

In diesem Artikel erfahren Sie:
- Was das Anthropic-Webfetch-Tool ist und seine wichtigsten Einschränkungen.
- Wie es funktioniert.
- Wie man es in cURL und Python verwendet.
- Was Bright Data bietet, um ähnliche Ziele zu erreichen.
- Wie das Anthropic-Webfetch-Tool und die Bright Data-Webdaten-Tools verglichen werden.
- Eine zusammenfassende Tabelle für einen schnellen Vergleich.
Tauchen wir ein!
Was ist das Anthropic-Webfetch-Tool?
Mit dem Anthropic-Webfetch-Tool können Claude-Modelle Inhalte von Webseiten und PDF-Dokumenten abrufen. Dieses Tool wurde in der Beta-Version von Claude am 2026-09-10 kostenlos eingeführt.
Durch Einbindung dieses Tools in eine Claude-API-Anfrage kann das konfigurierte LLM den vollständigen Text von angegebenen Webseiten oder PDF-URLs abrufen und analysieren. Dadurch erhält Claude Zugang zu aktuellen, quellenbasierten Informationen für fundierte Antworten.
Hinweise und Beschränkungen
Dies sind die wichtigsten Hinweise und Einschränkungen im Zusammenhang mit dem Anthropic Web Fetch Tool:
- Es ist über die Claude API ohne zusätzliche Kosten verfügbar. Sie zahlen nur die Standard-Token-Gebühren für die abgerufenen Inhalte, die in Ihrem Gesprächskontext enthalten sind.
- Ruft den gesamten Inhalt von bestimmten Webseiten und PDF-Dokumenten ab.
- Derzeit im Beta-Stadium und erfordert den Beta-Header
web-fetch-2026-09-10. - Claude kann URLs nicht dynamisch konstruieren. Sie müssen explizit vollständige URLs angeben, oder es können nur URLs verwendet werden, die aus früheren Websuchen oder Abrufergebnissen stammen.
- Es können nur URLs abgerufen werden, die bereits im Gesprächskontext aufgetaucht sind. Dazu gehören URLs aus Benutzernachrichten, Ergebnisse von clientseitigen Tools oder frühere Websuch- und Webfetch-Ergebnisse.
- Funktioniert nur mit den folgenden Modellen: Claude Opus 4.1
(claude-opus-4-1-20260805), Claude Opus 4(claude-opus-4-20260514), Claude Sonnet 4.5(claude-sonnet-4-5-20260929), Claude Sonnet 4(claude-sonnet-4-20260514), Claude Sonnet 3.7(claude-3-7-sonnet-20260219), Claude Sonnet 3.5 v2 (veraltet)(claude-3-5-sonnet-latest), und Claude Haiku 3.5(claude-3-5-haiku-latest). - Unterstützt keine dynamisch gerenderten JavaScript-Websites.
- Kann optionale Zitate für abgerufene Inhalte enthalten.
- Arbeitet mit Prompt-Caching, so dass zwischengespeicherte Ergebnisse über Konversationsrunden hinweg wiederverwendet werden können.
- Unterstützt die Parameter
max_uses,allowed_domains,blocked_domainsundmax_content_tokens. - Häufige Fehlercodes sind:
invalid_input,url_too_long,url_not_allowed,url_not_accessible,too_many_requests,unsupported_content_type,max_uses_exceeded, undunavailable.
Wie Web Fetch in Claude Models funktioniert
Dies geschieht hinter den Kulissen , wenn Sie das Anthropic-Webfetch-Tool zu Ihrer API-Anfrage hinzufügen:
- Claude bestimmt anhand der Eingabeaufforderung und der angegebenen URLs, wann der Inhalt abgerufen werden soll.
- Die API ruft den Volltextinhalt von der angegebenen URL ab.
- Für PDFs wird eine automatische Textextraktion durchgeführt.
- Claude analysiert den abgerufenen Inhalt und erzeugt eine Antwort, die optional auch Zitate enthält.
Die resultierende Antwort wird dann an den Benutzer zurückgesendet oder dem Gesprächskontext zur weiteren Analyse hinzugefügt.
Wie man das Anthropic Web Fetch Tool verwendet
Es gibt zwei Möglichkeiten, das Web Fetch Tool zu verwenden, indem es in einer Anfrage an eines der unterstützten Claude-Modelle aktiviert wird. Dies kann auf eine der folgenden Weisen geschehen:
- Über einen direkten API-Aufruf an die Anthropic API.
- Über eines der Claude-Client-SDKs, wie z. B. die Anthropic Python API-Bibliothek.
Sehen Sie in den folgenden Abschnitten, wie das geht!
In beiden Fällen demonstrieren wir, wie man mit dem Web Fetch Tool die Anthropic Homepage scrapen kann (siehe unten):

Voraussetzungen
Die wichtigste Voraussetzung für die Verwendung des Anthropic-Webfetch-Tools ist der Zugriff auf einen Anthropic-API-Schlüssel. Wir gehen hier davon aus, dass Sie über ein Anthropic-Konto mit einem API-Schlüssel verfügen.
Über einen direkten API-Aufruf
Verwenden Sie das Web-Fetch-Tool, indem Sie einen direkten API-Aufruf an die Anthropic-API mit einem der unterstützten Modelle tätigen, wie unten in einer cURL-POST-Anfrage gezeigt:
curl https://api.anthropic.com/v1/messages
--header "x-api-key: <YOUR_ANTHROPIC_API_KEY>"
--header "anthropic-version: 2023-06-01"
--header "anthropic-beta: web-fetch-2026-09-10"
--header "content-type: application/json"
--data '{
"model": "claude-sonnet-4-5-20260929",
"max_tokens": 1024,
"messages": [
{
"role": "Benutzer",
"Inhalt": "Scrape den Inhalt von 'https://www.anthropic.com/'"
}
],
"tools": [{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}]
}'Beachten Sie, dass claude-sonnet-4-5-20260929 eines der Modelle ist, die vom Web-Fetch-Tool unterstützt werden.
Beachten Sie auch, dass die beiden speziellen Header, anthropic-version und anthropic-beta, erforderlich sind.
Um das Web-Fetch-Tool im konfigurierten Modell zu aktivieren, müssen Sie das folgende Element zum Array tools im Anfragekörper hinzufügen:
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}Die Felder "type" und "name" sind wichtig, während "max_uses ” optional ist und festlegt, wie oft das Tool innerhalb einer einzigen Iteration aufgerufen werden kann.
Ersetzen Sie den Platzhalter <YOUR_ANTHROPIC_API_KEY> durch Ihren tatsächlichen Anthropic-API-Schlüssel. Führen Sie dann die Anfrage aus, und Sie sollten in etwa folgendes Ergebnis erhalten:
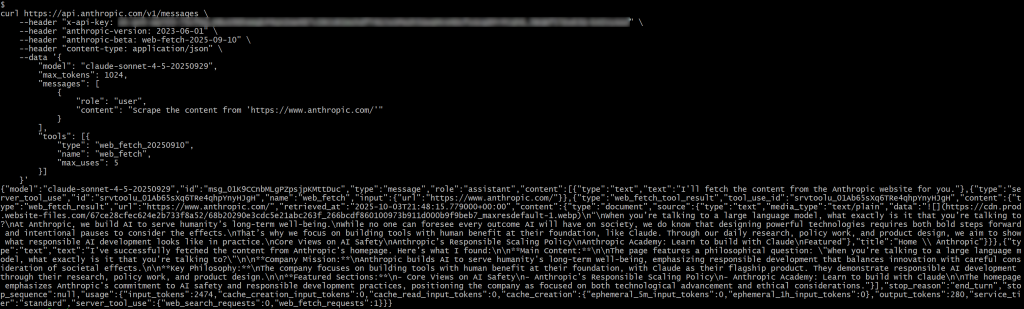
In der Antwort sollten Sie Folgendes sehen:
{"type": "server_tool_use", "id": "srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH", "name": "web_fetch", "input":{"url": "https://www.anthropic.com/"}}Dies gibt an, dass der LLM einen Aufruf an das web_fetch-Tool ausgeführt hat.
Konkret würde das Ergebnis des Werkzeugs in etwa so aussehen:

"Wenn Sie mit einem großen Sprachmodell sprechen, was genau ist es, mit dem Sie sprechen?
Bei Anthropic entwickeln wir KI, die dem langfristigen Wohlergehen der Menschheit dient.
Niemand kann alle Auswirkungen von KI auf die Gesellschaft vorhersehen, aber wir wissen, dass die Entwicklung leistungsstarker Technologien sowohl mutige Schritte nach vorne als auch bewusste Pausen erfordert, um die Auswirkungen zu bedenken.
Deshalb konzentrieren wir uns auf die Entwicklung von Werkzeugen, deren Grundlage der menschliche Nutzen ist, wie z. B. Claude. Durch unsere tägliche Forschung, unsere politische Arbeit und unser Produktdesign wollen wir zeigen, wie verantwortungsvolle KI-Entwicklung in der Praxis aussieht.
Zentrale Ansichten zur KI-Sicherheit
Anthropic's Politik der verantwortungsvollen Skalierung
Anthropische Akademie: Lernen Sie, mit Claude zu bauen
Ausgewählt
Dies stellt eine Art Markdown-ähnliche Version der Homepage der angegebenen Eingabe-URL dar. Es handelt sich um eine Art Markdown, da einige Links weggelassen werden und – abgesehen vom ersten Bild – die Ausgabe hauptsächlich aus Text besteht, was genau das ist, was das Web-Fetch-Tool zurückgeben soll.
Hinweis: Insgesamt ist das Ergebnis genau, aber es fehlen definitiv einige Inhalte, die bei der Verarbeitung durch das Tool verloren gegangen sein könnten. Tatsächlich enthält die Originalseite mehr Text als das, was abgerufen wurde.
Verwendung der Anthropic Python API-Bibliothek
Alternativ können Sie das Web-Fetch-Tool auch mit der Anthropic Python API-Bibliothek aufrufen:
# pip install anthropic
anthropic importieren
# Ersetzen Sie ihn durch Ihren Anthropic API-Schlüssel
ANTHROPIC_API_KEY = "<IHR_ANTHROPIC_API_KEY>"
# Initialisieren Sie den Anthropic-API-Client
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Durchführen einer Anfrage an Claude mit dem aktivierten Webabruf-Tool
response = client.messages.create(
model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": "Scrape den Inhalt von 'https://www.anthropic.com/'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
# Das von der KI erzeugte Ergebnis im Terminal ausgeben
print(response.content)
Dieses Mal wird das Ergebnis lauten:
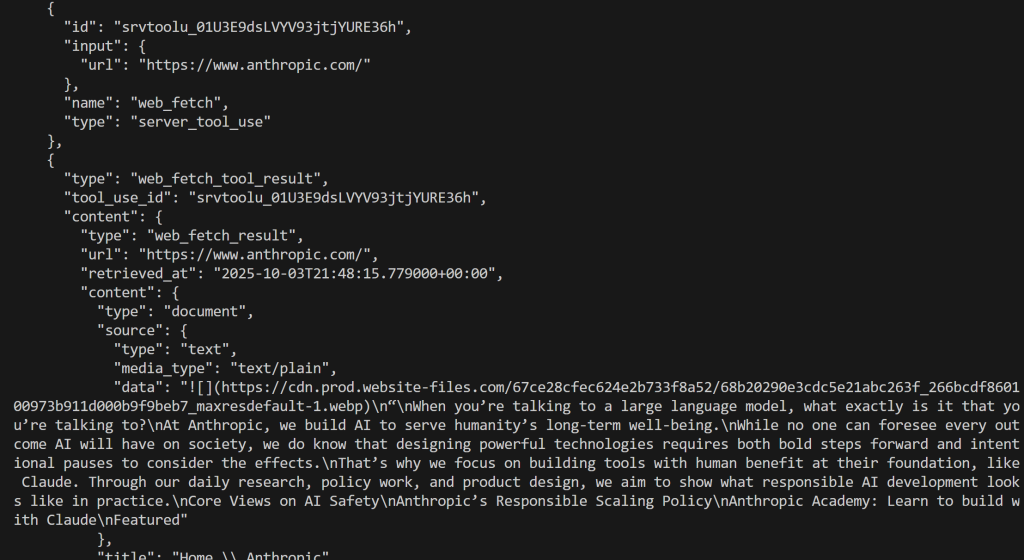
Großartig! Dies entspricht dem, was wir zuvor gesehen haben.
Eine Einführung in die Webdatentools von Bright Data
Die KI-Infrastruktur von Bright Data bietet eine Vielzahl von Lösungen, mit denen Ihre KI das Web durchsuchen, crawlen und frei navigieren kann. Dazu gehören:
- Unlocker API: Zuverlässiges Abrufen von Inhalten von jeder öffentlichen URL, automatisches Umgehen von Sperren und Lösen von CAPTCHAs.
- Crawl-API: Müheloses Crawlen und Extrahieren ganzer Websites mit Ausgaben in LLM-kompatiblen Formaten für effektive Inferenzen und Schlussfolgerungen.
- SERP-API: Sammeln Sie geospezifische Suchmaschinenergebnisse in Echtzeit, um relevante Datenquellen für eine bestimmte Anfrage zu finden.
- Browser-API: Ermöglichen Sie Ihrer KI die Interaktion mit dynamischen Websites und die Automatisierung von agentenbasierten Workflows in großem Umfang mithilfe von Remote-Stealth-Browsern.
Unter den zahlreichen Tools, Services und Produkten für die Abfrage von Webdaten in der Bright Data-Infrastruktur konzentrieren wir uns auf Web MCP. Es bietet KI-Integrationstools, die auf den Bright Data-Produkten aufbauen und direkt mit den von Anthropic angebotenen Tools vergleichbar sind. Beachten Sie, dass Web MCP auch als Claude MCP funktioniert und sich vollständig in alle Anthropic-Modelle integrieren lässt.
Von den mehr als 60 verfügbaren Tools ist das Tool scrape_as_markdown am besten geeignet, um verglichen zu werden. Es ermöglicht das Scrapen einer einzelnen Webseiten-URL mit erweiterten Optionen für die Extraktion von Inhalten und liefert die Ergebnisse im Markdown-Format. Dieses Tool kann auf jede Webseite zugreifen, auch auf solche mit Bot-Erkennung oder CAPTCHA.
Wichtig ist, dass dieses Tool auf Web MCP sogar in der kostenlosen Version verfügbar ist, d. h. Sie können es kostenlos nutzen. Es bietet also eine ähnliche Funktionalität zur Wiederherstellung von Webdaten wie das Web Fetch Tool von Anthropic, wodurch sich Web MCP ideal für einen direkten Vergleich eignet.
Anthropic Web Fetch Tool vs. Bright Data Webdaten-Tools
In diesem Abschnitt werden wir einen Prozess zum Vergleich des Anthropic Web Fetch Tools mit den Web Data Tools von Bright Data erstellen. Im Einzelnen werden wir:
- Verwendung des Webfetch-Tools über die Anthropic Python API-Bibliothek.
- Verbindung zum Web MCP von Bright Data über LangChain MCP-Adapter (aber auch jede andere unterstützte Integration ist möglich).
Wir werden beide Ansätze unter Verwendung desselben Prompts und Claude-Modells für die folgenden vier Eingabe-URLs ausführen:
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews""https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/""https://it.linkedin.com/in/antonello-zanini"
Diese repräsentieren eine gute Mischung aus realen Seiten, von denen man möchte, dass eine KI automatisch Inhalte abruft: eine Website-Startseite, eine G2-Produktseite, eine Amazon-Produktseite und ein öffentliches LinkedIn-Profil. Beachten Sie, dass G2 aufgrund des Cloudflare-Schutzes bekanntermaßen schwierig zu scrapen ist, weshalb es absichtlich in den Vergleich aufgenommen wurde.
Schauen wir mal, wie die beiden Tools abschneiden!
Voraussetzungen
Bevor Sie diesen Abschnitt lesen, sollten Sie:
- Python lokal installiert haben.
- Einen Anthropic-API-Schlüssel.
- Ein Bright Data-Konto mit einem API-Schlüssel.
Um ein Bright Data-Konto einzurichten und den API-Schlüssel zu generieren, folgen Sie der offiziellen Anleitung. Es wird auch empfohlen, die offizielle Web MCP-Dokumentation zu lesen.
Darüber hinaus sind Kenntnisse über die Funktionsweise der LangChain-Integration und über die von Web MCP bereitgestellten Tools hilfreich.
Skript zur Integration des Web Fetch Tools
Um das Anthropic Web Fetch Tool durch die ausgewählten Eingabe-URLs laufen zu lassen, können Sie eine Python-Logik wie folgt schreiben:
# pip install anthropic
anthropic importieren
Ersetzen Sie ihn durch Ihren Anthropic-API-Schlüssel
ANTHROPIC_API_KEY = ""
Initialisieren Sie den Anthropic-API-Client
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url):
return client.messages.create( model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": f "Scrape den Inhalt von '{url}'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
Anschließend können Sie diese Funktion mit einer Eingabe-URL wie folgt aufrufen:
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")
Bright Data Web Data Tools Integrationsskript
Web MCP kann mit einer Vielzahl von Technologien integriert werden, wie in unserem Blog beschrieben. Hier werden wir die Integration mit LangChain demonstrieren, da dies eine der einfachsten und beliebtesten Optionen ist.
Bevor Sie beginnen, empfehlen wir Ihnen, sich den Leitfaden anzusehen: “LangChain MCP-Adapter mit Bright Data’s Web MCP“.
In diesem Fall sollten Sie am Ende ein Python-Snippet wie dieses erhalten:
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
asyncio importieren
von langchain_anthropic importieren ChatAnthropic
from mcp import ClientSession, StdioServerParameter
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
import json
# Ersetzen Sie durch Ihre API-Schlüssel
ANTHROPIC_API_KEY = "<IHR_ANTHROPIC_API_KEY>"
BRIGHT_DATA_API_KEY = "<IHR_BRIGHT_DATA_API_KEY>"
async def scrape_content_with_bright_data_web_mcp_tools(agent, url):
# Beschreibung der Agentenaufgabe
input_prompt = f "Scrape den Inhalt von '{url}'"
# Ausführen der Anfrage im Agenten, Streaming der Antwort und Rückgabe als String
output = []
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
content = step["messages"][-1].content
if isinstance(content, list):
output.append(json.dumps(content))
sonst:
output.append(content)
return "".join(output)
async def main():
# Initialisierung der LLM-Engine
llm = ChatAnthropic(
model="claude-sonnet-4-5-20260929",
api_key=ANTHROPIC_API_KEY
)
# Konfiguration für die Verbindung mit einer lokalen Bright Data Web MCP-Serverinstanz
server_params = StdioServerParameter(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "false" # Optional auf "true" für den Pro-Modus gesetzt
}
)
# Verbindung zum MCP-Server herstellen
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialisierung der MCP-Client-Sitzung
await session.initialize()
# Abrufen der Web-MCP-Tools
tools = await load_mcp_tools(session)
# Erstellen des ReAct-Agenten mit Web-MCP-Integration
agent = create_react_agent(llm, tools)
# scrape_content_with_bright_data_web_mcp_tools(agent, "https://www.anthropic.com/")
if __name__ == "__main__":
asyncio.run(main())
Dies definiert einen ReAct-Agenten, der Zugriff auf die Web-MCP-Tools hat.
Zur Erinnerung: Web MCP bietet einen Pro-Modus, der Zugang zu Premium-Tools bietet. Die Verwendung des Pro-Modus ist in diesem Fall nicht unbedingt erforderlich. Sie können sich also nur auf die Tools verlassen, die im kostenlosen Modus verfügbar sind. Zu den kostenlosen Tools gehört scrape_as_markdown, das für diesen Benchmark ausreichend ist.
Einfacher ausgedrückt: Aus Kostensicht kostet die Verwendung von Web MCP im kostenlosen Modus nicht mehr als die Token-Nutzung für das Claude-Modell selbst (die in beiden Szenarien gleich ist). Im Wesentlichen ist die Kostenstruktur für diese Einrichtung die gleiche wie bei einer direkten Verbindung zu Claude über die API.
Benchmark-Ergebnisse
Führen Sie nun die beiden Funktionen aus, die die beiden Methoden für den Abruf von KI-Webdaten darstellen, indem Sie die folgende Logik verwenden:
# Wo werden die Benchmark-Ergebnisse gespeichert?
benchmark_results = []
# Die Eingabe-URLs, mit denen die beiden Ansätze getestet werden
urls = [
"https://www.anthropic.com/",
"https://www.g2.com/products/bright-data/reviews",
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/",
"https://it.linkedin.com/in/antonello-zanini"
]
# Jede URL testen
for url in urls:
print(f "Testing the two approaches on the following URL: {url}")
anthropic_start_time = time.time()
anthropische_Antwort = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agent, url)
hell_data_end_time = time.time()
benchmark_entry = {
"url": url,
"anthropic": {
"execution_time": anthropic_end_time - anthropic_start_time,
"output": anthropic_response.to_json()
},
"bright_data": {
"execution_time": bright_data_end_time - bright_data_start_time,
"output": bright_data_response
}
}
benchmark_results.append(benchmark_entry)
# Exportieren der Benchmark-Daten
with open("benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)
Die Ergebnisse lassen sich in der folgenden Tabelle zusammenfassen:
| Anthropic Web Fetch Tool | Helle Daten Web Data Tools | |
|---|---|---|
| Anthropische Homepage | ✔️ (teilweise Textinformationen) | ✔️ (vollständige Informationen in Markdown) |
| G2-Überprüfungsseite | ❌ (Tool schlug nach ~10 Sekunden fehl) | ✔️ (vollständige Markdown-Version der Seite) |
| Amazon Produktseite | ✔️ (teilweise Textinformationen) | ✔️ (vollständige Markdown-Version der Seite oder strukturierte JSON-Produktdaten im Pro-Modus) |
| LinkedIn-Profilseite | ❌ (Tool schlug sofort fehl) | ✔️ (vollständige Markdown-Version der Seite oder strukturierte JSON-Profildaten im Pro-Modus) |
Wie Sie sehen, ist das Anthropic-Webfetch-Tool nicht nur weniger effektiv als die Webdatentools von Bright Data, sondern liefert selbst dann, wenn es funktioniert, weniger vollständige Ergebnisse.
Das Anthropic-Tool konzentriert sich in erster Linie auf Text, während Web-MCP-Tools wie scrape_as_markdown die vollständige Markdown-Version einer Seite zurückgeben. Außerdem können Sie mit Pro-Tools wie web_data_amazon_product strukturierte Datenfeeds von beliebten Websites wie Amazon erhalten.
Insgesamt sind die Webdatentools von Bright Data der eindeutige Sieger, sowohl was die Genauigkeit als auch die Ausführungszeit angeht!
Zusammenfassung: Vergleichstabelle
| Anthropic Web Fetch Tool | Bright Data Webdaten-Tools | |
|---|---|---|
| Inhaltstypen | Webseiten, PDFs | Web-Seiten |
| Fähigkeiten | Text-Extraktion | Inhaltsextraktion, Web-Scraping, Web-Crawling und mehr |
| Ausgabe | Hauptsächlich einfacher Text | Markdown, JSON und andere LLM-kompatible Formate |
| Modell-Integration | Funktioniert nur mit bestimmten Claude-Modellen | Vollständige Integration mit jedem LLM und über 70 Technologien |
| Unterstützung für JavaScript-gerenderte Sites | ❌ | ✔️ |
| Anti-Bot-Umgehung/CAPTCHA-Behandlung | ❌ | ✔️ |
| Robustheit | Beta | Produktionsreife |
| Unterstützung für Batch Requests | ✔️ | ✔️ |
| Integration von Agenten | Nur in Claude-Lösungen | ✔️ (in jeder Lösung zur Erstellung von KI-Agenten, die MCP oder offizielle Bright Data-Tools unterstützt) |
| Verlässlichkeit und Vollständigkeit | Partieller Inhalt; kann bei komplexen Seiten fehlschlagen | Vollständige Inhaltsextraktion; verarbeitet komplexe Sites und Seiten mit Bot-Schutz |
| Kosten | Nur Standard-Token-Nutzung | Nur Standard-Token-Nutzung im kostenlosen Modus; zusätzliche Kosten im Pro-Modus |
Informationen zur Integration von Web MCP mit Anthropic-Technologien und Claude-Modellen finden Sie in den folgenden Anleitungen:
- Integrieren von Claude-Code mit Web MCP von Bright Data
- Web-Scraping mit Claude: KI-gestütztes Parsing in Python
- Verwendung von Bright Data mit Pica MCP in Claude Desktop
Schlussfolgerung
In diesem Blogbeitrag zum Vergleich haben Sie gesehen, wie das Anthropic-Webfetch-Tool im Vergleich zu den von Bright Data angebotenen Webdatenabruf- und Interaktionsfunktionen abschneidet. Sie erfuhren insbesondere, wie Sie das Anthropic-Tool in realen Beispielen einsetzen können, gefolgt von einem Benchmark-Vergleich mit einem entsprechenden LangChain-Agenten, der mit dem Web-MCP von Bright Data interagiert.
Der eindeutige Gewinner waren die Tools von Bright Data, die eine Reihe von KI-fähigen Produkten und Services umfassen, die eine Vielzahl von Anwendungsfällen und Szenarien unterstützen können.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und lernen Sie unsere KI-fähigen Web-Datentools kennen!





