
In diesem Blogbeitrag erfahren Sie:
- Warum Kubeflow Pipelines eine spezielle Komponente zur Erfassung von Webdaten enthalten sollten.
- Eine Anwendung dieses Ansatzes auf eine bestimmte TikTok-Sentimentanalyse-Pipeline.
- Wie Sie diese Pipeline implementieren, indem Sie sich über eine spezielle Scraping-Lösung mit den Kommentar-Datenfeeds von TikTok verbinden.
Lassen Sie uns eintauchen!
Warum Kubeflow Pipelines von strukturierten, aus dem Web gescrapten Daten profitieren
Moderne Machine-Learning- und KI-Workflows sind in hohem Maße auf hochwertige Daten angewiesen. Im Gegensatz dazu verarbeiten herkömmliche Pipelines häufig statische Datensätze oder vorverarbeitete Dateien. Diese Quellen können jedoch schnell veralten, sodass Modelle auf der Grundlage veralteter Informationen trainiert werden.
Hier kommen strukturierte, aus dem Web gescrapte Daten ins Spiel! Durch das Sammeln von Live-Kontextdaten aus dem Web können Pipelines mit den neuesten Trends, dem Nutzerverhalten und neuen Inhalten Schritt halten.
Kubeflow Pipelines, die für modulare, reproduzierbare und skalierbare ML-Workflows entwickelt wurden, profitieren enorm von der Integration von Komponenten zur Webdatenerfassung. Solche Komponenten liefern aktuelle, strukturierte Feeds, die automatisch erfasst, gefiltert und weiterverarbeitet werden können.
Eine Komponente zur Webdatenerfassung in Ihrer Pipeline trägt zweifellos zur Verbesserung der Modellgenauigkeit bei. Daher ist es strategisch sinnvoll, eine dedizierte Komponente zur Webdatenerfassung – oder sogar mehrere Komponenten für verschiedene Quellen – hinzuzufügen. Dadurch können sich Ihre Pipelines kontinuierlich anpassen, neu trainieren und Erkenntnisse nahezu in Echtzeit generieren, was eine solide Grundlage für jedes KI-gesteuerte Projekt schafft.
Vorstellung der Kubeflow-Pipeline für die Sentimentanalyse von TikTok
Um besser zu verstehen, wie eine Komponente zur Erfassung von Webdaten Kubeflow-Pipelines verbessert, betrachten wir ein Beispiel aus der Praxis. Stellen Sie sich vor, Sie möchten einen Datenanalyse-Workflow erstellen, der eine Reihe von TikTok-Beiträgen erfasst und deren Inhalt auf Stimmungen hin analysiert.
Sie könnten eine Pipeline mit zwei Komponenten entwerfen:
- TikTok-Kommentardatenkomponente: Ruft strukturierte Kommentardaten aus TikTok-Beiträgen per Web-Scraping ab.
- Datenanalyse-Komponente: Bereichert diese Kommentare mit Sentiment-Erkenntnissen (
positiv,negativoderneutral).
Das Problem ist, dass das Scraping von TikTok (oder vielen anderen beliebten Plattformen) bekanntermaßen eine Herausforderung darstellt. Das liegt an Anti-Scraping-Maßnahmen wie CAPTCHAs, JavaScript-Herausforderungen, IP-Blocks und Ratenbeschränkungen. Die Skalierung dieses Prozesses erhöht nur die Komplexität, da Drosselung und Sperren die Datenerfassung leicht stören können.
Um diese Probleme zu vermeiden, ist es sinnvoll, die Webdatenerfassungskomponente mit einem erstklassigen Webdatendienst wie Bright Data zu unterstützen. Bright Data ermöglicht groß angelegtes, zuverlässiges Web-Scraping mit einer hoch skalierbaren Infrastruktur, die auf 150 Millionen Proxy-IPs in 195 Ländern, einer Erfolgsquote von 99,95 % und einer Verfügbarkeit von 99,99 % basiert.
Im Detail werden wir TikTok Scraper nutzen, eine Web-Scraping-API, die entwickelt wurde, um die strukturierte Datenerfassung aus TikTok-Beiträgen zu vereinfachen. Dies ist eine von vielen Web-Scraping-APIs, die für das Abrufen von Daten aus beliebten Domains verfügbar sind. In ähnlicher Weise können Sie die Filter Dataset API verwenden, um gefilterte Daten aus Bright Data-Datensätzen abzurufen und Ihre ML/KI-Pipelines mit gebrauchsfertigen Daten zu versorgen.
So erstellen Sie eine Kubeflow-Pipeline mit einer dynamischen Web-Scraping-Datenkomponente
In diesem Abschnitt erfahren Sie, wie Sie die zuvor vorgestellte Kubeflow-Pipeline für die TikTok-Stimmungsanalyse erstellen.
Befolgen Sie die folgenden Schritte!
Voraussetzungen
Um dieses Tutorial durchzuführen, benötigen Sie:
- Docker muss auf Ihrem Rechner installiert sein und ausgeführt werden.
- Python 3.10+ lokal installiert.
- Ein Bright Data-Konto mit ordnungsgemäß konfiguriertem API-Schlüssel (Sie müssen sich jetzt noch nicht um die Einrichtung kümmern, da Sie in einem speziellen Unterabschnitt durch den Vorgang geführt werden).
Grundlegende Kenntnisse über die Funktionsweise von Kubeflow Pipelines helfen Ihnen ebenfalls, die folgenden Anweisungen zu verstehen.
Das empfohlene Betriebssystem für die Ausführung der folgenden Beispiele ist Linux, macOS oder WSL (Windows Subsystem for Linux).
Schritt 1: Projekt einrichten
Öffnen Sie zunächst Ihr Terminal und erstellen Sie ein neues Verzeichnis für das Kubeflow Pipelines-Projekt:
mkdir kfp-bright-data-pipelineWechseln Sie in das Projektverzeichnis und erstellen Sie darin eine virtuelle Python-Umgebung:
cd kfp-bright-data-pipeline
python -m venv .venvÖffnen Sie anschließend den Projektordner in Ihrer bevorzugten Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie eine neue Datei mit dem Namen tiktok_sentiment_analysis_kfp_pipeline.py im Stammverzeichnis des Projektverzeichnisses. Ihre Struktur sollte wie folgt aussehen:
kfp-bright-data-pipeline/
├── .venv/
└── tiktok_sentiment_analysis_kfp_pipeline.py # <-----------Aktivieren Sie die virtuelle Umgebung im Terminal der IDE. Unter Linux oder macOS führen Sie folgenden Befehl aus:
source venv/bin/activateUnter Windows führen Sie stattdessen folgenden Befehl aus:
venv/Scripts/activateInstallieren Sie nach Aktivierung der virtuellen Umgebung die erforderliche Abhängigkeit:
pip install kfpDie einzige erforderliche Bibliothek ist kfp, mit der Sie portable, skalierbare Machine-Learning-Pipelines erstellen und kompilieren können.
Öffnen Sie abschließend tiktok_sentiment_analysis_kfp_pipeline.py und importieren Sie die erforderlichen Module:
from kfp import dsl, compiler
from kfp.dsl import Input, Output, DatasetDas war’s schon! Sie verfügen nun über eine Python-Entwicklungsumgebung, in der Sie Ihre Kubeflow-Pipeline erstellen können.
Schritt 2: Erste Schritte mit Bright Data
Die erste Komponente Ihrer Pipeline ruft Live-Webdaten mithilfe der Web-Scraping-APIs von Bright Data ab. Bevor Sie diese implementieren, müssen Sie Ihr Bright Data-Konto ordnungsgemäß konfigurieren.
Da wir die Web-Scraping-APIs verwenden werden, sollten Sie sich ein paar Minuten Zeit nehmen, um die offiziellen Dokumente durchzulesen. Kurz gesagt, diese APIs liefern strukturierte Datenfeeds von beliebten Websites, die in ML/KI-Workflows (oder anderen unterstützten Anwendungsfällen) verwendet werden können.
Wenn Sie noch kein Konto haben, erstellen Sie eines. Andernfalls melden Sie sich an und öffnen Sie das Benutzer-Dashboard. Navigieren Sie von dort aus zum Abschnitt „Scrapers“: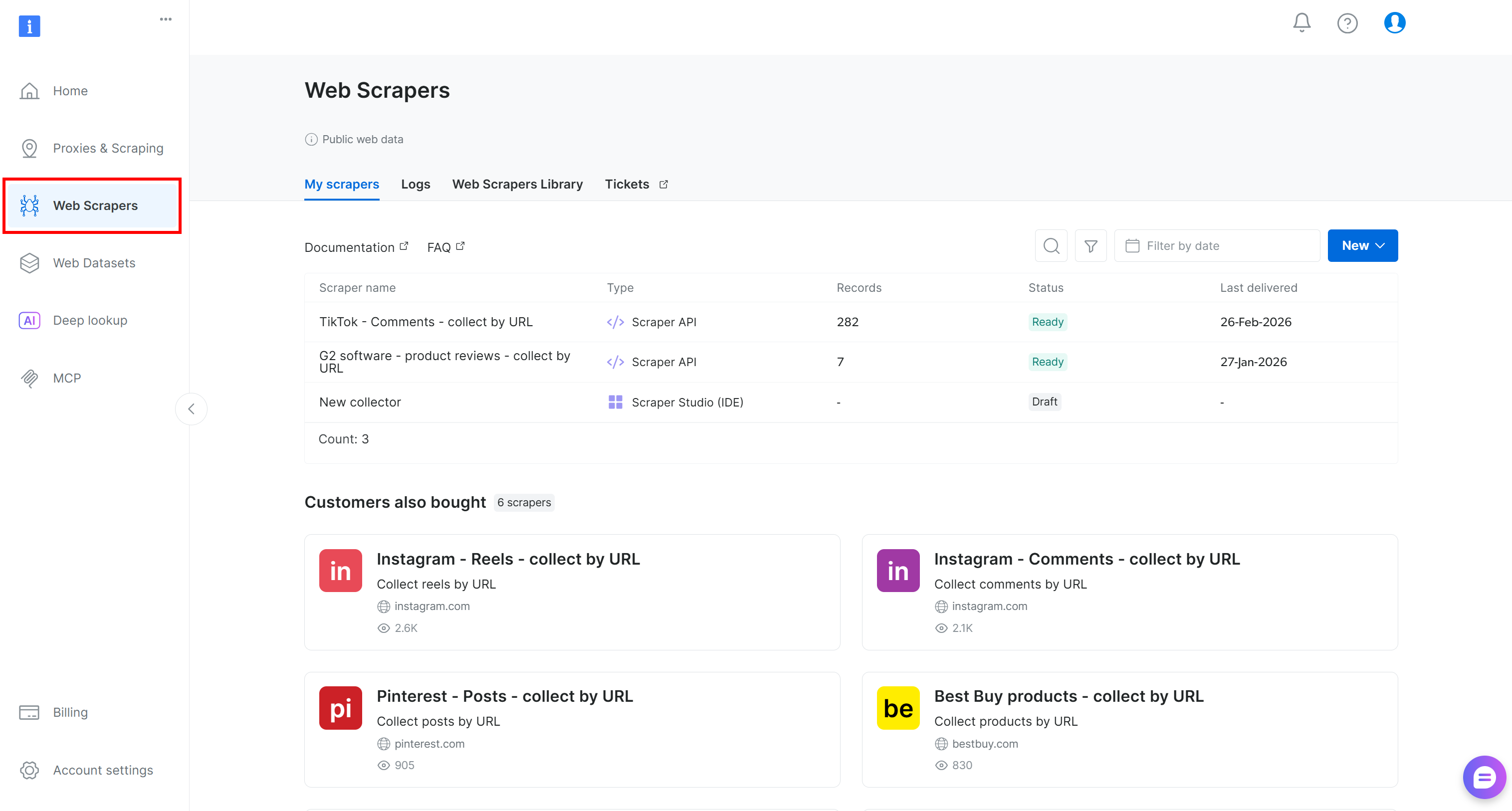
Gehen Sie zur Registerkarte „Web Scrapers Library”. Dort finden Sie über 120 vorgefertigte Scraper für einige der beliebtesten Plattformen im Internet.
Suchen Sie in diesem Tutorial nach „tiktok.com“, da unser Ziel darin besteht, Live-Kommentardaten aus TikTok-Beiträgen abzurufen und eine Stimmungsanalyse durchzuführen.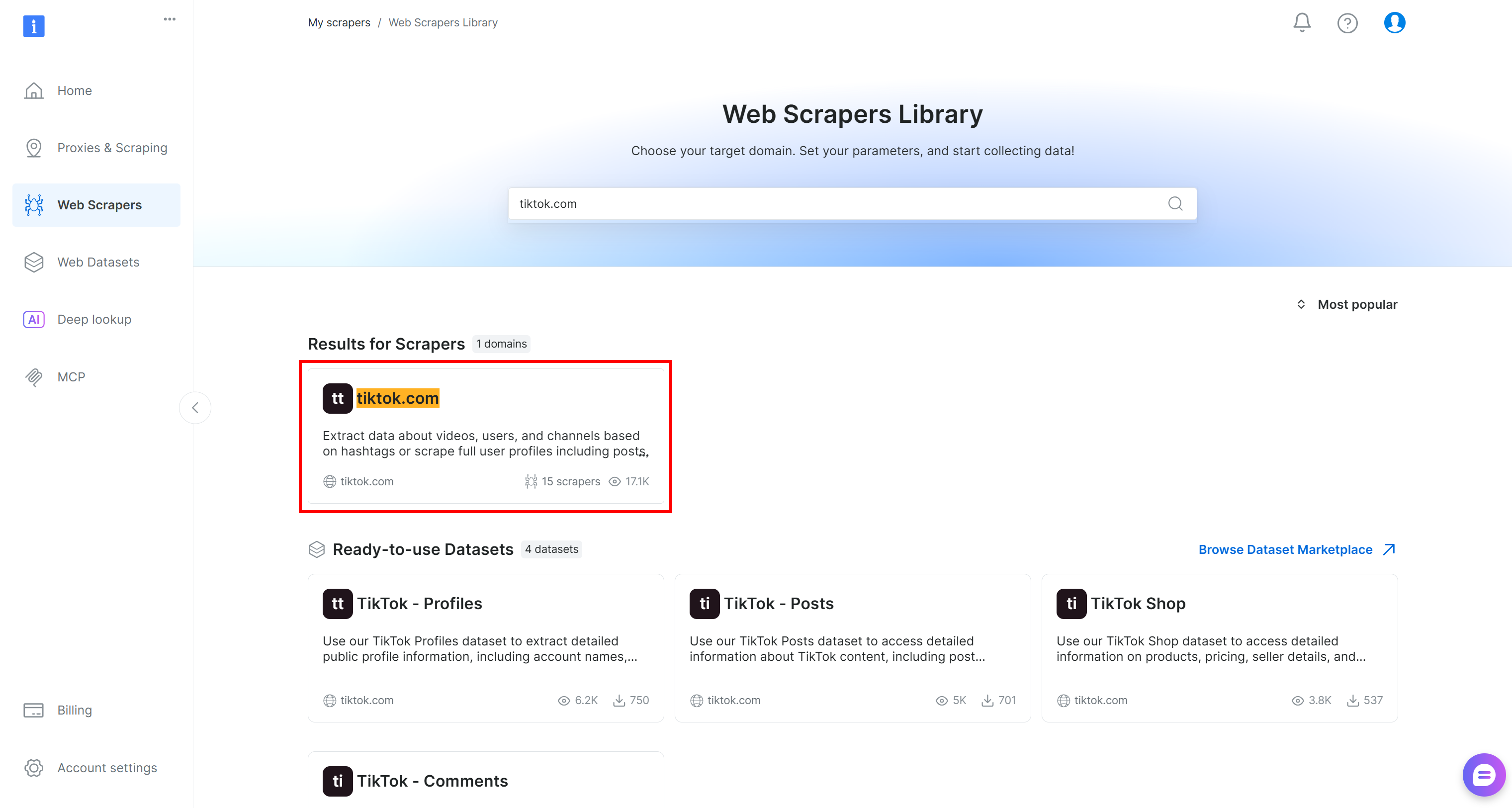
Auf der TikTok-Scraper-Seite können Sie die verfügbaren Scraping-Endpunkte erkunden.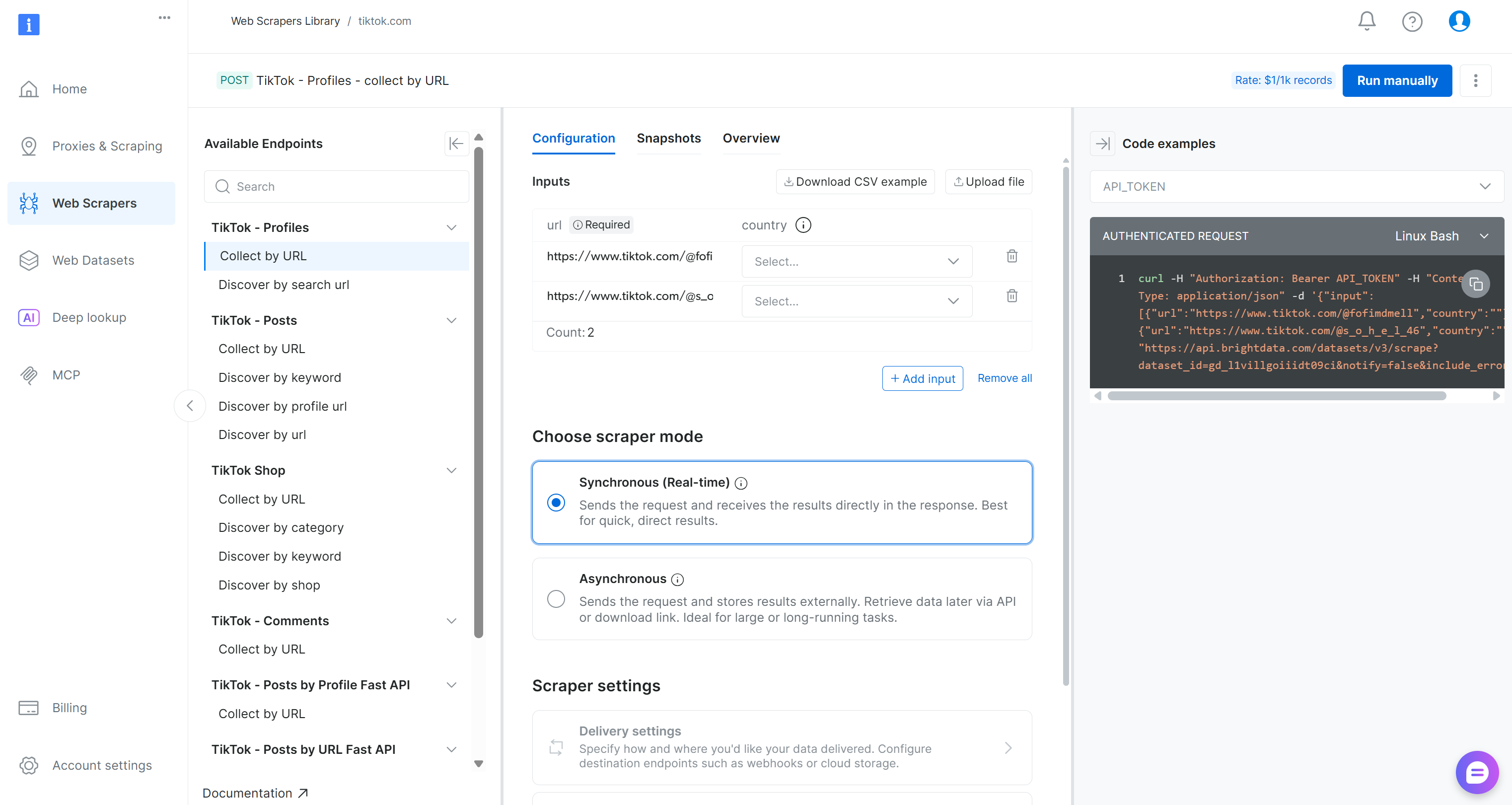
Hier können Sie Eingabeparameter konfigurieren, Anfrage-/Antwortformate überprüfen, Beispiel-API-Aufrufe anzeigen und vieles mehr.
Suchen Sie für diese Pipeline den Scraper „Collect by URL“ unter dem Dropdown-Menü „TikTok – Comments“: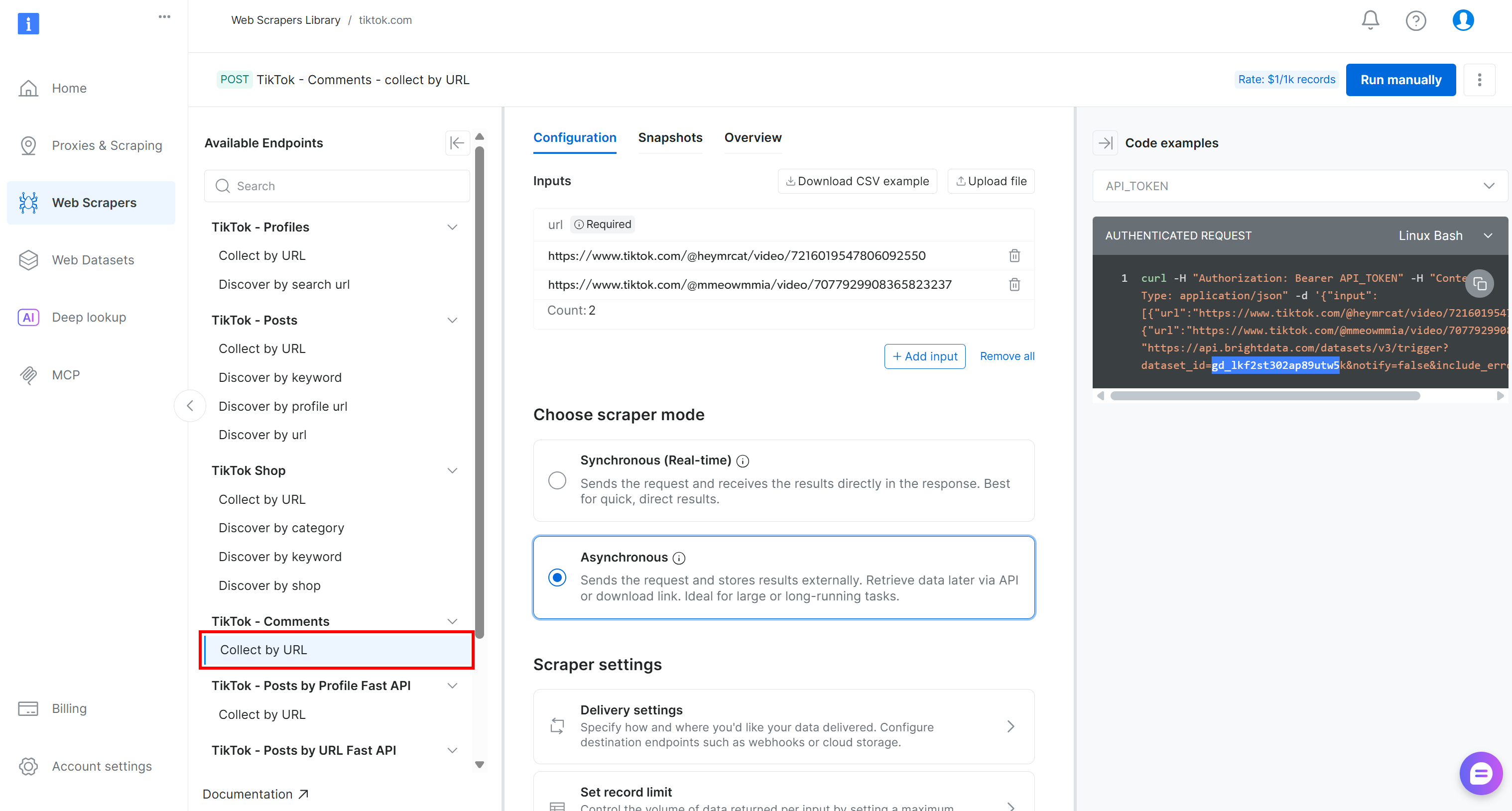
Dies ist der von Bright Data bereitgestellte Endpunkt, den Sie in der Datenerfassungskomponente Ihrer Kubeflow-Pipeline verwenden werden.
Notieren Sie sich die ID des Datensatzes:
gd_lkf2st302ap89utw5kSie benötigen diese, um die spezifische Web-Scraping-API für die TikTok-Kommentardatenerfassung auszulösen.
Wie Sie im Ausschnitt auf der rechten Seite sehen können, werden Bright Data-API-Aufrufe an die Web-Scraping-APIs mit einem API_TOKEN authentifiziert. Dieser Wert sollte durch Ihren Bright Data-API-Schlüssel ersetzt werden, was die empfohlene Methode zur Authentifizierung von API-Anfragen ist.
Rufen Sie Ihren API-Schlüssel wie in der Dokumentation beschrieben ab und bewahren Sie ihn an einem sicheren Ort auf. Sie werden ihn im nächsten Schritt verwenden!
Schritt 3: Definieren Sie die Komponente zur Erfassung von Webdaten
Implementieren Sie die Kubeflow-Pipeline-Komponente für die Webdatenerfassung, indem Sie sie mit der Bright Data Web-Scraping-API für TikTok-Scraping integrieren:
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"]
)
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Ersetzen Sie dies durch Ihren Bright Data API-Schlüssel.
# Die ID der Bright Data Web-Scraping-API „TikTok – Kommentare → Nach URL sammeln”
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Die HTTP-Header, die für alle Anfragen an Bright Data gelten
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# Lösen Sie die Bright Data Web-Scraping-API für die eingegebenen TikTok-Beiträge aus
trigger = requests.post(
f"https://api.brightdata.com/Datensätze/v3/trigger?Datensatz_ID={TIKTOK_DATENSATZ_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# Die Daten-Snapshot-ID abrufen
snapshot_id = trigger.json()["snapshot_id"]
# Den Snapshot-Endpunkt abfragen, um zu überprüfen, ob der Snapshot
# mit den gewünschten Daten erstellt wurde
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/Datensätze/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# Zugriff auf die JSON-Antwortdaten
response_data = progress.json()
# Wenn die Antwort keinen Status enthält, bedeutet dies, dass sie die gescrapten Daten enthält.
if isinstance(response_data, dict) and "status" in response_data:
# Extrahieren des aktuellen Snapshot-Status
status = progress.json()["status"]
# 5 Sekunden Wartezeit bis zur nächsten Überprüfung
time.sleep(5)
else:
scraped_data = response_data
break
# Speichern Sie den gescrapten Datensatz
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)Hinweis: Ersetzen Sie den Platzhalter <YOUR_BRIGHT_DATA_API_KEY> durch den zuvor abgerufenen Bright Data API-Schlüssel. Vermeiden Sie in einer produktionsreifen Pipeline die Hardcodierung von Geheimnissen in Ihren Komponenten. Verwalten Sie diese stattdessen sicher, wie in der Dokumentation erläutert.
In Kubeflow Pipelines ist eine Komponente eine in sich geschlossene Einheit (definiert über die Anmerkung dsl.component ), die eine bestimmte Aufgabe ausführt. In diesem Fall ruft die Komponente Webdaten von Bright Data ab. Jede Komponente ist in einem Docker-Container verpackt.
Für diese Komponente ist das Basisimage eine Python 3.10-Umgebung. Dann wird die Requests-Bibliothek hinzugefügt, da sie für HTTP-Anfragen an die API-Endpunkte von Bright Data verwendet wird. Zum Zeitpunkt der Bereitstellung, wenn die Komponente erstellt wird, wird das Python 3.10-Image abgerufen und Requests wird automatisch installiert.
Bright Data unterstützt sowohl synchrone als auch asynchrone Datenlieferung über seine Web-Scraping-APIs. Die synchrone Methode eignet sich ideal für die schnelle Datenabfrage, während die asynchrone Methode besser für größere Datensätze geeignet ist. Für eine produktionsreife Pipeline wird im Allgemeinen empfohlen, sich auf den asynchronen Ansatz zu verlassen.
Bei der asynchronen Methode sind die angeforderten Daten möglicherweise nicht sofort verfügbar. Stattdessen erstellt Bright Data einen Snapshot der angeforderten Daten, was einige Sekunden oder länger dauern kann. Dies erfordert einen Polling-Mechanismus, bei dem Sie wiederholt überprüfen, ob der Snapshot verfügbar ist, bevor Sie ihn abrufen.
Vor diesem Hintergrund funktioniert der Code der Webdatenkomponente Schritt für Schritt wie folgt:
- Senden der Datenanfrage: Die Komponente sendet einen API-Aufruf an Bright Data, um mit der Erstellung des Snapshots für die angeforderten Daten zu beginnen.
- Abfragen des Snapshot-Endpunkts: Die Komponente ruft wiederholt den Snapshot-Endpunkt auf, um den Status zu überprüfen. Wenn die Antwort ein
Statusfeld„running“ enthält, wird der Snapshot noch vorbereitet. Fehlt dasStatusfeld, bedeutet dies, dass der Snapshot fertig ist und die gescrapten Daten enthält. - Abrufen der Daten: Sobald der Snapshot fertig ist, extrahiert die Komponente die Daten aus der API-Antwort und stellt sie für nachgelagerte Komponenten in der Pipeline zur Verfügung.
Großartig! Die Kubeflow-Pipeline-Komponente für die Webdatenerfassung ist fertig.
Schritt 4: Erstellen der Komponente zur Stimmungsanalyse
Die von TikTok gesammelten Daten werden als JSON-Array mit der folgenden Struktur abgerufen: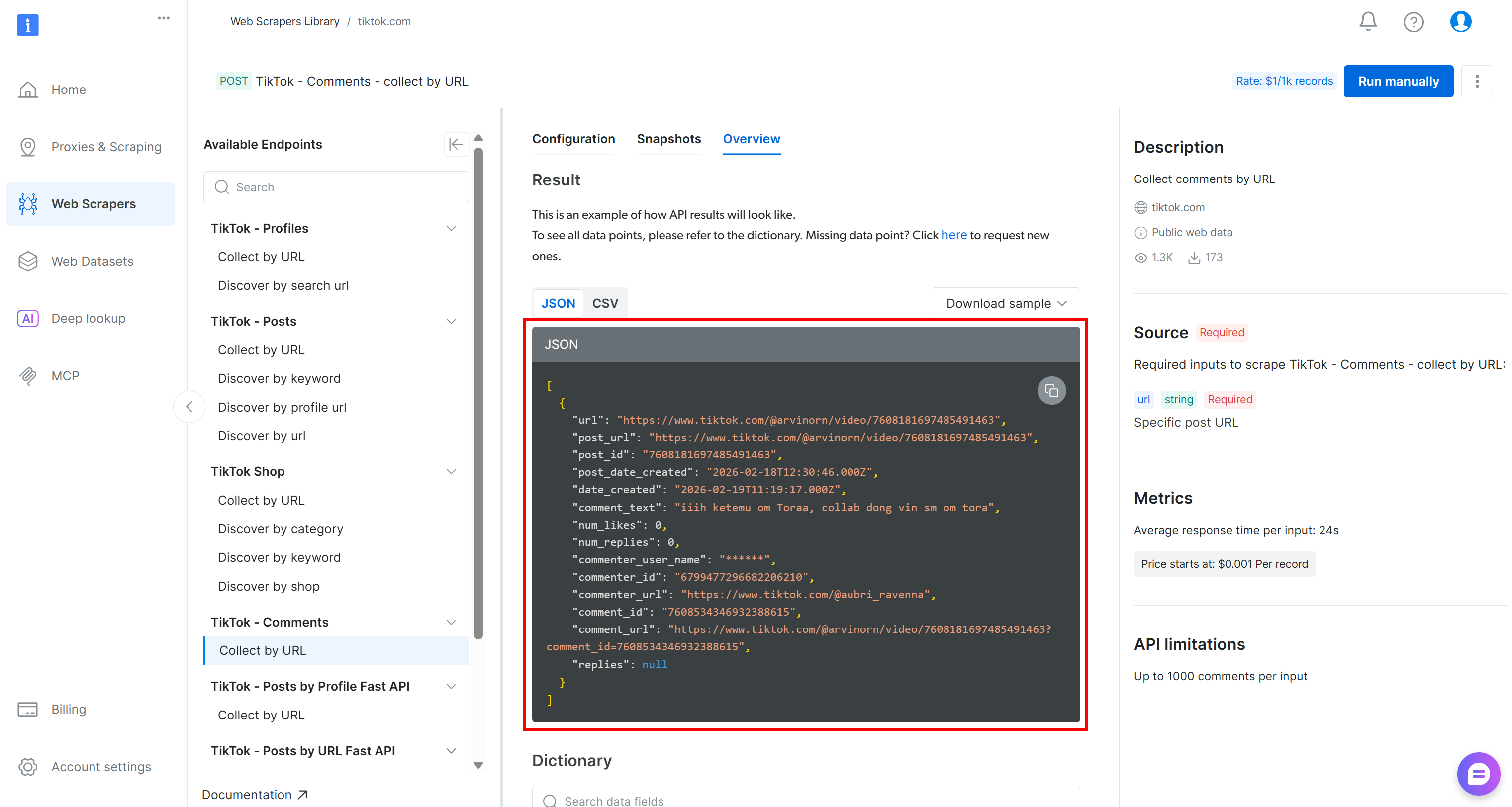
Um eine Sentimentanalyse dieser Daten durchzuführen, können Sie das Feld „comment_text“ an ein Sentimentanalyse-Tool wie VADER Sentiment Analysis übergeben. VADER ist ein lexikon- und regelbasiertes Tool, das speziell für die Erfassung von in sozialen Medien geäußerten Stimmungen entwickelt wurde. Natürlich können Sie auch andere Sentimentanalyse-Methoden verwenden, darunter KI-basierte Modelle.
VADER ist in NLTK enthalten, einem der beliebtesten Python-Toolkits für die Verarbeitung natürlicher Sprache. Ein typischer Arbeitsablauf sieht wie folgt aus:
- Lesen Sie das Eingabe-JSON-Array (die gescrapten TikTok-Kommentare) aus der vorherigen Komponente.
- Verwenden Sie
Pandas, um die Datenfilterung und -auswahl zu vereinfachen. - Übergeben Sie die Textdaten über
nltkan den VADER Sentiment Analyzer. - Speichern Sie die analysierten Ergebnisse, damit sie von nachgelagerten Komponenten verwendet werden können.
Zusammenfassend lässt sich die Komponente zur Sentimentanalyse wie folgt implementieren:
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"]
)
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# Laden Sie das VADER-Sentiment-Lexikon herunter (wird von NLTK für die Sentiment-Bewertung verwendet)
nltk.download("vader_lexicon")
# Laden Sie den Eingabedatensatz mit den TikTok-Kommentaren
df = pd.read_json(input_dataset.path)
# Initialisieren Sie den Sentiment-Analyzer
sia = SentimentIntensityAnalyzer()
# Wende die Sentimentanalyse auf jeden Kommentar an und klassifiziere ihn als positiv, negativ oder neutral
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" if sia.polarity_scores(str(t))["compound"] >= 0.05 else
„negative” if sia.polarity_scores(str(t))["compound"] <= -0.05 else „neutral”
))
# Speichern der Ergebnisse im Ausgabedatensatz für nachgelagerte Komponenten
df.to_json(sentiment_output.path, orient="records")Cool! Die beiden Hauptkomponenten der Pipeline (d. h. Webdatenerfassung und Sentimentanalyse) sind nun vollständig implementiert.
Schritt 5: Fertigstellung der Kubeflow-Pipeline
Nachdem die beiden Komponenten nun fertig sind, können Sie sie mit einer mit dsl.pipeline annotierten Funktion zu einer einzigen Kubeflow-Pipeline zusammenfassen:
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# Liste der TikTok-Post-URLs, aus denen Kommentare gescrapt werden sollen
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Sammeln von TikTok-Kommentaren mit der Bright Data-Web-Scraping-Komponente
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# Durchführung einer Sentimentanalyse der gesammelten Kommentare
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)Diese Pipeline führt zunächst die TikTok-Kommentarsammlungskomponente für zwei Zielvideos aus demselben Profil (@nike) aus. Im Einzelnen wurden die beiden TikTok-Quellvideos ausgewählt, weil sie neue Schuhe präsentieren. Die Durchführung einer Sentimentanalyse ist für das Unternehmen von entscheidender Bedeutung, um zu verstehen, was das Publikum über die Markteinführung denkt.
Der über die Bright Data Web-Scraping-API erstellte Datensatz wird dann an die nachgelagerte Komponente zur Sentimentanalyse weitergeleitet. Im Rahmen der Sentimentanalyse werden die gescrapten Kommentare verarbeitet und ein neuer Datensatz mit Sentiment-Labels (positiv, negativ oder neutral) erstellt. Diese Ausgabe kann von weiteren nachgelagerten Komponenten wie Berichten oder Visualisierungen verwendet werden.
Ausgezeichnet! Die Kubeflow-Pipeline ist nun vollständig definiert.
Schritt 6: Kompilieren der Pipeline
Der letzte Schritt besteht darin, die Pipeline in eine Kubeflow-YAML-Pipeline-Datei zu kompilieren:
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)Wenn Sie das Skript tiktok_sentiment_analysis_kfp_pipeline.py ausführen, generiert dieser Code eine Datei mit dem Namen tiktok_sentiment_analysis_kfp_pipeline.yaml. Diese YAML-Datei enthält die vollständige Pipeline-Spezifikation, die für die Kubeflow-Bereitstellung erforderlich ist. Mission erfüllt!
Schritt 7: Endgültiger Code
Nachfolgend finden Sie die vollständige Kubeflow-Pipeline, die Sie in Ihrer Datei tiktok_sentiment_analysis_kfp_pipeline.py haben sollten:
# tiktok_sentiment_analysis_kfp_pipeline.py
# pip install kfp
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Dataset
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"]
)
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Ersetzen Sie dies durch Ihren Bright Data API-Schlüssel.
# Die ID der Bright Data Web-Scraping-API „TikTok – Kommentare → Nach URL sammeln”
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Die HTTP-Header, die für alle Anfragen an Bright Data gelten
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# Lösen Sie die Bright Data Web-Scraping-API für die eingegebenen TikTok-Beiträge aus
trigger = requests.post(
f"https://api.brightdata.com/Datensätze/v3/trigger?Datensatz_ID={TIKTOK_DATENSATZ_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# Die Daten-Snapshot-ID abrufen
snapshot_id = trigger.json()["snapshot_id"]
# Den Snapshot-Endpunkt abfragen, um zu überprüfen, ob der Snapshot
# mit den gewünschten Daten erstellt wurde
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/Datensätze/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# Zugriff auf die JSON-Antwortdaten
response_data = progress.json()
# Wenn die Antwort keinen Status enthält, bedeutet dies, dass sie die gescrapten Daten enthält.
if isinstance(response_data, dict) and "status" in response_data:
# Extrahieren des aktuellen Snapshot-Status
status = progress.json()["status"]
# 5 Sekunden Wartezeit bis zur nächsten Überprüfung
time.sleep(5)
else:
scraped_data = response_data
break
# Speichern des gescrapten Datensatzes
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"]
)
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# Laden Sie das VADER-Sentiment-Lexikon herunter (wird von NLTK für die Sentimentbewertung verwendet)
nltk.download("vader_lexicon")
# Laden Sie den Eingabedatensatz mit den TikTok-Kommentaren
df = pd.read_json(input_dataset.path)
# Initialisieren Sie den Sentiment-Analyzer
sia = SentimentIntensityAnalyzer()
# Wende die Sentimentanalyse auf jeden Kommentar an und klassifiziere ihn als positiv, negativ oder neutral
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" if sia.polarity_scores(str(t))["compound"] >= 0.05 else
"negative" if sia.polarity_scores(str(t))["compound"] <= -0.05 else "neutral"
))
# Speichern Sie die Ergebnisse im Ausgabedatensatz für nachgelagerte Komponenten.
df.to_json(sentiment_output.path, orient="records")
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# Liste der TikTok-Post-URLs, aus denen Kommentare gescrapt werden sollen
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# TikTok-Kommentare mit der Web-Scraping-Komponente von Bright Data sammeln
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# Sentimentanalyse der gesammelten Kommentare durchführen
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)Starten Sie das obige Skript mit:
python3 tiktok_sentiment_analysis_kfp_pipeline.pyNach Ausführung des Befehls sollte eine Datei namens tiktok_sentiment_analysis_kfp_pipeline.yaml generiert werden, wie unten gezeigt:
Jetzt können Sie es entweder zum Testen in Kubeflow bereitstellen oder lokal mit Docker ausführen. In dieser Anleitung konzentrieren wir uns auf den zweiten Ansatz.
Schritt 8: Testen Sie die Kubeflow-Pipeline lokal
Um die Kubeflow-Pipeline lokal auszuführen, können Sie die DockerRunner-Klasse verwenden. Dazu muss Docker auf Ihrem Rechner installiert sein und ausgeführt werden.
Der DockerRunner führt jede Pipeline-Aufgabe in einem separaten Docker-Container aus. Mit anderen Worten: Er simuliert, wie die Pipeline in einer realen Kubeflow-Umgebung laufen würde.
Nachdem Sie Ihre virtuelle Umgebung aktiviert haben, installieren Sie zunächst die erforderliche Docker-Bibliothek:
pip install docker Fügen Sie anschließend eine Datei namens run_pipeline_local.py zu Ihrem Projektordner hinzu:
kfp-bright-data-pipeline/
├── .venv/
├── run_pipeline_local.py # <-----------
├── tiktok_sentiment_analysis_kfp_pipeline.py
└── tiktok_sentiment_analysis_kfp_pipeline.yamlFüllen Sie sie wie folgt aus:
# run_pipeline_local.py
# pip install docker
from kfp import local
from tiktok_sentiment_analysis_kfp_pipeline import tiktok_sentiment_pipeline
# Initialisieren Sie den lokalen Docker-Runner.
local.init(runner=local.DockerRunner())
# Führen Sie die Pipeline als Python-Funktionsaufruf aus.
pipeline_task = tiktok_sentiment_pipeline()Dieses Skript importiert die Funktion tiktok_sentiment_pipeline() aus tiktok_sentiment_analysis_kfp_pipeline.py und führt sie über den lokalen Docker-Runner aus, wobei jede Komponente in einem eigenen Container ausgeführt wird.
Um die Pipeline zu testen, stellen Sie sicher, dass Docker ausgeführt wird. Führen Sie dann Folgendes aus:
python3 run_pipeline_local.pyDie Ausführungsprotokolle sollten eine Erfolgsmeldung anzeigen, ähnlich wie im folgenden Beispiel:
Die Pipeline-Ausgabe wird im Ordner ./local_outputs gespeichert. Jetzt können Sie die Ergebnisse erkunden!
Schritt 9: Erkunden der Pipeline-Ergebnisse
Öffnen Sie nach dem Ausführen der Pipeline den Ordner ./local_outputs. Darin finden Sie einen Unterordner für den aktuellen Durchlauf, der alle erzeugten Artefakte enthält.
Beginnen Sie mit der Untersuchung des von der Komponente „collect-tiktok-comments” erstellten Datensatzes: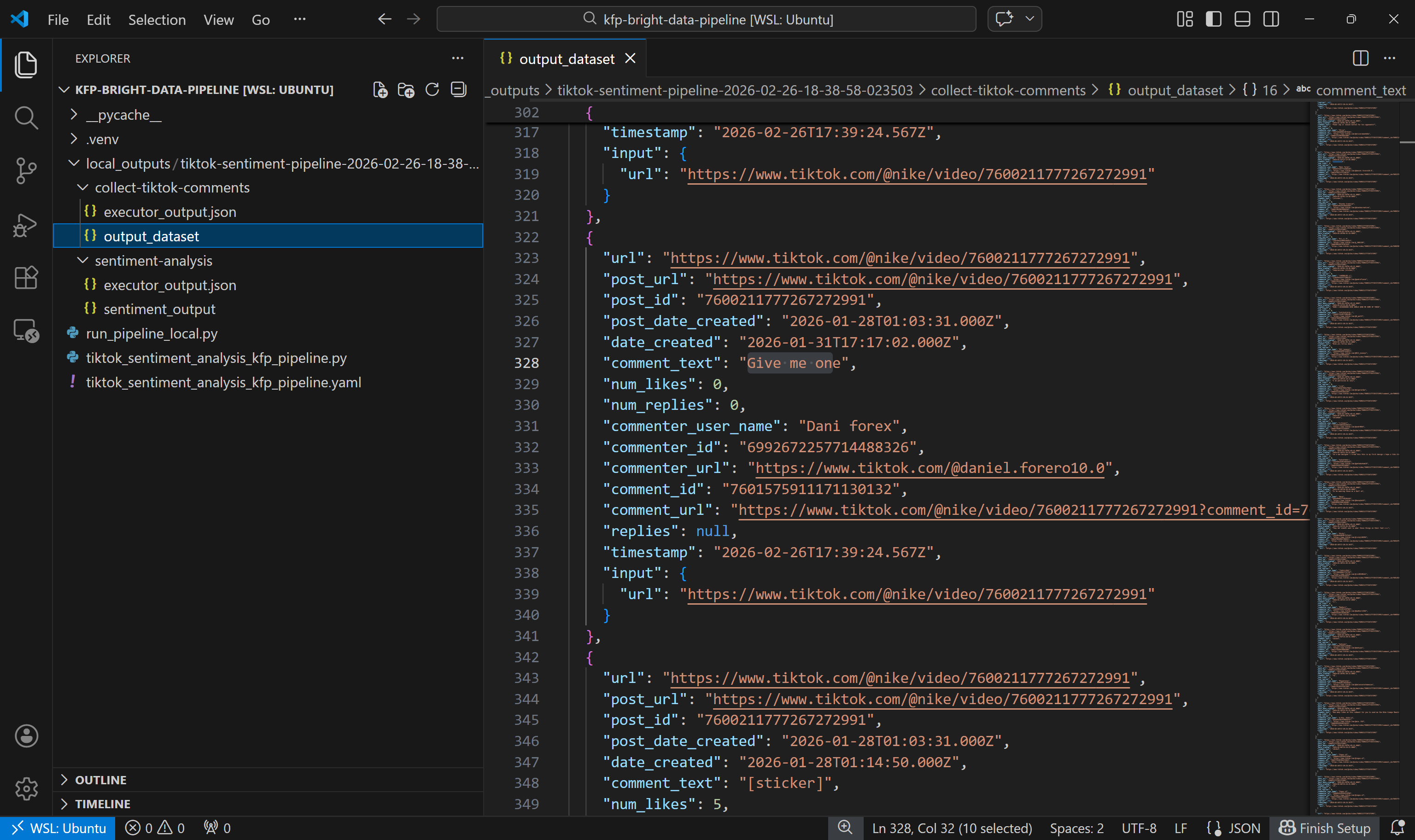
Dieser Datensatz enthält wie erwartet die Kommentare, die vom TikTok Scraper über Bright Data für die beiden angegebenen Beiträge zurückgegeben wurden.
Sehen Sie sich als Nächstes den Datensatz mit den Ergebnissen der Sentimentanalyse an: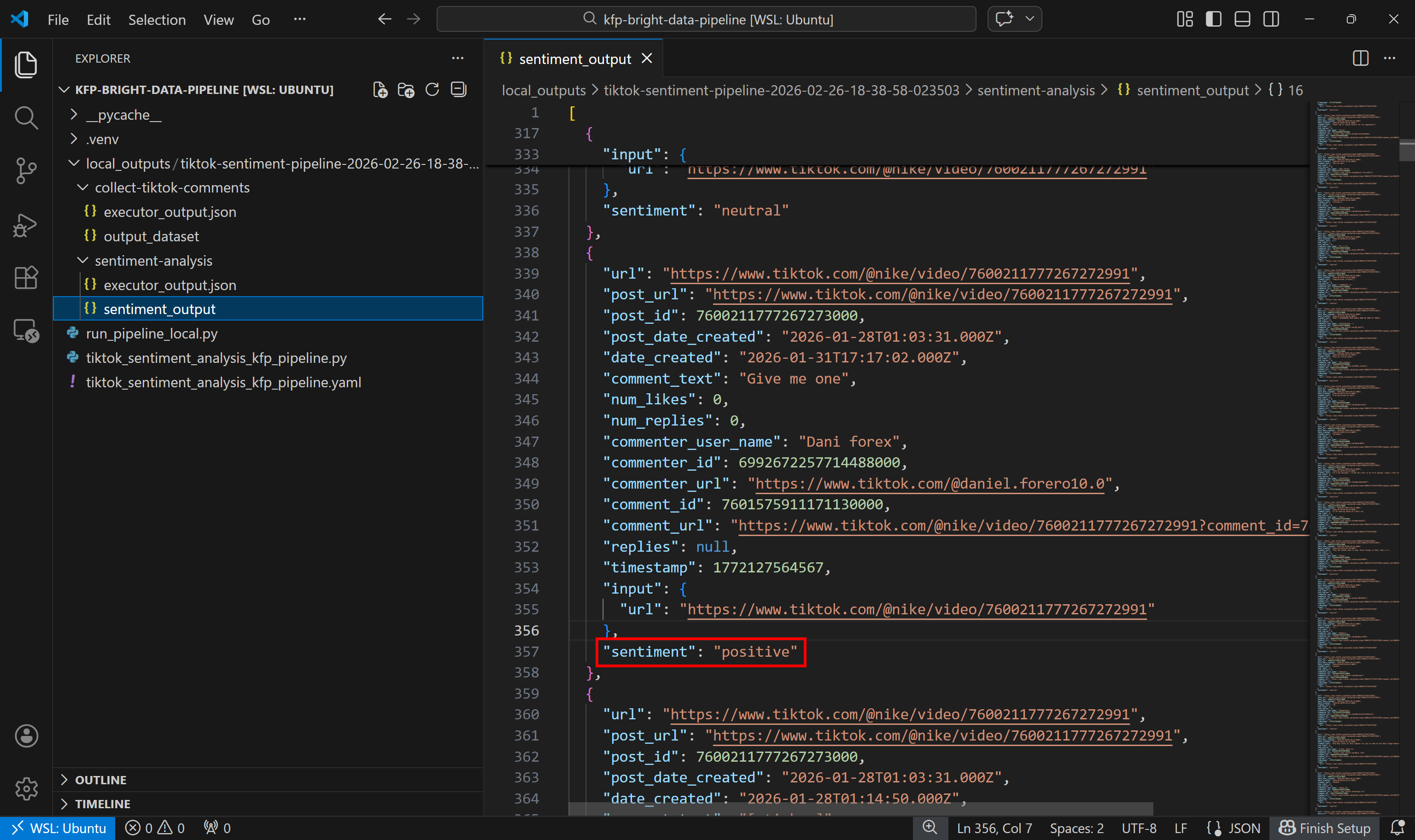
Beachten Sie, dass jeder Kommentar von der Sentimentanalyse-Komponente als positiv, negativ oder neutral gekennzeichnet wurde.
Et voilà! Sie haben gerade gesehen, wie Sie eine Kubeflow-Pipeline erstellen, die mit Bright Data aktuelle Webdaten abruft und anschließend analysiert.
Fazit
In diesem Tutorial haben Sie verstanden, warum Kubeflow-Pipelines von aktuellen Daten profitieren, die über Web-Scraping abgerufen werden. Insbesondere haben Sie gesehen, wie wichtig es ist, eine spezielle Komponente in Ihrer Pipeline zu haben, um aktuelle, kontextbezogene und strukturierte Daten aus dem Web zu sammeln.
Bright Data unterstützt dies durch eine breite Palette von Web-Scraping-APIs, die als strukturierte Datenfeeds für Ihre Pipelines dienen. Wie gezeigt, ist die Erstellung einer Komponente zur Webdatenerfassung in einer Kubeflow-Pipeline dank der Scraping-APIs von Bright Data ganz einfach!
Erstellen Sie ein kostenloses Bright Data-Konto und entdecken Sie noch heute unsere Webdatenlösungen!





