

In diesem Leitfaden erfahren Sie:
- Warum Web-Scraping eine hervorragende Methode ist, um LLMs mit Daten aus der realen Welt anzureichern
- Die Vorteile und Herausforderungen der Verwendung von Scraping-Daten in LangChain-Workflows
- Eine Bibliothek für die vereinfachte Integration von Scraping in LangChain
- Wie Sie in einem Schritt-für-Schritt-Tutorial eine vollständige LangChain-Web-Scraping-Integration erstellen
Lassen Sie uns loslegen!
Web-Scraping zur Optimierung Ihrer LLM-Anwendungen
Beim Web-Scraping werden Daten aus Webseiten abgerufen. Diese Daten können dann zur Unterstützung von RAG-Anwendungen (Retrieval-Augmented Generation) verwendet werden, indem sie in LLMs (Large Language Models) integriert werden.
RAG-Systeme benötigen Zugriff auf umfangreiche, aktuelle, domänenspezifische oder expansive Daten, die in statischen Datensätzen, die Sie online kaufen oder herunterladen können, nicht ohne Weiteres verfügbar sind. Web-Scraping schließt diese Lücke, indem es sowohl strukturierte Informationen aus verschiedenen Quellen wie Nachrichtenartikeln, Produktlisten und sozialen Medien bereitstellt.
Erfahren Sie mehr in unserem Artikel über das Sammeln von LLM-Trainingsdaten.
Vorteile und Herausforderungen der Verwendung von Scraping-Daten in LangChain
LangChain ist ein leistungsstarkes Framework für die Erstellung KI-gesteuerter Workflows, das eine vereinfachte Integration von LLMs mit verschiedenen Datenquellen ermöglicht. Es zeichnet sich durch Datenanalyse, Zusammenfassung und Beantwortung von Fragen aus, indem es LLMs mit domänenspezifischem Wissen in Echtzeit kombiniert. Die Beschaffung hochwertiger Daten ist jedoch immer ein Problem.
Web-Scraping kann dieses Problem lösen, bringt jedoch einige Herausforderungen mit sich, darunter Anti-Bot-Maßnahmen, CAPTCHAs und dynamische Websites. Die Wartung konformer und effizienter Scraper kann zudem zeitaufwändig und technisch komplex sein. Weitere Informationen finden Sie in unserem Leitfaden zu Anti-Scraping-Maßnahmen.
Diese Hürden können die Entwicklung von KI-gestützten Anwendungen, die auf Echtzeitdaten angewiesen sind, verlangsamen. Die Lösung? Die Web Scraper API von Bright Data– ein einsatzbereites Tool, das Scraping-Endpunkte für Hunderte von Websites bietet.
Mit erweiterten Funktionen wie IP-Rotation, CAPTCHA-Lösung und JavaScript-Rendering automatisiert Bright Data die Datenextraktion für Sie. Das gewährleistet eine zuverlässige, effiziente und problemlose Datenerfassung, die über einfache API-Aufrufe zugänglich ist.
LangChain Bright Data Tools
Sie könnten die Web-Scraping-API von Bright Data und andere Scraping-Tools zwar direkt in Ihren LangChain-Workflow integrieren, dafür wären jedoch benutzerdefinierte Logik und Boilerplate-Code erforderlich. Um Zeit und Aufwand zu sparen, sollten Sie das offizielle LangChain Bright Data-Integrationspaket langchain-brightdata bevorzugen.
Mit diesem Paket können Sie innerhalb von LangChain-Workflows eine Verbindung zu den Diensten von Bright Data herstellen. Insbesondere stellt es die folgenden Klassen zur Verfügung:
BrightDataSERP: Integriert sich in die SERP-API von Bright Data, um Suchmaschinenabfragen mit Geo-Targeting durchzuführen.BrightDataUnblocker: Arbeitet mit dem Web Unlocker von Bright Data zusammen, um auf Websites zuzugreifen, die möglicherweise geografisch beschränkt oder durch Anti-Bot-Systeme geschützt sind.BrightDataWebScraperAPI: Schnittstelle zur Web Scraper API von Bright Data, um strukturierte Daten aus verschiedenen Domänen zu extrahieren.
In diesem Tutorial konzentrieren wir uns auf die Verwendung der Klasse BrightDataWebScraperAPI. Zeit, sich anzusehen, wie das funktioniert!
LangChain-Web-Scraping mit Bright Data: Schritt-für-Schritt-Anleitung
In diesem Abschnitt erfahren Sie, wie Sie einen LangChain-Web-Scraping-Workflow erstellen. Das Ziel ist es, LangChain zu nutzen, um Inhalte aus einem LinkedIn-Profil mithilfe der Web Scraper API von Bright Data abzurufen und dann mit OpenAI zu bewerten, ob der Kandidat für eine bestimmte Stelle geeignet ist.
Wir verwenden meine öffentliche LinkedIn-Profilseite als Referenz, aber jedes andere LinkedIn-Profil funktioniert ebenfalls:
Hinweis: Was wir hier erstellen, ist nur ein Beispiel. Der Code, den Sie schreiben werden, lässt sich leicht an verschiedene Szenarien anpassen. Das bedeutet, dass er auch um zusätzliche Funktionen von LangChain erweitert werden kann. Sie könnten beispielsweise sogar einen RAG-Chatbot auf Basis von SERP-Daten erstellen.
Befolgen Sie die folgenden Schritte, um loszulegen!
Voraussetzungen
Um dieses Tutorial durchzuarbeiten, benötigen Sie Folgendes:
- Python 3+ auf Ihrem Rechner installiert
- Einen OpenAI-API-Schlüssel
- Ein Bright Data-Konto
Machen Sie sich keine Sorgen, wenn Ihnen etwas davon fehlt. Wir führen Sie durch den gesamten Prozess, von der Installation von Python bis zum Erhalt Ihrer OpenAI- und Bright Data-Anmeldedaten.
Schritt 1: Projekt einrichten
Überprüfen Sie zunächst, ob Python 3 auf Ihrem Computer installiert ist. Falls nicht, laden Sie es herunter und installieren Sie es.
Führen Sie diesen Befehl im Terminal aus, um einen Ordner für Ihr Projekt zu erstellen:
mkdir langchain-scrapinglangchain-scraping enthält Ihr Python-LangChain-Scraping-Projekt.
Navigieren Sie dann zum Projektordner und initialisieren Sie darin eine virtuelle Python-Umgebung:
cd langchain-scraping
python3 -m venv venvHinweis: Verwenden Sie unter Windows python anstelle von python3.
Öffnen Sie nun das Projektverzeichnis in Ihrer bevorzugten Python-IDE. PyCharm Community Edition oder Visual Studio Code mit der Python-Erweiterung sind dafür geeignet.
Fügen Sie in langchain-scraping eine Datei script.py hinzu. Dies ist ein leeres Python-Skript, das jedoch bald Ihre LangChain-Web-Scraping-Logik enthalten wird.
Aktivieren Sie die virtuelle Umgebung im Terminal der IDE unter Linux oder macOS mit dem folgenden Befehl:
source venv/bin/activateUnter Windows führen Sie folgenden Befehl aus:
venv/Scripts/activateSuper! Sie sind nun vollständig eingerichtet.
Schritt 2: Installieren Sie die erforderlichen Bibliotheken
Das Python LangChain-Scraping-Projekt basiert auf den folgenden Bibliotheken:
python-dotenv: Zum Laden von Umgebungsvariablen aus einer.env-Datei. Diese wird zur Verwaltung der API-Schlüssel von Bright Data und OpenAI verwendet.langchain-openai: LangChain-Integrationen für OpenAI über dasopenaiSDK.langchain-brightdata: LangChain-Integration mit Bright Data-Scraping-Diensten.
Installieren Sie in einer aktivierten virtuellen Umgebung alle Abhängigkeiten mit diesem Befehl:
pip install python-dotenv langchain-openai langchain-brightdataGroßartig! Sie sind nun bereit, eine Scraping-Logik zu schreiben.
Schritt 3: Bereiten Sie Ihr Projekt vor
Fügen Sie in script.py den folgenden Import hinzu:
from dotenv import load_dotenvErstellen Sie dann eine .env-Datei in Ihrem Projektordner, um alle Ihre Anmeldedaten zu speichern. So sollte Ihre aktuelle Projektdateistruktur aussehen:

Weisen Sie python-dotenv an, die Umgebungsvariablen aus .env zu laden, indem Sie diese Zeile in script.py einfügen:
load_dotenv()Cool! Jetzt ist es an der Zeit, die Web Scraper API-Lösung von Bright Data zu konfigurieren.
Schritt 4: Web Scraper API konfigurieren
Wie am Anfang dieses Artikels erwähnt, bringt das Web-Scraping einige Herausforderungen mit sich. Zum Glück wird es mit einer All-in-One-Lösung wie den Web Scraper APIs von Bright Data deutlich einfacher. Mit diesen APIs kannst du mühelos geparste Inhalte von über 120 Websites abrufen.
Um die Web Scraper API in LangChain mit langchain_brightdata einzurichten, befolgen Sie die nachstehenden Anweisungen. Eine allgemeine Einführung in die Lösung für Web-Scraping von Bright Data finden Sie in der offiziellen Dokumentation.
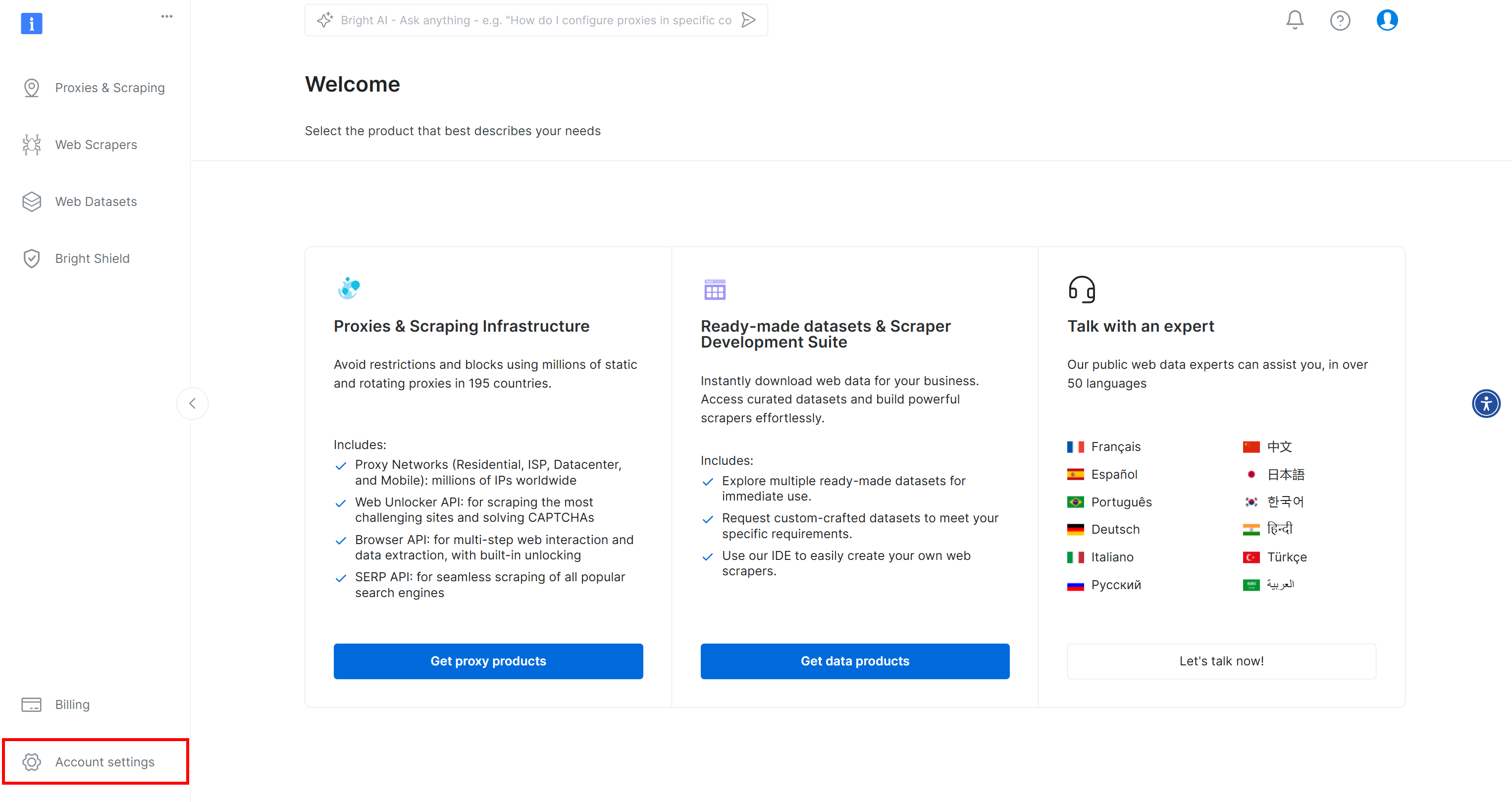
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie eines. Nach der Anmeldung werden Sie zu Ihrem Konto-Dashboard weitergeleitet. Klicken Sie hier auf die Schaltfläche „Kontoeinstellungen“ unten links:
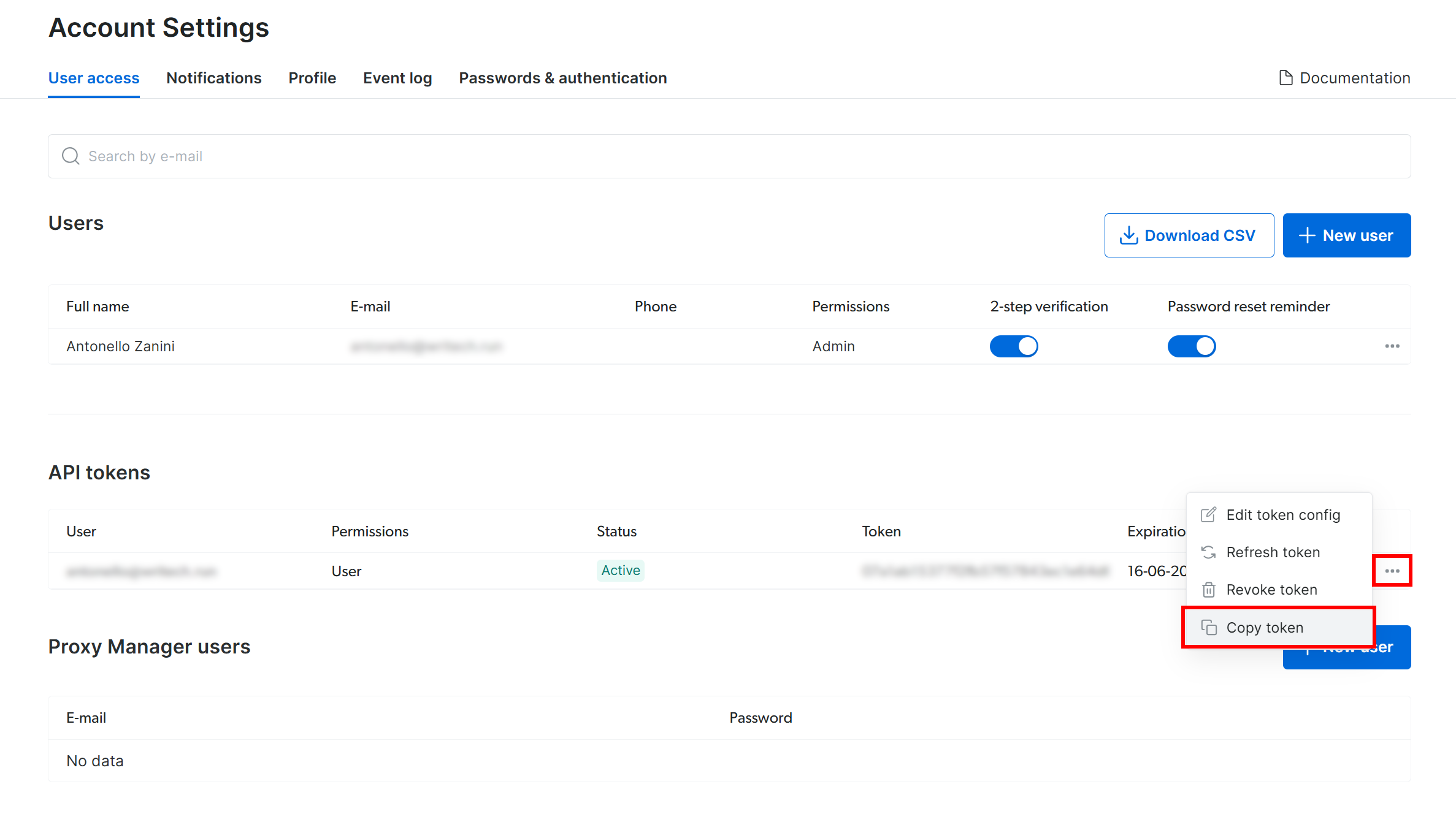
Wenn Sie auf der Seite „Kontoeinstellungen“ bereits einen Bright Data API-Token erstellt haben, klicken Sie auf „…“ und wählen Sie dann die Option „Token kopieren“:
Andernfalls klicken Sie auf die Schaltfläche „Token hinzufügen“:
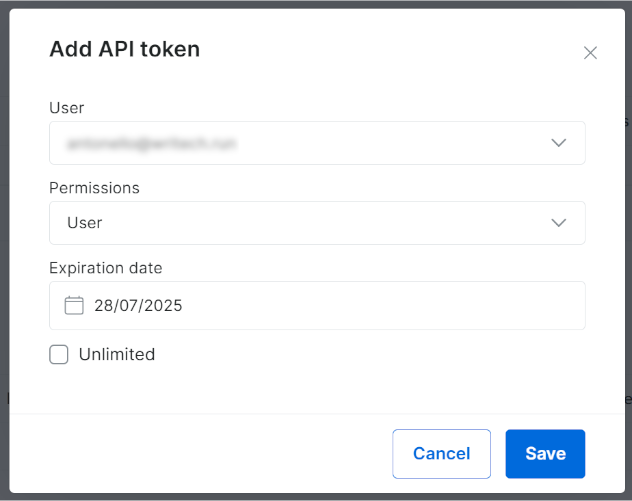
Das folgende Modalfenster wird angezeigt. Konfigurieren Sie Ihren Bright Data API-Token und klicken Sie auf die Schaltfläche „Speichern“:
Sie erhalten Ihren neuen API-Token:
Kopieren Sie den Wert Ihres Bright Data API-Schlüssels.
Speichern Sie diese Informationen in Ihrer .env -Datei als Umgebungsvariable BRIGHT_DATA_API_KEY:
BRIGHT_DATA_API_KEY="<IHR_BRIGHT_DATA_API_SCHLÜSSEL>"Ersetzen Sie <IHR_BRIGHT_DATA_API_SCHLÜSSEL> durch den Wert, den Sie aus dem Modal/der Tabelle kopiert haben.
Importieren Sie nun in script.py langchain_brightdata:
from langchain_brightdata import BrightDataWebScraperAPIEs sind keine weiteren Maßnahmen erforderlich, da langchain_brightdata automatisch versucht, den Bright Data API-Schlüssel aus der Umgebungsvariablen BRIGHT_DATA_API_KEY zu lesen.
Das war’s schon! Sie können nun die Web Scraper API in LangChain verwenden.
Schritt 5: Bright Data für das Web-Scraping verwenden
langchain_brightdata unterstützt die Integration mit der Web Scraper API von Bright Data über die Klasse BrightDataWebScraperAPI.
Nachfolgend finden Sie eine Übersicht über die Funktionsweise dieser Klasse:
- Sie sendet eine synchrone Anfrage an die konfigurierte Web-Scraper-API und akzeptiert die URL der zu scrapendenden Seite.
- Eine cloudbasierte Scraping-Aufgabe wird gestartet, um Daten von der angegebenen URL abzurufen und zu parsen.
- Die Bibliothek wartet, bis die Scraping-Aufgabe beendet ist, und gibt dann die gescrapten Daten im JSON-Format zurück.
Um das Web-Scraping in Ihren LangChain-Workflow zu integrieren, definieren Sie eine wiederverwendbare Funktion mit dem folgenden Code:
def get_scraped_data(url, dataset_type):
# Initialisieren Sie die LangChain Bright Data Scraper API-Integrationsklasse.
web_scraper_api = BrightDataWebScraperAPI()
# Abrufen der gewünschten Daten durch Verbindung mit der Web Scraper API
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return resultsDie Funktion akzeptiert die folgenden Argumente:
url: Die URL der Seite, von der Daten abgerufen werden sollen.dataset_type: Gibt den Typ der Web-Scraper-API an, die zum Extrahieren von Daten aus der Seite verwendet werden soll. Beispielsweise weist„linkedin_person_profile“die Web-Scraper-API an, Daten aus der angegebenen öffentlichen LinkedIn-Profil-URL zu scrapen.
In diesem Beispiel rufen Sie sie wie folgt auf:
url = „https://linkedin.com/in/antonello-zanini“
scraped_data = get_scraped_data(url, „linkedin_person_profile“)scraped_data enthält Daten wie diese:
{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
# Der Kürze halber ausgelassen...
"about": "Ich bin freiberuflicher Softwareentwickler, technischer Redakteur und technischer Autor mit Hunderten...",
"current_company": {
"name": "Freiberuflich"
},
"current_company_name": "Freiberuflich",
# Der Kürze halber ausgelassen...
„languages”: [
{
„title”: „Italienisch”,
„subtitle”: „Muttersprachliche oder zweisprachige Kenntnisse”
},
{
„title”: „Englisch”,
„subtitle”: „Vollständige professionelle Kenntnisse”
},
{
„title”: „Spanisch”,
„subtitle”: „Vollständige professionelle Kenntnisse”
}
],
„recommendations_count”: 32,
„recommendations”: [
# Der Kürze halber ausgelassen...
],
„posts”: [
# Der Kürze halber ausgelassen...
],
"activity": [
# Der Kürze halber ausgelassen...
],
# Der Kürze halber ausgelassen...
}Im Detail speichert es alle Informationen, die auf der öffentlichen Version der Ziel-LinkedIn-Profilseite verfügbar sind – jedoch im JSON-Format strukturiert. Um diese Daten zu erhalten, hat die Web Scraper API alle Anti-Bot- oder Anti-Scraping-Mechanismen für Sie umgangen.
Unglaublich! Sie haben gerade gelernt, wie Sie die Scraper-API von Bright Data Web für das Web-Scraping in LangChain verwenden können.
Schritt 6: Bereiten Sie sich auf die Verwendung von OpenAI-Modellen vor
Dieses Beispiel basiert auf OpenAI-Modellen für die LLM-Integration in LangChain. Um diese Modelle zu verwenden, müssen Sie einen OpenAI-API-Schlüssel in Ihren Umgebungsvariablen konfigurieren.
Fügen Sie daher die folgende Zeile zu Ihrer .env -Datei hinzu:
OPENAI_API_KEY="<YOUR_OPEN_API_KEY>"Ersetzen Sie <IHR_OPENAI_API_SCHLÜSSEL> durch den Wert Ihres OpenAI-API-Schlüssels. Wenn Sie nicht wissen, wie Sie einen solchen Schlüssel erhalten, folgen Sie der offiziellen Anleitung.
Importieren Sie nun in script.py langchain_openai wie folgt:
from langchain_openai import ChatOpenAISie müssen nichts weiter tun. langchain_openai sucht automatisch nach Ihrem OpenAI-API-Schlüssel in der Umgebungsvariablen OPENAI_API_KEY.
Großartig! Jetzt können Sie OpenAI-Modelle in Ihrem LangChain-Scraping-Skript verwenden.
Schritt 7: Generieren Sie die LLM-Eingabeaufforderung
Definieren Sie eine f-String-Variable, die die gescrapten Daten übernimmt und eine Eingabeaufforderung für das LLM generiert. In diesem Fall enthält die Eingabeaufforderung Ihre HR-Anfrage und bettet die gescrapten Kandidatendaten ein:
prompt = f"""
„Glauben Sie, dass dieser Kandidat gut für eine Remote-Position als Softwareentwickler geeignet ist? Warum?
Beantworten Sie diese Frage mit maximal 150 Wörtern.
KANDIDAT:
'{scraped_data}'
"""In diesem Beispiel erstellen Sie einen HR-Berater-KI-Workflow mit LangChain. Dank der Flexibilität der Web Scraper API (die über 120 Domänen unterstützt) in Kombination mit LLMs können Sie diesen Ansatz leicht anpassen, um eine Vielzahl anderer LangChain-Workflows zu unterstützen.
💡 Idee: Für noch mehr Flexibilität sollten Sie die Eingabeaufforderung aus der .env-Datei lesen.
Im aktuellen Beispiel lautet die vollständige Eingabeaufforderung:
Glauben Sie, dass dieser Kandidat für eine Remote-Stelle als Softwareentwickler geeignet ist? Warum?
Beantworten Sie diese Frage in maximal 150 Wörtern.
KANDIDAT:
'{
"input": {
"url": "https://linkedin.com/in/antonello-zanini"
},
"id": "antonello-zanini",
"name": "Antonello Zanini",
// der Kürze halber ausgelassen...
"about": "Ich bin freiberuflicher Softwareentwickler, technischer Redakteur und technischer Autor mit Hunderten...",
},
[der Kürze halber ausgelassen...]'Wenn Sie dies an ChatGPT übergeben, sollten Sie das gewünschte Ergebnis erhalten:
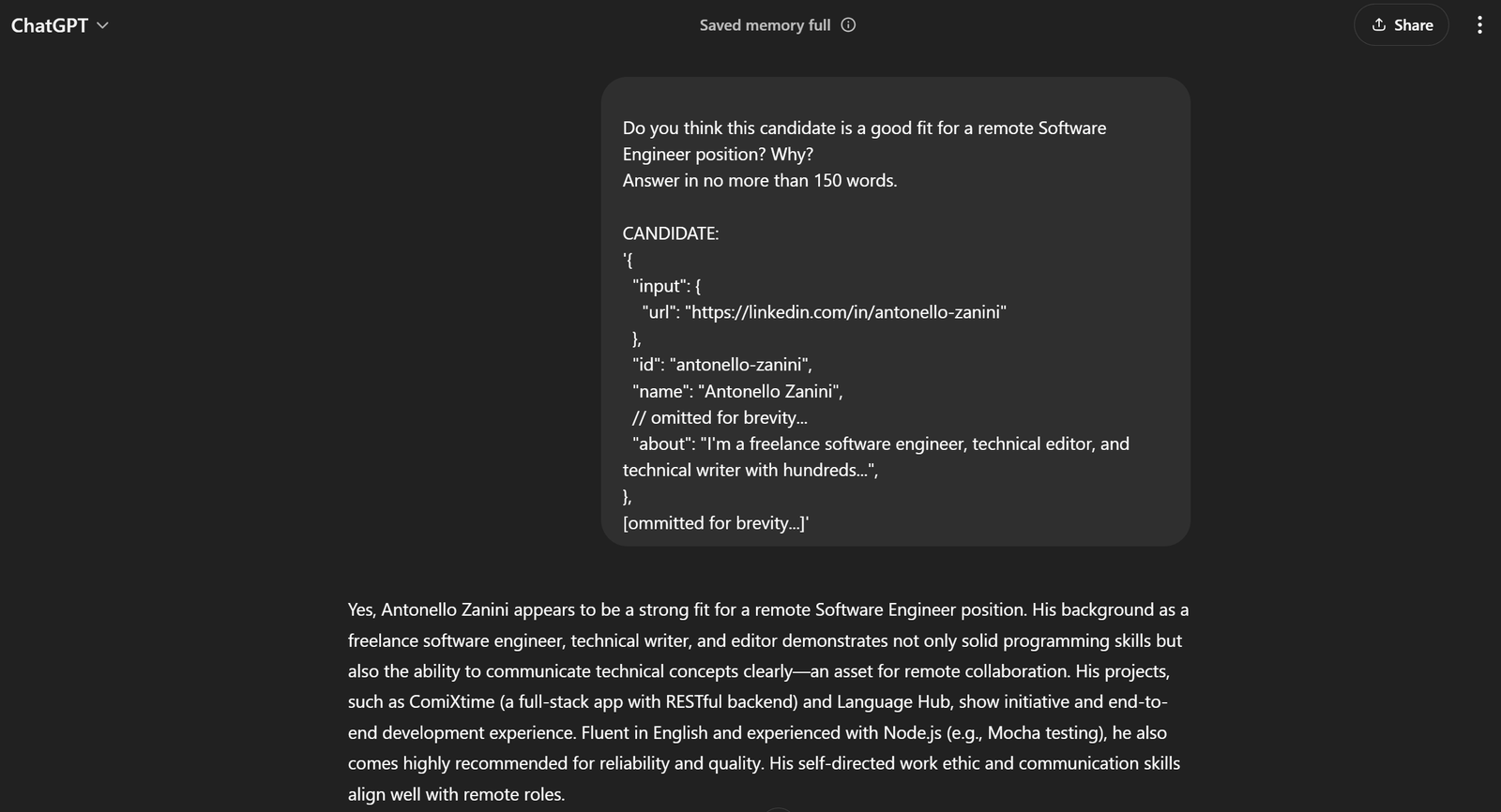
Das reicht aus, um zu erkennen, dass die Eingabeaufforderung hervorragend funktioniert!
Schritt 8: OpenAI integrieren
Übergeben Sie die zuvor generierte Eingabeaufforderung an ein ChatOpenAI LangChain-Objekt, das auf dem GPT-4o mini -KI-Modell konfiguriert ist:
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)Am Ende der KI-Verarbeitung sollte response.content ein Ergebnis enthalten, das der im vorherigen Schritt von ChatGPT generierten Bewertung ähnelt. Greifen Sie auf diese Textantwort zu mit:
evaluation = response.contentWow! Die LangChain-Web-Scraping-Logik ist fertig.
Schritt 9: Exportieren Sie die KI-verarbeiteten Daten
Jetzt müssen Sie nur noch die vom ausgewählten KI-Modell generierten Daten über LangChain in ein für Menschen lesbares Format, z. B. eine JSON-Datei, exportieren.
Initialisieren Sie zunächst ein Wörterbuch mit den gewünschten Daten. Exportieren Sie es anschließend und speichern Sie es als JSON-Datei, wie unten gezeigt:
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)Importieren Sie json aus der Python-Standardbibliothek:
import jsonHerzlichen Glückwunsch! Ihr Skript ist fertig.
Schritt 10: Fügen Sie einige Protokolle hinzu
Der Scraping-Prozess mit Web-Scraping und ChatGPT-Analyse kann einige Zeit in Anspruch nehmen. Dies ist aufgrund des Aufwands für das Scraping und die Verarbeitung von Daten aus Drittanbieterdiensten normal. Daher empfiehlt es sich, Protokolle einzufügen, um den Fortschritt des Skripts zu verfolgen.
Fügen Sie dazu an wichtigen Stellen im Skript wie folgt Print -Anweisungen hinzu:
url = "https://linkedin.com/in/antonello-zanini"
print(f"Scraping data with Web Scraper API from {url}...")
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("Data successfully scrapedn")
print("Erstellen der KI-Eingabeaufforderung...")
prompt = f"""
"Glauben Sie, dass dieser Kandidat für eine Remote-Stelle als Softwareentwickler geeignet ist? Warum?
Beantworten Sie diese Frage in maximal 150 Wörtern.
KANDIDAT:
'{scraped_data}'
"""
print("Eingabeaufforderung erstelltn")
print("Prompt wird an ChatGPT gesendet...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
evaluation = response.content
print("Antwort von ChatGPT erhaltenn")
print("Daten werden in JSON exportiert"...)
export_data = {
"url": url,
"evaluation": evaluation
}
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Daten nach '{file_name}' exportiertn")Beachten Sie, dass jeder Schritt des LangChain-Web-Scraping-Workflows klar protokolliert wird. Die Ausführung im Terminal ist nun viel einfacher zu verfolgen.
Schritt 11: Alles zusammenfügen
Ihre endgültige script.py -Datei sollte Folgendes enthalten:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_openai import ChatOpenAI
import json
# Laden Sie die Umgebungsvariablen aus der .env-Datei.
load_dotenv()
def get_scraped_data(url, dataset_type):
# Initialisieren Sie die LangChain Bright Data Scraper API-Integrationsklasse.
web_scraper_api = BrightDataWebScraperAPI()
# Die gewünschten Daten durch Verbindung mit der Web Scraper API abrufen
results = web_scraper_api.invoke({
"url": url,
"dataset_type": dataset_type
})
return results
# Den Inhalt der angegebenen Webseite abrufen
url = "https://linkedin.com/in/antonello-zanini"
print(f"Scraping data with Web Scraper API from {url}...")
# Verwenden Sie die Web Scraper API, um die gescrapten Daten abzurufen
scraped_data = get_scraped_data(url, "linkedin_person_profile")
print("Daten erfolgreich gescraptn")
print("Erstellen der KI-Eingabeaufforderung...")
# Definieren Sie die Eingabeaufforderung unter Verwendung der gescrapten Daten als Kontext
prompt = f"""
"Glauben Sie, dass dieser Kandidat für eine Remote-Stelle als Softwareentwickler geeignet ist? Warum?
Beantworten Sie diese Frage mit maximal 150 Wörtern.
KANDIDAT:
'{scraped_data}'
"""
print("Prompt erstelltn")
# ChatGPT bitten, die in der Eingabeaufforderung angegebene Aufgabe auszuführen
print("Senden der Eingabeaufforderung an ChatGPT...")
model = ChatOpenAI(model="gpt-4o-mini")
response = model.invoke(prompt)
# KI-Ergebnis abrufen
evaluation = response.content
print("Antwort von ChatGPT empfangen")
print("Daten nach JSON exportieren...")
# Die erzeugten Daten nach JSON exportieren
export_data = {
"url": url,
"evaluation": evaluation
}
# Das Ausgabedictionary in eine JSON-Datei schreiben
file_name = "analysis.json"
with open(file_name, "w") as file:
json.dump(export_data, file, indent=4)
print(f"Daten nach '{file_name}' exportiert")Können Sie das glauben? Mit nur etwa 50 Zeilen Code haben Sie gerade ein KI-basiertes LangChain-Web-Scraping-Skript erstellt.
Überprüfen Sie mit diesem Befehl, ob es funktioniert:
python3 script.pyOder unter Windows:
python script.pyDie Ausgabe im Terminal sollte wie folgt lauten:
Web-Scraping von Daten mit der Web Scraper API von https://linkedin.com/in/antonello-zanini...
Daten erfolgreich gescrapt
Erstellen der KI-Eingabeaufforderung...
Eingabeaufforderung erstellt
Senden der Eingabeaufforderung an ChatGPT...
Antwort von ChatGPT empfangen
Exportieren der Daten nach JSON...
Daten nach „analysis.json” exportiertÖffnen Sie die Datei „analysis.json”, die im Projektverzeichnis angezeigt wird, und Sie sollten etwa Folgendes sehen:
{
"url": "https://linkedin.com/in/antonello-zanini",
"evaluation": "Antonello Zanini scheint ein starker Kandidat für eine Remote-Position als Softwareentwickler zu sein. Seine Erfahrung als freiberuflicher Softwareentwickler zeugt von Anpassungsfähigkeit und Eigenmotivation, was für die Remote-Arbeit entscheidend ist. Sein technischer Schreibstil und sein redaktioneller Hintergrund lassen auf ausgeprägte Kommunikationsfähigkeiten schließen, die für die Zusammenarbeit mit Remote-Teams unerlässlich sind. Darüber hinaus unterstreicht sein vielfältiges Programmierwissen, das sich in Beiträgen zu Unit-Tests und JavaScript-Bundlern zeigt, seine technische Expertise.nnEr hat von Kunden viel positives Feedback erhalten, das seine Zuverlässigkeit und Klarheit bei der Erbringung von Leistungen hervorhebt, was wichtige Eigenschaften für eine effektive Remote-Zusammenarbeit sind. Darüber hinaus können seine Mehrsprachigkeit in Italienisch, Englisch und Spanisch die Kommunikation in vielfältigen internationalen Teams verbessern. Insgesamt macht Antonellos Kombination aus technischer Kompetenz, Kommunikationsfähigkeiten und positiven Empfehlungen ihn zu einem hervorragenden Kandidaten für eine Remote-Position.
}Et voilà! Der mit Live-Daten angereicherte HR-LangChain-Workflow ist nun vollständig.
Fazit
In diesem Tutorial haben Sie erfahren, warum Web-Scraping eine effektive Methode zum Sammeln von Daten für Ihre KI-Workflows ist und wie Sie diese Daten mit LangChain analysieren können.
Konkret haben Sie ein Python-basiertes LangChain-Web-Scraping-Skript erstellt, um Daten aus einer LinkedIn-Profilseite zu extrahieren und diese mit OpenAI-APIs zu verarbeiten. Dieser LangChain-Workflow eignet sich zwar ideal für die Unterstützung von HR-Aufgaben, aber der gezeigte Code lässt sich leicht auf andere Workflows und Szenarien ausweiten.
Die größten Herausforderungen beim Web-Scraping in LangChain sind:
- Online-Seiten ändern häufig ihre Seitenstrukturen.
- Viele Websites implementieren fortschrittliche Anti-Bot-Maßnahmen.
- Das gleichzeitige Abrufen großer Datenmengen kann komplex und kostspielig sein.
Die Web Scraper API von Bright Data stellt eine effektive Lösung für die Extraktion von Daten aus großen Websites dar und überwindet diese Herausforderungen mühelos. Dank ihrer reibungslosen Integration in LangChain ist sie ein unschätzbares Werkzeug zur Unterstützung von RAG-Anwendungen und anderen LangChain-basierten Lösungen.
Entdecken Sie auch unsere weiteren Angebote für KI und LLM.
Melden Sie sich jetzt an, um herauszufinden, welche Proxy-Dienste oder Scraping-Produkte von Bright Data Ihren Anforderungen am besten entsprechen. Testen Sie sie gratis!




