

In diesem Leitfaden zur Datenanalyse mit Python werden Sie sehen:
- Warum Python für die Datenanalyse verwenden?
- Gemeinsame Bibliotheken für die Datenanalyse mit Python
- Ein Schritt-für-Schritt-Tutorial für die Datenanalyse in Python
- Die Vorgehensweise bei der Datenanalyse
Lasst uns eintauchen!
Warum Python für die Datenanalyse verwenden?
Für die Datenanalyse werden in der Regel zwei wichtige Programmiersprachen verwendet:
Im Folgenden werden die wichtigsten Gründe für die Verwendung von Python für die Datenanalyse genannt:
- Geringe Lernkurve: Python hat eine einfache und lesbare Syntax, die sowohl Anfängern als auch Experten zugänglich ist.
- Vielseitigkeit: Python kann eine Vielzahl von Datentypen und -formaten verarbeiten, darunter CSV, Excel, JSON, SQL-Datenbanken, Parquet und andere. Außerdem eignet es sich für Aufgaben, die von einfacher Datenbereinigung bis hin zu komplexen Anwendungen für maschinelles Lernen und Deep Learning reichen.
- Skalierbarkeit: Python ist skalierbar und kann sowohl kleine Datensätze als auch große Datenverarbeitungsaufgaben bewältigen. Zum Beispiel helfen Bibliotheken wie Dask und PySpark dabei, Big Data mühelos zu verarbeiten.
- Unterstützung durch die Gemeinschaft: Python hat eine große und aktive Gemeinschaft von Entwicklern und Datenwissenschaftlern, die zu seinem Ökosystem beitragen.
- Integration von maschinellem Lernen und KI: Python ist die bevorzugte Sprache für maschinelles Lernen und KI. Bibliotheken wie TensorFlow, PyTorch und Keras unterstützen fortschrittliche Analysen und prädiktive Modellierung.
- Reproduzierbarkeit und Zusammenarbeit: Jupyter Notebooks helfen Ihnen bei der gemeinsamen Nutzung und Reproduktion von Datenanalyseschnipseln, was für die Zusammenarbeit in der Datenwissenschaft wichtig ist.
- Einzigartige Umgebung für verschiedene Zwecke: Python bietet die Möglichkeit, dieselbe Umgebung für verschiedene Zwecke zu verwenden. So können Sie beispielsweise dasselbe Jupyter-Notebook verwenden , um Daten aus dem Internet zu scrapen und sie anschließend zu analysieren. In derselben Umgebung können Sie auch Vorhersagen mit Modellen für maschinelles Lernen treffen.
Gemeinsame Bibliotheken für die Datenanalyse mit Python
Python wird im Bereich der Analytik auch wegen seines breiten Ökosystems an Bibliotheken häufig verwendet. Hier sind die gängigsten Bibliotheken für die Datenanalyse in Python:
- NumPy: Für numerische Berechnungen und den Umgang mit mehrdimensionalen Arrays.
- Pandas: Für die Datenmanipulation und -analyse, insbesondere mit tabellarischen Daten.
- Matplotlib und Seaborn: Für die Visualisierung von Daten und die Erstellung aufschlussreicher Diagramme.
- SciPy: Für wissenschaftliche Berechnungen und fortgeschrittene statistische Analysen.
- Plotly: Zum Erstellen von animierten Plots.
Sehen Sie sie in Aktion im folgenden Abschnitt mit Anleitung!
Datenanalyse mit Python: Ein vollständiges Beispiel
Sie wissen jetzt, warum Sie Python für die Datenanalyse verwenden sollten, und kennen die gängigen Bibliotheken, die diese Aufgabe unterstützen. Folgen Sie dieser schrittweisen Anleitung, um zu lernen, wie man Datenanalysen mit Python durchführt.
In diesem Abschnitt werden Sie Airbnb-Immobilieninformationen analysieren, die aus einem kostenlosen Datensatz von Bright Data abgerufen wurden.
Anforderungen
Um dieser Anleitung zu folgen, müssen Sie Python 3.6 oder höher auf Ihrem Rechner installiert haben.
Schritt 1: Einrichten der Umgebung und Installation der Abhängigkeiten
Angenommen, Sie nennen den Hauptordner Ihres Projekts data_analysis/. Am Ende dieses Schritts wird der Ordner die folgende Struktur haben:
data_analysis/
├── analysis.ipynb
└── venv/Wo:
analysis.ipynbist das Jupyter-Notebook, das den gesamten Python-Code für die Datenanalyse enthält.venv/enthält die virtuelle Python-Umgebung.
Sie können das Verzeichnis venv/ virtual environment wie folgt erstellen:
python -m venv venvUm es unter Windows zu aktivieren, führen Sie aus:
venvScriptsactivateUnter macOS/Linux führen Sie entsprechend aus:
source venv/bin/activateInstallieren Sie in der aktivierten virtuellen Umgebung alle erforderlichen Bibliotheken:
pip install pandas jupyter matplotlib seaborn numpyUm die Datei analysis.ipynb zu erstellen, müssen Sie zunächst den Ordner data_analysis/ öffnen:
cd data_analysisDann initialisieren Sie ein neues Jupyter Notebook mit diesem Befehl:
jupyter notebookSie können jetzt auf Ihre Jupyter Notebook App unter http://locahost:8888 in Ihrem Browser zugreifen.
Erstellen Sie eine neue Datei, indem Sie auf die Option “Neu > Python 3 (ipykernel)” klicken:
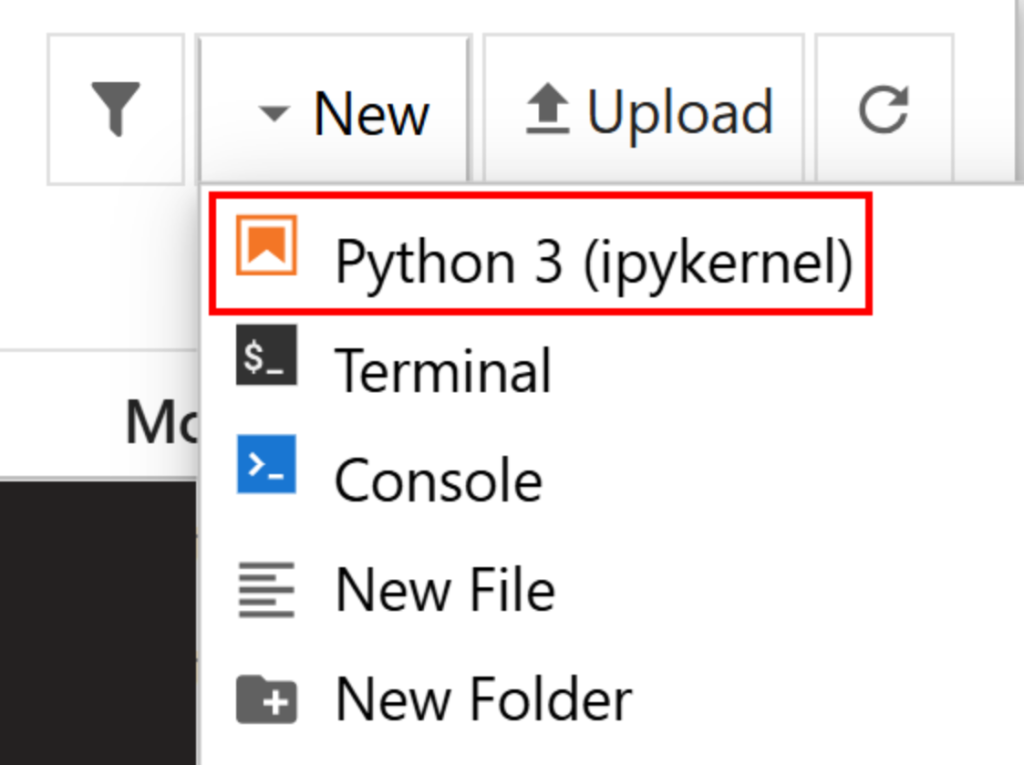
Standardmäßig wird die neue Datei untitled.ipynb genannt. Sie können sie im Dashboard wie folgt umbenennen:
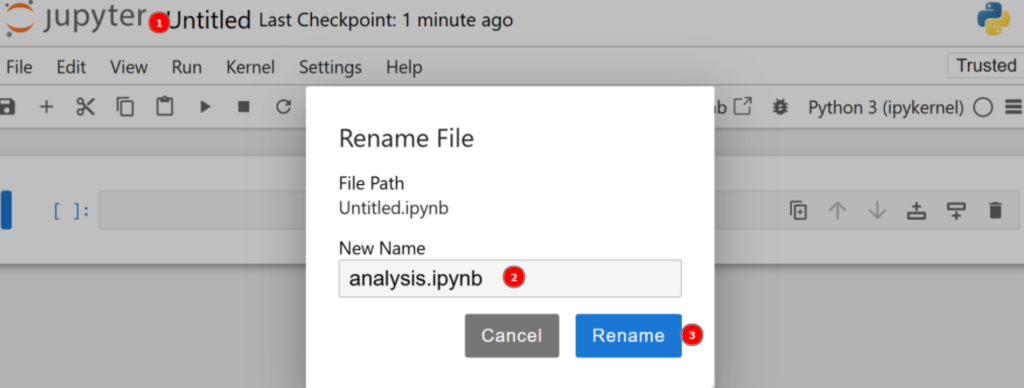
Großartig! Sie sind nun vollständig für die Datenanalyse mit Python gerüstet.
Schritt 2: Laden Sie die Daten herunter und öffnen Sie sie
Der für dieses Tutorial verwendete Datensatz stammt aus dem Datensatzmarktplatz von Bright Data. Um es herunterzuladen, melden Sie sich kostenlos auf der Plattform an und navigieren Sie zu Ihrem Benutzer-Dashboard. Folgen Sie dann dem Pfad “Web Datasets > Dataset”, um zum Dataset-Marktplatz zu gelangen:
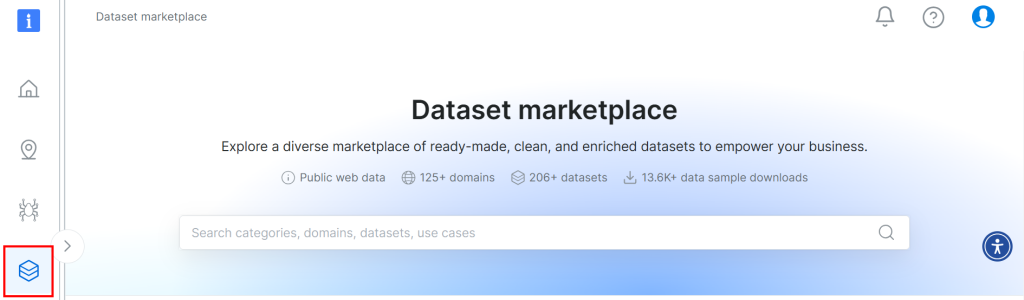
Scrollen Sie nach unten und suchen Sie nach der Karte “Airbnb Properties Information”:
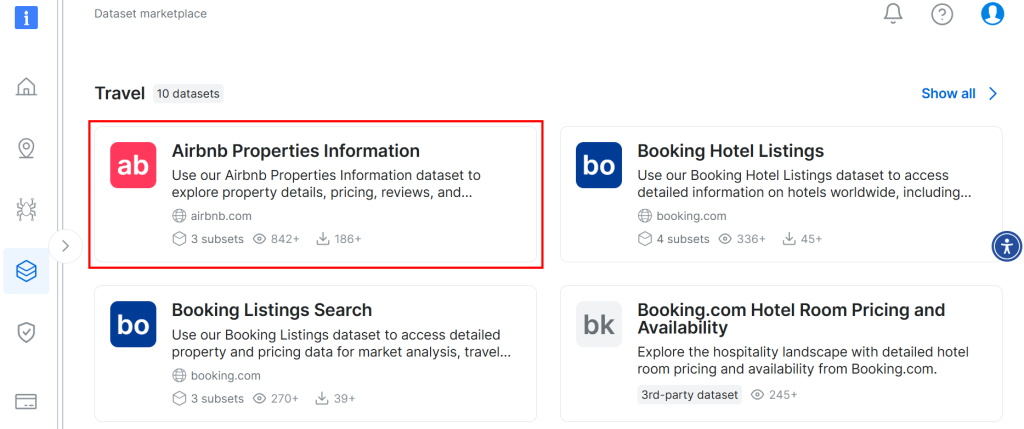
Um den Datensatz herunterzuladen, klicken Sie auf die Option “Probe herunterladen > Als CSV herunterladen”:
Sie können die heruntergeladene Datei nun umbenennen, z. B. in airbnb.csv. Um die CSV-Datei im Jupyter-Notebook zu öffnen, schreiben Sie das Folgende in eine neue Zelle:
import pandas as pd
# Open CSV
data = pd.read_csv("airbnb.csv")
# Show head
data.head()In diesem Ausschnitt:
- Die Methode
read_csv()öffnet die CSV-Datei als Pandas-Datensatz. - Die Methode
head()zeigt die ersten 5 Zeilen des Datensatzes an.
Nachfolgend ist das erwartete Ergebnis aufgeführt:
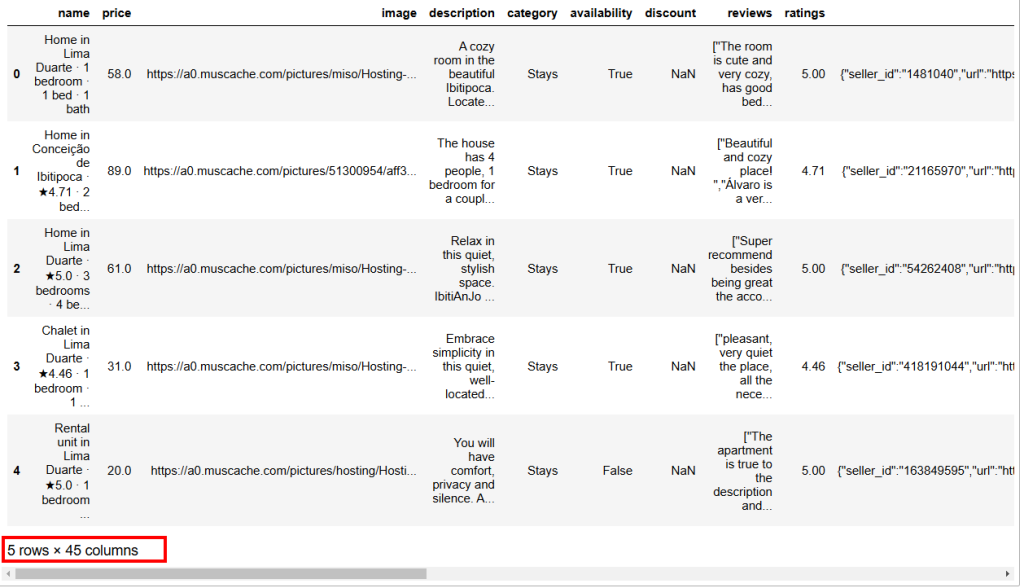
Wie Sie sehen können, hat dieser Datensatz 45 Spalten. Um sie alle zu sehen, müssen Sie den Balken nach rechts verschieben. In diesem Fall ist die Anzahl der Spalten jedoch hoch, und wenn Sie den Balken nur nach rechts verschieben, können Sie nicht alle Spalten sehen, da einige ausgeblendet wurden.
Um alle Spalten zu visualisieren, geben Sie Folgendes in eine separate Zelle ein:
# Show all columns
pd.set_option("display.max_columns", None)
# Display the data frame
print(data)Schritt 3: Verwalten von NaNs
In der Datenverarbeitung steht NaN für “Not a Number” (keine Zahl). Bei der Datenanalyse mit Python können Sie auf Datensätze mit leeren Werten, Zeichenketten, die eigentlich Zahlen enthalten sollten, oder Zellen, die bereits als NaN gekennzeichnet sind, stoßen (siehe z. B. die Spalte ” Rabatt" im obigen Bild).
Da es Ihr Ziel ist, Daten zu analysieren, müssen Sie NaNsrichtig behandeln. Es gibt hauptsächlich drei Möglichkeiten, dies zu tun:
- Alle Zeilen löschen, die
NaNsenthalten. - Ersetzen Sie die
NaNseiner Spalte durch den Mittelwert, der aus den anderen Zahlen derselben Spalte berechnet wurde. - Suche nach neuen Daten zur Anreicherung des Quelldatensatzes.
Der Einfachheit halber nehmen wir den ersten Ansatz.
Zuerst müssen Sie überprüfen, ob alle Werte der Spalte ” Rabatt" NaNssind. Wenn das der Fall ist, können Sie die gesamte Spalte löschen. Um dies zu überprüfen, schreiben Sie das Folgende in eine neue Zelle:
import numpy as np
is_discount_all_nan = data["discount"].isna().all()
print(f"Is the 'discount' column all NaNs? {is_discount_all_nan}")In diesem Ausschnitt analysiert die Methode isna().all() die NaNsder Spalte discount, die aus dem Datensatz mit data["discount"] gefiltert wurde.
Das Ergebnis ist True, was bedeutet, dass die Spalte discount **** gelöscht werden kann, da alle ihre Werte NaNssind. Um dies zu erreichen, schreiben Sie:
data = data.drop(columns=["discount"])Der ursprüngliche Datensatz wurde durch einen neuen Datensatz ohne die Rabattspalte überschrieben.
Jetzt können Sie den gesamten Datensatz analysieren und sehen, ob es weitere NaN in den Zeilen gibt:
total_nans = data.isna().sum().sum()
print(f"Total number of NaN values in the data frame: {total_nans}")Das Ergebnis, das Sie erhalten werden, ist:
Total number of NaN values in the data frame: 1248Das bedeutet, dass es 1248 weitere NaNsim Datenrahmen gibt. Um die Zeilen zu löschen, die mindestens ein NaN enthalten, geben Sie ein:
data = data.dropna()Jetzt hat der Datenrahmen keine NaNsmehr und ist bereit für die Python-Datenanalyse, ohne dass Bedenken wegen schiefer Ergebnisse bestehen.
Um zu überprüfen, ob der Prozess gut verlaufen ist, können Sie schreiben:
print(data.isna().sum().sum())Das erwartete Ergebnis ist 0.
Schritt 4: Datenexploration
Bevor Sie die Airbnb-Daten visualisieren, müssen Sie sich mit ihnen vertraut machen. Eine gute Methode ist es, zunächst die Statistiken Ihres Datensatzes wie folgt zu visualisieren:
# Show statistics of the entire dataset
statistics = data.describe()
# Print statistics
print(statistics)Dies ist das erwartete Ergebnis:
price ratings lat long guests
count 182.000000 182.000000 182.000000 182.000000 182.000000
mean 147.523352 4.804505 6.754955 -68.300942 6.554945
std 156.574795 0.209834 27.795750 24.498326 3.012818
min 16.000000 4.000000 -21.837300 -106.817450 2.000000
25% 50.000000 4.710000 -21.717270 -86.628968 4.000000
50% 89.500000 4.865000 30.382710 -83.479890 6.000000
75% 180.750000 4.950000 30.398860 -43.925480 8.000000
max 1003.000000 5.000000 40.481580 -43.801300 16.000000
property_id host_number_of_reviews host_rating hosts_year
count 1.820000e+02 182.000000 182.000000 182.000000
mean 1.323460e+17 3216.879121 4.776099 7.324176
std 3.307809e+17 4812.876819 0.138849 2.583280
min 3.089381e+06 2.000000 4.290000 1.000000
25% 3.107102e+07 73.000000 4.710000 6.000000
50% 4.375321e+07 3512.000000 4.710000 9.000000
75% 4.538668e+07 3512.000000 4.890000 9.000000
max 1.242049e+18 20189.000000 5.000000 11.000000
host_response_rate total_price
count 182.000000 182.000000
mean 98.538462 859.317363
std 8.012156 1498.684990
min 25.000000 19.000000
25% 100.000000 111.500000
50% 100.000000 350.000000
75% 100.000000 934.750000
max 100.000000 13165.000000 Die Methode describe() liefert die Statistiken zu den Spalten, die numerische Werte haben. Dies ist der erste Weg, um Ihre Daten zu verstehen. Die Spalte host_rating enthält zum Beispiel die folgenden interessanten Statistiken:
- Der Datensatz enthält insgesamt 182 Bewertungen (der
Zählwert). - Die Höchstnote ist 5, die Mindestnote ist 4,29 und der Mittelwert ist 4,77.
Dennoch sind die oben genannten Statistiken möglicherweise nicht zufriedenstellend. Versuchen Sie daher, ein Streudiagramm für die Spalte host_rating zu erstellen, um zu sehen, ob es ein interessantes Muster gibt, das Sie später untersuchen möchten. Hier sehen Sie, wie Sie mit seaborn ein Streudiagramm erstellen können:
import seaborn as sns
import matplotlib.pyplot as plt
# Define figure size
plt.figure(figsize=(15, 10))
# Plot the data
sns.scatterplot(data=data, x="host_rating", y="listing_name")
# Labeling
plt.title("HOST RATINGS SCATTERPLOT", fontsize=20)
plt.xlabel("Host ratings", fontsize=16)
plt.ylabel("Houses", fontsize=16)
# Show plot
plt.show()Das obige Snippet bewirkt Folgendes:
- Definiert die Größe des Bildes (in Zoll) mit der Methode
figure(). - Erzeugt einen Scatterplot unter Verwendung von seaborn durch die Methode
scatterplot()konfiguriert mit:Polylang Platzhalter nicht ändern
Dies ist das erwartete Ergebnis:
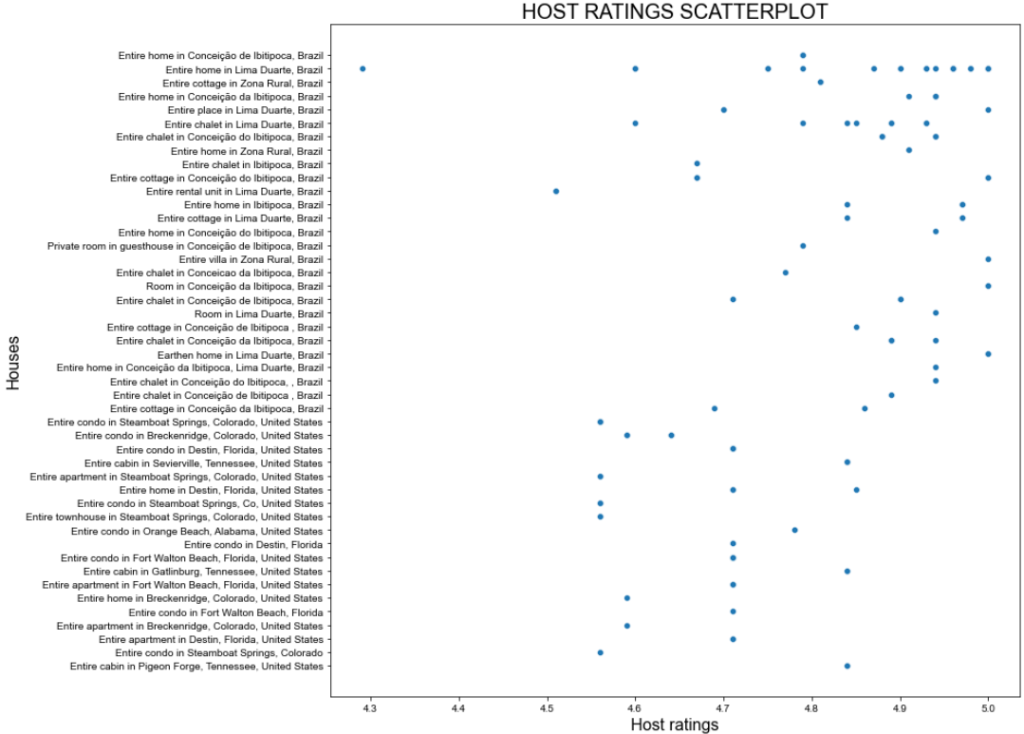
Toller Plan, aber wir können es besser machen!
Schritt 5: Datenumwandlung und -visualisierung
Die vorangegangene Streuung zeigt, dass es kein bestimmtes Muster bei den Gastgeberbewertungen gibt. Allerdings liegt die Mehrheit der Bewertungen über 4,7 Punkten.
Stellen Sie sich vor, Sie planen einen Urlaub und möchten an einem der besten Orte übernachten. Eine Frage, die Sie sich vielleicht stellen, ist: “Wie viel kostet es, in einem Haus mit einer Bewertung von mindestens 4,8 zu wohnen?”
Um diese Frage zu beantworten, müssen Sie zunächst Ihre Daten transformieren!
Die Transformation, die Sie durchführen können, besteht darin, einen neuen Datenrahmen zu erstellen, in dem die Bewertung größer als 4,8 ist. Dieser enthält die Spalte listing_n``ame mit den Namen der Wohnungen und die Spalte total_price mit deren Preisen.
Holen Sie sich diese Teilmenge und zeigen Sie ihre Statistiken mit an:
# Filter the DataFrame
high_ratings = data[data["host_rating"] > 4.8][["listing_name", "total_price"]]
# Caltulate and print statistics
high_ratings_statistics = high_ratings.describe()
print(high_ratings_statistics)Das obige Snippet erstellt einen neuen Datenrahmen namens high_ratings wie folgt:
data["host_rating"] > 4.8filtert nach Werten größer als 4.8 in der Spaltehost_ratingsaus demDataset.[["listing_name", "total_price"]]wählt nur die Spaltenlisting_nameundtotal_priceaus dem Datenrahmenhigh_ratingsaus.
Nachstehend finden Sie die erwartete Ausgabe:
total_price
count 78.000000
mean 321.061026
std 711.340269
min 19.000000
25% 78.250000
50% 116.000000
75% 206.000000
max 4230.000000Die Statistik zeigt, dass der durchschnittliche Gesamtpreis der ausgewählten Wohnungen 321 $ beträgt, mit einem Minimum von 19 $ und einem Maximum von 4230 $. Dies erfordert eine weitere Analyse!
Visualisieren Sie ein Streudiagramm der Preise für die Häuser mit hohen Bewertungen, indem Sie das gleiche Snippet wie zuvor verwenden. Sie müssen lediglich die im Diagramm verwendeten Variablen wie folgt ändern:
# Define figure size
plt.figure(figsize=(12, 8))
# Plot the data
sns.scatterplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show grid for better visualization
sns.set_style("ticks", {'axes.grid': True})
# Show plot
plt.show()Und so sieht das Ergebnis aus:
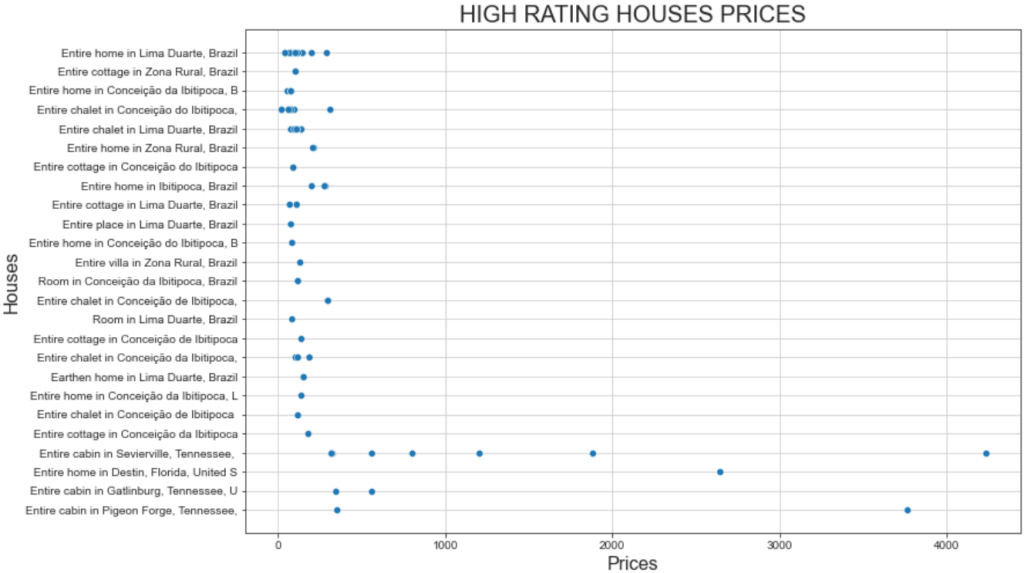
Diese Darstellung zeigt zwei interessante Fakten:
- Die Preise liegen meist unter 500 Dollar.
- Die Preise für die “ganze Hütte in Sevierville” und die “ganze Hütte in Pigeon” liegen weit über 1000 Dollar.
Eine bessere Möglichkeit, die Preisspanne zu visualisieren, ist die Darstellung eines Boxplots. So können Sie das tun:
# Define figure size
plt.figure(figsize=(15, 10))
# Plotting the boxplot
sns.boxplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES - BOXPLOT', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show plot
plt.show()Diesmal wird das Diagramm folgendermaßen aussehen:
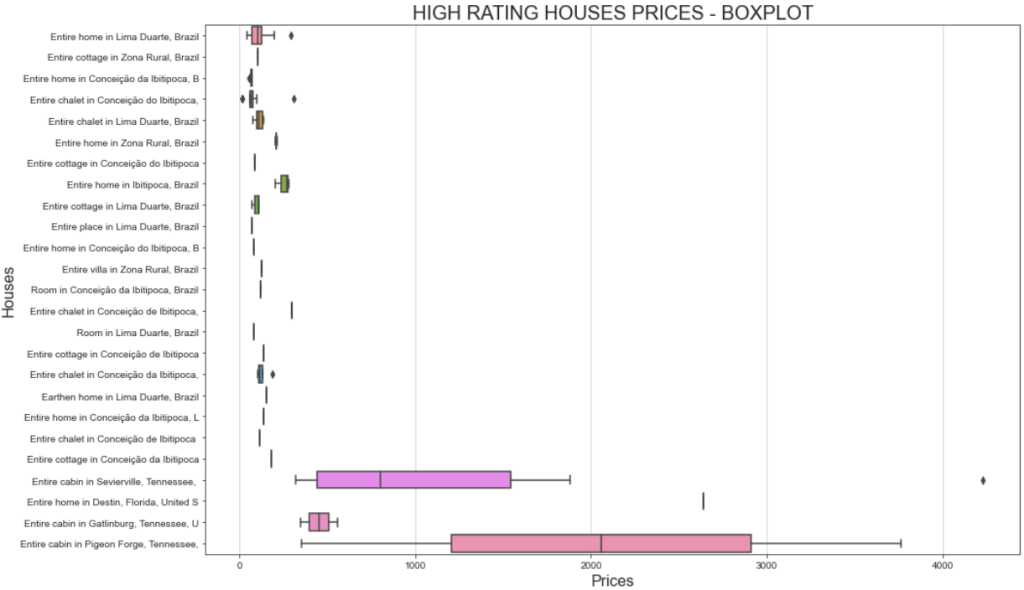
Wenn Sie sich fragen, warum ein und dasselbe Haus unterschiedlich viel kosten kann, müssen Sie bedenken, dass Sie nach den Bewertungen der Nutzer gefiltert haben. Das bedeutet, dass verschiedene Nutzer unterschiedlich gezahlt und unterschiedliche Bewertungen abgegeben haben.
Die erheblichen Preisunterschiede für die “Gesamte Hütte in Sevierville”, die von unter 1.000 $ bis über 4.000 $ reichen, können auch auf die Dauer des Aufenthalts zurückzuführen sein. Im Detail enthält der Originaldatensatz eine Spalte namens travel_details, die Informationen über die Dauer des Aufenthalts enthält. Die große Preisspanne könnte darauf hindeuten, dass einige Nutzer das Haus für einen längeren Zeitraum gemietet haben. Eine tiefergehende Analyse mit Python könnte dazu beitragen, weitere Erkenntnisse darüber zu gewinnen!
Schritt 6: Weitere Untersuchungen über die Korrelationsmatrix
Bei der Datenanalyse mit Python geht es darum, Fragen zu stellen und Antworten in den vorhandenen Daten zu finden. Eine effektive Möglichkeit, diese Fragen zu stellen, ist die Visualisierung der Korrelationsmatrix.
Die Korrelationsmatrix ist eine Tabelle, die die Korrelationskoeffizienten für verschiedene Variablen anzeigt. Der am häufigsten verwendete Korrelationskoeffizient ist der Pearson-Korrelationskoeffizient (PCC), der die lineare Korrelation zwischen zwei Variablen misst. Seine Werte reichen von -1 bis +1, was bedeutet:
- +1: Erhöht sich der Wert einer Variablen, steigt die andere linear an.
- -1 : Wenn der Wert einer Variablen steigt, sinkt die andere linear.
- 0: Man kann nichts über die lineare Beziehung zwischen den beiden Variablen sagen (dies erfordert eine nichtlineare Analyse).
In der Statistik sind die Werte der linearen Korrelation wie folgt definiert:
- 0,1-0,5: geringe Korrelation.
- 0,6-1: hohe Korrelation.
- 0: keine Korrelation.
Um die Korrelationsmatrix für den Datenrahmen anzuzeigen, können Sie Folgendes eingeben:
# Set the images dimensions
plt.figure(figsize=(12, 10))
# Labeling
plt.title('CORRELATION MATRIX', fontsize=20)
plt.xticks(fontsize=16) # x-axis font size
plt.yticks(fontsize=16) # y-axis font size
# Applying mask
mask = np.triu(np.ones_like(numeric_data.corr()))
dataplot = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})
#Add this code before creating the correlation matrix
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# Correlation matrix
dataplot = sns.heatmap(data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})Das obige Snippet bewirkt Folgendes:
- Die Methode
np.triu()wird verwendet, um eine Matrix zu diagonalisieren. Dies dient der besseren Visualisierung der Matrix, so dass sie als Dreieck und nicht als Quadrat dargestellt wird. - Die Methode
sns.heatmap()erstellt eine Heatmap. Sie dient auch zur besseren Visualisierung. Innerhalb der Methodedata.corr()werden die Pearson-Koeffizienten für jede Spalte derDatenrahmen-Datenberechnet.
Nachfolgend sehen Sie das Ergebnis, das Sie erhalten werden:

Der Hauptgedanke bei der Interpretation einer Korrelationsmatrix besteht darin, Variablen zu finden, die eine hohe Korrelation aufweisen, da diese den Ausgangspunkt für neue und tiefergehende Analysen bilden. Zum Beispiel:
- Die Variablen
latundlongweisen eine Korrelation von -0,98 auf. Dies ist zu erwarten, da Breiten- und Längengrad bei der Definition eines bestimmten Ortes auf der Erde stark korreliert sind. - Die Variablen
host_ratingundlongweisen eine Korrelation von -0,69 auf. Dies ist ein interessantes Ergebnis, das bedeutet, dass die Bewertung des Gastgebers in hohem Maße mit der Längengradvariablen korreliert ist. Es scheint also, dass Häuser, die in einem bestimmten Gebiet der Welt liegen, hohe Gastgeberbewertungen haben. - Die Variablen
latundlongweisen eine Korrelation von 0,63 bzw. -0,69 mit demPreisauf. Das reicht aus, um festzustellen, dass der Preis pro Tag stark vom Standort beeinflusst wird.
Bei Ihrer Analyse sollten Sie auch nach nicht korrelierten Variablen suchen. Zum Beispiel beträgt der Koeffizient der Variablen is_supperhost und Preis -0,18, was bedeutet, dass Superhosts nicht die höchsten Preise haben.
Nun, da die wichtigsten Konzepte klar sind, sind Sie an der Reihe, Ihre Daten zu untersuchen und zu analysieren!
Schritt 7: Alles zusammenfügen
So wird das fertige Jupyter-Notebook für die Datenanalyse mit Python aussehen:









Beachten Sie das Vorhandensein verschiedener Zellen, jede mit ihrem Ausgang.
Der Prozess der Datenanalyse mit Python
Der obige Abschnitt hat Sie durch den Prozess der Datenanalyse mit Python geführt. Auch wenn es wie ein schrittweises Vorgehen aus Opportunitätsgründen erschien, beruhte es in Wirklichkeit auf den folgenden bewährten Verfahren:
- Datenabruf: Wenn Sie das Glück haben, die benötigten Daten in einer Datenbank zu finden, haben Sie Glück! Wenn nicht, müssen Sie sie mit gängigen Datenbeschaffungsmethoden wieWeb Scraping abrufen.
- Datenbereinigung: Behandlung von
NaNs, Aggregation von Daten und Anwendung der ersten Filter auf den ursprünglichen Datensatz. - Datenexploration: Die Datenexploration – manchmal auch Datenermittlunggenannt – istder wichtigste Teil der Datenanalyse mit Python. Sie erfordert die Erstellung grundlegender Diagramme, damit Sie verstehen, wie Ihre Daten strukturiert sind oder ob sie bestimmten Mustern folgen.
- Datenmanipulation: Nachdem Sie die wichtigsten Ideen hinter den Daten, die Sie analysieren, erfasst haben, müssen Sie diese manipulieren. Dieser Teil erfordert das Filtern von Datensätzen und oft das Kombinieren von mehr als zwei Datensätzen zu einem (als ob Sie Tabellen-Joins in SQL durchführen würden).
- Datenvisualisierung: Dies ist der letzte Teil, in dem Sie Ihre Daten visuell darstellen, indem Sie mehrere Diagramme zu den manipulierten Datensätzen erstellen.
Schlussfolgerung
In diesem Leitfaden zur Datenanalyse mit Python haben Sie erfahren, warum Sie Python für die Datenanalyse verwenden sollten und welche gängigen Bibliotheken Sie zu diesem Zweck nutzen können. Außerdem haben Sie eine Schritt-für-Schritt-Anleitung durchlaufen und gelernt, wie Sie vorgehen müssen, wenn Sie eine Datenanalyse in Python durchführen möchten.
Sie haben gesehen, dass Jupyter Notebook Ihnen hilft, Teilmengen Ihrer Daten zu erstellen, sie zu visualisieren und aussagekräftige Erkenntnisse zu gewinnen. Und das alles, während Sie alles in derselben Umgebung strukturiert halten. Wo können Sie nun gebrauchsfertige Datensätze finden? Bright Data hat alles für Sie!
Bright Data betreibt ein großes, schnelles und zuverlässiges Proxy-Netzwerk, das von vielen Fortune-500-Unternehmen und über 20.000 Kunden genutzt wird. Es wird genutzt, um Daten auf ethische Weise aus dem Internet abzurufen und sie auf einem riesigen Marktplatz für Datensätze anzubieten:
- Geschäftsdaten: Daten aus wichtigen Quellen wie LinkedIn, CrunchBase, Owler und Indeed.
- E-Commerce-Datensätze: Daten von Amazon, Walmart, Target, Zara, Zalando, Asos, und vielen mehr.
- Immobilien-Datensätze: Daten von Websites wie Zillow, MLS und anderen.
- Social Media-Datensätze: Daten von Facebook, Instagram, YouTube und Reddit.
- Finanzielle Datensätze: Daten von Yahoo Finance, Market Watch, Investopedia und mehr.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und erkunden Sie unsere Datensätze.






