spezifischen HTML-Selektoren, auf die es abzielt, um die angeforderten Daten abzurufen.
Dann ruft der Code die Website auf und platziert den Inhalt der Website als BeautifulSoup-Objekt mit dem Namen soup. Der Code wählt mithilfe der HTML-Selektoren die Werte des Buchtitels und –preises als Listen aus dem Objekt soup aus. Schließlich erstellt der Code einen Pandas DataFrame aus dem Buchtitel sowie der Preisliste und speichert es als Excel-Datei.
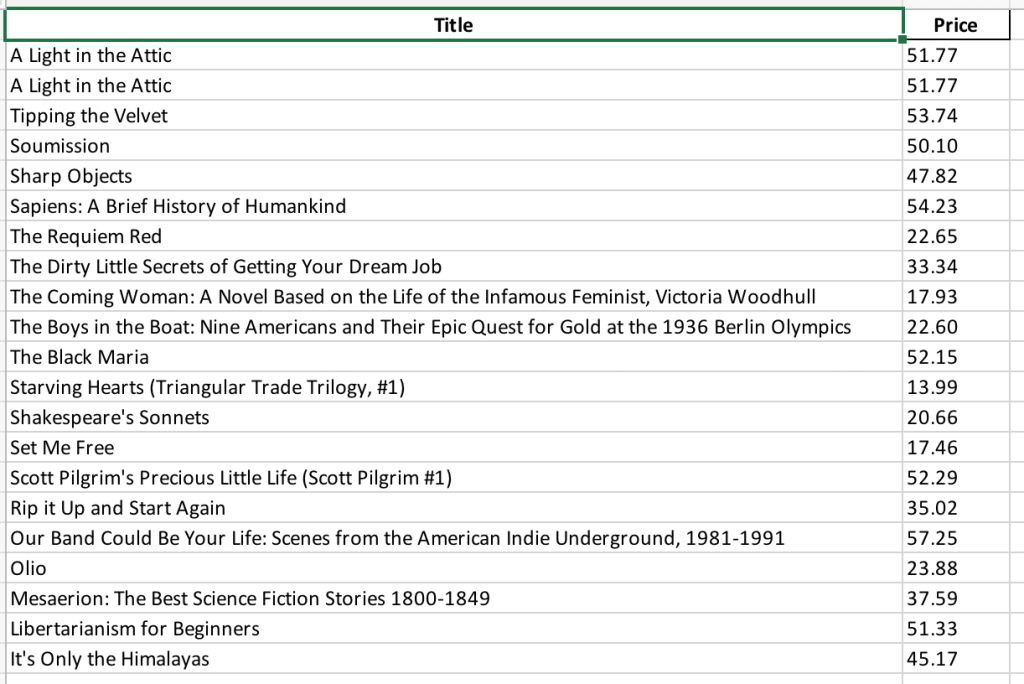
Als Nächstes müssen Sie den Code in einer Datei mit dem Namen books_scraping.py speichern und den Befehl python3 books_scraping.py von der Befehlszeile ausführen. Dieser Code generiert eine Excel-Datei mit dem Namen books_scraped.xlsx im selben Verzeichnis wie books_scraping.py:
Nachdem Sie nun ein Beispiel durchgegangen sind, gehen wir in diesem Tutorial noch einen Schritt weiter und scrapen eine weitere einfache Website: https://quotes.toscrape.com, die eine Sammlung von Zitaten enthält.
Lassen Sie uns erneut damit beginnen, die Reihenfolge der Schritte zu identifizieren.
Wenn Sie Chrome verwenden, suchen Sie nach den folgenden HTML-Selektoren:
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text, um das Zitat zu scrapenbody > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small, um den Autor zu identifizieren
Sobald Sie die HTML-Selektoren identifiziert haben, die Sie scrapen möchten, können Sie eine detaillierte Aufforderung wie die folgende erstellen, um den Scraping-Code zu generieren:
Sie sind ein Web-Scraping-Experte, der die Beautiful Soup-Bibliothek von Python und alle erforderlichen Automatisierungstools verwendet. Ich möchte, dass Sie ein detailliertes Schritt-für-Schritt-Skript zum Scrapen von
https://quotes.toscrape.comerstellen. Bitte gehen Sie wie folgt vor:
- Installieren Sie alle erforderlichen Python-Pakete.
- Extrahieren Sie das Zitat, das den HTML-Selektor
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.texthat, und den Autornamen, der den Selektor body >div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > smallhat.- Extrahieren Sie die Liste aller Zitate und Autoren und speichern Sie sie in einer Excel-Datei.
- Scrapen Sie nur die erste Seite.
Nachdem Sie diese Informationen eingegeben haben, sollte ChatGPT Ihnen den folgenden Befehl zur Verfügung stellen, der die Bibliotheken Beautiful Soup, Pandas und Openpyxl installiert:
pip3 install requests beautifulsoup4 pandas openpyxl
ChatGPT sollte auch den folgenden Web-Scraping-Code bereitstellen:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Fetch the web page content
url = "https://quotes.toscrape.com"
response = requests.get(url)
html_content = response.text
# Step 2: Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
Speichern Sie diesen Code in einer Datei mit dem Namen quotes_scraping.py und führen Sie den Befehl python3 books_scraping.py von der Befehlszeile aus. Dieser Code generiert eine Excel-Datei mit dem Namen quotes_scraped.xlsx im selben Verzeichnis wie quotes_scraping.py. Öffnen Sie die generierte Excel-Datei und sie sollte so aussehen:

Scrapen von komplexen Websites
Das Scrapen komplexer Websites kann eine Herausforderung sein, da dynamische Inhalte oft über JavaScript geladen werden, mit denen Tools wie requests und BeautifulSoup nicht umgehen können. Auf diesen Websites können Interaktionen wie das Klicken auf Schaltflächen oder das Scrollen erforderlich sein, um auf alle Daten zuzugreifen. Um dieser Herausforderung zu begegnen, können Sie WebDriververwenden, der Seiten wie einen Browser rendert und Benutzerinteraktionen simuliert, um sicherzustellen, dass alle Inhalte genauso zugänglich sind, wie es für einen typischen Benutzer der Fall wäre.
Zum Beispiel ist Yelp eine Crowdsourcing-Bewertungswebsite für Unternehmen. Yelp setzt auf dynamische Seitengenerierung und muss mehrere Benutzerinteraktionen simulieren. Hier verwenden Sie ChatGPT, um einen Scraping-Code zu generieren, der eine Liste der Unternehmen in Stockholm und deren Bewertungen abruft.
Um Yelp zu durchsuchen, dokumentieren wir zunächst die Schritte, die Sie befolgen werden:
- Suchen Sie den Selektor des Positionstextfeldes, das das Skript verwenden wird; in diesem Fall ist es
#search_location. Geben Sie „Stockholm“ in das Suchfeld für den Standort ein und suchen Sie dann nach der Suchschaltflächenselektor. In diesem Fall ist es#header_find_form > div.y-css-1iy1dwt > button. Klicken Sie auf die Suchschaltfläche, um die Suchergebnisse zu sehen. Dies kann einige Sekunden dauern. Finden Sie einen Selektor, der den Unternehmensnamen enthält (d. h.#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a):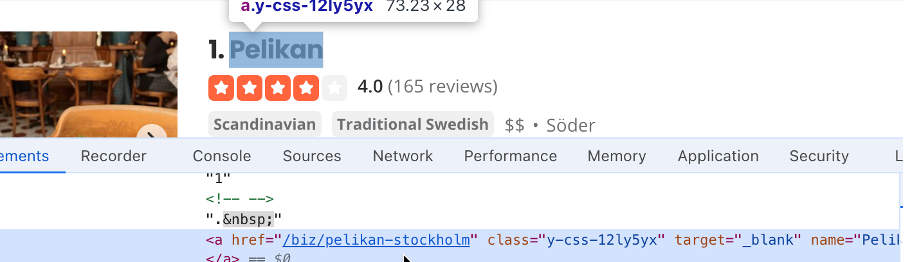
- Finden Sie den Selektor, der die Bewertung für das Unternehmen enthält (d. h.
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv):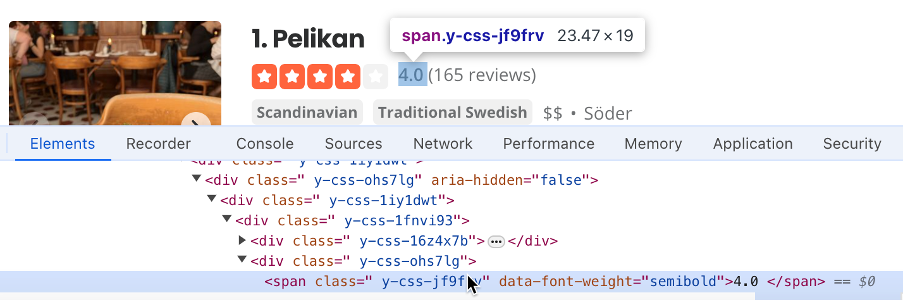
- Finden Sie den Selektor für die Schaltfläche Jetzt öffnen ; hier ist er
#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span: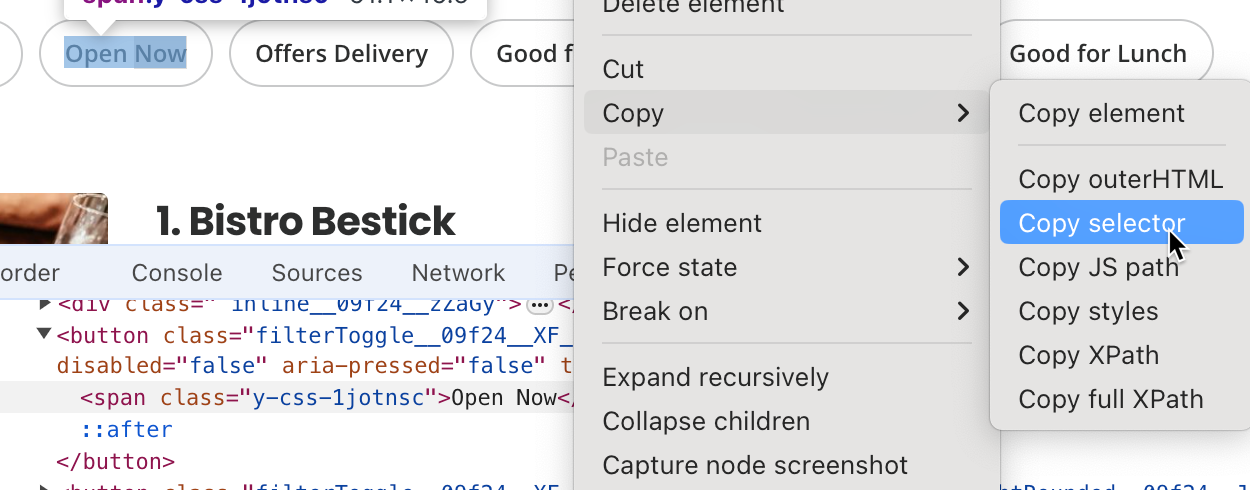
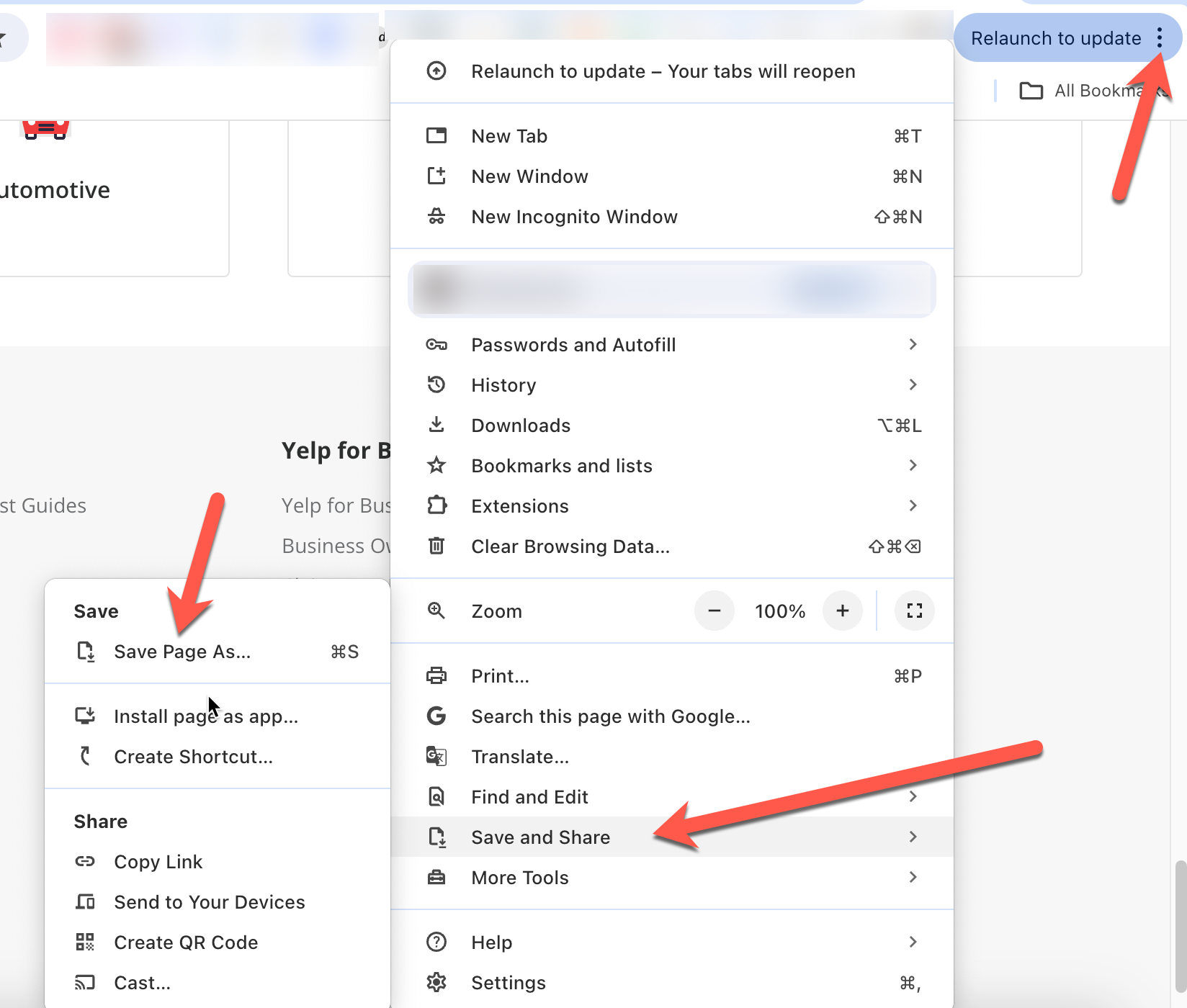
- Speichern Sie eine Kopie der Webseite, damit Sie sie später hochladen können, zusammen mit der ChatGPT-Aufforderung, damit ChatGPT den Kontext der Aufforderungen versteht. In Chrome können Sie das tun, indem Sie auf die drei Punkte oben rechts klicken und dann auf Speichern und Teilen > Seite speichern unterklicken:
Als Nächstes müssen Sie unter Verwendung der zuvor extrahierten Selektorwerte eine detaillierte Aufforderung verfassen, die ChatGPT bei der Generierung des Scraping-Skripts unterstützt:
Sie sind ein Experte für Web-Scraping. Ich möchte, dass Sie https://www.yelp.com/ scrapen, um bestimmte Informationen zu extrahieren. Folgen Sie vor dem Scrapen diesen Schritten:
- Löschen Sie das Feld mit dem Selektor
#search_location.- Geben Sie „Stockholm“ in das Suchfeld mit dem Selektor
#search_locationein.- Klicken Sie auf die Schaltfläche mit dem Selektor
#header_find_form > div.y-css-1iy1dwt > button.- Warten Sie ein paar Sekunden, bis die Seite die Suchergebnisse geladen hat.
- Klicken Sie auf die Schaltfläche Jetzt öffnen, die den Selektor
#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > spanhat, um die Unternehmen zu filtern, die gerade geöffnet haben.- Erstellen Sie eine Liste mit Unternehmensnamen; der Unternehmensname hat den Selektor
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a.- Erstellen Sie eine Liste mit den Unternehmensbewertungen; die Bewertungen haben den Selektor
#main-content > ul > li:nth-child(3) > div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv.- Erstellen Sie eine Excel-Datei mit den Unternehmensnamen und deren Bewertungen.
- Stellen Sie sicher, dass Sie alle relevanten Python-Pakete installieren.
- Verwenden Sie WebDriver von Selenium, um den Prozess zu automatisieren.
- Beziehen Sie sich auf die angehängte Kopie der Ergebnisse-HTML-Seite, um einen Überblick über das HTML-Format zu erhalten.
Nach Eingabe dieser Informationen fordert ChatGPT Sie auf, Selenium, das Webautomatisierungs-Framework, das WebDriver unterstützt, und Pandas zu installieren:
pip3 install selenium pandas
ChatGPT bietet Ihnen auch einen Scraping-Code zusammen mit einer Erklärung:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
import time
# Initialize the WebDriver
driver = webdriver.Chrome()
try:
# Open Yelp
driver.get('https://www.yelp.com/')
# Clear the location search box
location_box = driver.find_element(By.CSS_SELECTOR, '#search_location')
location_box.clear()
# Enter "Stockholm" in the location search box
location_box.send_keys('Stockholm')
# Click the search button
search_button = driver.find_element(By.CSS_SELECTOR, '#header_find_form > div.y-css-1iy1dwt > button')
search_button.click()
# Wait for search results to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#main-content'))
)
# Click on "Open Now" filter
open_now_button = driver.find_element(By.CSS_SELECTOR, '#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span')
open_now_button.click()
# Wait for the filter results to load
time.sleep(5)
# Extract business names and reviews
business_names = []
business_reviews = []
businesses = driver.find_elements(By.CSS_SELECTOR, '#main-content > ul > li')
for business in businesses:
try:
name = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a').text
review = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv').text
business_names.append(name)
business_reviews.append(review)
except Exception as e:
print(f"Error extracting data for a business: {e}")
# Create a DataFrame and save to Excel
df = pd.DataFrame({'Business Name': business_names, 'Reviews': business_reviews})
df.to_excel('stockholm_businesses.xlsx', index=False)
print("Data saved to stockholm_businesses.xlsx")
finally:
# Close the WebDriver
driver.quit()
Speichern Sie dieses Skript und führen Sie es mit Python in Visual Studio Code aus. Sie werden feststellen, dass der Code Chrome startet, zu Yelp navigiert, das Standorttextfeld löscht, „Stockholm“ eingibt, auf die Suchschaltfläche klickt, Unternehmen filtert, die gerade geöffnet sind, und dann die Seite schließt. Danach wird das Scraping-Ergebnis in der Excel-Datei stockholm_bussinsess.xlsx gespeichert:

Der gesamte Quellcode für dieses Tutorial ist auf GitHub verfügbar.
Zusammenfassung
In diesem Tutorial haben Sie gelernt, wie Sie ChatGPT verwenden, um bestimmte Informationen von Websites mit statischem HTML-Rendering und komplexeren Websites mit dynamischer Seitengenerierung, externen JavaScript-Links und Benutzerinteraktionen zu extrahieren.
Das Scrapen einer Website wie Yelp war zwar einfach, aber in Wirklichkeit kann das Web-Scraping komplexer HTML-Strukturen eine Herausforderung sein, und Sie werden wahrscheinlich IP-Sperren und CAPTCHAs erleben.
Um es einfacher zu machen, bietet Bright Data eine Vielzahl von Datenerfassungsdiensten, darunter fortschrittliche Proxy-Dienste zur Umgehung von IP-Sperren, Web Unlocker zur Umgehung und Lösung von CAPTCHAs, Web-Scraping-APIs für die automatische Datenextraktion und einen Scraping-Browser für eine effiziente Datenextraktion.
Registrieren Sie sich jetzt und entdecken Sie alle Produkte, die Bright Data zu bieten hat. Starten Sie noch heute eine kostenlose Testversion!



