

Walmart ist sowohl gemessen am Umsatz als auch hinsichtlich der Anzahl der Mitarbeiter der größte Konzern der Welt. Anders als allgemein angenommen, ist Walmart dabei viel mehr als nur ein Einzelhandelsunternehmen: Der Konzern unterhält eine der weltweit umfangreichsten E-Commerce-Websites, die eine hervorragende Informationsquelle in Sachen Produkte darstellt. Da sich die Website-Daten aufgrund der riesigen Produktpalette jedoch unmöglich von einer Person manuell erfassen lassen, dient uns die Website als idealer praktischer Anwendungsfall für das so genannte Web Scraping.
Dank Web Scraping können Sie schnell Daten (z. B. Produktname, Preis, Beschreibung, Bilder und Bewertungen) zu Tausenden von Walmart-Produkten abrufen und in einem beliebigen für Sie sinnvollen Format speichern. Die gescrapten Walmart-Daten ermöglichen es Ihnen, die Preise unterschiedlicher Produkte und deren Lagerbestand zu beobachten, Marktbewegungen und Kundenverhalten zu analysieren und diverse Anwendungen zu erstellen.
In diesem Artikel stellen wir Ihnen zwei höchst unterschiedliche Vorgehensweisen zum Scrapen von Walmart.com vor. Zunächst lernen Sie Schritt für Schritt, wie Sie die Walmart-Website mithilfe von Python und Selenium – einem Tool, das in erster Linie für die Automatisierung von Webanwendungen zu Testzwecken eingesetzt wird – scrapen können. Anschließend erfahren Sie, wie Sie die gleiche Aufgabe mit dem Walmart Scraper von Bright Data noch einfacher erledigen können.
Scrapen der Walmart-Website
Wie Sie vielleicht wissen, gibt es zahlreiche Möglichkeiten, Websites wie z. B. die von Walmart zu scrapen. Eine dieser Methoden besteht in der Verwendung von Python und Selenium.
Anleitung zum Scrapen der Walmart-Website mit Python und Selenium
Python ist in puncto Web Scraping eine der beliebtesten Programmiersprachen. Selenium hingegen wird vorwiegend für die Automatisierung von Tests verwendet. Aufgrund seiner Fähigkeit zur Automatisierung von Webbrowsern kann es jedoch auch beim Web Scraping eingesetzt werden.
Im Grunde genommen simuliert Selenium manuelle Vorgänge in einem Webbrowser. Mithilfe von Python und Selenium können Sie das Öffnen eines Internetbrowsers und einer beliebigen Webseite simulieren und anschließend Informationen von dieser Seite abrufen. Zu diesem Zweck wird ein WebDriver verwendet, der zur Steuerung von Webbrowsern dient.
Falls Sie Selenium noch nicht installiert haben, müssen Sie sowohl die Selenium-Bibliothek als auch einen Browser-Treiber installieren. Eine entsprechende Anleitung steht Ihnen in der Selenium-Dokumentation zur Verfügung.
Aufgrund seiner großen Beliebtheit findet auch der ChromeDriver in diesem Artikel Berücksichtigung, wobei die Schritte unabhängig vom Treiber die gleichen sind.
Im Folgenden erfahren Sie, wie Sie Python und Selenium zur Durchführung einiger gängiger Web-Scraping-Aufgaben verwenden können:
Suche nach Produkten
Um Selenium zur Simulation der Suche nach Walmart-Produkten verwenden zu können, müssen Sie das Tool zunächst importieren. Dazu können Sie den folgenden Code verwenden:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import ServiceNach dem Import von Selenium wird im nächsten Schritt ein Webbrowser (in diesem Fall Chrome) damit geöffnet. Sie können nach Wunsch auch einen anderen Browser wählen. Nachdem ein Browser geöffnet wurde, sind die darauffolgenden Schritte stets identisch. Das Öffnen eines Browsers ist ganz einfach: Führen Sie dazu den folgenden Code als Python-Skript oder in einem Jupyter-Notizbuch aus:
s=Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=s)Dieser einfache Code bewirkt schlicht und einfach, dass Chrome geöffnet wird. Die Ausgabe sieht folgendermaßen aus:
Nachdem Sie Chrome geöffnet haben, rufen Sie nun die Homepage von Walmart auf, wozu Sie folgenden Code verwenden können:
driver.get("https://www.walmart.com")
Wie im Screenshot zu sehen ist, wird damit die Website Walmart.com aufgerufen.
Als Nächstes sehen wir uns den Quellcode der Seite mithilfe des Werkzeugs „Untersuchen“ genauer an. Dieses Werkzeug ermöglicht es Ihnen, jedes beliebige Element auf einer Webseite zu untersuchen. Sie können damit den HTML- und CSS-Code einer beliebigen Webseite anzeigen (und sogar bearbeiten).
Da wir hier nach einem Produkt suchen wollen, navigieren Sie zunächst zur Suchleiste, klicken mit der rechten Maustaste darauf und wählen „Untersuchen“. Suchen Sie das Eingabe-Tag mit dem Attribut type gleich search. Dies ist die Suchleiste, in die der Suchbegriff einzugeben ist. Suchen Sie dann das Attribut name und sehen Sie sich seinen Wert an. In diesem Fall sehen Sie, dass das Attribut name den Wert q hat:
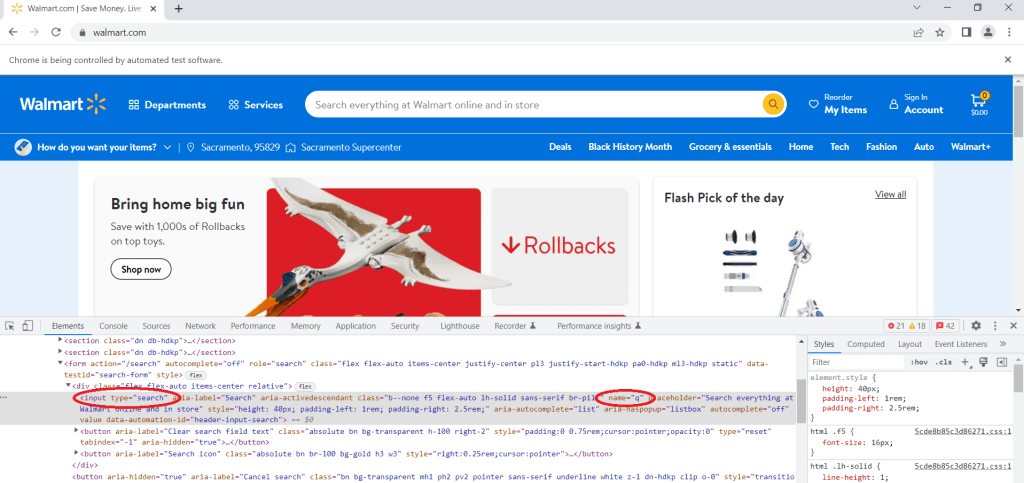
Zur Eingabe einer Suchanfrage in der Suchleiste können Sie folgenden Code verwenden:
search = driver.find_element("name", "q")
search.send_keys("Gaming Laptops")Dieser Code gibt die Suchanfrage Gaming Laptops ein. Sie können jedoch jede beliebige Suchphrase verwenden, indem Sie den Begriff „Gaming Laptops“ ein. Sie können jedoch jede beliebige Suchphrase verwenden, indem Sie den Begriff „Gaming Laptops“ durch einen beliebigen anderen Begriff ersetzen:
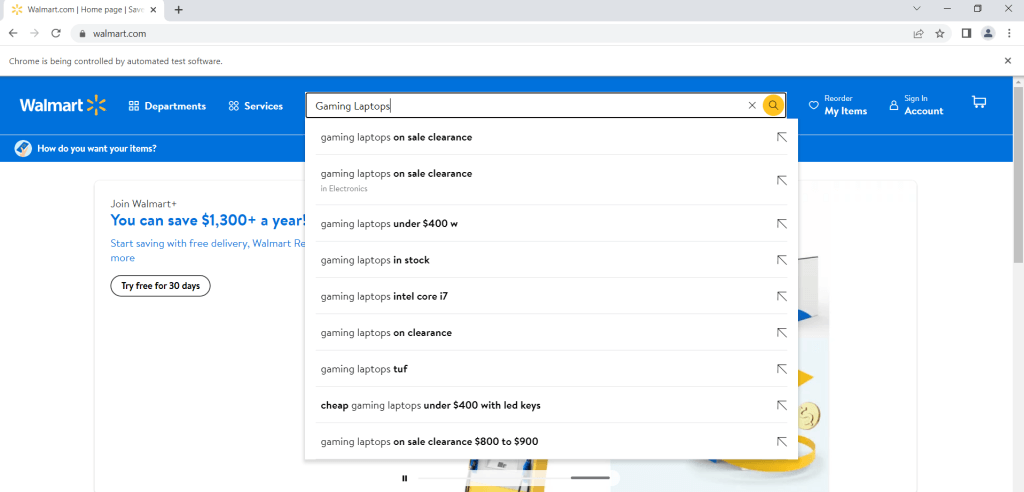
Bitte beachten Sie, dass der obige Code den Suchbegriff nur in die Suchleiste einträgt, aber nicht die entsprechende Suche startet. Um die Suche nach dem gewünschten Begriff durchzuführen, wird folgende Codezeile benötigt:
search.send_keys(Keys.ENTER)Die Ausgabe sieht folgendermaßen aus:
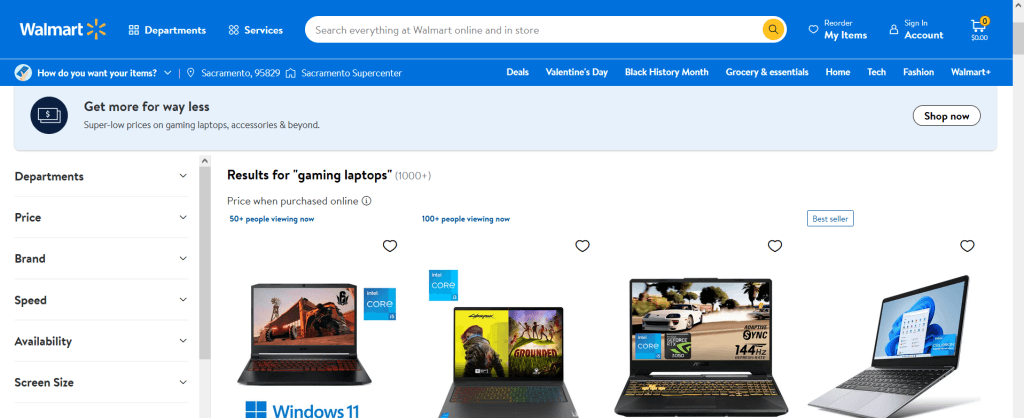
Nun sollten Sie sämtliche Treffer für den von Ihnen eingegebenen Suchbegriff erhalten. Um nach einem anderen Begriff zu suchen, müssen Sie lediglich die letzten beiden Zeilen des Codes mit dem gewünschten neuen Suchbegriff ausführen.
Navigieren zu einer Produktseite und Scrapen von Produktinformationen
Eine weitere gängige Aufgabe, die sich mithilfe von Selenium ausführen lässt, ist das Öffnen der Seite eines bestimmten Produkts und das Abrufen diesbezüglicher Informationen. Sie können beispielsweise den Namen, die Beschreibung, den Preis, die Bewertung oder die Rezensionen des Produkts auslesen.
Nehmen wir an, Sie haben ein Produkt ausgewählt, dessen Informationen Sie scrapen möchten. Öffnen Sie zuerst die Produktseite. Dafür können Sie folgenden Code verwenden (vorausgesetzt, Sie haben Selenium im ersten Beispiel bereits installiert und importiert):
url = "https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101"
driver.get(url)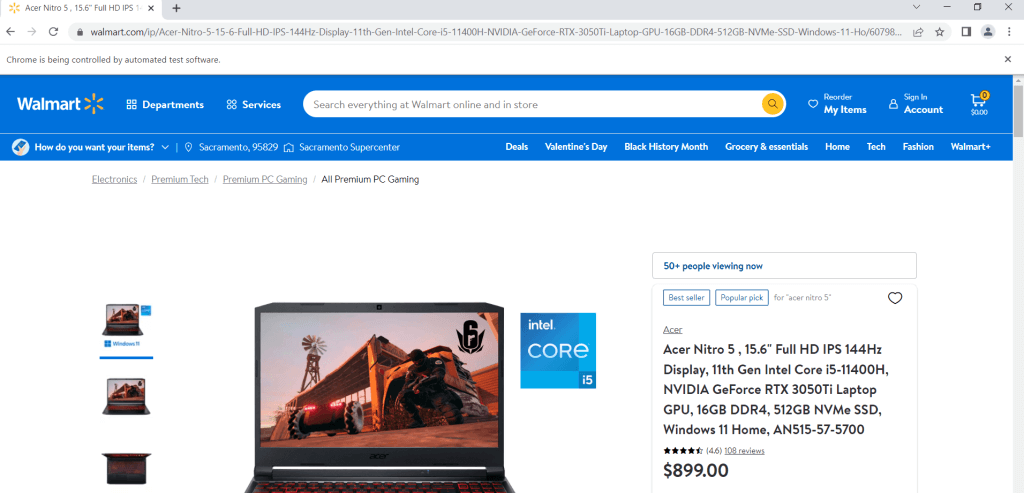
Sobald die Seite aufgerufen wurde, müssen Sie das Werkzeug „Untersuchen“ verwenden: Navigieren Sie zu einem beliebigen Element, dessen Informationen Sie scrapen möchten, klicken Sie mit der rechten Maustaste darauf und wählen Sie „Untersuchen“. Wenn Sie beispielsweise den Produkttitel untersuchen, werden Sie feststellen, dass der Titel in einem H1-Tag steht. Da dies der einzige H1-Tag auf der Seite ist, können Sie ihn mithilfe des folgenden Codes auslesen:
title = driver.find_element(By.TAG_NAME, "h1")
print(title.text)
>>>'Acer Nitro 5 , 15.6" Full HD IPS 144Hz Display, 11th Gen Intel Core i5-11400H, NVIDIA GeForce RTX 3050Ti Laptop GPU, 16GB DDR4, 512GB NVMe SSD, Windows 11 Home, AN515-57-5700'Analog dazu können Sie den Preis, die Bewertung und die Anzahl der Rezensionen zu einem Produkt ausfindig machen und scrapen:
price = driver.find_element(By.CSS_SELECTOR, '[itemprop="price"]')
print(price.text)
>>> '$899.00'
rating = driver.find_element(By.CLASS_NAME,"rating-number")
print(rating.text)
>>> '(4.6)'
number_of_reviews = driver.find_element(By.CSS_SELECTOR, '[itemprop="ratingCount"]')
print(number_of_reviews.text)
>>> '108 reviews'Beachten Sie bitte, dass Walmart das Scrapen von Daten auf die hier beschriebene Art und Weise erheblich erschwert. Dies liegt an den von Walmart eingesetzten Anti-Spam-Systemen, die aktiv versuchen, Web Scraper zu blockieren. Sollten Sie also feststellen, dass Ihre Web-Scraping-Versuche wiederholt blockiert werden, ist das wahrscheinlich nicht Ihre Schuld, und Sie werden nicht viel dagegen tun können. Die im nächsten Abschnitt vorgestellte Lösung sollte sich in dieser Hinsicht jedoch als wesentlich effektiver erweisen.
Schritt-für-Schritt-Anleitung zum Scraping der Walmart-Website mit Bright Data
Wie Sie feststellen konnten, gestaltet sich das Scrapen der Walmart-Website mit Python und Selenium nicht ganz so einfach. Die Web Scraper IDE von Bright Data liefert Ihnen für das Scrapen dieser Website jedoch eine wesentlich komfortablere Lösung. Dank dieses Tools lassen sich die oben beschriebenen Aufgaben einfacher und effizienter durchführen. Darüber hinaus bietet die Web Scraper IDE den Vorteil, dass Walmart Ihre Versuche nicht unverzüglich blockieren kann.
Um die Web Scraper IDE verwenden zu können, müssen Sie zunächst ein Benutzerkonto bei Bright Data einrichten. Nachdem Sie sich registriert und eingeloggt haben, sehen Sie die folgende Anzeige. Klicken Sie auf die Schaltfläche Datasets & Web Scraper IDE auf der linken Seite:
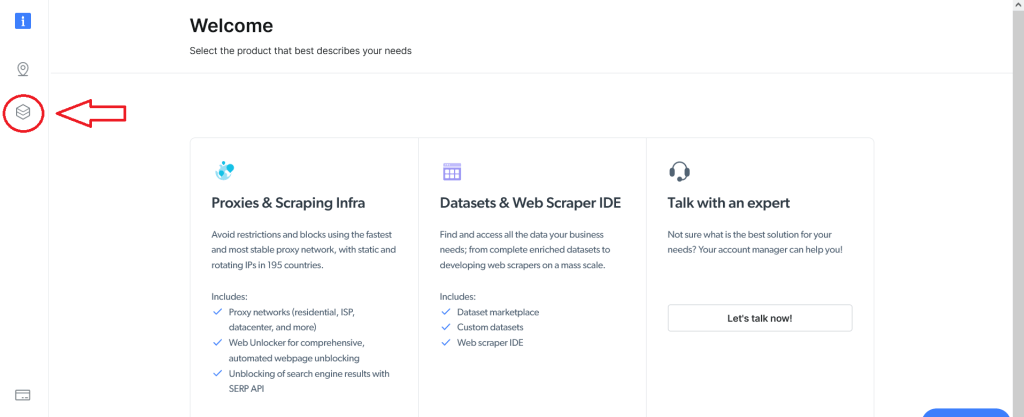
Daraufhin erscheint die folgende Anzeige. Navigieren Sie von dort aus zum Feld My scrapers („Meine Scraper“):
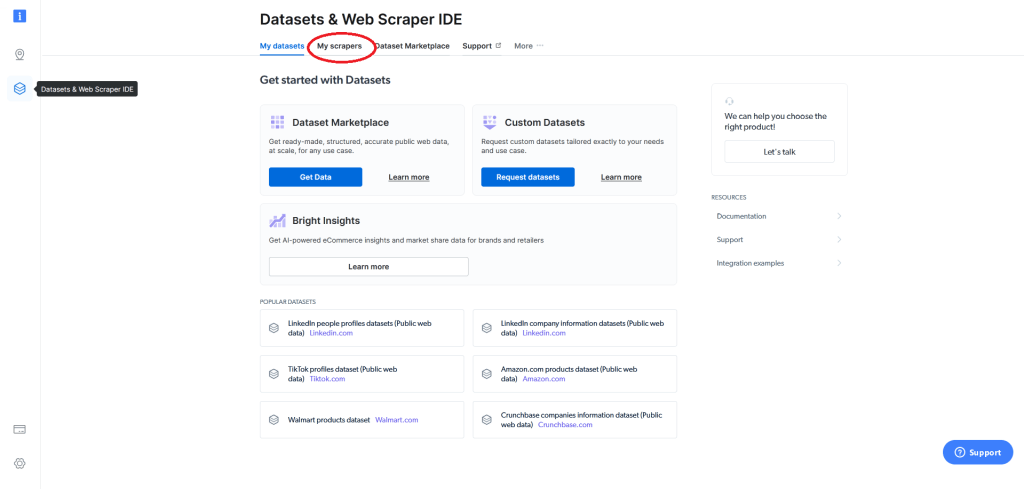
Hier werden Ihre bestehenden Web Scraper (falls vorhanden) angezeigt und Sie haben die Möglichkeit zur Erstellung eines Web Scrapers (IDE). Sollten Sie Bright Data zum ersten Mal verwenden und somit noch über keine Web Scraper verfügen, klicken Sie auf Develop a web scraper (IDE) („Web Scraper erstellen“):
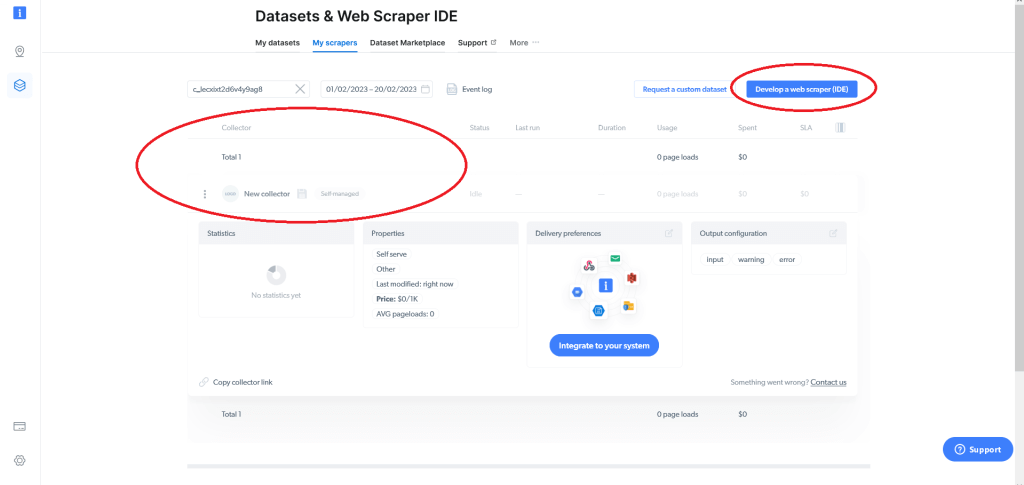
Sie können entweder eine der vorhandenen Vorlagen verwenden oder den Code von Grund auf neu schreiben. Zum Scrapen von Walmart.com klicken Sie auf Start from scratch („Neu beginnen“). Daraufhin wird die Bright Data Web Scraper IDE geöffnet:
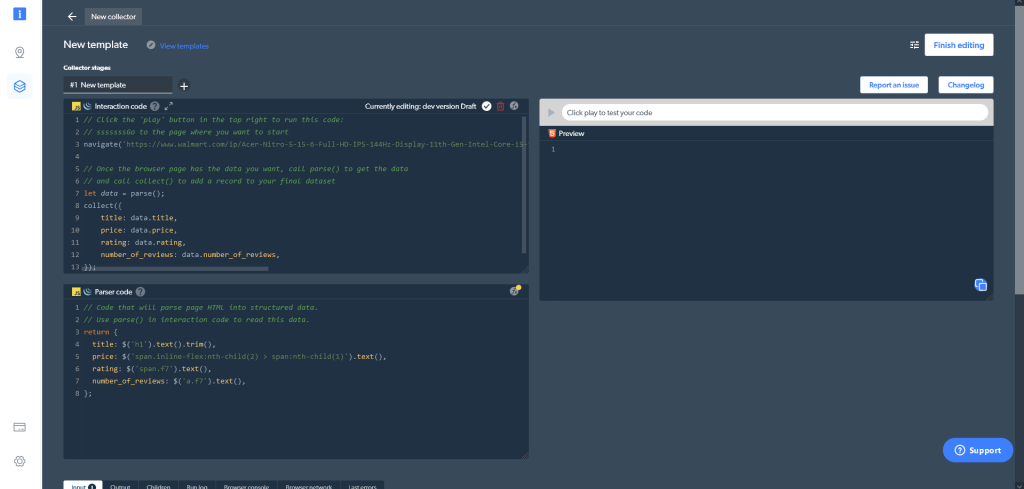
Die Web Scraper IDE umfasst eine Reihe unterschiedlicher Fenster. Im linken oberen Bereich befindet sich das Fenster Interaction code („Interaktionscode“). Wie sein Name bereits andeutet, wird dieses Fenster für die Interaktion mit einer Website verwendet (z. B. zum Navigieren und Scrollen auf der Website, zum Klicken auf Schaltflächen und für diverse sonstige Vorgänge). Darunter befindet sich das Fenster Parser code („Parser-Code“), über das Sie die HTML-Ergebnisse aus der Interaktion mit der Website parsen können. Auf der rechten Seite steht Ihnen eine Vorschau zur Verfügung, um Ihren Code zu testen.
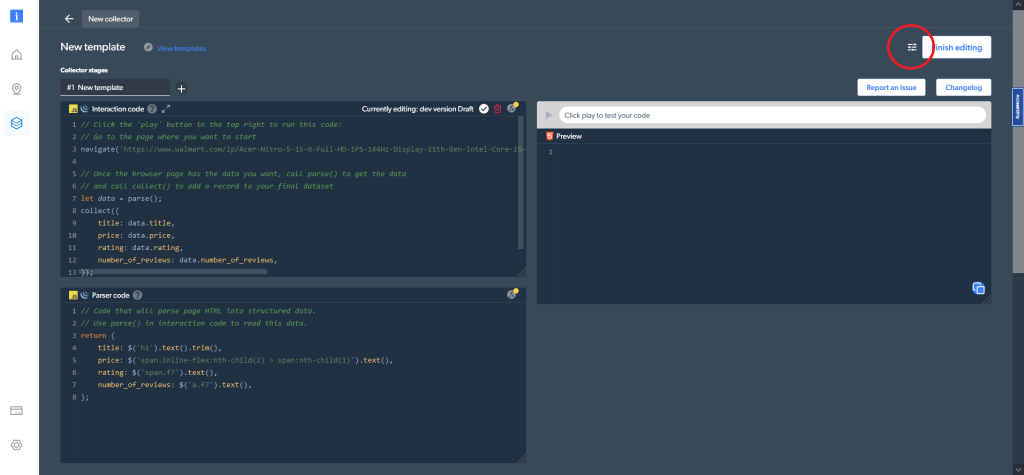
Zusätzlich können Sie in den Code-Einstellungen in der rechten oberen Ecke zwischen unterschiedlichen Worker-Typen auswählen. Sie können zwischen einem Code (der Standardoption) und einem Browser-Worker zum Navigieren und Crawlen der Daten umschalten:
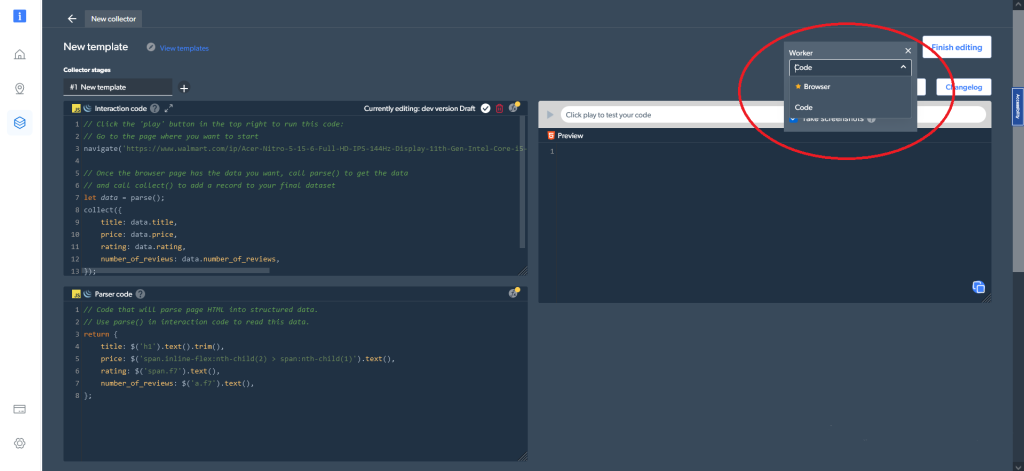
Lernen Sie nun, wie Sie die gleichen Daten für dasselbe Produkt wie zuvor mit Python und Selenium abrufen können. Rufen Sie zunächst die Produktseite auf. Dazu können Sie im Fenster Interaction code die folgende Codezeile verwenden:
navigate('https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101');Stattdessen können Sie mit navigate(input.url) auch einen veränderbaren Eingabeparameter verwenden. Fügen Sie in diesem Fall die zu scrapenden URLs wie hier gezeigt als Eingabe hinzu:
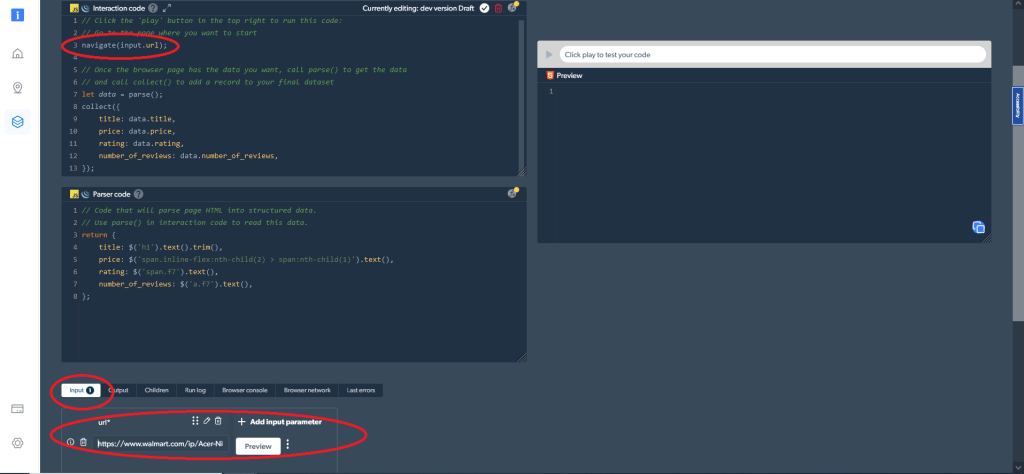
Danach werden die gewünschten Daten gesammelt, wozu Sie folgenden Code verwenden können:
let data = parse();
collect({
title: data.title,
price: data.price,
rating: data.rating,
number_of_reviews: data.number_of_reviews,
});Als letzten Schritt müssen Sie das HTML in strukturierte Daten parsen. Dazu können Sie im Fenster Parser code den folgenden Code verwenden:
return {
title: $('h1').text().trim(),
price: $('span.inline-flex:nth-child(2) > span:nth-child(1)').text(),
rating: $('span.f7').text(),
number_of_reviews: $('a.f7').text(),
};Anschließend können Sie die gewünschten Daten direkt in der Web Scraper IDE abrufen. Klicken Sie einfach auf die Wiedergabe-Schaltfläche auf der rechten Seite (oder drücken Sie Strg+Eingabe), um die gewünschten Ergebnisse auszulesen. Alternativ können Sie die Daten auch direkt aus der Web Scraper IDE herunterladen:
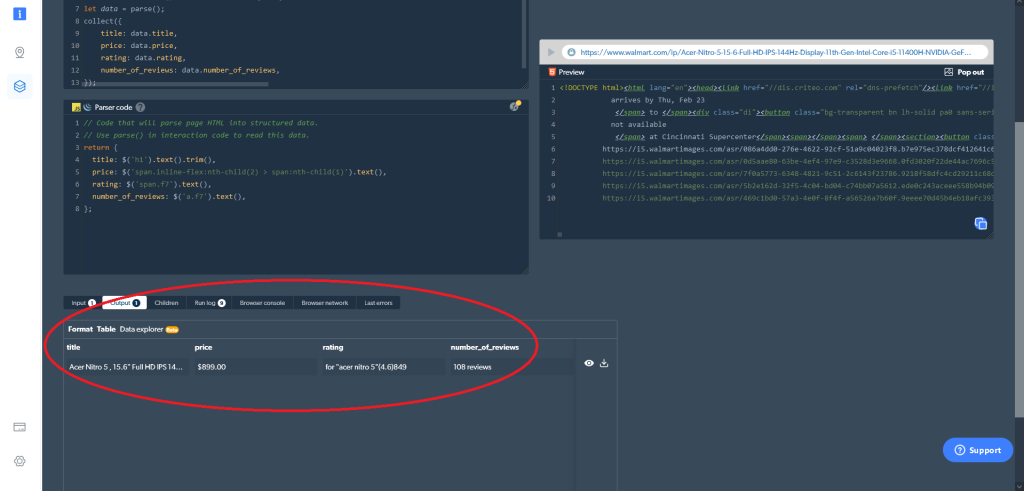
Falls Sie als Worker-Typ Browser statt Code gewählt haben, sähe die Ausgabe wie folgt aus:
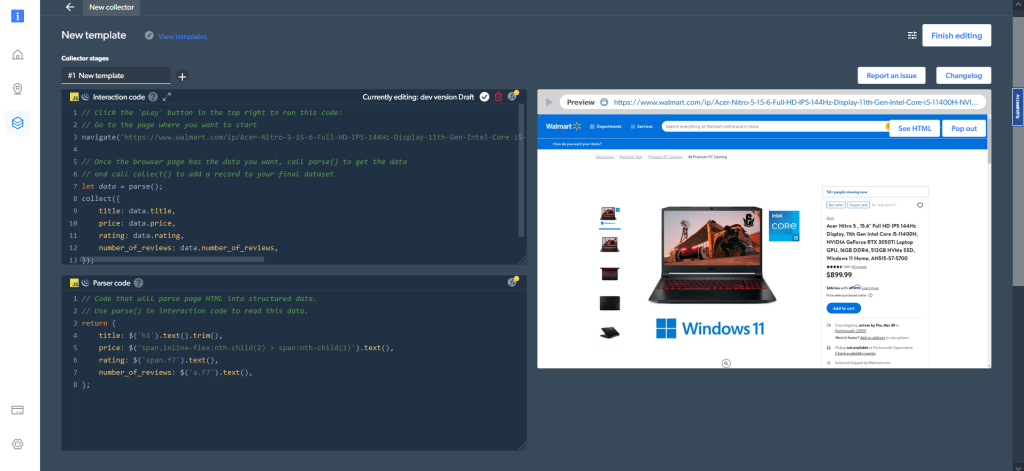
Das direkte Abrufen von Ergebnissen in der Web Scraper IDE ist nur eine der Möglichkeiten, die Ihnen zur Abfrage der Daten zur Verfügung stehen. Sie können Ihre Präferenzen für die Ausgabe im Dashboard My scrapers festlegen.
Sollte sich das Web Scraping selbst mit der Web Scraper IDE als zu kompliziert erweisen, bietet Bright Data Ihnen im Dataset Marketplace („Datensatz-Marktplatz“) einen Walmart-Produktdatensatz an, in dem zahlreiche Datensätze mit einem Klick abgerufen werden können:
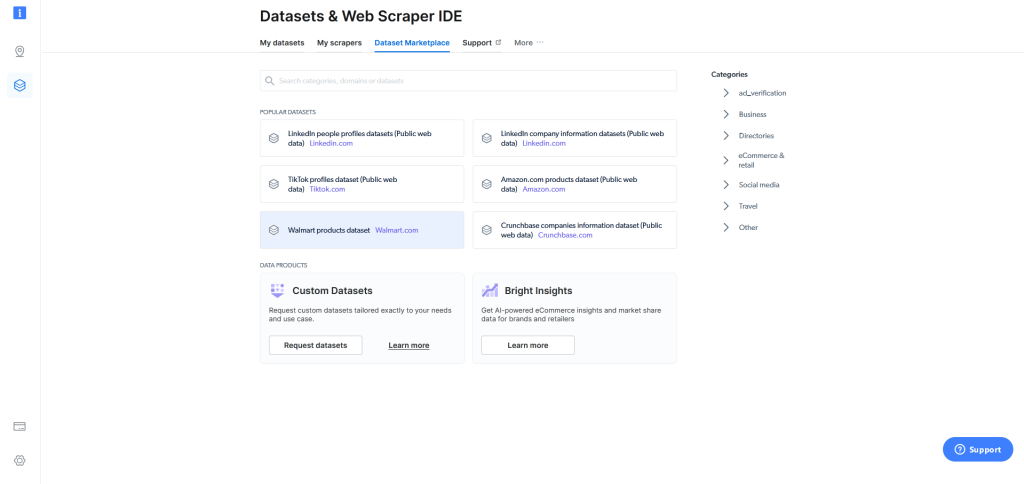
Wie Sie gesehen haben, ist die Verwendung der Web Scraper IDE von Bright Data einfacher und anwenderfreundlicher als das Erstellen eines eigenen Web Scrapers mithilfe von Python und Selenium. Und das Beste dabei: Die Web Scraper IDE von Bright Data erlaubt es auch Anfängern, mit dem Sammeln von Daten der Walmart-Website zu beginnen. Dagegen sind zum Scrapen von Walmart.com mit Python und Selenium fundierte Programmierkenntnisse notwendig.
Ein weiterer überzeugender Pluspunkt des Walmart Scrapers von Bright Data ist neben der Benutzerfreundlichkeit seine Skalierbarkeit. Sie können mühelos Daten zu beliebig vielen Produkten abrufen.
Ein wichtiger Aspekt im Zusammenhang mit Web Scraping sind die geltenden Datenschutzbestimmungen. Viele Unternehmen unterbinden oder beschränken das Scrapen von Informationen von ihrer Website. Wenn Sie also Ihren eigenen Web Scraper mithilfe von Python und Selenium erstellen, müssen Sie sicherstellen, dass Sie nicht gegen irgendwelche Gesetze und Vorschriften verstoßen. Bei Verwendung der Web Scraper IDE von Bright Data übernimmt jedoch Bright Data diese Verantwortung und sorgt dafür, dass die branchenüblichen Vorgehensweisen und sämtliche Datenschutzbestimmungen eingehalten werden.
Fazit
In diesem Artikel haben Sie erfahren, was für das Scrapen von Walmart-Daten spricht, und gelernt, wie Sie die Preise, Namen, die Anzahl der Rezensionen und Bewertungen von Tausenden von Walmart-Produkten auslesen können.
Wie Sie gesehen haben, können Sie diese Daten mithilfe von Python und Selenium scrapen, was sich jedoch als schwierig erweisen kann und mit einigen insbesondere für Anfänger nicht unerheblichen Herausforderungen verbunden ist. Allerdings gibt es Lösungen, die das Scrapen von Walmart-Daten wesentlich vereinfachen, wie z. B. die Web Scraper IDE. Sie bietet Funktionen und Codevorlagen zum Scrapen vieler beliebter Websites, hilft beim Umgehen von CAPTCHAs und erfüllt sämtliche Datenschutzbestimmungen.






