

In diesem praktischen Tutorial lernen Sie, wie Sie mit Playwright Python Daten aus Glassdoor scrapen können. Außerdem erfahren Sie mehr über die Anti-Scraping-Techniken von Glassdoor und wie Bright Data Ihnen dabei helfen kann. Sie lernen auch die Bright Data-Lösung kennen, mit der Sie Glassdoor viel schneller scrapen können.
Überspringen Sie das Scraping, holen Sie sich die Daten
Möchten Sie den Scraping-Prozess überspringen und direkt auf die Daten zugreifen? Dann werfen Sie doch einen Blick auf unseren Glassdoor-Datensatz.
Die Glassdoor-Datensätze bieten einen vollständigen Unternehmensüberblick mit Bewertungen und FAQs, die Einblicke in Jobs und Unternehmen geben. Mit unseren Glassdoor-Datensätzen können Sie Markttrends und Geschäftsinformationen zu Unternehmen finden und erfahren, wie aktuelle und ehemalige Mitarbeiter diese wahrnehmen und bewerten. Je nach Ihren Anforderungen haben Sie die Möglichkeit, den gesamten Datensatz oder einen individuell angepassten Teil davon zu erwerben.
Die Datensätze sind in Formaten wie JSON, NDJSON, JSON Lines, CSV oder Parquet verfügbar und können optional auch in .gz-Dateien komprimiert werden.
Ist es legal, Glassdoor zu scrapen?
Ja, es ist legal, Daten von Glassdoor zu scrapen, aber es muss ethisch und in Übereinstimmung mit den Nutzungsbedingungen, der robots.txt-Datei und den Datenschutzrichtlinien von Glassdoor erfolgen. Einer der größten Mythen ist, dass das Scraping öffentlicher Daten wie Unternehmensbewertungen und Stellenanzeigen nicht legal ist. Dies ist jedoch nicht wahr. Es sollte innerhalb der gesetzlichen und ethischen Grenzen erfolgen.
So scrapen Sie Glassdoor-Daten
Glassdoor verwendet JavaScript, um seine Inhalte darzustellen, was das Scraping komplexer machen kann. Um dies zu bewältigen, benötigen Sie ein Tool, das JavaScript ausführen und wie ein Browser mit der Webseite interagieren kann. Beliebte Optionen sind Playwright, Puppeteer und Selenium. Für dieses Tutorial verwenden wir Playwright Python.
Beginnen wir mit der Erstellung des Glassdoor-Scrapers von Grund auf! Unabhängig davon, ob Sie Playwright noch nicht kennen oder bereits damit vertraut sind, hilft Ihnen dieses Tutorial bei der Erstellung eines Web-Scrapers mit Playwright Python.
Einrichten der Arbeitsumgebung
Bevor Sie beginnen, stellen Sie sicher, dass Sie Folgendes auf Ihrem Rechner eingerichtet haben:
- Offizielle Website
- Visual Studio Code
Öffnen Sie anschließend ein Terminal und erstellen Sie einen neuen Ordner für Ihr Python-Projekt. Navigieren Sie dann zu diesem Ordner:
mkdir glassdoor-scraper
cd glassdoor-scraper
Erstellen und aktivieren Sie eine virtuelle Umgebung:
python -m venv glassdoorenv
glassdoorenvScriptsactivate
Installieren Sie Playwright:
pip install playwright
Installieren Sie anschließend die Browser-Binärdateien:
playwright install
Diese Installation kann einige Zeit in Anspruch nehmen, bitte haben Sie etwas Geduld.
So sieht der gesamte Einrichtungsprozess aus:
Sie sind nun eingerichtet und können mit dem Schreiben Ihres Glassdoor-Scraper-Codes beginnen!
Die Struktur der Glassdoor-Website verstehen
Bevor Sie mit dem Scraping von Glassdoor beginnen, ist es wichtig, dessen Struktur zu verstehen. In diesem Tutorial konzentrieren wir uns auf das Scraping von Unternehmen an einem bestimmten Standort, die bestimmte Funktionen haben.
Wenn Sie beispielsweise Unternehmen in New York City mit Stellen im Bereich maschinelles Lernen und einer Gesamtbewertung von mehr als 3,5 finden möchten, müssen Sie die entsprechenden Filter auf Ihre Suche anwenden.
Werfen Sie einen Blick auf die Glassdoor-Unternehmensseite:
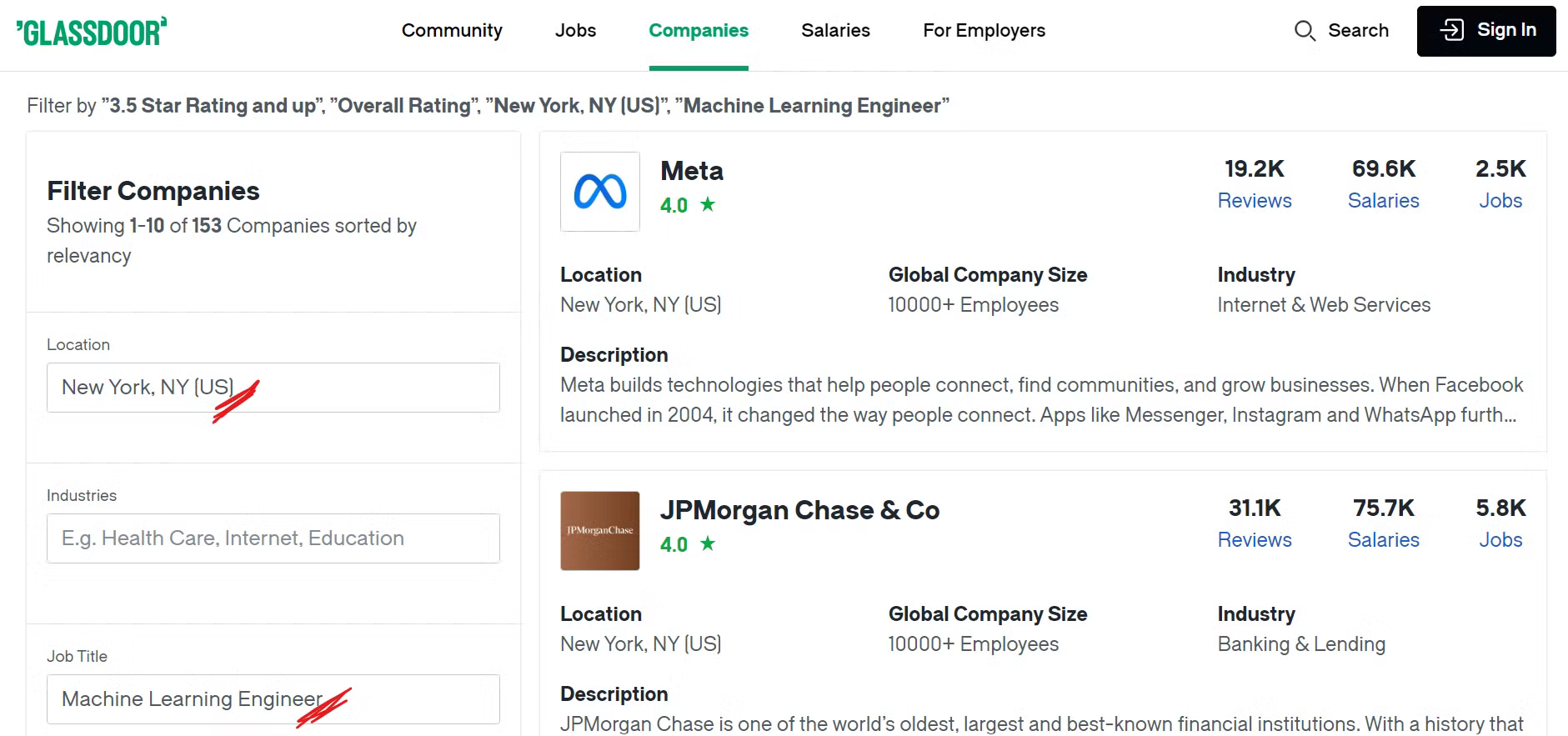
Wenn Sie nun die gewünschten Filter anwenden, werden Ihnen zahlreiche Unternehmen angezeigt, und Sie fragen sich vielleicht, welche konkreten Daten wir dabei erfassen. Das sehen wir uns als Nächstes an!
Identifizieren wichtiger Datenpunkte
Um die Daten von Glassdoor effektiv zu erfassen, müssen Sie die Inhalte identifizieren, die Sie scrapen möchten.
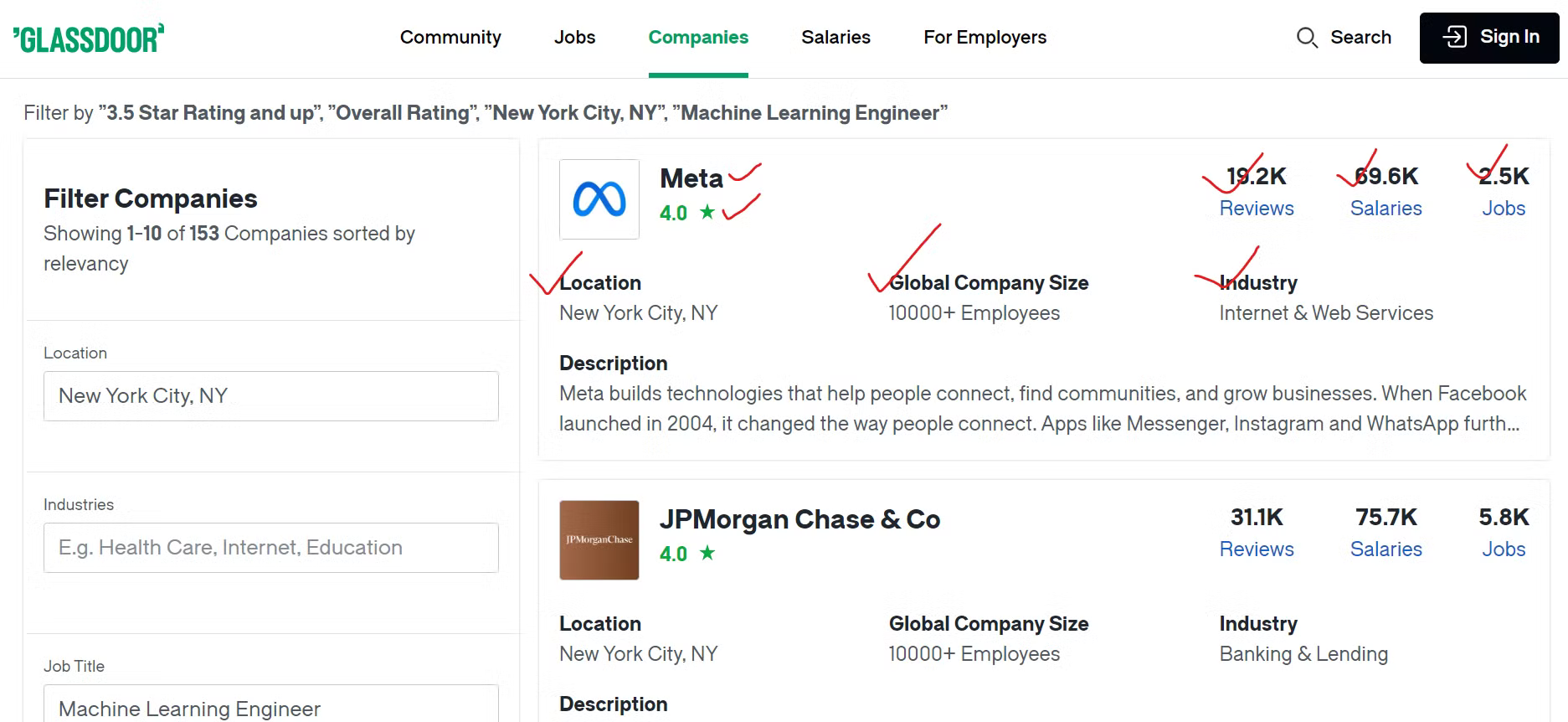
Wir extrahieren verschiedene Details zu jedem Unternehmen, wie z. B. den Firmennamen, einen Link zu den Stellenangeboten und die Gesamtzahl der offenen Stellen. Darüber hinaus erfassen wir die Anzahl der Mitarbeiterbewertungen, die Anzahl der gemeldeten Gehälter und die Branche, in der das Unternehmen tätig ist. Wir extrahieren auch den geografischen Standort des Unternehmens und die Gesamtzahl der Mitarbeiter weltweit.
Erstellen eines Glassdoor-Scrapers
Nachdem Sie nun die Daten identifiziert haben, die Sie scrapen möchten, ist es an der Zeit, den Scraper mit Playwright Python zu erstellen.
Beginnen Sie damit, die Glassdoor-Website zu untersuchen, um die Elemente für den Firmennamen und die Bewertungen zu finden, wie in der Abbildung unten gezeigt:
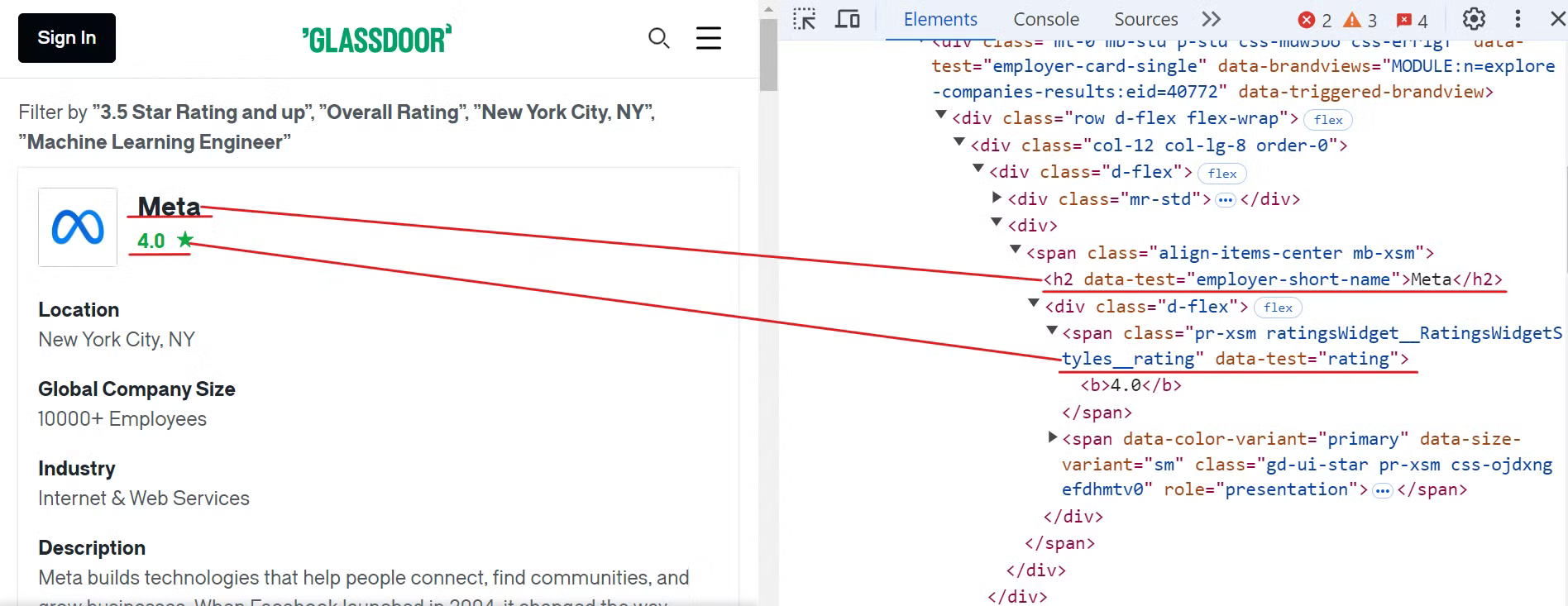
Um diese Daten zu extrahieren, können Sie die folgenden CSS-Selektoren verwenden:
[data-test="employer-short-name"]
[data-test="rating"]
Auf ähnliche Weise können Sie andere relevante Daten extrahieren, indem Sie einfache CSS-Selektoren verwenden, wie in der Abbildung unten gezeigt:
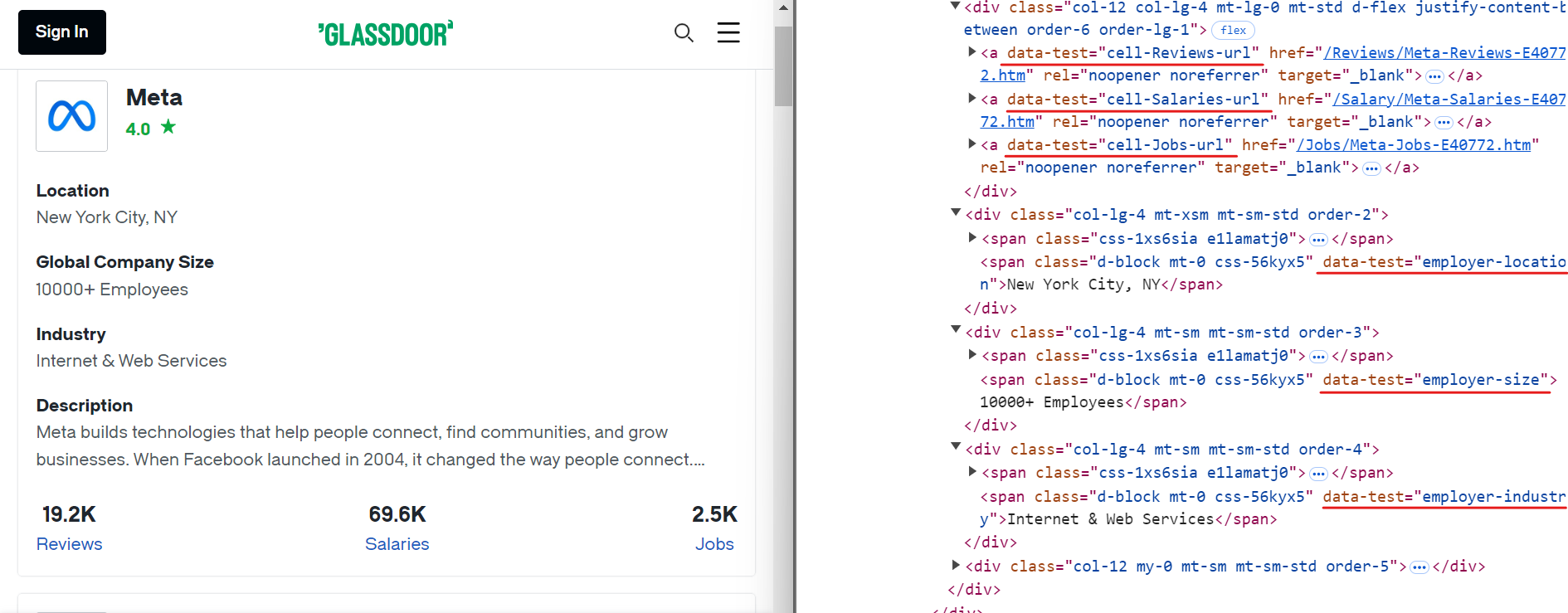
Hier sind die CSS-Selektoren, die Sie zum Extrahieren zusätzlicher Daten verwenden können:
[data-test="employer-location"] /* Geografischer Standort des Unternehmens */
[data-test="employer-size"] /* Anzahl der Mitarbeiter weltweit */
[data-test="employer-industry"] /* Branche, in der das Unternehmen tätig ist */
[data-test="cell-Jobs-url"] /* Link zu den Stellenangeboten des Unternehmens */
[data-test="cell-Jobs"] h3 /* Gesamtzahl der offenen Stellen */
[data-test="cell-Reviews"] h3 /* Anzahl der Mitarbeiterbewertungen */
[data-test="cell-Salaries"] h3 /* Anzahl der gemeldeten Gehälter */
Erstellen Sie als Nächstes eine neue Datei mit dem Namen glassdoor.py und fügen Sie den folgenden Code hinzu:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Starten Sie eine Chromium-Browserinstanz.
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Definieren Sie die Basis-URL und die Abfrageparameter für die Glassdoor-Suche.
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Erstellen Sie die vollständige URL mit Abfrageparametern und navigieren Sie dorthin.
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Initialisieren Sie einen Zähler für die extrahierten Datensätze.
record_count = 0
# Alle Unternehmenskarten auf der Seite suchen und durchlaufen, um Daten zu extrahieren
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extrahieren Sie relevante Daten aus jeder Unternehmenskarte.
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# URL für Stellenangebote erstellen
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extrahieren Sie zusätzliche Daten zu Stellenangeboten, Bewertungen und Gehältern
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Extrahierte Daten ausgeben
print({
"Unternehmen": company_name,
"Bewertung": rating,
"Jobs-URL": jobs_url_path,
„Anzahl der Stellenangebote”: jobs_count,
„Anzahl der Bewertungen”: reviews_count,
„Anzahl der Gehälter”: salaries_count,
„Branche”: industry,
„Standort”: location,
„Globale Unternehmensgröße”: global_company_size,
})
record_count += 1
except Exception as e:
print(f"Fehler beim Extrahieren der Unternehmensdaten: {e}")
print(f"Gesamtzahl der extrahierten Datensätze: {record_count}")
# Browser schließen
await browser.close()
# Einstiegspunkt für das Skript
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Dieser Code richtet ein Playwright-Skript ein, um Unternehmensdaten unter Anwendung bestimmter Filter zu scrapen. Beispielsweise werden Filter wie Standort (New York, NY), Bewertung (3,5+) und Berufsbezeichnung (Machine Learning Engineer) angewendet.
Anschließend startet er eine Chromium-Browserinstanz, navigiert zu der Glassdoor-URL, die diese Filter enthält, und extrahiert Daten aus jeder Unternehmenskarte auf der Seite. Nach dem Sammeln der Daten gibt er die extrahierten Informationen auf der Konsole aus.
Und hier ist die Ausgabe:

Gut gemacht!
Es gibt noch ein Problem. Derzeit extrahiert der Code nur 10 Datensätze, obwohl auf der Seite etwa 150 Datensätze verfügbar sind. Das zeigt, dass das Skript nur Daten von der ersten Seite erfasst. Um mehr Datensätze zu extrahieren, müssen wir die Paginierung implementieren, was im nächsten Abschnitt behandelt wird.
Paginierung
Jede Seite auf Glassdoor zeigt Daten für etwa 10 Unternehmen an. Um alle verfügbaren Datensätze zu extrahieren, müssen Sie die Paginierung verarbeiten, indem Sie jede Seite bis zum Ende durchgehen. Dazu müssen Sie die Schaltfläche „Weiter“ suchen, überprüfen, ob sie aktiviert ist, und darauf klicken, um zur nächsten Seite zu gelangen. Wiederholen Sie diesen Vorgang, bis keine weiteren Seiten mehr verfügbar sind.
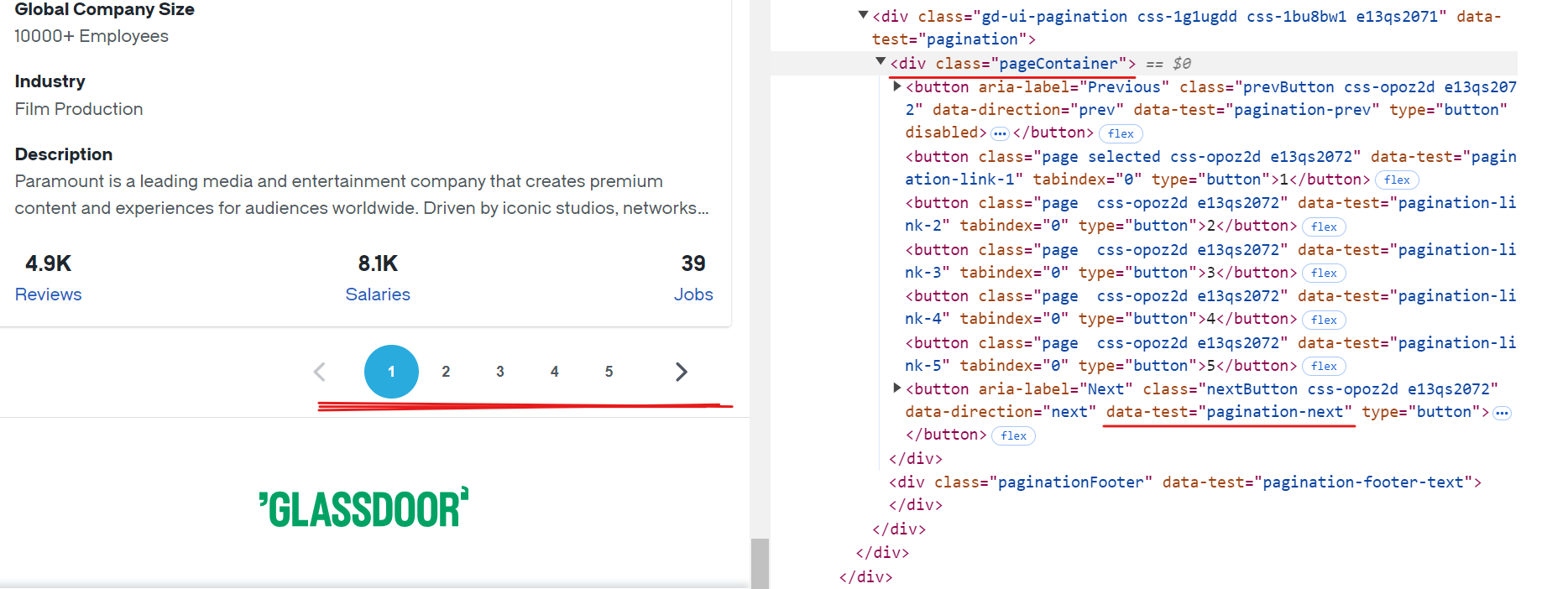
Der CSS-Selektor für die Schaltfläche „Weiter“ lautet [data-test="pagination-next"], der sich innerhalb eines <div> -Tags mit der Klasse pageContainer befindet, wie in der obigen Abbildung gezeigt.
Hier ist ein Code-Schnipsel, der zeigt, wie die Paginierung gehandhabt wird:
while True:
# Stellen Sie sicher, dass der Paginierungscontainer sichtbar ist, bevor Sie fortfahren.
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifizieren Sie die Schaltfläche „Weiter“ auf der Seite.
next_button = page.locator('[data-test="pagination-next"]')
# Stellen Sie fest, ob die Schaltfläche „Weiter” deaktiviert ist und keine weiteren Seiten angezeigt werden.
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Beenden Sie den Vorgang, wenn keine weiteren Seiten mehr vorhanden sind.
# Zur nächsten Seite navigieren
await next_button.click()
await asyncio.sleep(3) # Zeit zum vollständigen Laden der Seite einräumen
Hier ist der geänderte Code:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Starten Sie eine Chromium-Browserinstanz.
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Definieren Sie die Basis-URL und die Abfrageparameter für die Glassdoor-Suche
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
„locId”: „1132348”,
„locType”: „C”,
„locName”: „New York, NY (US)”,
„occ”: „Machine Learning Engineer”,
„filterType”: „RATING_OVERALL”,
}
# Erstellen Sie die vollständige URL mit Abfrageparametern und navigieren Sie dorthin.
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Initialisieren Sie einen Zähler für die extrahierten Datensätze.
record_count = 0
while True:
# Suchen Sie alle Unternehmenskarten auf der Seite und durchlaufen Sie sie, um Daten zu extrahieren.
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extrahieren Sie relevante Daten aus jeder Unternehmenskarte.
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# URL für Stellenangebote erstellen
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extrahieren Sie zusätzliche Daten zu Stellenangeboten, Bewertungen und Gehältern
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Extrahierte Daten ausgeben
print({
"Unternehmen": company_name,
"Bewertung": rating,
"Jobs-URL": jobs_url_path,
„Anzahl der Stellenangebote“: jobs_count,
„Anzahl der Bewertungen“: reviews_count,
„Anzahl der Gehälter“: salaries_count,
„Branche“: industry,
„Standort“: location,
„Globale Unternehmensgröße“: global_company_size,
})
record_count += 1
except Exception as e:
print(f"Fehler beim Extrahieren der Unternehmensdaten: {e}")
try:
# Stellen Sie sicher, dass der Paginierungscontainer sichtbar ist, bevor Sie fortfahren.
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifizieren Sie die Schaltfläche „Weiter” auf der Seite.
next_button = page.locator('[data-test="pagination-next"]')
# Feststellen, ob die Schaltfläche „Weiter“ deaktiviert ist und keine weiteren Seiten angezeigt werden
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Anhalten, wenn keine weiteren Seiten zum Navigieren vorhanden sind
# Zur nächsten Seite navigieren
await next_button.click()
await asyncio.sleep(3) # Zeit zum vollständigen Laden der Seite einräumen
except Exception as e:
print(f"Fehler beim Navigieren zur nächsten Seite: {e}")
break # Schleife bei Navigationsfehler beenden
print(f"Gesamtzahl der extrahierten Datensätze: {record_count}")
# Browser schließen
await browser.close()
# Einstiegspunkt für das Skript
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Das Ergebnis lautet:

Großartig! Sie können nun Daten aus allen verfügbaren Seiten extrahieren, nicht nur aus der ersten.
Daten als CSV speichern
Nachdem Sie die Daten extrahiert haben, speichern Sie sie zur weiteren Verarbeitung in einer CSV-Datei. Dazu können Sie das Python-Modul „csv” verwenden. Nachfolgend finden Sie den aktualisierten Code, mit dem die gescrapten Daten in einer CSV-Datei gespeichert werden:
import asyncio
import csv
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Starten Sie eine Chromium-Browserinstanz.
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Definieren Sie die Basis-URL und die Abfrageparameter für die Glassdoor-Suche
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Erstellen Sie die vollständige URL mit Abfrageparametern und navigieren Sie dorthin.
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Öffnen Sie die CSV-Datei, um die extrahierten Daten zu schreiben.
with open("glassdoor_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([
"Unternehmen", "Jobs-URL", "Anzahl der Stellenangebote", "Anzahl der Bewertungen", "Anzahl der Gehälter",
"Branche", "Standort", "Globale Unternehmensgröße", "Bewertung"
])
# Zähler für die extrahierten Datensätze initialisieren
record_count = 0
while True:
# Alle Unternehmenskarten auf der Seite suchen und durchlaufen, um Daten zu extrahieren
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extrahieren Sie relevante Daten aus jeder Unternehmenskarte.
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# URL für Stellenangebote erstellen
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extrahieren Sie zusätzliche Daten zu Stellenangeboten, Bewertungen und Gehältern.
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Schreiben Sie die extrahierten Daten in die CSV-Datei.
writer.writerow([
company_name, jobs_url_path, jobs_count, reviews_count, salaries_count,
industry, location, global_company_size, rating
])
record_count += 1
except Exception as e:
print(f"Fehler beim Extrahieren der Unternehmensdaten: {e}")
try:
# Sicherstellen, dass der Paginierungscontainer sichtbar ist, bevor fortgefahren wird
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifizieren der Schaltfläche „Weiter” auf der Seite
next_button = page.locator('[data-test="pagination-next"]')
# Feststellen, ob die Schaltfläche „Weiter” deaktiviert ist und keine weiteren Seiten angezeigt werden
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Anhalten, wenn keine weiteren Seiten zum Navigieren vorhanden sind
# Zur nächsten Seite navigieren
await next_button.click()
await asyncio.sleep(3) # Zeit zum vollständigen Laden der Seite einräumen
except Exception as e:
print(f"Fehler beim Navigieren zur nächsten Seite: {e}")
break # Schleife bei Navigationsfehler beenden
print(f"Gesamtzahl der extrahierten Datensätze: {record_count}")
# Browser schließen
await browser.close()
# Einstiegspunkt für das Skript
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Dieser Code speichert nun die extrahierten Daten in einer CSV-Datei namens glassdoor_data.csv.
Das Ergebnis lautet:
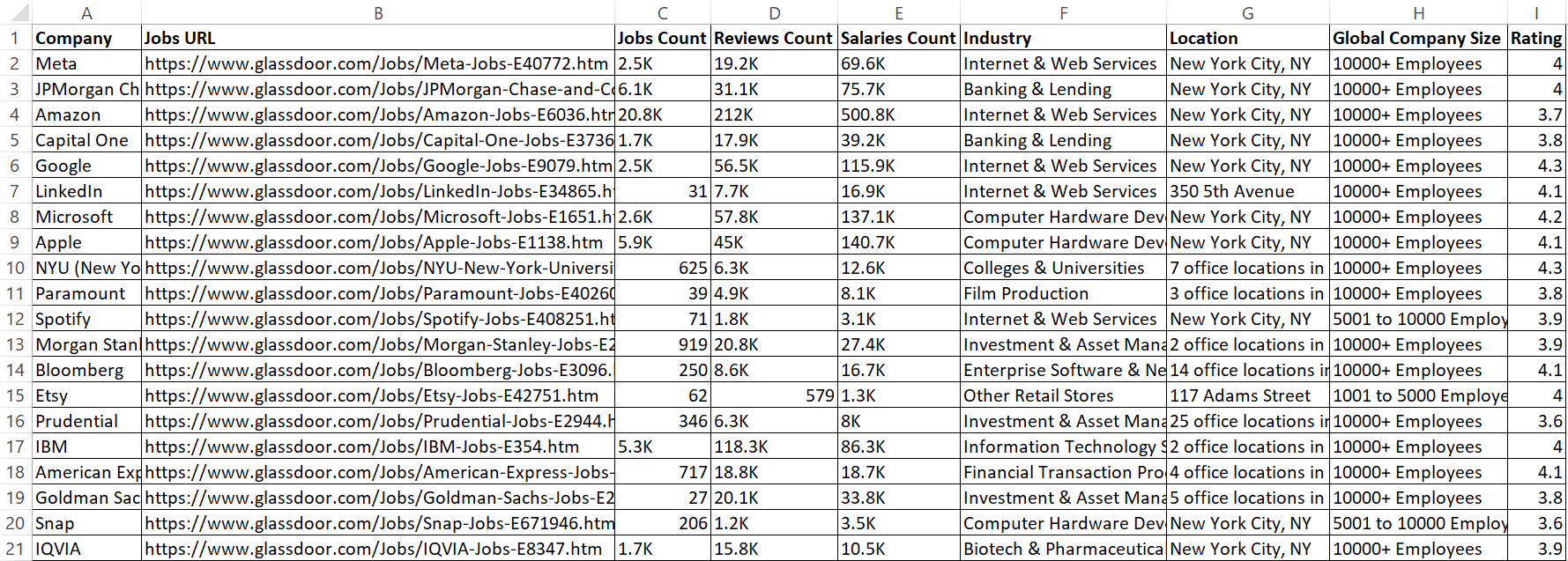
Großartig! Jetzt sehen die Daten übersichtlicher und leichter lesbar aus.
Von Glassdoor eingesetzte Anti-Scraping-Techniken
Glassdoor überwacht die Anzahl der Anfragen, die innerhalb eines bestimmten Zeitraums von einer IP-Adresse kommen. Wenn die Anfragen ein festgelegtes Limit überschreiten, kann Glassdoor die IP-Adresse vorübergehend oder dauerhaft sperren. Wenn ungewöhnliche Aktivitäten festgestellt werden, kann Glassdoor außerdem eine CAPTCHA-Prüfung durchführen, wie ich selbst erlebt habe.
Die oben beschriebene Methode eignet sich für das Scraping von einigen hundert Unternehmen. Wenn Sie jedoch Tausende von Unternehmen scrapen müssen, besteht ein höheres Risiko, dass die Anti-Bot-Mechanismen von Glassdoor Ihr automatisiertes Scraping-Skript markieren, wie ich es beim Scraping größerer Datenmengen erlebt habe.
Das Scraping von Daten aus Glassdoor kann aufgrund der Anti-Scraping-Mechanismen schwierig sein. Das Umgehen dieser Anti-Bot-Mechanismen kann frustrierend und ressourcenintensiv sein. Es gibt jedoch Strategien, mit denen Ihr Scraper menschliches Verhalten nachahmen und die Wahrscheinlichkeit einer Sperrung verringern kann. Zu den gängigen Techniken gehören der Rotierende Proxy, das Setzen echter Request-Header, das Randomisieren von Request-Raten und vieles mehr. Diese Techniken können zwar Ihre Chancen auf ein erfolgreiches Scraping verbessern, garantieren jedoch keinen 100-prozentigen Erfolg.
Der beste Ansatz zum Scrapen von Glassdoor trotz der Anti-Bot-Maßnahmen ist daher die Verwendung einer Glassdoor-Scraper-API 🚀.
Eine bessere Alternative: Glassdoor Scraper API
Bright Data bietet einen Glassdoor-Datensatz an, der bereits gesammelt und für die Analyse strukturiert ist, wie zuvor in diesem Blogbeitrag erläutert. Wenn Sie keinen Datensatz kaufen möchten und nach einer effizienteren Lösung suchen, sollten Sie die Glassdoor Scraper API von Bright Data in Betracht ziehen.
Dieses leistungsstarke API wurde entwickelt, um Glassdoor-Daten nahtlos zu scrapen, dynamische Inhalte zu verarbeiten und Anti-Bot-Maßnahmen mühelos zu umgehen. Mit diesem Tool sparen Sie Zeit, gewährleisten die Genauigkeit der Daten und können sich darauf konzentrieren, aus den Daten umsetzbare Erkenntnisse zu gewinnen.
Um mit der Glassdoor Scraper API zu beginnen, führen Sie die folgenden Schritte aus:
Erstellen Sie zunächst ein Konto. Besuchen Sie die Bright Data-Website, klicken Sie auf “Gratis testen” und folgen Sie den Anweisungen zur Anmeldung. Nach der Anmeldung werden Sie zu Ihrem Dashboard weitergeleitet, wo Sie einige kostenlose Credits erhalten.
Gehen Sie nun zum Abschnitt „Web Scraper API“ und wählen Sie „Glassdoor“ unter der Kategorie „B2B-Daten“ aus. Dort finden Sie verschiedene Optionen zur Datenerfassung, z. B. das Erfassen von Unternehmen nach URL oder das Erfassen von Stellenangeboten nach URL.
Unter „Glassdoor companies overview information“ (Übersichtsinformationen zu Glassdoor-Unternehmen) erhalten Sie Ihren API-Token und kopieren Sie Ihre Datensatz-ID (z. B. gd_l7j0bx501ockwldaqf).
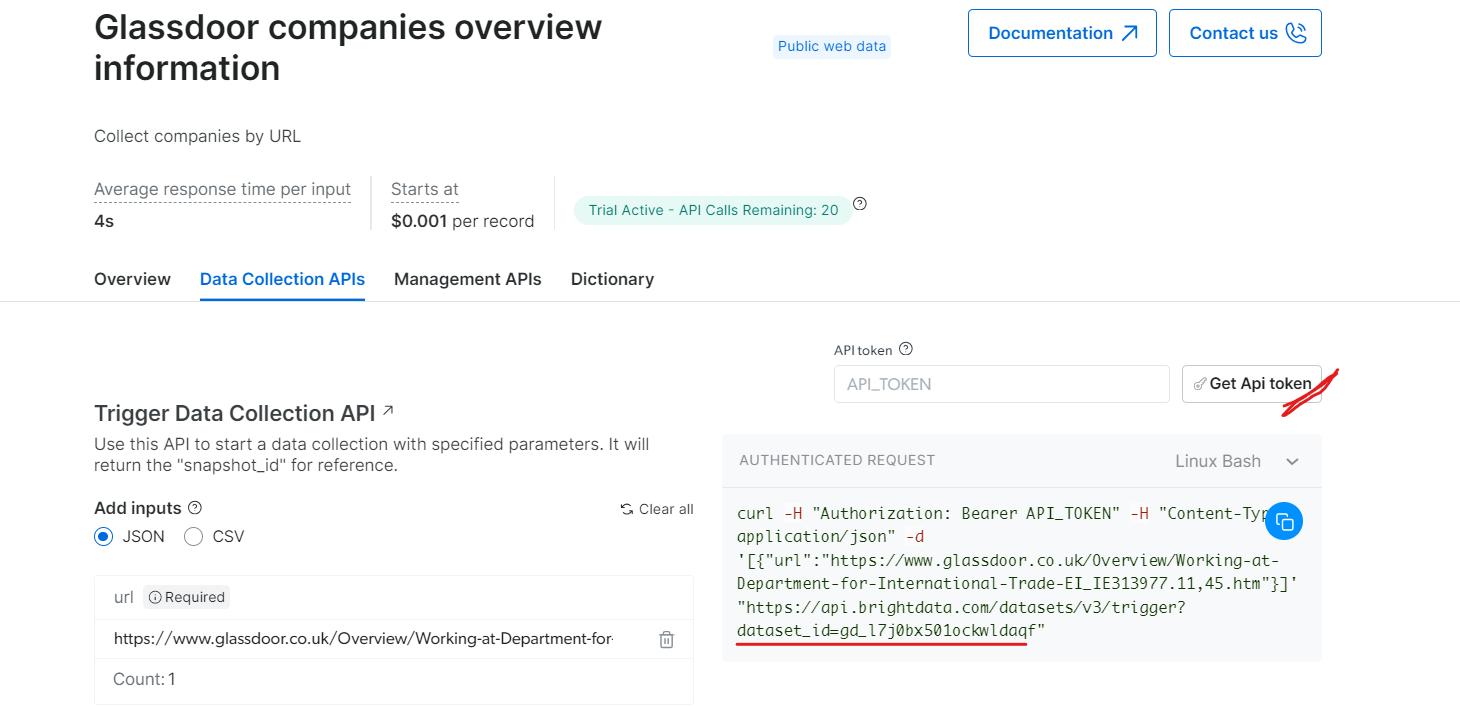
Hier ist ein einfacher Code-Schnipsel, der zeigt, wie Sie Unternehmensdaten extrahieren können, indem Sie die URL, den API-Token und die Datensatz-ID angeben.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Löst einen Datensatz mithilfe der BrightData-API aus.
Argumente:
api_token (str): Der API-Token für die Authentifizierung.
dataset_id (str): Die Datensatz-ID, die ausgelöst werden soll.
company_url (str): Die URL der zu analysierenden Unternehmensseite.
Rückgabewerte:
dict: Die JSON-Antwort der API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/datensätze/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "COMPANY_PAGE_URL"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)
Nach Ausführung des Codes erhalten Sie eine Snapshot-ID wie unten gezeigt:

Verwenden Sie die Snapshot-ID, um die tatsächlichen Daten des Unternehmens abzurufen. Führen Sie den folgenden Befehl in Ihrem Terminal aus. Für Windows verwenden Sie:
curl.exe -H „Authorization: Bearer API_TOKEN”
„https://api.brightdata.com/datensätze/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json”
Für Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datensätze/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Nach Ausführung des Befehls erhalten Sie die gewünschten Daten.
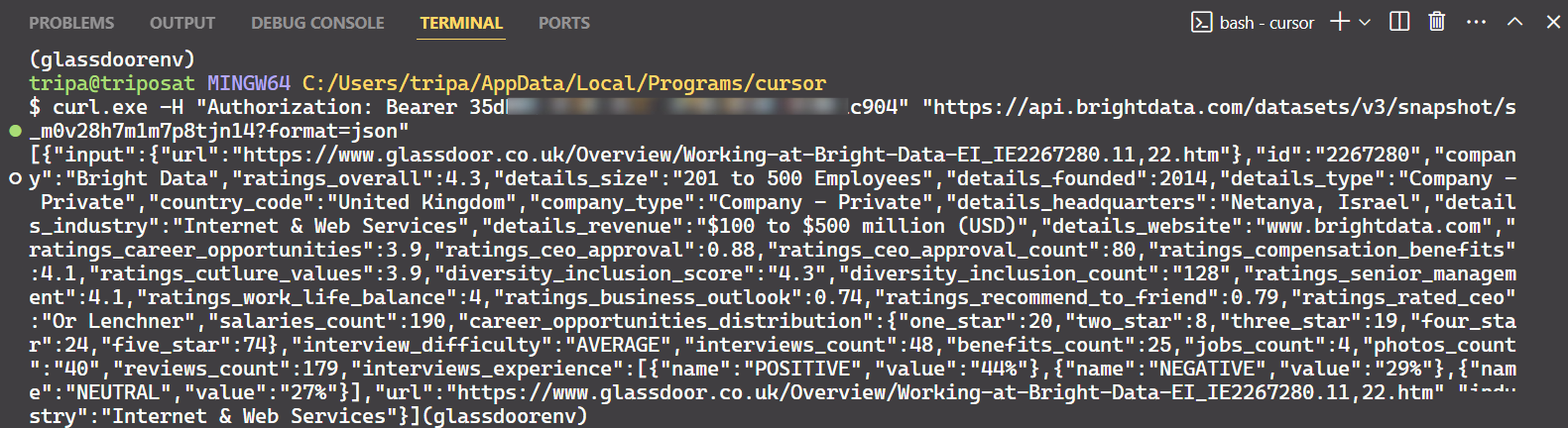
Das ist alles!
Auf ähnliche Weise können Sie verschiedene Arten von Daten aus Glassdoor extrahieren, indem Sie den Code ändern. Ich habe eine Methode erklärt, aber es gibt noch fünf weitere Möglichkeiten, dies zu tun. Ich empfehle Ihnen daher, diese Optionen zu erkunden, um die gewünschten Daten zu scrapen. Jede Methode ist auf bestimmte Datenanforderungen zugeschnitten und hilft Ihnen, genau die Daten zu erhalten, die Sie benötigen.
Fazit
In diesem Tutorial haben Sie gelernt, wie Sie Glassdoor mit Playwright Python scrapen können. Außerdem haben Sie etwas über die von Glassdoor eingesetzten Anti-Scraping-Techniken gelernt und wie Sie diese umgehen können. Um diese Probleme zu lösen, wurde die Bright Data Glassdoor Scraper API eingeführt, mit der Sie die Anti-Scraping-Maßnahmen von Glassdoor überwinden und die benötigten Daten nahtlos extrahieren können.
Sie können auch Scraping-Browser ausprobieren, einen Browser der nächsten Generation, der in jedes andere Browser-Automatisierungstool integriert werden kann. Scraping-Browser kann Anti-Bot-Technologien leicht umgehen und gleichzeitig Browser-Fingerprinting vermeiden. Er stützt sich auf Funktionen wie User-Agent-Rotation, IP-Rotation und CAPTCHA-Lösung.
Melden Sie sich jetzt an und testen Sie die Produkte von Bright Data kostenlos.






