

In diesem Lernprogramm lernen Sie Folgendes:
- Was Cloudflare ist.
- Ein genauerer Blick auf seinen WAF-Mechanismus.
- Wie das Anti-Bot-System aus technischer Sicht funktioniert.
- Was passiert, wenn Sie eine von Cloudflare geschützte Website mit Standard-Automatisierungstools anvisieren?
- High-Level-Ansätze zur Umgehung von Cloudflare.
- Wie man die Cloudflare-Menschenprüfung in Python umgeht.
- Wie man Cloudflare im großen Stil umgeht.
Lasst uns eintauchen!
Was ist Cloudflare?
Cloudflare ist ein Webinfrastruktur- und Sicherheitsunternehmen, das eines der größten Netzwerke im Internet betreibt. Es bietet eine umfassende Palette von Dienstleistungen an, die Websites schneller und sicherer machen sollen.
Im Kern funktioniert Cloudflare vor allem als CDN(Content Delivery Network), das den Inhalt von Websites in einem globalen Netzwerk zwischenspeichert, um die Ladezeiten zu verbessern und die Latenzzeit zu verringern. Darüber hinaus bietet es Funktionen wie DDoS-Schutz(Distributed Denial-of-Service), eine WAF (Web Application Firewall), Bot-Management, DNS-Dienste und mehr.
Durch die Integration in das Netzwerk von Cloudflare können Websites schnell verbesserte Sicherheit und optimierte Leistung erhalten. Dies hat Cloudflare zur bevorzugten Lösung für Millionen von Websites weltweit gemacht.
Verstehen der Anti-Bot-Mechanismen von Cloudflare
Einer der Gründe, warum Cloudflare so beliebt ist, ist seine WAF(Web Application Firewall). Diese kann auf jeder Webseite, die über das globale Netzwerk von Cloudflare bereitgestellt wird, aktiviert werden. Im Detail stellt sie eine der effektivsten Lösungen gegen Scraper, unerwünschte Crawler und Bots im Allgemeinen dar.
Genauer gesagt, sitzt die Cloudflare WAF vor Ihren Webanwendungen. Sie prüft und filtert eingehende Anfragen in Echtzeit, um Angriffe oder unerwünschten Datenverkehr zu stoppen, bevor sie Ihre Server erreichen oder auf Ihre Webseiten zugreifen.
Als Teil seiner mehrschichtigen Verteidigungsstrategie verwendet die Cloudflare WAF proprietäre Algorithmen, um bösartige Bots zu erkennen und zu blockieren. Diese Algorithmen analysieren mehrere Merkmale des eingehenden Datenverkehrs, darunter:
- TLS-Fingerabdrücke: Untersucht, wie der TLS-Handshake vom HTTP-Client oder Browser durchgeführt wird. Dabei werden Details wie die angebotenen Cipher Suites, die Reihenfolge der Aushandlung und andere Merkmale auf niedriger Ebene untersucht. Bots und nicht standardisierte Clients haben oft ungewöhnliche, nicht browserähnliche TLS-Signaturen, die sie verraten.
- Details der HTTP-Anfrage: Untersucht HTTP-Header, Cookies, User-Agent-Strings und andere Aspekte. Bots verwenden oft Standard- oder verdächtige Konfigurationen, die sich von denen echter Browser unterscheiden.
- JavaScript-Fingerabdrücke: Führt JavaScript im Browser des Kunden aus, um detaillierte Informationen über die Umgebung zu sammeln. Dazu gehören die genaue Browserversion, das Betriebssystem, installierte Schriftarten oder Erweiterungen und sogar subtile Hardwaremerkmale. Diese Datenpunkte bilden einen Fingerabdruck, der hilft, echte Benutzer von automatisierten Skripten zu unterscheiden.
- Verhaltensanalyse: Einer der stärksten Indikatoren für automatisierten Traffic ist unnatürliches Verhalten. Cloudflare überwacht Muster wie schnelle Anfragen, fehlende Mausbewegungen, identische Klickpfade, Leerlaufzeiten und mehr. Mithilfe von maschinellem Lernen wird ermittelt, ob das Surfverhalten mit dem eines Menschen oder eines Bots übereinstimmt. Dies ist eine der komplexesten Anti-Bot-Techniken.
Cloudflare bietet im Allgemeinen zwei Arten der menschlichen Überprüfung:
- Zeigen Sie immer die Herausforderung der menschlichen Überprüfung
- Automatische Überprüfung durch einen Menschen (nur wenn verdächtige Aktivitäten festgestellt werden)
Erkunden Sie beide Optionen unten!
Modus 1: Immer die Herausforderung der menschlichen Verifizierung anzeigen
Der erste Modus ist weniger verbreitet, bietet aber einen stärkeren Schutz. Die Idee ist, beim ersten Zugriff auf eine Website immer eine menschliche Überprüfung zu verlangen.
So funktioniert zum Beispiel StackOverflow zum Zeitpunkt dieses Schreibens. Versuchen Sie, es im Inkognito-Modus zu besuchen (um eine neue Sitzung ohne Cookies zu gewährleisten), und Sie werden ein CAPTCHA namens Cloudflare Turnstile sehen, selbst wenn Sie ein echter menschlicher Nutzer sind:
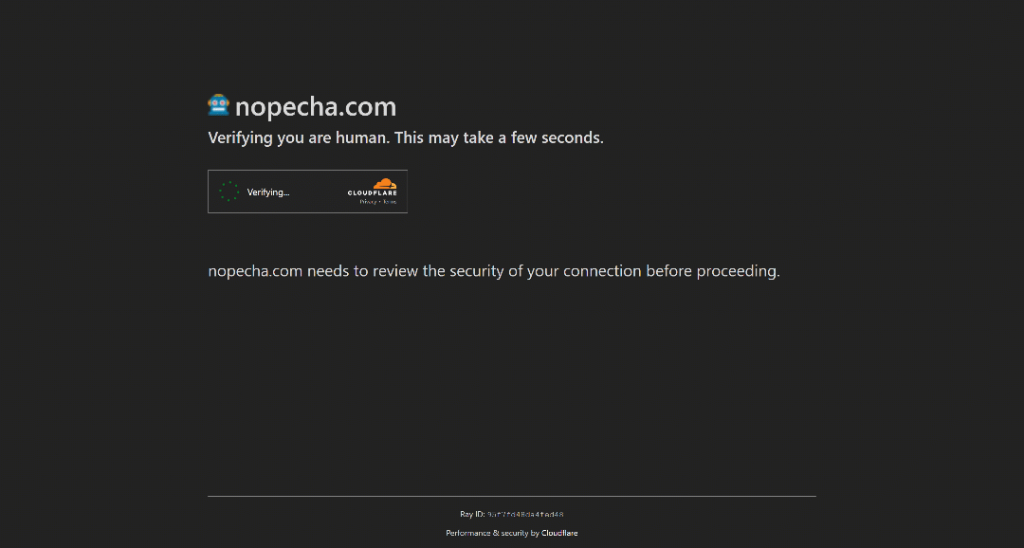
Hinweis: Wenn Sie diesen Artikel lesen, kann sich der Bot-Schutz von StackOverflow bereits geändert haben oder anders funktionieren.
Wenn Sie in diesem Fall ein automatisiertes Skript erstellen, besteht die einzige Möglichkeit darin, die Turnstile CAPTCHA-Interaktion auf eine menschenähnliche Weise zu automatisieren. Das ist eine besondere Herausforderung, da Turnstile sich auf eine Verhaltensanalyse hinter den Kulissen und andere proprietäre Prüfungen stützt. Auf diese Weise gelingt es, mit einem einzigen Klick zu überprüfen, ob Sie ein Mensch sind.
Modus #2: Automatisierte menschliche Verifizierung Herausforderung
In diesem Modus stellt Cloudflare nur dann eine Herausforderung aus, wenn es vermutet, dass eine Anfrage von einem Bot stammen könnte. Dazu wird eine JavaScript-Herausforderung präsentiert, die unsichtbar im Browser ausgeführt wird, um zu überprüfen, ob sich der Client wie ein legitimer Benutzer verhält:
Dieser Vorgang ist nahtlos und wird in der Regel automatisch abgeschlossen, wenn Sie ein Mensch sind und einen normalen Browser verwenden. Wenn Sie ihn bestehen, können Sie ohne Unterbrechung auf der Website weiternavigieren. Da dies nur minimale Unterbrechungen für normale Nutzer verursacht, ist dies der bei weitem häufigste Cloudflare-Modus.
Wenn die JavaScript-Herausforderung jedoch fehlschlägt (was bedeutet, dass Cloudflare zu dem Schluss kommt, dass der Client wahrscheinlich ein Bot ist), wird ein Turnstile CAPTCHA zur menschlichen Verifizierung angezeigt:
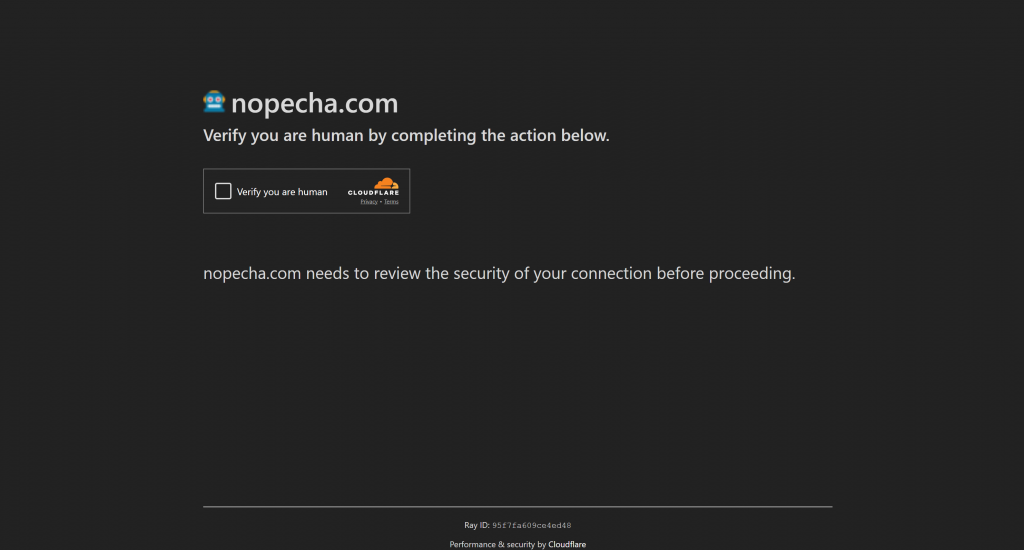
Jetzt sind Sie wieder bei dem, was Sie im vorherigen Szenario gesehen haben. In diesem Modus kann die Verwendung eines Bots, der menschenähnliche Fingerabdrücke präsentiert, ausreichen, um die erste Überprüfung zu bestehen und das Drehkreuz-CAPTCHA ganz zu vermeiden. Wenn es dennoch auftaucht, brauchen Sie eine Möglichkeit, damit umzugehen.
Wie Cloudflare im Detail aus technischer Sicht funktioniert
Versuchen Sie, die NopeCHA-Cloudflare-Testseite mit Ihrem Browser im Inkognito-Modus zu öffnen. Diese Seite ist durch die Cloudflare WAF geschützt, sodass der automatische JavaScript-basierte Verifizierungsprozess sofort beginnt.
Im Hintergrund werden eine Reihe von POST-Anfragen mit den Endpunkten von Cloudflare ausgetauscht, die verschlüsselte Daten in ihren Payloads übertragen:

Der genaue Inhalt dieser Payloads ist nicht öffentlich dokumentiert. Auf der Grundlage der bekannten Erkennungsstrategien von Cloudflare kann man jedoch davon ausgehen, dass sie verschiedene Arten von Browser- und System-Fingerprints enthalten.
Da Ihr Browser und Ihre Hardwarekonfiguration in Ordnung sind, sollte diese Herausforderung automatisch bestanden werden. Andernfalls müssen Sie die erforderliche Benutzerinteraktion durchführen (d. h. auf das Kontrollkästchen klicken).
Sobald die Überprüfung erfolgreich war, stellt der Cloudflare-Server ein cf_clearance-Cookie aus, das angibt, dass diese spezielle Benutzersitzung auf die Website zugreifen darf:
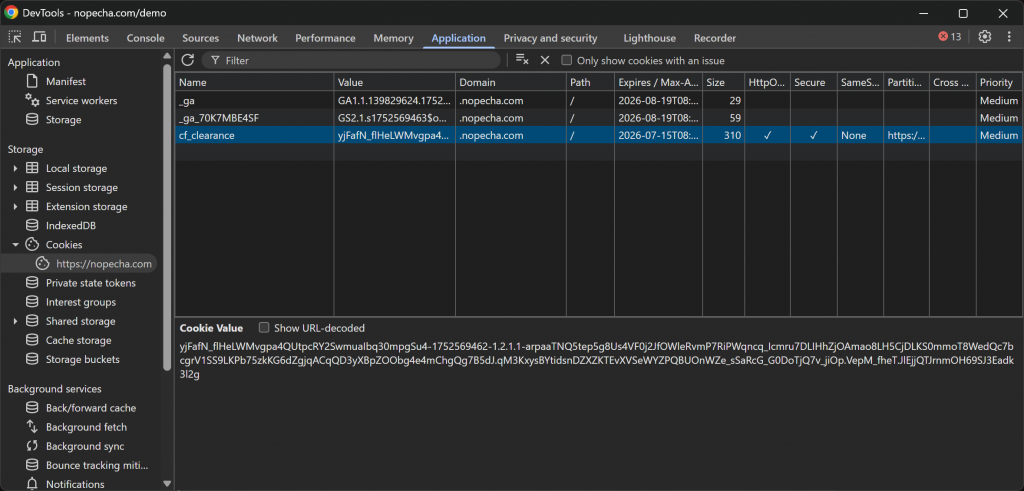
In diesem Fall ist das Cookie 15 Tage lang gültig. Das bedeutet, dass er theoretisch von einem automatisierten Bot einige Wochen lang wiederverwendet werden könnte, um auf die Zielseite zuzugreifen, ohne dass der Verifizierungsprozess erneut durchlaufen werden muss.
Was passiert, wenn Sie versuchen, eine Verbindung zu einer Cloudflare-geschützten Website herzustellen?
Werfen wir nun einen Blick darauf, was tatsächlich passiert, wenn ein automatisierter Bot versucht, eine von Cloudflare geschützte Seite zu besuchen.
Hinweis: Die folgenden Beispielskripte sind in Python geschrieben, aber die gleichen Prinzipien gelten unabhängig von der Programmiersprache, dem HTTP-Client oder dem Browser-Automatisierungstool, das Sie wählen.
Für diese Demonstration werden wir die Cloudflare-Herausforderungsseite von ScrapingCourse verwenden:
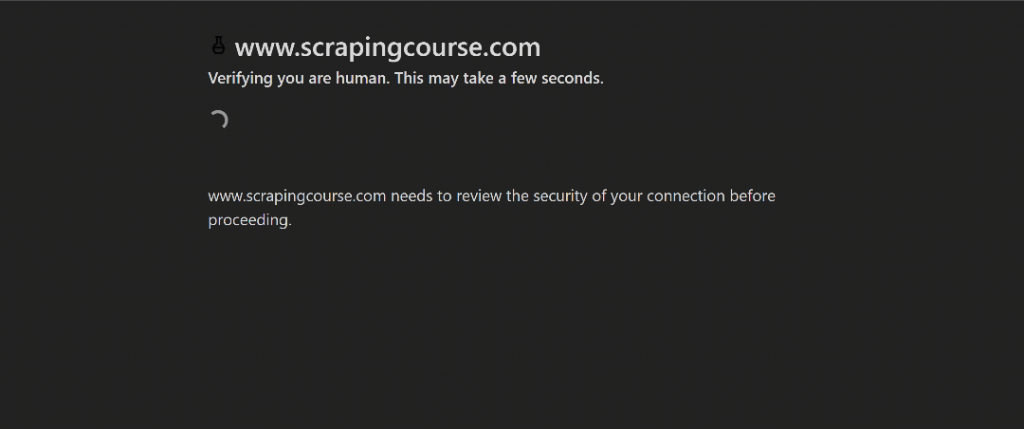
Dies ist eine Website, die die Überprüfung von Cloudflare bestehen muss. Sobald die Herausforderung erfolgreich gelöst ist, wird die folgende Seite angezeigt:
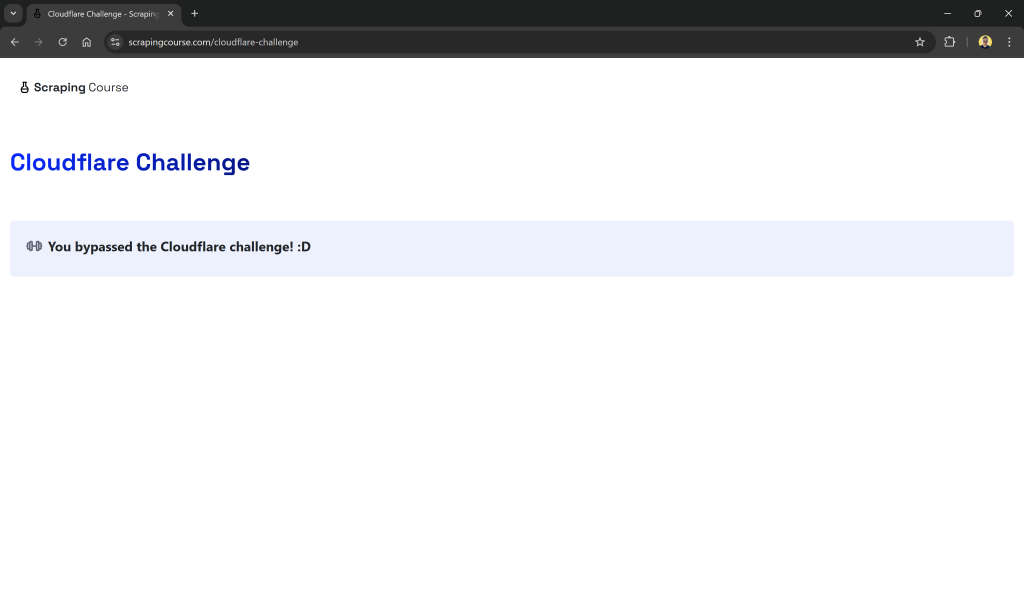
In den folgenden Beispielen wird speziell geprüft, ob der abgerufene Seiteninhalt die Zeichenfolge enthält:
"You bypassed the Cloudflare challenge! :D"Damit wird bestätigt, dass der Verifizierungsprozess erfolgreich abgeschlossen wurde.
Als einfachen Test werden wir sehen, was passiert, wenn wir die oben genannte Cloudflare-geschützte Seite mit zwei verschiedenen Ansätzen besuchen:
- Mit einem HTTP-Client wie Requests
- Mit einem Browser-Automatisierungstool wie Playwright
Cloudflare-geschützte Seiten mit Anfragen anvisieren
Prüfen Sie, ob Requests automatisch die menschliche Überprüfung von Cloudflare umgehen können:
# pip install requests
import requests
# Connect to the target page
response = requests.get(
"https://www.scrapingcourse.com/cloudflare-challenge"
)
# Raise exceptions in case of HTTP error status codes
response.raise_for_status()
# Verify if you received the success page
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html) Beachten Sie, dass das Skript nicht einmal die abschließende print()-Anweisung erreichen wird. Stattdessen wird es mit fehlschlagen:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://www.scrapingcourse.com/cloudflare-challengeWie Sie sehen können, hat Cloudflare die Anfrage als von einem automatisierten Skript stammend erkannt und sie mit einer 403 Forbidden-Antwort blockiert.
Besuch von Cloudflare-geschützten Seiten mit Playwright
Versuchen wir es nun mit einer Browser-Automatisierungslösung wie Playwright:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Dieses Skript weist einen Chromium-Browser an, die Zielseite aufzurufen. Anschließend prüft es mithilfe eines Locators, ob ein Element mit dem gewünschten Text auf der Seite erscheint, und wartet automatisch darauf (standardmäßig wartet Playwright bis zu 30 Sekunden).
Führen Sie die erforderlichen Installationsbefehle aus und führen Sie das obige Skript aus. Sie werden die folgende Ausgabe sehen:
Cloudflare Bypassed: FalseWenn Sie es im Headless-Modus(headless=False) ausführen, werden Sie feststellen, dass das Skript auf der Verifizierungsseite von Cloudflare stecken bleibt. Es wird ein Turnstile CAPTCHA angezeigt und wartet darauf, dass es manuell gelöst wird:

Hinweis: Wenn Sie versuchen, das Anklicken der Turnstile-Checkbox zu automatisieren, wird die Überprüfung fehlschlagen. Das liegt daran, dass Cloudflare intelligent genug ist, um zu erkennen, dass es sich um eine automatisierte und nicht um eine echte menschliche Interaktion handelt.
Hochrangige Ansätze zur Umgehung von Cloudflare
Lernen Sie drei Methoden kennen, mit denen Sie den Cloudflare-Schutz mit Ihrem automatisierten Skript umgehen können.
Ansatz #1: Cloudflare komplett umgehen
Vergessen Sie nicht, dass Cloudflare als CDN fungiert, was bedeutet, dass es den Inhalt von Websites zwischenlagert und über mehrere geografisch verteilte Server verteilt. Daher sind Websites, die über Cloudflare verteilt werden, in der Regel nur über Server im CDN-Netzwerk zugänglich.
Stellen Sie sich nun vor, Sie könnten die IP-Adresse des Servers der Website hinter dem CDN herausfinden. Die Folge wäre, dass Sie mit der Website interagieren und dabei Cloudflare vollständig umgehen könnten. Schließlich kann Cloudflare nur Anfragen auswerten, die durch sein Netzwerk laufen.
Dies ist möglich, indem Sie DNS-History-Lookup-Tools wie SecurityTrails verwenden, um alle historischen DNS-Einträge zu ermitteln, die die IP-Adresse des ursprünglichen Servers offenbaren. Sobald Sie die IP-Adresse erhalten haben, können Sie versuchen, Anfragen direkt an den Server zu senden und Cloudflare zu umgehen.
Das Problem ist, dass der Server möglicherweise zusätzliche Konfigurationen hat, die nur Anfragen aus dem IP-Bereich von Cloudflare akzeptieren. Das würde es fast unmöglich machen, eine direkte Verbindung zur Website herzustellen, ohne blockiert zu werden. Außerdem ist es ziemlich schwierig und unwahrscheinlich, die ursprüngliche Server-IP zu finden.
Ansatz #2: Verlassen Sie sich auf einen Cloudflare Solver
Im Internet finden Sie mehrere kostenlose und quelloffene Bibliotheken, mit denen Sie Cloudflare umgehen können. Einige der beliebtesten sind:
- Cloudscraper: Ein Python-Modul, das die Anti-Bot-Herausforderungen von Cloudflare bewältigt.
- Cfscrape: Ein leichtes PHP-Modul zur Umgehung der Anti-Bot-Seiten von Cloudflare.
- Humanoid: Ein Node.js-Paket zur Umgehung von Cloudflare’s Anti-Bot JavaScript Herausforderungen.
Es überrascht nicht, dass die meisten dieser Projekte seit Jahren keine Updates mehr erhalten haben. Der Grund dafür ist, dass die Entwickler aufgrund des ständigen Kampfes, mit den Aktualisierungen von Cloudflare Schritt zu halten, aufgegeben haben. Daher funktionieren diese Tools im Allgemeinen nicht lange.
Ansatz Nr. 3: Verwenden Sie eine Automatisierungslösung mit Cloudflare-Bypass-Funktionen
In den meisten Fällen ist die beste Lösung für das Scraping einer Cloudflare-geschützten Website die Verwendung einer All-in-One-Automatisierungslösung. Um effektiv zu sein, müssen diese Bibliotheken oder Online-Dienste mindestens die folgenden Funktionen bieten:
- JavaScript-Rendering, so dass die JavaScript-Herausforderungen von Cloudflare ordnungsgemäß ausgeführt werden können.
- TLS-, HTTP-Header- und Browser-Fingerprint-Spoofing, um echte Benutzer zu simulieren und eine Entdeckung zu vermeiden.
- Turnstile CAPTCHA-Lösungsfähigkeiten, um die menschliche Überprüfung von Cloudflare zu handhaben, wenn sie erscheint.
- Simulierte menschenähnliche Interaktion, z. B. das Bewegen der Maus entlang einer B-Spline-Kurve, um das natürliche Benutzerverhalten nachzuahmen.
Darüber hinaus enthalten Premium-Lösungen oft ein integriertes Proxy-Netzwerk, um IP-Adressen zu rotieren und das Risiko einer Blockierung zu verringern.
In den folgenden zwei Kapiteln werden Sie sowohl Open-Source- als auch Premium-Lösungen in Aktion sehen!
Wie man Cloudflare Human Check in Python umgeht
Die meisten Open-Source-Lösungen, die vorgeben, Cloudflare zu umgehen, schaffen dies nur für eine begrenzte Zeitspanne. Das liegt daran, dass es sich im Wesentlichen um ein Katz-und-Maus-Spiel handelt, und ihr Open-Source-Charakter (wo Cloudflare-Ingenieure ihren Code leicht studieren können) ist nicht hilfreich.
Daher ist es nicht verwunderlich, dass viele Tools, die früher funktionierten (wie Puppeteer Stealth), das Ziel nicht mehr erreichen. Dennoch gibt es zum Zeitpunkt der Erstellung dieses Artikels zwei Lösungen, die es tatsächlich schaffen, den Schutz von Cloudflare zu umgehen:
- Camoufox: Ein quelloffener Python-Browser mit Anti-Detektionsfunktion, der auf einem angepassten Firefox-Build basiert und entwickelt wurde, um die Bot-Erkennung zu umgehen und Web-Scraping zu ermöglichen.
- SeleniumBase: Ein quelloffenes, professionelles Python-Toolkit für fortgeschrittene Web-Automatisierung.
Mal sehen, wie beide gegen die Cloudflare-Herausforderungsseite von ScrapingCourse abschneiden!
Umgehung des Clouflare-Drehkreuzes mit Camoufox
Installieren Sie zunächst Camoufox in Ihrem Python-Projekt mit:
pip install camoufox[geoip]Rufen Sie dann die erforderlichen zusätzlichen Abhängigkeiten mit ab:
python -m camoufox fetchWeitere Informationen finden Sie in der offiziellen Installationsanleitung.
Die Camoufox Python-Bibliothek baut auf Playwright auf, daher ist ihre API sehr ähnlich. Besuchen Sie die Zielseite, warten Sie auf das Erscheinen der Turnstile-Herausforderung und behandeln Sie sie (falls sie tatsächlich erscheint) mit der folgenden Logik:
# pip install camoufox[geoip]
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
with Camoufox(
headless=False,
humanize=True,
window=(1280, 720) # So that the Turnstile checkbox is on coordinate (210, 290)
) as browser:
page = browser.new_page()
# Visit the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
# Wait for the Cloudflare Turnstile to appear and load
page.wait_for_load_state(state="domcontentloaded")
page.wait_for_load_state("networkidle")
page.wait_for_timeout(5000) # 5 seconds
# Ckick the Turnstile checkbox (if it is present)
page.mouse.click(210, 290)
try:
# Wait for the desired text to appear
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Beachten Sie, dass die Logik für die Handhabung des Drehkreuzes ein wenig kompliziert ist. Sie beruht auf der Annahme, dass das Drehkreuz-Kontrollkästchen ungefähr an der Koordinate (210, 290) in einem 1280×720-Browserfenster erscheint.
Wenn Sie das obige Skript ausführen, erhalten Sie das folgende Ergebnis:
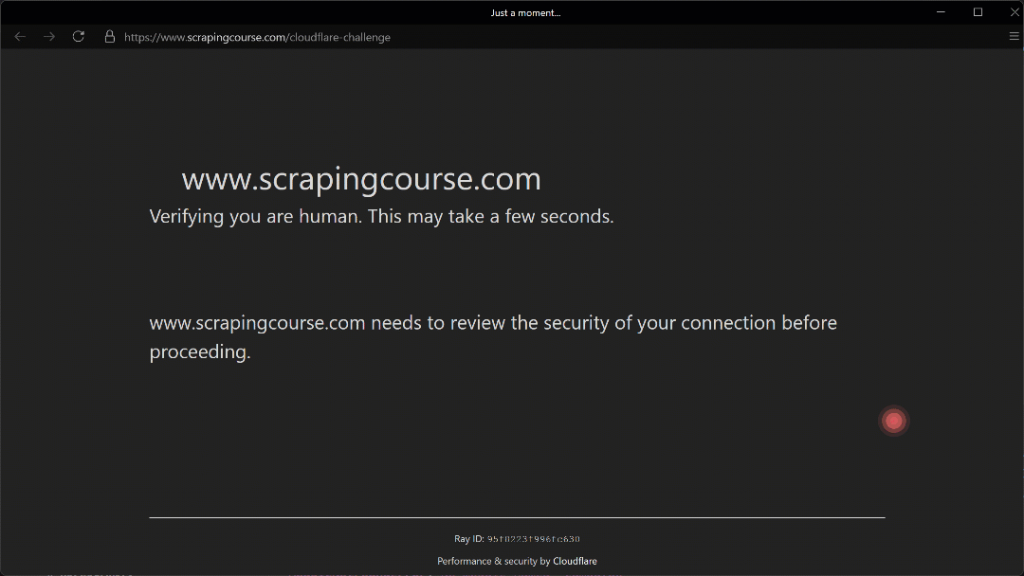
Die automatische Mausbewegung in Richtung der Koordinate (210, 290) wirkt dank des Parameters Humanize=True realistisch.
Wie hier zu sehen ist, gelingt es Camoufox erfolgreich, das Kontrollkästchen anzuklicken. Als Ergebnis sehen Sie im Terminal diese Ausgabe:
Cloudflare Bypassed: TrueAuftrag erfüllt!
Vermeiden Sie Clouflare mit SeleniumBase
Installieren Sie SeleniumBase mit:
pip install seleniumbaseDann verwenden Sie es, um Cloudflare mit zu behandeln:
# pip install seleniumbase
from seleniumbase import Driver
from seleniumbase.common.exceptions import TextNotVisibleException
# Launch in undetected-chromedriver mode
driver = Driver(uc=True)
# Visit the target page
url = "https://www.scrapingcourse.com/cloudflare-challenge"
driver.uc_open_with_reconnect(url, 4)
# Click the Turnstile (if it is present) and reload the page
driver.uc_gui_click_captcha()
try:
# Wait for the desired text to appear
driver.wait_for_text("You bypassed the Cloudflare challenge! :D", "main")
challenge_bypassed = True
except TextNotVisibleException:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
driver.quit()
print("Cloudflare Bypassed:", challenge_bypassed) Im Modus uc=True (der unter der Haube den undetected-chromedriver verwendet) kann SeleniumBase die dedizierte Methode uc_gui_click_captcha() nutzen, um das Turnstile CAPTCHA zu behandeln – falls es erscheint. Dies bedeutet, dass dieses Mal keine eigene Klicklogik erforderlich ist.
Führen Sie das Skript aus und Sie sollten es sehen:
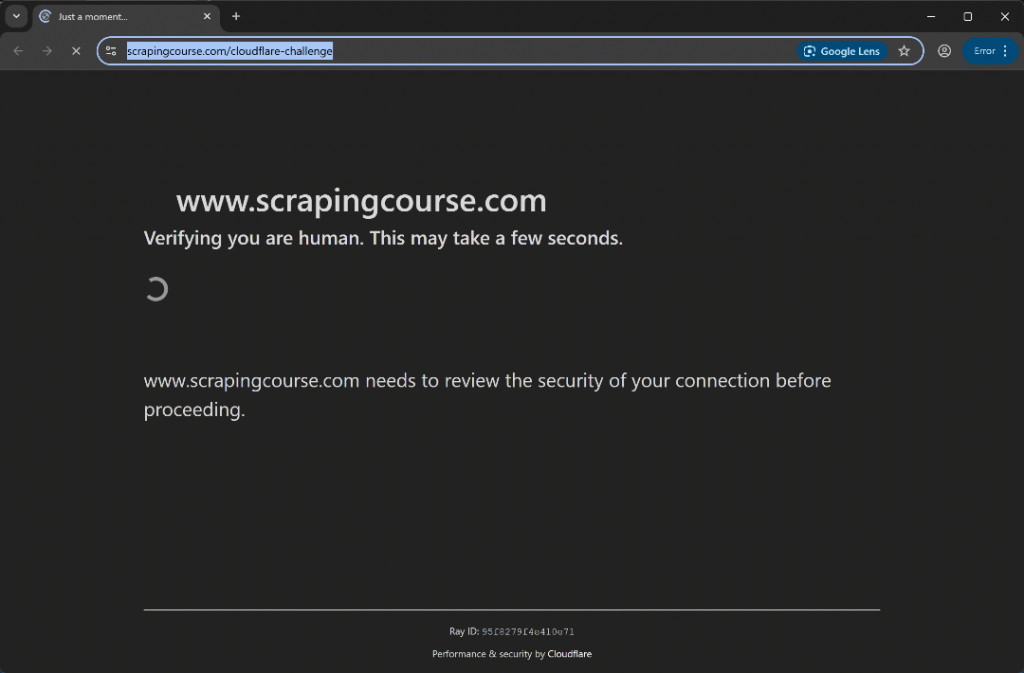
Diesmal umgeht das Automatisierungsskript die anfängliche Überprüfungsphase, ohne das Turnstile CAPTCHA überhaupt auszulösen. In jedem Fall hätte die Methode uc_gui_click_captcha() das CAPTCHA erfolgreich verarbeiten können. Dies ist dank des UC-Modus möglich, über den Sie in unserem SeleniumBase Scraping-Leitfaden mehr erfahren können.
Et voilà! Cloudflare wurde wieder einmal umgangen.
Wie man Cloudflare in großem Maßstab umgeht
Die beiden zuvor vorgestellten Bibliotheken eignen sich gut für einfache Automatisierungsskripte, haben aber drei große Nachteile:
- Um einen hohen Prozentsatz an effektiven Ergebnissen zu erzielen, müssen sie die Browser im Kopfzeilenmodus ausführen. Dies verbraucht eine Menge Systemressourcen und erschwert die Skalierbarkeit.
- Sie sind inkonsistent und können vorübergehend nicht mehr funktionieren, wenn Cloudflare seine Erkennungslogik aktualisiert. Da diese Lösungen von der Community gewartet werden, kann es Tage oder sogar Wochen dauern, bis Updates veröffentlicht werden.
- Es gibt keine offizielle Unterstützung. Sie müssen sich auf Online-Ressourcen und die Hilfe der Community verlassen.
Aus diesen Gründen werden Open-Source-Bibliotheken mit Cloudflare-Umgehungsfunktionen nicht für Produktionsprojekte empfohlen. Für skalierbare, konsistente Ergebnisse – und die Unterstützung eines engagierten 24/7-Supportteams –benötigen Sie Premiumprodukte, wie sie von Bright Data angeboten werden.
Im Einzelnen werden wir uns auf die folgenden beiden Lösungen konzentrieren:
- Web Unlocker: Ein All-in-One-Scraping-Endpunkt, der alle Anti-Bot-Bypass-Funktionen enthält, um HTML von jeder Website abzurufen.
- Browser-API: Ein unendlich skalierbarer Cloud-Browser, der jeden Automatisierungsworkflow unterstützt. Er lässt sich mit Puppeteer, Selenium, Playwright und jedem anderen Browser-Automatisierungstool integrieren. Er umfasst eine erweiterte Fingerabdruckverwaltung, eine integrierte CAPTCHA-Lösung und eine automatische Proxy-Rotation.
Sehen Sie, wie Sie diese Werkzeuge in Python (obwohl sie jede Programmiersprache unterstützen) in Ihre Automatisierungsskripte integrieren können!
Umgehung von Cloudflare mit Web Unlocker
Bevor Sie beginnen, folgen Sie der offiziellen Anleitung zum kostenlosen Einrichten von Web Unlocker in Ihrem Bright Data-Konto. Sie müssen außerdem einen Bright Data-API-Schlüssel für die Authentifizierung Ihrer Anforderungen an den Web Unlocker-Endpunkt generieren.
Wir gehen hier davon aus, dass der Name Ihrer Web Unlocker Zone web_unlocker lautet.
Sobald Sie die oben genannten Schritte abgeschlossen haben, testen Sie Web Unlocker mit der in diesem Artikel verwendeten Zielseite:
# pip install requests
import requests
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": "web_unlocker", # Replace with the name of your Web Unlocker zone
"url": "https://www.scrapingcourse.com/cloudflare-challenge",
"format": "raw"
}
# Perform a request to the Web Unlocker endpoint
response = requests.post(
"https://api.brightdata.com/request",
json=data,
headers=headers
)
# Get the response and check if Cloudflare was bypassed
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html)Web Unlocker gibt den HTML-Inhalt der Seite hinter der Cloudflare-Verifizierungswand zurück. Insbesondere wird die Variable html einen Inhalt wie diesen enthalten:
<!doctype html>
<html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Cloudflare Challenge - ScrapingCourse.com</title>
<!-- omitted for brevity ... -->
<main class="page-content py-4" id="main-content" data-testid="main-content" data-content="main">
<div class="container" id="content-container" data-testid="content-container" data-content="container">
<div class="cloudflareChallenge">
<h1 id="page-title" class="page-title text-4xl font-bold mb-2 text-left gradient-text highlight gradient-text leading-10" data-testid="page-title" data-content="title">
Cloudflare Challenge
</h1>
<div class="challenge-info bg-[#EDF1FD] rounded-md p-4 mb-8 mt-5" id="challenge-info" data-testid="challenge-info" data-content="challenge-info">
<div class="info-header flex items-center gap-2 pb-2" id="info-header" data-testid="info-header" data-content="info-header">
<img width="25" height="15" src="https://www.scrapingcourse.com/assets/images/challenge.svg" data-testid="challenge-image" data-content="challenge-image">
<h2 class="challenge-title text-xl font-bold" id="challenge-title" data-testid="challenge-title" data-content="challenge-title">
You bypassed the Cloudflare challenge! 😀
</h2>
</div>
</div>
</div>
</div>
</main>
<!-- omitted for brevity ... -->
</html>Dies ist genau der HTML-Inhalt der Seite, die sich hinter der Cloudflare-Mauer zur menschlichen Überprüfung befindet. Daher ist es keine Überraschung, dass die Ausgabe des Skripts so aussieht:
Cloudflare Bypassed: TrueBeachten Sie, dass Ihnen nur erfolgreiche Anfragen in Rechnung gestellt werden, und dass eine kostenlose Testversion verfügbar ist!
Cloudflare mit Browser-API automatisieren
Als Voraussetzung müssen Sie in Ihrem Bright Data-Konto ein Browser-API-Produkt einrichten. Kopieren Sie auf der Zonenseite die CDP-Verbindungs-URL von Playwright:
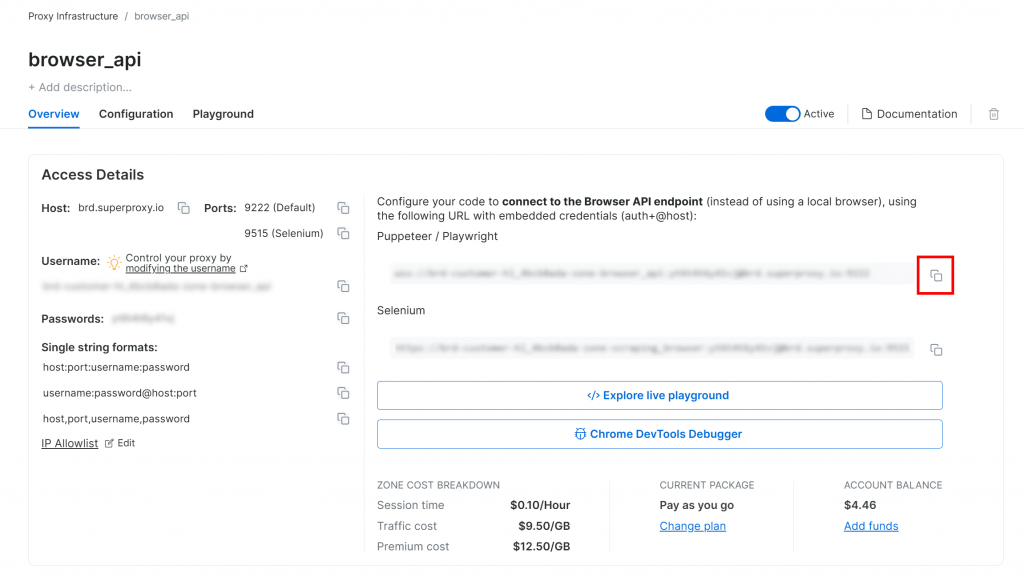
Diese URL enthält Ihre Anmeldeinformationen und ermöglicht es Ihnen, eine beliebige Browser-Automatisierungslösung, die Remote-CDP(Chrome DevTools Protocol) unterstützt, anzuweisen, eine Verbindung zur Bright Data-Browser-API herzustellen. Mit anderen Worten: Ihr Automatisierungstool wird auf einer remote gehosteten Browserinstanz betrieben, die von Bright Data verwaltet wird. Das bedeutet, dass Skalierbarkeit und Browser-Wartung für Sie übernommen werden.
Erweitern Sie das zuvor gezeigte Playwright-Skript, um eine Verbindung zur Browser-API über die CDP-URL herzustellen:
# pip install playwright
# python install -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
BRIGHT_DATA_API_CDP_URL = "<YOUR_BRIGHT_DATA_API_CDP_URL>" # Replace with your Browser API Playwright CDP URL
with sync_playwright() as p:
# Connect to the remote Browser API
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_API_CDP_URL)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Dieses Mal wird das Skript die Cloudflare-Überprüfung dank der fortgeschrittenen Fähigkeiten der Browser-API erfolgreich umgehen. Sie werden die folgende Ausgabe im Terminal sehen:
Cloudflare Bypassed: TrueGut gemacht! Die Umgehung von Cloudflare ist kein Problem mehr.
Schlussfolgerung
In diesem Artikel haben Sie erfahren, wie Cloudflare funktioniert, und praktische Lösungen zur Umgehung von Cloudflare in Ihren Automatisierungsabläufen erkundet. Wie Sie hier gesehen haben, ist die Umgehung der Anti-Scraping-Maßnahmen von Cloudflare eine Herausforderung, aber durchaus möglich.
Ganz gleich, für welchen Ansatz Sie sich entscheiden, mit professionellen, schnellen und zuverlässigen Lösungen wie diesen wird alles einfacher:
- Web Unlocker: Ein Endpunkt, der automatisch Ratenbegrenzungen, Fingerprinting und andere Anti-Bot-Beschränkungen für Sie umgeht.
- Browser-API: Ein vollständig gehosteter Browser, mit dem Sie die Interaktion mit beliebigen Webseiten automatisieren können.
Melden Sie sich jetzt kostenlos an und finden Sie heraus, welche Lösung von Bright Data am besten zu Ihren Bedürfnissen passt!




