

In diesem Leitfaden erfahren Sie mehr:
- Was LlamaIndex ist und warum er so häufig verwendet wird.
- Was es für die Entwicklung von KI-Agenten einzigartig macht, ist vor allem die integrierte Unterstützung für Datenintegrationen.
- Wie man LlamaIndex verwendet, um einen KI-Agenten zu erstellen, der Daten sowohl von allgemeinen Websites als auch von spezifischen Suchmaschinen abrufen kann.
Lasst uns eintauchen!
Was ist LlamaIndex?
LlamaIndex ist ein quelloffenes Python-Daten-Framework zur Erstellung von LLM-gestützten Anwendungen.
Sie hilft Ihnen, produktionsreife KI-Workflows und Agenten zu erstellen, die in der Lage sind, relevante Informationen zu finden und abzurufen, Erkenntnisse zu synthetisieren, detaillierte Berichte zu erstellen, automatisierte Aktionen durchzuführen und vieles mehr.
LlamaIndex ist eine der am schnellsten wachsenden Bibliotheken für den Aufbau von KI-Agenten, mit über 42k GitHub-Sternen:
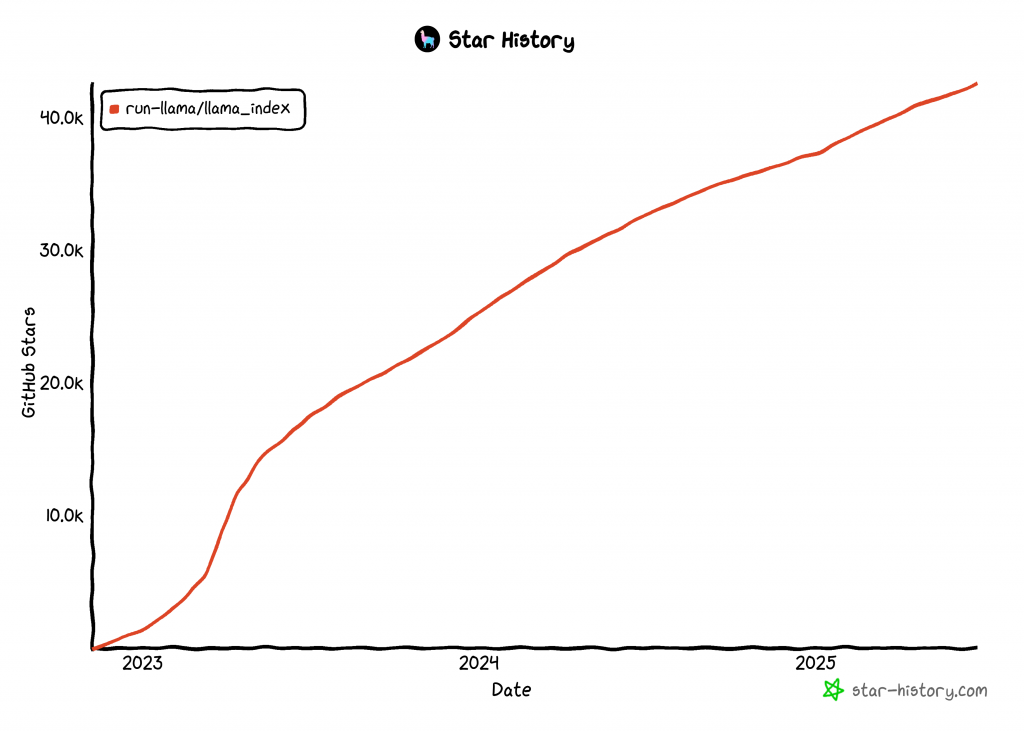
Integrieren Sie Daten in Ihren LlamaIndex AI Agent
Im Vergleich zu anderen Technologien zur Entwicklung von KI-Agenten konzentriert sich LlamaIndex auf Daten. Aus diesem Grund wird LlamaIndex im GitHub-Repository des Projekts als “Daten-Framework” definiert.
LlamaIndex befasst sich insbesondere mit einer der größten Einschränkungen von LLMs. Das ist ihr Mangel an Wissen über aktuelle oder Echtzeit-Ereignisse. Diese Einschränkung ergibt sich, weil LLMs auf statischen Datensätzen trainiert werden und keinen eingebauten Zugang zu aktuellen Informationen haben.
Um dieses Problem zu lösen, führt LlamaIndex die Unterstützung für Werkzeuge ein, die:
- Stellen Sie Datenkonnektoren zur Verfügung, um Daten aus APIs, PDFs, Word-Dokumenten, SQL-Datenbanken, Webseiten und vielem mehr zu übernehmen.
- Strukturieren Sie Ihre Daten mithilfe von Indizes, Diagrammen und anderen Formaten, die für den LLM-Verbrauch optimiert sind.
- Aktivieren Sie die erweiterte Suche, so dass Sie eine LLM-Eingabeaufforderung eingeben können und eine wissenserweiterte Antwort erhalten, die auf dem relevanten Kontext basiert.
- Unterstützung der nahtlosen Integration mit externen Frameworks wie LangChain, Flask, Docker und ChatGPT.
Mit anderen Worten, mit LlamaIndex zu bauen bedeutet typischerweise, die Kernbibliothek mit einer Reihe von Plugins/Integrationen zu kombinieren, die auf Ihren Anwendungsfall zugeschnitten sind. Betrachten Sie zum Beispiel ein LlamaIndex-Szenario für Web-Scraping.
Das Web ist heute die größte und umfassendste Datenquelle der Welt. Daher sollte ein KI-Agent idealerweise Zugriff darauf haben, um seine Antworten zu fundieren und Aufgaben effektiver zu erfüllen. Hier kommen die LlamaIndex Bright Data Tools ins Spiel!
Mit den Bright Data-Tools gewinnt Ihr LlamaIndex-KI-Agent:
- Echtzeit-Web-Scraping-Funktionalität von jeder beliebigen Webseite.
- Strukturierte Produkt- und Plattformdaten von Websites wie Amazon, LinkedIn, Zillow, Facebook und vielen anderen.
- Die Möglichkeit, Suchmaschinenergebnisse für jede Suchanfrage abzurufen.
- Visuelle Datenerfassung über ganzseitige Screenshots, nützlich für Zusammenfassungen oder visuelle Analysen.
Sehen Sie im nächsten Kapitel, wie diese Integration funktioniert!
Erstellen eines LlamaIndex-Agenten, der das Web mit Hilfe von Bright Data Tools durchsuchen kann
In diesem Abschnitt erfahren Sie Schritt für Schritt, wie Sie mit LlamaIndex einen Python-KI-Agenten erstellen, der mit Bright Data-Tools verbunden ist.
Durch diese Integration erhält Ihr Agent leistungsstarke Funktionen für den Zugriff auf Webdaten. Im Einzelnen erhält der KI-Agent die Möglichkeit, Inhalte aus beliebigen Webseiten zu extrahieren, Suchmaschinenergebnisse in Echtzeit abzurufen und vieles mehr. Weitere Informationen finden Sie in unserer offiziellen Dokumentation.
Befolgen Sie die folgenden Schritte, um mit LlamaIndex Ihren Bright Data-gestützten KI-Agenten zu erstellen!
Voraussetzungen
Für dieses Tutorial benötigen Sie Folgendes:
- Python 3.9 oder höher auf Ihrem Rechner installiert (die neueste Version wird empfohlen).
- Ein Bright Data-API-Schlüssel für die Integration mit
BrightDataToolSpec. - Einen API-Schlüssel eines unterstützten LLM-Anbieters (in diesem Leitfaden verwenden wir Gemini, der kostenlos über die API genutzt werden kann. Sie können aber auch jeden anderen von LlamaIndex unterstützten Anbieter verwenden).
Machen Sie sich keine Sorgen, wenn Sie noch keinen Gemini- oder Bright Data-API-Schlüssel haben. Wir zeigen Ihnen in den nächsten Schritten, wie Sie beides erstellen können.
Schritt #1: Erstellen Sie Ihr Python-Projekt
Öffnen Sie zunächst ein Terminal und erstellen Sie einen neuen Ordner für Ihr LlamaIndex-KI-Agentenprojekt:
mkdir llamaindex-bright-data-agentllamaindex-bright-data-agent/ enthält den Code für Ihren KI-Agenten mit Webdatenabfragefunktionen, die von Bright Data unterstützt werden.
Wechseln Sie dann in das Projektverzeichnis und erstellen Sie darin eine virtuelle Umgebung:
cd llamaindex-bright-data-agent
python -m venv venvÖffnen Sie nun den Projektordner in Ihrer bevorzugten Python-IDE. Wir empfehlen Visual Studio Code (mit der Python-Erweiterung) oder PyCharm Community Edition.
Erstellen Sie eine neue Datei namens agent.py im Stammverzeichnis des Ordners. Ihre Projektstruktur sollte nun wie folgt aussehen:
llamaindex-bright-data-agent/
├── venv/
└── agent.pyAktivieren Sie in Ihrem Terminal die virtuelle Umgebung. Unter Linux oder macOS führen Sie diesen Befehl aus:
source venv/bin/activateUnter Windows führen Sie entsprechend aus:
venv/Scripts/activateIn den nächsten Schritten werden wir Sie durch die Installation der erforderlichen Pakete führen. Wenn Sie es jedoch vorziehen, sie alle jetzt zu installieren, führen Sie aus:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-gemini llama-indexHinweis: Wir installieren llama-index-llms-gemini, weil dieses Tutorial Gemini als LLM-Anbieter verwendet. Wenn Sie vorhaben, einen anderen Anbieter zu verwenden, installieren Sie stattdessen die entsprechende LlamaIndex-Integration dafür.
Sie sind bereit! Sie verfügen nun über eine Python-Entwicklungsumgebung, um einen KI-Agenten mit LlamaIndex und Bright Data-Tools zu erstellen.
Schritt #2: Einrichten von Umgebungsvariablen Lesen
Ihr LlamaIndex-Agent stellt über API-Schlüssel eine Verbindung zu externen Diensten wie Gemini und Bright Data her. Aus Sicherheitsgründen sollten Sie API-Schlüssel niemals direkt in Ihren Python-Code codieren. Verwenden Sie stattdessen Umgebungsvariablen, um sie geheim zu halten.
Um die Arbeit mit Umgebungsvariablen zu erleichtern, installieren Sie die Bibliothek python-dotenv. Führen Sie in Ihrer aktivierten virtuellen Umgebung aus:
pip install python-dotenvÖffnen Sie dann Ihre agent.py-Datei und fügen Sie die folgenden Zeilen am Anfang ein, um Variablen aus einer .env-Datei zu laden:
from dotenv import load_dotenv
load_dotenv()Die Funktion load_dotenv() sucht im Stammverzeichnis des Projekts nach einer .env-Datei und lädt deren Werte automatisch in die Umgebung.
Erstellen Sie nun eine .env-Datei neben Ihrer agent.py-Datei, etwa so:
llamaindex-bright-data-agent/
├── venv/
├── .env # <-------------
└── agent.pyPerfekt! Sie haben nun eine sichere Methode zur Verwaltung sensibler API-Anmeldeinformationen für Dienste von Drittanbietern eingerichtet. Tim fährt mit der Ersteinrichtung fort, indem er die .env-Datei mit den erforderlichen envs auffüllt.
Schritt Nr. 3: Einstieg in die Arbeit mit Bright Data
Zum jetzigen Zeitpunkt stellt die BrightDataToolSpec die folgenden Tools in LlamaIndex bereit:
scrape_as_markdown: Liest den Rohinhalt einer beliebigen Webseite aus und gibt ihn im Markdown-Format zurück.get_screenshot: Erfasst einen ganzseitigen Screenshot einer Webseite und speichert ihn lokal.search_engine: Führt eine Suchanfrage bei Suchmaschinen wie Google, Bing, Yandex und anderen durch. Sie gibt die gesamte SERP oder eine JSON-strukturierte Version dieser Daten zurück.web_data_feed: Ruft strukturierte JSON-Daten von bekannten Plattformen ab.
Die ersten drei Tools – scrape_as_markdown, get_screenshot und search_engine - verwenden die Web Unlocker API von Bright Data. Diese Lösung öffnet die Tür zum Web Scraping und Screenshoting von jeder Website, auch von solchen mit strengem Anti-Bot-Schutz. Außerdem unterstützt sie den Zugriff auf SERP-Webdaten von allen wichtigen Suchmaschinen.
Im Gegensatz dazu nutzt web_data_feed die Web Scraper API von Bright Data. Dieser Endpunkt gibt vorstrukturierte Daten aus einer vordefinierten Liste von unterstützten Plattformen wie Amazon, Instagram, LinkedIn, ZoomInfo und anderen zurück.
Um diese Tools zu integrieren, müssen Sie Folgendes tun:
- Aktivieren Sie die Web Unlocker Lösung in Ihrem Bright Data Dashboard.
- Rufen Sie Ihr Bright Data-API-Token ab, das Zugriff auf die Web Unlocker- und Web Scraper-API gewährt.
Folgen Sie den nachstehenden Schritten, um die Einrichtung abzuschließen!
Wenn Sie noch kein Bright Data-Konto haben, sollten Sie zunächst ein Konto erstellen(). Wenn Sie bereits ein Konto haben, melden Sie sich an und öffnen Sie Ihr Dashboard. Klicken Sie auf die Schaltfläche “Proxy-Produkte abrufen”:
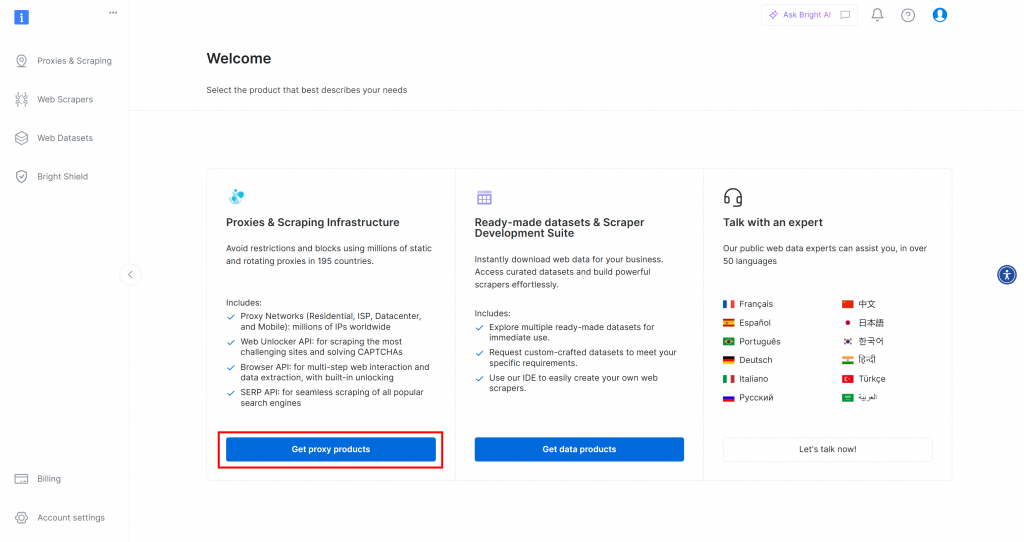
Sie werden auf die Seite “Proxies & Scraping-Infrastruktur” weitergeleitet:
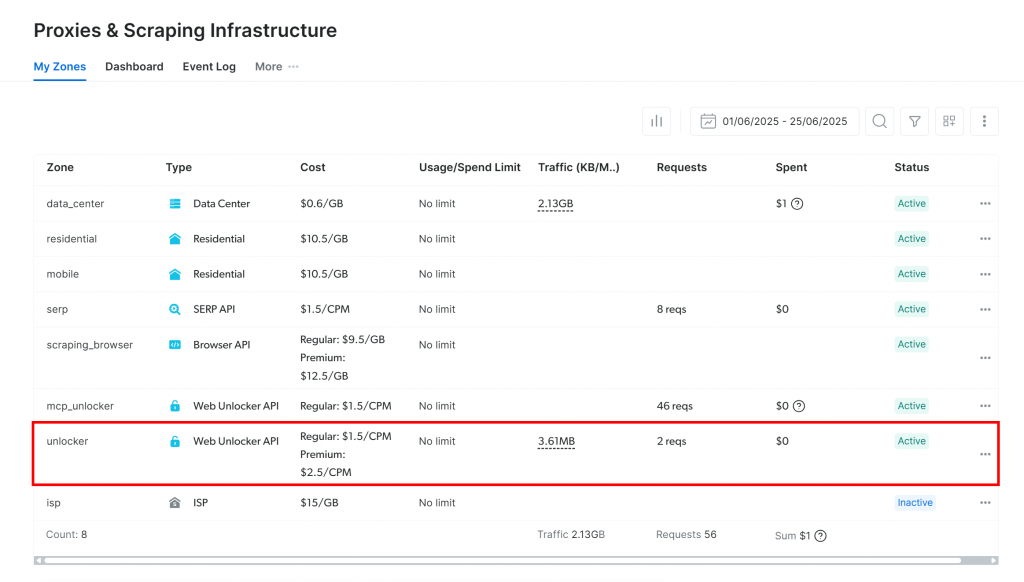
Wenn Sie bereits eine aktive Web Unlocker API-Zone sehen (wie oben), können Sie loslegen. Der Zonenname(in diesem Fallunlocker) ist wichtig, da Sie ihn später in Ihrem Code benötigen.
Wenn Sie noch keine haben, scrollen Sie zum Abschnitt “Web Unlocker API” und klicken Sie auf “Zone erstellen”:
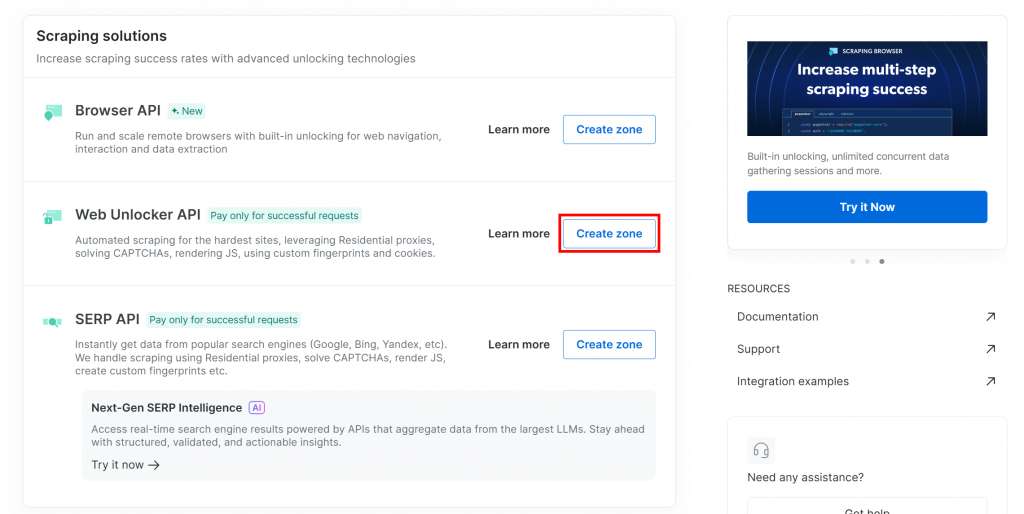
Geben Sie Ihrer neuen Zone einen Namen, z. B. unlocker, aktivieren Sie erweiterte Funktionen für eine bessere Leistung, und klicken Sie auf “Hinzufügen”:
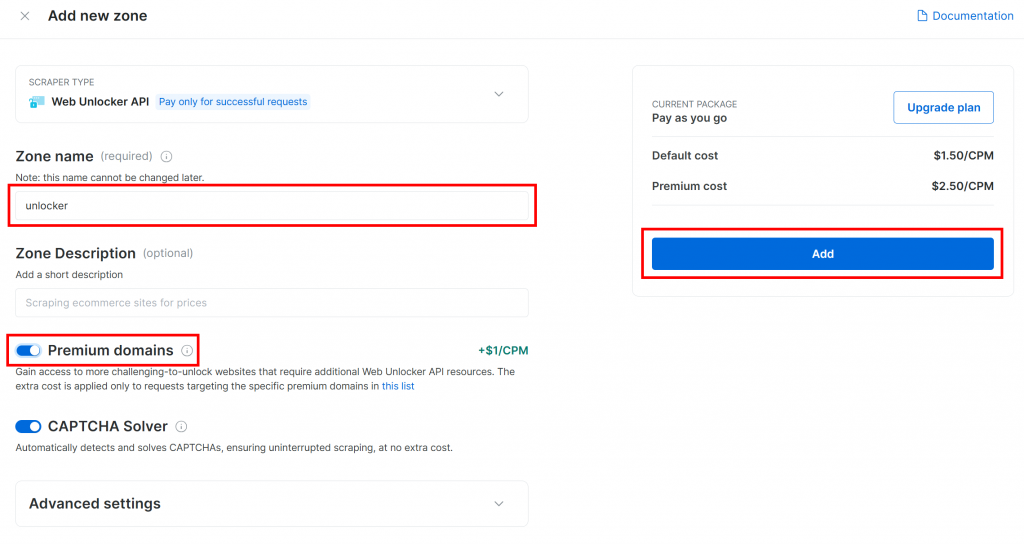
Sobald die Zone erstellt ist, werden Sie zur Konfigurationsseite der Zone weitergeleitet:
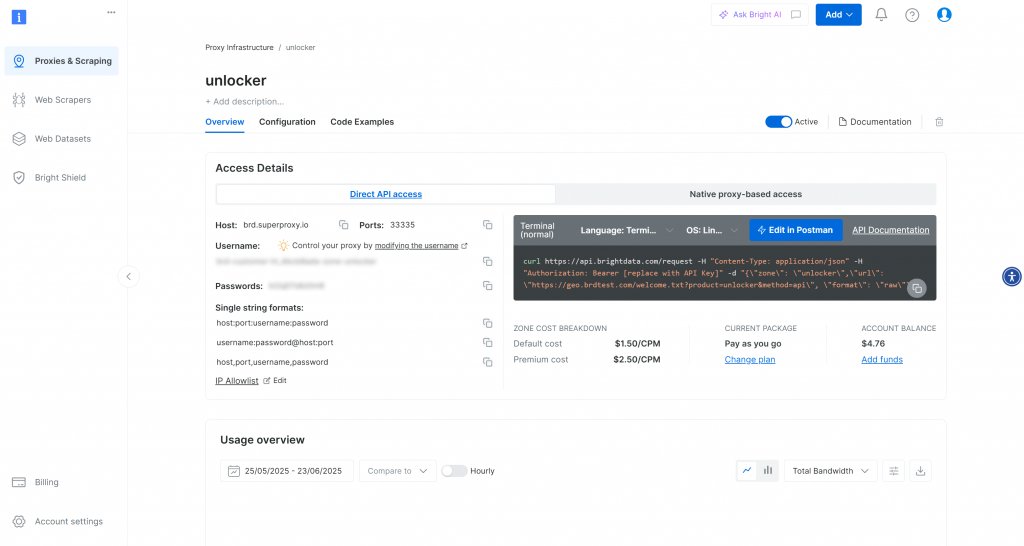
Stellen Sie sicher, dass der Aktivierungsschalter auf “Aktiv” steht. Dies bestätigt, dass die Zone richtig konfiguriert und einsatzbereit ist.
Folgen Sie anschließend der offiziellen Bright Data-Anleitung, um Ihren API-Schlüssel zu generieren. Sobald Sie ihn haben, speichern Sie ihn sicher in Ihrer .env-Datei wie folgt:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Ersetzen Sie den Platzhalter durch Ihren tatsächlichen API-Schlüsselwert.
Erstaunlich! Es ist an der Zeit, Bright Data-Tools in Ihr LlamaIndex-Agentenskript zu integrieren.
Schritt #4: Installieren und Konfigurieren der LlamaIndex Bright Data Tools
Laden Sie in agent.py zunächst Ihren Bright Data-API-Schlüssel aus der Umgebung:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Vergessen Sie nicht, os aus der Python-Standardbibliothek zu importieren:
import osWenn Ihre virtuelle Umgebung aktiviert ist, installieren Sie das LlamaIndex Bright Data Tools-Paket:
pip install llama-index-tools-brightdataImportieren Sie in Ihrer agent.py-Datei die Klasse BrightDataToolSpec:
from llama_index.tools.brightdata import BrightDataToolSpecErstellen Sie dann eine Instanz von BrightDataToolSpec mit Ihrem API-Schlüssel und dem Zonennamen:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="<BRIGHT_DATA_WEB_UNLOCKER_API_ZONE_NAME>", # Replace with the actual value
verbose=True, # Useful while developing
)Ersetzen Sie den Platzhalter durch den Namen der Web Unlocker API-Zone, die Sie zuvor eingerichtet haben. In diesem Fall ist es unlocker:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True,
)Beachten Sie, dass die Option verbose auf True gesetzt wurde. Dies ist bei der Entwicklung hilfreich, da es nützliche Informationen darüber ausgibt, was passiert, wenn der LlamaIndex-Agent über Bright Data Anfragen stellt.
Konvertieren Sie dann die Werkzeugspezifikation in eine Liste der verwendbaren Werkzeuge in Ihrem Agenten:
brightdata_tools = brightdata_tool_spec.to_tool_list()Fantastisch! Die Bright Data-Tools sind nun integriert und bereit, Ihren LlamaIndex-Agenten zu betreiben. Der nächste Schritt besteht darin, Ihr LLM zu verbinden.
Schritt Nr. 5: Vorbereitung des LLM-Modells
Um Gemini (den gewählten LLM-Anbieter) zu verwenden, installieren Sie zunächst das erforderliche Integrationspaket:
pip install llama-index-llms-google-genaiAls nächstes importieren Sie die Klasse GoogleGenAI aus dem installierten Paket:
from llama_index.llms.google_genai import GoogleGenAINun initialisieren Sie den Gemini LLM wie folgt:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)In diesem Beispiel verwenden wir das Modell Gemini-2.5-Flash. Sie können dieses Modell bei Bedarf gegen jedes andere unterstützte Gemini-Modell austauschen.
Hinter den Kulissen sucht GoogleGenAI automatisch nach einer Umgebungsvariablen namens GEMINI_API_KEY. Um sie zu setzen, öffnen Sie Ihre .env-Datei und fügen Sie die folgende Zeile hinzu:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Ersetzen Sie den Platzhalter durch Ihren tatsächlichen Gemini-API-Schlüssel. Wenn Sie keinen haben, können Sie ihn mit Hilfe der offiziellen Anleitung kostenlos abrufen.
Hinweis: Wenn Sie es vorziehen, einen anderen LLM-Anbieter zu verwenden, unterstützt LlamaIndex viele Optionen. Schauen Sie einfach in die offiziellen LlamaIndex-Dokumente für Anweisungen zur Einrichtung.
Gute Arbeit! Sie haben nun alle Kernkomponenten zusammengefügt, um einen LlamaIndex-Agenten mit Web-Datenabfrage-Fähigkeiten zu bauen.
Schritt #6: Erstellen Sie den LlamaIndex Agent
Installieren Sie zunächst das Hauptpaket von LlamaIndex:
pip install llama-indexDann importieren Sie in Ihrer agent.py-Datei die Klasse FunctionCallingAgent:
from llama_index.core.agent import FunctionCallingAgentFunctionCallingAgent ist ein spezieller Typ des LlamaIndex-KI-Agenten, der mit externen Tools interagieren kann, z. B. mit den Bright Data-Tools, die Sie zuvor konfiguriert haben.
Initialisieren Sie den Agenten mit Ihren LLM- und Bright Data-Tools wie folgt:
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)Damit wird ein KI-Agent eingerichtet, der Benutzereingaben mit Ihrem LLM verarbeitet und bei Bedarf Bright Data-Tools zum Abrufen von Informationen aufrufen kann. Das verbose=True-Flag ist während der Entwicklung praktisch, da es anzeigt, welche Tools der Agent für jede Anforderung verwendet.
Gut gemacht! Die Integration von LlamaIndex und Bright Data ist abgeschlossen. Der nächste Schritt besteht darin, die REPL für die interaktive Nutzung zu erstellen.
Schritt Nr. 7: Implementierung der REPL
REPL steht für “Read-Eval-Print Loop” und ist ein interaktives Programmiermuster, bei dem Sie Befehle eingeben, diese auswerten lassen und die Ergebnisse sofort sehen können. In diesem Zusammenhang, Sie:
- Geben Sie einen Befehl oder eine Aufgabe ein.
- Überlassen Sie es dem KI-Agenten, das Problem zu bewerten und zu lösen.
- Siehe die Antwort.
Diese Schleife läuft unendlich lange, bis Sie "exit" eingeben.
Im Umgang mit KI-Agenten ist die REPL in der Regel praktischer als das Senden isolierter Prompts. Der Grund dafür ist, dass Ihr LlamaIndex-Agent dadurch den Sitzungskontext beibehalten und seine Antworten verbessern kann, indem er aus früheren Interaktionen lernt.
Nun implementieren Sie die REPL-Logik in agent.py wie folgt:
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Diese REPL:
- Liest die Eingaben des Benutzers aus der Befehlszeile mit
input(). - Bewertet es mit dem LlamaIndex-Agenten von Gemini und Bright Data mit
agent.chat(). - Gibt die Antwort auf der Konsole aus.
Großartig! Der LlamaIndex-KI-Agent ist bereit.
Schritt Nr. 8: Alles zusammenstellen und den Agenten ausführen
Dies sollte Ihre agent.py-Datei jetzt enthalten:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent import FunctionCallingAgent
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker",
verbose=True, # Useful while developing
)
brightdata_tools = brightdata_tool_spec.to_tool_list()
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionCallingAgent.from_tools(
tools=brightdata_tools,
llm=llm,
verbose=True, # Useful while developing
)
# Implement the REPL interaction loop
print("Gemini-powered Agent with Bright Data tools for web data retrieval. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = agent.chat(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Führen Sie das Agentenskript mit dem folgenden Befehl aus:
python agent.pyWenn das Skript startet, sehen Sie etwa so aus:

Geben Sie die folgende Eingabeaufforderung in das Terminal ein:
Generate a report summarizing the most important information about the product "Death Stranding 2" using data from its Amazon page: "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"Das Ergebnis wird sein:
Das ging ziemlich schnell, also lassen Sie uns aufschlüsseln, was passiert ist:
- Der Agent erkennt, dass die Aufgabe Amazon-Produktdaten erfordert, und ruft daher das Tool
web_data_feedmit dieser Eingabe auf:{"source_type": "amazon_product", "url": "https://www.amazon.com/Death-Stranding-2-Beach-PlayStation-5/dp/B0F19GPDW3/"} - Dieses Tool fragt asynchron die Amazon Web Scraper API von Bright Data ab, um strukturierte Produktdaten abzurufen.
- Sobald die JSON-Antwort zurückgegeben wird, leitet der Agent sie an den Gemini LLM weiter.
- Gemini verarbeitet die neuen Daten und erstellt eine klare, präzise Zusammenfassung.
Mit anderen Worten: Der Agent wählt bei der Eingabeaufforderung intelligent das beste Werkzeug aus. In diesem Fall ist das web_data_feed. Damit werden Produktdaten in Echtzeit von der angegebenen Amazon-Seite in einem asynchronen Ansatz abgerufen. Anschließend verwendet der LLM diese Daten, um eine aussagekräftige Zusammenfassung zu erstellen.
In diesem Fall kehrte der KI-Agent zurück:
Here's a summary report for "Death Stranding 2: On The Beach - PS5" based on its Amazon product page:
**Product Report: Death Stranding 2: On The Beach - PS5**
* **Title:** Death Stranding 2: On The Beach - PS5
* **Brand/Manufacturer:** Sony Interactive Entertainment
* **Price:** $69.99 USD
* **Release Date:** June 26, 2026
* **Availability:** Available for pre-order.
**Description:**
"Death Stranding 2: On The Beach" is an upcoming PlayStation 5 title from legendary game creator Hideo Kojima. Players will embark on a new journey with Sam and his companions to save humanity from extinction, traversing a world filled with otherworldly enemies and obstacles. The game explores the question of human connection and promises to once again change the world through its unique narrative and gameplay.
**Key Features:**
* **Pre-order Bonus:** Includes Quokka Hologram, Battle Skeleton Silver (LV1,LV2,LV3), Boost Skeleton Silver (LV1,LV2,LV3), and Bokka Silver (LV1,LV2,LV3).
* **Open World:** Features large, varied open-world environments with unique challenges.
* **Gameplay Choices:** Offers multiple approaches to combat and stealth, allowing players to choose between aggressive tactics, sneaking, or avoiding danger.
* **New Story:** Continues the narrative from the original Death Stranding, following Sam on a fresh journey with unexpected twists.
* **Player Interaction:** Player actions can influence how other players interact with the game's world.
**Category & Ranking:**
* **Categories:** Video Games, PlayStation 5, Games
* **Best Sellers Rank:** #10 in Video Games, #1 in PlayStation 5 Games
**Sales Performance:**
* **Bought in past month:** 7,000 unitsBeachten Sie, dass der KI-Agent ohne die Bright Data-Tools nicht in der Lage wäre, ein solches Ergebnis zu erzielen. Das liegt daran:
- Das gewählte Amazon-Produkt ist ein neues Produkt, und LLMs werden nicht auf solch frischen Daten trainiert.
- LLMs sind möglicherweise nicht in der Lage, Webseiten in Echtzeit selbst zu scrapen oder darauf zuzugreifen.
- Das Scraping von Amazon-Produkten ist aufgrund von strengen Anti-Bot-Systemen wie dem berüchtigten Amazon CAPTCHA bekanntermaßen schwierig.
Wichtig: Wenn Sie andere Aufforderungen ausprobieren, werden Sie feststellen, dass der Agent automatisch die entsprechenden konfigurierten Tools auswählt und verwendet, um die Daten abzurufen, die er für die Generierung von geerdeten Antworten benötigt.
Et voilà! Sie haben jetzt einen LlamaIndex-KI-Agenten mit erstklassigen Webdaten-Zugriffsfunktionen, die durch die Integration mit Bright Data unterstützt werden.
Schlussfolgerung
In diesem Artikel haben Sie gelernt, wie Sie mit LlamaIndex einen KI-Agenten mit Echtzeit-Zugriff auf Webdaten dank der Bright Data-Tools erstellen können.
Diese Integration gibt Ihrem Agenten die Möglichkeit, öffentliche Webinhalte im Markdown-Format, in strukturierten JSON-Formaten und sogar als Screenshots abzurufen. Das gilt sowohl für Websites als auch für Suchmaschinen.
Beachten Sie, dass die hier gezeigte Integration nur ein einfaches Beispiel ist. Wenn Sie fortschrittlichere Agenten erstellen möchten, benötigen Sie zuverlässige Tools zum Abrufen, Validieren und Umwandeln von Live-Webdaten. Genau dafür ist die KI-Infrastruktur von Bright Data ausgelegt.
Erstellen Sie ein kostenloses Bright Data-Konto und erkunden Sie unsere KI-fähigen Datentools noch heute!




