

In diesem Leitfaden erfahren Sie:
- Was SeleniumBase ist und warum es für das Web-Scraping nützlich ist
- Wie es sich von Vanilla Selenium unterscheidet
- Welche Funktionen und Vorteile SeleniumBase bietet
- Wie Sie damit einen einfachen Scraper erstellen
- Wie Sie es für komplexere Anwendungsfälle nutzen können
Lassen Sie uns loslegen!
Was ist SeleniumBase?
SeleniumBase ist ein Python-Framework für die Browser-Automatisierung. Es basiert auf den Selenium/WebDriver-APIs und bietet ein professionelles Toolkit für die Web-Automatisierung. Es unterstützt eine Vielzahl von Aufgaben, vom Testen bis zum Scraping.
SeleniumBase ist eine All-in-One-Bibliothek zum Testen von Webseiten, zur Automatisierung von Workflows und zur Skalierung webbasierter Vorgänge. Es verfügt über erweiterte Funktionen wie CAPTCHA-Umgehung, Vermeidung von Bot-Erkennung und Tools zur Produktivitätssteigerung.
SeleniumBase vs. Selenium: Vergleich der Funktionen und APIs
Um die Gründe für SeleniumBase besser zu verstehen, ist es sinnvoll, es direkt mit der Vanilla-Version von Selenium zu vergleichen – dem Tool, auf dem es basiert.
Einen schnellen Vergleich zwischen Selenium und SeleniumBase finden Sie in der folgenden Übersichtstabelle:
| Funktion | SeleniumBase | Selenium |
|---|---|---|
| Integrierte Test-Runner | Integriert mit pytest, pynose und behave |
Erfordert manuelle Einrichtung für die Testintegration |
| Treiberverwaltung | Lädt automatisch den zur Browserversion passenden Treiber herunter | Erfordert manuelles Herunterladen und Konfigurieren des Treibers |
| Web-Automatisierungslogik | Kombiniert mehrere Schritte in einem einzigen Methodenaufruf | Erfordert mehrere Codezeilen für ähnliche Funktionen |
| Selektor-Handhabung | Erkennt automatisch CSS- oder XPath-Selektoren | Erfordert die explizite Definition von Selektortypen in Methodenaufrufen |
| Zeitüberschreitungsbehandlung | Wendet Standard-Timeouts an, um Fehler zu vermeiden | Methoden schlagen sofort fehl, wenn keine Timeouts explizit festgelegt sind |
| Fehlerausgaben | Bietet übersichtliche, lesbare Fehlermeldungen für eine einfachere Fehlerbehebung | Erzeugt ausführliche und weniger interpretierbare Fehlerprotokolle |
| Dashboards und Berichte | Enthält integrierte Dashboards, Berichte und Screenshots von Fehlern | Keine integrierten Dashboards oder Berichtsfunktionen |
| Desktop-GUI-Anwendungen | Bietet visuelle Tools für die Testausführung | Keine Desktop-GUI-Tools für die Testausführung |
| Testrekorder | Integrierter Testrekorder zum Erstellen von Skripten aus manuellen Browseraktionen | Erfordert manuelles Schreiben von Skripten |
| Testfallverwaltung | Bietet CasePlans zum Organisieren von Tests und zum Dokumentieren von Schritten direkt im Framework | Keine integrierten Tools zur Testfallverwaltung |
| Unterstützung für Daten-Apps | Enthält ChartMaker zum Generieren von JavaScript aus Python zum Erstellen von Daten-Apps | Keine zusätzlichen Tools zum Erstellen von Daten-Apps |
Zeit, sich mit den Unterschieden auseinanderzusetzen!
Integrierte Test-Runner
SeleniumBase lässt sich in gängige Testrunner wie pytest, pynose und behave integrieren. Diese Tools bieten eine übersichtliche Struktur, nahtlose Testerkennung, Ausführung, Teststatusverfolgung (z. B. bestanden, fehlgeschlagen oder übersprungen) und Befehlszeilenoptionen zum Anpassen von Einstellungen wie der Browserauswahl.
Mit Vanilla Selenium müssten Sie manuell einen Optionsparser implementieren oder sich auf Tools von Drittanbietern verlassen, um Tests über die Befehlszeile zu konfigurieren.
Verbesserte Treiberverwaltung
Standardmäßig lädt SeleniumBase eine kompatible Treiberversion herunter, die der Hauptversion Ihres Browsers entspricht. Sie können dies mit der Option --driver-version=VER in Ihrem pytest-Befehl überschreiben. Beispiel:
pytest my_script.py --driver-version=114
Stattdessen müssen Sie bei Selenium den entsprechenden Treiber manuell herunterladen und konfigurieren. In diesem Fall sind Sie selbst dafür verantwortlich, die Kompatibilität mit der Browserversion sicherzustellen.
Multi-Action-Methoden
SeleniumBase kombiniert mehrere Schritte zu einzelnen Methoden, um die Webautomatisierung zu vereinfachen. Die Methode driver.type(selector, text) führt beispielsweise Folgendes aus:
- Wartet, bis das Element sichtbar ist
- Wartet, bis das Element interaktiv ist
- Löscht vorhandenen Text
- Gibt den angegebenen Text ein
- Sendet, wenn der Text mit
„n”endet
Mit Raw Selenium wären für die Nachbildung derselben Logik einige Zeilen Code erforderlich.
Vereinfachte Selektor-Verarbeitung
SeleniumBase kann automatisch zwischen CSS-Selektoren und XPath-Ausdrücken unterscheiden. Dadurch entfällt die Notwendigkeit, Selektortypen explizit mit By.CSS_SELECTOR oder By.XPATH anzugeben. Sie können den Typ jedoch weiterhin explizit angeben, wenn Sie dies bevorzugen.
Beispiel mit SeleniumBase:
driver.click("button.submit") # Wird automatisch als CSS-Selektor erkannt
driver.click("//button[@class='submit']") # Wird automatisch als XPath erkannt
Der entsprechende Code in Vanilla Selenium lautet:
driver.find_element(By.CSS_SELECTOR, "button.submit").click()
driver.find_element(By.XPATH, "//button[@class='submit']").click()
Standard- und benutzerdefinierte Zeitüberschreitungswerte
SeleniumBase wendet automatisch eine Standard-Zeitüberschreitung von 10 Sekunden auf Methoden an, um sicherzustellen, dass Elemente Zeit zum Laden haben. Dadurch werden sofortige Fehler verhindert, die bei Raw Selenium häufig auftreten.
Sie können benutzerdefinierte Zeitüberschreitungswerte auch direkt in Methodenaufrufen festlegen, wie im folgenden Beispiel gezeigt:
driver.click("button", timeout=20)
Der entsprechende Selenium-Code wäre viel ausführlicher und komplexer:
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button"))).click()
Klare Fehlermeldungen
SeleniumBase liefert übersichtliche, leicht verständliche Fehlermeldungen, wenn Skripte fehlschlagen. Im Gegensatz dazu generiert Raw Selenium oft ausführliche und weniger interpretierbare Fehlerprotokolle, deren Debugging zusätzlichen Aufwand erfordert.
Dashboards, Berichte und Screenshots
SeleniumBase enthält Funktionen zum Erstellen von Dashboards und Berichten für Testläufe. Außerdem werden Screenshots von Fehlern im Ordner ./latest_logs/ gespeichert, um die Fehlerbehebung zu vereinfachen. Raw Selenium verfügt standardmäßig nicht über diese Funktionen.
Zusätzliche Funktionen
Im Vergleich zu Selenium bietet SeleniumBase:
- Desktop-GUI-Anwendungen zur visuellen Ausführung von Tests, wie z. B. SeleniumBase Commander für
pytestund SeleniumBase Behave GUI fürbehave. - Einen integrierten Recorder/Testgenerator zum Erstellen von Testskripten auf der Grundlage manueller Browseraktionen. Dies reduziert den Aufwand für das Schreiben von Tests für komplexe Workflows erheblich.
- Testfall-Management-Software namens CasePlans zum Organisieren von Tests und Dokumentieren von Schrittbeschreibungen direkt innerhalb des Frameworks.
- Tools wie ChartMaker zum Erstellen von Daten-Apps durch Generieren von JavaScript-Code aus Python. Damit ist es eine vielseitige Lösung, die über die Standard-Testautomatisierung hinausgeht.
SeleniumBase: Funktionen, Methoden und CLI-Optionen
Entdecken Sie, was SeleniumBase so besonders macht, indem Sie sich mit seinen Funktionen und seiner API vertraut machen.
Funktionen
Hier finden Sie eine Liste der wichtigsten Funktionen von SleniumBase:
- Enthält einen Aufzeichnungsmodus zum sofortigen Generieren von Browsertests in Python.
- Unterstützt mehrere Browser, Tabs, Iframes und Proxys innerhalb desselben Tests.
- Verfügt über eine Testfall-Management-Software mit Markdown-Technologie.
- Intelligenter Warte-Mechanismus verbessert automatisch die Zuverlässigkeit und reduziert unzuverlässige Tests.
- Kompatibel mit
pytest,unittest,noseundbehavefür die Testerkennung und -ausführung. - Enthält erweiterte Protokollierungstools für Dashboards, Berichte und Screenshots.
- Kann Tests im Headless-Modus ausführen, um die Browser-Oberfläche auszublenden.
- Unterstützt die Multithread-Testausführung über parallele Browser hinweg.
- Ermöglicht die Ausführung von Tests mit dem Emulator für mobile Geräte von Chromium.
- Unterstützt die Ausführung von Tests über einen Proxy-Server, auch über einen authentifizierten.
- Passt die User-Agent-Zeichenfolge des Browsers für Tests an.
- Verhindert die Erkennung durch Websites, die Selenium-Automatisierung blockieren.
- Integriert sich mit selenium-wire zur Überprüfung von Browser-Netzwerkanfragen.
- Flexible Befehlszeilenschnittstelle für benutzerdefinierte Testausführungsoptionen.
- Globale Konfigurationsdatei zur Verwaltung der Testeinstellungen.
- Unterstützt Integrationen mit GitHub Actions, Google Cloud, Azure, S3 und Docker.
- Unterstützt die Ausführung von JavaScript aus Python.
- Kann mit Shadow-DOM-Elementen interagieren, indem
::shadowin CSS-Selektoren verwendet wird.
Die vollständige Listefinden Sie in der Dokumentation. Lesen Sie unbedingt unseren Blogbeitrag zur Verwendung von SeleniumBase mit Proxys.
Methoden
Nachfolgend finden Sie eine Liste der nützlichsten SeleniumBase-Methoden:
driver.open(url): Navigiert das Browserfenster zur angegebenen URL.driver.go_back(): Navigieren Sie zurück zur vorherigen URL.driver.type(selector, text): Aktualisieren Sie das durch den Selektor identifizierte Feld mit dem angegebenen Text.driver.click(selector): Klicken Sie auf das durch den Selektor identifizierte Element.driver.click_link(link_text): Klicken Sie auf den Link, der den angegebenen Text enthält.driver.select_option_by_text(dropdown_selector, option): Wählen Sie eine Option aus einem Dropdown-Menü anhand des sichtbaren Texts aus.driver.hover_and_click(hover_selector, click_selector): Bewegen Sie den Mauszeiger über ein Element und klicken Sie auf ein anderes.driver.drag_and_drop(drag_selector, drop_selector): Ziehen Sie ein Element und legen Sie es auf einem anderen Element ab.driver.get_text(selector): Rufen Sie den Text des angegebenen Elements ab.driver.get_attribute(selector, attribute): Rufen Sie das angegebene Attribut eines Elements ab.driver.get_current_url(): Ruft die URL der aktuellen Seite ab.driver.get_page_source(): Rufen Sie den HTML-Quellcode der aktuellen Seite ab.driver.get_title(): Ruft den Titel der aktuellen Seite ab.driver.switch_to_frame(frame): Wechselt zum angegebenen iframe-Container.driver.switch_to_default_content(): Den iframe-Container verlassen und zum Hauptdokument zurückkehren.driver.open_new_window(): Öffnet ein neues Browserfenster in derselben Sitzung.driver.switch_to_window(window): Wechselt zum angegebenen Browserfenster.driver.switch_to_default_window(): Zurück zum ursprünglichen Browserfenster.driver.get_new_driver(OPTIONS): Öffnen Sie eine neue Treibersitzung mit den angegebenen Optionen.driver.switch_to_driver(driver): Wechselt zum angegebenen Browser-Treiber.driver.switch_to_default_driver(): Zurück zum ursprünglichen Browser-Treiber.driver.wait_for_element(selector): Warten, bis das angegebene Element sichtbar ist.driver.is_element_visible(selector): Überprüfen, ob das angegebene Element sichtbar ist.driver.is_text_visible(text, selector): Überprüfen Sie, ob der angegebene Text innerhalb eines Elements sichtbar ist.driver.sleep(seconds): Die Ausführung für die angegebene Zeit unterbrechen.driver.save_screenshot(name): Speichert einen Screenshot imPNG-Formatunter dem angegebenen Namen.driver.assert_element(selector): Überprüfen Sie, ob das angegebene Element sichtbar ist.driver.assert_text(text, selector): Überprüfen Sie, ob der angegebene Text im Element vorhanden ist.driver.assert_exact_text(text, selector): Überprüft, ob der angegebene Text genau mit dem Element übereinstimmt.driver.assert_title(title): Überprüft, ob der Titel der aktuellen Seite mit dem angegebenen Titel übereinstimmt.driver.assert_downloaded_file(file): Überprüfen Sie, ob die angegebene Datei heruntergeladen wurde.driver.assert_no_404_errors(): Überprüfen Sie, ob die Seite keine defekten Links enthält.driver.assert_no_js_errors(): Überprüfen Sie, ob auf der Seite keine JavaScript-Fehler vorhanden sind.
Die vollständige Liste finden Sie in der Dokumentation.
CLI-Optionen
SeleniumBase erweitert pytest um die folgenden Befehlszeilenoptionen:
--browser=BROWSER: Legt den Webbrowser fest (Standard: „chrome“).--chrome: Abkürzung für--browser=chrome.--edge: Abkürzung für--browser=edge.--firefox: Abkürzung für--browser=firefox.--safari: Abkürzung für--browser=safari.--settings-file=DATEI: Überschreibt die Standard-Einstellungen von SeleniumBase.--env=ENV: Legt die Testumgebung fest, auf die überdriver.envzugegriffen werden kann.--account=STR: Konto festlegen, zugänglich überdriver.account.--data=STRING: Zusätzliche Testdaten, zugänglich überdriver.data.--var1=STRING: Zusätzliche Testdaten, zugänglich überdriver.var1.--var2=STRING: Zusätzliche Testdaten, zugänglich überdriver.var2.--var3=STRING: Zusätzliche Testdaten, zugänglich überdriver.var3.--variables=DICT: Zusätzliche Testdaten, zugänglich überdriver.variables.--proxy=SERVER:PORT: Verbindung zu einem Proxy-Server herstellen.--proxy=USERNAME:PASSWORD@SERVER:PORT: Verwendung eines authentifizierten Proxy-Servers.--proxy-bypass-list=STRING: Zu umgehende Hosts (z. B. „*.foo.com“).--proxy-pac-url=URL: Verbindung über PAC-URL herstellen.--proxy-pac-url=BENUTZERNAME:PASSWORT@URL: Authentifizierter Proxy mit PAC-URL.--proxy-driver: Proxy für Treiber-Download verwenden.--multi-proxy: Mehrere authentifizierte Proxys in Multithreading zulassen.--agent=STRING: Ändern Sie die User-Agent-Zeichenfolge des Browsers.--mobile: Mobilgeräte-Emulator aktivieren.--metrics=STRING: Mobile Metriken festlegen (z. B. „CSSWidth,CSSHeight,PixelRatio“).--chromium-arg="ARG=N,ARG2": Chromium-Argumente festlegen.--firefox-arg="ARG=N,ARG2": Firefox-Argumente festlegen.--firefox-pref=SET: Firefox-Einstellungen festlegen.--extension-zip=ZIP: Chrome-Erweiterungsdateienim ZIP-oder CRX-Formatladen.--extension-dir=DIR: Chrome-Erweiterungsverzeichnisse laden.--disable-features="F1,F2": Funktionen deaktivieren.--binary-location=PATH: Chromium-Binärpfad festlegen.--driver-version=VER: Treiberversion festlegen.--headless: Standardmäßiger Headless-Modus.--headless1: Den alten Headless-Modus von Chrome verwenden.--headless2: Neuen Headless-Modus von Chrome verwenden.--headed: GUI-Modus unter Linux aktivieren.--xvfb: Führen Sie Tests mit Xvfb unter Linux aus.--locale=LOCALE_CODE: Legt die Spracheinstellung des Browsers fest.--reuse-session: Browsersitzung für alle Tests wiederverwenden.--reuse-class-session: Sitzung für Klassentests wiederverwenden.--crumbs: Cookies zwischen wiederverwendeten Sitzungen löschen.--disable-cookies: Cookies deaktivieren.--disable-js: Deaktiviert JavaScript.--disable-csp: Content Security Policy deaktivieren.--disable-ws: Web-Sicherheit deaktivieren.--enable-ws: Web-Sicherheit aktivieren.--log-cdp: Chrome DevTools Protocol (CDP)-Ereignisse protokollieren.--remote-debug: Mit Chrome Remote Debugger synchronisieren.--visual-baseline: Visuelle Basislinie für Layout-Tests festlegen.--timeout-multiplier=MULTIPLIER: Multipliziert die Standard-Timeout-Werte.
Die vollständige Liste der Befehlszeilenoptionen finden Sie in der Dokumentation.
Verwendung von SeleniumBase für Web-Scraping: Schritt-für-Schritt-Anleitung
Befolgen Sie diese Schritt-für-Schritt-Anleitung, um zu erfahren, wie Sie einen SeleniumBase-Scraper erstellen, um Daten aus der Sandbox „Quotes to Scrape“ abzurufen:
Eine ähnliche Anleitung für die Verwendung von Vanilla Selenium finden Sie in unserem Leitfaden zum Web-Scraping mit Selenium.
Schritt 1: Initialisierung des Projekts
Bevor Sie beginnen, stellen Sie sicher, dass Python 3 auf Ihrem Computer installiert ist. Ist dies nicht der Fall, laden Sie es herunter und installieren Sie es.
Öffnen Sie das Terminal und führen Sie den folgenden Befehl aus, um ein Verzeichnis für Ihr Projekt zu erstellen:
mkdir seleniumbase-Scraper
seleniumbase-scraper enthält Ihren SeleniumBase-Scraper.
Navigieren Sie dorthin und initialisieren Sie eine virtuelle Umgebung darin:
cd seleniumbase-Scraper
python -m venv env
Laden Sie anschließend den Projektordner in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind dafür geeignet.
Erstellen Sie eine Datei scraper.py im Projektverzeichnis, das nun folgende Dateistruktur aufweisen sollte:

scraper.py wird in Kürze Ihre Scraping-Logik enthalten.
Aktivieren Sie die virtuelle Umgebung im Terminal der IDE. Unter Linux oder macOS führen Sie dazu den folgenden Befehl aus:
./env/bin/activate
Unter Windows führen Sie stattdessen folgenden Befehl aus:
env/Scripts/activate
Starten Sie in der aktivierten Umgebung diesen Befehl, um SeleniumBase zu installieren:
pip install seleniumbase
Großartig! Sie haben nun eine Python-Umgebung für das Web-Scraping mit SeleniumBase.
Schritt 2: SeleniumBase-Test-Setup
SeleniumBase unterstützt zwar die pytest- Syntax zum Erstellen von Tests, aber ein Web-Scraping-Bot ist kein Testskript. Sie können dennoch alle Optionen der SeleniumBase -pytest -Befehlszeilen -Erweiterung nutzen, indem Sie die SB-Syntax verwenden:
from seleniumbase import SB
with SB() as sb:
pass
# Scraping-Logik...
Sie können Ihren Test nun mit folgendem Befehl ausführen:
python3 Scraper.py
Hinweis: Unter Windows ersetzen Sie python3 durch python.
Um ihn im Headless-Modus auszuführen, führen Sie Folgendes aus:
python3 Scraper.py --headless
Beachten Sie, dass Sie mehrere Befehlszeilenoptionen kombinieren können.
Schritt 3: Verbindung zur Zielseite herstellen
Verwenden Sie die Methode open(), um den gesteuerten Browser anzuweisen, Ihre Zielseite aufzurufen:
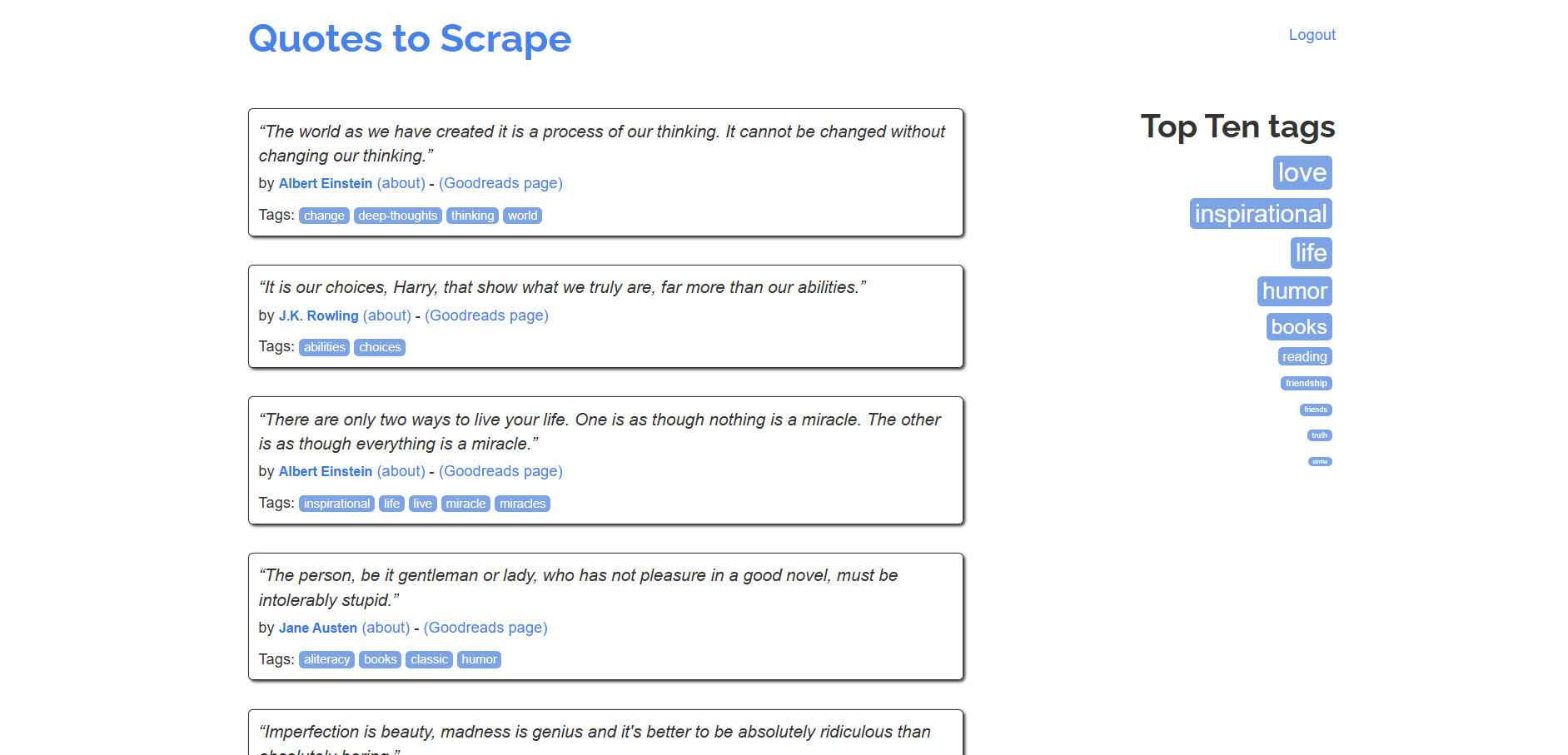
sb.open("https://quotes.toscrape.com/")
Wenn Sie das Scraping-Testskript im Headless-Modus ausführen, sehen Sie für den Bruchteil einer Sekunde Folgendes:
Beachten Sie, dass Sie im Vergleich zu Vanilla Selenium den Treiber nicht manuell schließen müssen. SeleniumBase übernimmt dies für Sie.
Schritt 4: Wählen Sie die Quote-Elemente aus
Öffnen Sie die Zielseite im Inkognito-Modus Ihres Browsers und überprüfen Sie ein Zitat-Element:
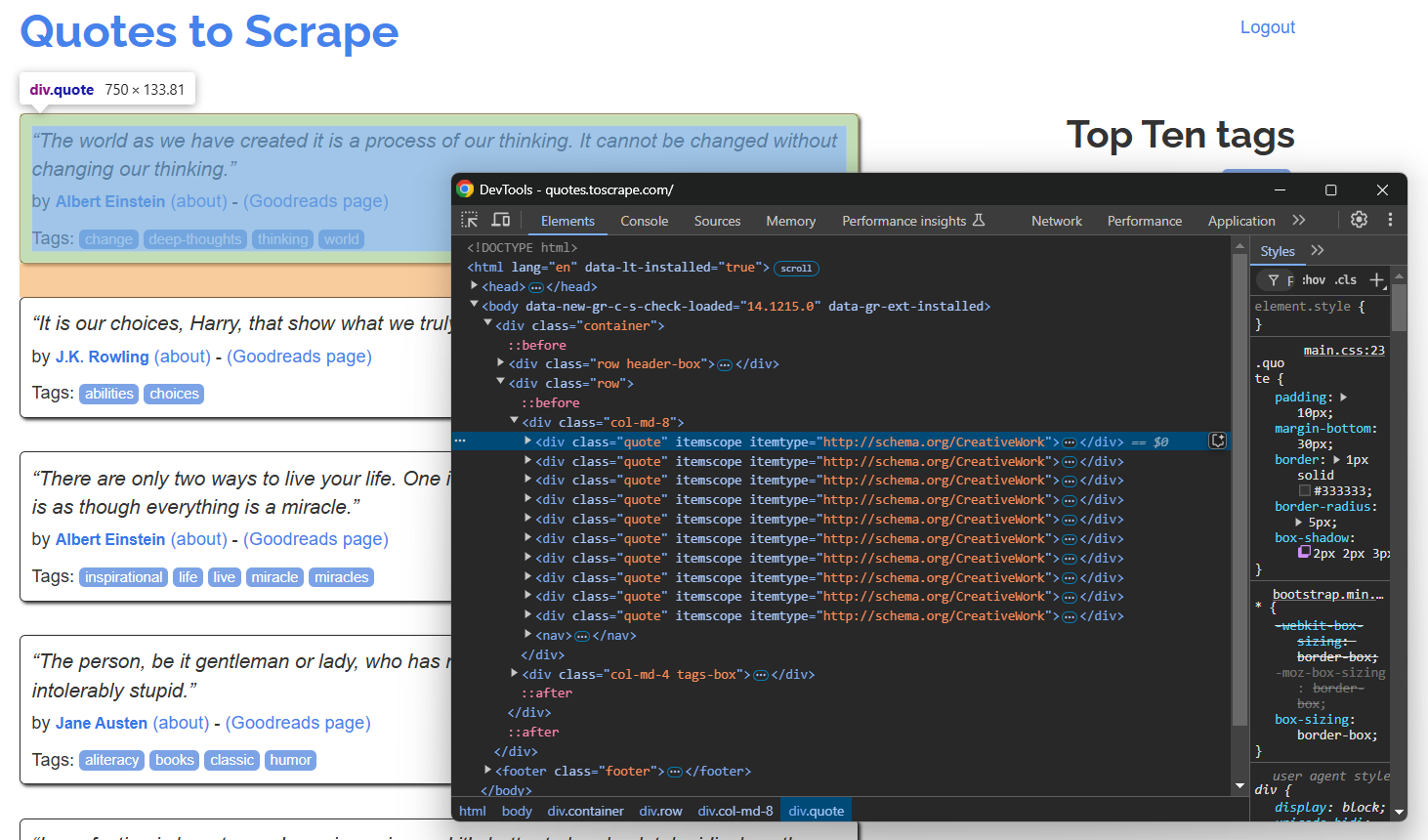
Da die Seite mehrere Zitate enthält, erstellen Sie ein Zitate -Array, um die gescrapten Daten zu speichern:
quotes = []
Im Abschnitt „DevTools“ oben sehen Sie, dass alle Zitate mit dem CSS-Selektor .quote ausgewählt werden können. Verwenden Sie find_elements(), um sie alle auszuwählen:
quote_elements = sb.find_elements(".quote")
Bereiten Sie als Nächstes die Iteration über die Elemente vor und scrapen Sie die Daten aus jedem Zitat-Element. Fügen Sie die gescrapten Daten zu einem Array hinzu:
for quote_element in quote_elements:
# Scraping-Logik...
Großartig! Die allgemeine Extraktionslogik ist nun fertig.
Schritt 5: Zitierdaten extrahieren
Untersuchen Sie ein einzelnes Zitat-Element:
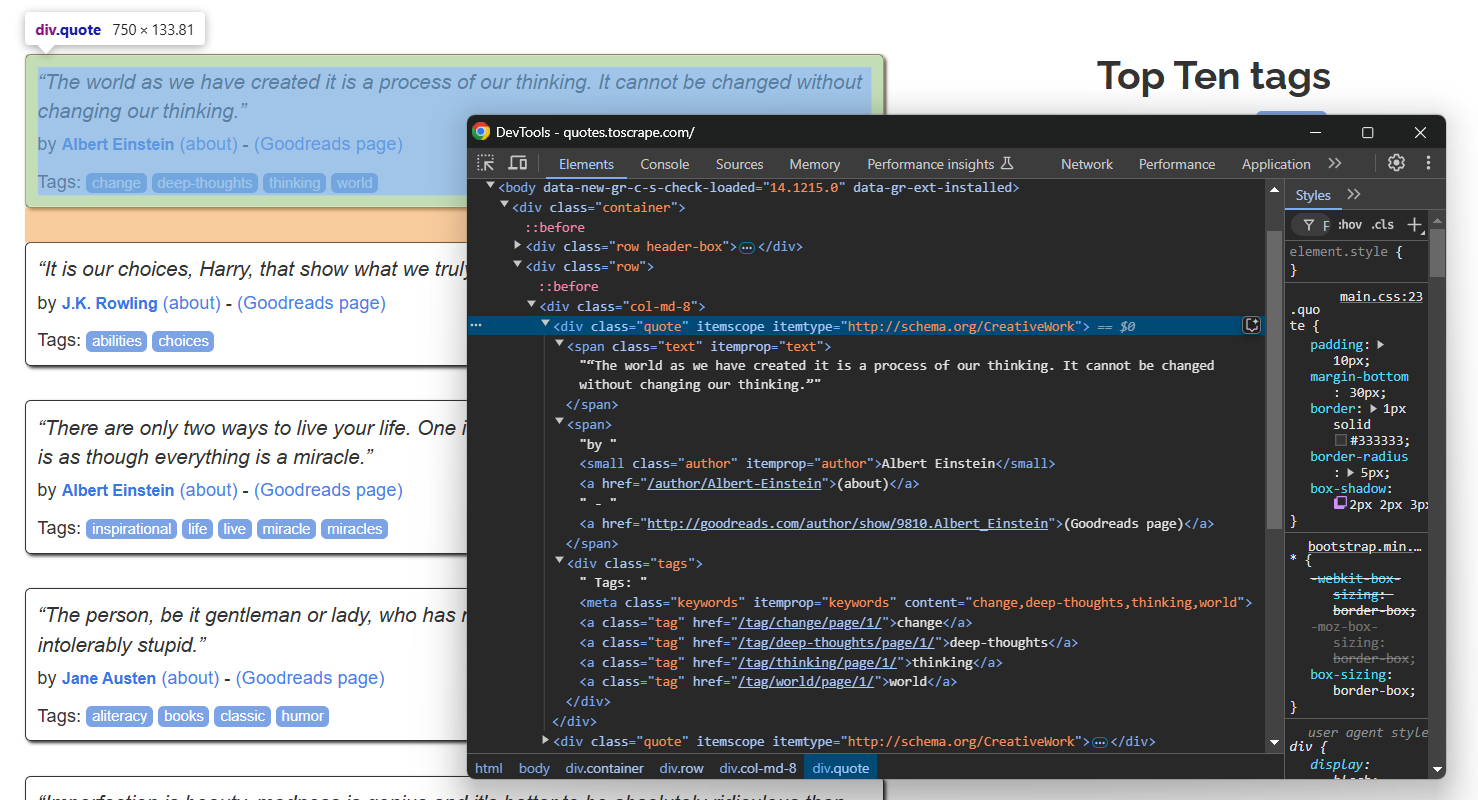
Beachten Sie, dass Sie Folgendes extrahieren können:
- Den Zitattext aus
.text - Den Autor des Zitats aus
.author - Die Zitat-Tags aus
.tag
Wählen Sie jeden Knoten aus und extrahieren Sie Daten daraus mit dem Text attribut:
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
Beachten Sie, dass find_elements() einfache Selenium-WebElement-Objekte zurückgibt. Um Elemente darin auszuwählen, müssen Sie daher die nativen Methoden von Selenium verwenden. Aus diesem Grund müssen Sie By.CSS_SELECTOR als Locator angeben.
Stellen Sie sicher, dass Sie By am Anfang Ihres Skripts importieren:
from selenium.webdriver.common.by import By
Beachten Sie, dass zum Scraping der Tags eine Schleife erforderlich ist, da ein einzelnes Zitat ein oder mehrere Tags enthalten kann. Beachten Sie auch die Verwendung der Methode replace(), um die speziellen doppelten Anführungszeichen zu entfernen, die den Text umgeben.
Schritt 6: Füllen Sie das Zitate-Array
Füllen Sie ein neues Zitate -Objekt mit den gescrapten Daten und fügen Sie es zu quotes hinzu:
quote = {
"text": text,
"author": author,
"tags": tags
}
quotes.append(quote)
Fantastisch! Die SelenumBase-Scraping-Logik ist fertig.
Schritt 7: Crawling-Logik implementieren
Denken Sie daran, dass die Zielwebsite mehrere Seiten enthält. Um zur nächsten Seite zu navigieren, klicken Sie unten auf die Schaltfläche „Weiter →“:
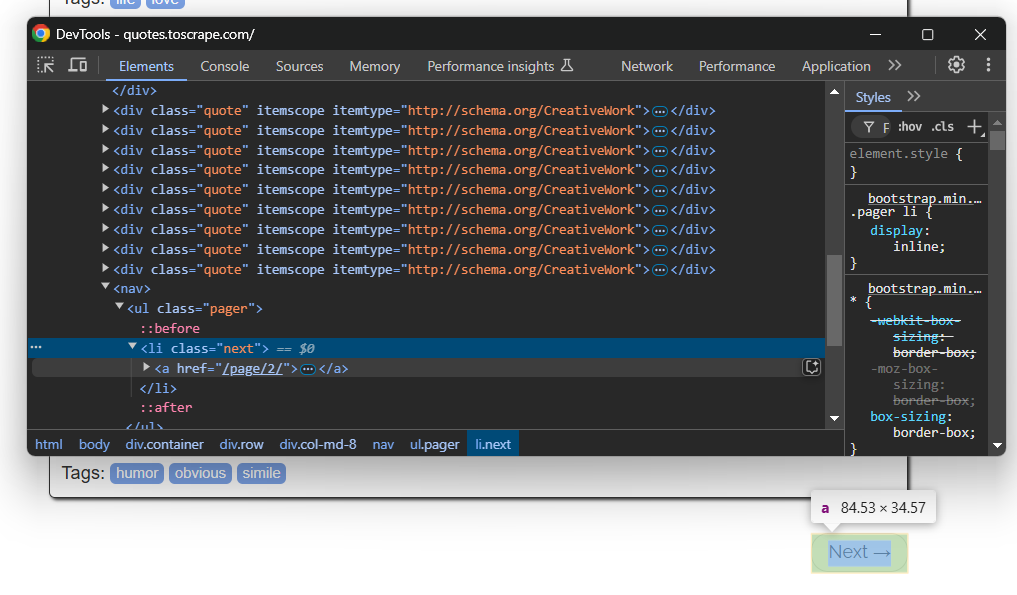
Auf der letzten Seite ist diese Schaltfläche nicht vorhanden.
Um das Web-Crawling zu implementieren und alle Seiten zu scrapen, fügen Sie Ihre Scraping-Logik in eine Schleife ein, die auf die Schaltfläche „Weiter →” klickt und stoppt, wenn die Schaltfläche nicht mehr verfügbar ist:
while sb.is_element_present(".next"):
# Scraping-Logik...
# Besuchen Sie die nächste Seite.
sb.click(".next a")
Beachten Sie die Verwendung der speziellen SleniumBae-Methode is_element_present(), um zu überprüfen, ob die Schaltfläche vorhanden ist oder nicht.
Perfekt! Ihr SeleniumBase-Scraper durchläuft nun die gesamte Website.
Schritt 8: Exportieren der gescrapten Daten
Exportieren Sie die gescrapten Daten in Anführungszeichen wie folgt in eine CSV-Datei:
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# Glätten Sie die Zitatobjekte für das Schreiben in CSV.
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
Vergessen Sie nicht, csv aus der Python-Standardbibliothek zu importieren:
import csv
Schritt 9: Alles zusammenfügen
Ihre Datei script.py sollte nun den folgenden Code enthalten:
from seleniumbase import SB
from selenium.webdriver.common.by import By
import csv
with SB() as sb:
# Mit der Zielseite verbinden
sb.open("https://quotes.toscrape.com/")
# Speicherort für die gescrapten Daten
quotes = []
# Alle Zitatseiten durchlaufen
while sb.is_element_present(".next"):
# Alle Zitat-Elemente auf der Seite auswählen
quote_elements = sb.find_elements(".quote")
# Diese durchlaufen und Daten für jedes Zitat-Element scrapen
for quote_element in quote_elements:
# Logik zur Datenextraktion
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# Neues Zitat-Objekt mit den gescrapten Daten füllen
quote = {
"text": text,
"author": author,
"tags": tags
}
# Zur Liste der gescrapten Zitate hinzufügen
quotes.append(quote)
# Nächste Seite aufrufen
sb.click(".next a")
# Exportiere die gesammelten Daten in CSV
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# Die Zitatobjekte für das Schreiben in CSV flach machen
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
Führen Sie den SeleniumBase-Scraper im Headless-Modus aus mit:
python3 script.py --headless
Nach einigen Sekunden erscheint eine Datei namens quotes.csv im Projektordner.
Öffnen Sie sie, und Sie sehen:
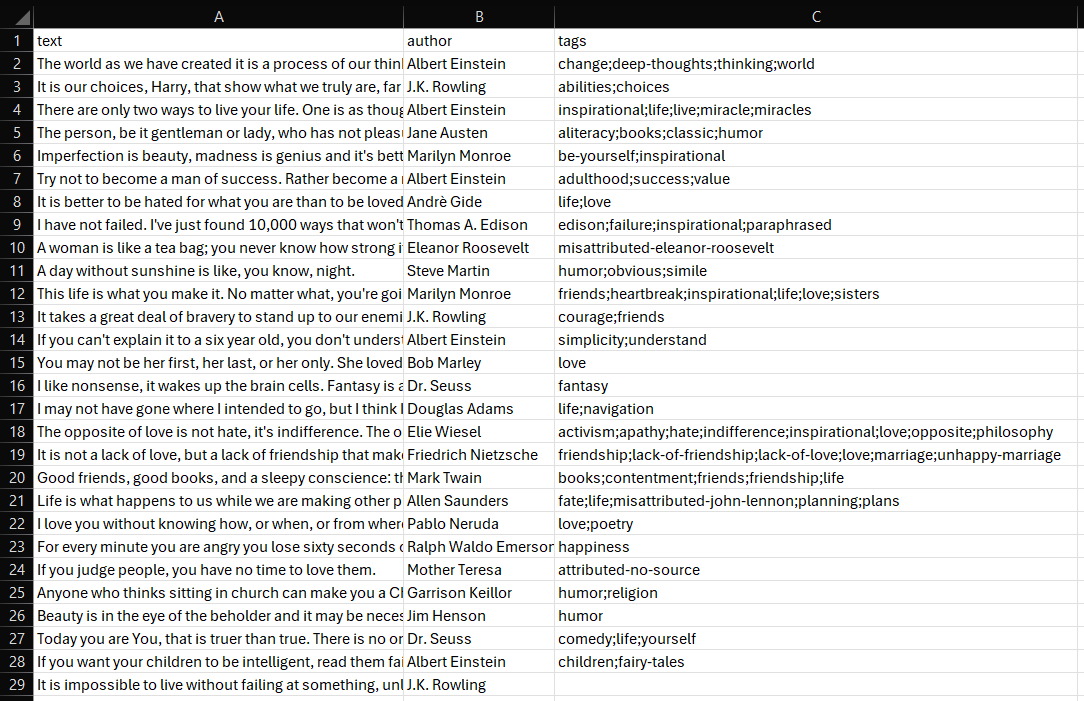
Et voilà! Ihr SeleniumBase-Web-Scraping-Skript funktioniert einwandfrei.
Fortgeschrittene Anwendungsfälle für SeleniumBase-Scraping
Nachdem Sie nun die Grundlagen von SeleniumBase kennengelernt haben, können Sie sich mit einigen komplexeren Szenarien befassen.
Automatisches Ausfüllen und Absenden von Formularen
Hinweis: Bright Data führt kein Scraping hinter einer Anmeldung durch.
Mit SeleniumBase können Sie auch wie ein menschlicher Benutzer mit Elementen auf einer Seite interagieren. Angenommen, Sie müssen mit einem Anmeldeformular wie dem unten gezeigten interagieren:
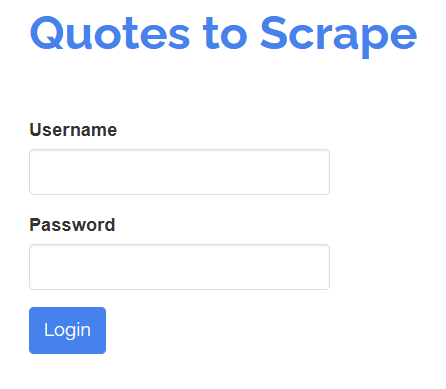
Ihr Ziel ist es, die Felder „Benutzername” und „Passwort” auszufüllen und dann das Formular durch Klicken auf die Schaltfläche „Anmelden” zu übermitteln. Dies können Sie mit einem SeleniumBase-Test wie folgt erreichen:
# login.py
from seleniumbase import BaseCase
BaseCase.main(__name__, __file__)
class LoginTest(BaseCase):
def test_submit_login_form(self):
# Zielseite aufrufen
self.open("https://quotes.toscrape.com/login")
# Formular ausfüllen
self.type("#username", "test")
self.type("#password", "test")
# Formular absenden
self.click("input[type="submit"]")
# Überprüfen, ob Sie sich auf der richtigen Seite befinden
self.assert_text("Top Ten tags")
Dieses Beispiel eignet sich hervorragend für die Erstellung eines Tests. Beachten Sie daher die Verwendung der Klasse „BaseCase ”. Damit können Sie pytest -Tests erstellen.
Führen Sie den Test mit diesem Befehl aus:
pytest login.py
Der Browser wird geöffnet, die Anmeldeseite geladen, das Formular ausgefüllt, abgeschickt und anschließend überprüft, ob der angegebene Text auf der Seite angezeigt wird.
Die Ausgabe im Terminal sieht in etwa so aus:
login.py . [100 %]
======================================== 1 bestanden in 11,20 s =========================================
Umgehen Sie einfache Anti-Bot-Technologien
Viele Websites implementieren fortschrittliche Anti-Scraping-Maßnahmen, um Bots daran zu hindern, auf ihre Daten zuzugreifen. Zu diesen Techniken gehören CAPTCHA-Herausforderungen, Ratenbegrenzungen, Browser-Fingerprinting und andere. Um Websites effektiv zu scrapen, ohne blockiert zu werden, müssen Sie diese Schutzmaßnahmen umgehen.
SeleniumBase bietet eine spezielle Funktion namens UC-Modus (Undetected-Chromedriver Mode), die Scraping-Bots dabei hilft, eher wie menschliche Benutzer zu wirken. Dadurch können sie der Erkennung durch Anti-Bot-Dienste entgehen, die den Scraping-Bot sonst direkt blockieren oder CAPTCHAs auslösen würden.
Der UC-Modus basiert auf undetected-chromedriver und enthält mehrere Updates, Fehlerbehebungen und Verbesserungen, darunter
- Automatische User-Agent-Rotation, um eine Erkennung zu vermeiden.
- Automatische Konfiguration von Chromium-Argumenten nach Bedarf.
- Spezielle
uc_*()-Methoden zum Umgehen von CAPTCHAs.
Sehen wir uns nun an, wie man den UC-Modus in SeleniumBase verwendet, um Anti-Bot-Herausforderungen zu umgehen.
In dieser Demonstration sehen Sie, wie Sie auf die Anti-Bot-Seite der Scraping Course-Website zugreifen können:
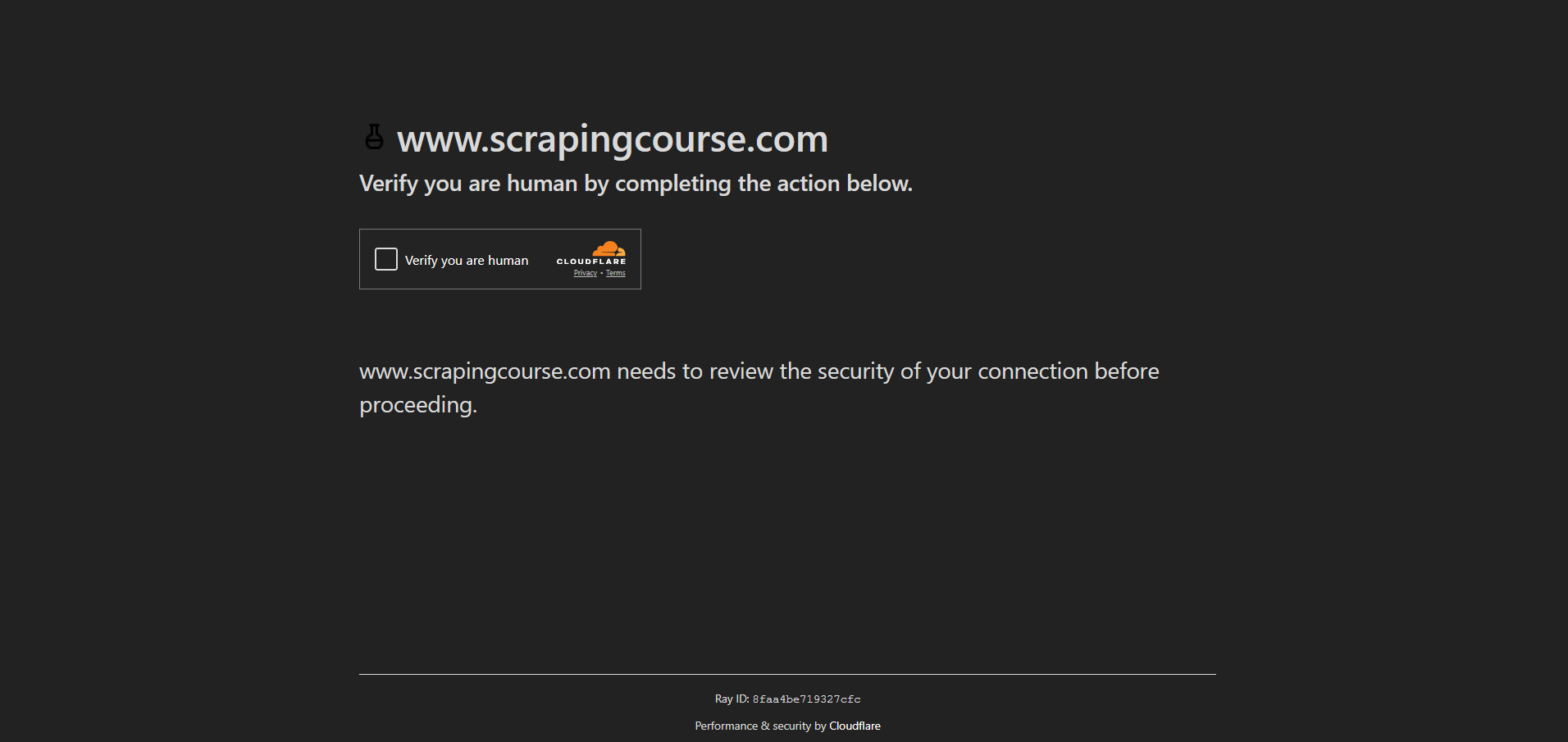
Um die Anti-Bot-Maßnahmen zu umgehen und das CAPTCHA zu bearbeiten, aktivieren Sie den UC-Modus und verwenden Sie die Methoden uc_open_with_reconnect() und uc_gui_click_captcha():
from seleniumbase import SB
with SB(uc=True) as sb:
# Zielseite mit Anti-Bot-Maßnahmen
url = "https://www.scrapingcourse.com/antibot-challenge"
# Öffnen Sie die URL im UC-Modus mit einer Wiederverbindungszeit von 4 Sekunden, um eine anfängliche Erkennung zu vermeiden.
sb.uc_open_with_reconnect(url, reconnect_time=4)
# Versuch, das CAPTCHA zu umgehen
sb.uc_gui_click_captcha()
# Screenshot der Seite erstellen
sb.save_screenshot("screenshot.png")
Starten Sie nun das Skript und überprüfen Sie, ob es wie erwartet funktioniert. Da uc_gui_click_captcha() PyAutoGUI benötigt, um zu funktionieren, installiert SeleniumBase es bei der ersten Ausführung für Sie:
PyAutoGUI erforderlich! Wird jetzt installiert...
Sie werden sehen, wie der Browser automatisch auf das Kontrollkästchen „Verify you are human” (Bestätigen Sie, dass Sie ein Mensch sind) klickt, indem er Ihre Maus bewegt. Die Datei screenshot.png in Ihrem Projektordner zeigt Folgendes an:
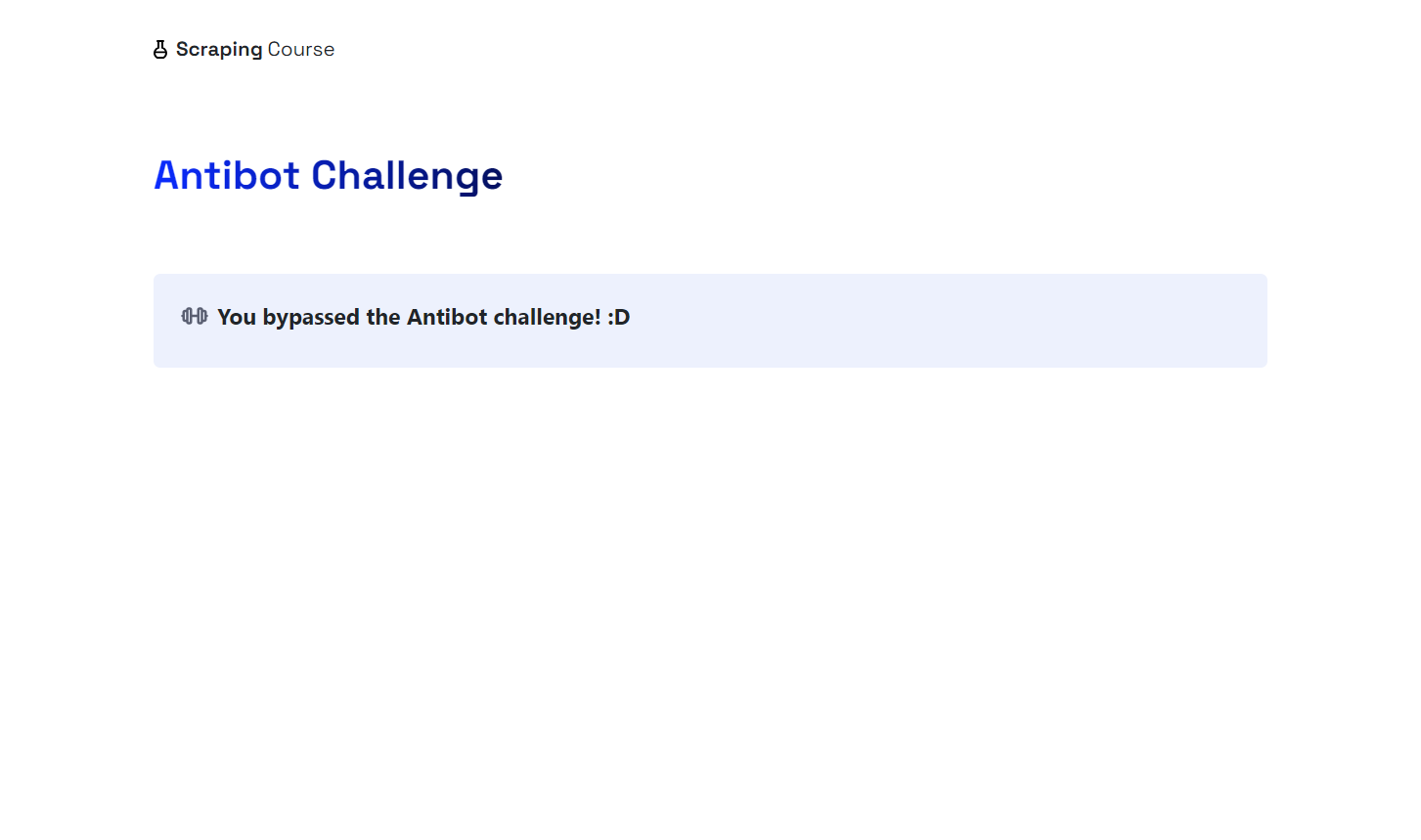
Wow! Cloudflare wurde umgangen.
Umgehen Sie komplexe Anti-Bot-Technologien
Anti-Bot-Lösungen werden immer ausgefeilter, und der UC-Modus ist möglicherweise nicht immer effektiv. Aus diesem Grund bietet SeleniumBase auch einen speziellen CDP-Modus (Chrome DevTools Protocol Mode) an.
Der CDP-Modus arbeitet innerhalb des UC-Modus und ermöglicht es Bots, menschlicher zu wirken, indem sie den Browser über den CDP-Treiber steuern. Während der normale UC-Modus keine WebDriver-Aktionen ausführen kann, wenn der Treiber vom Browser getrennt ist, kann der CDP-Treiber weiterhin mit dem Browser interagieren und diese Einschränkung überwinden.
Der CDP-Modus basiert auf python-cdp, trio-cdp und nodriver. Er wurde entwickelt, um fortschrittliche Anti-Bot-Lösungen von realen Websites zu umgehen, wie im folgenden Beispiel gezeigt:
from seleniumbase import SB
with SB(uc=True, test=True) as sb:
# Zielseite mit fortschrittlichen Anti-Bot-Maßnahmen
url = "https://gitlab.com/users/sign_in"
# Besuchen Sie die Seite im CDP-Modus.
sb.activate_cdp_mode(url)
# CAPTCHA bearbeiten
sb.uc_gui_click_captcha()
# 2 Sekunden warten, bis die Seite neu geladen ist und der Treiber die Kontrolle wieder übernimmt
sb.sleep(2)
# Screenshot der Seite erstellen
sb.save_screenshot("screenshot.png")
Das Ergebnis lautet:
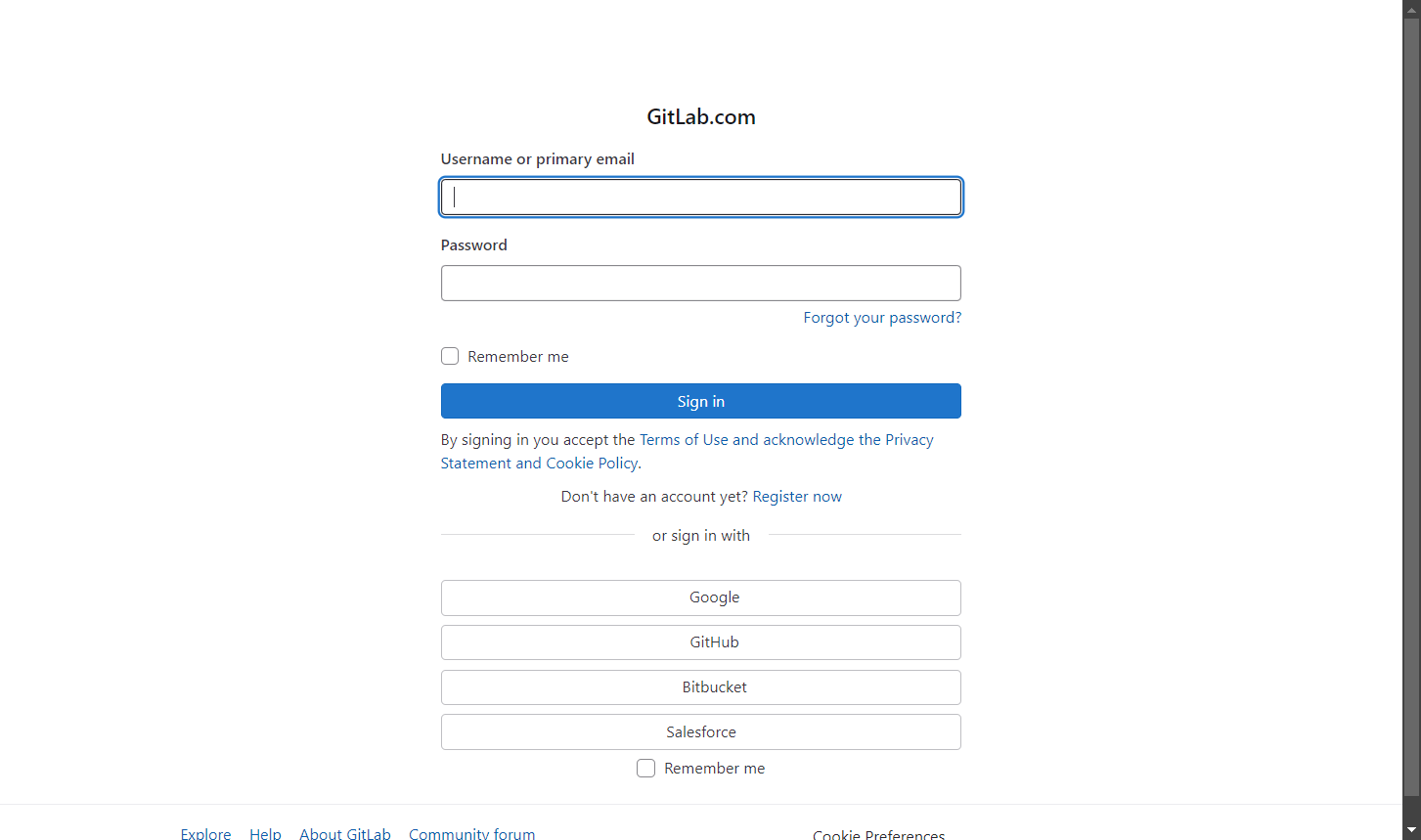
Das war’s schon! Sie sind jetzt ein SeleniumBase-Scraping-Meister.
Fazit
In diesem Artikel haben Sie SeleniumBase, seine Funktionen und Methoden sowie seine Verwendung für das Web-Scraping kennengelernt. Sie haben mit grundlegenden Szenarien begonnen und dann komplexere Anwendungsfälle erkundet.
Der UC-Modus und der CDP-Modus sind zwar effektiv, um bestimmte Anti-Bot-Maßnahmen zu umgehen, aber sie sind nicht narrensicher.
Websites können Ihre IP-Adresse weiterhin blockieren, wenn Sie zu viele Anfragen stellen, oder Sie mit komplexeren CAPTCHAs herausfordern, die mehrere Aktionen erfordern. Eine effektivere Lösung ist die Verwendung eines Webbrowser-Automatisierungstools wie Selenium in Kombination mit einem speziell für das Scraping entwickelten, cloudbasierten und hoch skalierbaren Browser wie Scraping-Browser von Bright Data.
Der Scraping-Browser ist ein Browser, der mit Playwright, Puppeteer, Selenium und anderen zusammenarbeitet. Er wechselt bei jeder Anfrage automatisch die Exit-IPs und kann Browser-Fingerprinting, Wiederholungsversuche, CAPTCHA-Lösung und vieles mehr verarbeiten. Vergessen Sie Blockierungen und optimieren Sie Ihre Scraping-Vorgänge.
Melden Sie sich jetzt an und testen Sie gratis!




