

Crawl4AI und Firecrawl sind zwei der größten AI-Buzz-Produkte in der Datenerfassungsbranche. In diesem Leitfaden werden wir die grundlegende Nutzung und die Statistiken beider Produkte erläutern.
Wenn Sie die Lektüre beendet haben, werden Sie in der Lage sein, die folgenden Fragen zu beantworten.
- Was ist Crawl4AI?
- Was ist Firecrawl?
- Wo kann jeder von ihnen glänzen?
- Wo sind sie zu kurz gekommen?
- Warum ist Bright Data eine gute Alternative zu beidem?
Der Vergleich dieser neuen Tools verdeutlicht die umfassenden und skalierbaren Lösungen von Bright Data. Ganz gleich, ob Sie allgemeine Scraping-Funktionen oder eine umfassende Datenerfassungs-Suite benötigen, Bright Data liefert bewährte Technologie.
Überblick und Zweck
Bevor wir uns mit den Einzelheiten befassen, sollten wir einen genaueren Blick darauf werfen, was jedes dieser Produkte ist und für wen sie vermarktet werden. Da sie für unterschiedliche Zwecke entwickelt wurden, ist dies kein Vergleich von Äpfeln mit Äpfeln. Es ist eher ein “Werkzeugkasten vs. Schweizer Taschenmesser”-Vergleich.
Crawl4AI

Crawl4AI ist eine Open-Source-Python-Bibliothek, die KI-gestütztes Web-Scraping einfacher und leichter zugänglich macht. Sie richtet sich eher an Entwickler, die ihre Extraktionspipelines erweitern möchten. Sie ist vollständig quelloffen. Der Code ist auf ihrer GitHub-Seite frei verfügbar. Crawl4AI ist mehr auf die traditionellen Scraping-Tools von Bright Data abgestimmt.
Firecrawl
Firecrawl ist eines der führenden Unternehmen im Bereich KI-gestütztes Web Scraping. Das Unternehmen bietet ein sprachunabhängiges Framework und zahlreiche Integrationsoptionen. Firecrawl stößt vor allem bei Menschen auf Interesse, die traditionell nicht in der Datenerfassung oder sogar in der Entwicklung tätig sind. Mit Firecrawl wird Scraping auch für Menschen zugänglich, die nicht immer über Programmierkenntnisse verfügen.
Einzigartige Merkmale
Crawl4AI
Crawl4AI zeichnet sich dadurch aus, dass es vollständig quelloffen ist und eine freizügige Lizenzierung verwendet. Werfen Sie einen Blick auf die Funktionen, die Crawl4AI zu einer sehr attraktiven Option für Entwickler machen. Dieses Tool bietet konfigurierbare Optionen und Vertrauen durch Transparenz im Code.
- Offene Quelle: Jeder kann sich den Code ansehen. Bugs werden oft schnell entdeckt und von der Community schnell behoben. Die transparente Codebasis bedeutet, dass es keine Überraschungen gibt – wenn man weiß, wie man Code liest.
- LLM-gesteuerte und LLM-freie Extraktion: Mit Crawl4AI haben Sie die Wahl, ein kleines, lokales Modell für die Extraktion zu verwenden oder ein externes Modell wie Deepseek einzubinden.
- Freizügige Lizenzierung: Die Lizenzierung von Crawl4AI ist sehr flexibel und freizügig. Dies weckt das Interesse sowohl von Hobbyisten als auch von Unternehmensentwicklern.
- Python-Bibliothek: Crawl4AI ist kein Abo-Dienst. Es ist eine Python-Bibliothek. Sie können es in andere Dinge einbinden und wenn Sie wollen, können Sie Ihren eigenen Scraper mit Crawl4AI als Backend erstellen.
Firecrawl
Firecrawl ist eines der beliebtesten Enterprise-Tools für Web-Scraping. Firecrawl bietet ein sprachunabhängiges Framework – Sie können Python, JavaScript oder die GUI-Website verwenden, um Ihre Extraktion durchzuführen. Firecrawl bietet eine Reihe von Tarifen an, die sowohl für Hobbyisten als auch für Unternehmenskunden geeignet sind.
- Unternehmen: Firecrawl ist ein Unternehmensprodukt. Sie bieten eine Open-Source-Option an. Die Hauptproduktlinie richtet sich jedoch an Personen, die heute eine skalierbare Datenerfassung wünschen.
- Sprachunabhängig: Firecrawl bietet GUI-Unterstützung durch seine Webapp. Sie bieten auch SDK-Unterstützung für Python und JavaScript. Es gibt auch von der Community entwickelte SDKs für Go und Rust. Mit Firecrawl sind Sie nicht auf Python beschränkt. Sie sind nicht einmal auf eine Programmierumgebung beschränkt.
- Verarbeitung natürlicher Sprache (NLP): Firecrawl ist auf die Entwicklung und Datenerfassung über natürliche Sprache ausgerichtet. Sie sagen dem Modell, was es tun soll. Dann führt das Modell die Sammelaufgabe aus.
Benutzerfreundlichkeit
Crawl4AI
Die ersten Schritte mit Crawl4AI sind relativ einfach. Sie können es über pip installieren und es von Ihrer Python-Umgebung aus aufrufen. Die folgenden Schnipsel zeigen, wie Sie es installieren und Ihre Installation überprüfen.
Installieren Sie Crawl4AI mit dem unten stehenden Befehl.
pip install crawl4aiFühren Sie das Setup aus, um Browser und Werkzeuge zu installieren.
crawl4ai-setupVerwenden Sie den Befehl doctor, um Ihre Installation zu überprüfen und eventuelle Probleme zu erkennen.
crawl4ai-doctorDer folgende Code ist sehr einfach. Er stammt direkt aus der Crawl4AI-Dokumentation hier. Fügen Sie ihn in eine beliebige Python-Datei ein und führen Sie ihn mit python name-of-file.py aus. In der Praxis läuft Crawl4AI besser als ein Shell-Befehl. Die direkte Ausführung aus VSCode oder anderen IDEs neigt dazu, Asyncio-Probleme zu verursachen.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://www.example.com",
)
print(result.markdown[:300]) # Show the first 300 characters of extracted text
if __name__ == "__main__":
asyncio.run(main())Firecrawl
Wenn Sie mit Firecrawl beginnen, navigieren Sie einfach zu deren Spielwiese und geben Sie Ihre Ziel-URL ein. Diese Schnittstelle ist sehr freundlich für Nicht-Entwickler.
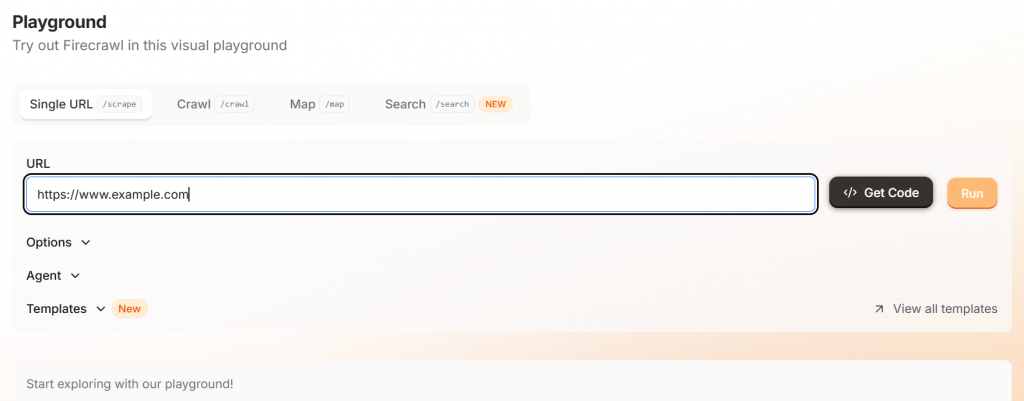
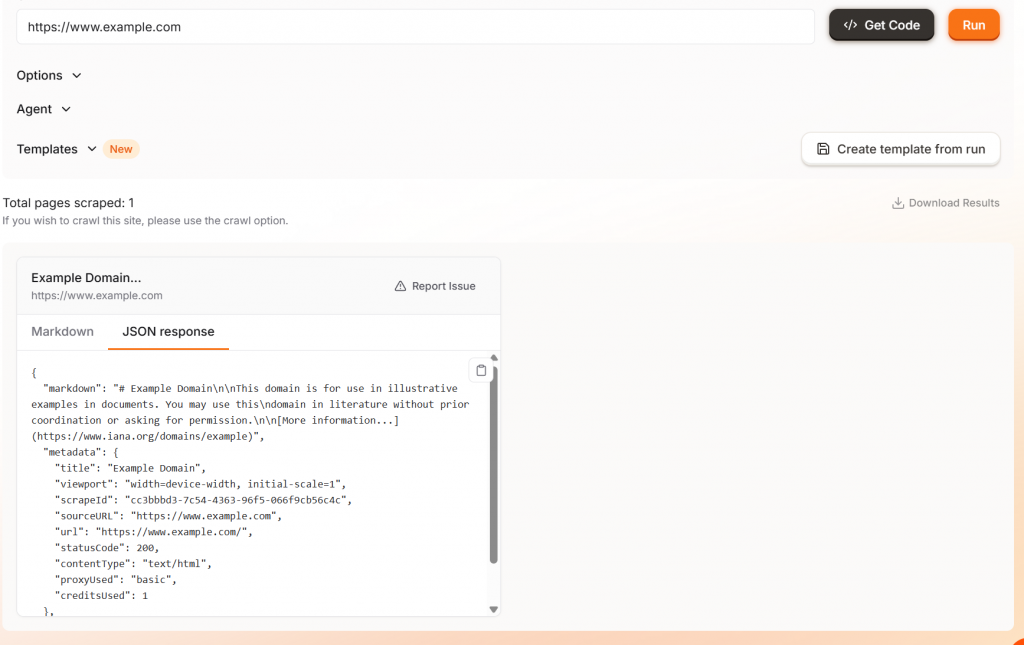
Wenn Sie auf die Schaltfläche “Ausführen” klicken, sehen Sie eine Beispielausgabe, die entweder in Markdown oder JSON vorliegt.
Leistung und Skalierbarkeit
Crawl4AI
Der folgende Ausschnitt stammt aus dem Beispielcode, den Sie vorhin gesehen haben. Alles in allem dauerte das Scrapen der Beispiel-Domain knapp zwei Sekunden. Ohne ein LLM ist Crawl4AI außergewöhnlich schnell. Es konkurriert mit dem manuellen Scraping mit Requests und BeautifulSoup in Bezug auf die Leistung.

Markdown-Scraping und Roh-HTML sind jedoch so sauber wie möglich. Crawl4AI listet zwar Unterstützung für JSON-Extraktion ohne LLM auf, aber die Unterstützung ist begrenzt und fehlerhaft. Um vollständige Datenstrukturen zu extrahieren, müssen Sie eine LLM-Unterstützung zu Ihrem Code hinzufügen. Das sind die versteckten Kosten von Crawl4AI, Sie müssen einen externen LLM hosten oder dafür bezahlen, um echte Parsing-Aufträge zu erledigen.
Im folgenden Code verwenden wir ein OpenAI-Modell, um die Seite von Books to Scrape zu analysieren. Wenn Sie es selbst ausführen möchten, müssen Sie den API-Schlüssel durch Ihren eigenen ersetzen.
import asyncio
import json
from pydantic import BaseModel
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, LLMConfig
from crawl4ai.extraction_strategy import LLMExtractionStrategy
openai_api_key = "your-openai-api-key"
class Product(BaseModel):
name: str
price: str
async def main():
#tell the llm what to scrape and set config
llm_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider="openai/gpt-4o-mini", api_token=openai_api_key),
schema=Product.model_json_schema(),
extraction_type="schema",
instruction="Extract all product objects with 'name' and 'price' from the content.",
chunk_token_threshold=1000,
overlap_rate=0.0,
apply_chunking=True,
input_format="markdown",
extra_args={"temperature": 0.0, "max_tokens": 800}
)
#build the crawler config
crawl_config = CrawlerRunConfig(
extraction_strategy=llm_strategy,
cache_mode=CacheMode.BYPASS
)
#create a browser config if needed
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
#crawl a single page
result = await crawler.arun(
url="https://books.toscrape.com",
config=crawl_config
)
if result.success:
#assume the extracted content is json
data = json.loads(result.extracted_content)
print("Extracted items:", data)
#show usage stats
llm_strategy.show_usage()
else:
print("Error:", result.error_message)
if __name__ == "__main__":
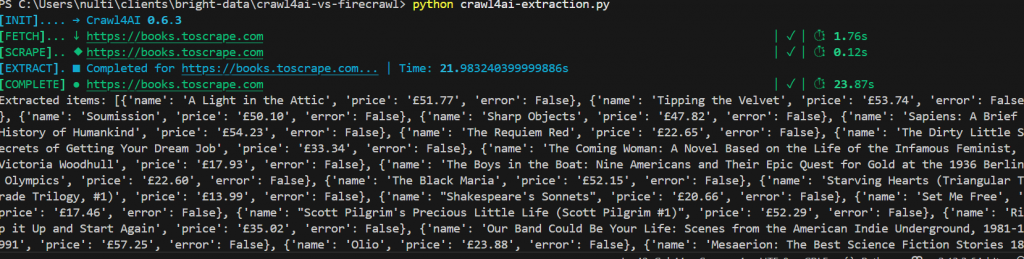
asyncio.run(main())Hier ist unser Ergebnis. Insgesamt hat es knapp 25 Sekunden gedauert. Sie können auch jedes Buch zusammen mit seinem Preis in einem sauber strukturierten JSON-Objekt sehen.
Firecrawl
Mit Firecrawl geben Sie einfach eine URL ein und die Seite wird gescraped. Wenn Sie die Standardversion von Firecrawl verwenden, gibt es Ihre Seite als rohes Markdown aus, das in ein JSON-Objekt ausgelagert wird.
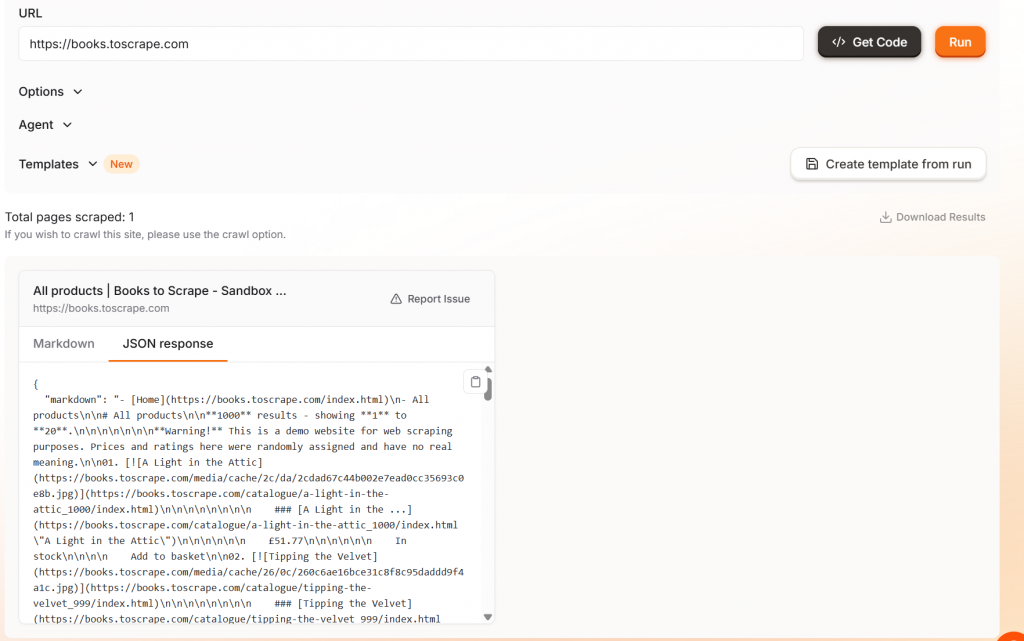
Firecrawl hat eine coole Funktion, wenn Sie Ihren Code ausführen. Während Ihr Scraper läuft, können Sie den Browser beobachten, wie er die Seite rendert.
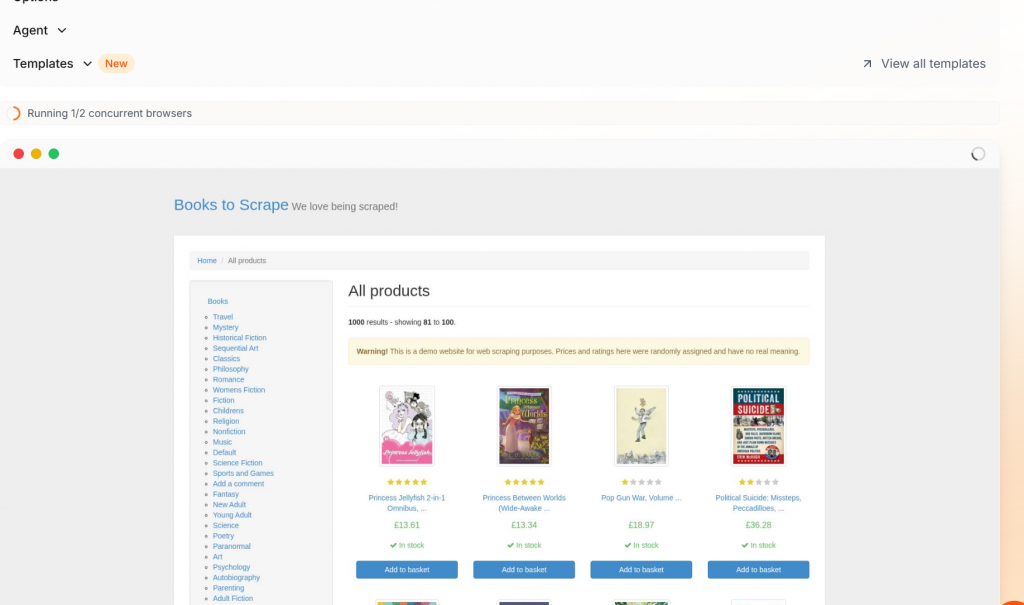
Datenqualität und -genauigkeit
Crawl4AI
Wenn Crawl4AI mit GPT-4o verbunden war, funktionierte es mit 100%iger Genauigkeit. Um die Anzahl der Artikel zu überprüfen, fügten wir die folgende Zeile in unseren Code ein.
print("Total products scraped:", len(data))Wie Sie in der folgenden Ausgabe sehen, haben Crawl4AI und GPT-4o alle 20 Elemente auf der Seite gefunden.

In Verbindung mit einem LLM wird Crawl4AI zu einem überraschend leistungsstarken Werkzeug mit bemerkenswerter Genauigkeit.
Firecrawl
Firecrawl bietet zwei verschiedene Produkte an, wenn es um das Scrapen geht. Sie können einfaches altes Firecrawl für einfache, schmutzige Scraping-Optionen verwenden. Firecrawl Extract ermöglicht es Ihnen, strukturierte JSON-Objekte zu extrahieren.
Regelmäßiges Firecrawl
Dies ist die Ausgabe von Books To Scrape mit normalem Firecrawl. Wie Sie sehen können, ist es schlecht – wirklich schlecht. Firecrawl hat die Seite in Markdown konvertiert. Dann hat es den rohen Markdown in scheinbar zufällige JSON-Felder zerlegt. Diese Daten müssen manuell mit Code weiter bereinigt oder an einen LLM übergeben werden.
{
"markdown": "All products \| Books to Scrape - Sandboxnn[Books to Scrape](index.html) We love being scraped!nn- [Home](index.html)n- All productsnn- [Books](catalogue/category/books_1/index.html) - [Travel](catalogue/category/books/travel_2/index.html)n - [Mystery](catalogue/category/books/mystery_3/index.html)n - [Historical Fiction](catalogue/category/books/historical-fiction_4/index.html)n - [Sequential Art](catalogue/category/books/sequential-art_5/index.html)n - [Classics](catalogue/category/books/classics_6/index.html)n - [Philosophy](catalogue/category/books/philosophy_7/index.html)n - [Romance](catalogue/category/books/romance_8/index.html)n - [Womens Fiction](catalogue/category/books/womens-fiction_9/index.html)n - [Fiction](catalogue/category/books/fiction_10/index.html)n - [Childrens](catalogue/category/books/childrens_11/index.html)n - [Religion](catalogue/category/books/religion_12/index.html)n - [Nonfiction](catalogue/category/books/nonfiction_13/index.html)n - [Music](catalogue/category/books/music_14/index.html)n - [Default](catalogue/category/books/default_15/index.html)n - [Science Fiction](catalogue/category/books/science-fiction_16/index.html)n - [Sports and Games](catalogue/category/books/sports-and-games_17/index.html)n - [Add a comment](catalogue/category/books/add-a-comment_18/index.html)n - [Fantasy](catalogue/category/books/fantasy_19/index.html)n - [New Adult](catalogue/category/books/new-adult_20/index.html)n - [Young Adult](catalogue/category/books/young-adult_21/index.html)n - [Science](catalogue/category/books/science_22/index.html)n - [Poetry](catalogue/category/books/poetry_23/index.html)n - [Paranormal](catalogue/category/books/paranormal_24/index.html)n - [Art](catalogue/category/books/art_25/index.html)n - [Psychology](catalogue/category/books/psychology_26/index.html)n - [Autobiography](catalogue/category/books/autobiography_27/index.html)n - [Parenting](catalogue/category/books/parenting_28/index.html)n - [Adult Fiction](catalogue/category/books/adult-fiction_29/index.html)n - [Humor](catalogue/category/books/humor_30/index.html)n - [Horror](catalogue/category/books/horror_31/index.html)n - [History](catalogue/category/books/history_32/index.html)n - [Food and Drink](catalogue/category/books/food-and-drink_33/index.html)n - [Christian Fiction](catalogue/category/books/christian-fiction_34/index.html)n - [Business](catalogue/category/books/business_35/index.html)n - [Biography](catalogue/category/books/biography_36/index.html)n - [Thriller](catalogue/category/books/thriller_37/index.html)n - [Contemporary](catalogue/category/books/contemporary_38/index.html)n - [Spirituality](catalogue/category/books/spirituality_39/index.html)n - [Academic](catalogue/category/books/academic_40/index.html)n - [Self Help](catalogue/category/books/self-help_41/index.html)n - [Historical](catalogue/category/books/historical_42/index.html)n - [Christian](catalogue/category/books/christian_43/index.html)n - [Suspense](catalogue/category/books/suspense_44/index.html)n - [Short Stories](catalogue/category/books/short-stories_45/index.html)n - [Novels](catalogue/category/books/novels_46/index.html)n - [Health](catalogue/category/books/health_47/index.html)n - [Politics](catalogue/category/books/politics_48/index.html)n - [Cultural](catalogue/category/books/cultural_49/index.html)n - [Erotica](catalogue/category/books/erotica_50/index.html)n - [Crime](catalogue/category/books/crime_51/index.html)nn# All productsnn**1000** results - showing **1** to **20**.nnnnnnn**Warning!** This is a demo website for web scraping purposes. Prices and ratings here were randomly assigned and have no real meaning.nn01. [](catalogue/a-light-in-the-attic_1000/index.html)nnnnnnnn ### [A Light in the ...](catalogue/a-light-in-the-attic_1000/index.html "A Light in the Attic")nnnnnn £51.77nnnnnn In stocknnnn Add to basketnn02. [](catalogue/tipping-the-velvet_999/index.html)nnnnnnnn ### [Tipping the Velvet](catalogue/tipping-the-velvet_999/index.html "Tipping the Velvet")nnnnnn £53.74nnnnnn In stocknnnn Add to basketnn03. [](catalogue/soumission_998/index.html)nnnnnnnn ### [Soumission](catalogue/soumission_998/index.html "Soumission")nnnnnn £50.10nnnnnn In stocknnnn Add to basketnn04. [](catalogue/sharp-objects_997/index.html)nnnnnnnn ### [Sharp Objects](catalogue/sharp-objects_997/index.html "Sharp Objects")nnnnnn £47.82nnnnnn In stocknnnn Add to basketnn05. [](catalogue/sapiens-a-brief-history-of-humankind_996/index.html)nnnnnnnn ### [Sapiens: A Brief History ...](catalogue/sapiens-a-brief-history-of-humankind_996/index.html "Sapiens: A Brief History of Humankind")nnnnnn £54.23nnnnnn In stocknnnn Add to basketnn06. [](catalogue/the-requiem-red_995/index.html)nnnnnnnn ### [The Requiem Red](catalogue/the-requiem-red_995/index.html "The Requiem Red")nnnnnn £22.65nnnnnn In stocknnnn Add to basketnn07. [](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html)nnnnnnnn ### [The Dirty Little Secrets ...](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html "The Dirty Little Secrets of Getting Your Dream Job")nnnnnn £33.34nnnnnn In stocknnnn Add to basketnn08. [](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html)nnnnnnnn ### [The Coming Woman: A ...](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull")nnnnnn £17.93nnnnnn In stocknnnn Add to basketnn09. [](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html)nnnnnnnn ### [The Boys in the ...](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics")nnnnnn £22.60nnnnnn In stocknnnn Add to basketnn10. [](catalogue/the-black-maria_991/index.html)nnnnnnnn ### [The Black Maria](catalogue/the-black-maria_991/index.html "The Black Maria")nnnnnn £52.15nnnnnn In stocknnnn Add to basketnn11. [](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html)nnnnnnnn ### [Starving Hearts (Triangular Trade ...](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html "Starving Hearts (Triangular Trade Trilogy, \#1)")nnnnnn £13.99nnnnnn In stocknnnn Add to basketnn12. [](catalogue/shakespeares-sonnets_989/index.html)nnnnnnnn ### [Shakespeare's Sonnets](catalogue/shakespeares-sonnets_989/index.html "Shakespeare's Sonnets")nnnnnn £20.66nnnnnn In stocknnnn Add to basketnn13. [](catalogue/set-me-free_988/index.html)nnnnnnnn ### [Set Me Free](catalogue/set-me-free_988/index.html "Set Me Free")nnnnnn £17.46nnnnnn In stocknnnn Add to basketnn14. [](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html)nnnnnnnn ### [Scott Pilgrim's Precious Little ...](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html "Scott Pilgrim's Precious Little Life (Scott Pilgrim \#1)")nnnnnn £52.29nnnnnn In stocknnnn Add to basketnn15. [](catalogue/rip-it-up-and-start-again_986/index.html)nnnnnnnn ### [Rip it Up and ...](catalogue/rip-it-up-and-start-again_986/index.html "Rip it Up and Start Again")nnnnnn £35.02nnnnnn In stocknnnn Add to basketnn16. [](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html)nnnnnnnn ### [Our Band Could Be ...](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991")nnnnnn £57.25nnnnnn In stocknnnn Add to basketnn17. [](catalogue/olio_984/index.html)nnnnnnnn ### [Olio](catalogue/olio_984/index.html "Olio")nnnnnn £23.88nnnnnn In stocknnnn Add to basketnn18. [](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html)nnnnnnnn ### [Mesaerion: The Best Science ...](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html "Mesaerion: The Best Science Fiction Stories 1800-1849")nnnnnn £37.59nnnnnn In stocknnnn Add to basketnn19. [](catalogue/libertarianism-for-beginners_982/index.html)nnnnnnnn ### [Libertarianism for Beginners](catalogue/libertarianism-for-beginners_982/index.html "Libertarianism for Beginners")nnnnnn £51.33nnnnnn In stocknnnn Add to basketnn20. [](catalogue/its-only-the-himalayas_981/index.html)nnnnnnnn ### [It's Only the Himalayas](catalogue/its-only-the-himalayas_981/index.html "It's Only the Himalayas")nnnnnn £45.17nnnnnn In stocknnnn Add to basketnnn-nPage 1 of 50nnn- [next](catalogue/page-2.html)",
"metadata": {
"language": "en-us",
"description": "",
"created": "24th Jun 2016 09:29",
"viewport": "width=device-width",
"title": "n All products | Books to Scrape - Sandboxn",
"robots": "NOARCHIVE,NOCACHE",
"favicon": "https://books.toscrape.com/static/oscar/favicon.ico",
"scrapeId": "aa3667ec-647b-42ab-adb2-9c35e042896d",
"sourceURL": "https://books.toscrape.com",
"url": "https://books.toscrape.com/",
"statusCode": 200,
"contentType": "text/html",
"proxyUsed": "basic",
"creditsUsed": 80
},
"scrape_id": "aa3667ec-647b-42ab-adb2-9c35e042896d"
}Das normale Firecrawl holt sich die Seite, aber viel mehr als das tut es nicht. Sie erhalten eine aufgeschnittene Markdown-Seite, die in ein großes JSON-Objekt zerschlagen wird. Sie können die Seite abrufen, aber es erfordert viel Arbeit, Ihre Webseite in brauchbare Daten umzuwandeln.
Firecrawl-Auszug
Extract ist die nächsthöhere Stufe. Mit Extract erhalten Sie volle Unterstützung für Scraping über NLP. Sie teilen dem Modell mit, welche Daten es abrufen soll, und es extrahiert sie aus der Seite. Wie Sie in der Abbildung unten sehen können, erhalten wir sogar ein empfohlenes Schema mit den Feldern Titel, Preis und Verfügbarkeit. Wenn Sie mit Ihrem Schema zufrieden sind, klicken Sie auf die Schaltfläche “Ausführen”.
Bitte beachten Sie, dass Ihrer Website ein /* angehängt ist – dies weist Extract an, automatisch die gesamte Website zu crawlen. Um Credits zu sparen, entfernen Sie das /*.
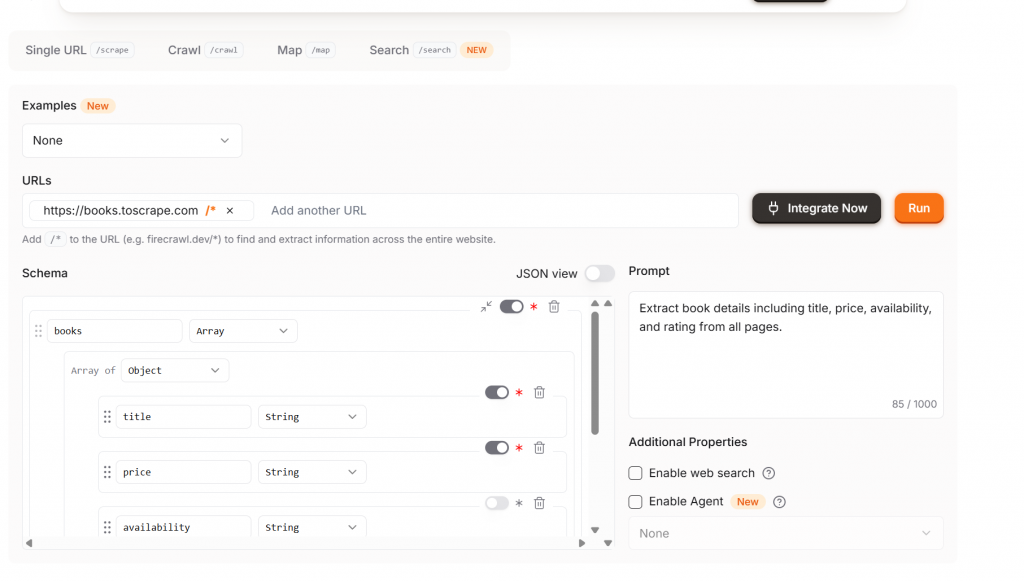
Wenn Sie eine einzelne Seite crawlen möchten, müssen Sie nur Extract von der Standardeinstellung abändern. Das Bild unten zeigt unsere Konfiguration für das Scrapen einer einzelnen Seite. Der Operator /* kann leicht übersehen werden. Sparen Sie sich das Geld und verwenden Sie ihn nur bei Bedarf.
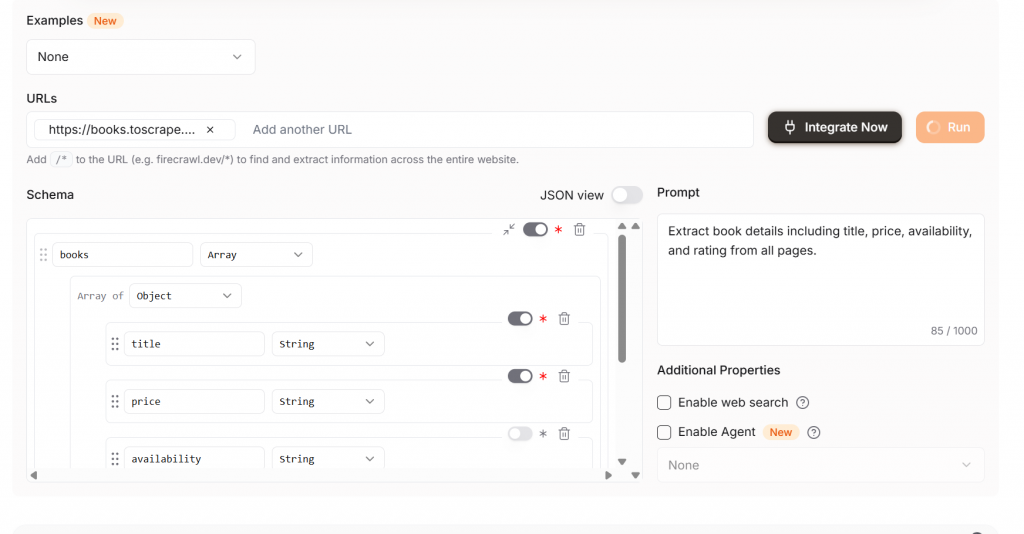
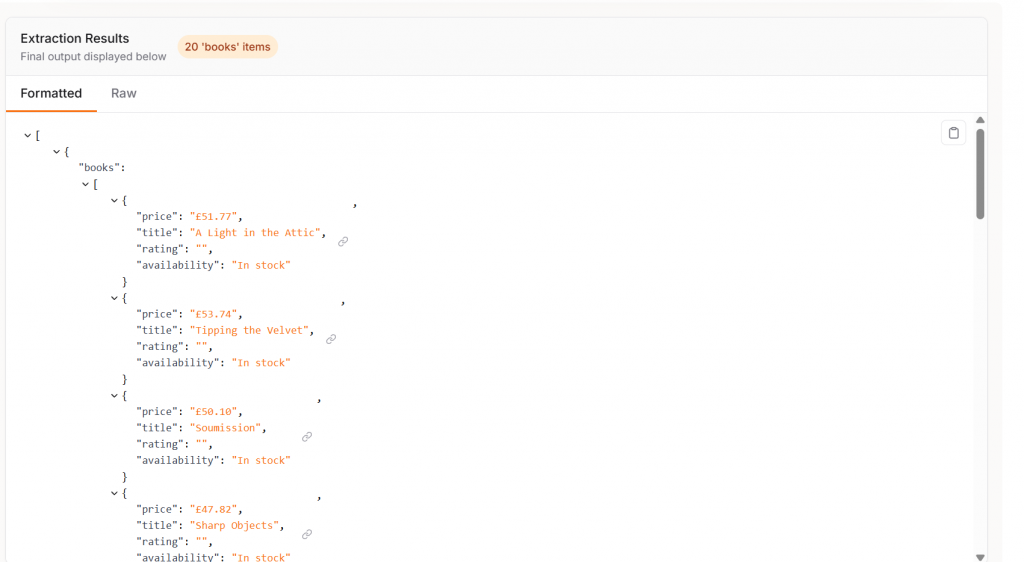
Mit Firecrawl Extract ist unsere Ausgabe sauber und sofort einsatzbereit. Wie Sie sehen können, erhalten wir strukturierte JSON-Objekte mit den folgenden Merkmalen.
TitelPreisBewertungVerfügbarkeit
Sicherheit und Compliance
Crawl4AI
Crawl4AI bietet keine in die Software integrierte Compliance-Garantie. Es werden einige Konfigurationen angeboten, die Sie bei der Einhaltung von Dingen wie der robots.txt-Datei unterstützen können.
Wenn Sie Crawl4AI nutzen, sind Sie selbst für die Einhaltung von Gesetzen wie GDPR und CCPA verantwortlich. Crawl4AI bietet fast keine Hilfe bei der Einhaltung von Gesetzen und Sicherheitsvorschriften. Das bedeutet, dass Sie, wenn Sie ein Projekt in großem Umfang durchführen, wahrscheinlich zusätzliche Hilfe in Anspruch nehmen müssen, um sicherzustellen, dass Sie die richtigen Praktiken befolgen.
Firecrawl
Laut der Dokumentation gibt Firecrawl Ihre Daten zur Verarbeitung an Google weiter. Firecrawl weist in seinen Nutzungsbedingungen ausdrücklich darauf hin, dass es die GDPR und das CCPA befolgt, dass Sie aber verpflichtet sind, diese Richtlinien selbst einzuhalten. Jeder Verstoß gegen diese Gesetze liegt in Ihrer Verantwortung und Firecrawl ist nicht für den Missbrauch seiner Tools verantwortlich.
Firecrawl bietet zwar mehr Haftungsschutz als Crawl4AI. Allerdings ist das immer noch nicht viel. Ihre Produkte haben keine Leitplanken. Es wird von Ihnen erwartet, dass Sie die Regeln befolgen, und wenn Sie das nicht tun, sind Sie für jeden Missbrauch haftbar. Weitere Informationen finden Sie in den vollständigen Firecrawl-Servicebedingungen.
Preisgestaltung und Lizenzierung
Crawl4AI
Die Nutzung von Crawl4AI ist für jeden kostenlos. Wir verwenden den Begriff “kostenlos” hier ziemlich locker. Wie Sie wahrscheinlich bemerkt haben, wenn Sie uns folgen, erfordert jede echte Extraktionsarbeit die Integration des LLM. Sie können den LLM entweder selbst hosten oder an einen Dienst wie die OpenAI API anschließen. Wenn Sie Crawl4AI verwenden, müssen Sie immer noch für externe Dienste oder Infrastrukturkosten bezahlen, wenn Sie selbst hosten. Diese Kosten summieren sich. Crawl4AI wird Ihre Betriebskosten nicht auf Null senken.
Crawl4AI wird unter der Apache-Lizenz vertrieben. Sie dürfen Crawl4AI-Derivate verändern, verbreiten und sogar kommerziell verkaufen. Wenn Sie Hilfe bei der Einhaltung von Vorschriften haben, macht die freizügige Lizenzierung von Crawl4AI es zu einer sehr attraktiven Option für Entwickler und Datenteams.
Firecrawl
Regelmäßiges Firecrawl
Vanilla Firecrawl gibt es in verschiedenen Preisstufen. Sie können den kostenlosen Plan ausprobieren. Ihre bezahlten Pläne reichen von $16/Monat für 3.000 Seiten bis hin zu $333/Monat für 500.000 Seiten.

Firecrawl-Auszug
Bei Verwendung von Extract reichen die kostenpflichtigen Pläne von $89/Monat für 18.000.000 Token pro Jahr bis zu $719/Monat für 192.000.000 API-Token pro Jahr.

Firecrawl-Lizenzierung
Firecrawl verwendet verschiedene Lizenzen für eine Vielzahl seiner Produkte. Sie können alle verschiedenen Lizenzen hier einsehen. Bitte beachten Sie, dass es sich bei Firecrawl um ein Produkt auf Unternehmensebene handelt und Sie nicht in der Lage sein werden, den Code als Ihren eigenen zu verpacken. Sogar der Open Source Code wird unter der AGPL-3.0 Lizenz vertrieben. Genau wie andere GNU-Software-Vereinbarungen ist diese Lizenz sehr restriktiv, wenn es um die Nutzung in Unternehmen geht.
Gemeinschaft und Unterstützung
Crawl4AI
Als Open-Source-Projekt bietet Crawl4AI so viel Unterstützung wie möglich mit den ihm zur Verfügung stehenden Ressourcen. Es gibt keinen Helpdesk oder SLA. Es steht Ihnen jedoch frei, die Entwickler über ihren Discord-Kanal zu kontaktieren. Die Wartezeiten können variieren. Erwarten Sie nicht, dass ein engagiertes Team Probleme verfolgt und Ihre Anforderungen zeitnah löst.
Firecrawl
Über das Dashboard bietet Firecrawl Ihnen Support-Optionen wie Dokumentation, FAQ-Seiten und Status-Updates. Sie können das Support-Team über die Schaltfläche “Support kontaktieren” kontaktieren – wobei die Priorität je nach Tarifstufe variiert. Sie können auch jederzeit dem Discord-Kanal beitreten, um Community-Support zu erhalten.

Anwendungsfälle aus der Praxis
Crawl4AI
Crawl4AI hat eine Vielzahl von realen Anwendungsfällen für moderne Entwickler. Sie sind nur durch das begrenzt, was Sie bauen können.
- Backend-Unterstützung: Wenn Sie sich entscheiden, Ihre eigenen Datenprodukte zu erstellen, können Sie Crawl4AI mit einem eigenen LLM integrieren und Ihre Produkte verkaufen.
- AI-Agenten: Wie wir bereits in diesem Artikel beschrieben haben, können Sie externe LLMs direkt in Crawl4AI einbinden, um leistungsstarke Extraktionsoperationen mit benutzerdefinierter Datenstruktur auszugeben – CSV, JSON XML – jedes Format, das Ihr LLM gesehen hat, ist ein brauchbares Format.
- Hobbyprojekte und Startups: Open-Source-Tools wie Crawl4AI bieten schnellen Zugang zu Experimenten, Proof of Concepts und Pipeline-Prototypen.
Firecrawl
Firecrawl wurde für Teams entwickelt, die ein hohes Volumen an Scraping mit sehr wenig Eigenentwicklung benötigen. Wenn Sie ohne viel Arbeit von einer Idee zu einem greifbaren Produkt kommen wollen, kann Firecrawl Ihnen dabei helfen.
- Crawling auf Produktionsniveau: Firecrawl ist für das Crawling in großem Umfang konzipiert. Ihre Tools crawlen standardmäßig sogar ganze Websites.
- Überwachung der Inhalte: Führen Sie routinemäßige Crawls bei Wettbewerbern durch, um deren Preise und Inhalte zu überwachen.
- Saubere und fertige Daten: Mit Extract können Sie Ihre Daten direkt an das Datenteam übergeben, ohne dass eine Bereinigung erforderlich ist.
Pro und Kontra
| Crawl4AI | Firecrawl | |
|---|---|---|
| Profis | – Vollständig quelloffen und transparent. – Freizügige Apache-Lizenz – erstellen, ändern, weiterverkaufen. – Flexibel: LLM-gestützte oder LLM-freie Optionen. – Plug-and-Play-Python-Bibliothek für benutzerdefinierte Pipelines. |
– Sehr einfach für Nicht-Entwickler: GUI, Spielplatz, NLP-Eingabeaufforderung. – Funktioniert in mehreren Sprachen (Python, JS, Go, Rust). – Schnell einsatzbereit für einmaliges oder routinemäßiges Scraping. – Preise und Supportstufen für Unternehmen verfügbar. |
| Nachteile | – Erfordert ein separates LLM für eine wirklich strukturierte Extraktion – dies verursacht zusätzliche versteckte Kosten. – Eingeschränkte integrierte Compliance-Unterstützung – der Benutzer muss GDPR/CCPA verwalten. – Async-Macken – Shell läuft am besten, IDEs können es kaputt machen. |
– Die Basisausgabe ist ohne Extract oft unübersichtlich – rohes Markdown erfordert mehr Arbeit. – Keine wirklichen Leitplanken für die Einhaltung von Vorschriften – der Benutzer haftet immer noch. – Closed-Source-Kern, AGPL-Beschränkungen begrenzen benutzerdefinierte Builds. – Die Nutzungskosten können durch Skalierung oder Wildcard-Crawling schnell ansteigen. |
Warum Sie Bright Data in Betracht ziehen sollten
Crawl4AI und Firecrawl haben beide Kompromisse. Crawl4AI kommt mit Entwicklerbedarf und versteckten LLM-Kosten. Mit Firecrawl sind Sie an die Nutzungsebenen und das Firecrawl-Ökosystem gebunden.
Bright Data bietet eine Reihe von Produkten an, die die gleichen Nischen wie die oben genannten Tools ausfüllen können.
Top Bright Data Tools
- Scraper-APIs: Führen Sie vorgefertigte Scraper mit sauberen, sofort verwendbaren Daten aus – wann immer Sie wollen.
- Web Unlocker API: Umgehen Sie Website-Sperren und lösen Sie CAPTCHAs, scrapen Sie als Markdown und kontrollieren Sie sogar Ihre Geolocation.
- Browser-API: Steuern Sie einen entfernten Browser mit integrierten Proxies und CAPTCHA-Lösung von Ihrer Programmierumgebung aus.
- Datensätze: Greifen Sie auf eine umfangreiche Bibliothek historischer Datensätze aus über 100 Bereichen zu, die Jahre zurückreichen.
Unser MCP Server verschafft Ihnen Zugang zu den besten Bright Data Produkten in einem LLM-freundlichen Paket. Schließen Sie ihn an Ihren LLM an, schreiben Sie Ihre Prompts und lassen Sie Ihr System seine Arbeit tun.
Helle Datenintegrationsoptionen
Wir bieten sogar die Integration mit einigen der besten Tools der heutigen KI- und Entwicklungsbranche. Wir fügen laufend neue Integrationen hinzu. Schauen Sie in unseren Dokumenten nach, um die aktuellste Liste zu erhalten.
Schlussfolgerung
Bei Bright Data lösen wir nicht nur ein Scraping-Problem – wir bieten ein ganzes Ökosystem für Ihren KI-Stack. Vom Sammeln von Live-Daten bis hin zum Anzapfen historischer Archive für das Training sorgen wir dafür, dass Sie Ihre Zeit mit Erkenntnissen und nicht mit der Infrastruktur verbringen.
Starten Sie noch heute Ihren kostenlosen Test und erleben Sie den Unterschied.





