

In diesem Leitfaden erfahren Sie mehr:
- Was eine Zero-Shot-Klassifizierung ist und wie sie funktioniert
- Vor- und Nachteile der Verwendung
- Relevanz dieser Praxis beim Web Scraping
- Schritt-für-Schritt-Anleitung zur Implementierung einer Zero-Shot-Klassifizierung in einem Web-Scraping-Szenario
Lasst uns eintauchen!
Was ist eine Zero-Shot-Klassifizierung?
Zero-Shot-Klassifizierung (ZSC) ist die Fähigkeit, eine Klasse vorherzusagen, die ein maschinelles Lernmodell während seiner Trainingsphase noch nie gesehen hat. Eine Klasse ist eine bestimmte Kategorie oder Bezeichnung, die das Modell einem Datenteil zuordnet. Zum Beispiel könnte es dem Text einer E-Mail die Klasse “Spam” oder einem Bild die Klasse “Katze” zuordnen.
ZSC kann als ein Beispiel für Transferlernen eingestuft werden. Transfer-Lernen ist eine Technik des maschinellen Lernens, bei der man das Wissen, das man bei der Lösung eines Problems gewonnen hat, zur Lösung eines anderen, aber verwandten Problems einsetzt.
Der Kerngedanke von ZSC wird seit einiger Zeit in verschiedenen Arten von neuronalen Netzen und maschinellen Lernmodellen erforscht und umgesetzt. Sie kann auf verschiedene Modalitäten angewendet werden, darunter:
- Text: Stellen Sie sich vor, Sie haben ein Modell, das darauf trainiert ist, Sprache im Großen und Ganzen zu verstehen, aber Sie haben ihm noch nie ein Beispiel für eine “Produktbewertung für nachhaltige Verpackungen” gezeigt. Mit ZSC können Sie es bitten, solche Bewertungen aus einem Stapel von Text zu identifizieren. Dies geschieht, indem es die Bedeutung der von Ihnen gewünschten Kategorien (Labels) versteht und sie dem Eingabetext zuordnet, anstatt sich auf vorher gelernte Beispiele für jedes spezifische Label zu verlassen.
- Bilder: Ein Modell, das auf einer Reihe von Tierbildern (z. B. Katzen, Hunde, Pferde) trainiert wurde, könnte in der Lage sein, das Bild eines Zebras als “Tier” oder sogar als “gestreiftes pferdeähnliches Tier” zu klassifizieren, ohne dass es während des Trainings jemals ein Zebra gesehen hätte.
- Audio: Ein Modell könnte darauf trainiert werden, gängige Stadtgeräusche wie “Autohupe”, “Sirene” und “Hundegebell” zu erkennen. Dank ZSC kann ein Modell ein Geräusch identifizieren, auf das es nie explizit trainiert wurde, wie z. B. “Presslufthammer”, indem es dessen akustische Eigenschaften versteht und sie mit bekannten Geräuschen in Beziehung setzt.
- Multimodale Daten: ZSC kann mit verschiedenen Datentypen arbeiten, z. B. ein Bild auf der Grundlage einer textlichen Beschreibung einer Klasse klassifizieren, die es noch nie gesehen hat, oder umgekehrt.
Wie funktioniert ZSC?
Die Zero-Shot-Klassifizierung gewinnt dank der Popularität von vortrainierten LLMs zunehmend an Interesse. Diese Modelle werden anhand großer Mengen von KI-orientierten Daten trainiert und können so ein tiefes Verständnis von Sprache, Semantik und Kontext entwickeln.
Für ZSC werden die vortrainierten Modelle oft mit einer Aufgabe namens NLI(Natural Language Inference) feinabgestimmt. Bei NLI geht es um die Bestimmung der Beziehung zwischen zwei Textstücken: einer “Prämisse” und einer “Hypothese”. Das Modell entscheidet, ob es sich bei der Hypothese um eine Folgerung (wahr, wenn die Prämisse zutrifft), einen Widerspruch (falsch, wenn die Prämisse zutrifft) oder eine neutrale Aussage (ohne Bezug) handelt.
Bei einer Zero-Shot-Klassifikation dient der Eingabetext als Prämisse. Die Kandidaten-Kategorie-Etiketten werden als Hypothesen behandelt. Das Modell berechnet, welche “Hypothese” (Bezeichnung) am wahrscheinlichsten von der “Prämisse” (Eingabetext) umfasst wird. Das Label mit dem höchsten Entailment-Score wird als Klassifikation gewählt.
Vorteile und Grenzen der Zero-Shot-Klassifizierung
Es ist an der Zeit, die Vor- und Nachteile von ZSC zu untersuchen.
Vorteile
ZSC bietet mehrere betriebliche Vorteile, darunter:
- Anpassungsfähigkeit an neue Klassen: ZSC öffnet die Tür zur Klassifizierung von Daten in unbekannte Kategorien. Dies geschieht durch die Definition neuer Bezeichnungen, ohne dass das Modell neu trainiert oder spezifische Trainingsbeispiele für die neuen Klassen gesammelt werden müssen.
- Geringerer Bedarf an beschrifteten Daten: Die Methode verringert die Abhängigkeit von umfangreichen gelabelten Datensätzen für die Zielklassen. Dadurch wird die Datenbeschriftung – einhäufiger Engpass in der Zeit- und Kostenplanung von Projekten des maschinellen Lernens – verringert.
- Effiziente Implementierung von Klassifikatoren: Neue Klassifizierungsverfahren können schnell konfiguriert und bewertet werden. Dies ermöglicht schnellere Iterationszyklen als Reaktion auf sich verändernde Anforderungen.
Beschränkungen
Die Zero-Shot-Klassifizierung ist zwar leistungsstark, hat aber auch ihre Grenzen:
- Leistungsschwankungen: ZSC-gestützte Modelle können im Vergleich zu überwachten Modellen, die ausführlich auf festen Klassensätzen trainiert wurden, eine geringere Genauigkeit aufweisen. Dies liegt daran, dass ZSC auf semantischer Inferenz beruht und nicht auf direktem Training an Beispielen der Zielklasse.
- Abhängigkeit von der Qualität des Modells: Die Leistung von ZSC hängt von der Qualität und den Fähigkeiten des zugrunde liegenden, vorab trainierten Sprachmodells ab. Ein leistungsfähiges Basismodell führt im Allgemeinen zu besseren ZSC-Ergebnissen.
- Mehrdeutigkeit und Formulierung von Bezeichnungen: Klarheit und Eindeutigkeit der Kandidatenbezeichnungen beeinflussen die Genauigkeit. Mehrdeutige oder schlecht definierte Bezeichnungen können zu einer suboptimalen Leistung führen.
Die Bedeutung der Zero-Shot-Klassifizierung beim Web Scraping
Das ständige Aufkommen neuer Informationen, Produkte und Themen im Web erfordert anpassungsfähige Datenverarbeitungsmethoden. Alles beginnt mit Web Scraping – demautomatisierten Prozess des Abrufs von Daten aus Webseiten.
Herkömmliche Methoden des maschinellen Lernens erfordern eine manuelle Kategorisierung oder ein häufiges Neutrainieren, um neue Klassen in gescrapten Daten zu verarbeiten, was im großen Maßstab ineffizient ist. Stattdessen löst die Zero-Shot-Klassifizierung die Herausforderungen, die sich aus der dynamischen Natur von Webinhalten ergeben, indem sie diese ermöglicht:
- Dynamische Kategorisierung von heterogenen Daten: Aus verschiedenen Quellen gescrapte Daten können in Echtzeit mit einem benutzerdefinierten Satz von Etiketten klassifiziert werden, die für die aktuellen Analyseziele relevant sind.
- Anpassung an sich verändernde Informationslandschaften: Neue Kategorien oder Themen können sofort in das Klassifizierungsschema aufgenommen werden, ohne dass umfangreiche Modellneuentwicklungszyklen erforderlich sind.
Typische Anwendungsfälle für ZSC beim Web-Scraping sind also:
- Dynamische Kategorisierung von Inhalten: Beim Scraping von Inhalten wie Nachrichtenartikeln oder Produktlisten aus mehreren Domänen kann ZSC die Elemente automatisch vordefinierten oder neuen Kategorien zuordnen.
- Stimmungsanalyse für neue Themen: Für gescrapte Kundenrezensionen neuer Produkte oder Social-Media-Daten im Zusammenhang mit neuen Marken kann ZSC Sentiment-Analysen durchführen, ohne dass für das jeweilige Produkt oder die jeweilige Marke spezifische Sentiment-Trainingsdaten erforderlich sind. Dies erleichtert die zeitnahe Überwachung der Markenwahrnehmung und die Bewertung des Kundenfeedbacks.
- Identifizierung von aufkommenden Trends und Themen: Durch die Definition von Hypothesenetiketten, die potenzielle neue Trends darstellen, kann ZSC zur Analyse von gescraptem Text aus Foren, Blogs oder sozialen Medien verwendet werden, um die zunehmende Verbreitung dieser Themen zu ermitteln.
Praktische Umsetzung der Zero-Shot-Klassifizierung
Dieser Abschnitt des Tutorials führt Sie durch den Prozess der Anwendung der Zero-Shot-Klassifizierung auf Daten, die aus dem Internet abgerufen wurden. Die Zielseite ist “Eishockeymannschaften: Formulare, Suche und Paginierung“:

Zunächst extrahiert ein Web Scraper die Daten aus der obigen Tabelle. Dann klassifiziert ein LLM die Daten mithilfe von ZSC. Für dieses Tutorial werden Sie den DistilBart-MNLI von Hugging Face verwenden: einen leichtgewichtigen LLM der BART-Familie.
Folgen Sie den nachstehenden Schritten und sehen Sie, wie Sie das gewünschte ZSC-Ziel erreichen!
Voraussetzungen und Abhängigkeiten
Um dieses Tutorial zu wiederholen, müssen Sie Python 3.10.1 oder höher auf Ihrem Rechner installiert haben.
Angenommen, Sie nennen den Hauptordner Ihres Projekts zsc_project/. Am Ende dieses Schritts wird der Ordner die folgende Struktur haben:
zsc_project/
├── zsc_scraper.py
└── venv/Wo:
zsc_scraper.pyist die Python-Datei, die die Kodierungslogik enthält.venv/enthält die virtuelle Umgebung.
Sie können das Verzeichnis venv/ virtual environment wie folgt erstellen:
python -m venv venvUm es zu aktivieren, führen Sie unter Windows aus:
venvScriptsactivateUnter macOS und Linux führen Sie die gleiche Funktion aus:
source venv/bin/activateIn der aktivierten virtuellen Umgebung installieren Sie die Abhängigkeiten mit:
pip install requests beautifulsoup4 transformers torchDiese Abhängigkeiten sind:
Anfragen: Eine Bibliothek zur Erstellung von HTTP-Web-Anfragen.beautifulssoup4: Eine Bibliothek zum Parsen von HTML- und XML-Dokumenten und zum Extrahieren von Daten aus diesen Dokumenten. Erfahren Sie mehr in unserem Leitfaden zu BeautifulSoup Web Scraping.Transformatoren: Eine Bibliothek von Hugging Face, die Tausende von vortrainierten Modellen enthält.Fackel: PyTorch, ein Open-Source-Framework für maschinelles Lernen.
Wunderbar! Jetzt haben Sie alles, was Sie brauchen, um die Daten aus der Ziel-Website zu extrahieren und ZSC durchzuführen.
Schritt 1: Ersteinrichtung und Konfiguration
Initialisieren Sie die Datei zsc_scraper.py, indem Sie die erforderlichen Bibliotheken importieren und einige Variablen einrichten:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process Der obige Code bewirkt Folgendes:
- Definiert die zu durchsuchende Ziel-Website mit
BASE_URL. CANDIDATES_LABELSspeichert eine Liste von Zeichenfolgen, die die Kategorien definieren, die das Zero-Shot-Klassifizierungsmodell zur Klassifizierung der ausgewerteten Daten verwendet. Das Modell versucht zu bestimmen, welche dieser Bezeichnungen die einzelnen Teamdaten am besten beschreibt.- Legt die maximale Anzahl der zu durchsuchenden Seiten und die maximale Anzahl der abzurufenden Mannschaftsdaten fest.
Perfekt! Sie haben alles, was Sie brauchen, um mit der Zero-Shot-Klassifikation in Python zu beginnen.
Schritt #2: Abrufen der Seiten-URLs
Beginnen Sie damit, das Paginierungselement auf der Zielseite zu untersuchen:

Hier können Sie sehen, dass die URLs für die Paginierung in einem HTML-Knoten .pagination enthalten sind.
Definieren Sie eine Funktion zum Auffinden aller eindeutigen Seiten-URLs aus dem Paginierungsbereich der Website:
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urlsDiese Funktion:
- Sendet eine HTTP-Anfrage an die Ziel-Website mit der Methode
get(). - Verwaltet die Paginierung mit der Methode
select()von BeautifulSoup. - Iteriert mit einer
for-Schleifedurch jede Seite, um eine konsistente Reihenfolge zu gewährleisten. - Gibt die Liste aller eindeutigen, ganzseitigen URLs zurück.
Super! Sie haben eine Funktion erstellt, mit der Sie die URLs der Webseiten abrufen können, von denen Sie die Daten abrufen wollen.
Schritt #3: Scrapen Sie die Daten
Beginnen Sie damit, das Paginierungselement auf der Zielseite zu untersuchen:

Hier sehen Sie, dass die abzurufenden Mannschaftsdaten in einem .table HTML-Knoten enthalten sind.
Erstellen Sie eine Funktion, die eine Einzelseiten-URL nimmt, ihren Inhalt abruft und Teamstatistiken extrahiert:
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_dataDiese Funktion:
- Ruft die Daten aus den Tabellenzeilen mit der Methode
select()ab. - Verarbeitet jede Teamzeile mit der Schleife
for row in table_rows:. - Gibt die abgerufenen Daten in einer Liste zurück.
Gut gemacht! Sie haben eine Funktion zum Abrufen der Daten von der Ziel-Website erstellt.
Schritt Nr. 4: Orchestrierung des Prozesses
Koordinieren Sie den gesamten Arbeitsablauf in den folgenden Schritten:
- Laden des Klassifikationsmodells
- Holen Sie die URLs der zu durchsuchenden Seiten
- Daten von jeder Seite abrufen
- Klassifizierung des gescrapten Textes mit ZSC
Erreichen Sie dies mit dem folgenden Code:
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Dieser Code:
- Lädt das vortrainierte Modell mit der Methode
pipeline()und gibt seine Aufgabe mit"zero-shot-classification"an. - Ruft die vorherigen Funktionen auf und führt die eigentliche ZSC aus.
Perfekt! Sie haben eine Funktion erstellt, die alle vorangegangenen Schritte koordiniert und die eigentliche Zero-Shot-Klassifizierung durchführt.
Schritt Nr. 5: Alles zusammenfügen und den Code ausführen
Nachfolgend ist der Inhalt der Datei zsc_scraper.py aufgeführt:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process per page
# Fetch page URLs
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urls
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_data
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Sehr gut! Sie haben Ihr erstes ZSC-Projekt abgeschlossen.
Führen Sie den Code mit dem folgenden Befehl aus:
python zsc_scraper.pyDies ist das erwartete Ergebnis:
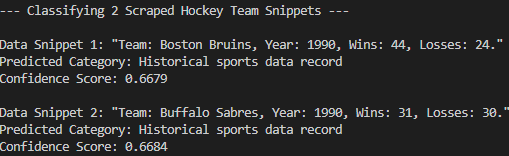
Wie Sie sehen können, hat das Modell die gescrapten Daten korrekt in den “Historischen Sportdatensatz” eingeordnet. Das wäre ohne die Nullschuss-Klassifizierung nicht möglich gewesen. Auftrag erfüllt!
Schlussfolgerung
In diesem Artikel haben Sie gelernt, was eine Zero-Shot-Klassifizierung ist und wie man sie in einem Web-Scraping-Kontext anwendet. Webdaten ändern sich ständig, und man kann nicht erwarten, dass ein vortrainierter LLM alles im Voraus weiß. ZSC hilft, diese Lücke zu schließen, indem es neue Informationen dynamisch und ohne erneutes Training klassifiziert.
Die eigentliche Herausforderung liegt jedoch in der Beschaffung frischer Daten, dennnicht alle Websites sind einfach zu scrapen. Hier kommt Bright Data ins Spiel und bietet eine Reihe leistungsfähiger Tools und Dienste an, mit denen sich die Hindernisse beim Scrapen überwinden lassen. Dazu gehören.
- Web Unlocker: Eine API, die Anti-Scraping-Schutzmaßnahmen umgeht und mit minimalem Aufwand sauberes HTML von jeder Webseite liefert.
- Scraping-Browser: Ein Cloud-basierter, kontrollierbarer Browser mit JavaScript-Rendering. Er verwaltet automatisch CAPTCHAs, Browser-Fingerprinting, Wiederholungsversuche und mehr für Sie. Er lässt sich nahtlos mit Panther oder Selenium PHP integrieren.
- Web Scraper APIs: Endpunkte für den programmatischen Zugriff auf strukturierte Webdaten aus Dutzenden von beliebten Domains.
Für das Szenario des maschinellen Lernens können Sie auch unseren AI-Hub besuchen.
Melden Sie sich jetzt bei Bright Data an und testen Sie unsere Scraping-Lösungen kostenlos!





