

Dieses Tutorial führt Sie durch das manuelle Scraping öffentlicher Daten von Airbnb mit Python. Die gesammelten Daten können dabei helfen, Markttrends zu analysieren, wettbewerbsfähige Preisstrategien zu entwickeln, Stimmungsanalysen aus Gästebewertungen durchzuführen oder Empfehlungssysteme aufzubauen.
Entdecken Sie außerdem die fortschrittlichen Lösungen von Bright Data. Die spezialisierten Proxys und scrapingfreundlichen Browser vereinfachen und verbessern den Datenextraktionsprozess.
So scrapen Sie Airbnb
Bevor wir loslegen, sollten Sie über einige Grundkenntnisse in Web-Scraping und HTML verfügen. Stellen Sie außerdem sicher, dass Python auf Ihrem Computer installiert ist, falls dies noch nicht der Fall ist. Dieoffizielle Python-Anleitungenthält detaillierte Anweisungen dazu. Wenn Sie Python bereits installiert haben, stellen Sie sicher, dass es auf Python 3.7.9 oder neuer aktualisiert ist. Wir empfehlen außerdem, vor dem Start das vollständige Python-Web-Scraping-Tutorial zu lesen.
Sobald Python installiert ist, starten Sie Ihr Terminal oder Ihre Befehlszeilenschnittstelle und erstellen Sie mit den folgenden Befehlen ein neues Projektverzeichnis:
mkdir airbnb-scraper && cd airbnb-scraper
Nachdem Sie ein neues Projektverzeichnis erstellt haben, müssen Sie einige zusätzliche Bibliotheken einrichten, die Sie für das Web-Scraping verwenden werden. Konkret werden Sie Requests verwenden, eine Bibliothek, die HTTP-Anfragen in Python ermöglicht; pandas, eine robuste Bibliothek für die Datenbearbeitung und -analyse; Beautiful Soup (BS4) zum Parsen von HTML-Inhalten; und Playwright zur Automatisierung browserbasierter Aufgaben.
Um diese Bibliotheken zu installieren, öffnen Sie Ihr Terminal oder Ihre Shell und führen Sie die folgenden Befehle aus:
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
playwright install
Stellen Sie sicher, dass der Installationsvorgang ohne Fehler abgeschlossen wurde, bevor Sie mit dem nächsten Schritt dieses Tutorials fortfahren.
Hinweis: Der letzte Befehl (d. h.
playwright install) ist erforderlich, um die Browser-Binärdateien zu installieren.
Struktur und Datenobjekte von Airbnb
Bevor Sie mit dem Scraping von Airbnb beginnen, ist es wichtig, sich mit dessen Struktur vertraut zu machen. Die Hauptseite von Airbnb verfügt über eine benutzerfreundliche Suchleiste, mit der Sie nach Unterkunftsmöglichkeiten, Erlebnissen und sogar Abenteuern suchen können.
Nach Eingabe Ihrer Suchkriterien werden die Ergebnisse in einer Liste angezeigt, in der die Objekte mit ihren Namen, Preisen, Standorten, Bewertungen und anderen relevanten Details aufgeführt sind. Es ist erwähnenswert, dass diese Suchergebnisse nach verschiedenen Parametern wie Preisklasse, Objekttyp und Verfügbarkeitsdaten gefiltert werden können.
Wenn Sie mehr Suchergebnisse als die zunächst angezeigten sehen möchten, können Sie die Paginierungsschaltflächen am unteren Rand der Seite verwenden. Jede Seite enthält in der Regel zahlreiche Einträge, sodass Sie weitere Unterkünfte durchsuchen können. Mit den Filtern oben auf der Seite können Sie Ihre Suche nach Ihren Bedürfnissen und Vorlieben verfeinern.
Um die HTML-Struktur der Airbnb-Website besser zu verstehen, gehen Sie wie folgt vor:
- Navigieren Sie zur Airbnb-Website.
- Geben Sie den gewünschten Ort, den Zeitraum und die Anzahl der Gäste in die Suchleiste ein und drücken Sie die Eingabetaste.
- Starten Sie die Entwicklertools des Browsers, indem Sie mit der rechten Maustaste auf eine Immobilienkarte klicken und „Untersuchen“ auswählen.
- Untersuchen Sie das HTML-Layout, um die Tags und Attribute zu finden, die die Daten enthalten, die Sie scrapen möchten.
Scrapen Sie ein Airbnb-Inserat
Nachdem Sie nun mehr über die Struktur von Airbnb wissen, richten Sie Playwright ein, um zu einem Airbnb-Inserat zu navigieren und Daten zu scrapen. In diesem Beispiel erfassen Sie den Namen des Inserats, den Standort, Preisangaben, Angaben zum Eigentümer und Bewertungen.
Erstellen Sie ein neues Python-Skript namens „airbnb_scraper.py“ und fügen Sie den folgenden Code hinzu:
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
async def scrape_airbnb():
async with async_playwright() as pw:
# Neuen Browser starten
browser = await pw.chromium.launch(headless=False)
page = await browser.new_page()
# Zur Airbnb-URL gehen
await page.goto('https://www.airbnb.com/s/homes', timeout=600000)
# Warten, bis die Angebote geladen sind
await page.wait_for_selector('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
# Informationen extrahieren
results = []
listings = await page.query_selector_all('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
for listing in listings:
result = {}
# Name der Immobilie
name_element = await listing.query_selector('div[data-testid="listing-card-title"]')
if name_element:
result['property_name'] = await page.evaluate("(el) => el.textContent", name_element)
else:
result['property_name'] = 'N/A'
# Standort
location_element = await listing.query_selector('div[data-testid="listing-card-subtitle"]')
result['location'] = await location_element.inner_text() if location_element else 'N/A'
# Preis
price_element = await listing.query_selector('div._1jo4hgw')
result['price'] = await price_element.inner_text() if price_element else 'N/A'
results.append(result)
# Browser schließen
await browser.close()
return results
# Scraper ausführen und Ergebnisse in einer CSV-Datei speichern
results = asyncio.run(scrape_airbnb())
df = pd.DataFrame(results)
df.to_csv('airbnb_listings.csv', index=False)
Die Funktion scrape_airbnb() öffnet asynchron einen Browser, ruft die Startseite von Airbnb auf und sammelt Details wie Name, Lage und Preis der einzelnen Unterkünfte. Wenn ein Element nicht gefunden wird, wird es als N/A markiert. Nach der Verarbeitung werden die erfassten Daten in einem Pandas-DataFrame gespeichert und als CSV-Datei mit dem Namen airbnb_listings.csv gespeichert.
Um das Skript auszuführen, führen Sie python3 airbnb_scraper.py in Ihrem Terminal oder Ihrer Shell aus. Ihre CSV-Datei sollte wie folgt aussehen:
property_name,location,price
„Brand bei Bludenz, Österreich”,343 Kilometer entfernt,„2.047 €
pro Nacht”
„Saint-Nabord, Frankreich”,281 Kilometer entfernt,„315 €
pro Nacht”
„Kappl, Österreich”,362 Kilometer entfernt,„1.090 €
pro Nacht”
„Fraisans, Frankreich”,394 Kilometer entfernt,„181 €
pro Nacht”
„Lanitz-Hassel-Tal, Deutschland”,239 Kilometer entfernt,„185 €
pro Nacht”
„Hohentannen, Schweiz”,291 Kilometer entfernt,„189 €
pro Nacht”
…Ausgabe ausgelassen…
Verbessern Sie das Web-Scraping mit Bright Data Proxies
Das Scraping von Websites kann manchmal Herausforderungen mit sich bringen, wie z. B. IP-Sperren und Geoblocking. Hier kommen die Proxysvon Bright Data ins Spiel, mit denen Sie diese Hürden umgehen und Ihre Daten-Scraping-Bemühungen verbessern können.
Nachdem Sie das vorherige Skript einige Male ausgeführt haben, stellen Sie möglicherweise fest, dass Sie keine Daten mehr erhalten. Dies kann passieren, wenn Ihre IP-Adresse von Airbnb erkannt wird und Sie daran gehindert werden, deren Website zu scrapen.
Um die damit verbundenen Herausforderungen zu mindern, ist die Implementierung von Proxys für das Scraping ein praktischer Ansatz. Hier sind einige der Vorteile der Verwendung von Proxys für das Web-Scraping:
- Umgehen von IP-Beschränkungen
- Rotation von IP-Adressen
- Lastenausgleich sorgt für die Verteilung des Netzwerk- oder Anwendungsdatenverkehrs auf viele Ressourcen, wodurch verhindert wird, dass eine einzelne Komponente zu einem Engpass wird, und Redundanz im Falle eines Ausfalls gewährleistet ist.
So integrieren Sie Bright Data-Proxys in Ihr Python-Skript
Angesichts der zuvor genannten Vorteile ist es verständlich, warum man die Proxies von Bright Data in ein Python-Skript integrieren möchte. Die gute Nachricht ist, dass dies ganz einfach ist. Sie müssen lediglich ein Bright Data-Konto einrichten, Ihre Proxy-Einstellungen konfigurieren und diese dann in Ihrem Python-Code implementieren.
Um loszulegen, müssen Sie ein Bright Data-Konto erstellen. Rufen Sie dazu die Bright Data-Website auf und wählen Sie „Gratis testen“ aus. Folgen Sie dann den Anweisungen.
Melden Sie sich bei Ihrem Bright Data-Konto an und klicken Sie auf die Kreditkarte in der linken Navigationsleiste, um auf „Abrechnung“ zuzugreifen. Hier müssen Sie Ihre bevorzugte Zahlungsmethode eingeben, um Ihr Konto zu aktivieren:
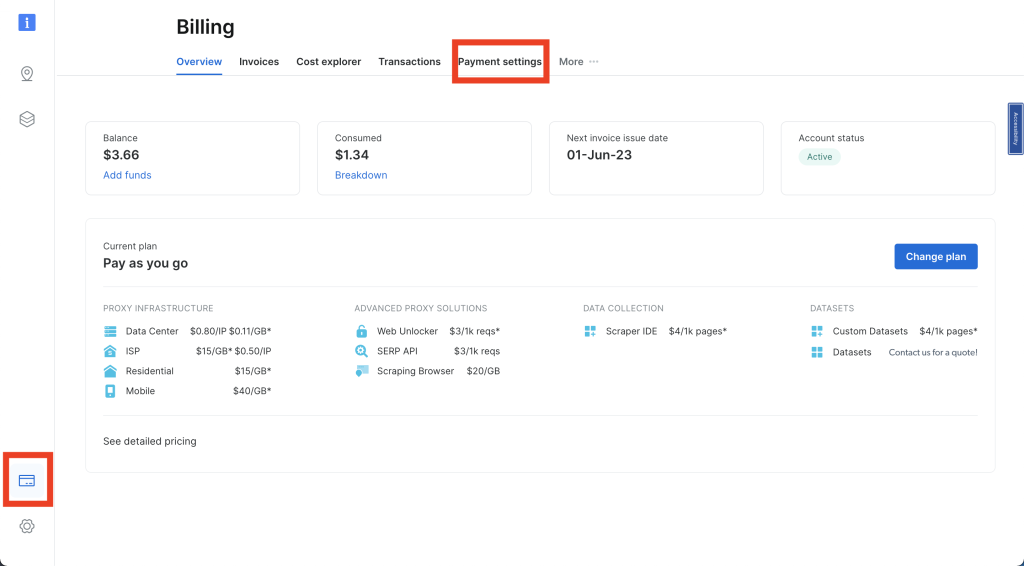
Klicken Sie anschließend auf das Pin-Symbol in der linken Navigationsleiste, um zur Seite „Proxies & Scraping Infrastructure“ (Proxys und Scraping-Infrastruktur) zu gelangen. Klicken Sie dann auf „Add“ (Hinzufügen) > „Residential-Proxys“ (Residential-Proxys):
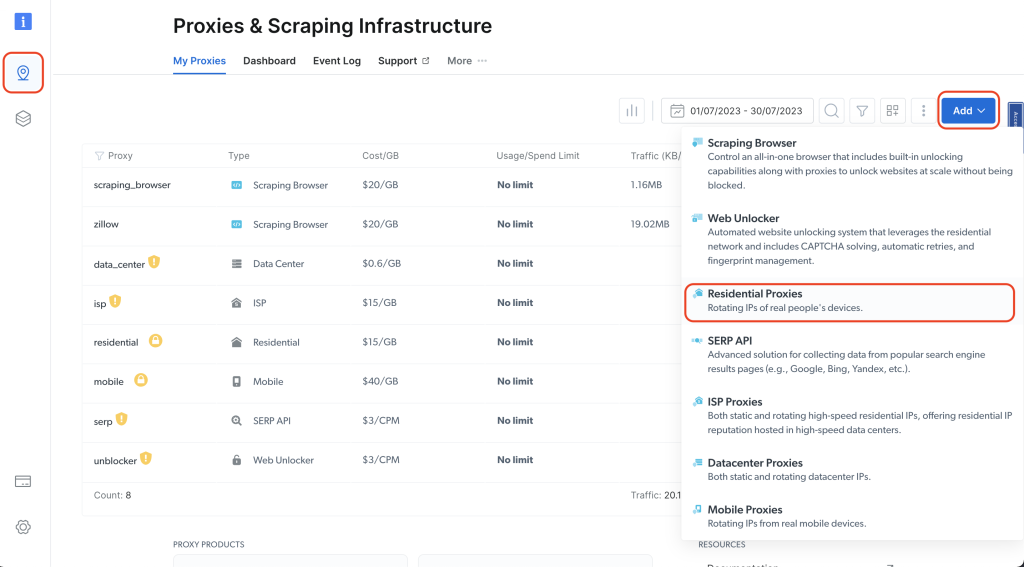
Geben Sie Ihrem Proxy einen Namen (z. B. residential_proxy1) und wählen Sie unter „IP-Typ“ die Option „Gemeinsam genutzt “. Klicken Sie dann auf „Hinzufügen“:

Nachdem Sie Ihren Residential-Proxy erstellt haben, notieren Sie sich die Zugriffsparameter, da Sie diese Angaben in Ihrem Code verwenden müssen:
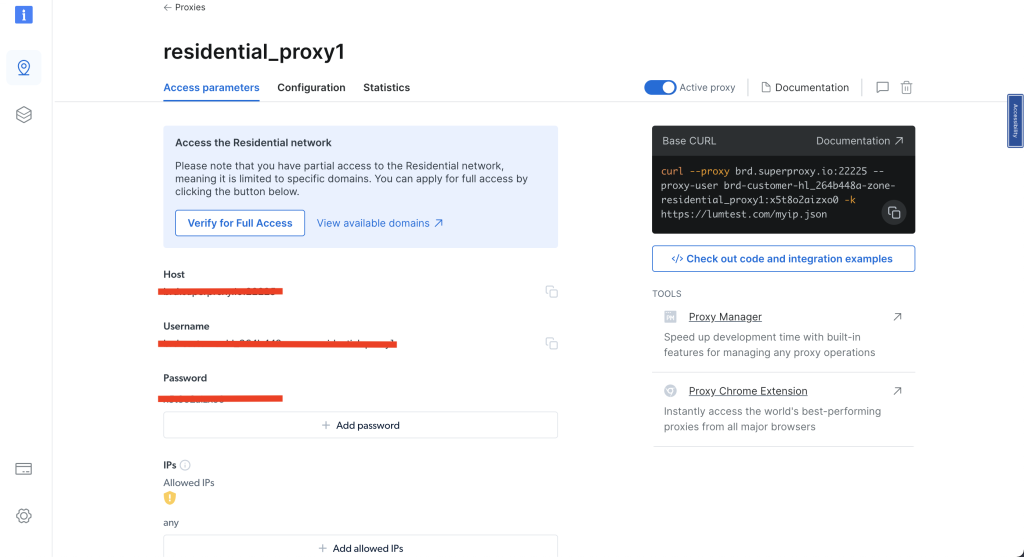
Um den Residential-Proxy von Bright Data nutzen zu können, müssen Sie ein Zertifikat für Ihren Browser einrichten. Eine Anleitung zur Installation des Zertifikats finden Sie in diesem Bright Data-Tutorial.
Erstellen Sie ein neues Python-Skript „airbnb_scraping_proxy.py“ und fügen Sie den folgenden Code hinzu:
from playwright.sync_api import sync_playwright
import pandas as pd
def run(playwright):
browser = playwright.chromium.launch()
context = browser.new_context()
# Proxy einrichten
proxy_username='YOUR_BRIGHTDATA_PROXY_USERNAME'
proxy_password='YOUR_BRIGHTDATA_PROXY_PASSWORD'
proxy_host = 'YOUR_BRIGHTDATA_PROXY_HOST'
proxy_auth=f'{proxy_username}:{proxy_password}'
proxy_server = f'http://{proxy_auth}@{proxy_host}'
context = browser.new_context(proxy={
'server': proxy_server,
'username': proxy_username,
'password': proxy_password
})
page = context.new_page()
page.goto('https://www.airbnb.com/s/homes')
# Warten, bis die Seite geladen ist
page.wait_for_load_state("networkidle")
# Daten extrahieren
results = page.eval_on_selector_all('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr', '''(listings) => {
return listings.map(listing => {
return {
property_name: listing.querySelector('div[data-testid="listing-card-title"]')?.innerText || 'N/A',
location: listing.querySelector('div[data-testid="listing-card-subtitle"]')?.innerText || 'N/A',
price: listing.querySelector('div._1jo4hgw')?.innerText || 'N/A'
}
})
}''')
df = pd.DataFrame(results)
df.to_csv('airbnb_listings_scraping_proxy.csv', index=False)
# Browser schließen
browser.close()
with sync_playwright() as playwright:
run(playwright)
Dieser Code verwendet die Playwright-Bibliothek, um einen Chromium-Browser mit einem bestimmten Proxy zu starten. Er navigiert zur Startseite von Airbnb, extrahiert Details wie Namen, Standorte und Preise der Immobilien aus den Angeboten und speichert die Daten mit pandas in einer CSV-Datei. Nach der Datenextraktion wird der Browser geschlossen.
Hinweis: Ersetzen Sie
proxy_username,proxy_passwordundproxy_hostdurch Ihre Bright Data-Zugriffsparameter.
Um das Skript auszuführen, führen Sie python3 airbnb_scraping_proxy.py in Ihrem Terminal oder Ihrer Shell aus. Die gescrapten Daten werden in einer CSV-Datei namens airbnb_listings_scraping_proxy.csv gespeichert. Ihre CSV-Datei sollte wie folgt aussehen:
property_name,location,price
„Sithonia, Griechenland”,Lagomandra,”3.305 $
pro Nacht”
„Apraos, Griechenland”,„1.080 Kilometer entfernt”,„237 $
pro Nacht”
„Magnisia, Griechenland”, Milopotamos Paralympic, „200 $
pro Nacht”
„Vourvourou, Griechenland”, 861 Kilometer entfernt, „357 $
pro Nacht”
„Rovies, Griechenland”, „1.019 Kilometer entfernt”, „1.077 $
pro Nacht”
…Ausgabe ausgelassen…
Airbnb mit dem Scraping-Browser von Bright Data scrapen
Mit dem Bright Data Scraping Browser lässt sich der Scraping-Prozess noch effizienter gestalten. Dieses Tool wurde speziell für das Web-Scraping entwickelt und bietet eine Reihe von Vorteilen, darunter automatische Entsperrung, einfache Skalierung und die Umgehung von Bot-Erkennungssoftware.
Gehen Sie zu Ihrem Bright Data-Dashboard und klicken Sie auf das Pin-Symbol, um zur Seite „Proxy & Scraping-Infrastruktur“ zu gelangen. Klicken Sie dann auf „Add“ > „Scraping-Browser“:
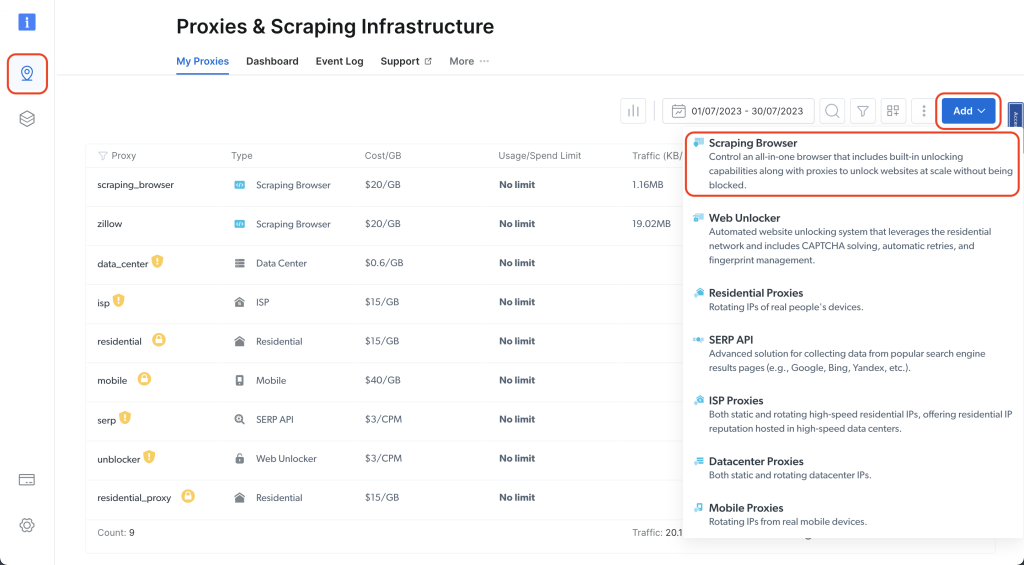
Geben Sie ihm einen Namen (z. B. „scraping_browser”) und klicken Sie auf „Hinzufügen”:

Wählen Sie als Nächstes „Zugriffsparameter“ und geben Sie Ihren Benutzernamen, Host und Ihr Passwort ein – diese Angaben werden später in dieser Anleitung benötigt:
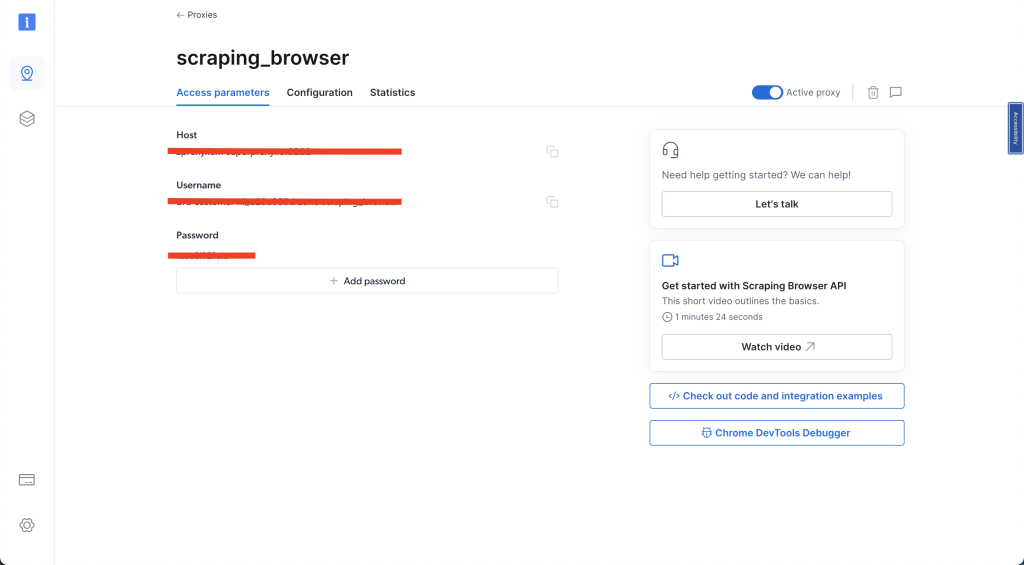
Nachdem Sie diese Schritte abgeschlossen haben, erstellen Sie ein neues Python-Skript mit dem Namen airbnb_scraping_brower.py und fügen Sie den folgenden Code hinzu:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
import pandas as pd
username='IHR_BRIGHTDATA_BENUTZERNAME'
password='IHR_BRIGHTDATA_PASSWORT'
auth=f'{username}:{password}'
host = 'IHR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_airbnb():
async with async_playwright() as pw:
# Neuen Browser starten
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('verbunden')
page = await browser.new_page()
# Zur Airbnb-URL gehen
await page.goto('https://www.airbnb.com/s/homes', timeout=120000)
print('fertig, auswerten')
# Den gesamten HTML-Inhalt abrufen
html_content = await page.evaluate('()=>document.documentElement.outerHTML')
# HTML mit Beautiful Soup analysieren
soup = BeautifulSoup(html_content, 'html.parser')
# Informationen extrahieren
results = []
listings = soup.select('div.g1qv1ctd.c1v0rf5q.dir.dir-ltr')
for listing in listings:
result = {}
# Name der Immobilie
name_element = listing.select_one('div[data-testid="listing-card-title"]')
result['property_name'] = name_element.text if name_element else 'N/A'
# Standort
location_element = listing.select_one('div[data-testid="listing-card-subtitle"]')
result['location'] = location_element.text if location_element else 'N/A'
# Preis
price_element = listing.select_one('div._1jo4hgw')
result['price'] = price_element.text if price_element else 'N/A'
results.append(result)
# Browser schließen
await browser.close()
return results
# Scraper ausführen und Ergebnisse in einer CSV-Datei speichern
results = asyncio.run(scrape_airbnb())
df = pd.DataFrame(results)
df.to_csv('airbnb_listings_scraping_browser.csv', index=False)
Dieser Code verwendet den Bright Data-Proxy, um eine Verbindung zu einem Chromium-Browser herzustellen und Details zu Immobilien (d. h. Name, Standort und Preis) von der Airbnb-Website zu scrapen. Die abgerufenen Daten werden in einer Liste gespeichert, dann in einem DataFrame gespeichert und in eine CSV-Datei mit dem Namen airbnb_listings_scraping_browser.csv exportiert.
Hinweis: Denken Sie daran, den
Benutzernamen,das Passwortundden Hostdurch Ihre Bright Data-Zugriffsparameter zu ersetzen.
Führen Sie den Code von Ihrem Terminal oder Ihrer Shell aus:
python3 airbnb_scraping_browser.py
Sie sollten eine neue CSV-Datei mit dem Namen „airbnb_listings_scraping_browser.csv” in Ihrem Projekt sehen. Die Datei sollte wie folgt aussehen:
property_name,location,price
„Benton Harbor, Michigan”,Round Lake,„514 $
pro Nacht”
„Pleasant Prairie, Wisconsin”,Lake Michigan,„366 $
pro Nacht”
„New Buffalo, Michigan”,Lake Michigan,„2.486 $
pro Nacht”
„Fox Lake, Illinois”, Nippersink Lake, „199 $
pro Nacht”
„Salem, Wisconsin”, Hooker Lake, „880 $
pro Nacht”
…Ausgabe ausgelassen…
Scrapen Sie nun einige Daten zu einem einzelnen Eintrag. Erstellen Sie ein neues Python-Skript namens „airbnb_scraping_single_listing.py” und fügen Sie den folgenden Code hinzu:
import asyncio
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_airbnb_listing():
async with async_playwright() as pw:
# Neuen Browser starten
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
# Zur Airbnb-URL gehen
await page.goto('https://www.airbnb.com/rooms/26300485', timeout=120000)
print('done, evaluating')
# Warten, bis der Inhalt geladen ist
await page.wait_for_selector('div.tq51prx.dir.dir-ltr h2')
# Den gesamten HTML-Inhalt abrufen
html_content = await page.evaluate('()=>document.documentElement.outerHTML')
# HTML mit Beautiful Soup analysieren
soup = BeautifulSoup(html_content, 'html.parser')
# Hostnamen extrahieren
host_div = soup.select_one('div.tq51prx.dir.dir-ltr h2')
host_name = host_div.text.split("hosted by ")[-1] if host_div else 'N/A'
print(f'Hostname: {host_name}')
# Bewertungen extrahieren
reviews_span = soup.select_one('span._s65ijh7 button')
reviews = reviews_span.text.split(" ")[0] if reviews_span else 'N/A'
print(f'Bewertungen: {reviews}')
# Browser schließen
await browser.close()
return {
'host_name': host_name,
'reviews': reviews,
}
# Scraper ausführen und Ergebnisse in einer CSV-Datei speichern
results = asyncio.run(scrape_airbnb_listing())
df = pd.DataFrame([results]) # results ist nun ein Wörterbuch
df.to_csv('scrape_airbnb_listing.csv', index=False)
In diesem Code navigieren Sie zur gewünschten Listing-URL, extrahieren den HTML-Inhalt, parsen ihn mit Beautiful Soup, um den Namen des Gastgebers und die Anzahl der Bewertungen abzurufen, und speichern schließlich die extrahierten Details mit pandas in einer CSV-Datei.
Führen Sie den Code von Ihrem Terminal oder Ihrer Shell aus:
python3 airbnb_scraping_single_listing.py
Sie sollten nun eine neue CSV-Datei mit dem Namen scrape_airbnb_listing.csv in Ihrem Projekt sehen. Der Inhalt dieser Datei sollte wie folgt aussehen:
host_name,reviews
Amelia,88
Der gesamte Code für dieses Tutorial ist in diesem GitHub-Repository verfügbar.
Vorteile der Verwendung des Bright Data Scraping-Browser
Es gibt mehrere Gründe, warum Sie den Scraping-Browser von Bright Data einer lokalen Chromium-Instanz vorziehen sollten. Hier sind einige dieser Gründe:
- Automatische Entsperrung: Der Bright Data Scraping-Browser behandelt automatisch CAPTCHAs, gesperrte Seiten und andere Herausforderungen, mit denen Websites Scraper abwehren. Dadurch wird die Wahrscheinlichkeit, dass Ihr Scraper gesperrt wird, drastisch reduziert.
- Einfache Skalierung: Die Lösungen von Bright Data sind so konzipiert, dass sie leicht skaliert werden können, sodass Sie Daten von einer großen Anzahl von Webseiten gleichzeitig sammeln können.
- Bot-Erkennungssoftware überlisten: Moderne Websites verwenden ausgeklügelte Bot-Erkennungssysteme. Der Bright Data Scraping-Browser kann menschliches Verhalten erfolgreich imitieren, um diese Erkennungsalgorithmen zu überlisten.
Wenn Ihnen das manuelle Scraping von Daten oder das Einrichten von Skripten zu zeitaufwändig oder komplex erscheint, sind die benutzerdefinierten Datensätze von Bright Data eine hervorragende Alternative. Sie bieten einen Airbnb-Datensatz mit Informationen zu Airbnb-Immobilien, auf den Sie zugreifen und den Sie analysieren können, ohne selbst Scraping durchführen zu müssen.
Um die Datensätze anzuzeigen, klicken Sie im linken Navigationsmenü auf „Webdaten“, wählen Sie dann „Datensatz-Marktplatz“ und suchen Sie nach „Airbnb“. Klicken Sie auf „Datensatz anzeigen“. Auf dieser Seite können Sie Filter anwenden und die gewünschten Daten kaufen. Sie zahlen entsprechend der Anzahl der gewünschten Datensätze:
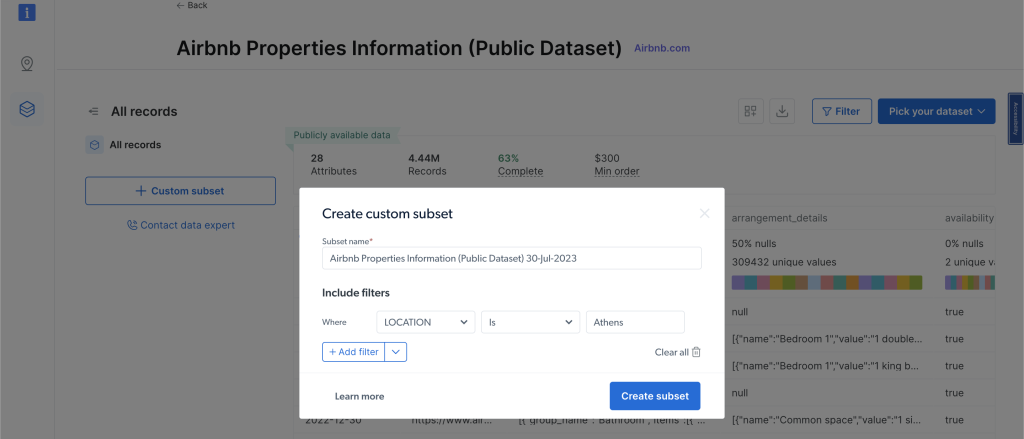
Fazit
In diesem Tutorial haben Sie gelernt, wie Sie mit Python Daten aus Airbnb-Inseraten extrahieren können, und Sie haben gesehen, wie Tools von Bright Data, wie die Proxy und der Scraping-Browser, diese Aufgabe noch einfacher machen können.
Bright Data bietet eine Reihe von Tools, mit denen Sie schnell und einfach Daten von jeder Website, nicht nur von Airbnb, sammeln können. Diese Tools machen schwierige Web-Scraping-Aufgaben zu einfachen Aufgaben und sparen Ihnen Zeit und Mühe. Sie sind sich nicht sicher, welches Produkt Sie benötigen? Sprechen Sie mit den Webdaten-Experten von Bright Data, um die richtige Lösung für Ihre Datenanforderungen zu finden.
Sind Sie daran interessiert, andere Websites zu scrapen? Lesen Sie weiter in den folgenden Artikeln:
Hinweis: Dieser Leitfaden wurde zum Zeitpunkt der Erstellung von unserem Team gründlich getestet. Da Websites jedoch häufig ihren Code und ihre Struktur aktualisieren, funktionieren einige Schritte möglicherweise nicht mehr wie erwartet.






