

In dieser Anleitung geht es um Folgendes:
- Warum sollten Sie E-Commerce-Daten aus dem Internet scrapen?
- eBay Scraping-Bibliotheken und Tools
- Scraping von eBay-Produktdaten mit Beautiful Soup
Warum sollten Sie E-Commerce-Daten aus dem Internet scrapen?
Das Scrapen von E-Commerce-Daten ermöglicht es Ihnen, nützliche Informationen für verschiedene Szenarien und Tätigkeiten zu erhalten. Dazu gehören:
- Preisüberwachung: Wenn Unternehmen E-Commerce-Websites verfolgen, können sie die Preise der Artikel in Echtzeit überwachen. Sie können Preisschwankungen erkennen, Trends ausmachen und Ihre Preisstrategie entsprechend anpassen. Wenn Sie ein Verbraucher sind, können Sie so die besten Angebote finden und eine Menge Geld sparen.
- Analyse der Wettbewerber: Wenn Sie Informationen über die Produktangebote, Preise, Rabatte und Werbeaktionen Ihrer Mitbewerber erfassen, sind Sie in der Lage, datengestützte Entscheidungen über Ihre eigenen Preisstrategien, Ihr Produktsortiment und Ihre Marketingkampagnen zu treffen.
- Marktforschung: E-Commerce-Daten bieten wertvolle Einblicke in Markttrends, Verbraucherpräferenzen und Nachfragemuster. Um neue Trends zu untersuchen und das Kundenverhalten zu verstehen, können Sie diese Informationen als Quelle für die Datenanalyse nutzen.
- Stimmungsanalyse: Mit dem Scrapen von Kundenrezensionen auf E-Commerce-Websites gewinnen Sie Einblicke in die Kundenzufriedenheit, das Produktfeedback und verbesserungswürdige Bereiche.
Wenn es um E-Commerce-Scraping geht, ist eBay aus mindestens drei guten Gründen eine der beliebtesten Optionen:
- eBay verfügt über eine breite Produktpalette.
- Es basiert auf einem Auktions- und Bietsystem, mit dem Sie viel mehr Daten abrufen können als bei Amazon und ähnlichen Plattformen.
- Es hat mehrere Preise für dieselben Artikel (Auktion + Sofort-Kaufen)
Durch die Extraktion von Daten aus eBay greifen Sie auf eine Fülle von Informationen zu, die Sie bei der Überwachung, dem Vergleich und der Analyse von Preisen unterstützen.
eBay Scraping-Bibliotheken und Tools
Python gilt dank seiner Benutzerfreundlichkeit, der einfachen Syntax und dem großen Angebot an Bibliotheken als eine der besten Sprachen für das Scraping. Deshalb wählen wir diese Programmiersprache für das Scrapen von eBay. In unserer ausführlichen Anleitung über das Web-Scraping in Python erfahren Sie mehr über dieses Thema.
Sie müssen nun die richtigen Scraping-Bibliotheken aus den vielen verfügbaren auswählen. Um die richtige Entscheidung zu treffen, erkunden Sie eBay im Browser. Wenn Sie sich die AJAX-Aufrufe der Website ansehen, werden Sie feststellen, dass die meisten Daten der Website in das vom Server zurückgegebene HTML-Dokument eingebettet sind.
Das bedeutet, dass ein einfacher HTTP-Client zur Nachbildung der Anfrage an den Server und ein HTML-Parser ausreichen. Aus diesem Grund empfehlen wir:
- Requests: Die beliebteste HTTP-Client-Bibliothek für Python. Sie vereinfacht das Senden von HTTP-Anfragen und die Bearbeitung der Antworten, was das Abrufen der Inhalte der Website von den Webservern erleichtert.
- Beautiful Soup: Eine Python-Bibliothek mit vollem Funktionsumfang für das Parsen von HTML und XML. Sie wird hauptsächlich für das Web Scraping verwendet, da sie leistungsstarke Techniken zur Erkundung des DOM und zur Extraktion von Daten aus seinen Elementen bietet.
Dank Requests und Beautiful Soup können Sie die Ziel-Website in Python scrapen. Schauen wir uns an, wie das geht!
Scraping von eBay-Produktdaten mit Beautiful Soup
In dieser Schritt-für-Schritt-Anleitung erfahren Sie, wie Sie ein Python-Skript zum Scrapen von eBay-Webseiten erstellen.
Schritt 1: Erste Schritte
Um das Preis-Scraping zu implementieren, müssen Sie folgende Voraussetzungen erfüllen:
- Python 3+ muss auf Ihrem Computer installiert sein: Laden Sie das Installationsprogramm, starten Sie es und folgen Sie den Anweisungen des Installationsassistenten.
- Eine Python-IDE Ihrer Wahl: Visual Studio Code mit einer Erweiterung für Python oder PyCharm Community Edition sind zwei hervorragende Möglichkeiten.
Als nächstes initialisieren Sie ein Python-Projekt mit einer virtuellen Umgebung namens ebay scraper, indem Sie die folgenden Befehle ausführen:
mkdir ebay-scraper
cd ebay-scraper
python -m venv envGeben Sie den Projektordner ein und fügen Sie die Datei scraper.py mit dem folgenden Schnipsel hinzu:
print('Hello, World!')Es handelt sich ein Beispielskript, das nur „Hello, World!“ ausgibt, aber es wird bald die Logik zum Scrapen von eBay enthalten.
Überprüfen Sie, ob es funktioniert, indem Sie es ausführen mit:
python scraper.pyIhr Gerät sollte Folgendes angezeigen:
Hello, World!Toll, jetzt haben Sie ein Python-Projekt!
Schritt 2: Installieren Sie die Scraping-Bibliotheken
Es ist an der Zeit, die für die Durchführung von Web Scraping erforderlichen Bibliotheken zu den Abhängigkeiten Ihres Projekts hinzuzufügen. Um die Pakete Beautiful Soup und Requests zu installieren, führen Sie den folgenden Befehl im Projektordner aus:
pip install beautifulsoup4 requestsImportieren Sie die Bibliotheken in scraper.py und nutzen Sie sie, um Daten aus eBay zu extrahieren:
import requests
from bs4 import BeautifulSoup
# scraping logic...Vergewissern Sie sich, dass Ihre Python-IDE keinen Fehler meldet. Nun sind Sie bereit, die Preisüberwachung mit Scraping zu implementieren!
Schritt 3: Laden Sie die Ziel-Website herunter
Wenn Sie ein eBay-Nutzer sind, haben Sie vielleicht bemerkt, dass die URL der Produktseite das folgende Format hat:
https://www.ebay.com/itm/<ITM_ID>Wie Sie sehen, handelt es sich um eine dynamische URL, die sich je nach Artikelnummer ändert.
Dies ist zum Beispiel die URL eines Artikels auf eBay:
https://www.ebay.com/itm/225605642071?epid=26057553242&hash=item348724e757:g:~ykAAOSw201kD1un&amdata=enc%3AAQAIAAAA4OMICjL%2BH6HBrWqJLiCPpCurGf8qKkO7CuQwOkJClqK%2BT2B5ioN3Z9pwm4r7tGSGG%2FI31uN6k0IJr0SEMEkSYRrz1de9XKIfQhatgKQJzIU6B9GnR6ZYbzcU8AGyKT6iUTEkJWkOicfCYI5N0qWL8gYV2RGT4zr6cCkJQnmuYIjhzFonqwFVdYKYukhWNWVrlcv5g%2BI9kitSz8k%2F8eqAz7IzcdGE44xsEaSU2yz%2BJxneYq0PHoJoVt%2FBujuSnmnO1AXqjGamS3tgNcK5Tqu36QhHRB0tiwUfAMrzLCOe9zTa%7Ctkp%3ABFBMmNDJgZJiIn diesem Beispiel ist 225605642071 die eindeutige Produktkennung. Beachten Sie, dass die Abfrageparameter nicht erforderlich sind, um die Seite zu besuchen. Sie können diese entfernen. eBay lädt die Produktseite trotzdem korrekt.
Anstatt die Zielseite in Ihrem Skript zu programmieren, haben Sie auch die Möglichkeit, die Produktkennung aus einem Befehlszeilenargument lesen zu lassen. Auf diese Weise können Sie Daten von jeder beliebigen Produktseite abrufen.
Aktualisieren Sie dafür scraper.py wie folgt:
import requests
from bs4 import BeautifulSoup
import sys
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Item ID argument missing!')
sys.exit(2)
# read the item ID from a CLI argument
item_id = sys.argv[1]
# build the URL of the target product page
url = f'https://www.ebay.com/itm/{item_id}'
# scraping logic...
Assume you want to scrape the product 225605642071. You can launch your scraper with:
python scraper.py 225605642071Mit sys können Sie auf die Befehlszeilenargumente zugreifen. Das erste Element von sys.argv ist der Name Ihres Skripts: scraper.py. Um die Produktkennung zu erhalten, müssen Sie dann das Element mit Index 1 ansteuern.
Wenn Sie die Produktkennung in der CLI vergessen, schlägt die Anwendung fehl und gibt die folgende Fehlermeldung aus:
Item ID argument missing!Andernfalls liest sie den CLI-Parameter und verwendet ihn in einem f-String, um die Ziel-URL Produkts, das sie scrapen möchten, zu erzeugen. In diesem Fall enthält die URL Folgendes:
https://www.ebay.com/itm/225605642071Mit der folgenden Codezeile können Sie nun zum Herunterladen dieser Website „Requests“ verwenden:
page = requests.get(url)Im Hintergrund führt request.get() eine HTTP-GET-Anfrage an die als Parameter übergebene URL aus. Die vom eBay-Server erzeugte Antwort, einschließlich des HTML-Inhalts der Ziel-Website, werden auf der Seite gespeichert.
Großartig! Erfahren Sie nun, wie Sie von dort aus Daten abrufen.
Schritt 4: Parsen Sie das HTML-Dokument
page.text enthält das vom Server zurückgegebene HTML-Dokument. Um es zu parsen, übergeben Sie es an den BeautifulSoup() Constructor:
soup = BeautifulSoup(page.text, 'html.parser')Der zweite Parameter gibt den von Beautiful Soup verwendeten Parser an. Falls Sie damit nicht vertraut sind, html.parser ist der Name des in Python integrierten HTML-Parsers.
Die Variable soup speichert nun eine Baumstruktur, die einige nützliche Methoden zur Auswahl von Elementen aus dem DOM bereitstellt. Die beliebtesten sind:
- find(): Gibt das erste HTML-Element zurück, das der als Parameter übergebenen Selektor-Bedingung entspricht.
- find_all(): Gibt eine Liste mit HTML-Elementen zurück, die der eingegebenen Selektorstrategie entsprechen.
- select_one(): Gibt die HTML-Elemente zurück, die dem eingegebenen CSS-Selektor entsprechen.
- select(): Gibt eine Liste von HTML-Elementen zurück, die dem als Parameter übergebenen CSS-Selektor entsprechen.
Damit können Sie HTML-Elemente nach Tag (Auszeichnungsmarkierung), ID, CSS-Klassen und mehr auswählen. Anschließend können Sie Daten aus deren Attributen und Textinhalten extrahieren. Schauen wir uns an, wie das geht!
Schritt 5: Überprüfen Sie die Produktseite
Wenn Sie eine effektive Data-Scraping-Strategie aufbauen wollen, müssen Sie sich zunächst mit der Struktur der Seiten der Ziel-Website vertraut machen. Öffnen Sie Ihren Browser und schauen Sie sich auf eBay einige Produkte an.
Sie werden zunächst feststellen, dass die Seite je nach Produktkategorie unterschiedliche Informationen enthält. Bei den Elektroartikeln haben Sie Zugang zu technischen Spezifikationen.

Wenn Sie sich Kleidungsstücke anschauen, sehen Sie die verfügbaren Größen und Farben.

Diese Inkonsistenzen der Struktur der einzelnen Seiten der Website machen das Scraping etwas schwieriger. Einige Informationsfelder befinden sich jedoch auf allen Seiten, z. B. die Preise der Artikel und für den Versand.
Machen Sie sich auch mit den DevTools Ihres Browsers vertraut. Klicken Sie mit der rechten Maustaste auf ein HTML-Element, das interessante Daten enthält, und wählen Sie „inspect“ (untersuchen). Daraufhin öffnet sich das nachstehende Fenster:
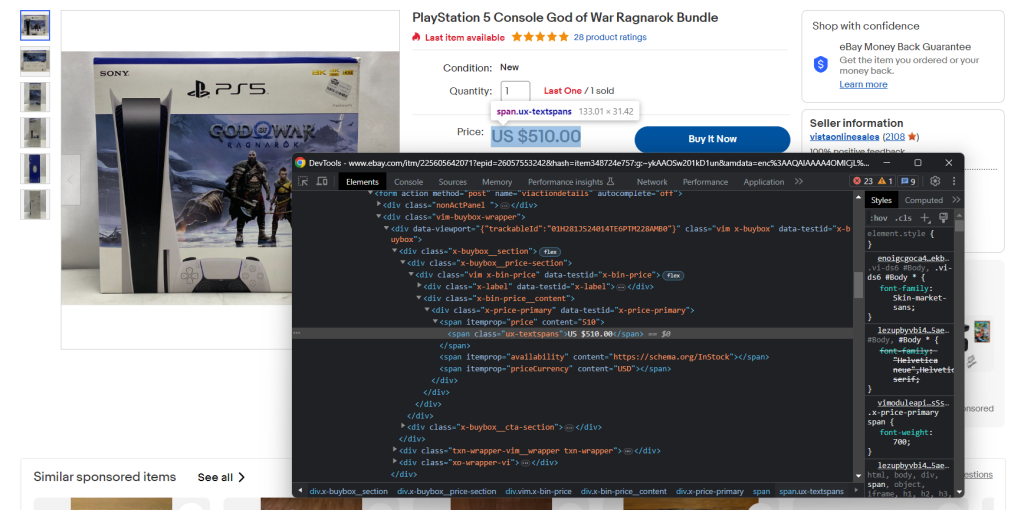
Hier können Sie die DOM-Struktur der Seite erkunden. Sie werden verstehen, wie Sie effektive Selektorstrategien festlegen können.
Nehmen Sie sich etwas Zeit, um die Produktseiten mit den DevTools zu prüfen.
Schritt 6: Extrahieren Sie die Preisdaten
Zunächst benötigen Sie eine Datenstruktur, in der Sie die zu Daten, die Sie scrapen möchten, speichern können. Initialisieren Sie ein Python-Wörterbuch mit:
item = {}Wie Sie während des letzten Schrittes bemerkt haben, sind die Preisdaten in diesem Abschnitt enthalten:

Prüfen Sie das HTML-Preiselement:
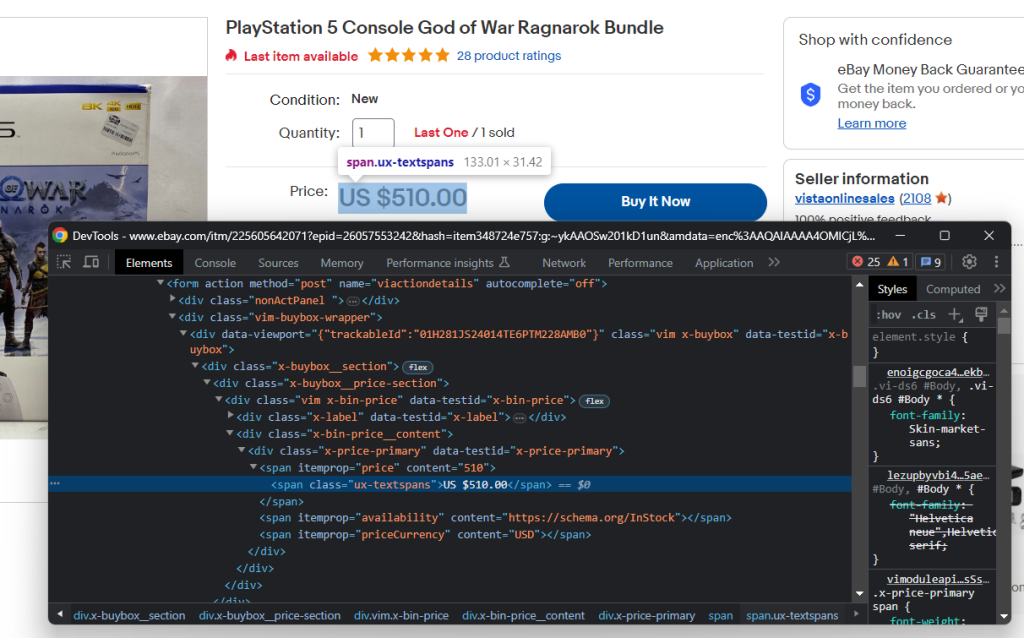
Den Preis des Artikels können Sie mit dem unten stehenden CSS-Selektor ermitteln:Schnipsel wählt die HTML-Elemente „Preis“ und „Währung“ aus und erfasst dann die in ihrem Content-Attribut enthaltene Zeichenfolge.
.x-price-primary span[itemprop="price"]
And the currency with:
.x-price-primary span[itemprop="priceCurrency"]
Apply those selectors in Beautiful Soup and retrieve the desired data with:
price_html_element = soup.select_one('.x-price-primary span[itemprop="price"]')
price = price_html_element['content']
currency_html_element = soup.select_one('.x-price-primary span[itemprop="priceCurrency"]')
currency = currency_html_element['content']Dieser Schnipsel wählt die HTML-Elemente „Preis“ und „Währung“ aus und erfasst dann die in ihrem Content-Attribut enthaltene Zeichenfolge.
Denken Sie daran, dass der oben genannte Preis nur ein Teil des Gesamtpreises ist, den Sie zahlen müssen, um den gewünschten Artikel zu erhalten. Dazu gehören auch die Versandkosten.
Überprüfen Sie das Versandelement:
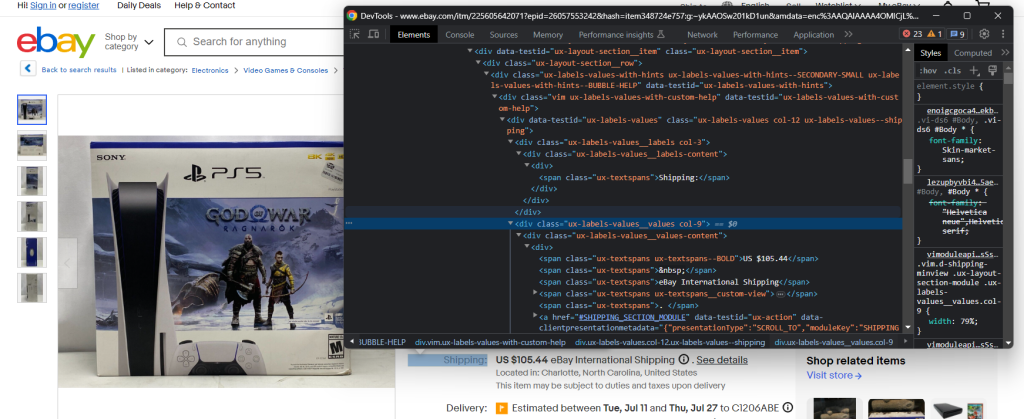
Dieses Mal ist das Extrahieren der gewünschten Daten etwas schwieriger, da es keinen einfachen CSS-Selektor gibt, mit dem Sie das Element erhalten können. Eine Möglichkeit ist, jedes ux-labels-values__labels div zu durchlaufen. Wenn das aktuelle Element die Zeichenfolge „Versand:“ enthält, können Sie auf das nächste Geschwisterelement im DOM zugreifen und den Preis aus .ux-textspans–BOLD extrahieren:
label_html_elements = soup.select('.ux-labels-values__labels')
for label_html_element in label_html_elements:
if 'Shipping:' in label_html_element.text:
shipping_price_html_element = label_html_element.next_sibling.select_one('.ux-textspans--BOLD')
# if there is a shipping price HTML element
if shipping_price_html_element is not None:
# extract the float number of the price from
# the text content
shipping_price = re.findall("d+[.,]d+", shipping_price_html_element.text)[0]
breakDas Element Versandpreis enthält die gewünschten Daten in folgendem Format:
US $105.44Um den Preis zu extrahieren, können Sie einen regulären Ausdruck (eng. „Regular expression“, Regex) mit der Methode re.findall() verwenden. Vergessen Sie nicht, die folgende Zeile in den Importabschnitt Ihres Skripts einzufügen:
import re
Add the collected data to the item dictionary:
item['price'] = price
item['shipping_price'] = shipping_price
item['currency'] = currency
Print it with:
print(item)
And you will get:
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD'}Das reicht aus, um einen Preisverfolgungsprozess in Python zu implementieren. Dennoch gibt es auf der eBay-Produktseite eine Menge weiterer nützlicher Informationen. Es lohnt sich also, zu lernen, wie man diese extrahiert!
Schritt 7: Rufen Sie die Artikelbeschreibung auf
Wenn Sie einen Blick auf die Registerkarte „Info zum Artikel“ werfen, werden Sie feststellen, dass sie eine Menge interessanter Daten enthält:
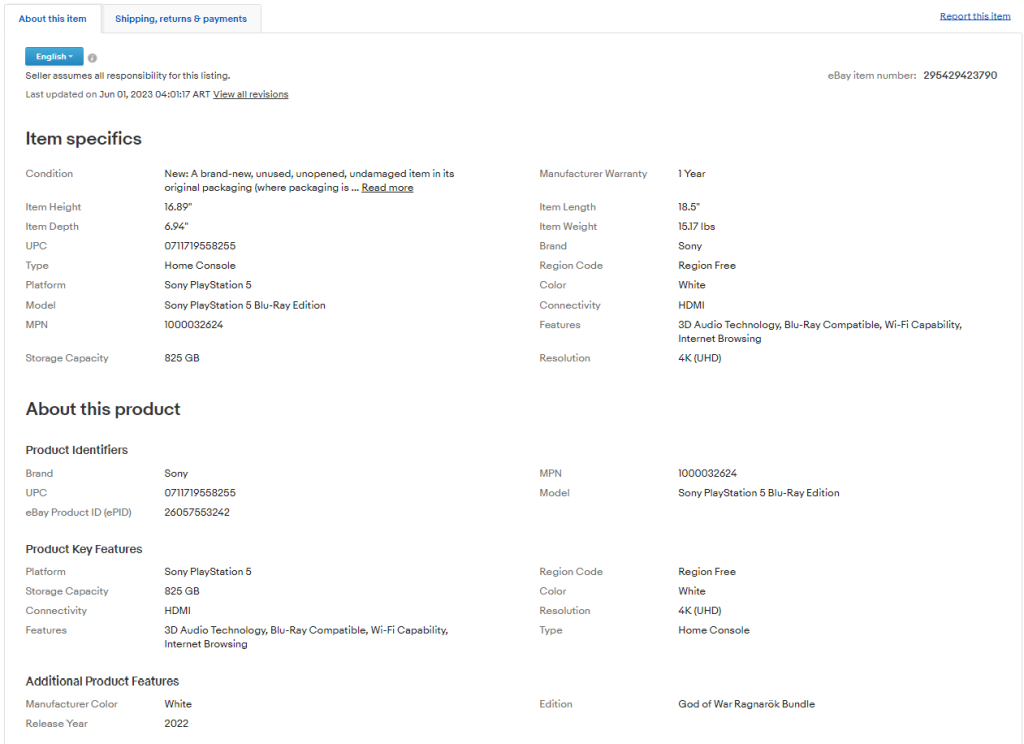
Die Abschnitte und Felder darin ändern sich von Produkt zu Produkt, sodass Sie einen Weg finden müssen, sie alle auf intelligente Weise zu scrapen.
Die wichtigsten Abschnitte sind „Artikelmerkmale“ und „Über dieses Produkt“. Diese beiden Abschnitte sind bei den meisten Produkten vorhanden. Untersuchen Sie einen der beiden. Sie können sie auswählen mit:
.section-title
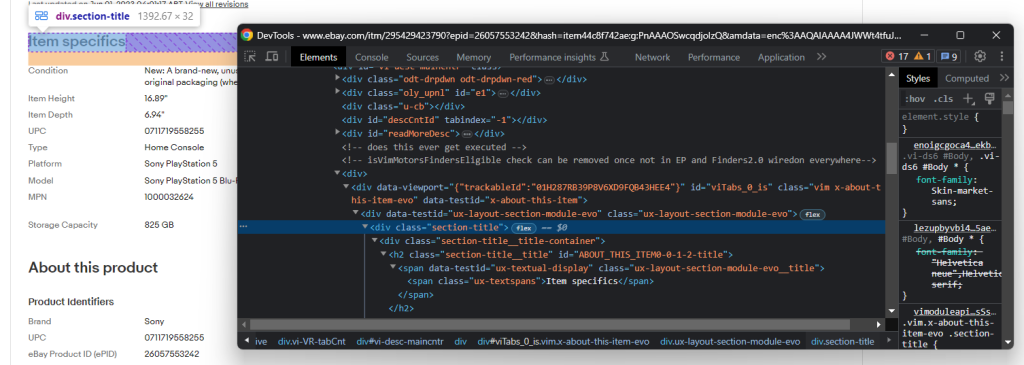
Erkunden Sie die DOM-Struktur eines Abschnitts:
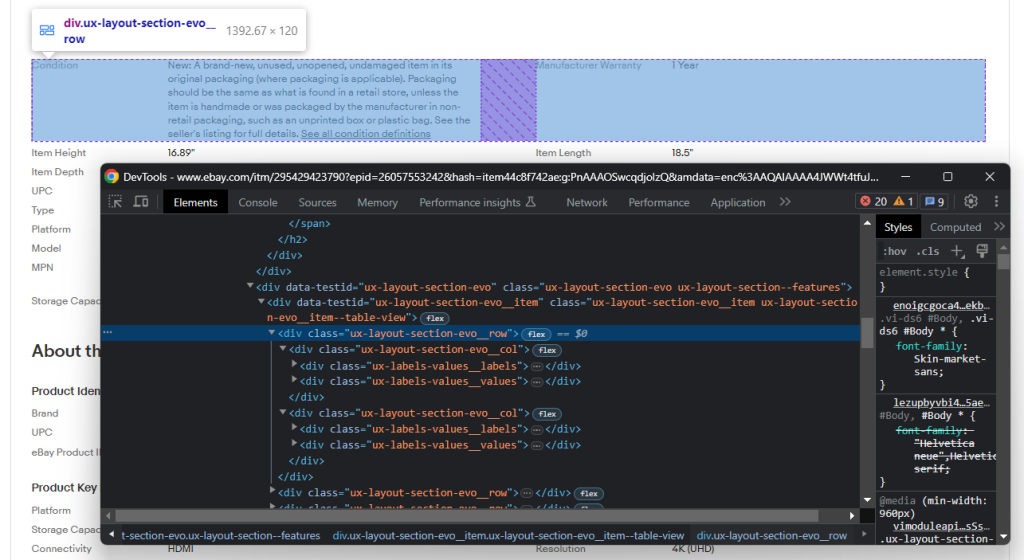
Sie besteht aus mehreren Zeilen, die jeweils einige .ux-layout-section-evo__col-Elemente enthalten. Diese enthalten zwei Elemente:
- .ux-labels-values__labels: Name des Attributs.
- .ux-labels-values__values: Wert des Attributs.
Sie sind nun bereit, alle Informationen des Info-Bereichs programmatisch abzurufen:
section_title_elements = soup.select('.section-title')
for section_title_element in section_title_elements:
if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:
# get the parent element containing the entire section
section_element = section_title_element.parent
for section_col in section_element.select('.ux-layout-section-evo__col'):
print(section_col.text)
col_label = section_col.select_one('.ux-labels-values__labels')
col_value = section_col.select_one('.ux-labels-values__values')
# if both elements are present
if col_label is not None and col_value is not None:
item[col_label.text] = col_value.textDieser Code durchläuft jedes HTML-Element des Info-Bereichs und fügt das Schlüssel-Werte-Paar, das mit jedem Produktattribut verknüpft ist, dem Artikelverzeichnis hinzu.
Am Ende der for-Schleife enthält der Artikel Folgendes:
{'price': '499.99', 'shipping_price': '72.58', 'currency': 'USD', 'Condition': "New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details. See all condition definitionsopens in a new window or tab ", 'Manufacturer Warranty': '1 Year', 'Item Height': '16.89"', 'Item Length': '18.5"', 'Item Depth': '6.94"', 'Item Weight': '15.17 lbs', 'UPC': '0711719558255', 'Brand': 'Sony', 'Type': 'Home Console', 'Region Code': 'Region Free', 'Platform': 'Sony PlayStation 5', 'Color': 'White', 'Model': 'Sony PlayStation 5 Blu-Ray Edition', 'Connectivity': 'HDMI', 'MPN': '1000032624', 'Features': '3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing', 'Storage Capacity': '825 GB', 'Resolution': '4K (UHD)', 'eBay Product ID (ePID)': '26057553242', 'Manufacturer Color': 'White', 'Edition': 'God of War Ragnarök Bundle', 'Release Year': '2022'}Wunderbar! Sie haben soeben Ihr Ziel Ihrer Datenabfrage erreicht!
Schritt 8: Exportieren Sie die gescrapten Daten nach JSON
Jetzt werden die gescrapten Daten in einem Python-Wörterbuch gespeichert. Um es leichter weiterzugeben und lesbar zu machen, können Sie es nach JSON exportieren:
import json
# scraping logic...
with open('product_info.json', 'w') as file:
json.dump(item, file)Zunächst müssen Sie die Datei product_info.json mit öffnen() initialisieren. Dann schreiben Sie die JSON-Darstellung des Artikelwörterbuchs mit json.dump() in die Ausgabedatei. Lesen Sie unseren Artikel, um mehr darüber zu erfahren, wie man Daten in Python parst und in JSON serialisiert.
Da das Json-Paket aus der Python-Standardbibliothek stammt, müssen Sie nicht einmal eine zusätzliche Abhängigkeit installieren, um Ihr Ziel zu erreichen.
Klasse! Sie haben mit den Rohdaten einer Webseite begonnen und verfügen nun über halbstrukturierte JSON-Daten. Nun ist es an der Zeit, einen Blick auf den gesamten eBay Scraper zu werfen.
Schritt 9: Fügen Sie alles zusammen
Hier ist das vollständige scraper.py-Skript:
import requests
from bs4 import BeautifulSoup
import sys
import re
import json
# if there are no CLI parameters
if len(sys.argv) <= 1:
print('Item ID argument missing!')
sys.exit(2)
# read the item ID from a CLI argument
item_id = sys.argv[1]
# build the URL of the target product page
url = f'https://www.ebay.com/itm/{item_id}'
# download the target page
page = requests.get(url)
# parse the HTML document returned by the server
soup = BeautifulSoup(page.text, 'html.parser')
# initialize the object that will contain
# the scraped data
item = {}
# price scraping logic
price_html_element = soup.select_one('.x-price-primary span[itemprop="price"]')
price = price_html_element['content']
currency_html_element = soup.select_one('.x-price-primary span[itemprop="priceCurrency"]')
currency = currency_html_element['content']
shipping_price = None
label_html_elements = soup.select('.ux-labels-values__labels')
for label_html_element in label_html_elements:
if 'Shipping:' in label_html_element.text:
shipping_price_html_element = label_html_element.next_sibling.select_one('.ux-textspans--BOLD')
# if there is not a shipping price HTML element
if shipping_price_html_element is not None:
# extract the float number of the price from
# the text content
shipping_price = re.findall("d+[.,]d+", shipping_price_html_element.text)[0]
break
item['price'] = price
item['shipping_price'] = shipping_price
item['currency'] = currency
# product detail scraping logic
section_title_elements = soup.select('.section-title')
for section_title_element in section_title_elements:
if 'Item specifics' in section_title_element.text or 'About this product' in section_title_element.text:
# get the parent element containing the entire section
section_element = section_title_element.parent
for section_col in section_element.select('.ux-layout-section-evo__col'):
print(section_col.text)
col_label = section_col.select_one('.ux-labels-values__labels')
col_value = section_col.select_one('.ux-labels-values__values')
# if both elements are present
if col_label is not None and col_value is not None:
item[col_label.text] = col_value.text
# export the scraped data to a JSON file
with open('product_info.json', 'w') as file:
json.dump(item, file, indent=4)In weniger als 70 Zeilen Code können Sie einen Web Scraper erstellen, mit dem Sie die Daten der Artikel auf eBay überwachen können.
Starten Sie sie zum Beispiel für den Artikel mit der Kennung 225605642071 mit:
python scraper.py 225605642071Am Ende des Scraping-Prozesses wird die nachstehende Datei product_info.json im Stammordner Ihres Projekts erscheinen:
{
"price": "499.99",
"shipping_price": "72.58",
"currency": "USD",
"Condition": "New: A brand-new, unused, unopened, undamaged item in its original packaging (where packaging is applicable). Packaging should be the same as what is found in a retail store, unless the item is handmade or was packaged by the manufacturer in non-retail packaging, such as an unprinted box or plastic bag. See the seller's listing for full details",
"Manufacturer Warranty": "1 Year",
"Item Height": "16.89"",
"Item Length": "18.5"",
"Item Depth": "6.94"",
"Item Weight": "15.17 lbs",
"UPC": "0711719558255",
"Brand": "Sony",
"Type": "Home Console",
"Region Code": "Region Free",
"Platform": "Sony PlayStation 5",
"Color": "White",
"Model": "Sony PlayStation 5 Blu-Ray Edition",
"Connectivity": "HDMI",
"MPN": "1000032624",
"Features": "3D Audio Technology, Blu-Ray Compatible, Wi-Fi Capability, Internet Browsing",
"Storage Capacity": "825 GB",
"Resolution": "4K (UHD)",
"eBay Product ID (ePID)": "26057553242",
"Manufacturer Color": "White",
"Edition": "God of War Ragnarok Bundle",
"Release Year": "2022"
}Herzlichen Glückwunsch! Sie haben gerade gelernt, wie man eBay in Python scrapen kann!
Fazit
Mit diesem Leitfaden haben Sie herausgefunden, warum eBay eines der besten Scraping-Ziele ist, um Produktpreise zu verfolgen, und wie Sie das erreichen können. In dieser Schritt-für-Schritt-Anleitung haben Sie erfahren, wie Sie einen Python-Scraper erstellen, der Artikeldaten abrufen kann. Wie Sie gesehen haben, ist das nicht besonders komplex und erfordert nur wenige Codezeilen.
Sie haben auch gesehen, wie inkonsistent die Struktur der Ebay-Seiten ist. Der hier erstellte Scraper könnte also für ein Produkt funktionieren, für ein anderes aber nicht. Außerdem ändert sich die Benutzeroberfläche von eBay häufig, was Sie zwingt, das Skript ständig auf dem neuesten Stand zu halten. Zum Glück können Sie dies mit unserem eBay Scraper tun!
Wenn Sie Ihr Scraping ausweiten und Preise von anderen E-Commerce-Plattformen extrahieren möchten, sollten Sie bedenken, dass viele stark auf JavaScript angewiesen sind. Bei solchen Websites funktioniert ein herkömmlicher Ansatz, der auf einem HTML-Parser basiert, nicht. Stattdessen benötigen Sie ein Tool, das JavaScript rendern und automatisch Fingerabdrücke erkennen kann sowie CAPTCHAs und automatische Wiederholungsversuche für Sie erledigt. Das ist genau das, was unser neuer Scraping-Browser bietet!
Sie möchten sich gar nicht mit eBay Web Scraping beschäftigen, sind aber an Artikeldaten interessiert? Dann kaufen Sie einen eBay-Datensatz.


